
注意力机制融合前端网络中间层的语声情感识别
2023-09-20 06:50朱应俊周文君马建敏
应用声学 2023年5期
朱应俊 周文君 朱 川 马建敏
(复旦大学航空航天系 上海 200433)
0 引言
语声情感识别(Speech emotion recognition,SER)已在娱乐产品的情感交互、远程教育的情感反馈、智能座舱的情绪监测中得到广泛应用。在应用中,通过建立语声信号的声学特征与情感的映射关系,对语声的情感进行分类。基于单一特征的SER 模型因受到特征信息量不足的制约而影响识别准确率。随着对语声情感特征研究的逐步深入,通过对多种语声特征进行融合以消除特征中的冗余信息并提升识别准确率的方法受到越来越多的关注,已形成了特征级、中间层级、决策级等融合方式。
对语声情感特征进行特征级的融合可以在增加信息量并提高识别准确率的同时有效减小特征维度。Liu等[1]使用基于相关性分析和Fisher 准则的特征选择方法,去除来自同一声源且具有较高相关性的冗余特征。Cao等[2]也提出了基于Spearman 相关性分析和随机森林特征选择的方法提取相关性最弱的特征以进行融合。基于网络中间层进行的融合则利用神经网络将原始特征转化为高维特征表达,以获取不同模态数据在高维空间的融合表示。Cao等[3]在话语级别的情感识别中使用门控记忆单元(Gated memory unit,GMU)来获取语声信号的静态与动态特征融合后的情感中间表示。Zhang等[4]提出了基于块的时间池化策略用于融合多个预训练的卷积神经网络(Convolutional neural network,CNN)模型学习到的片段级情感特征,得到固定长度的话语级情感特征。语声特征的融合还可基于多个模型在其输出阶段进行决策级融合以集成其情感分类结果[5]。Noh等[6]使用基于验证准确度的指数加权平均法则组成了分级投票决策器对多个CNN 模型的决策结果进行融合。Yao等[7]使用基于置信度的决策级融合整合了在多任务学习中获得的循环神经网络(Recurrent neural network,RNN)、CNN 和深度神经网络(Deep neural network,DNN)。
注意力机制可用于自动计算输入数据对输出数据的贡献大小,近年来也在语声识别相关领域得到了较多运用。Bahdanau等[8]将注意力机制应用于RNN 和n-gram 语言模型,建立了端到端的序列模型。Mirsamadi等[9]将基于局部注意力机制的加权时间池化策略用于RNN 模型,以学习与情感相关的短时帧级特征。Kwon[10]使用特殊的扩张CNN 从输入的过渡语声情感特征中提取空间信息并生成空间注意力图以对特征进行加权。
