
基于超声射频信号的支持向量机双参量B线识别方法*
2023-09-20 06:49张皓宇马泉龙钟徽
应用声学 2023年5期
张皓宇 马泉龙 张 蕾 钟徽
(西安交通大学生命学院 生物医学信息工程教育部重点实验室 西安 710049)
0 引言
随着现代超声医学的不断发展进步,曾经被视作超声盲区的肺脏超声检查也由于其无辐射、可床旁诊断等优点成为临床上检测肺脏疾病、监测重症病人生理指标的重要手段。肺超声中有一种被称为B 线的重要超声伪影,多用于检测、诊断肺部疾病,在超声影像上表现为从胸膜线产生并延伸至屏幕底部的离散、激光样垂直高回声伪影[1],并与肺滑动同步移动。1998 年,Lichtenstein等[2]提出B 线定义,并用肺脏超声图像中的B 线来区分肺水肿和慢性阻塞性肺病。2004 年,Jambrik等[3]通过分析121名患者的胸部X光片与肺超声之间的相关性,证实了B线作为检测血管外肺水指标的可行性。2010 年,Jambrik等[4]通过肺损伤动物模型实验验证了B 线数量与肺干湿比之间的显著相关性,提出了一种简单、半定量、无创的评估肺超声B 线的肺积水指数。肺超声影像中B 线数量的增加与肺水肿、肺纤维化、肺炎等肺病变之间显著的相关性已经成为临床上对患者进行床旁无创、快速诊断的重要依据,医生可以按照肺超声检查国际推荐标准[5],快速评估患者的病情,并做出相应的诊断。但在相同的评估标准之下,不同的医生对同一患者的评估、甚至同一医生在不同时间对同一患者的评估都可能会产生一定偏差,这与评估者的临床经验、评估时的生理状态等因素有关。因此,能够辅助医生对肺超声进行评估的算法可以大大提高医生诊断的稳定性和准确性。
2016年,Moshavegh等[6]提出了一种自动检测和表征B 线的方法,该方法首先检测图像中分割胸膜线,再向下对B线进行检测。Corradi等[7]通过比较肺超声图像灰度值变化的平均值和标准差,提出了一种检测机械通气心脏手术患者肺水肿的计算机辅助定量方法。2020年,Cristiana等[8]提出了一种基于深度卷积神经网络的自动评估肺超声B 线的深度学习算法,并将评估结果与超声专家评估结果进行比较,表现出较好的敏感性和特异性。
现有的B 线识别方法大多基于超声图像,但超声图像是由原始超声回波射频(Radio frequency,RF)信号经过预处理、平滑、对比度增强等处理得到的便于医生肉眼观察的图像,在由RF 信号转变为图像的过程中,真实信号丢失或弱化了一部分的组织信息以换取超声图像更有利于观察的性能,故本文提出的利用原始RF 信号对肺超声结果进行评估可以提高信息的利用率,避免不同超声仪器参数设置的影响,可以得到普适性更高的评估算法。与基于卷积神经网络的自动评估B 线深度学习算法相比,本文采用的非线性支持向量机(Support vector machine,SVM)复杂度更小,提取特征参量的运算量也更小,有望应用于临床超声检查中,实现实时的B线识别功能。
