
基于机器学习的大数据隐私非交互式查询研究
2023-09-20 10:36赵青杉
计算机仿真 2023年8期
李 静,赵青杉,高 媛
(1. 忻州师范学院计算机系,山西 忻州 034000;2. 中北大学大数据学院,山西 太原 030051)
1 引言
在网络信息发达的现代社会,基于网络技术与信息采集设备获取的海量数据极具价值,以这些数据为基础挖掘不同领域状态,实现数据共享成为当今时代数据应用的流行趋势[1,2]。但数据共享技术在为使用者带来便利的同时也存在一定风险[3],易导致使用者自身隐私信息被他人窥探,成为他人获取不法利益的工具。针对此问题,部分研究学者提出隐私保护数据查询理念,成为数据共享领域的一大热点。
文献[4]提出大数据环境中交互式查询差分隐私保护方法。引入数据关联性分析方法,降低冗余信息量。利用交替方向乘子法建立查询负载矩阵,并对其进行分解处理。采用自适应加噪技术产生差分隐私保护所需要的合理数量的噪声,实现大数据交互式查询差分隐私保护。文献[5]提出基于混合型位置大数据的差分隐私聚类方法。采用KD-medoids降维聚类算法,预处理混合型位置大数据,实现大数据位置信息的提取与记录。利用邻近搜索,得到聚类中心点,并对其进行k聚类簇划分,加入Laplace噪声,使其满足差分隐私。但是,异常传统方法虽然具有较好的隐私数据保护性能,但传统研究主要集中于交互式查询,导致非交互式查询存在耗时较长的问题。
针对这一问题,研究基于机器学习的大数据隐私非交互式查询方法,在非交互式查询过程中有机结合机器学习和差分隐私,利用预测模型获取满足差分隐私标准的查询结果,并通过实验分析验证该方法的实际应用效果。
2 大数据隐私非交互式查询方法
基于机器学习[6,7]的大数据隐私非交互式查询方法可通过三个主要步骤实现:
1)在大数据集A中,基于关联规则挖掘其中数据包含的关联程度,设定阈值,选取关联程度低于阈值的数据记录,构建大数据特征集W;
2)选取K-means聚类算法划分特征集,获取查询集f(W),采用自适应噪声添加算法在查询集内加入拉普拉斯噪声,获取符合差分隐私标准的查询集(W);
3)利用f(W)和(W)构建训练样本集,采用机器学习算法中的线性回归算法对其进行训练,生成预测模型,在其中输入A内的初始数据,得到符合差分隐私保护的查询结果集合。
2.1 基于关联规则的大数据特征集构建
针对A,采用FP-growth关联分析算法挖掘其中数据包含的关联程度[8],实现流程如图1所示。
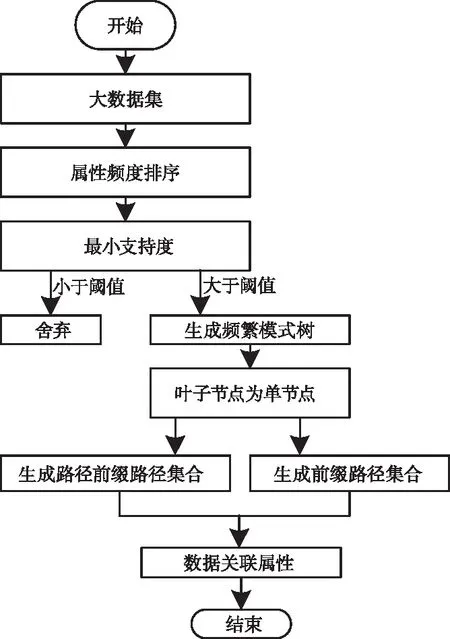
图1 数据关联程度挖掘流程
数据关联程度挖掘流程可归纳为5个环节,具体描述如下:
环节1:整体扫描A,得到频繁项候选集Ap;
环节2:依照最小支持度在Ap内选取数据,生成频繁模式树;
环节3:对频繁模式树进行剪枝;
环节4:在上一环节基础上获取前缀路径集合Az;
环节5:基于Az得到数据关联程度。
将数据关联程度与预先设定的阈值φ相比,选取关联程度低于φ的数据记录,构建W。
2.2 查询集构建
2.2.1 K-means聚类算法
针对W={Wi|i=1,2,…,n},采用K-means聚类算法划分W,以Cj(j=1,2,…,k)和cj(j=1,2,…,k)分别描述聚类的k个类别和初始聚类中心,cj表达式如下

(1)
式(1)内,n表示W内特征数据数量。
利用式(2)确定数据wi与数据wj间的欧氏距离d(wi,wj):

(2)
采用K-means聚类算法的迭代过程将W内特征数据划分至不同簇内[9],令目标函数H最小化,由此得到具有独立性与紧密性的簇。
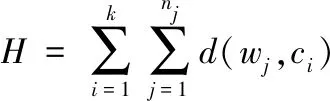
(3)
K-means聚类算法具体实现过程如下:
1)设定输入与输出
输入:k与W={Wi|i=1,2,…,n},输出:符合H最小化的k个簇;
2)确定cj
在W={Wi|i=1,2,…,n}内的n个特征数据内随机确定k个cj;
3)迭代进行(4)与(5)内容,至H固定;
4)依照各特征数据的均值,确定各特征数据同k个cj之间的d值,依照权重下限值再次划分相应特征数据;
5)确定各聚类均值。
基于以上过程获取f(W)。
2.2.2 基于密度的初始聚类中心算法
采用基于密度的初始聚类中心点算法确定K-means聚类算法中的k个cj。利用式(4)确定W={Wi|i=1,2,…,n}内全部特征数据的密度:

(4)
式中,σ为初始聚类中心点集合。
利用式(5)确定密度最大的特征数据:
wmax=max{wi|wi∈W,i=1,2,…,n}
(5)
以wmax为第一个初始聚类中心,将其引入M内,得到M=M∪{wmax},同时在W内清除此特征数据,依据半径r确定wmax邻域中全部的特征数据,在W内清除这些特征数据。在此基础上再次利用式(5)确定密度最大的特征数据,直至初始聚类中心达到k个。
2.2.3 自适应噪声添加算法
为保护查询结果的隐私性,需在f(W)内添加满足拉普拉斯分布的噪声[10]。但特殊数据具有较高灵敏度,直接添加噪声将造成数据丧失可用性,因此需采用自适应地噪声添加算法。大数据非交互式查询结果的隐私保护水平由隐私保护预算ε描述,ε值与隐私保护水平和噪声添加量之间均表现为反比例相关。基于此依照高适用性的ε值能够同时确定隐私保护水平和噪声添加量。