在已有对语声特征融合及注意力机制在SER任务中应用研究的基础上,通过对语声信号进行预加重和分帧加窗等处理,得到基于谱特征和时序特征的前端网络,利用压缩-激励(Squeeze-andexcitation,SE)通道注意力机制对前端网络中间层进行融合,有效利用不同前端网络在SER 任务中的优势提高情感识别准确率。通过在汉语情感数据集中的对比实验,对前端网络选择的合理性和SE 通道注意力机制用于对前端网络中间层进行融合的有效性进行验证。
1 SER模型
本文判断语声信号情感类别的SER 模型如图1所示,该模型由3个模块组成:前端网络模块、注意力机制融合模块和后端网络分类模块。前端网络模块对输入的语声信号进行预加重和分帧加窗等处理后,提取梅尔倒谱系数(Mel-frequency cepstral coefficients,MFCC)和逆梅尔倒谱系数(Inverted MFCC,IMFCC)作为谱特征,把谱特征输入到二维卷积神经网络(Two dimensional CNN,2D-CNN)得到MFCC 2D-CNN 和IMFCC 2D-CNN;提取散射卷积网络系数(Scattering convolution network coefficients,SCNC)作为时序特征,把时序特征输入到长短期记忆网络(Long-short term memory,LSTM)中得到SCNC LSTM。注意力机制融合模块引入SE 通道注意力机制,将MFCC 2D-CNN、IMFCC 2D-CNN 和SCNC LSTM 前端网络中提取的中间层进行加权融合得到融合深度特征(Fusion deep feature,FDF)。后端分类模块基于DNN构建分类器,依据输入的FDF映射输出情感分类结果。
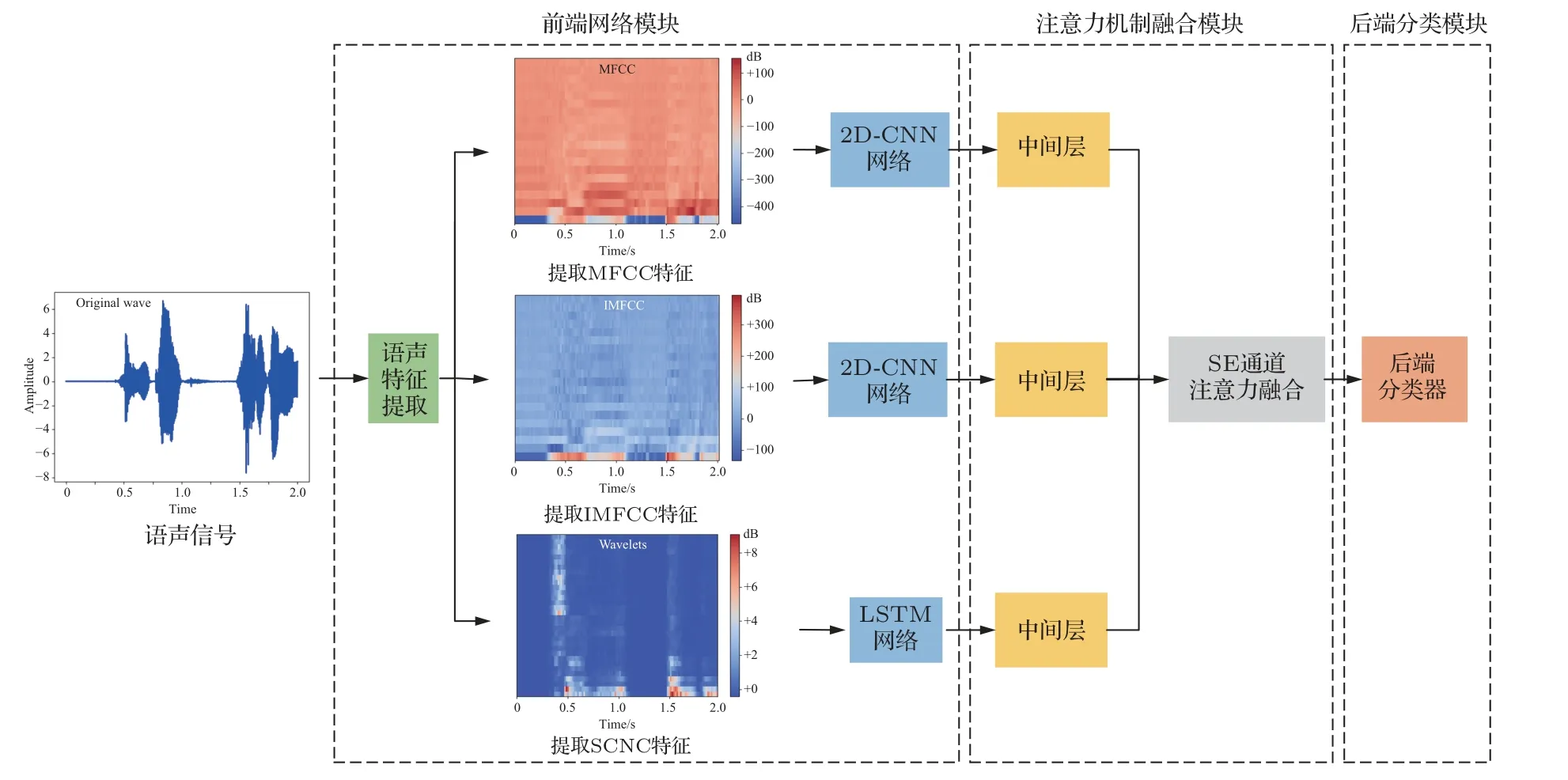
图1 SER 模型结构Fig.1 Structure of SER model
1.1 基 于MFCC 和IMFCC 特 征 的2D-CNN前端网络
MFCC 和IMFCC谱特征中不同频谱区间的频谱能量分布体现着不同情感状态下的声道形状和发声状态[11],其中计算MFCC 特征时使用的Mel三角滤波器模拟了人耳听觉的非线性机制,更加关注于语声信号的低频部分而对中高频的变化不够敏感[12];IMFCC特征则通过IMel 滤波器在高频区域分布更加密集来获取更多高频信息[13]。Hz 频率与Mel 频率及IMel 频率之间的定量关系可分别表示为[14]