1 理论和方法
1.1 特征参数选取
本文选用的超声RF 数据每帧包含256 条扫描线,每条扫描线有2336个数据点,采样率为40 MHz。由于B 线的特征是垂直于成像探头的激光样线,与扫描线方向相同。故将每一条扫描线上的全部RF数据点看作一个识别对象,分别对每个识别对象提取信息熵、排列熵、峰度、偏度和能量5 种特征参量,并评估这些参量B线识别的效果。
(1) 信息熵
信息熵是反映信号混乱程度的参数[9],信号越混乱,信息熵越大。肺中富含气体,超声波在气相表面发生全反射,无法探测气相后的组织信息,在超声图像上产生A 线和黑色区域,黑色区域在RF 信号中表现为0 左右的低幅值数据,由于混响效应[10]而产生的B 线在图像上表现为明亮的彗星尾征,在RF 信号中表现为幅值较高的回波数据。本研究认为与正常肺气相区域相比,B 线区域RF 数据的信息熵在宏观上应具有更大的值,选取信息熵作为特征参量有助于B线识别算法的实现。信息熵的计算公式如下:
其中,H为信息熵,X为RF 信号时间序列幅值,f(Xi)是信号幅值为Xi的概率密度,单位为bit。
(2) 排列熵
排列熵是一种检测动力学突变和时间序列随机性的方法,可以反映出时间序列微小的细节变化,能够定量评估信号序列中含有的随机噪声,越规律的时间序列,排列熵越小[11]。本研究认为胸膜线下,病变导致的血管外肺水增多使得肺水肿区域富含气体与液体,而超声波在该区域的多次反射形成了B 线,故B 线区域与其他区域相比,其RF 数据在微观上应具有一定的规律性与重复模式,选择排列熵作为特征参量有助于区分识别B 线。排列熵的计算步骤如下:
对一个含有2336 个数据点的元素X进行空间重构,得到矩阵Y为
式(2)中,m为嵌入维数,t为延迟时间,k=N -(m-1)t,矩阵Y的每一行都是一个重构分量,共有k个重构分量。
(a) 将每一个重构分量按照升序重新排列,得到向量中各元素位置的列索引构成一组符号序列:
(b)M维相空间映射不同的符号序列总共有m!种,计算每一种符号序列出现的次数除以总数m!,作为该符号序列出现的概率。得到概率{P1,P2,···,PK},按公式(4) 计算得到元素X的排列熵:
式(4)中,Hpe为元素X的排列熵,k为重构分量总数Pj为第j个符号序列出现的概率。
峰度与偏度是研究信号包络特征以及分级定征的常用统计量,本研究提取各个元素的峰度与偏度并进一步评估其在B线识别方面的效果。
(3) 峰度
峰度又称峰态系数,表征概率密度分布曲线在平均值处峰值高低的特征数。峰度反映了RF 信号包络峰部的尖度,是和正态分布相比较而言的统计量,如果峰度大于3,峰的形状比较尖,比正态分布更陡峭,反之亦然。RF数据元素X包络的峰度按公式(5)计算:
式(5)中,Kurt(X)为RF数据元素X包络的峰度,μ为RF数据元素X包络的均值。
(4) 偏度
