
基于距离排序的DUPSO-DSVM民歌快速分类算法研究*
2023-10-24 02:52吕小姣张玉梅杨红红吴晓军
计算机工程与科学 2023年10期
吕小姣,张玉梅,杨红红,吴晓军
(1.民歌智能计算与服务技术文化和旅游部重点实验室,陕西 西安710119;2.陕西师范大学计算机科学学院,陕西 西安710119;3.陕西师范大学现代教学技术教育部重点实验室,陕西 西安710062)
1 引言
随着计算机技术的发展,音频信号分析、分类检索和音频信号合成已经成为语音研究领域的热点话题,各种机器学习分类算法都为音乐分类问题提供了很好的解决办法。中国民歌是历史和岁月的积淀,中国传统文化的精髓也都在民歌上体现得淋漓尽致。由于各个区域的语言和生活习俗不尽相同,不同的地域也就形成了各式各样风格的民歌[1]。在时代发展的潮流中,越来越多的人们开始追求流行音乐,而忘却了先辈们留下来的非物质文化遗产——民歌。因此,对于中国民歌的分类和保护工作必须提上日程,大力推广民歌,让越来越多的人了解民歌,了解中华民族不同地域的优秀传统文化。
在音乐分类问题上,国外在关于乐器和流派的分类问题上进行了深入研究,国内研究人员则主要聚焦于中国传统戏曲、传统民乐和民歌的分类[2]。数据集的创建是进行分类实验的基础。Tzanetakis等[3]构建的数据集GTZAN包含了10个音乐流派的歌曲,目前该数据集已成为音乐分类研究常用的一个公开数据集。在音乐分类的特征选择问题上,由于语音的特征较多,所以要将不同的音频特征进行组合分析与比较。Sujeet等[4]在印度2种民间音乐的分类问题上,提取民歌的音色、频谱和节拍作为特征进行分类。卢坚等[5]针对音乐特征进行了综合性的分析,包括音调、响度、谐度等感觉特征与梅尔频率倒谱系数等,并考察这些特征在分类中的性能表现。张一彬等[6]使用音频处理技术,提取了戏曲数据的短时能量、过零率和谱通量等构建特征向量。在众多关于音乐分类的研究中,支持向量机SVM(Support Vector Machine)是被使用最多的分类算法。Sujeet等[4]、张一彬等[6]、Agostini等[7]以及刘怡等[8]分别在民间音乐、戏曲、乐器和民歌的分类研究中都使用了SVM分类算法,但是他们都是使用经典的SVM算法,并没有对SVM的参数进行优化。
基于以上分析,以往民歌分类研究中还存在数据集不完整、音频特征单一以及分类方法的参数未进行优化等问题,这使得最终的分类效果不理想。因此,本文提出基于距离排序的DUPSO-DSVM(Dissipative Uniform Particle Swarm Optimization—Distance sorted Support Vector Machine)算法,对SVM的核心参数以及参数训练时间进行优化,并针对民歌分类问题中的民歌数据集创建及数据预处理、民歌特征参数提取和民歌分类方法展开研究。