其中,f表示Hz 频率,fMel和fIMel分别为Mel 频率及IMel频率。
将语声信号的功率谱通过Mel 及IMel 三角滤波器,并将对数能量带入离散余弦变换(Discrete cosine transform,DCT)以消除相关性,可计算得到语声信号的MFCC 系数及IMFCC 系数。还引入其一阶二阶差分项作为动态特征以体现语声情感的时域连续性[15]。特征差分项dt的实现如下:
其中,ct表示MFCC或IMFCC倒谱系数,st表示一阶导数的时间差。将一阶差分结果重复带入即可得到二阶差分,最终可计算得到带有差分项的MFCC及IMFCC特征。
为了利用CNN 在提取特征矩阵的局部空间相关性信息方面的优势[16],本文搭建了改进Alexnet的2D-CNN,网络结构简图如图2 所示,网络卷积部分的结构参数如表1 所示。卷积层使用了ReLU 激活函数,并进行了L2 正则化,正则化参数为0.02。在完成卷积运算后,使用扁平化层(Flatten)对卷积特征进行降维,输入到节点数分别为2048 和512的两层全连接层对特征进行整合,并由6 个节点的Softmax 分类层得到情感分类结果。将MFCC和IMFCC特征分别输入2D-CNN 训练得到MFCC 2D-CNN前端网络和IMFCC 2D-CNN前端网络。
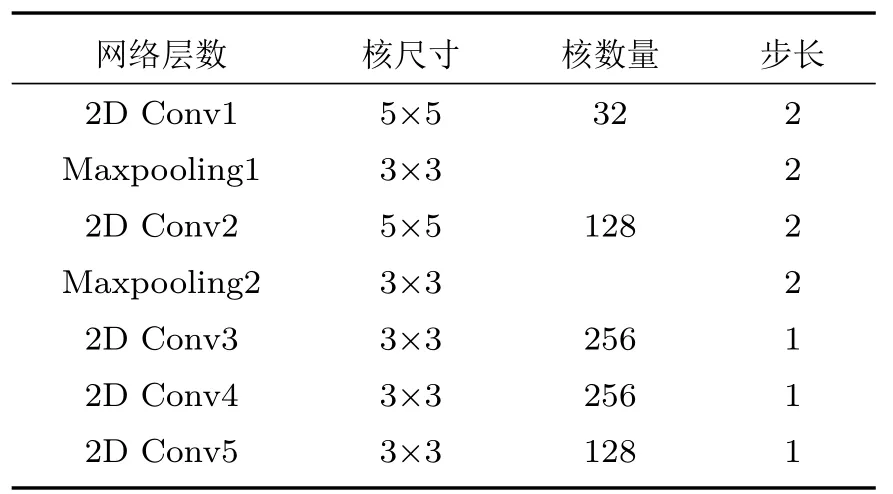
表1 2D-CNN 前端网络卷积层参数Table 1 Parameters of convolutional layers in 2D-CNN front-end network
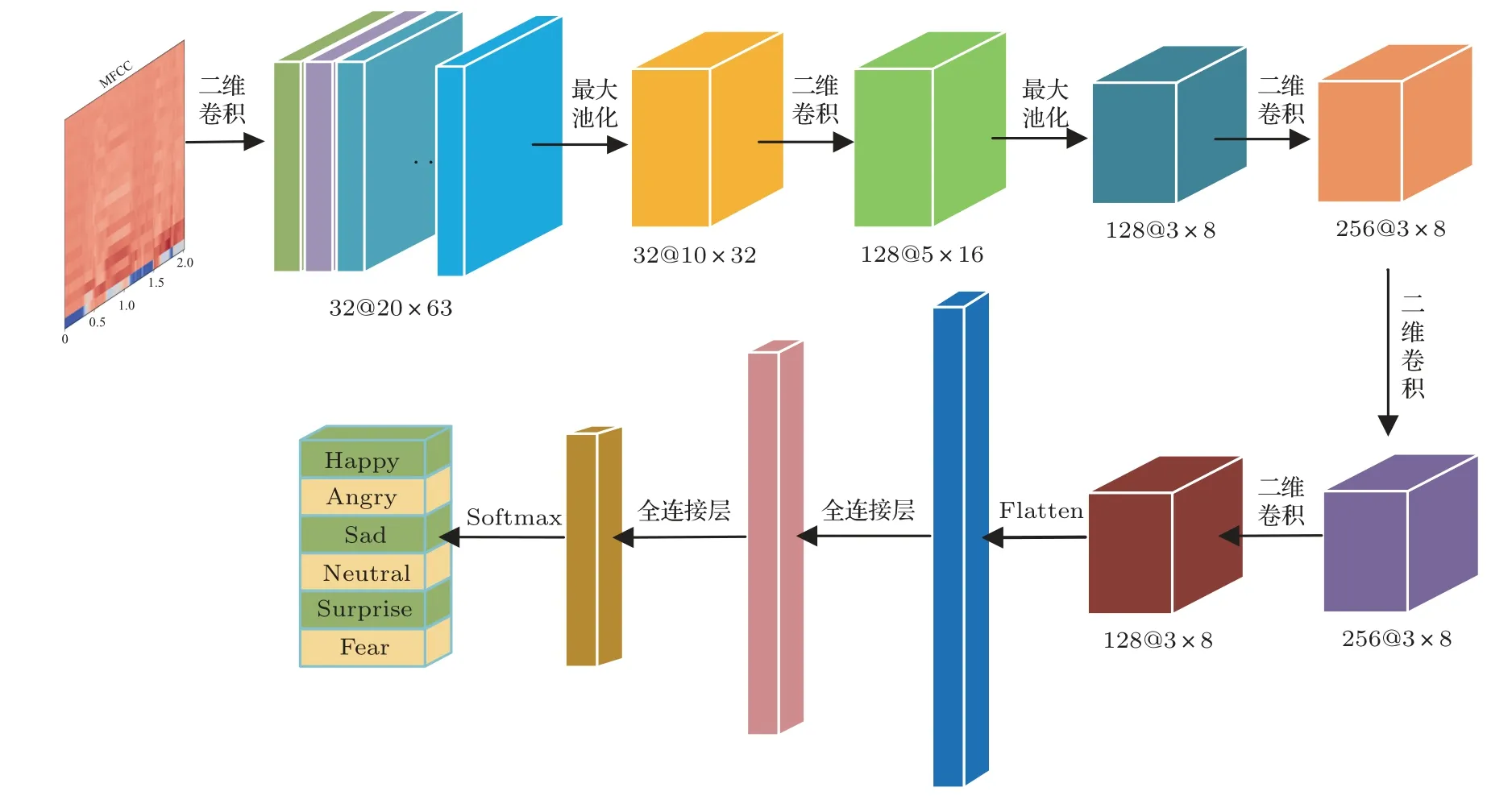
图2 基于MFCC 与IMFCC 的2D-CNN 前端网络结构Fig.2 2D-CNN front-end network structure based on MFCC and IMFCC
在反向传播过程中,为了应对由样本量过少及训练数据分布不均衡导致的网络性能下降的问题,本文引入了Focal loss损失函数[17],通过给难分类样本(Hard example)较大的权重,给易分类样本(Easy example)较小的权重,来放大难分类样本的损失并抑制易分类样本的损失,从而使网络聚焦于难分类样本的学习,提高分类准确率。Focal loss 损失函数Lfl的计算如下:
其中,pt表示分类器预测的概率值,γ为权重放大因子,αt是类别权重。为了增大2D-CNN 前端网络对难分类样本的权重,将γ取为4,因为数据集中各类情感样本数目相同,将αt设置为1。
