
基于时延神经网络模型的舰船辐射噪声目标识别*
2023-09-20 06:50赵乾坤刘峰梁秀兵宋永强
应用声学 2023年5期
赵乾坤 刘峰 梁秀兵 汪 涛 宋永强
(军事科学院国防科技创新研究院 北京 100071)
0 引言
水声目标识别技术对维护海洋权益、海洋资源开发具有十分重要的作用,在反潜、鱼雷防御、海底地形勘探等领域应用广泛[1]。前期研究表明,水声信道受海洋环境的影响会产生多径、衰减、畸变等复杂变化,多种类别的水声信号耦合在一起,使得舰船信号往往淹没在背景噪声之中。同时,舰船辐射噪声具有较大的类内差异性和类间相似性,使得同类型目标在不同的航行状态和环境下,具有不同的噪声辐射特性。除此之外,水声目标类别十分广泛,如渔船、货轮、军舰等水面目标;潜艇、海洋生物、钻井平台等水下目标,这些问题都增加了水声信号的识别难度。因此,水声信号目标识别一直是国内外水声领域公认的难题。
传统的水声信号特征提取方法经过多年的发展,已经从简单的时域或频域特征发展到时-频结合、人耳听觉感知、高阶统计量等特征分析方法。其中,时频分析方法提供了时间域与频率域的联合分布信息,可以清楚地描述信号频率随时间变化的关系,是目前最为常用的特征提取方法,如短时傅里叶变换(Short time Fourier transform,STFT)[2]、梅尔频率倒谱系数(Mel-Frequency cepstral coefficients,MFCC)[3]、希尔伯特-黄变换(Hilbert-Huang transform,HHT)等。分类器设计方面,常用的方法包括隐马尔科夫模型(Hidden Markov model,HMM)、高斯混合模型(Gaussian mixed model,GMM)、支持向量机(Support vector machine,SVM)以及级联分类器等都在水声信号识别中得到了应用。然而,传统方法的参数有限无法对大规模数据和海洋环境进行建模,系统部署后难以进行数据的迭代更新,这些问题都使得水声信号依然长期依赖人工判读。
近年来,深度学习技术的快速发展,以其对非线性系统的良好拟合能力,为水声目标识别领域提供了新思路。基于深度学习的水声目标识别算法可以利用神经网络自动地学习特征并完成分类。越来越多的研究人员开始采用深度学习进行声目标识别研究,并借助深度神经网络实现特征优化和目标识别[4-5],可有效提高自动识别系统的泛化能力和环境适应性。Kamal等[6]首先将深度置信网络(Deep belief network,DBN)模型应用于水声信号被动目标识别任务中,在40 个类别的目标共1000 个测试样本的测试集上取得了90.23%的分类正确率,结果表明利用深度学习模型进行水下目标识是一种可行的途径。王强等[7]从3 类目标的实测水声数据库中提取梅尔倒谱特征及傅里叶变换特征,比较了DBN、卷积神经网络(Convolutional neural networks,CNN)、SVM的识别率,其中DBN的识别率最高。