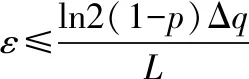
图2所示为自适应噪声添加流程。
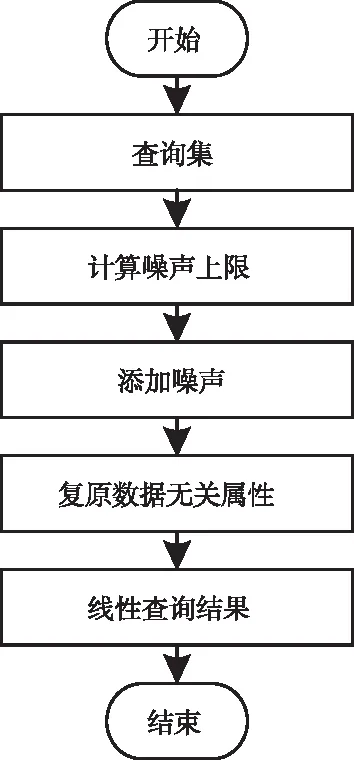
图2 自适应噪声添加流程
2.3 基于机器学习算法的隐私保护预测模型
基于以上过程获取实际查询集f(W)与符合差分隐私标准的查询集(W),利用f(W)和(W)构建训练样本集T=〈f(W),(W)〉,采用机器学习算法中的线性回归算法对其进行训练,生成预测模型,利用该模型预测查询结果。
利用基于机器学习算法的隐私保护预测模型获取大数据隐私非交互查询结果的具体过程如下:
设定输入为大数据特征集的查询集f(W)、符合差分隐私标准的查询集(W)、ε值和大数据集A;设定输出为隐私非交互式查询结果集。
1)利用f(W)和(W)构建训练样本集T=〈f(W),(W)〉;
2)利用线性回归算法训练T=〈f(W),(W)〉,生成预测模型;
3)在所获取的预测模型内输入大数据集;
4)获取大数据隐私非交互式查询结果f(A)。
3 实验分析
实验为验证本文所研究基于机器学习的大数据隐私非交互式查询研究方法在实际查询应用中的应用效果,以某购物网站数据库内2020年7月、8月和9月的销售数据为实验数据,分别构建三个初始大数据集,分别命名为7月数据集、8月数据集和9月数据集,各数据集内每一个数据均表示一次商品销售行为。实验设计之初,为兼顾本文方法并行性与可扩展性等性能的验证,选取分布式集群式实验方法。同时为确保实验过程中的网络时延无差异,实验过程在相同网络环境下进行。在开源的Hadoop系统中验证本文方法的应用性能,实验所得具体结果如下所示。
3.1 数据无关性实验结果与分析
针对实验所使用的三个大数据集,即7月数据集、8月数据集和9月数据集,设置最小支持度,确定各数据集的关联关系,所获得结果通过表1描述。
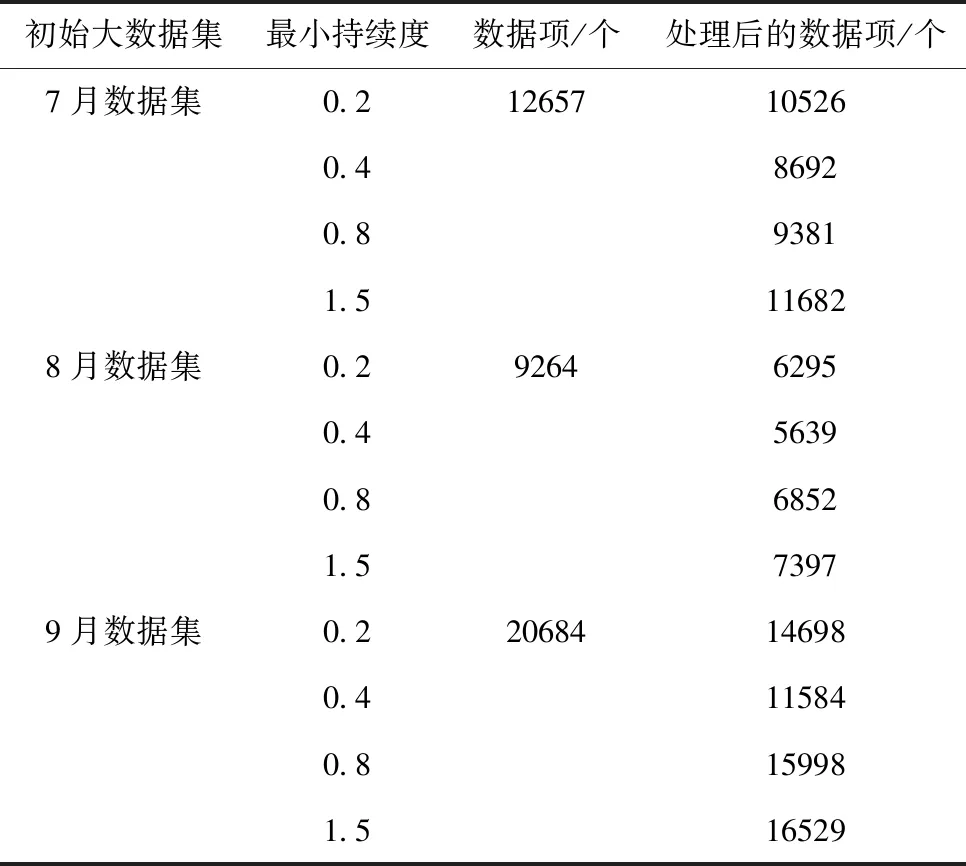
表1 各数据集关联关系分析结果
分析表1得到,采用所提方法分析各数据集后,数据集内数据量呈现不同程度的降低趋势,由此说明采用关联关系能够显著降低大数据隐私非交互查询过程中的数据计算压力,节约大量时间与空间。同时分析表1还能得到,在最小支持度值分别为0.2、0.4、0.8和1.5的条件下,三个数据集的数据量均在最小支持度值为0.4的条件下降低幅度最显著,由此在实际应用过程中,可将本文方法中的最小支持度值设定为0.4。
3.2 数据效用性实验结果与分析
