
基于双向图神经网络的变压器故障知识图谱构建
2023-10-12 00:42栗佳初朱永利
电力科学与工程 2023年9期
栗佳初,朱永利
(华北电力大学 计算机系,河北 保定 071003)
0 引言
变压器作为重要的输变电设备,其健康状况直接影响电力系统安全运行[1]。快速且准确地了解变压器信息,可以提升变压器检修和维护的效率[2],进而保证用户的用电质量。
电力变压器运维方案的制定通常依赖专家经验[3,4],从而导致运维措施可解释性弱,且效率不高。目前,电力系统已积累了大量的故障处理案例,由于其记录方式主要为非结构化的文本,故知识的结构化程度不高[5]。因此,有必要设计更精细、丰富的知识表示方法,形成变压器故障知识表示网络,以进一步为智能运维提供数据支撑及理论支持[6]。
知识图谱的概念于2012 年被提出,其初衷是为了改善搜索结果。知识图谱具备强大的学习和推理能力,所以迅速受到了学术界和工业界的广泛关注[7-9]。
构建知识图谱的基础是信息抽取,即从非结构化的文本数据中提取出与事件有关的信息,并以结构化的形式存储、展现。目前,相关学者对知识图谱开展了大量研究[10-13]。
信息抽取的准确性直接影响知识图谱的构建质量。文献[14]提出一种关系抽取神经网络模型,用双向长短期记忆网络(Bidirectional long short-term memory network,BiLSTM)模块进行实体提取,将卷积层用于关系分类,将BiLSTM 层产生的信息传递到卷积层以提升关系分类的精度。文献[15,16]使用BERT(Bidirectional encoder representation from transformers)预训练模型提取字符的特征,通过软标签嵌入进行全局关系预测。文献[17,18]将关系抽取问题转化为多头选择问题。文献[19]提出GraphRel 模型,采用LSTM 抽取信息,并使用双向图神经网络(Bidirectional graph convolutional networks,BiGCN)进行关系推理,使模型在NYT数据集上比之前的模型精度提高了3.2%。
上述研究多是在英文数据集上开展的,流程基本固定:用BiLSTM 挖掘字符间的依赖特征,用条件随机场(Conditional random field,CRF)进行实体的分类,关系提取使用卷积网络或者将其转化为多头选择问题。
受上述文献的启发,本文使用预训练模型BERT 提取字符特征,然后使用BiLSTM 提取文本上下文特征,用CRF 进行实体识别,用多头选择判定实体间关系,以关系矩阵作为节点特征的邻接矩阵,最后用BiGCN 根据邻接矩阵对节点特征进行再次更新,纠正错误的实体关系。
1 变压器故障知识图谱构建方法
1.1 本体层设计
在人工智能领域,本体这一概念被用于刻画知识,由类、关系、属性3 部分组成。
在变压器故障知识图谱中,故障诊断的知识由事件逻辑来表达,其语料库涉及故障现象、故障原因、检测方法、维修方法。
首先,定义事件参数。构成事件的元素主要有:对象(object)、触发词(trigger)、状态(state)。对象指发生故障的设备,如铁芯、套管等。触发词指事件触发元素,如出现、导致等。状态一般是对发生故障设备的描述,如受潮、损坏等。
然后,定义事件参数的类概念和关系。为了保证节点的一致性,类的属性也看作节点。类概念主要描述了事件参数定义;关系则主要描述了触发词的定义和事件之间的逻辑关系。
变压器故障事件和参数模型如图1 所示。