2 民歌数据集的构建和预处理
数据的搜集和数据集的创建为分类研究提供原材料,分类器的训练常常对数据资源数量的要求比较高。互联网上针对中国民歌分类问题的相关研究比较少,也很难找到合适的公开民歌数据集。本文的民歌数据集由作者构建,选择广东、广西、贵州、湖南、江西、内蒙古、青海、陕北、四川和西藏共10个地域的民歌构建分类实验的数据集。
MP3格式的音乐文件采样率和精度都比较高,然而较高的音频采样率会使得特征提取的开销过大,而且每个音乐文件含有许多无关的标签信息,这些无关信息会干扰到实验结果。因此,在实验之前,要对音频数据的采样频率、声道数、采样精度等进行格式转换。数据集预处理的过程如图1所示。

Figure 1 Preprocessing of the dataset
数据集的预处理过程是:首先将民歌文件进行无关标签的删除;然后对民歌文件进行30 s切分保存,为了保持实验结果的有效性,将切分后不足30 s的音频文件删除;最后对音频文件进行文件格式转换。整个民歌数据集共有2 500个音频数据文件,每个地域民歌类型有250个音频文件。
3 民歌特征分析和提取
音频信号研究的首要工作是抽取在分类问题上有区分度的特征系数,一般较为常见的特征系数包括短时参数(短时能量、短时过零率等)、线性预测系数、梅尔频率倒谱系数MFCC(Mel-scale Frequency Cepstral Coefficient)和线性预测倒谱系数LPCC(Linear Predictive Cepstral Coefficient)等[9],其中MFCC和LPCC特征系数更加符合听觉规律和发声原理。
(1)MFCC。
MFCC在语音信号研究中是一种常见的特征函数。由于人的听觉在不同频率信号上的敏感度差异明显,所以当2个响度不同的信号同时通过人耳时,响度较低的成分会受到较高响度信号的影响而使人不易察觉,这就是掩蔽效应[10]。因此,要对音频的高频到低频部分进行滤波,得到语音的输入特征,这样的特征符合听觉模型的特点,又对信号没有过多的限制和假设[11]。实际频率f与其梅尔频率Mel(f)的关系如式(1)所示:
Mel(f)=2595 lg(1+f/700)
(1)
由于音频信号的非稳态特性,在对其进行研究分析时不能够直接应用到识别系统中,应该先经过预处理进行加工。以一段陕北民歌为例,MFCC的提取步骤如图2所示。

Figure 2 Process of MFCC extraction
(2)LPCC。
线性预测倒谱系数LPCC是线性预测系数的倒谱域表现形式[12],它基于发声原理,能够很好地描述元音,但是较难描述辅音且不易抗噪[13]。LPCC参数是根据全极点模式对线性预测系数LPC(Linear Prediction Coefficient)递推而得到的,递推公式如式(2)所示:
(2)
其中,c1,…,cn表示n个LPCC特征系数,a1,…,ap表示p个LPC特征系数。