1.2 基于SCNC特征的LSTM前端网络
本文引入了由不变散射卷积网络(Invariant scattering convolution network,ISCN)自动提取的SCNC 特征[18]作为时序特征。将语声帧视作短时平稳信号,输入由多层小波散射变换与取模算子级联得到的ISCN 中,提取其散射系数作为SCNC 特征,该特征能够最小化信号的平移和形变的影响,具有较强的变形稳定性,且保留用于分类的高频信息,故在网络中间层对特征进行融合时能够维持分类鲁棒性[19]。
对语声信号进行的小波变换可表示为{x ⊗ψλ}λ,其中指数λ=2-jr给出了带通滤波器ψλ的频率位置,⊗表示卷积运算,对于语声信号仅计算λ在r ∈[0,π)范围内所对应的路径。沿路径p=(λ1,λ2,···,λm) 迭代进行小波变换和取模运算可求得小波变换系数:
其中,对于每条路径p,S[p]x(u)是窗口位置u的函数,将式(5)代入其中即可得到计算m阶加窗散射系数的公式如下:
为了提高特征的高频分辨率,将分帧加窗后的语声片段输入由5 层小波变换和取模算子级联得到的ISCN 中,以提取网络的加窗散射系数作为SCNC特征。
LSTM 相较于CNN 可以更好地处理时间序列的任务,同时LSTM 解决了RNN 的长时依赖问题[20],并避免了反向传播过程中的梯度消失[21]。本文搭建了基于SCNC 特征的LSTM 前端网络,网络由LSTM 层和3 层全连接层组成,为对应每帧语声提取到的32维的SCNC特征,LSTM层设置了32个节点,每个节点通过126 个时间步进行更新[22]。单个节点的结构如图3所示。
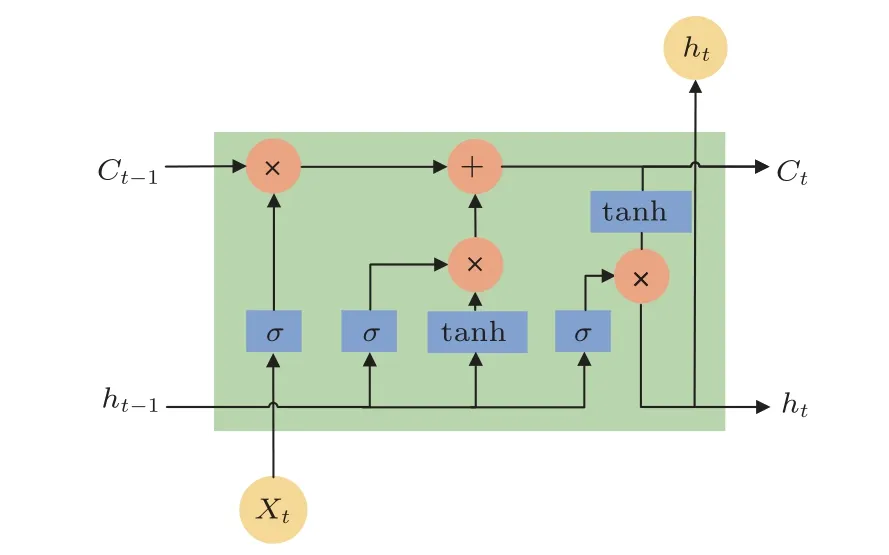
图3 单个LSTM 节点的内部结构Fig.3 Internal structure of LSTM node
在LSTM 节点中,Xt表示SCNC 特征沿时间轴的输入,Ct表示由当前输入产生的细胞待更新的状态,由输入门it和遗忘门ft决定当前细胞状态要如何更新,细胞状态的迭代公式为
ht表示当前节点输出的隐藏状态,由输出门ot和当前细胞状态计算得到,使用tanh 函数作为激活函数,其计算如下:
将LSTM 网络层输出的全部隐藏状态H使用Flatten 层降维后输入到节点数分别为1024 和256的全连接层进行特征整合,激活函数为ReLU 函数,全连接层后使用了Dropout 函数以抑制过拟合,Dropout 率为0.3,并由6 个节点的Softmax 分类层得到情感分类结果。将SCNC特征输入LSTM以训练得到SCNC LSTM 前端网络。