Yue等[8]使用CNN和DBN对16种不同类型的水声目标进行了分类,在有监督和无监督的情况下,其准确率分别达到94.75%和96.96%,其结果优于对比实验中SVM 和Wndchrm(用于生物图像分析的开源程序)的识别精度。考虑到水声目标信号的时序性质,也有学者应用时序模型开展智能识别研究。张少康等[9]应用长短时记忆(Long short-term memory,LSTM)网络分别对水下目标噪声的时域时间序列数据、频谱数据、梅尔倒谱数据进行深层次特征提取与识别,并使用实际水声目标噪声信号对该方法进行了验证。结果表明,在上述3 种输入数据情况下,采用LSTM 模型均能有效实现水下目标噪声特征提取与智能识别。Li等[10]提出了一种基于时延神经网络(Time delay neural network,TDNN)的分类器,用滤波器组(Filter bank,Fbank)提取包含频谱信息的特征作为网络的输入,实验结果表明,该方法比SVM 等传统方法具有更高的分类精度,且在真实环境下的三重分类实验中准确率达到90%以上,说明该分类器在建模时间序列和表示复杂非线性关系方面具有很大的优势。随着注意力机制(Attention) 在自然语言处理领域的成功应用,许多学者将注意力机制运用到水下目标识别领域,也取得了不错的识别效果。Li等[11]提出了一种基于注意机制和迁移学习的船舶辐射噪声识别方法,在公共数据集上实现了99%的识别准确率;徐承等[12]将多维自注意力机制引入多特征融合水下目标识别框架,分别在特征维度和时间维度高效完成深层次目标弱信息特征抽取,显著提升了识别效果。
经以上研究启发,本文尝试基于注意力机制和TDNN 构建深度网络架构,进行有效地舰船辐射噪声数据深层特征挖掘和分类识别。结果表明,本文验证的网络架构方法有效。
1 方法介绍
1.1 Fbank初级特征提取
人耳在不同频率下的感知是多样化和非线性的,基于人耳听觉特征的MFCC和Fbank被广泛应用,它们都使用梅尔滤波器组,不同之处在于Fbank特征没有进行离散余弦变换,离散余弦变换去除了各维信号之间的相关性,这也使得没有进行此步骤的Fbank 特征更具有声音的本质信息,且比MFCC计算量更小[13]。Fbank 特征不仅可以改善声信号的线性感知能力,能更好地表征声频的在低频部分的频域特征,提高声纹识别的性能,而且在声纹识别实验中发现Fbank 特征比MFCC 特征表现更好。由于水声目标识别与声纹识别的任务相似性,所以本文采用Fbank特征输入后续网络,如图1所示,它的一般步骤是:预加重、分帧、加窗、STFT、梅尔滤波等。
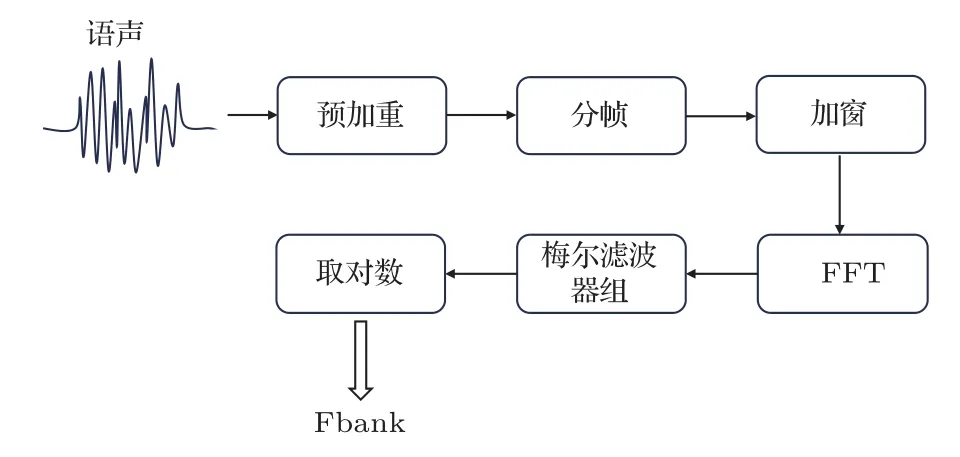
图1 Fbank 特征提取流程Fig.1 Fbank feature extraction process
