
基于动态规划和流形排序的知识库问答未登录词处理
2023-11-02 12:34何儒汉万方名胡新荣刘军平
计算机应用与软件 2023年10期
何儒汉 万方名 胡新荣 刘军平
1(武汉纺织大学数学与计算机学院 湖北 武汉 430200)
2(武汉纺织大学湖北省服装信息化工程技术研究中心 湖北 武汉 430200)
0 引 言
近年来,随着人工智能领域的高速发展,知识图谱成为了计算机科学领域的研究热点。知识图谱通过资源描述框架,高效地组织非结构化语料中的结构化信息,其特点是数据均以三元组的形式保存。比较成熟的英文知识图谱有Freebase[1]、DBpedia[2]和YAGO[3]等,中文知识图谱有Zhishi.me[4]、CN-DBpedia[5]等。知识谱图被广泛应用于工业界,例如,知识库问答(KBQA)是知识图谱结合自然语言处理技术,实现自动问答的任务,该任务通过自然语言处理技术获取问句的语义信息,结合实体检测、识别和关系抽取,最后在知识库中检索,得到最终答案。
目前知识库问答研究方法主要分为两条路线。第一条路线旨在围绕通过语义解析寻找一种中间表达,再将其转化为查询语句如SPARQL在知识库搜索实体得到最终答案[6-7];第二种思路去除了这种中间表达,致力于使用深度学习的方法直接进行问句与三元组的匹配,这种方法是近几年比较常见的做法[8-11]。而这类KBQA方法大多基于APA(Alignment-Prediction-Answering)框架。该框架把问答任务分解为实体识别、实体链指、关系检测等子任务,每个子任务负责独立的任务,但在现有的这两种思路中,都没有考虑到未登录词(Out-Of-Vocabulary,OOV)。
现有的智能问答工作大多基于一个叫作Glove的词向量库[12],这是一个由40 000个长度为300的向量组成的词表,每个单词对应一个向量,在进行实体链接等流程之前需要将问题和关系中的单词转化为对应的向量,但因词表大小限制等原因,在词库中匹配不到的词就是未登录词。根据检测,现在常见的KBQA系统中未登录词的比例高达38%以上[10,13]。
目前针对未登录词的研究主要有基于规则的方法和基于统计的方法。基于规则的方法综合未登录词的词性、前缀词素以及后缀词素等信息来为未登录词分配最可能的标签[14],这种方法的准确率一般较低;基于统计的方法是统计大量语料中的未登录词并将其表示放入一个词表中,然后在其他语料中遇到该词就使用这些未登录词在词表中的表示[15],这种方法的缺点是时间成本高,并且还是解决不了层出不穷的新词;在其他领域如机器翻译还有使用同义词来代替未登录词等方法,但这些方法都没有解决建表成本高等问题。
