
基于WebGL的BIM轻量化关键技术研究
2023-11-02 12:33黄丙湖徐帮树张家宝何亚文
计算机应用与软件 2023年10期
黄丙湖 王 涛 徐帮树 张家宝 何亚文
1(中国石油大学(华东)海洋与空间信息学院 山东 青岛 266580)
2(山东大学齐鲁交通学院 山东 济南 250061)
3(山东科技大学土木工程与建筑学院 山东 青岛 266590)
0 引 言
BIM(Building Information Modeling)技术在AECO/FM(Architecture,Engineering,Construction,Operations and Facility Management)行业的广泛运用[1]和Web 3D技术日渐成熟,掀起了一股WebBIM研究与应用热潮。由于BIM中包含建筑全生命周期的几何信息和语义信息,通过BIM服务器,可将信息实时更新和最大范围共享,提高各个运营商之间的沟通效率,减少运营成本。
在WebBIM的研究中,魏国富等[2]基于OBJ与SVG的ID映射,实现模型与平面图纸的二三维联动。Wei[3]通过将Autodesk Forge View、Dynamo与Flux的集成,开发了一款BIM参数化设计系统,允许多人协同设计。Scully等[4]利用3D Repo云服务设计了基于X3DOM的3D BIM版本控制系统。刘小军等[5]提出了一套面向手机网页浏览大规模三维场景的漫游算法。Chen等[6]提出基于Bigtable和MapReduce的分布式系统框架用于存储、浏览和计算大规模BIM数据。
然而BIM有众多的数据源,各数据依赖于软件系统环境而无法直接被WebGL读取和渲染,IFC(Industry Foundation Classes)标准的发布,有助于BIM数据在不同软件平台之间实现共享和交换。在这里,BIM模型可以划分为IFC标准模型和专业软件模型[7],对于这两类模型的数据转换,有众多的学者做了相关研究。Xu等[8-9]利用IFCOpenShell工具实现对IFC数据的提取与格式转换。针对专业软件模型,除了众多软件生产商提供的解决方案如Autodesk Forge View、FME、BimAngle Engine和SimLab等,也同样引起了相关从业者和学者的关注。Jeremy Tammik开源了RvtVa3c项目,对Revit数据的自定义导出具有很好的指导意义。陈志杨等[10]借助Revit API完成BIM属性信息和几何信息的提取。
现今,随着数据量激增,对本已经包含大量信息的BIM数据而言,有限的存储资源和计算能力成为技术发展的瓶颈,BIM轻量化成为关键技术[11-12]。Zhou等[13]基于IFC数据,利用Delaunay三角剖分算法对B-rep(Boundary Representation)模型进行重构并通过实例复用实现BIM轻量化存储。Zhou等[14]提出S-LPM框架,通过对Mesh分割和重复体素去除操作,实现模型轻量化,Liu等[15]将其运用至智慧城市可视化管理中。
