
一种基于聚类的门控卷积网络语声分离方法*
2023-09-20 06:50胡维平吴华楠
应用声学 2023年5期
罗 宇 胡维平 吴华楠
(广西师范大学电子工程学院 桂林 541000)
0 引言
语声分离任务源于鸡尾酒会问题[1]。传统学习方法存在计算复杂度高和区分性训练困难的问题。与上述相比,深度学习为语声分离任务提供了快速准确的方法,其高效的建模能力将掩码推断视为一个分类问题。在以往的频域语声分离中,需要考虑分离语声的说话人排列问题[2]。因为频域中将语声分帧,再进行语声分离,可能会将一个说话人的语声帧分离到另一个说话人上,造成网络分离的语声信息混乱。深度聚类是最早基于深度学习的语声分离体系结构,使用经过区别训练的嵌入,在高维嵌入的特征空间中进行聚类来解决语声分离输出排列问题。
说话人聚类的语声分离可以看作是一种矩阵分解任务,输入的混合语声作为输入矩阵,是若干个输出矩阵之和,基于此理论来利用掩码方法。深度聚类训练目标是理想二值掩码(Ideal binary mask,IBM),每个时频单元对应一个源信号,由此可将掩码估计等同于时频单元聚类分类的问题。陆续有很多研究人员采取聚类方法来进行说话人分离。Hershey等[3]提出了深度聚类(Deep clustering,DPCL),训练了一个深层网络,将对比嵌入向量分配给频谱图的每个时频区域,输出标签的匹配转换为亲和力矩阵的匹配,最小化同一人的时频单元嵌入向量之间的距离,最大化不同人之间的距离,其高度依赖于嵌入形成的低秩成对亲和力矩阵。Chen等[4]提出了深度吸引子网络(Deep attractor network,DANet),通过在混合信号的高维嵌入空间中创建吸引子点,吸引子是由嵌入向量动态计算得到,将每个声源对应的时频单元聚集在一起,通过学习聚类中心来对不同的说话人生成不同的掩码,这样就可以得到一种可学习的聚类中心,与DPCL 相比更加灵活,得到的结果也更加理想。Luo等[5]提出了独立说话人的吸引子网络(Speaker-independent speech separation with deep attractor network,ADANet),利用嵌入空间的一组辅助点(锚定点),使用嵌入和每个吸引子之间的相似性来估计混合物中每个源的掩码。ADANet 解决了DANet中两种创建吸引子方法的问题,但是网络引入一个期望最大化(Expectation maximization,EM)迭代过程,需要对于每一种取法计算锚框和吸引子,因此计算开销增大。Wang等[6]提出了嵌合体网络(Chimera),该结构将深度聚类与掩码推理网络结合在多目标训练方案中,提出了多个备选损失函数来训练深度聚类网络,在训练掩码推理网络以实现最佳分离时,深度聚类损失可作为正则化项,防止训练过拟合。
时域卷积网络(ConvTasNet)是一种全卷积声频分离网络,在序列建模和声频处理任务中展现了优越的性能[8]。本文利用ConvTasNet 的时域卷积网络(Temporal convolutional networks,TCN)结构,设计了基于聚类的门控卷积网络(Gate-conv cluster)框架,编解码器分别是一维卷积和一维转置卷积,在分离网络中,用堆叠的门控卷积(Gateconv)来提取语声信号的深层次特征;同时在特征空间中搭建聚类模块,对长时语声特征进行映射分离。聚类定义的损失函数是负尺度不变信源噪声比(-SISNR),对目标语声信号进行端到端训练。该框架很好地解决了传统聚类方法无法做到端到端训练和时域卷积网络语声建模中短时依赖的问题。
1 模型设计及方法介绍
语声分离是指从给定的混合语声信号中提取所有重叠的信号源[9]。对于给定的线性混合单通道信号y[t],单通道语声分离提取所有C个说话人的源信号为Xc[t],c为说话人索引。
1.1 Gate-conv cluster