未登录词很难完全避免,原因有两点:① 命名实体包含重要信息,但很多命名实体也是低频词,通常不能包含在词汇表中;② 网络新词层出不穷,旧词表无法及时更新,特别是在当前模型越来越大的情况下,添加新单词后对模型再次训练的成本非常高昂。为了解决上述问题,本文提出了一种基于动态规划和流形排序的问答模型DPQA(Dynamic Programming-based Question Answering),首先在维基百科上抓取了大量英文文本并对其进行分析得到126 136个单词,通过词语出现的频次进行排序,然后根据奇夫定律对其生成一个代价词典,根据代价词典使用动态规划的方法找到最优子串序列,最后使用一种简易但有效的基于流形排序的重排序算法[16]定位最终子串,使用子串表示代替关系和问句中的随机向量。通过实验验证了DPQA在多个问答数据集上均具有良好的表现,在单关系数据集上效果尤为突出,进一步提升了知识库问答任务的准确度。
1 DPQA模型
1.1 任务定义
本文提出的方法基于英文知识库Freebase[1],对其实体和关系进行匹配搜索。Freebase知识库中每个条目通过(subject,relation,object)的形式表示。SimpleQuestion和WebQuestion分别为Facebook公司公开的单关系与多关系的知识库问答数据集,其中的数据均为人工标注,并且数据集中的每个问句与Freebase知识库中的一个条目相对应。
给定一个问题,它的实体和关系在知识库中,问题、关系使用Glove词向量库表示,词表中没有的单词即未登录词使用随机向量表示。知识库问答模型的目标是找到连接主题实体和知识库中指向答案的关系。对于候选关系集中的每个关系,模型计算与问题的语义相似度,并选择得分最高的关系路径作为答案路径[13]。
1.2 单元定义
本文对模型中会用到的单元有如下定义:
(1) 问题集定义为Q={q1,q2,…,qq_n},其中每个单元qi(i∈{1,2,…,q_n})都是问题集中的一个问题,q_n为问题集中所有问题的数量。
(2) 关系集R={r1,r2,…,rr_n},其中每个单元r都是关系集中的一个关系,r_n为关系集中所有关系的数量行。
1.3 模型结构
该方法主要解决知识库问答中的未登录词问题,模型中实体检测部分结合了[10,13,17]的注意力机制模块(撰写本文时准确率最高的模型)和MOYU的BiLSTM模块[10]。引入未登录词处理模块后模型如图1所示。

图1 加入了未登录词模块的知识库问答模型
2 未登录词检测层
本节描述DPQA的未登录词检测层,该层由三个部分组成,结构如图2所示。
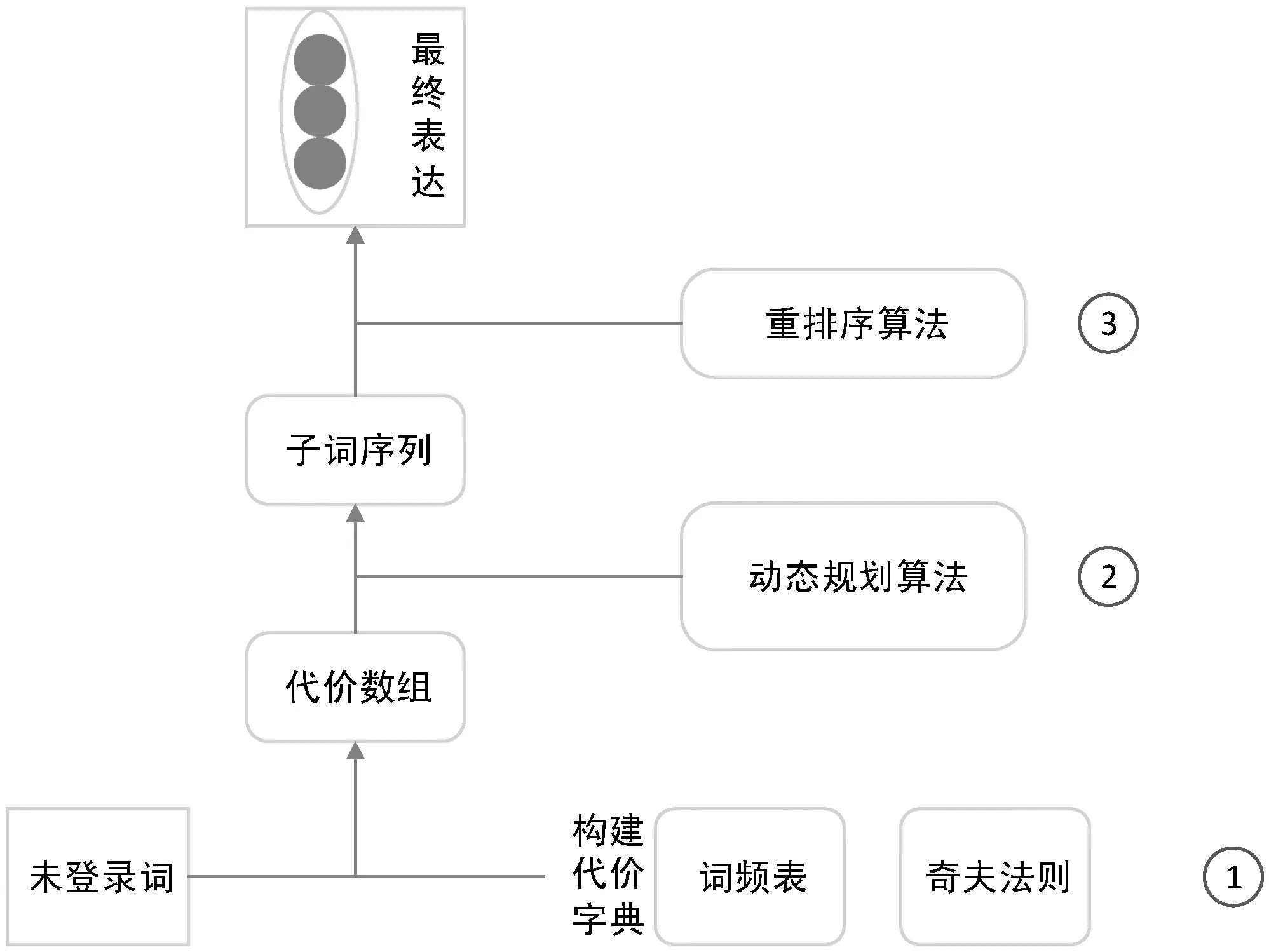
图2 未登录词检测模块
2.1 构建代价词典
本文利用奇夫定律(Zipf’s law)为词表构建代价词典。其思想是在自然语言文本集中,单词出现的频率与该文本集中所有单词的频率排名成反比,定律具体为频率排名第一的单词出现的频率大约是排名第二位单词的两倍,而排名第二位的单词则是出现排名第四单词的两倍,其公式为:
(1)
式中:P(r)表示排名为r的单词频率;r表示一个单词出现频率的排名,单词频率分布中C约等于0.1,α约等于1。
本文在维基百科上爬取大量英文语料并做了清洗与分析,得到一个长度为126 136的词表,并根据词频进行排序,词表如表1所示。

表1 维基百科词频分布
根据奇夫定律与词表,构建了代价词典。首先有词表W={w1,w2,…,wn},n为词表的长度,wi是词表W中的词频排第i位的词,则有:
Costi=log((i+1)×log(n))
(2)
代价词典Cost={Cost1,Cost2,…,Cost126136},部分数据如表2所示。

表2 代价词典
2.2 动态规划
生成代价词典后,本文使用动态规划的方法为未登录词生成子词序列。以未登录词“whitecoffee”为例。
首先计算该词的代价数组C_array,置代价数组第一位C_array[0]为0,然后计算第一个字符“w”的代价,并与该字符所有可能的字符串的代价相比较,取最小的放入代价数组,例如“w”只有一种情况,所以C_array[1]为Cost[w]=9.227 322 4,第二个字符“h”的代价因为有两个字符串的情况“w”+“h”和“wh”,Cost[w]+Cost[h]=9.227 322 4+8.786 002 7=18.013 325 1,而Cost[wh]=13.096 018 351,取其中最小值13.096 018 351,以此类推可得到未登录词“whitecoffee”的代价数组:[[0,9.227 322 400 521 313,13.096 018 351 828 421,19.670 329 707 960 61,13.599 631 067 643 815,8.262 530 146 419 405,15.902 117 370 952 112,17.530 582 158 440 907,19.058 702 043 470 937,24.217 757 342 685 466,29.297 030 357 217 277,18.529 402 695 330 45]]。
然后回溯恢复代价最低的字符串,可获得“whitecoffee”的C_space为:[(37.167 639 620 636 27,1),(36.000 389 611 532 61,2),(30.252 829 901 108 456,3),(inf,4),(inf,5),(18.529 402 695 330 45,6),(inf,7),(inf,8),(inf,9),(inf,10),(inf,11)],inf代表词表中无该词,所以代价为无限大,最后取代价最小的值(18.529 402 695 330 45,6)为分隔处,可获得第一个子词“coffee”,以此类推得到最优子词序列[white,coffee]。动态规划的流程如图3所示。