预加重:主要是对高频部分进行补偿,将舰船辐射噪声信号输入传递函数的高通滤波器进行处理,能够提升高频的能量,帮助提升识别的效果。对于n时刻信号的采样值x[n],经过预加重处理后得到的输出:
其中,a为预加重系数,取值一般在0.9~1之间。
分帧:舰船辐射噪声信号具有短时平稳性,为了能在短时“小段”上进行傅里叶变换,将信号按照给定长度切割成一个个小段,称之为分帧。为了避免分帧后的相邻帧变化过大,一般会保留一些两帧间的重叠区域。
加窗:是在信号分帧后对每一帧乘上一个不断移动的有限长窗函数的过程。窗外的值设定为0,其目的是消除各个帧两端可能会造成的信号不连续性,避免出现吉布斯效应。本文使用汉明窗:
其中,N为窗口长度。
快速傅里叶变换(FFT):为了将信号从时域转换到频域,得到频谱上的能量分布,便于观察不同的信号特性。在乘上汉明窗后,每帧要经过FFT 以得到各帧的频谱。假设采样点是N,则计算如下:
梅尔滤波器组:将功率谱通过一组梅尔刻度的三角滤波器来提取频带,滤波器组中的每个滤波器都是三角形的,中心频率为f(m),中心频率处的响应为1,并向0 线性减小,直到达到两个相邻滤波器的中心频率,其中响应为0,各f(m)之间的间隔随着m值的增大而增宽。经过FFT 的信号分别与每个滤波器进行频率相乘累加,得到的值即为该帧数据在该滤波器对应频段的能量值。单独滤波器的表达式为
最后,计算每个滤波器组输出的对数能量为
得到梅尔频谱图如图2所示。

图2 梅尔频谱图Fig.2 Mel spectrum
1.2 基于TDNN模型的高级特征提取
水声信号是一种典型的时序信号,存在着时间关联特性。本实验利用改进的TDNN 沿时间轴采用一维卷积结构作为特征提取器[14],将水声信号有区别地嵌入到一个向量空间中,利用水声信号的短时平稳特性提取帧级特征,然后将声频的帧级特征的均值和标准差连接起来作为长时特征,最后通过前馈网络实现目标类别的划分。深度特征提取网络依次由1 个TDNN 模块(卷积核长度为5)、3个带有压缩激励和分层类残差连接的残差块(SERes2Block)、1 个TDNN 模块(卷积核长度为1)和1个注意力统计池化模块(Attentive statistics pooling,ASP)组成。其中TDNN 模块均包含ReLU 激活层和一个批处理规范化层(Batch normalization,BN)。而且,由于神经网络可以学习分层特征,这些更深层次的特征是最复杂的,应该与舰船类别密切相关,更浅的特征图也有助于提取更鲁棒的舰船声纹嵌入码。因此,采用的网络模型连接所有SERes2Block 的输出特征,多层特征聚合(Multi-layer feature aggregation,MFA)之后,用一个全连接层(Fully connected layer,FC)处理连接的信息,输入到ASP后,生成得到帧维度的均值向量和标准差向量[15],再经过一个FC 生成192 维度的特征,然后用AAM-Softmax 方式进行分类识别。具体网络结构如表1 所示,其中T为时间帧数,k表示卷积核长度,d表示空洞卷积维度。