综上所述,由于IFC作为一种开放的数据标准,有较多的学者对其进行深入的研究。但由于IFC涉及广泛的应用领域和模型参数化设计给几何数据重构与数据轻量化带来一定的困难。作为商业模型数据,往往有软件厂商提供相应的解决方案和软件接口服务。转换的数据会用于特定的平台,转换的细节对于用户来说是“黑箱操作”。借助IFC、IndoorGML、FBX、OBJ等一些中间数据进行交换会产生一定的数据冗余和数据损失,随着转换链的增长,这些风险发生的概率会增加。本文从应用的角度出发,借鉴RvtVa3c开源项目,通过Revit API,设计RVT转GLB数据的程序接口,实现BIM数据的轻量化存储,在一定意义上减少信息在转换过程中发生丢失的现象。
1 Revit几何信息描述
Revit是一个记录与设计的平台,一份Revit数据中不仅包含模型的几何信息,同时包含设计所需的明细表、设计图纸与二维和三维的视图信息等。在数据提取与转换过程中,首先需要了解Revit坐标系和几何数据结构。
1.1 Revit坐标系
Revit使用三种坐标原点,分别为测量点、项目基点和图形原点。以测量点为原点的坐标系为测量坐标系,用于描述项目基点在真实世界中的位置;以项目基点为原点的坐标系为局部坐标系,用于描述建筑间的相对位置关系;而以图形原点为坐标原点的坐标系为模型坐标系,用于描述三维视图中各个构件的几何位置,原点为(0,0,0)。在三维视图中,族实例可用Transform表示为:
(1)
式中:O为距离图形原点的位移;(a1,a2,a3)T、(b1,b2,b3)T、(c1,c2,c3)T为族实例本地坐标系的坐标轴在模型坐标系中的向量表示。
其次,Revit在三维视图中使用左手坐标系,以屏幕向右为X轴正方向,竖直向上为Z轴正方向,垂直屏幕向里为Y轴正方向;而WebGL多使用右手坐标系,即水平向右为X轴正方向,竖直向上为Y轴正方向,垂直屏幕向外为Z轴正方向,图1表示Revit坐标系转向WebGL右手坐标系的过程,其中当模型需要整体偏移或姿态调整时,可在GLTF的根节点Node中指定偏转矩阵。
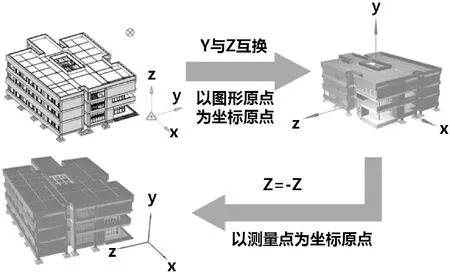
图1 坐标转换
1.2 Revit模型信息组织
Revit建模是基于对象的,族(或称为图元)是一类相同构件的抽象,如单扇窗、双扇窗、百叶窗等,族的参数定义了构件的行为。族类别是对族集合的分类,如窗、柱、墙等,而族类型是对族的细分,它定义了某一族的不同尺寸与材料等。在三维视图中所看到的每个构件,都是某一族类型的实例,对于尺寸大小固定的族类型可以通过Transform矩阵来构建不同位置的构件。