偏度是统计数据分布偏斜方向和程度的度量,反映了RF 信号包络幅度值非对称性程度,偏度小于0 说明RF 信号包络中出现了少量值较小的数据点,偏度大于0说明RF信号包络中出现了少量值较大的数据点。RF 数据元素X包络的偏度按公式(6)计算:
式(6) 中,Skew(X)为RF 数据元素X包络的偏度,μ为RF 数据元素X包络的均值,σ为RF数据X包络的方差,k2、k3分别表示二阶和三阶中心矩。
(5) 能量
信号能量是表征信号时域特性的一个重要参数,从超声图像可以直观地看出与非B线区域相比,B 线区域更加明亮,灰度值更高,RF 数据同样表现出相似的特点,即B 线区域幅值更大,信号能量更高,故本研究选择信号能量作为B 线识别的特征参量,并进一步研究其B线识别性能。RF 信号元素X的能量按公式(7)计算:
式(7)中,E(X)为RF 信号元素X的能量,N为元素X中数据点的数量,Xj是元素X中第j个数据点的幅值。
1.2 基于非线性SVM的分类识别
SVM是一种监督学习方式的二分类模型,其决策边界是对学习样本求解的最大边距超平面,是一种具有稀疏性和稳健性的分类器,可以对线性可分的样本进行较准确的二元分类。对于线性不可分的学习样本,非线性SVM 利用核函数,通过非线性映射算法将二位线性不可分的样本映射到高维特征空间中,使得样本点再高维空间线性可分,采用与线性SVM 相同的间隔最大化原则学习得到非线性SVM模型。
对于n维特征空间,目标超平面为
其中,w=(w1,w2,···,wn)为法向量;b为位移项。求解最大超平面:
利用拉格朗日乘子法,结合特征空间多维特征,得到其对偶问题:
其中,κ(xi,xj)称为核函数,用于降低升维后特征空间的计算复杂度。本文主要使用的核函数为高斯核函数:
本研究从肺超声RF 数据提取的多个特征参数组成的二维原始空间均为线性不可分,故采用非线性SVM进行识别分类。
2 结果与分析
2.1 实验数据的获取
本实验选用西安交通大学医学院实验动物中心提供的实验6只白兔,平均体质量2.3 kg。实验器材和药品包括兔台、兔子固定箱、5 mL 注射器、留置针、0.9%氯化钠溶液、分析纯油酸、异氟烷。实验仪器采用Sonix Touch 超声诊断系统,线阵超声探头,频率4~10 MHz。美国MATRX动物呼吸麻醉机,氧气流量400 mL/min,异氟烷麻醉挥发罐档位2~4。
实验前对实验兔禁食8 H,并称重,将实验兔俯卧位放入兔子固定箱,佩戴呼吸麻醉机面罩,调整氧气流量至400 mL/min,麻醉挥发罐档位调至3 档,待兔子麻醉后撤下兔子固定箱,仰卧位固定于兔台,胸部备皮。由左右两侧第四、第五肋间对肺进行超声检查,留取正常无B线、具有明显胸膜线和A线的肺部超声图(图1(a))和RF 数据。按0.1 mL/kg 经耳缘静脉注射分析纯油酸,制备急性肺损伤模型,每隔1 min 进行一次肺超声检查,记录肺超声图像由存在少量B 线(图1(b))到存在弥漫性B线(图1(c))过程的RF数据和对应的超声图像共100组。