1.3 基于SE通道注意力机制的网络中间层融合
在SER 任 务 中,MFCC 2D-CNN 和IMFCC 2D-CNN 前端网络更加关注谱特征中的语声能量信息,而SCNC LSTM 前端网络则侧重于语声的时序性信息。为了发挥两类网络的优势,本文将前端网络模型视作特征提取器,分别提取了MFCC 2D-CNN 与IMFCC 2D-CNN 前端网络最后一层卷积层的输出,提取了SCNC LSTM 前端网络的隐藏状态H。前端网络的中间层深度特征作为话语级的特征表示,由于不同网络中的深度特征对情感分类的贡献程度不同,本文引入SE 通道注意力机制,利用SE Block对各前端网络中间层权重进行调整[23],融合过程如图4所示。
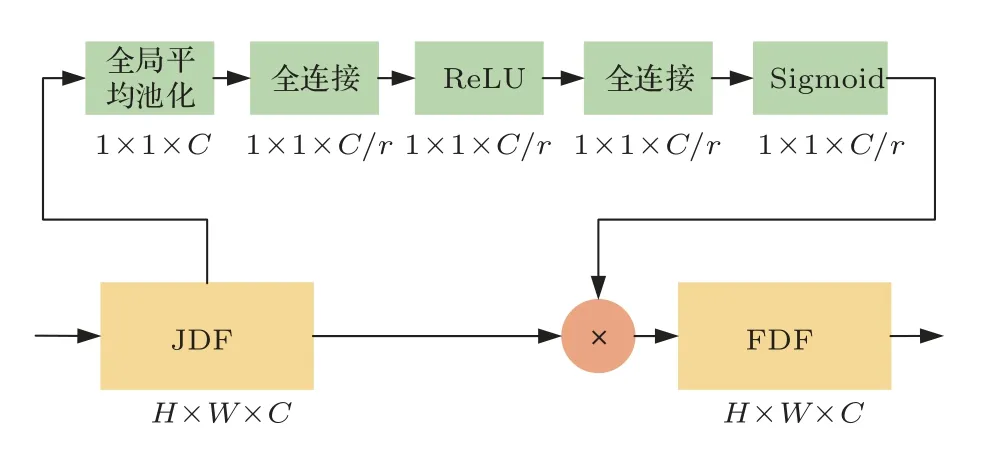
图4 SE 通道注意力机制融合过程Fig.4 SE channel attention mechanism workflow
SE 通道注意力机制的实现通过两步完成。第一步为Squeeze 操作,对应于图4 中的全局平均池化,其实现如下:
其中,压缩函数Fsq在特征维度上对中间层矩阵uc进行压缩降维,将H ×W ×C的多通道特征降为1×1×C的C维向量,以表征网络中间层的全局信息。第二步的Excitation 操作对全局平均池化后生成的zc依次进行了全连接、ReLU 激活、全连接、Sigmoid 激活,得到代表各通道重要性的权重矩阵,其表达式为
其中,δ为线性激活函数,W1与W2为两个全连接层,σ为Sigmoid激活函数。
将Excitation 操作后求得的权重矩阵s与前端网络中间层矩阵相乘可得到FDF矩阵,从而实现由多通道的联合深度特征(Joint deep feature,JDF)向FDF的转变。
1.4 DNN后端分类器
利用SE 通道注意力机制融合前端网络中间层得到了FDF矩阵作为话语级的情感特征,输入基于DNN的后端网络分类器进行SER,网络共有5 层全连接层,节点数分别为2048、512、256、64,激活函数均为ReLU 函数,最后由Softmax 分类层输出得到多分类预测矩阵,取概率最大的一类作为最终的情感预测结果。在网络中使用了Dropout 来抑制过拟合,其中Dropout 率为0.2。为了研究基于SE 通道注意力机制的网络中间层融合方式对每一类情感的识别效果,将DNN 后端网络的分类结果基于混淆矩阵进行输出表示。
2 实验与结果分析