在BIM轻量化中需要获得每个构件的图形信息,如图2所示,每个构件可以由任意一个图形元素构成。在数据转化过程中,需要获取组成这些图形元素的点坐标、索引和法向量等几何信息以及变换矩阵信息。
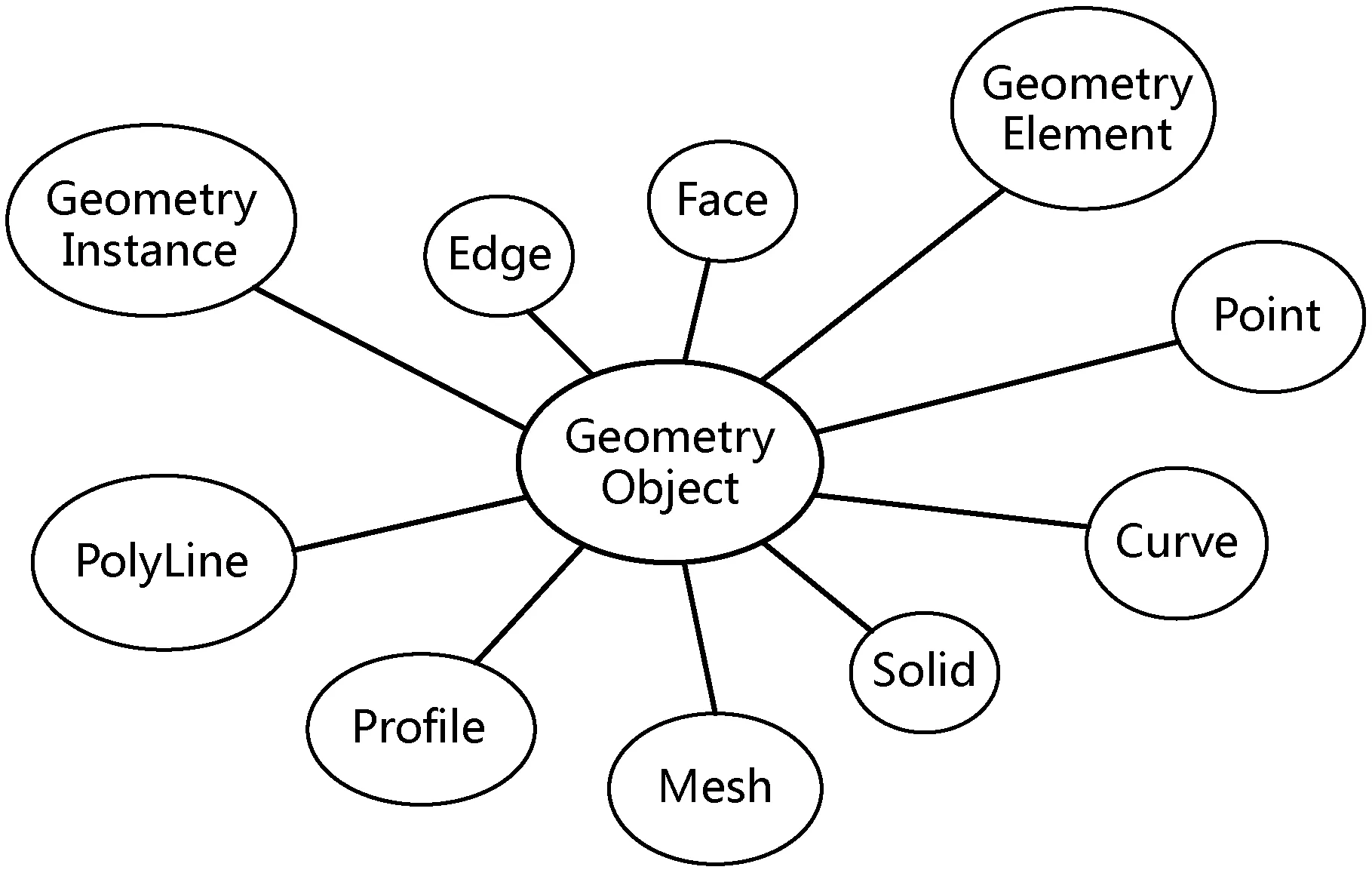
图2 Revit图形元素
2 GLTF信息描述
一个好的数据结构影响着传输、渲染和功能实现。GLTF(GL Transmission Format)作为面向图形实时快速渲染,可扩展的数据传输格式。它因直接传输给图形API,不需要二次转换,格式开源而得到业界的广泛认可。因此本文选用GLB作为BIM模型信息的存储格式。
2.1 GLTF数据结构
通常,一个GLTF文件包含以JSON格式存储的场景信息文件和一个存储几何信息的二进制文件,gltf文件中buffers数组的每个元素通过URI引用bin文件。如图3所示,gltf文件中包含场景、相机、节点树、材料信息、缓冲区信息等,各个键值元素之间通过索引进而描述整个场景需要绘制的信息,bin文件主要包含顶点坐标、顶点索引、法向量、关键帧、绑定姿势的逆矩阵等。而纹理信息可以在gltf中的images元素通过URI引用外部的图片文件,也可以同几何信息一样写入bin文件中或者以base64编码写入gltf的buffers中。
在gltf场景文件中,scene指定scenes数组中需要渲染的node节点,nodes数组中的每个node元素既可以指向一个mesh元素,也可以有子节点。多个node可以指定同一个mesh元素,实现几何数据的复用,减少数据冗余。图4显示从gltf和bin文件中获取信息绘制线段的过程。图中indices和POSITION分别指向顶点索引和顶点坐标的accessor存取器元素,accessor描述从bufferView中获取数据方式和数据类型。同样,两个accessors中的bufferView各自指向bufferViews中对应顶点索引和顶点坐标的bufferView元素,bufferView描述其在整个二进制缓冲区的位置,字节长度以及数据存储的间隔等信息。meshes中mode指示获取数据后的绘制方式,如点、线、三角扇等。其中componentType、type、mode和target属性值均是常量枚举值。
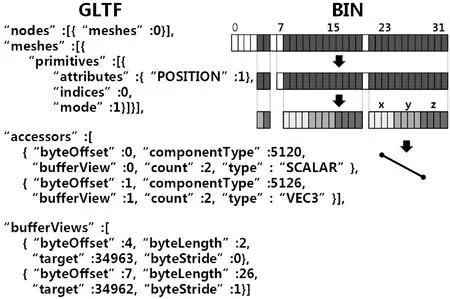
图4 GLTF数据解析
每个node还可以指定该节点的4×4矩阵用于调整姿态,在渲染时,所有的子节点都必须经过父节点矩阵左乘。一般的,node中的矩阵还可以分解为T×R×S,T与S分别表示偏移和缩放,均为32位浮点值类型、长度为3的数组,而R表示四元数旋转,为32位浮点值类型、长度为4的数组。
相比于欧拉变换容易产生万向节死锁问题以及矩阵变换至少需要存储9个参数参与计算,四元数变换只需存储4个参数就可以完成复杂的旋转。令旋转单位四元数q=[w,x,y,z],向量p=[0,vx,vy,vz],则经过q变换后的向量为:
p′=qpq-1
(2)
p′=[wxyz]×[0vxvyvz]×
[w-x-y-z]
(3)
(4)
因此,四元数(右手性)转换成3×3矩阵为:
(5)
根据式(5),可以求得旋转矩阵对应的四元数。
2.2 GLB数据结构
如前所述,通常GLTF文件主要包含gltf和bin文件,就意味着至少要向服务器发送两次Http请求,而将bin数据以base64编码写入gltf文件中则在渲染时需要额外的解码时间。在考虑后期工作需要频繁调度数据,本文最终采用GLB数据格式。
如图5所示,GLB文件是将gltf和bin文件整合在一起以小端字节序存储的二进制文件。它开始包含12字节头,分别为magic、version和length,用于描述文件的GLTF ASCII码、版本信息和整个文件所占的字节长度。Chunk 0与Chunk 1分别为JSON存储区和bin存储区,length和type均占四个字节,用于描述JSON和bin的字节长度与识别JSON和BIN字符的ASCII码。Chunk 0和Chunk 1各存储的字节长度缺省为4的倍数,否则在Chunk 0和Chunk 1后分别用0x20和0x00占位以满足规则。
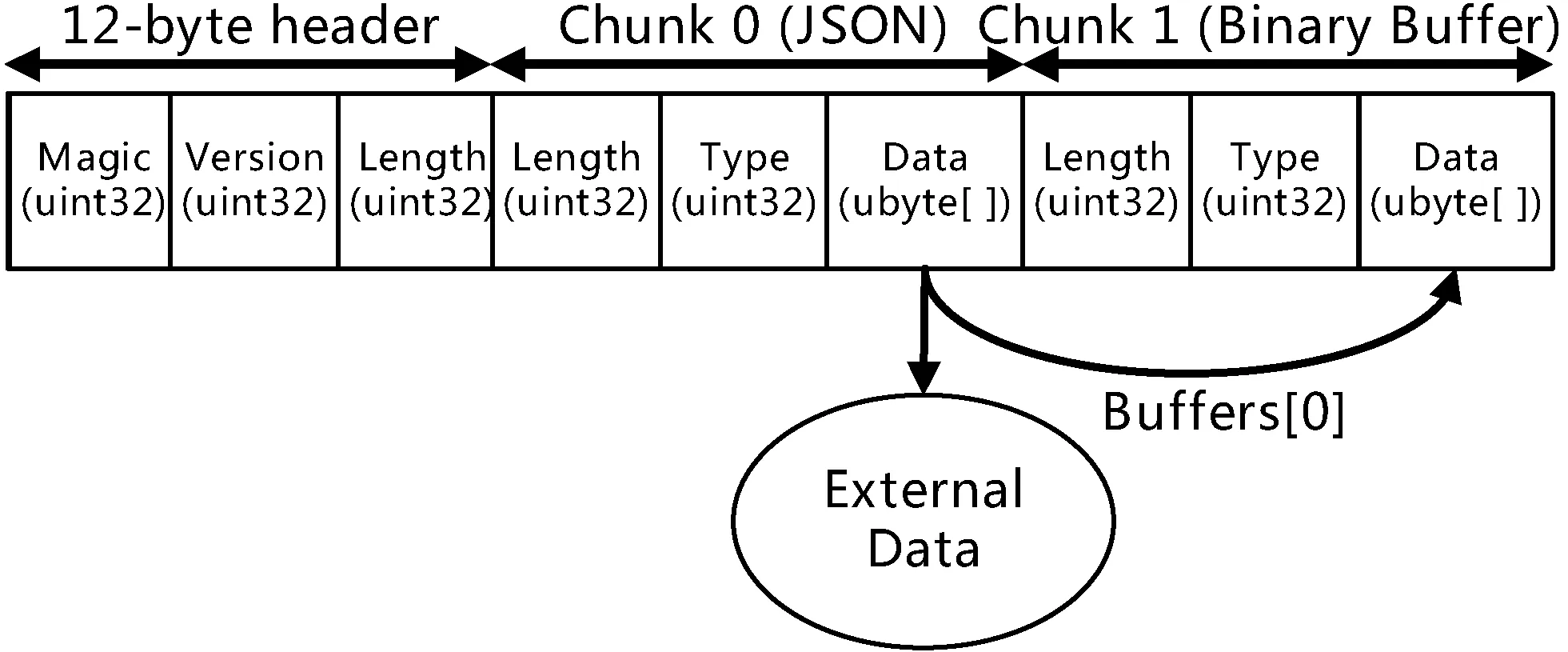
图5 GLB数据结构
2.3 通用GLTF数据转GLB数据
如下所示,为通用的GLTF数据结构,将buffer中的uri属性设置为null,借助Newtonsoft将GLFT对象序列化并压缩成不含空格、换行符的JSON字符串,并将该字符串转换为UTF-8编码的字节数组。根据2.2节GLB的数据结构,用对应的数据类型依次写入0x46546C67、2(GLTF版本为2)、总字节长度值、JSON字节长度值、0x4E4F534A、JSON字节数组、BIN字节长度值、0x003E4942,以及每个BinaryData的几何数据。其中在JSON区与BIN区用0x20和0x00所占位数计入总字节长度和各区的字节长度。
public struct GLTF
{
public Asset asset {get;set;}
public List
public List
public List
public List
public List
public List
public List
public List
public List
public List
}
public struct BinaryData
{
public List
public List
public List
public List
}
3 RVT数据转换
3.1 数据转换
在BIM轻量化的工作中,用于数据转换所设计的功能主要封装在以下几个类中:
GLTF:包含GLTF的数据结构以及常量枚举。
Map
GltfMath:用于坐标转换、四元数、包围盒、最值、向量和矩阵等计算。
GltfCheck:对GLTF数据的检查,剔除不合格数据,维护索引。
GltfExportContext:继承Revit IExportContext接口,实现数据的读取与写入操作。
其中,Revit提供IExportContext接口以支持BIM数据的提取,基本流程如图6所示。通过遍历每个构件,实现坐标、法向量、材质等信息的提取。

图6 IExportContext遍历数据流程
根据接口函数遍历的流程,本文在每个函数中设计了不同的功能:
OnViewBegin:获取并计算模型相对测量点的旋转四元数R和偏移矩阵T并赋给RootNode。
OnElementBegin:创建Node节点,计算构件在三维视图中的包围盒,提取属性信息。
OnInstanceBegin:对含有非Instance的几何信息,创建子节点、Mesh、Accessor、BufferView、Buffer对象,并维护之间的索引关系;实例化Instance子节点,添加父节点对Instance子节点的索引;计算偏转矩阵并将矩阵入栈。
OnMaterial:在几何表面的呈现上,GLTF是基于物理的渲染,即通过金属度和粗糙度来计算表面的反射效果。该函数负责将Revit的材质信息转换为GLTF的材质信息,并提取材料属性;对已存在相同的Material,记录该Material的索引,将赋给要创建的Mesh.Primitive中的Material属性。
OnPolymesh:坐标转换,借助RvtVa3c中的VertexLookupInt类实现顶点去冗。对于存储单个Mesh数据,需要一定的顶点冗余,如图7所示,Face1、Face2、Face3共用v1顶点,但v1点可能对应多个法向量或纹理坐标,因此顶点去冗范围被限制于绘制单个面的几何数据。提取坐标、法向量,并生成在当前Mesh的顶点索引。
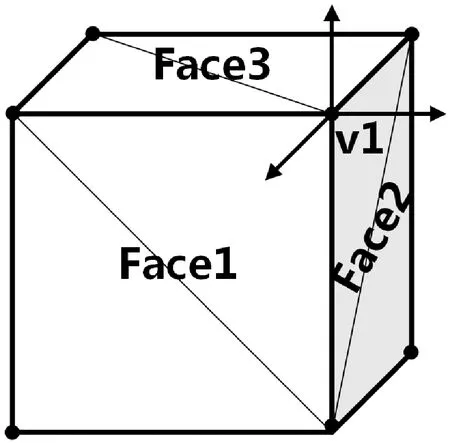
图7 面几何数据去冗
OnInstanceEnd:每个Instance对应一个Mesh,并赋予一个由InstanceNode.NodeName与InstanceNode.getSymbolId().IntegerValue组成的ID。如图8所示,①和②是具有相同ID、不同位置的构件,对已存在相同ID的Mesh,添加Node对Mesh的索引;否则创建Mesh、Accessor、BufferView和Buffer对象,维护之间索引。计算该Instance的四元数R和偏移矩阵T,并赋给Node节点,矩阵出栈。
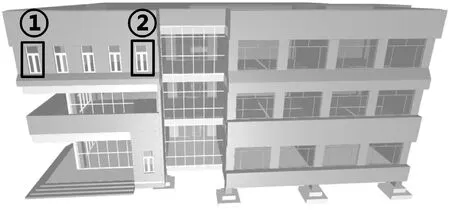
图8 族实例几何数据的复用