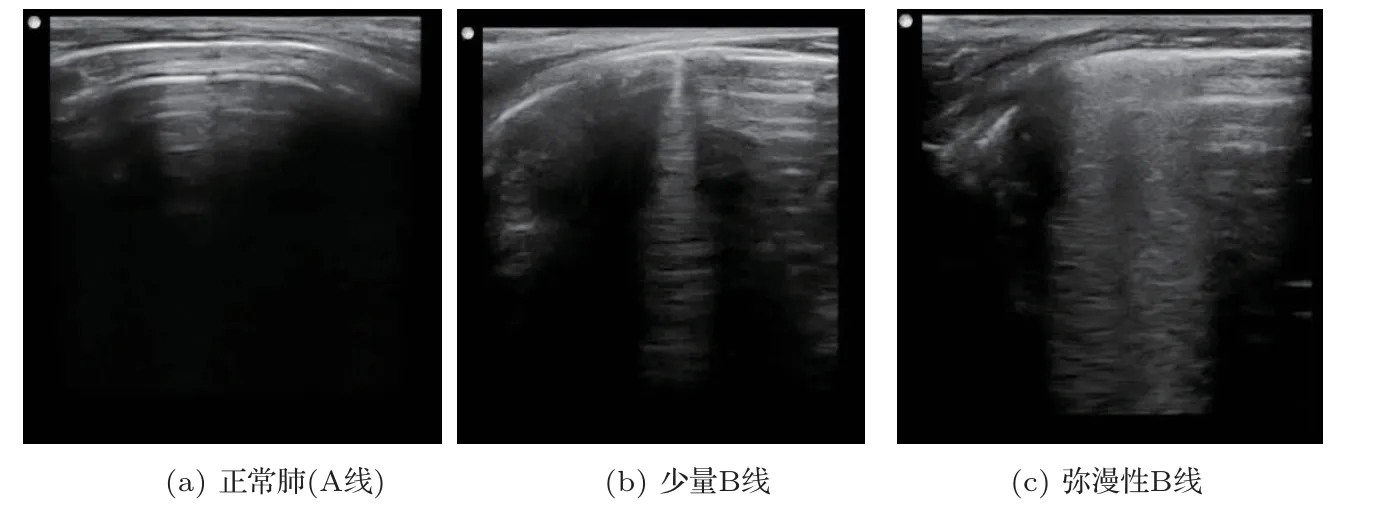
图1 肺超声图Fig.1 Images of lung ultrasound
2.2 单参数分析
本文共选取100 帧RF 原始数据,依据B 线从胸膜线产生并延伸至屏幕底部、与肺滑行同步运动、呈现离散、激光样垂直高回声的伪影表现的特征,对所有识别对象标定B 线或非B 线标签。分别统计B 线区域与非B 线区域各个特征参量的均值和标准差并使用独立样本t 检验判断其是否有显著差异性,如表1 所示。最后将各个参数随机平均分为10份,轮流取其中9份作为训练集,剩下1份作为测试集输入贝叶斯分类器,得到单参数分类的平均灵敏度、特异性、准确率和曲线下面积(Area under curve,AUC)如表2所示。
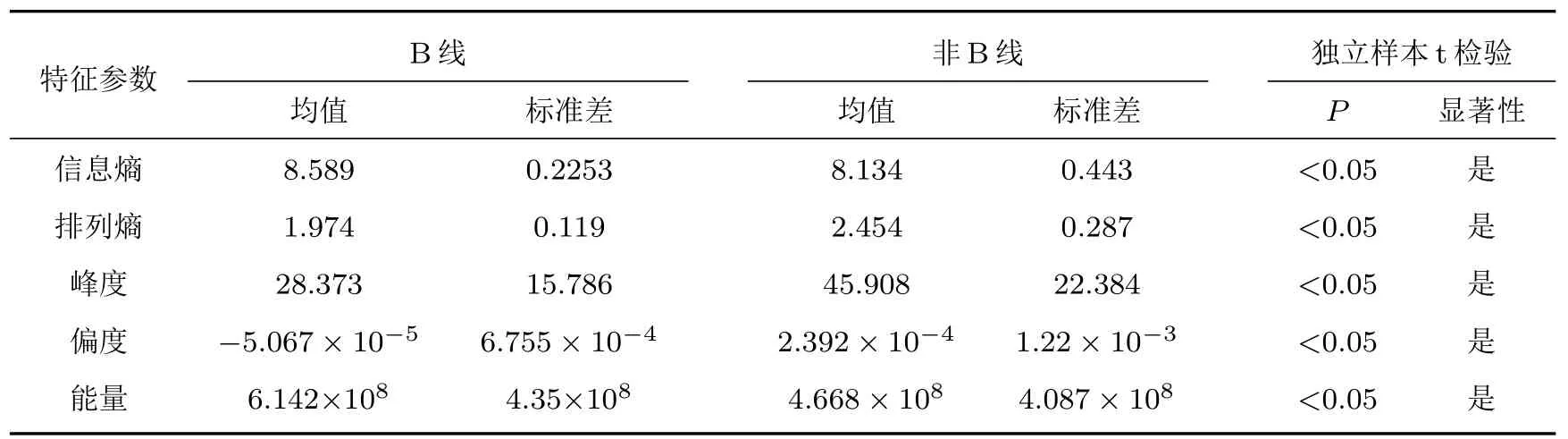
表1 特征参数统计特征Table 1 Statistical characteristics of characteristic parameters

表2 特征参数单参数贝叶斯分类Table 2 Bayesian classification results of single characteristic parameters
由表1 可见,对本文提取的5 个特征参数分别进行独立样本t 检验后,结果显示B 线与非B线的上述所有特征参数之间均具有显著差异性(P <0.05)。可以发现,B 线排列熵均值(1.974)显著低于非B 线排列熵均值(2.454);B 线信息熵均值(8.589)显著高于非B 线信息熵均值(8.134)。这是因为信息熵与排列熵分别从两个不同方面反映了信号的复杂程度,信息熵从信号幅值出现的概率密度评估信号在宏观上的混乱程度,排列熵却并不关注信号具体幅值,而是分析信号重构分量内数据升序排列顺序出现的概率,排列熵侧重于被分析信号内相似片段的重复性,而对相似片段内信号幅值较小的波动变化以及异常点并不敏感,相比于信息熵,排列熵弱化了B 线信号衰减等其他因素导致的信号幅值变化的影响,突出了B 线信号在微观上的重复规律性,这使得表1 中数据显示与非B 线区域相比,信息熵显示B 线区域信号混乱程度更高而排列熵却显示其更具有规律性。
表2 中单参数的贝叶斯分类器分类结果显示信息熵(灵敏度72.547%,特异性91.337%,准确率85.074%,AUC=0.91)和排列熵(灵敏度89.953%,特异性78.303%,准确率82.186%,AUC=0.90)的识别效果最好,峰度、偏度和能量3 个参数识别特异性较高,灵敏度较低且与信息熵和排列熵相比差距较大。表明排列熵与信息熵对于判断RF 信号是否为B线的能力较上述其他特征参数更高。贝叶斯分类灵敏度较低的3个特征参数(峰度、偏度、能量)其标准差较大,B 线与非B 线相应特征参数数值重合区间内识别对象数量较多,导致大多数B 线数据被分类为非B 线,从而使得分类模型表现出灵敏度非常低而特异性非常高的特点。
