
基于LightGBM的LoRa室外指纹定位算法
2023-11-02 13:05张子凡庞成鑫冉浦东刁志峰
计算机应用与软件 2023年10期
张子凡 庞成鑫* 冉浦东 范 磊 刁志峰 张 军
1(上海电力大学电子与信息工程学院 上海 201306)
2(同济大学设计创意学院 上海 200092)
3(国家电网南瑞南京控制系统有限公司 江苏 南京 210000)
0 引 言
物联网技术的发展,在诸如物流检测、生产监控、河道检测等领域内产生了越来越多基于物联网应用的位置信息服务。LoRaWAN是低功耗广域网(LPWAN)技术之一。它由Semtech开发,是在Sub—GHz免许可频段中使用最广泛的LPWAN技术之一,具有低成本、低功耗和较长距离通信的优点[1]。在学校校区和工业园区这样若干平方公里的区域进行企业级组网较为合适。例如学校和厂区中的货物推车经常在各个时段被不同的人员推到不同的地点,这通常导致重要的公有财产在使用的时候反而难以找到甚至导致推车的损坏及丢失。
为了解决这个问题,可以使用具有LoRaWAN技术的智能推车。智能推车既可对自身进行定位帮助后勤人员寻找、使用和统计,又可从低功耗方面受益,因为没有人希望找到并频繁更换相当数量智能推车的电池。
如今,国内外学者在尝试各种方法在LoRaWAN中实现精确定位。在较为广阔的地段单纯使用接收信号强度(Received Signal Strength Indicate,RSSI)模型,其原理是使用基站接收到的信号强度计算出信号的传播损耗,再将其以理论与经验模型转化为距离,通过多个基站的重叠覆盖范围运用朴素贝叶斯原理计算出节点的最大概率位置。计算估计位置时,误差约为1 000~2 000 m[2]。Ha等[3]针对这个问题提出了使用指纹定位辅助ToA的定位系统,利用LoRa信号在空间中的传播时间来计算信号发射端与接收端的距离。其方法特点是比较少的基站数目同样能够进行定位,但是这种算法在空旷地带的精度很高而在城市范围内则精度欠佳(200 m左右)。Fargas等[4]使用TDoA方法来估计物体在农村地区的位置。通过研究人员进行的实验验证结果,但是该算法定位误差在某些情况下超过1 km,误差较大。即使在一些情况下将定位误差缩小到100 m左右,但是算法框架中数据包的发送数量却超过10 000,并且算法总处理时间较长。还有不少研究针对室内定位和室外小范围定位取得了不错的定位精度[5-7],但是在基站与终端距离更远、地理环境更复杂、干扰更多样的环境下精度还是不理想。
本文提出基于LightGBM的指纹定位算法进行室外定位。通过在学校整个校区内的实验估算了在类似大小中应用本文算法得出的定位准确性和算法实时性。
1 定位算法
考虑到并非所有应用都需要在整个LoRa的最大有效范围内定位,本文专注于一片厂区或者校园大小的区域,本文采用机器学习融合指纹定位的算法实现LoRa的室外定位。离线阶段包括指纹库的构建以及LightGBM算法的参数训练。
1.1 指纹定位原理及指纹库的创建
当在空间范围内安置数目大于三个、位置较分散的网关后,区域内终端与网关通信将在各个基站分别多组产生各自的RSSI值(rssigw1,rssigw2,…,rssigwn)。空间中干扰众多,城市环境的高楼会严重影响附近被遮挡的样本点。因此需要对数据进行预处理。