另外,族的结构影响数据读取的行为,对于同一个族实例,也可以实现内部几何元素的复用,如图9所示,栏杆构件中包含①实例,①实例嵌套着②和③子实例。

图9 复合族实例
OnElementEnd:对含有非Instance的几何信息,创建子节点、Mesh、Accessor、BufferView和Buffer对象,维护索引。
OnLinkBegin:Revit建模过程中,通常会将项目文件拆分成多个子文件,目的在于方便管理和减少系统运行负担。通过OnLinkBegin函数,将链接文件的坐标系转到当前项目文件的模型坐标系中,切换当前document对象,矩阵入栈,将遍历链接文件中的构件。
OnLinkEnd:矩阵出栈。
Finish:文件写入前进行数据清洗,并检查GLTF中各个属性内部的枚举值、字节统计值、数据类型、字节偏移以及属性内部和属性之间索引的正确性。文件写入时动态分配内存,例如索引一般不会超过两个字节。
3.2 数据清洗
在数据导出过程中,容易产生空节点,造成数据不够整洁、数据量增大的情况,甚至会在读取时发生解析错误。增加条件判断以应对发生空节点的情况往往会因为条件判断不当而导致数据损失,索引错位而难以维护,并且也很难预防各种出现空节点的情况。因此本文不再关注对发生不合格节点情况的判断,而是最后将每个构件所对应的节点从数据集中单独提取出来进行维护。图10所示为从数据集中提取并维护索引的双扇窗节点及其子节点,其中Node1、Node6为空节点,需要被识别和清除。任何一个空节点的清除将会影响其他节点位置的变化、潜在空节点的产生以及节点在父节点中索引的变化。
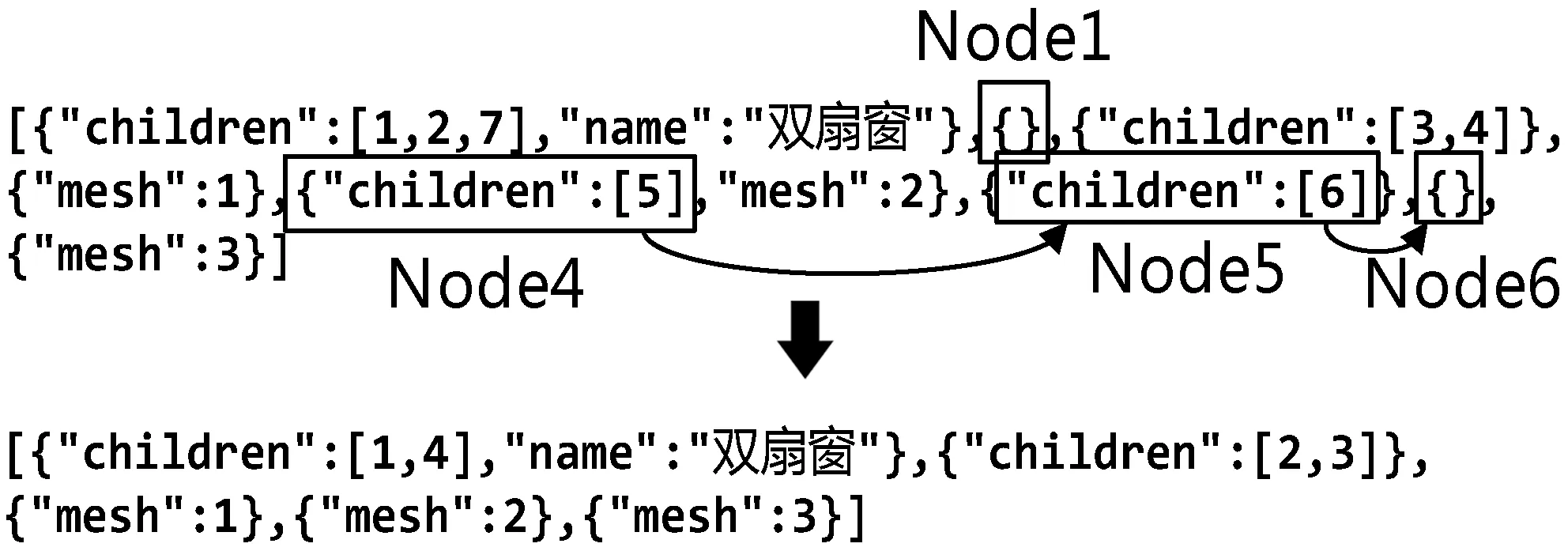
图10 节点清洗
对每个节点进行检查,算法流程如下所示。
1) 初始化,获得Nodes数组中的根节点RootNode,根据RootNode中的children数组递归循环整个Nodes数组,在递归循环中实例化Segment,每个Segment中包含当前Node、Node在数组中的索引Index、Node的父节点索引ParentIndex以及在父节点的children数组中的索引DeleteIndex,返回包含Segment的数组Segments。
2) 遍历Segments,对每个Segment.Node进行检查,伪代码如下:
输入:Seg
输出:none
BEGIN
1: Node←Seg.Node;
2: If(Node.Children is not null and
Node.Children.Count is 0) Then
3: Node.Children←null;
4: If(Node.Children is null and Node.Mesh is null)
Then//节点不合格
5: Index←Seg.Index;
//该节点的删除会导致后面节点位置的变化
6: For I←Index+1 to Segments.Count