2.3 基于非线性SVM的双参数B线识别
由2.2 节可知,基于B 线和非B 线RF 数据提取的特征参数虽然有显著差异性,但其数值均有一定程度上的重合,而这样线性不可分的性质对贝叶斯分类器有较差的影响。为了获得更好的分类效果并且寻找上述参数中识别效果最好的双参数组合,选择单参数贝叶斯分类中识别效果前三的参数(信息熵、排列熵和峰度)组成3 组双特征参数组合,以及识别效果最差的两个参数(偏度和能量)组成一组双特征参数组合,将上述4 个特征参数组合输入非线性SVM 进行分类,本研究使用的SVM 基于MATLAB 中LibSVM 工具箱,采用高斯径向核函数。
不同参数组合如下:组合1 为排列熵加信息熵;组合2 为信息熵加偏度;组合3 为排列熵加偏度;组合4 为峰度加能量。对不同的参数组合采用十折交叉验证的方法测试其分类效果:将数据集随机平均分为10份,轮流将其中9 份作为训练集,剩余1 份作为测试集,进行10 次模型训练和B 线识别,计算不同参数组合的受试者工作特征AUC,平均灵敏度、平均特异性和平均准确率如表3所示。
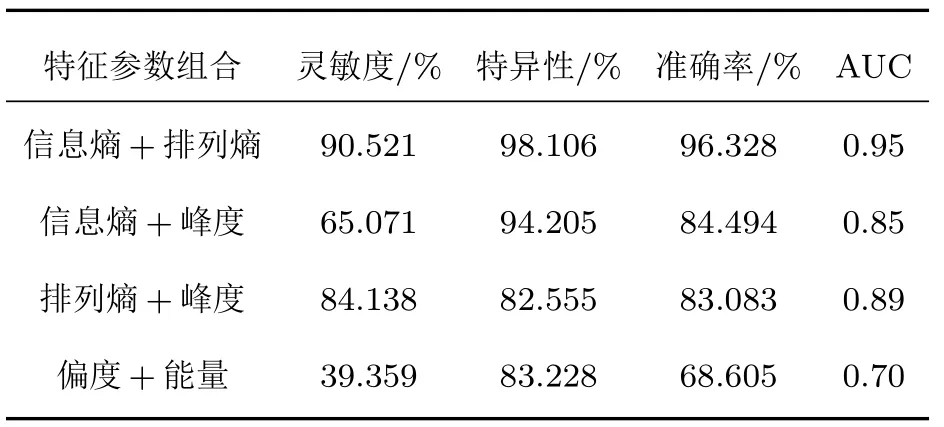
表3 不同输入组合十折交叉验证结果统计Table 3 Ten fold cross validation results for different input combinations
由表3 可知,4 个组合输入SVM 的识别效果最好的是信息熵加排列熵组合,将该组合作为输入的B 线识别平均灵敏度为90.521%,平均特异性为98.106%,平均准确率为96.328%,AUC等于0.95,均为4 种组合中的最高值,可以较好的实现对B 线的识别。识别效果最差的是偏度加能量组合,将该组合作为输入的B 线识别平均灵敏度为39.359%,平均特异性为83.228%,平均准确率为68.605%,AUC等于0.70。信息熵加峰度双特征参数组合对B 线的平均识别灵敏度(灵敏度=65.071%)较信息熵加排列熵(灵敏度=90.521%)以及排列熵加峰度(灵敏度=84.138)较低,但由于其平均特异性(特异性=94.205%)较排列熵加峰度组合高,故组合二、组合三的识别平均准确率相近,分别为84.494%和83.083%。
与表2中单参数贝叶斯分类器识别效果对比可知,特征参数两两组成双参数特征参数组合输入非线性SVM 得到的B 线识别效果要优于该组合中单参数识别效果较差的特征参数的识别效果。当组成双特征参数组合的两个特征参数的单参数识别效果均较好时,比如信息熵加排列熵组合,其双参数SVM 对B 线的识别效果显著优于其单独的识别效果。同时,当组成双特征参数组合的两个特征参数单参数识别效果均较差时,比如偏度加能量组合,其双参数SVM 的识别效果虽然依然较差,但较其各自单参数识别效果有显著的改善。