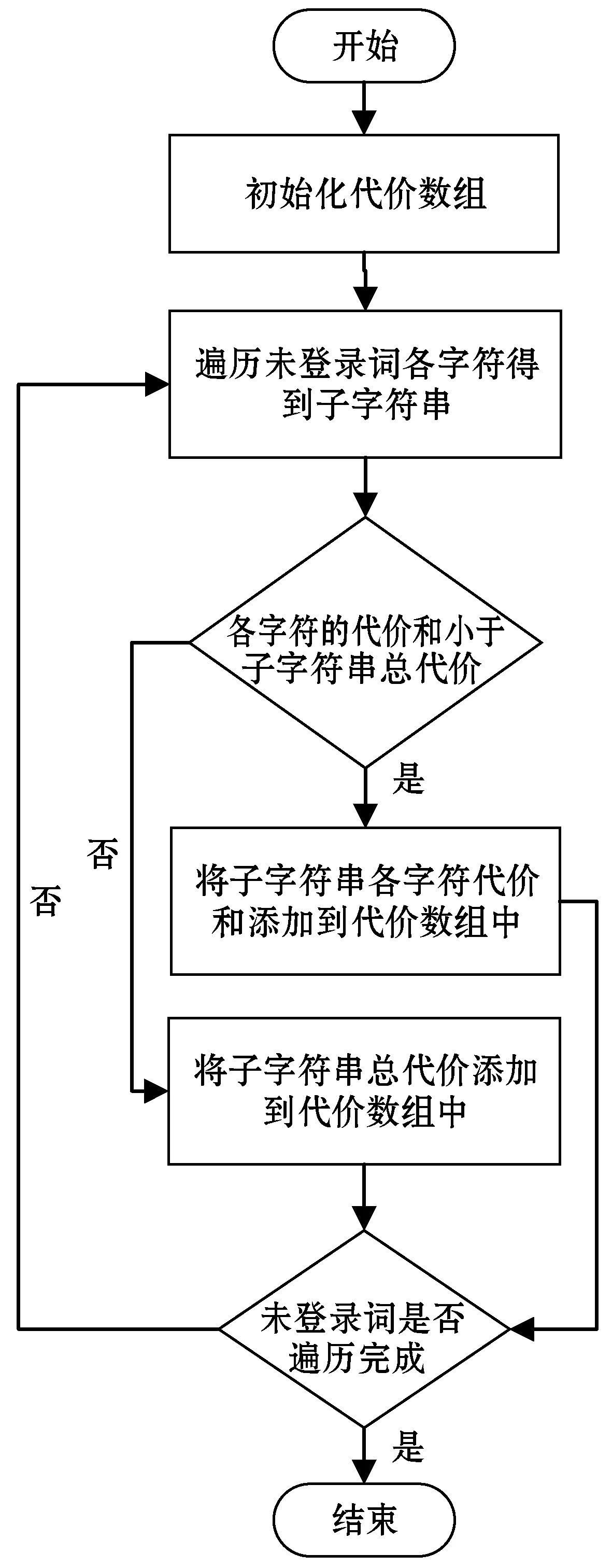
图3 动态规划流程
2.3 重排序
获取了最优特征词序列后,使用一种基于流行排序方法对特征词进行排序[18]。流形排序[19-20]是一种基于样本数据集的流形分布假设的排序算法,该算法是一个半监督学习的方法,即对于一个图模型,给定一些种子节点,根据节点之间的内在流行结构对每个节点进行排序,得到每个节点的最终排序得分。流形排序方法根据多个语料之间的流形结构对单词之间的相似度进行计算,首先根据语料库的结构,对流行结构图中的各节点做相似度排序。相似性排序的主要思想是对每个节点计算该节点与其他节点的相似度,此过程实质上是一种图学习的过程。流形排序算法用上述过程计算相似度最后进行排序,主要由图初始化及相似度计算与排序两个模块组成。基于流形排序是目前效果较好的特征词排序算法[18-19]。
本文根据流形排序方法,综合考虑统和语义结构两个维度的信息,为多个候选词进行重要度排序。该方法具体步骤,如下所示:
1) 各候选词的重要度基于词频进行初始化。已有研究发现,相比于如IG、CHI等传统监督学习方法,词频排序的特征词选择方法的效果反而更加突出。本方法根据统计维基百科语料的词频给候选词进行初始化,有:
y=[y1,y2,…,yn]
(3)
式中:yi表示语料c中第i个单词在c中的词频;n表示语料中所有单词的数量。
2) 本方法通过结合语料中候选词的语义信息与位置信息构建语料网络图G=(V,E),其中V表示语料d的单词列表,其中每个单词表示语料图G中的一个节点v;E表示各个边e的集合,每条边e连接各个节点v,两个节点之间是否存在边取决于以下两点:① 在原语料某一段落中是否有同时出现两个节点对应的特征词的情况出现;② 比较两个节点条件共现度是否超过算法提前设定的阈值。条件共现度矩阵方法是魏伟等[21]于2019年提出的一种词共现表示方法。相比于传统的词共现表示,条件共现度矩阵方法增加了对语料语义粒度信息和事实在相同段落中的相关词表示等因素的考量,也就是它保存了更多的语义结构信息,使得稳定性和效果都得到了比较明显的提升。条件共现度矩阵方法在传统方法的框架上计算候选词相对语料特征空间的条件概率。使用矩阵W=(ccodmij)n×n表示语料c,第i个候选词A与第j个候选词B的条件共现度ccodmij计算方法如下:
(4)
式中:p(B|A)表示候选词A与候选词B的共现概率,p(A)为候选词A在语料c里出现的概率,使用comij表示语料c中第i与第j个单词的共现次数,即:
(5)
式中:S为语料c中的所有段落;fsj为语料中第j个单词在第s个段落中的出现频次;n表示候选词列表的长度。由此可知条件共现度矩阵为不对称矩阵:ccodmij≠ccodmji。此外,设定ccodmij=0。