(3)短时平均能量。
语音信号的能量不是一直稳定的,它会随着时间的改变而变化,尤其是清、浊音之间的能量明显不一样[14],所以分析短时平均能量可以描述语音的能量特征变化。一段音频信号在某时刻的短时平均能量定义如式(3)所示:
(3)
其中,x(m)表示语音信号,w(n1)表示加窗函数,一般选择矩形窗或汉明窗,N表示窗长。短时平均能量不仅能够作为区分清音和浊音的特征参数,也能够作为辅助的特征参数用于语音识别。
(4)短时平均过零率。
音频信号的过零率是语音信号每一帧采样点的值正、负变化的频数,能够度量信号频率,直观形象地反映出语音中的噪音信息[15]。一般情况下,音乐的过零率比语音信号的过零率高。假设语音信号x(n2)分帧后有yi(n2),L表示帧长,则短时平均过零率的定义如式(4)所示:
1≤i≤fn
(4)
其中,fn表示分帧后的总帧数,sgn[·]表示符号函数,如式(5)所示:
(5)
4 民歌快速分类算法DUPSO-DSVM
DUPSO算法在搜寻最优参数时会出现训练时间过长的问题,本文提出民歌快速分类算法DUPSO-DSVM,通过对支持向量进行预选取来减少训练样本,以此优化参数的训练时间。
4.1 支持向量机
SVM在处理非线性回归、模式识别和分类等问题方面应用广泛,它的基本原理是统计学习理论[16]。C-SVC(C-Support Vector Classification)算法是较为常见的二分类支持向量机算法,其中C表示惩罚系数,其建立过程如下:
(1)设数据的训练集为式(6):
T={(x1,y1),…,(xi1,yi1)…,
(xl,yl)}∈(X×Y)l
(6)
其中,xi1∈X=Rn,yi1∈Y={-1,1},i1=1,2,…,l,xi1表示特征向量,yi1表示类别标签。
(2)选择合适的核函数K(xi1,xj1)和惩罚系数C,建立如式(7)所示的模型:
(7)
K(xi1,xj1)=exp(-g‖xi1-xj1‖2)
(8)

(9)
(4)构造决策函数如式(10)所示:
(10)
因此,当SVM选择径向基核函数完成民歌的分类任务时,民歌的分类正确率往往会受到惩罚系数C和核函数参数g的影响,所以本文选择使用DUPSO算法优化SVM的参数,以此取得更好的民歌分类效果。
4.2 基于距离排序的支持向量预选取算法
支持向量往往存在于2类样本的相邻边界区域,所以本文将利用2类样本的距离排序对边界向量进行选择,以此达到支持向量预选取的目的[17]。基于距离排序的支持向量预选取算法的步骤如下所示:
步骤1假设有待分类的陕北民歌和四川民歌数据样本,提取它们的40维MFCC、12维LPCC、1维短时平均能量参数以及1维短时平均过零率参数构成54维特征向量,再加上1维的民歌类别标签组成集合T:
T={(x1,1,x1,2,…,x1,54,y1),…,
(xN,1,xN,2,…,xN,54,yN)}