表1 深层特征提取网络结构Table 1 Deep feature extraction network structure
其中,SE-Res2Block 模块作为特征建模模块,如图3 所示,由两个相同的带有ReLU 激活层和BN 层的TDNN 模块、1 个带有ReLU 激活层和BN层的分层类残差连接的残差块(Res2Block)、1 个压缩激励模块(Squeeze-and-excitation block,SEBlock)和1 个从输入到输出的直接连接构成。一维Res2Net 模块将输入通道平均分成8 个部分,如图4所示,第一个特征图保留,不进行变换,这是对前一层特征的复用,同时也降低了参数量和计算量。从第二个特征图开始,都经过一个3×512 的一维卷积,并且当前特征图的卷积结果,会与后一个特征图进行残差连接(逐元素相加)。然后,后一个特征图再进行3×512的一维卷积。最后,将所有输出通道部分合并为Res2Block 输出。这样使得层内融合了不同尺度的特征,可获得更强的表征。整体网络模型1~3层Res2Block的空洞卷积膨胀率d分别为2、3、4。

图3 SE-Res2Block 结构示意图Fig.3 SE-Res2Block structure diagram

图4 Res2Conv1DReLUBN 结构Fig.4 Res2Conv1DReLUBN structure
在SE-Res2Block 的最后使用了SE-Block,它是现代卷积神经网络所必备的结构,引入通道注意力机制,对通道间的依赖关系进行了建模,可增强有用的通道和抑制无用的通道,能够有效地提升性能,而且计算量并不大。基本思路如图5 所示,是将一个T ×1×512 的特征图的每个特征通道都映射成一个值(常用全局平均池化,即:取该特征通道的均值,代表该通道),从而特征图会映射为一个向量,长度与特征通道数一致。之后,向量通过FC (与用1 维卷积等价)进行降维,输出长度为特征通道数的1/4(即128)。然后经过激活函数ReLU。再通过一个FC,输出长度与特征通道数一致(即512)。接着经过激活函数Sigmoid,此时输出向量的每一个值,范围都是0~1 之间。最后用输出向量的每一个值,对输入特征图的对应通道进行加权相乘。

图5 SE-Block 结构Fig.5 SE-Block structure
ASP 是带有注意力机制的统计池化层,因其在说话人嵌入方面的优异性能而被安置在深度特征提取的最后[16]。具体结构如图6 所示,对输入的1536×T的特征图,按照T维度计算每个特征维度的均值和标准差,将均值和标准差分别在T维度重复堆叠T次,再将原输入特征图、均值和标准差在特征维度进行串联,得到的特征图维度为4608×T。然后进行一维卷积将4608×T特征图降维,经过tanh激活函数得到维度为128×T的特征图,再对其进行一维卷积将其升维到1536×T,进行Softmax 激活,在T维度上对帧权重进行了标准化处理,避免了不同批次之间的巨大差异,而且,此时特征图每一行特征在T维度上求和都等于1,可以将其视为一种注意力分数,求出基于注意力的均值和标准差,再将它们按照特征维度进行串联,得到ASP最终的输出。