图1 变压器故障事件和参数模型Fig. 1 Transformer fault event and parameter model
从图1 可知:故障事件包括故障原因事件、故障现象事件、故障检测事件和故障维修事件。故障原因与故障现象之间的关系是“导致(lead to)”;故障维修方法与故障原因之间的关系是“维修(fix)”;故障检测事件与故障现象之间的关系是“检测(detect)”。每个事件包括对应的故障部件和状态,均为事件的参数。
变压器故障语料库主要由故障事件构成,宏观上可分为变压器结构部分和故障描述部分。结构部分主要分为3 个层次:设备、子设备、零件。设备主要指变压器,子设备主要指铁芯、绕组、油箱等变压器的功能部件。零件指螺栓、外壳等不可再分的组件。在对故障事件的描述中,部分故障现象同时也是故障原因,比如绝缘垫块潮湿造成铁芯多点接地。垫块潮湿既是现象又是造成铁芯多点接地的原因。
概念类被定义之后,类之间就会存在相应的类关系。本文设计的事件关系主要包括:consist_of,lead_to,detect,fix,has_attribute 和appear。其中,consist_of 表示设备结构之间的关系,has_attribute表示设备与属性之间的关系;这2 种关系描述的是变压器知识的定性关系。lead_to 表示状态间的事件逻辑关系,detect 表示检测方法与设备故障状态之间的关系,fix 表示维修方法与设备故障状态之间的关系;这3 种属于事件逻辑关系。除此之外,设备状态值可能会导致设备属性值发生变化,因此设备状态与设备属性之间也存在lead_to 关系。
1.2 标注策略
借鉴英文数据集的标注方法,将信息提取任务转化为文本的标注任务。标注包含实体类别层、关系层、关系位置层。实体层采用BIO 的标注方式,B 表示一个实体的开头,I 表示一个实体的中间和尾部,O 表示非实体。
实体主要包括故障设备、状态、检测方法、维修方法。其中检测方法和维修方法属于较长的实体,模型需要具备足够的记忆能力才能取得好的效果。
根据上文提出的本体模型,本文共涉及8 个实体类别、7 个关系类别。8 个实体类别分别为:
equipment,sub-equipment,component,state,gas,attribute,detect_method,fix_method。7 个关系类别分别为:appear,lead_to,consist_of,has_attribute,generate,detect,fix。关系类别按尾实体先后位置依次标记在头实体最后一个字符上,如附录所示。
网络模型的输入为变压器故障诊断文本,输出为实体和关系标签。根据标签可以将非结构化的文本转化为有意义的图结构。
在收集的案例语料中,每个故障都有其对应的故障原因和故障表示。此外,还存在不同的故障原因可以引起相同或相似的故障现象,以及一个故障原因可以引起多种不同的故障现象的情况。因此当故障相同时,对应的故障原因和故障现象并不完全一致。
2 联合抽取模型
本文使用中文BERT 通过微调学习文本的词向量,并将其作为堆叠BiLSTM 层的输入,以捕捉文本的深层语境特征;CRF 用来识别实体;最后,根据关系矩阵用BiGCN 更新节点特征。信息抽取模型框架如图2 所示。

图2 信息抽取模型框架Fig. 2 Framework of information extraction model
CRF 被用来划分全局最优标签序列,基于字符依赖性特征序列M,输出标签序列Y。标签序列和特征序列的联合概率分布如式(1)所示。
式中:A为标签之间的转移概率矩阵,由训练得到;Yi为第i个字符的预测标签。
从式(2)中可以得到M和Y的条件概率。
式中:Y′为一个可能的标签序列;f(M)为所有可能的标签序列的集合。
在训练CRF 时,以最大似然估计作为损失函数来最大化P(Y|M),如公式(3)(4)所示。
在实体类别预测过程中,使用维特比算法预测最佳标签序列。
为了缓解错误的实体分类对关系识别造成的影响,将BiLSTM 的输出特征与预测标签向量进行拼接,记为向量Z。关系概率计算为:
式中:δ为sigmoid 激活函数;p(ci,r,cj)为字符ci与cj之间存在关系r的概率;“⊕”表示计算各个关系的概率值;Wv,W f,Wb分别为全连接层权重矩阵、前向关系权重矩阵、后向关系权重矩阵。
在训练过程中,最小化交叉熵损失作为优化目标,如式(6)。
式中:n为字数;m为关系类别的数量;q(ci,r,cj)为实体ci和cj之间存在关系的概率;p(ci,rk,cj)为实体ci和cj之间的每个关系的概率。
常规的信息抽取方法没有考虑关系对实体识别的影响。考虑到关系的确定能够帮助模型更好地识别实体,例如关系类别如果为“fix”则头尾实体分别为“fix_method”和“state”,因此本文引入了BiGCN,将字符的深度上下文特征作为节点特征,以上一阶段对关系的预测结果作为邻接矩阵,再次进行实体关系的联合抽取。
传统的GCN 无法建模方向,但是知识图谱三元组中定义了头实体和尾实体。根据关系的方向,邻接矩阵被分为前向邻接矩阵和后向邻接矩阵,如公式(7)—(9)所示。
BiGCN 运算后的节点特征先与邻接矩阵相乘,再经过激活函数。节点特征最终的更新公式如式(10)所示。
考虑关系概率对节点特征更新影响的优点是,可以有效纠正模型前期积累的错误特征,增强模型的识别能力。
3 实验验证
3.1 实验平台与数据
本文的实验环境:操作系统为Win10,CPU为intel core i5-7300,GPU 为2080ti;软件python 3.7,pytorch1.7.0。
电力变压器公开的运维文档与事故处理报告较少。本文从《电力设备预防性试验规程》等文献中摘取与变压器运维相关的描述故障原因和故障现象的语句。
在此基础上,进一步标注实体关系,得到数据集,含2 456 条语句,63 070 个字符。将其中80%用作训练,其他用作测试。具体数据统计如表1 所示。
3.2 模型参数设置
模型的参数直接决定着模型的识别能力。本文参数通过搜索确定。搜索范围和最终选定的参数(加黑)如表2 所示。