7: Do TemSeg←Segments[I];
8: TemSeg.Index←TemSeg.Index-1;
9: ParentIndex←TemSeg.ParentIndex;
//对不是根节点的父节点children数组进行维护
10: If ParentIndex is not -1 Then
11: ParentNode←Segments[ParentIndex].Node;
12: DeleteIndex←TemSeg.DeleteIndex;
13: ParentNode.Children[DeleteIndex]=TemSeg.Index;
//对父节点在待删节点之后,对父节点索引减1
14: If ParentIndex>Index Then
15: ParentIndex←ParentIndex-1;
16: Delete Segments[Index];//节点删除
17: PIndex←Seg.ParentIndex;
18: DIndex←Seg.DeleteIndex;
//不合格节点删除对其父节产生影响
19: If PIndex is not -1 Then
20: PNode←Segments[PIndex].Node;
21: For J←DIndex+1 to PNode.Children.Count
22: Do
Segments[PNode.Children[J]].DeleteIndex=J-1;
23: Delete PNode.Children[DIndex];
//递归,对父节点进行检查
24: Seg←Segments[PIndex] Goto(1);
END
3) 遍历Segments,提取Node,返回Nodes数组。
4 实验与展示
本文采用C#语言和Visual Studio 2012工具对Autodesk Revit 2018进行二次开发。将教学楼、住宅小区和某施工场地BIM模型作为实验数据,使用插件分别将其导出为未执行轻量化操作的GLB数据、执行轻量化操作的GLB数据和属性信息文件,并用Draco对轻量化后的GLB数据进行压缩,处理结果如图11所示。
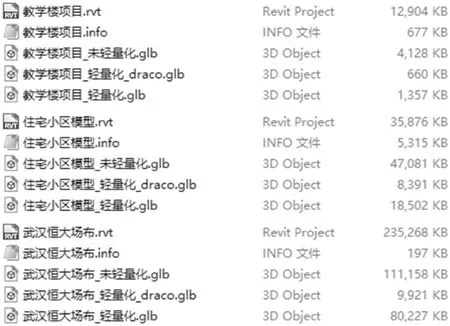
图11 Revit文件、未轻量化、轻量化与压缩文件大小对比
在调试过程中分别统计了各GLB数据中Mesh的数量,如表1所示。Mesh数量在一定程度上体现数据轻量化的效果,每多一个Mesh,在GLB中的bin区至少多包含一份几何数据,与之对应,在JSON区多包含一份获取该几何数据的描述信息。另外,轻量化的结果因模型而异,对于富含相同构件的BIM模型,轻量化的结果较好。其中恒大场布模型包含214个Mesh,原因在于该模型大部分所用的是自定义的族,细分的粒度不如Revit内建的族,例如,在塔吊的模型解析过程中,几何数据作为一个整体被提取。