按照7∶3的比例将数据集划分成训练集和测试集,将民歌的训练集按照标签分成2类,即:

步骤2根据式(10)计算出2类民歌的特征向量构成的训练样本的距离矩阵,如式(11)所示:
d(xii,xji)=
(11)
其中,K(xii,xji)表示核函数,用于将非线性可分的民歌样本映射到高维空间,使得样本线性可分,选择径向基核函数,其表达式如式(12)所示:
(12)
其中,σ表示函数的宽度参数,用以控制函数的径向作用范围。
步骤3对距离矩阵中的每个元素按照从小到大的顺序排序,在排序的过程中元素关联的民歌样本点不能重复,即每个民歌样本点在排序中只出现1次。
步骤4在排好的序列中抽取一定比例的前z个元素所关联的2z个民歌样本点作为训练样本进行训练。
4.3 基于距离排序的DUPSO-DSVM的民歌快速分类
粒子群优化PSO(Particle Swarm Optimization)算法的思想最初是来自对鸟类捕食行为的讨论[18]。虽然PSO算法的效率比遗传算法等的效率高,但是它的缺点是容易陷入极值。PSO算法的基本思想是在多维空间中移动一组粒子,以在复杂空间中搜索粒子位置的最优解。它的粒子速度Vid(t)和位置Xid(t)的更新公式分别如式(13)和式(14)所示:
Vid(t+1)=ωVid(t)+c′1r1[Pid(t)-Xid(t)]+
c′2r2[Pgd(t)-Xid(t)]
(13)
Xid(t+1)=Xid(t)+Vid(t+1)
(14)
其中,id表示粒子的序号,c′1和c′2表示学习系数,r1和r2表示0~1的随机值,ω表示惯性权重,t表示当前的迭代次数,Pid(t)表示粒子当前的个体最优值,Pgd(t)表示种群当前的全局最优值。
均匀动态粒子群优化UPSO(Uniform Search Particle Swarm Optimization)算法[19]在优化函数特别是非均匀多峰函数时具有更快的收敛速度和更优的算法稳定性。耗散粒子群优化DPSO(Dissipative Particle Swarm Optimization)算法[20]在PSO算法中引入一个排斥的过程,根据某种确定的概率,重新定位粒子的位置和速度,能够提升种群中粒子的多样性,从而防止粒子过早成熟。
由于实验中的粒子极值通常是非均匀的,所以在UPSO算法的基础上引入DPSO算法的排斥过程,形成耗散均匀搜索粒子群优化DUPSO(Dissipative Uniform Particle Swarm Optimization)算法[21],可以解决预测参数的全局优化问题。但是,DUPSO算法在进行参数优化时,训练数据量过大会导致训练时间较长的问题。
DUPSO算法对于粒子位置和速度的更新原理,不仅可以为提升种群的多样性做出更有利的贡献,而且还能够使种群中粒子的分布更加均匀[22]。本文将DUPSO算法与DSVM算法进行结合,对SVM中的2个参数C和g以及算法的训练时间进行优化。优化算法的流程图如图3所示,算法具体的步骤如下:

Figure 3 Flow chart of folk songs fast classification using DUPSO-DSVM
步骤1首先将提取到的40维MFCC、12维LPCC、1维短时平均能量参数以及1维短时平均过零率参数构成的54维特征向量进行预处理和归一化。
步骤2使用DSVM算法对10类民歌按照一对余的分类方法进行支持向量的预选取。首先根据式(10)的样本距离计算规则计算出2类样本的距离矩阵,然后对距离矩阵进行排序,在排序过程中距离矩阵元素关联的每个民歌样本点只能出现1次,在排好的序列中按照57%的比例选择前z个元素所关联的2z个民歌样本组成训练集。
步骤3初始化支持向量机的参数C和g,选择径向基核函数作为DSVM算法的核函数,建立DSVM算法民歌分类模型。
步骤4对种群中每个粒子的初始位置Xid(0)和初始速度Vid(0)进行随机初始化,然后计算出各个粒子的适应度F(Xid(0)),并且令第id个粒子的当前最优值Pid(0)=Xid(0),将使得F(Xid(0))的值最小的粒子位置Xid(0)作为种群的全局最优值。
步骤5根据DUPSO算法的更新规则式(14)和式(15)对粒子个体的位置Xid(t)和速度Vid(t)进行更新:
Vid(t+1)=ωVid(t)+
c[rPid(t)+(1-r)Pgd(t)-Xid(t)]
(15)
其中,c表示学习系数,r表示0~1的随机值,ω表示惯性权重,t表示当前的迭代次数。
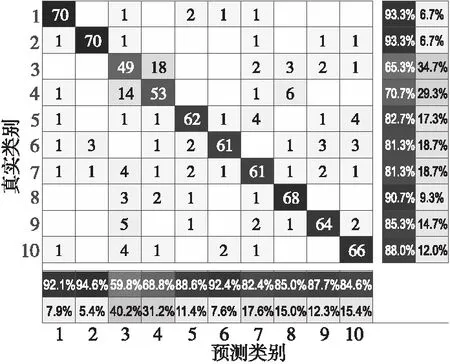
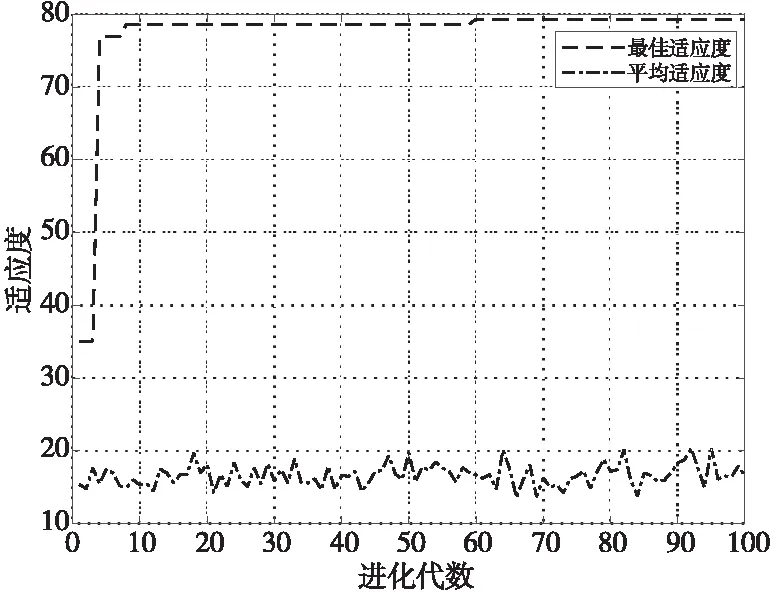
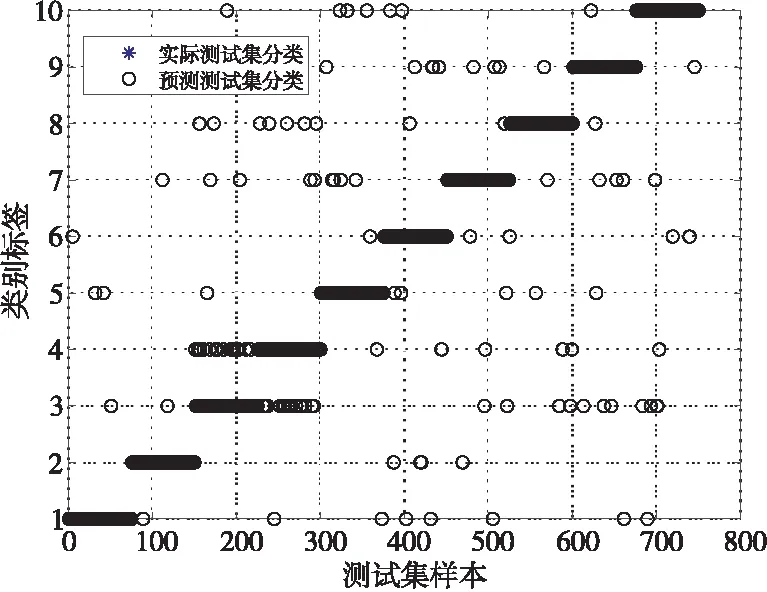
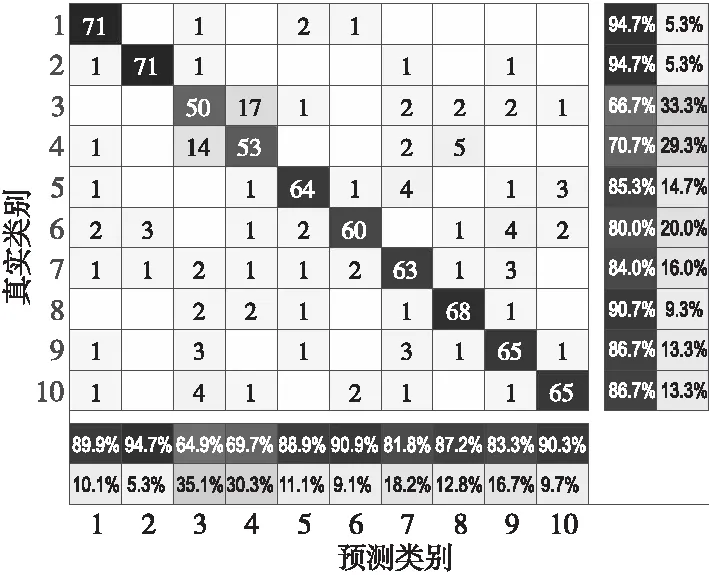
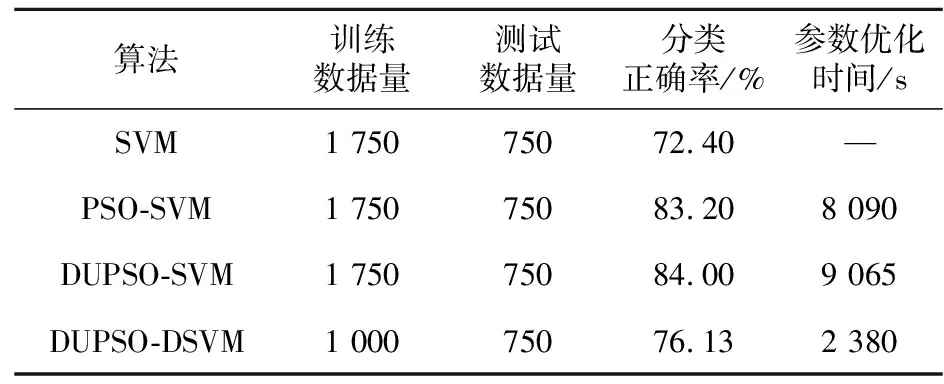
步骤6获取粒子的个体最优值Pid(t)和种群的全局最优值Pgd(t),并计算当前时刻粒子的适应度值。若F(Xid(t)) 步骤7若训练达到迭代次数,则将利用DUPSO算法求得的最优参数值C和g代入DSVM算法,在10个地域的民歌测试集上进行分类预测,否则返回步骤5继续进行迭代。 商家回应:您反馈的食材问题小店非常重视,小店选用食材都是当天采购,绝对新鲜的。这个问题希望您可以和小店取得联系,将事情核实。一定给您满意的结果。 为了验证DUPSO-DSVM民歌分类算法的有效性,本节针对不同的语音特征和分类方法进行研究和比较,以确定出适用于中国地域民歌的最佳分类方法。实验硬件平台为Intel®CoreTMi7处理器,主频为2.9 GHz,内存为16 GB,在Windows操作系统上运行Matlab R2019a。 