本文认为高斯核函数将特征空间新向量表示为原始空间映射函数的内积,构建新的高维线性可分特征空间,并建立一个线性超平面对样本进行分类,新的特征空间包含了特征参数各自对于分类的相关性,使参数组合具有了与其各自对分类的相关性相比更高的相关性,提高了分类准确率。
2.4 后处理
由于本文基于RF 数据提取的B 线区域与非B线区域的信息熵与排列熵是线性不可分的,采用了高斯核的非线性SVM 进行分类,模型中引入了惩罚因子,因此在更高维度的特征空间中进行分类时,分类模型对于边界间的样本是有一定容忍度的,即允许一定的错误分类的情况出现,这是因为对于惩罚因子过大时,识别模型对错分情况容忍度很低,会出现过拟合;惩罚因子过小时,可能导致无法达到分类效果,出现欠拟合现象。与之对应的,本文采用信息熵、排列熵双参数非线性SVM 识别后的结果显示,一张超声图像中识别错误的情况大致分为两类:一是将非B 线区域中的若干扫描线识别为B线;二是将B线区域中的若干扫描线识别为非B线。图2 展示了SVM识别效果图,其中识别为B线的扫描线用蓝色半进行了标注。

图2 SVM 识别图(识别为B 线的线束用蓝色在图中标注)Fig.2 SVM identification images (B-Line regions were marked in blue)
分析识别错误的识别对象,发现出现识别错误的线束大多为图像中位置分散的单独扫描线或少量连续扫描线,而B 线的宽度总是≥3 条扫描线的宽度,同一条B 线包含的扫描线在图像中的位置是连续的,并且B 线从胸膜线产生,一直延续到屏幕底端。根据以上性质,本文在SVM识别的基础上提出了一种后处理的算法,可以有效地提高B 线识别效果。
对于SVM 模型的识别结果,后处理算法首先遍历其识别为B 线的扫描线位置,找到被识别为B线,但与其他B线间隔>5 (每根扫描线的宽度为1)且宽度≤2 的扫描线区域,将其识别结果更正为非B线。再次遍历识别结果,找到所有间隔≤2的相邻B 线,判断其间隔中非B 线在屏幕底部位置是否依然具有较强的能量,若是,则认为此扫描线满足B线由胸膜线一直延伸到屏幕底端的性质,将其识别结果更正为B线,若否,则不做更改。
图3 展示了后处理算法提高B线识别效果的对比图。可以看出,后处理算法很好地找到B 线区域中和非B 线区域中识别错误的扫描线,并有效地更正了识别结果,得到了更加准确的B线位置与范围。表4 展示了将排列熵加信息熵输入SVM 后所有识别结果输入后处理算法得到的B 线识别平均灵敏度、特异性和准确率。可以看出,后处理算法对B线识别的灵敏度有显著提升,达到95.23%,准确率也有提高(准确率96.88%),特异性有较小下降(特异性97.22%),综合3项指标可知后处理算法可以显著有效地提升B 线识别能力,以较小的运算量改善SVM识别效果。