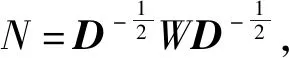
二次排序的本质是转移了语料图结构中候选词的权值。候选词以一定的概率将该词的重要度传递给与该词有边相连的多个候选词。使用词频来为语料中单词重要度进行初始化:y=[y1,y2,…,yn]。后续各候选词权重排序过程为:
f(t+1)=αNf(t)+(1-α)y
(6)
式中:α的值域为[0,1]。候选词列表最初通过词频排序,在之后的每次计算中根据α计算重要度然后传递给邻接的所有单词。根据以上方法不断迭代,直到算法收敛,收敛结果为:
(7)
流形排序算法的优化函数定义为:
(8)
该函数的核心思想是使语料中距离相近的单词相似度更高。μ是算法的正则化参数,其值域为(0,∞)。
算法1基于流形排序的子词排序算法
输入:子词序列、语料词频。
输出:子词重要性排序。
step1计算序列中所有特征词词频,并将词频序列作为特征词初始重要性排序y。
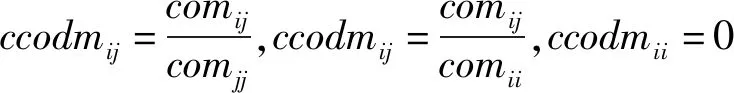
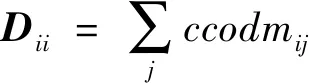
step4结合相似度矩阵N以及在step1中初始化的排序y,根据函数f(t+1)=αNf(t)+(1-α)y不断迭代计算出最终子词重要性排序。
end
3 DPQA实验分析
本节通过实验证明了DPQA模型的稳定性及有效性。首先介绍了本文方法所使用的知识库等数据,然后对评测指标以及算法的实现细节进行阐述,最后对实验结果做进一步的分析与解释。
3.1 数据集与评测指标
本方法使用了Facebook在2016年发布的KBQA数据集SimpleQuestion(单关系,后文中用“SQ”表示),包含75 909条训练数据,108 445条验证数据及216 884条测试数据。在多关系问题上,本文采用了WebQuestion数据集(后文中使用“WQ”表示),WQ包含6 642个问答对。
该方法采用两种方法作为评测指标,第一种是未登录词的比例,即所有的问题与关系中包含的未登录词数量和问题、关系总词数的比值;第二种采用关系检测的准确率。
3.2 实验与结果分析
本文研究对比了通过动态规划和流形排序后得到的词向量与随机向量的向量差异度,具体方法使用的对比两向量的夹角。首先找出在原词向量库中没有但在另一个含有219万个词向量的词向量库glove840中包含的单词OOV,通过本文提出的方法得出最终子词s,取该子词在glove840中的向量Vs与该未登录词(相对于原词向量库)在glove840中的向量Voov做夹角计算,结果如表3所示。
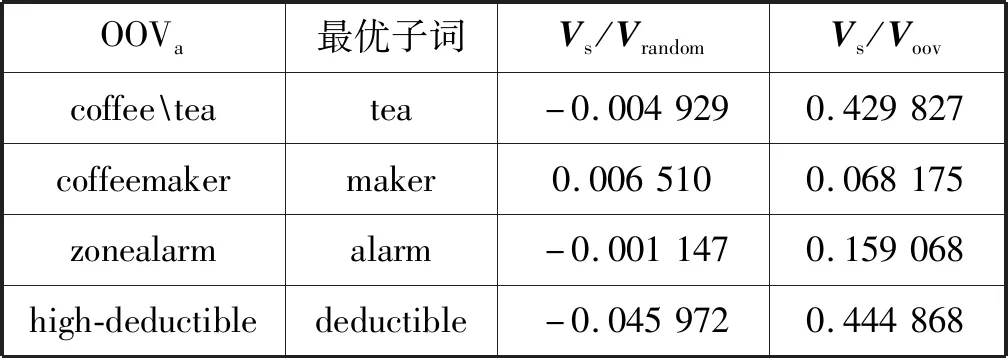
表3 未登录词与其子词的向量夹角对比
可以观察到通过本文研究得出的向量相比之前的随机向量与OOV的相似度更高,获取到了以前模型没有的信息。