实验部分首先通过消融实验对语声特征的维度选择及前端网络设计的合理性进行了验证,其次通过与前端融合和中间层非计权融合的对比实验验证了SE 通道注意力机制用于网络中间层融合的有效性,最后通过与参考文献中融合方式的对比实验对基于SE 通道注意力机制的网络融合方式在SER任务中的准确率与时间复杂度进行了分析。
2.1 实验平台与数据集
实验选用的CPU 型号为11th Gen Intel Core i5-11400,搭配4666 MHz 频率的双通道DDR4 内存,容量共32 GB,用于深度学习加速的GPU 型号为NVIDIA GeForce RTX3060,显存容量为12 GB,开发使用的语言版本为Python 3.8.3,使用的深度学习框架为Tensorflow 2.4.0。
本文实验基于中国科学院自动化研究所录制的汉语情感语料库的部分数据进行,该数据子集包含了来自4 位说话者的1200 条语声,其情感倾向包括生气(Anger)、悲伤(Sad)、害怕(Fear)、开心(Happy)、中性(Neutral)、惊讶(Surprise),语声的采样率为16000 Hz。实验中,将语声片段的时长统一为2 s 共32000个采样点,对其进行加窗分帧操作后可得到126 个语声帧。求得各语声特征维度如表2所示。
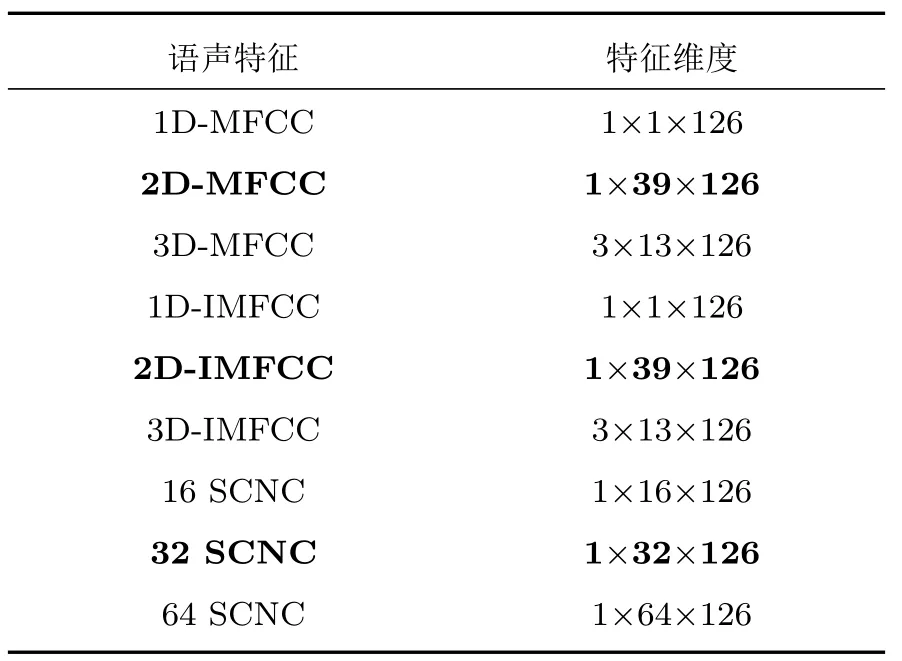
表2 语声特征及维度Table 2 Speech features and its dimension
2.2 实验设置
为消除数据集划分方式对网络性能的影响,将中国科学院自动化研究所语声情感数据集进行随机排序,并按照80%、10%、10%的比例划分为训练集、验证集和测试集。取五折交叉验证后的各情感平均分类准确率(Average ACC)和宏F1 得分(Macro-F1 Score)作为网络性能的评价指标。
为验证前端网络设置及对应特征维度选择的合理性,实验分别对比了:(1) 基于一维谱特征1D-MFCC 与1D-IMFCC 的1D CNN前端网络。(2) 基于三维谱特征3D-MFCC 与3D-IMFCC 的3D-CNN前端网络。(3)使用平均池化(Ave-pool)层的2D-CNN前端网络。(4) 基于16维与64维SCNC特征的LSTM 前端网络。(5) 基于32维SCNC特征的2D-CNN前端网络。为验证在网络中间层进行融合相较于特征级融合的优势,实验对比了两类前端融合方式:(1) 前端特征级注意力机制融合。(2) 前端特征级非计权融合。除此之外,还比较了对网络中间层进行非计权融合后的网络性能。