实验首先提取广东、广西、贵州、湖南、江西、内蒙古、青海、陕北、四川和西藏10个地域民歌的40维MFCC、12维LPCC、1维短时平均能量和1维短时平均过零率参数共54维特征作为特征向量。整个民歌数据集共有2 500个样本,每种民歌包含250个样本,每个样本数据为55维,前54维是音频特征,最后1维为DSVM算法的分类标签,1~10分别代表10个不同地域的民歌类型,将民歌的特征向量按照7∶3随机分成训练集和测试集。 Table 1 Classification results of folk songs of algorithms using different characteristics 图4~图7分别展示了以广东、广西、贵州、陕北和四川5个地域民歌的MFCC、LPCC、短时平均能量和短时平均过零率特征参数值。 Figure 4 MFCC values of ten regional folk songs 对连续的语音信号经过预加重、分帧加窗、快速傅里叶变换等一系列处理操作后得到5个地域民歌的MFCC参数。由图4可以看出,同一地域民歌中MFCC在每一帧信号中的幅值都不一样。从整体来看,5个不同地域民歌的幅值变化情况更是大不相同。 语音特征系数LPCC能够很好地描述人的发声原理,在民歌分类问题上,具有很好的鲁棒性。由图5可以看出,广东民歌的LPCC参数比较集中,而四川民歌的则表现得较为离散。 Figure 5 LPCC values of ten regional folk songs 对5个不同地域的民歌进行分帧,计算出每一帧的短时平均能量,将分帧后每一帧的时间计算出来,绘制出民歌的短时平均能量图。由图6可以看出,广东民歌的短时平均能量变化较为突出,而陕北民歌的短时平均能量变化则不太明显。 Figure 6 Short-term average energy values of ten regional folk songs 连续语音信号中过零意味着信号在时域的波形通过时间轴,因为高频率意味着较高的短时平均过零率,低频意味着较低的短时平均过零率,可以认为清、浊音和短时平均过零率的高低有关。所以,通过对图7中不同地域民歌短时平均过零率进行分析,能够区分出不同地域民歌中的清音和浊音。 Figure 7 Short-term zero-crossing rates of ten regional folk songs 将MFCC、LPCC、短时平均能量和短时平均过零率这4种特征分别进行组合,选择支持向量机作为分类算法,进行10个地域民歌的分类实验,通过仿真结果得到每一种特征组合下的民歌分类正确率,组合情况如表1所示。 机器学习领域的分类算法很多。为了选择出最适合解决民歌分类问题的分类器,本节根据提取的40维MFCC、12维LPCC、1维短时平均能量以及1维短时平均过零率参数,共54维参数组成的特征向量,分别使用支持向量机、K近邻分类器、朴素贝叶斯分类器、决策树分类器和BP神经网络在民歌数据集上进行仿真实验。