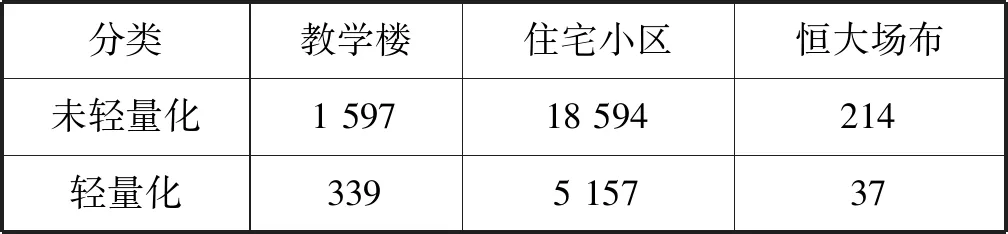
表1 GLB中Mesh数量统计
同时,将住宅小区模型与恒大场布模型的轻量化并经过Draco压缩处理的结果上传至阿里云服务器,轻量化未经过压缩处理的结果上传至Cesium Ion平台进行测试,如图12所示,左侧为Three.js渲染结果,右侧为Cesium的渲染结果。其中,渲染被Draco压缩的GLB模型之前需要解码,解码时间内会阻塞前端页面响应,HTML5引入了WebWorker工作线程可以很好地解决此问题,并且Three.js内置了子线程解码模型并将解码后的数据发送给主线程进行渲染的功能。
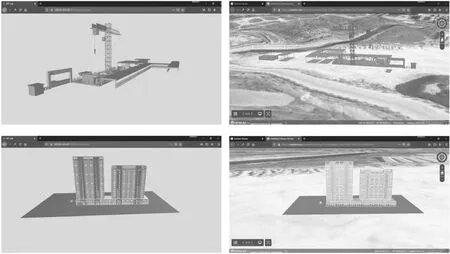
图12 模型在Three.js与Cesium引擎中的渲染效果
在对属性信息提取的工作中,基于RvtVa3c对构件工程信息提取工作的基础上,进一步提取材料属性、物理属性,并将属性信息以JSON格式写入info文件中,属性ID与GLB中node.name一一对应,教学楼模型的属性信息如图13所示。
对数据损失进行评估时,发现住宅小区模型构件总数为7 489个,而渲染结果显示7 480个,损失9个构件,如图14所示,在转换过程中会有较小的数据损失。
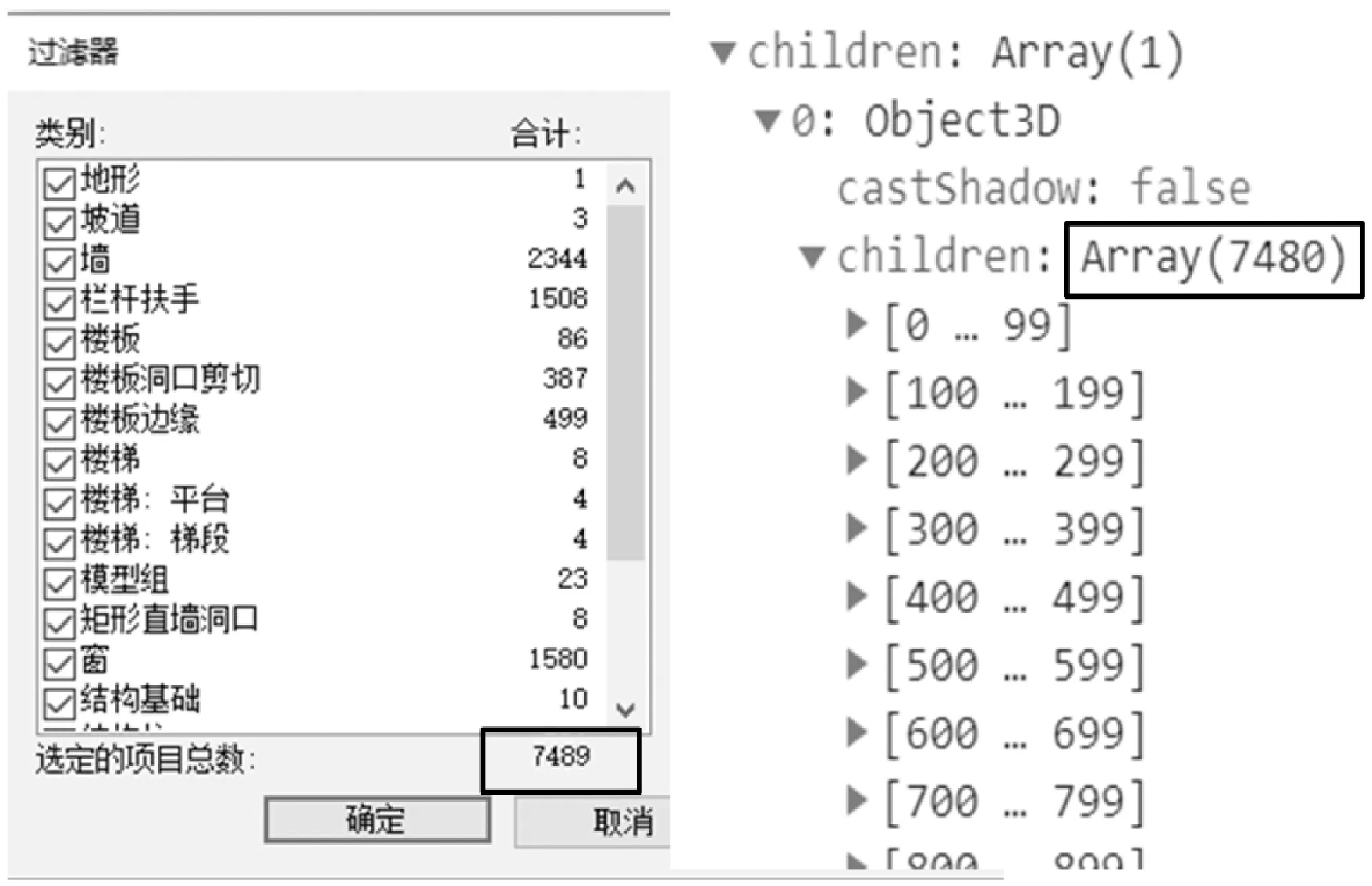
图14 住宅小区模型数据转换损失评估
5 结 语
BIM模型作为建筑参数化的载体,具有空间不均匀、高度复杂、语义丰富和数据量大等特性。将BIM与互联网技术相结合,需要从数据结构与算法、数据传输以及计算机图形学等方向做相应的研究。但是BIM有众多的数据源,增加了数据使用成本,给数据融合造成了一定的难度。而IFC作为BIM的数据标准,借助其进行数据交换,很大程度上受限于各个软件平台对标准的实现程度以及模型轻量化带来的难度。本文借助Revit API实现BIM轻量化,仍有很大的不足:(1) 该转换方法仅仅适用于Revit平台,不具有普适性。(2) 数据在转换过程中仍有少量几何数据损失,需要进一步完善。(3) 需对数据的加载以及渲染策略进行优化。因此这些不足也是以后需要研究方向。
猜你喜欢
精密成形工程(2022年2期)2022-02-22
销售与市场(营销版)(2021年10期)2021-11-21
销售与市场(营销版)(2019年6期)2019-06-21
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
数学大世界(2018年1期)2018-04-12
网络安全技术与应用(2017年9期)2017-09-20
中等数学(2017年2期)2017-06-01
专用汽车(2016年1期)2016-03-01