图6 ASP 结构Fig.6 ASP structure
1.3 分类器设计及模型优化
本文采用基于AAM-Softmax[17]的分类。原始的Softmax没有考虑优化去使得类内具有高度相似性而类间具有显著差异性。但是舰船辐射噪声通常面临海洋环境干扰、行驶状态改变等引起的类内差异大类间差异小的问题。而采用AAM-Softmax(如公式(6))进行分类时,在cosθ内加入了角度余量损失(angular margin)m,增强类内紧凑性和类间差异性,从而提高的判别能力,以及提升了训练的稳定度。
这里使用Adam 来对网络模型进行优化,算法计算梯度平方的指数加权平均以及gt的指数加权平均:
其中,β1和β2分别为两个移动平均的衰减率,通常取值为β1=0.9,β2=0.99。
Adam算法的参数更新差值:
2 实验
2.1 实验数据
本文采用两组实验数据作为验证,分别为开源数据集ShipsEar和课题组自行采集的实验数据。
其中,第一组数据为ShipsEar 数据集,该数据集共包含90 段声频记录,分为5 个类别,数据是利用自容式水听器对码头上往来的船只噪声信号进行记录,以采集不同船速下的噪声以及与进坞或离坞时的空化噪声。由于数据是在真实开放水域中采集的,部分信号中混杂了人说话声、自然背景噪声,偶尔也会记录到海洋哺乳动物的声音。经初步处理后,消除了背景噪声干扰强烈和模糊不清的信号。对数据进行预处理,去除空白信号,并将原始信号按照5 s 时长进行分帧和标注,共生成1956 个标注样本。详细信息如表2 所示,第一列是声信号目标类别,第二列是每类对应的细分船只,第三列是每类目标的帧数。

表2 第一组实验数据Table 2 First set of experimental data
第二组数据为课题组自行采集的数据(如图7所示),该数据采集利用4 组自容式水听器对航道上过往的船只进行记录,并利用船舶自动识别系统(Automatic identification system,AIS)对来往的船只进行标注,包括目标类别、距离、航向、航速等信息。采集过程中变换了多个采集地点,实验共持续4天,每天平均采集时间7 h,采集区域水深10~18 m,经过听声和记录比对,滤除记录缺失数据、空声数据、干扰数据等,共计43种目标(包括捕捞船、货船、拖船、客船、集装箱船、快艇等),144组wav文件。为了更加贴近真实场景下的应用效果,将144 段目标数据划分为4个类别,分别为客轮(Passenger)、货船(Cargo ship)、小渔船(Yacht)和其他(Others),并将采集的整段数据随机选取放入训练集或者测试集,再按照5 s的固定时长对数据进行截取,这样可以保证数据的独立性。若采取先截取再随机采样的方式划分数据,由于同一目标或相邻时间内的信号数据变化不大,会使得训练集和测试集中的数据具有较强的相似性。经划分后共获得8530 组数据,其中训练集5971组,测试集2529组。