图8为民歌分类算法的基本步骤。 Figure 8 Process of folk songs classification algorithms 根据式(16),可以得到上述5种分类器在民歌数据集上的分类正确率,如表2所示。 Table 2 Classification results of folk songs with different classification algorithms (16) 从表2可以看出,SVM的分类预测率为72.4%,而决策树的正确率最低,这表明SVM在民歌分类问题中是一种非常有效的分类器。 5.3.1 PSO-SVM分类算法的仿真结果 采用PSO算法进行SVM参数优化时,初始种群设置为20,迭代次数为100,学习因子c′1=1.5,c′2=1.7。实验得到的适应度曲线、民歌测试集的分类预测结果、预测偏差和混淆矩阵等结果如图9~图12所示。 Figure 9 Fitness curve of PSO-SVM algorithm 图9适应度曲线表明,在训练过程中粒子的最佳正确率达到了78.69%,此时惩罚因子C和核函数参数g的最优值分别为74.56和3.13。图10中测试集的样本数目为750,通过预测分类和实际分类的比较结果可以得出最终测试集的分类正确率达到了83.2%,相比优化前的72.4%提高了10.8%。 Figure 10 Actual and prediction classification plots of PSO-SVM algorithm on test set 图11的预测偏差表明,实验的分类结果达到了不错的效果。图12混淆矩阵的每一个矩阵元素Xa,b表示的是实际类别为a预测类别为b的民歌数量。显然,混淆矩阵的对角线元素就代表预测准确的民歌数量,由混淆矩阵可以看出类别1和类别2的分类正确率最高,即广东民歌和广西民歌的分类正确率最好。 Figure 11 Prediction bias plot of PSO-SVM algorithm on test set Figure 12 Confusion matrix of PSO-SVM algorithm 5.3.2 DUPSO-SVM分类算法的仿真结果 采用DUPSO算法优化SVM参数并进行民歌分类得到的适应度曲线、民歌测试集的分类预测结果和混淆矩阵结果如图13~图15所示。 Figure 13 Fitness curve of DUPSO-SVM algorithm 本节对民歌分类算法DUPSO-SVM在民歌分类问题上的有效性进行验证,对10个地域风格的民歌进行分类实验。图13适应度曲线表明,在训练过程中粒子的最佳正确率达到了79.49%,此时惩罚因子C和核函数参数g的最优值分别为94.59和2.26。图14表明,测试集的分类正确率达到了84%,相比标准PSO算法的83.2%提高了0.8%。