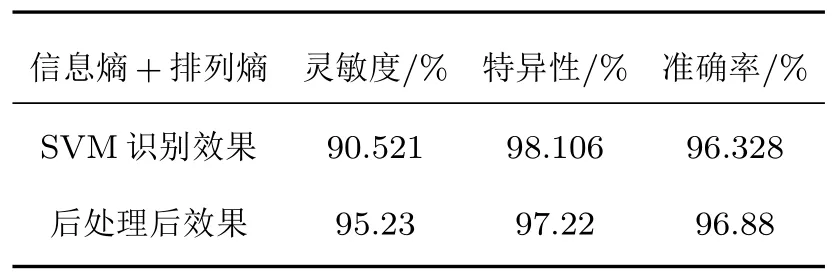
表4 后处理前后B 线识别效果对比Table 4 Comparison of B-Line recognition effect before and after post-processing
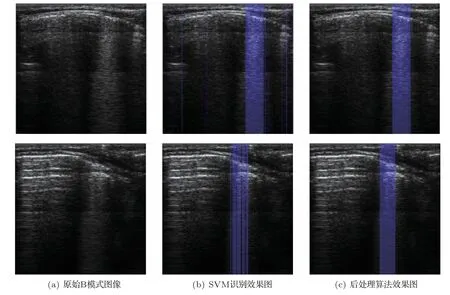
图3 原始B 超图像、SVM 识别B 线效果图和后处理效果图对比(图中蓝色标注的线束为识别为B 线的线束)Fig.3 Comparison of original B mode images,SVM recognition images and post-processing images
3 讨论
本研究基于超声RF 数据进行肺超声特殊征象B 线的识别,选取了RF 数据的5 种特征参数,包括信息熵、排列熵、包络峰度、偏度和RF 信号能量。为了确定对于B 线分类效果最好的特征参量以及最好的B 线识别效果,对各个参数进行了独立样本t 检验,采用单参数贝叶斯分类器与双参数非线性SVM,并选择了4 种不同的特征参数组合输入SVM,对100帧RF 数据进行了分类识别实验,进行了各特征参数的统计学分析,比较了各个参数单参数分类的效果、不同参数组合输入非线性SVM 的识别效果以及单参数与双参数的识别效果,最后在信息熵与排列熵双参数SVM 识别的基础上提出并采用了一种后处理算法,并对后处理算法的效果进行了比较分析。
结果显示B 线与非B 线的所有特征参数之间均具有显著差异,但不同特征参数对于B 线识别的相关性差别较大,根据单参数贝叶斯分类结果,标准差较小的排列熵和信息熵相关性较高,而标准差较大的峰度、偏度和信号能量相关度较低,说明对于两种类别RF 信号的特征参数,具有显著差异性且标准差较小的特征参数更有利于B线的识别。
与单参数贝叶斯分类相比,双参数SVM 分类的识别灵敏度、特异性、准确率以及AUC 均有显著的提高,且单参数分类效果好的特征参数作为双特征参数输入组合的一部分时,分类准确率也高于那些含有单参数分类效果较差的特征参数的参数组合,说明多参数输入分类器时会提供各自对于分类识别的能力,并且参数组合不仅仅包含单参数分类能力,还会由于参数间隐含的相关关系,使得参数组合与分类的相关度更高,进一步提高识别准确率。但本研究并未比较双参数组合与更高维度的特征参数组合输入SVM 时的分类效果,后期研究会采用更高维度的特征参数组合,探究更高维特征空间对于B线识别的能力。
4 种输入非线性SVM 的特征参数组合中,信息熵加排列熵的分类效果最好,平均灵敏度为90.521%,平均特异性为98.106%,平均准确率达到96.328%,AUC达到0.95,均大于其他3 种输入特征参数的组合。进一步采用后处理算法对信息熵加排列熵的分类结果进行处理,显著改善B线识别效果,平均灵敏度达到95.23%,平均特异性为97.22%,平均准确率为96.88%,实现了对B线的较准确识别。