图7 第二组实验数据Fig.7 Second set of data
2.2 参数设置
模型是由Pytorch和Librosa编制的。网络模型在5 s 长的片段上训练了500 个历时。初始学习率被设定为0.001。如果验证集的准确度在连续5个历时中没有提高,则学习率呈指数衰减,如公式(10)所示:
采用Adam 优化器。随着网络中层数的增加,分布会逐渐发生变化。缓慢收敛意味着整体分布接近非线性函数取值区间的上界和下界,导致梯度在反向传播过程中消失。所以引入归一化、L2 正则化和激活函数,使输入值落入更敏感的区域。它可以使梯度变大,学习收敛变快,加快收敛速度。相关参数设置如表3所示。
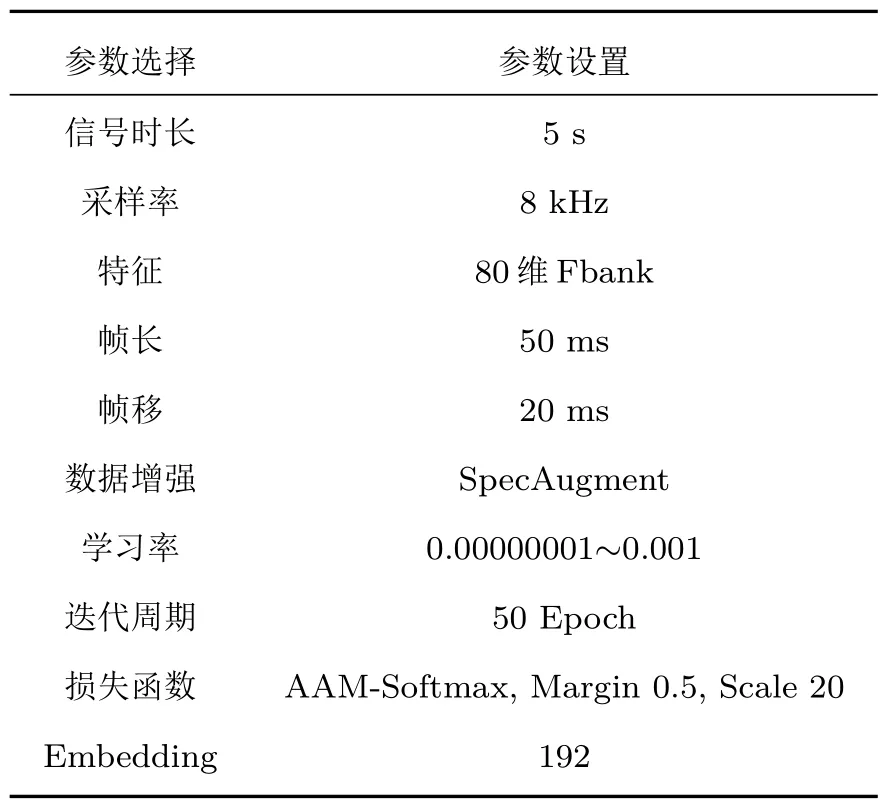
表3 网络训练相关参数设置Table 3 Network training related parameter settings
2.3 实验结果对比及分析
选择循环神经网络(Recurrent neural network,RNN)模型和深度神经网络(Deep neural networks,DNN)模型作为对照实验,来验证本文实验模型的有效性。表4 中比较了基于ShipsEar 数据集各种模型的水下声学信号识别的准确率。根据实验结果,本文采用的基于注意力机制改进的TDNN 模型(Fbank-attention-TDNN)的错误率最低,其准确率表明有79.2%的机会正确识别水下声学信号的类型。由于全连接神经网络(Fully connected neural network,FCNN)模型的FC 的参数最多,模型在训练过程中更容易过拟合,因此会提高了模型的错误率,使模型在测试过程中准确率最低。虽然传统的RNN模型和DNN模型利用连接的模型也同样稳定地收敛了,但效果不及本文实验的模型。原因是TDNN 结合了信号的长时关联性,更好地利用了梅尔谱图前帧和后帧的时间相关性以及频率的结构信息,同时,本文实验的模型也使用了残差连接多尺度特征聚合,可以接受全局信息的特点使得模型在训练过程中学习每个网络层的信息,会令模型的错误率逐渐下降,当注意力机制被引入模型时,模型的效果更加稳健。在不牺牲特征信息的情况下,本文采用的模型相较于传统结果可能会大幅减少参数,使其能够产生最好的结果。

表4 实验结果(基于ShipsEar 数据集)Table 4 Experimental results(Based on ShipsEar dataset)