图15混淆矩阵表明了每一种地域风格的民歌的分类正确率,可以看出广东民歌和广西民歌的分类正确率最高,均为94.7%。 Figure 14 Prediction bias plot of DUPSO-SVM algorithm on test set Figure 15 Confusion matrix of DUPSO-SVM algorithm 5.3.3 DUPSO-DSVM分类算法的仿真结果 保持测试集不变,本节对训练集中的数据利用DSVM算法进行支持向量预选取,选择1 000个样本组成训练集,利用DUPSO-DSVM算法进行样本训练,得到的实验结果如表3所示。 Table 3 Experimental results of DUPSO-DSVM algorithm 从表3可以看出,DUPSO-SVM算法相对于PSO-SVM算法的分类正确率提高了0.8%,但是训练时间也增加了975 s。在经过支持向量预选取算法的优化之后,训练数据由1 750个样本减少为1 000个训练样本,DUPSO-SVM的参数优化时间为9 065 s,而DUPSO-DSVM算法参数优化时间为2 380 s,其优化时间只占DUPSO-SVM算法优化时长的26.26%。DUPSO-DSVM算法大大缩短了参数的优化时间,但仍保持着较高的分类正确率,相对于仅使用SVM进行分类的分类正确率提高了3.73%。 本文基于DUPSO-DSVM算法对中国民歌的分类问题进行研究。首先,收集了10个不同地域共2 500条民歌数据资源,创建数据集并进行数据预处理;然后,对民歌进行特征分析提取,确定了将40维MFCC、12维LPCC、1维短时平均能量和1维短时平均过零率参数共54维特征作为特征向量;最后,使用本文提出的基于距离排序的DUPSO-DSVM快速分类算法与5种经典的分类算法进行比较。实验结果表明,DUPSO-SVM算法使得民歌的分类正确率最终达到了84%;DUSPO-DSVM算法使得参数训练时间只占优化前时间的26.26%,在民歌快速分类方面取得了良好的效果。5 仿真实验

5.1 音频特征对比
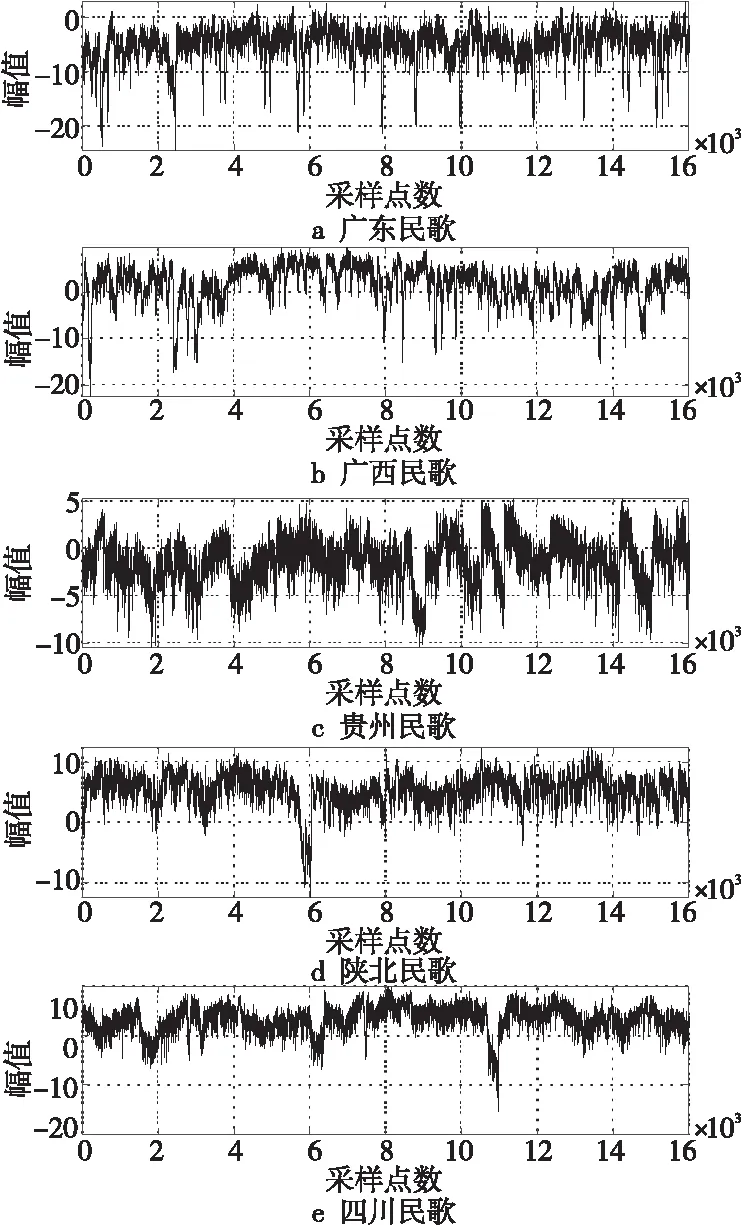



5.2 分类算法对比


5.3 DUPSO-DSVM快速分类算法分析



6 结束语
猜你喜欢
中华养生保健(2020年7期)2020-11-16
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
散文诗(2017年19期)2018-01-31
西江月(2017年4期)2017-11-22
岷峨诗稿(2017年4期)2017-04-20
电子制作(2017年9期)2017-04-17
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