Gate-conv cluster 是 在convtasnet 的tcn 结构[7-8,10]上提出的编码器-解码器框架,编码器是一维卷积,并行编码计算混合语声的时域特征;然后将其送入一维非线性Gate-conv堆叠的嵌入网络中,在高维度的特征空间中进行聚类,估计出目标语声的掩蔽值;后利用编码后的混合语声与估计出来的掩蔽值做点乘,最后通过一维转置卷积重构得到纯净的语声信号。图1 显示了搭建的Gate-conv cluster框架以及gate-conv结构。
1.2 编码器
其中,Yconv是混合信号y[t]的时域特征表示,ReLU(·) 是用于确保非负输出的元素整流线性单元;Conv1D(·)是由可学习权重参数的1*1卷积核。
1.3 Gate-conv
分离网络由门控卷积网络和嵌入空间中的聚类组成。受Chimera 聚类集群框架[6]启发,语声经过深度神经网络,结合门控支路提取的非线性信息对于在聚类空间中时频单元生成掩码具有更好的性能。Gate-conv在ConvTasNet中一维卷积块1-D-conv中增加了非线性门控卷积支路[8,11],每个一维卷积模块增加两个Sigmoid 门,一个对应于一维卷积模块中的第一个1*1 卷积层即1*1_conv,另一个对应于从深度可分离卷积depthwise_conv到输出1*1_conv 的所有层,depthwise_conv 中的卷积层是大小为K的卷积核。
Gate-conv 结构块中,门控卷积块的不同颜色表示不同的膨胀因子,特征映射首先通过一个通道数为256 的1*1_conv 块,然后是8 个剩余的通道数为512 的Gate-conv块,膨胀率为1,2,···,128,重复4 次;其中Gate-conv 中卷积核大小为3,步长stride为1。其中在每两个卷积操作之间添加激活函数和归一化,经过depthwise_conv 后的1*1_conv的Output 作为下一个门控卷积块的输入;剩下的1*1_conv 块的跳跃连接总和作为Gate-conv 结构块的输出[8]。
1.4 嵌入空间中的聚类
在门控卷积网络后端搭建了聚类框架,经过门控卷积网络的混合声音的特征单元,被投射到一个高维空间[12]。特征单元在和不同源分配生成的吸引子距离计算上,任意两点的距离都可能极为相近,导致难以将其区分出来;同时高维数据集的簇可能存在于不同的维度集合里。所以确定一定维数的特征空间很有必要,特征空间使用嵌入尺寸参数embed_size为σ的深度神经网络实现。为了将每个嵌入的特征单元分配给混合特征矩阵中的不同说话人,沿着时间追踪嵌入空间中说话人的质心,其中来自不同声源的质心被称为吸引子点At(i,σ,τ),i是说话人的源分配,σ是特征空间维度,τ是时间步长,该吸引子点用于确定当前说话人的特征向量分配。
与去年的调查相比,其他变化仅有CPA报道的AB Smithers北方木制品公司倒闭。这家工厂在我们去年的名单中仅显示9.7万m3的年产能。
吸引子的位置在每个时间步都会更新。首先,吸引子的先前位置用于确定当前特征单元的说话人分配。然后通过聚类操作,基于先前吸引子的加权平均值和说话人分配定义的当前特征向量中心更新吸引子[13]。
其中分离模型U(·),在特征空间中,属于同一源的所有嵌入的特征单元表示会互相吸引[14]。嵌入特征空间中的特征单元和每个吸引子之间的距离(通常表示为点积)决定了该特征单元的源分配,然后使用该分配为每个说话人定义一个掩码,该掩码乘以经过一维卷积编码器后的混合源语声的时域特征表示来恢复该源。图2 显示了嵌入空间中聚类来恢复源信号的操作。
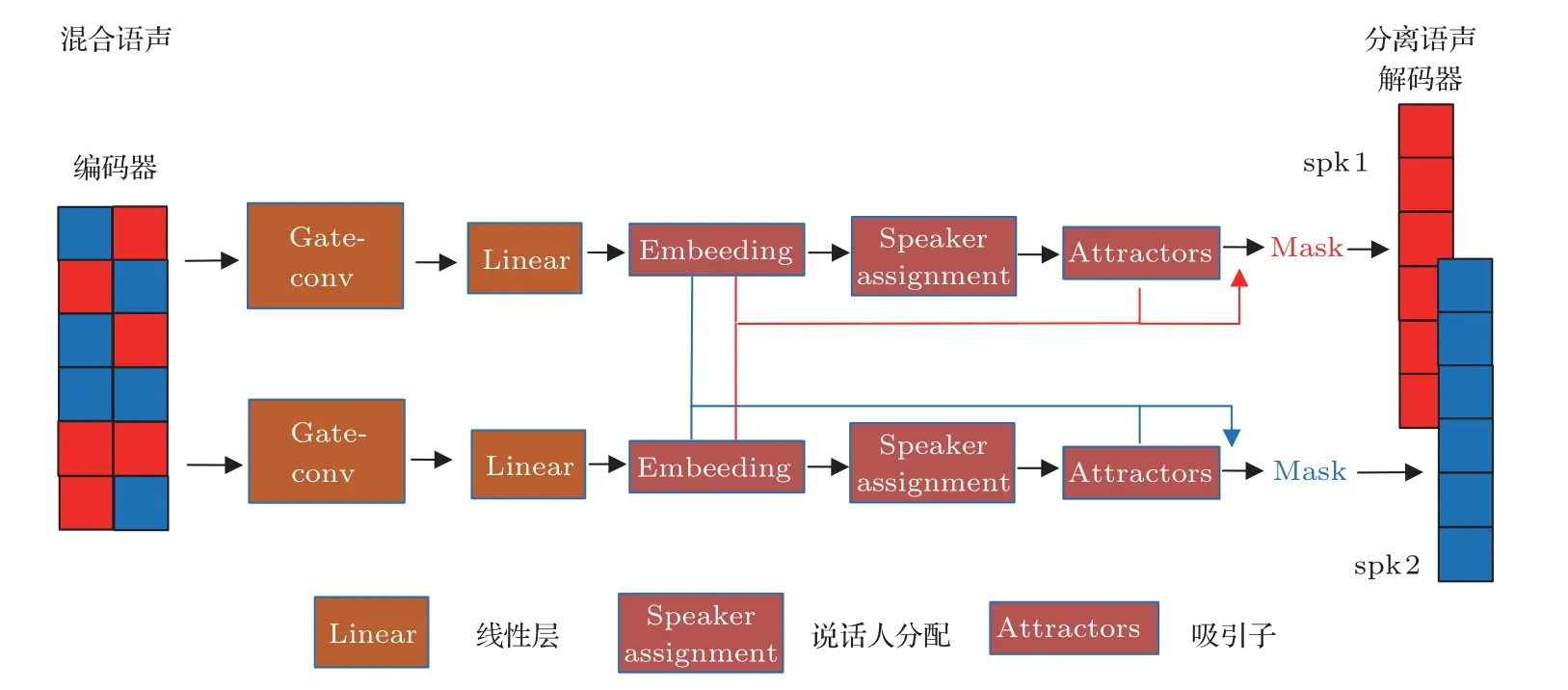
图2 嵌入空间中聚类分离源信号示意图Fig.2 Schematic diagram of clustering separated source signals in the embedding space
其中,U(·)是由分离网络参数σ定义的掩码估计模型。