本文方法中为确保查询结果的隐私性,在查询过程中引入了噪声。数据效用性分析的主要目的是判断本文方法所获取的大数据隐私非交互式查询结果受噪声干扰的程度。分析过程中为进一步说明本文方法的数据效用性能,以文献[4]方法和文献[5]方法为对比方法,以平均绝对误差为指标,对比本文方法与对比方法所获取的大数据隐私非交互式查询结果精度,平均绝对误差值与查询结果精度之间具有反比例相关性,即平均绝对误差值越低,方法所得到的查询结果精度越高。设定隐私保护预算值取值范围为0.1—1。本文方法与两种对比方法查询结果精度对比结果如图3所示。

图3 数据效用性分析结果
分析图3得到,在三个数据集内,随着隐私保护预算值逐渐提升,本文方法与两种对比方法所获取的查询结果平均绝对误差值均呈现不同程度的下降趋势,但在三个数据集内,本文方法所获取的查询结果平均绝对误差值均低于两种对比方法。
在图3(a)内,在隐私保护预算值取值为0.3的条件下,本文方法的平均绝对误差值为89项,文献[4]方法和文献[5]方法的平均绝对误差值分别为231项和174项;在隐私保护预算值取值为0.6的条件下,本文方法的平均绝对误差值为20项,文献[4]方法和文献[5]方法的平均绝对误差值分别为110项和64项;在隐私保护预算值取值为1.0的条件下,本文方法的平均绝对误差值为4项,文献[4]方法和文献[5]方法的平均绝对误差值分别为12项和23项。在图3(b)与图3(c)内不同隐私保护预算值条件下同样能够表现出本文方法所得到的查询结果精度优势。这是由于本文方法在保护查询结果隐私性过程中采用添加噪声的方式,未损耗隐私保护预算。
同时本文方法中的隐私保护预算值反映了本文方法的隐私保护性能,在该值逐渐提升的条件下,本文方法所得到的查询结果精度逐渐提升,说明隐私保护程度越低,本文方法所得到的查询结果精度越高,即所得到的查询结果数据效应性更高。
4 结论
本文针对以往普遍使用的隐私数据查询方法中存在的部分缺陷,研究基于机器学习的大数据隐私非交互式查询方法。本文方法以机器学习问题取代数据查询问题,通过机器学习算法中的线性回归算法构建预测模型,获取符合差分隐私标准的查询结果。并通过实验验证了本文方法的可应用性。
下一步研究工作主要针对查询记录内容类别属性的划分,基于查询记录的类别属性差异优化本文方法,可在确保本文方法查询结果精度基础上,提升大数据集收敛速度。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2021年5期)2021-07-28
当代陕西(2019年15期)2019-09-02
电影(2018年8期)2018-09-21
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