采用上述相同的方法对本文构建的数据集进行验证。从图8和图9 中可以看出,训练集中的数据随着迭代次数的增加识别率逐渐提高,但测试集中的数据在收敛到70%附近时振荡较为明显,且无法再提高识别率,模型训练存在一定的过拟合现象。分析其原因,一是在数据划分的时候,训练集和测试集中的数据偏差较大,难以实现较好的拟合;二是每个类别中包含了多种不同型号的船只,这些目标的类内一致性和类间可分性问题还值得进一步研究,如其他类别中包含了海监船、拖船等多种型号的船只;三是由于采集环境受限,本文的数据采集位于近岸,噪声干扰较大,难以稳定采集到观测目标的声纹信号,这些都会对分类问题造成干扰。本次实验所测数据更接近真实环境下的需求,可在一定程度上对本文所提方法进行验证。
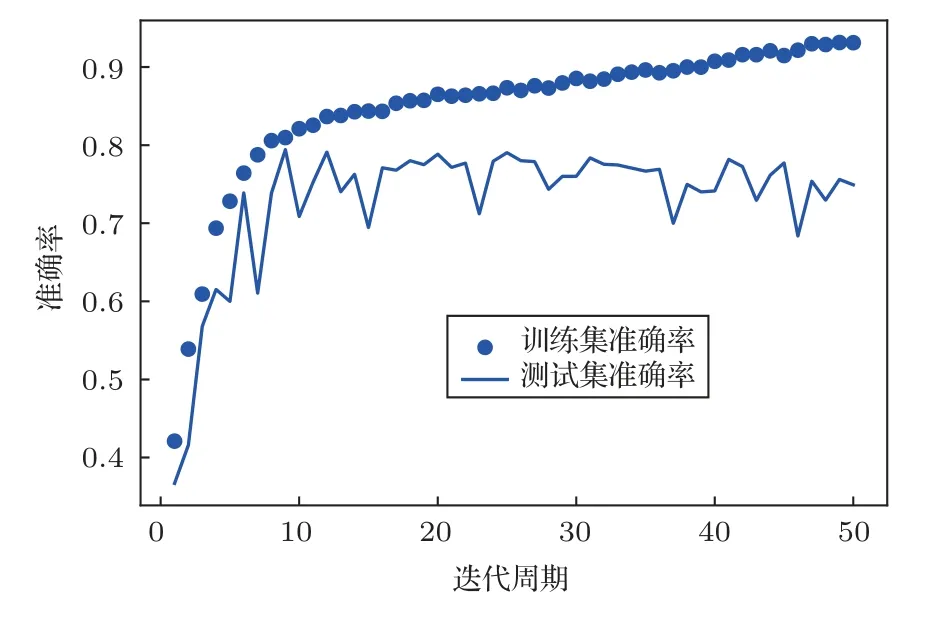
图8 训练和测试准确率对照曲线Fig.8 Comparison curve of training and test accuracy

图9 训练和测试损失对照曲线Fig.9 Comparison curve of training and test loss
图10 为本文方法在测试集识别结果的混淆矩阵,可用来呈现算法性能的可视化效果,每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目[18]。如第二行的Passenger,共有测试样本514 个,正确分类结果为426个,误分类为Others、Cargo boat和Little boat 的个数分别为60 个、9 个和19 个,通过混淆矩阵能够很快地分析每个类别的误分类情况。
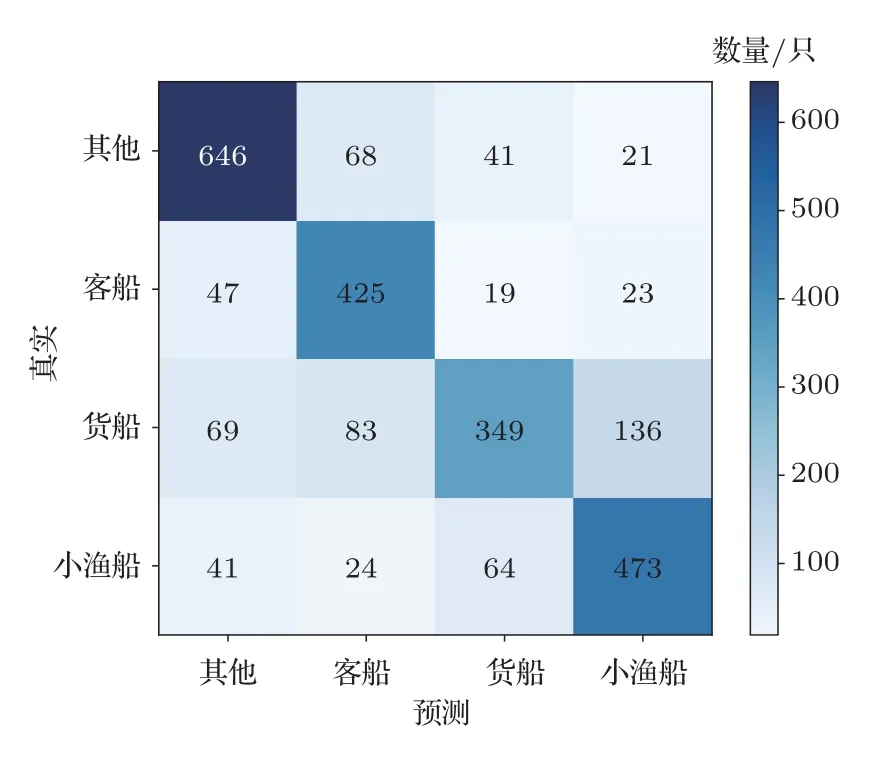
图10 分类混淆矩阵Fig.10 Confusion matrices for of targets
3 结论
本文以典型的船舶类水下辐射噪声信号为研究对象,以水声信号的分类识别为目的,研究了采用一种基于注意力机制的TDNN 网络模型在水声信号分类识别的应用能力。分别对ShipsEar开源数据集和课题组自行采集的实验数据进行了实验,提取信号梅尔频谱作为输入特征,识别准确率分别达到79.2%和73.9%,验证了实验模型在水声目标识别问题上的有效性。下一步将验证多特征融合输入是否会提高模型得识别准确率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学年刊A辑(中文版)(2020年3期)2020-10-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
电子制作(2017年22期)2017-02-02
电子制作(2017年19期)2017-02-02
系统工程与电子技术(2016年7期)2016-08-21
噪声与振动控制(2015年4期)2015-01-01
声学技术(2014年1期)2014-06-21