表1 数据统计信息Tab. 1 Data statistics

表2 模型参数设置Tab. 2 Model parameter settings
3.3 实验结果与分析
3.3.1 对比实验
为了验证本文方法的优越性,选择算法1[18]和算法2[19]作为对比算法。以准确率P和F1分数作为评价指标。实验结果如表3 和图3 所示。

表3 实验结果Tab. 3 Experimental results %
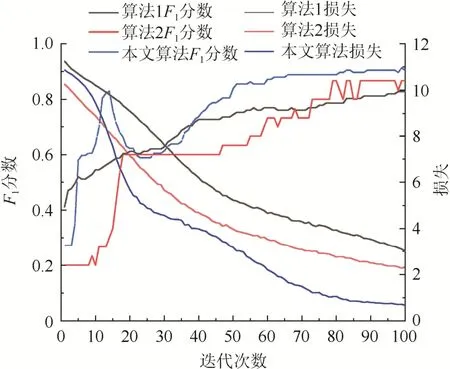
图3 各算法F1 分数及损失对比Fig. 3 Comparison of F1 scores and losses of each algorithm
从表3 和图3 可以看出,本文提出的模型在变压器运维文本的信息抽取任务中具有明显的优势。
结果分析:
相比算法1。本文算法将BiLSTM 的输出特征与预测标签向量进行拼接,缓解了错误的实体分类对关系识别造成的影响,且考虑关系概率对节点特征更新的影响,可以有效纠正模型前期积累的错误特征。
相比算法2。本文算法使用预训练模型BERT获取词向量,更好地考虑了上下文字义和语境意义;针对本文语料,通过微调模型获得更优的性能。
3.3.2 消融实验
为了验证BiGCN 对模型信息提取能力的影响,选择BERT-BiLSTM-CRF(算法3)作为对比算法。相比本文模型,算法3 仅去掉BiGCN 更新节点特征的过程,其他参数设置、模型结构与本文模型保持一致。
消融实验结果见表4。

表4 消融实验结果Tab. 4 Ablation experimental results %
由表4 可知,加入BiGCN 模块的模型获得了3.1 个百分点的联合F1分数提升。BiGCN 可以推断和纠正错误的实体关系,联合抽取提高了实体识别和关系识别两个子任务的相关性,性能获得明显的提升。
4 变压器故障知识图谱的可视化与应用
将通过上述方法提取到的三元组存储在neo4j 图数据库中。该库以节点和关系为对象存储图结构数据,可以使用Cypher 语言进行快速查询。
同时开发线上网站,提供知识图谱自动化构建服务。用户输入要处理的文本,后端会调用模型进行信息抽取,然后返回构建好的图谱。
在关系查询界面,支持3 种查询方式:根据头节点、关系查询尾节点,根据头节点、尾节点查找最短路径,根据关系、尾节点查找头节点。
针对变压器运维过程中信息关联性弱及决策生成效率低的问题,为提高决策生成服务能力,系统首先将输入问题转化为查询图,将其表述为状态和动作的搜索问题。查询图由4 种类型的节点组成:基础实体,存在变量,λ变量,聚合函数。基础实体是存在于知识图谱中的实体。存在变量和λ变量不是基础实体。最终将可以映射到λ变量的所有实体作为答案。聚合函数旨在对实体进行过滤。首先从知识图谱中检索基础实体及关系,构造查询图[20]。以“铁芯发生过热故障的处理方法?”为例,查询逻辑形式为:
λx.∃y.method(x,y) ∧appear(铁芯,过热)∧
fix(y,过热) ∧detect(y, 过热)
铁芯和过热为2 个基础实体,之间的关系为“appear”。y表示存在变量,描述构造关系。x表示λ变量,即答案节点,用于映射查询检索到的实体。聚合函数的约束是返回的节点类型,为fix_method。x、y都是方法实体,代表铁芯过热的维修措施或者需要进行的检修试验。检索到的实体由聚合函数筛选,返回铁芯过热的维修措施给运维人员。运维人员核验与完善生成的处理方法,生成运维报告。
5 结论
本文基于电力变压器运维相关文献,提出一种基于BERT-BiLSTM-CRF-BiGCN 的知识图谱构建方法,主要结论如下:
1)设计了变压器故障知识图谱本体层,包含8 种本体、7 种关系。基于本体对故障诊断文本进行标注,建立了实体和关系联合提取数据集。
2)提出实体和关系联合提取方法,首先通过BERT 预训练模型学习词向量,堆叠BiLSTM 模块,根据深度语境更新字符特征,再使用BiGCN结合关系矩阵纠正错误的实体关系。模型联合F1分数可以达到89.94%,明显优于对比模型。
3)开发软件提供线上知识图谱自动化构建、实体查询、关系查询和决策生成的服务,提升变压器运维决策生成的效率。
猜你喜欢
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
中国交通信息化(2019年5期)2019-08-30
能源(2018年8期)2018-09-21
能源(2017年11期)2017-12-13
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