为了进一步验证SE 通道注意力机制用于网络中间层融合的适用性,还和文献[2]中基于随机森林特征选择算法的前端融合、文献[3]中基于GMU 的分层网络中间层融合和文献[7]中基于置信度的后端融合方式进行了比较分析,并取预测测试集的总耗时作为时间复杂度指标进行讨论。
2.3 实验结果与讨论
不同维度语声特征在对应前端网络中的分类结果如表3 中所示。由表3 可知基于二维MFCC特征的2D-CNN 前端网络相较于基于一维及三维MFCC 特征的前端网络取得了更高的平均准确率和宏F1 得分;基于二维IMFCC 特征的2D-CNN 前端网络亦优于基于一维与三维IMFCC 特征的前端网络;且最大池化在2D-CNN 前端网络中的效果好于平均池化。对比16 维与64 维的SCNC 特征可知,基于32 维SCNC 特征的LSTM 前端网络性能更好,且优于基于SCNC特征的2D-CNN前端网络。
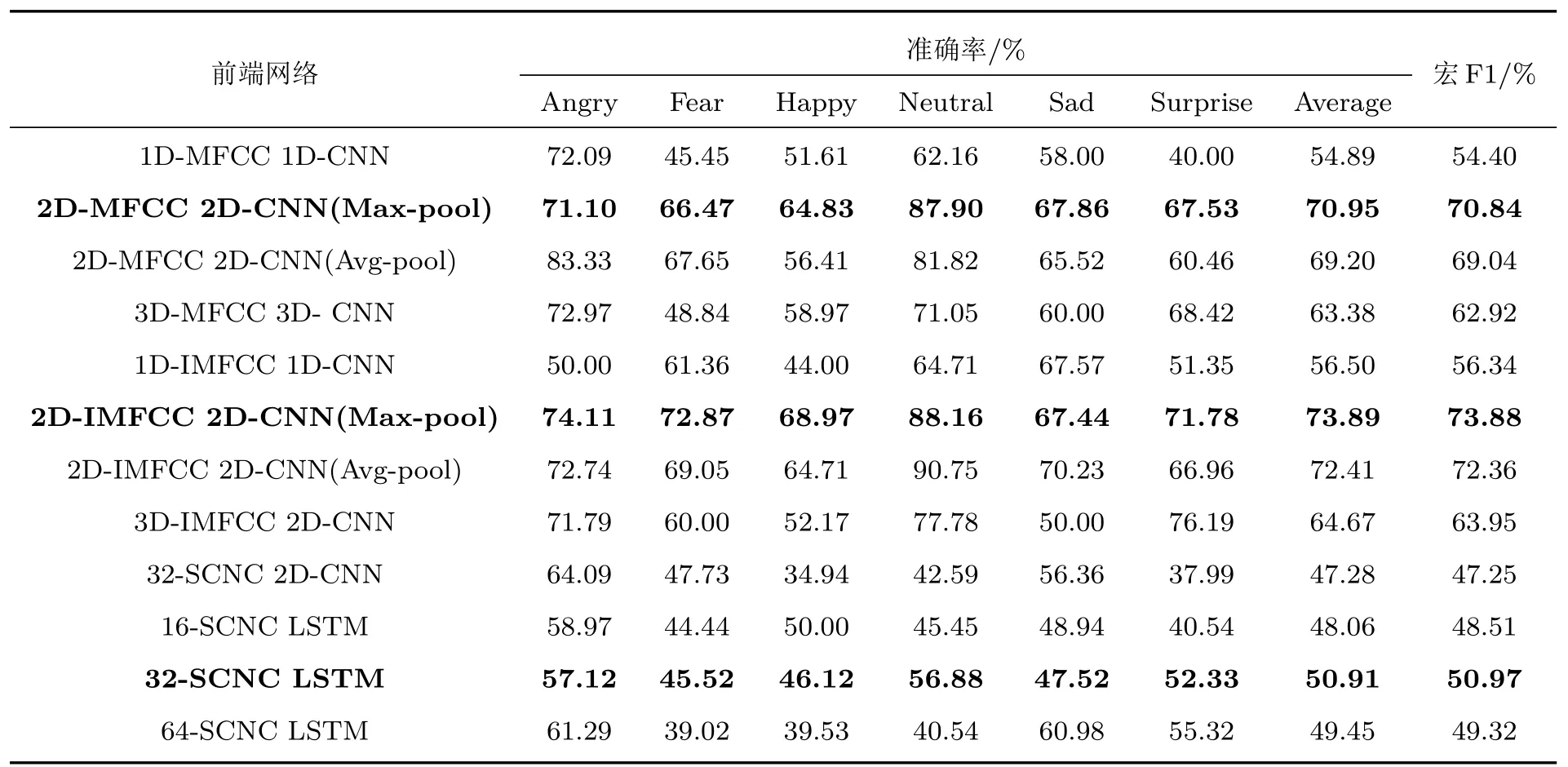
表3 三类语声特征在不同前端网络中的分类结果Table 3 Classification results of three SER features in different front-end networks
分析可知,对于二维MFCC 和IMFCC 特征,2D-CNN 前端网络可有效利用特征矩阵中的频谱能量信息进行分类。而最大池化相较于平均池化,对特征矩阵中的纹理信息更加敏感,更有利于对区分性信息的提取。对于SCNC 特征,LSTM 前端网络能够更好地学习序列中的时间相关性,由5 层ISCN提取的32维SCNC 特征则可较好地保留用于分类的高频信息。
将本文所选的3 类前端网络的分类结果表示为混淆矩阵,如图5 所示,其中对角线数据表示网络对每类情感的识别准确率。观察混淆矩阵可知,3 类前端网络对“中性(Neutral)”与“愤怒(Angry)”两类情感的识别准确率显著高于其余情感类别。

图5 三类前端网络的分类混淆矩阵Fig.5 Confusion matrix for three front-end networks
基于SE 通道注意力机制的网络中间层融合方式对比前端融合方式与中间层非计权融合方式的情感分类结果如表4 所示,观察可知,前端特征级的拼接融合或注意力机制融合相较于单一特征仅能使情感分类的平均准确率小幅提升,这证明了前端融合特征泛化能力有限,无法充分利用多种语声特征的优势。而基于网络中间层进行非计权拼接融合后的准确率相较于特征级融合有了显著提高,但其表现依旧差于采用SE 通道注意力机制的融合方式。这证明了基于网络中间层进行的融合优于特征级的融合,也进一步验证了基于SE 通道注意力机制进行融合的有效性。不同融合方式取得的分类混淆矩阵分别如图6 所示,观察可知后端分类网络均在“中性”情感上取得了最高的识别准确率,这也证明了前端网络在某一类情感识别中的优势在融合后可以得到保留。