本文提出的这种基于超声RF 数据SVM 双参数(信息熵和排列熵)B线识别方法相较于Cristiana等[8]提出的基于卷积神经网络的深度学习算法对计算机算力的要求更低,计算速度更快,有利于对B线的实时快速识别。Cristiana等[8]分析识别效果时计算的灵敏度、特异性等指标是以某超声图像是否存在B 线为标准,比较模型识别与专家判断结果是否一致为依据,若模型识别与专家判断某超声图像中存在B 线则认为识别正确,而本文是将超声图像的每条扫描线包含的所有RF 数据作为一个最小的识别对象,分析识别效果时计算的灵敏度、特异性与准确率是以每一条扫描线是否属于B 线为标准,比较模型识别与专家判断结果是否一致,识别结果不仅包含被识别的图像中是否存在B 线的信息,并且指明了B 线的具体位置与范围,可以为定量研究B线与肺病变严重程度的关系提供重要依据。
本研究选用的超声RF 数据来自油酸致肺损伤动物模型实验,实验中出现B 线的具体病理可能并不统一,具有一定的局限性。在后续研究中会与相关医院超声科合作,获得可供研究的具体病例的RF 数据,将B 线识别与产生B 线的具体病理特征结合起来,以提高B线识别的可靠性与特异性。
4 结论
本文提出了一种基于超声RF 信号的肺脏超声特殊征象B 线的识别方法,提取肺超声RF 数据的信息熵、排列熵、峰度、偏度和能量作为特征参数,利用单参数贝叶斯分类器以及非线性SVM,获得并比较了不同参数以及不同参数组合对于B 线识别的效果,并将识别效果最好的信息熵加排列熵参数组合的识别结果输入后处理算法,最终得到B 线识别平均灵敏度为95.23%,平均特异性为97.22%,平均准确率为96.88%,能够以较高的灵敏度、特异性和准确率实现对肺超声B 线的识别。与基于图像的B线识别方法相比,本文提出的基于RF 数据的B 线识别方法受到超声仪器参数调整的影响更小,可以适用于多种不同超声仪器,普适性较强,应用场景较广。同时,基于RF数据提取的特征参量包含更多组织结构信息,对B线的识别更加可靠有效,可以为临床经验有限的医生提供准确的辅助诊断信息,减缓肺超声诊断的学习曲线,提高诊断准确率。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
贵州大学学报(自然科学版)(2021年4期)2021-09-12
昆明医科大学学报(2021年4期)2021-07-23
国际放射医学核医学杂志(2020年4期)2020-07-27
雷达学报(2018年3期)2018-07-18
科技创新与应用(2018年36期)2018-01-29
电子测试(2017年12期)2017-12-18
雷达学报(2017年6期)2017-03-26
数字技术与应用(2016年6期)2016-07-09
罕少疾病杂志(2016年5期)2016-03-11