在基于掩蔽Mask 的解决方案中[15-16],根据式(4)推导出恢复源信号Xc的特征向量由估计掩码与混合信号经过编码器后的Yconv点乘得到。
其中,t和k分别是时间步长和特征向量索引,而Yconv通过混合信号y[t]经过一维卷积编码的潜在特征表示;是为说话人c通过聚类生成的掩码;⊙是元素乘法运算。
1.5 解码器
2 训练目标
本文以尺度不变信噪比为训练目标[8]。网络训练目标函数是标准信号重建误差,这使得在训练和测试阶段都可以进行端到端操作。
3 实验结果及分析
3.1 数据集设置
实验采用的原始语声数据集来自WSJ0 语料库[8]。利用该语料库创建双说话人混合数据集WSJ0-2mix:首先从WSJ0 语料库中si_tr_s 文件夹中随机选择两个说话者的语声,并以-5~5 dB之间随机选择的信噪比(Signal to noise ratio,SNR)进行混合,建成包括49 名男性和51 名女性说话人、总量为30 h的训练集。此外,10 h验证集和5 h测试集来自WSJ0 的si_dt_05 文件夹和si_et_05 文件夹的16 个说话人的言语(与训练集不同)。最后,经过8 kHz降采样,得到精度为16 bit的20000条语声训练集、5000 条语声验证集、3000 条语声数据测试集[3]。
3.2 参数设置
该网络的编码器与解码器即一维卷积,卷积核大小均为20,网络在4 s长的片段上进行训练。初始学习速率设置为1×10-3,如果在连续3 个时期内验证集的准确性没有提高,学习率将减半,优化器使用Adam进行训练[17]。
通过信号失真比改善(Signal distortion ratio improvement,SDRi)[18]和尺度不变信噪比改善(Scale invariant SNR improvement,SI-SNRi)[8]来评价该方法,其中指标数值越大表明语声分离性能越好。
3.3 双支路非线性门控卷积的验证分析
为了验证双支路非线性门控卷积对于TCN 结构的改进作用,在后端均不添加聚类操作的情况下,Gate-conv 和ConvTasNet,在WSJ0-2mix 数据集下,使用相同实验设置,分别使用Gate-conv和使用ConvTasNet 的1-D-conv 再进行聚类后端分离,运行50个epoch,实验结果如表1所示。
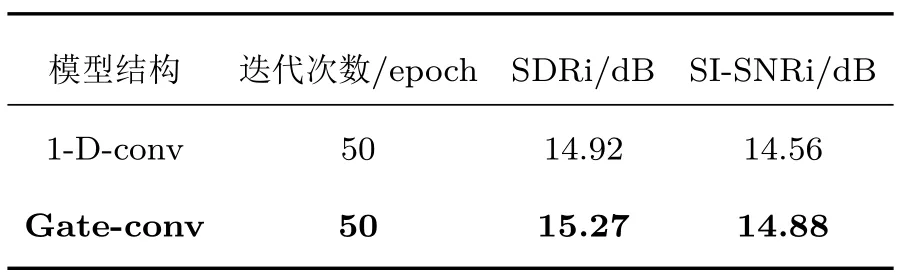
表1 使用非线性双支路门控卷积与一维卷积的分离结果对比Table 1 Comparison of separation results using nonlinear bipartite gated convolution with one-dimensional convolution
从表1 可以看出,在基线原有ConvTasNet 中1-D-conv 上增加双支路非线性门控激活后的Gateconv,分离结果均有不同程度的提升,其中SDRi 提升了0.35 dB,SI-SNRi 提升0.32 dB。由此可得出,非线性双支路门控卷积提高了卷积网络的非线性表达能力,在序列建模工作控制更多的信息流,能够有效地提取语声信号的深层次特征,对于语声分离效果有着一定的改善。
3.4 高维聚类和不做聚类直接估计mask 方法的验证分析
基于Gate-conv,在WSJ0-2mix数据集下,使用相同实验设置,分别进行高维空间聚类(Gate-conv cluster)和不做聚类(Gate-conv)直接估计mask 分离,运行50个epoch,实验结果如表2所示。

表2 高维空间聚类和不做聚类方法的分离结果对比Table 2 Comparison of separation results between high-dimensional spatial clustering and no clustering methods