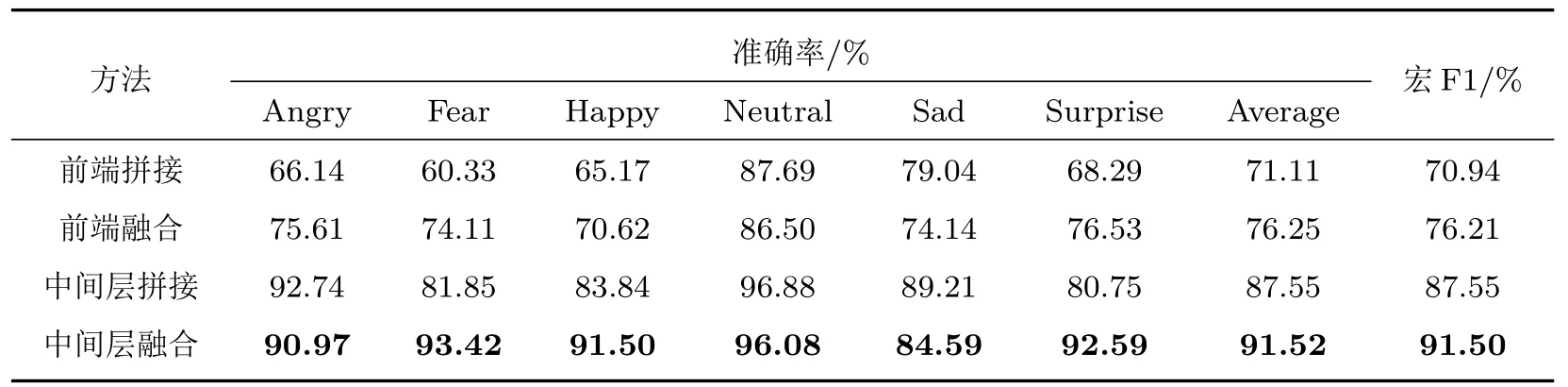
表4 不同网络融合方式的对比实验结果Table 4 Comparative test results of different network fusion methods
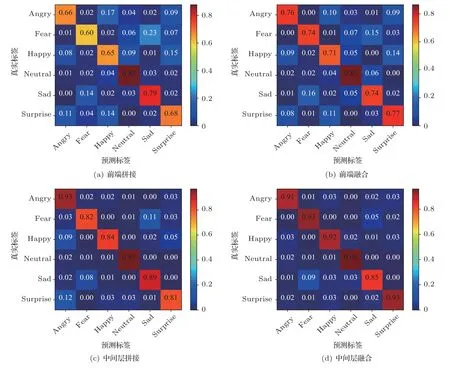
图6 不同网络融合方式的分类混淆矩阵Fig.6 Confusion matrix for different network fusion methods
文献[2–3,7]中不同阶段的融合方式在测试集上的平均准确率和预测耗时如表5 所示。观察数据可知,基于随机森林特征选择算法的特征融合方式[2]所用预测时间最短,这也体现了传统机器学习方法在预测效率上的优势。基于置信度的后端决策级融合方式[7]在使用多类语声特征获得较高的准确率的同时耗费了最长的预测时间。而基于GMU的网络中间层融合方式[3]对动静态谱特征进行融合则可兼顾识别效率与准确率。本文相较于融合方式[3]在谱特征的基础上增加了时序特征,使用SE通道注意力机制用于网络中间层融合,平均准确率提高了5.39%,预测耗时则仅增加0.015 s。对比实验证明了本文基于通道注意力机制的融合网络用于SER 任务时,通过对多种语声特征和分类网络的有效利用,可以实现更高的平均识别准确率。

表5 融合方式的准确率与复杂度对比Table 5 Accuracy and complexity comparison
3 结论
本文把SE 通道注意力机制用于对基于谱特征的和时序特征的前端网络的中间层融合,并进行了实验验证。实验结果表明,多特征分类相较于单一特征分类在情感识别准确率上具有明显的优势;中间层融合的多特征融合方式优于前端特征级的融合方式;利用SE 通道注意力机制对前端网络中间层进行融合,能有效利用不同前端网络在SER 任务中的优势提高情感识别准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
轮胎工业(2020年4期)2020-03-01
中国交通信息化(2018年5期)2018-08-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
焊接(2016年8期)2016-02-27
焊接(2016年6期)2016-02-27