如表4所示,本文研究把SQ中的未登录词比例降低了20.4百分点,将WQ中的未登录词比例降低了12.47百分点,可以看出本文研究对未登录词的检测及补齐有很明显的效果。经过分析,DPQA对WQ的未登录词效果没有SQ明显的原因首先是WQ中的未登录词本身较少,其次与两个数据集中的词语分布有关。

表4 SQ和WQ数据集上未登录词比例(%)
最终模型对关系检测的准确率如表5所示,针对单关系数据集DPQA有比较好的提升,达到了93.84%,超过了其他几种比较编码框架的学习方法,证明了DPQA模型良好的建模效果,具体表现为未登录词比例降低了20.4百分点,在不依赖更大词库的情况下大幅减小了未登录词信息丢失对整个模型的影响,其次表现在最终的关系检测中准确率获得了目前最优成绩。在多关系数据集WebQuestion上,DPQA比Bi-LSTM、HR-Bi-LSTM等模型效果都要好,并且训练时间有明显的减少。

表5 关系抽取准确率(%)
3.3 时间性能实验
因为大幅减少未登录词,所以在对单词做向量化的时候可以减少大量无用的稀疏表示,所以DPQA在训练时间上有了不错的优化,相比于用时最少的BiCNN,在相同超参数的情况下,DPQA在SQ和WQ数据集上分别有5.4 s(12.3%)和5.9 s(14.2%)的提升,具体如表6所示。

表6 关系抽取时间 单位:s
根据对实验数据的详细分析,对DPQA的优点有如下总结:(1) DPQA可以在同词库的情况下,显著降低未登录词对整个问答系统的负面影响,最大限度地利用了问题和关系中的信息;(2) 由于未登录词的减少,数据预处理时的稀疏向量随之减少,使模型训练时间大幅下降;(3) 随着社会的进步,在新词层出不穷、未登录词越来越多的情况下,DPQA相比于其他没有未登录词检测层的模型,会具有越来越明显的优势。
4 结 语
近年来的KBQA算法大多集中在关系检测和实体检测上,较少有关注问题与关系中的未登录词问题,所以问答准确率不可避免地会碰到瓶颈。本文为知识库问答领域提出了基于动态规划与流形排序的新方法,为智能问答的解决方案提供了新的思路。通过实验,DPQA在单关系和多关系问答集上都表现良好,特别是在单关系问题上表现突出,为解决通用知识库问答系统中的未登录词问题提供了简单可行的方案。
猜你喜欢
园林科技(2021年3期)2022-01-19
英语世界(2021年13期)2021-01-12
数学物理学报(2020年2期)2020-06-02
数学年刊A辑(中文版)(2019年3期)2019-10-08
数学物理学报(2019年1期)2019-03-21
国家图书馆学刊(2016年2期)2016-10-09
读者·校园版(2015年7期)2015-05-14
振动工程学报(2015年2期)2015-03-01
深圳大学学报(理工版)(2015年5期)2015-02-28
图书馆论坛(2014年8期)2014-03-11