从表2 可以看出,在Gate-conv 后端进行聚类(Gate-conv cluster),其中SDRi提升了1.03 dB,SISNRi 提升1.01 dB。经过实验研究发现,Gate-conv cluster 在高维空间中聚类,通过说话人分配和吸引子进一步使网络训练每个说话人更长时间序列的特征向量表示,克服了ConvTasNet 语声建模的短时依赖性问题,进一步提高了语声分离的性能。
3.5 最优嵌入空间维数研究
在门控卷积网络后端使用嵌入尺寸参数embed_size为σ的深度神经网络生成高维度的特征空间,在WSJ0-2mix数据集下,使用相同实验设置,运行50 个epoch 进行分离,进行最优嵌入空间维数的研究,实验结果如表3所示。

表3 不同嵌入空间维数的分离结果对比Table 3 Comparison of separation results for different embedding space dimensions
从表3 可以看出,在进行验证不同嵌入空间维数时,随着嵌入空间维数的增加有助于提高网络分离性能,但当维数增加到一定值时,网络分离效果显著下降;当σ为20时,SDRi和SI-SNRi达到最佳,分别为16.30 dB和15.89 dB。实验研究表明了在不同维度嵌入空间的接近度会影响不同源信号特征单元聚类的性能[19],同时也证明了在最优维度特征空间中Gate-conv cluster框架能够在语声分离任务中表现得更好。
3.6 与不同聚类方法和基线ConvTasNet 的研究比较
通过以上实验验证分析研究,Gate-conv cluster 在运行100 个epoch 后,与不同聚类方法和基线ConvTasNet 在同一数据集wsj0-2mix 下进行说话人分离的研究比较,实验结果如表4所示。

表4 与不同聚类方法和基线ConvTasNet 的分离结果对比Table 4 Comparison of separation results of different clustering methods and baseline ConvTasNet
从表4 所示,在时域上,Gate-conv cluster 与ConvTasNet 的TCN 结构的基线[8]相比,在因果任务中实现了端到端训练,SDRi和SI-SNRi分别能提高1.12 dB 和1.03 dB;与之前聚类操作的网络架构相比,性能明显优之前无语声建模的聚类框架,其中SDRi 和SI-SNRi 分别达到16.72 dB 和16.33 dB的效果。实验证明了本文提出Gate-conv cluster,通过堆叠的门控卷积对语声进行深层次的建模,然后在最优维度的空间中,聚类对映射的特征单元进行表示和划分,为恢复不同信号源提供了一个长期的说话者表示信息,能够进一步提高语声分离性能。
4 结论
本文介绍了在时域上用于单通道语声分离任务的Gate-conv cluster,首先将使用改进的堆叠双支路非线性门控卷积对编码后的语声进行建模,然后通过实验研究了最优嵌入空间的维数,在高维特征空间中进行聚类,追踪不同源信号的长时特征表示;同时网络训练使用了基于目标语声的尺度不变信噪比作为损失函数,实现端到端信号分离。实验结果表明,与基线ConvTasNet 和以往传统聚类分离的方法相比,Gate-conv cluster 框架具有更好的分离性能。
由于时域卷积更关注语声的局部信息,因此,下一阶段工作将使网络能够学习全局说话人信息,提高语声分离模型的鲁棒性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
通信学报(2019年5期)2019-06-11
北京航空航天大学学报(2018年1期)2018-04-20
通信技术(2018年3期)2018-03-21
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年6期)2015-02-27
电子设计工程(2015年20期)2015-01-29