本文的数据预处理分为三个部分,按照先后顺序第一是对采集样本中的空缺值进行填补。实际使用网关的性能会存在差异。例如唐周益丹等[5]的论文中使用了灵敏度为-90 dBm的网关,不能识别接收功率小于-90 dBm的LoRa信号,导致其难以接收长距离或是复杂环境下的终端信号。本文中实验使用的中兴ZTE-IWG200网关灵敏度为-140 dBm,对于实际信号强度弱于-140 dBm的信号没有分辨能力。这个灵敏度已经相当高了,因此我们将某样本点可能出现的RSSI空缺值由-140 dBm代替,也不会对结果产生较大影响。第二步是针对噪声和环境的复杂性对同一地点的多组信号采用中值滤波。最后为了提高模型的泛化能力和收敛速度,将数据作归一化处理。
数据在经过预处理之后将构成一组大于三维的向量,再附上某地本身的二维地理位置(xi,yi)便是指纹(rssigw1,rssigw2,…,rssigwn,xi,yi)。通过一定数量[8]的指纹可以构建好离线指纹库。表1展示了带4个基站、共n个样本点的指纹数据库。

表1 指纹数据库
最后的在线阶段使用未知位置的指纹经过数据预处理后作为离线算法输入,最终算法模型计算出相应的位置输出,整个过程如图1所示。
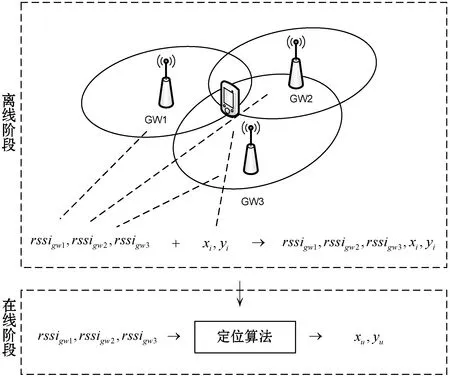
图1 LoRa指纹定位过程
1.2 LightGBM算法
LightGBM是微软于2016年开源发布的一种基于决策树的梯度提升算法[9],其具有支持并行处理、训练速度快、准确率高、内存占用量小的特点,是基于梯度提升树算法的优化版本,目前在Kaggle等各种比赛上取得了很好的成绩[10]。
介绍LightGBM前,首先要介绍梯度提升(Gradient Boosting)[11]。集成学习中的提升方法(Boosting)通过将若干个弱分类器通过组合,构造出一个强分类器[12]。在此之上,梯度提升的核心思想通过计算负梯度近似计算残差来逐步提升模型,它采用决策树作为基分类器。
当定义初始值f0(x)=0后,之后的第n步迭代的模型可以表示为:
fn(x)=fn-1(x)+T(x;Θn)
(1)
式中:fn-1(x)是当前模型;T(x;Θn)所代表的残差为模型优化的关键参数。下一个基分类器的Θn可以通过式(2)确定。
(2)
梯度提升使用了模型负梯度值近似计算T(x;Θn),从而使之后的每次迭代减少了整体的损失函数值。当训练第i个样本时,该处的负梯度近似值为:
(3)
通过近似拟合来优化损失函数,在每次迭代中减少损失函数的值并形成新的基学习器,通过之前每次迭代产生的基学习器线性相加,最后可以得到强学习器。
LightGBM作为梯度提升算法的一种,最重要的是改进采用了直方图(Histogram)算法和带有深度限制的按叶子生长(leaf-wise)算法。
直方图算法通过把连续的浮点型特征离散化成K个整数,从而构造出一个宽度为K的直方图。遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后从直方图的离散值中,遍历出最优的分割点。对比精确分割,虽然有一定准确度降低。但由于弱分类器对准确度要求不高,因此这种方法在梯度提升框架下影响不大且可以有效防止过拟合。
传统的树生长策略使用层生长(level-wise)策略,但很多叶子的分裂增益较低,没有生长的必要。因此LightGBM使用叶子生长(leaf-wise)策略:每次从当前所有叶子中具有最大delta loss的节点来生长,这种生长方式需要配合参数最大深度限制(max_depth)以及叶子数(number_leaves)使用,在保证高效的同时又限制了树过深或者叶子过多,防止模型出现过拟合。改进策略如图2所示。
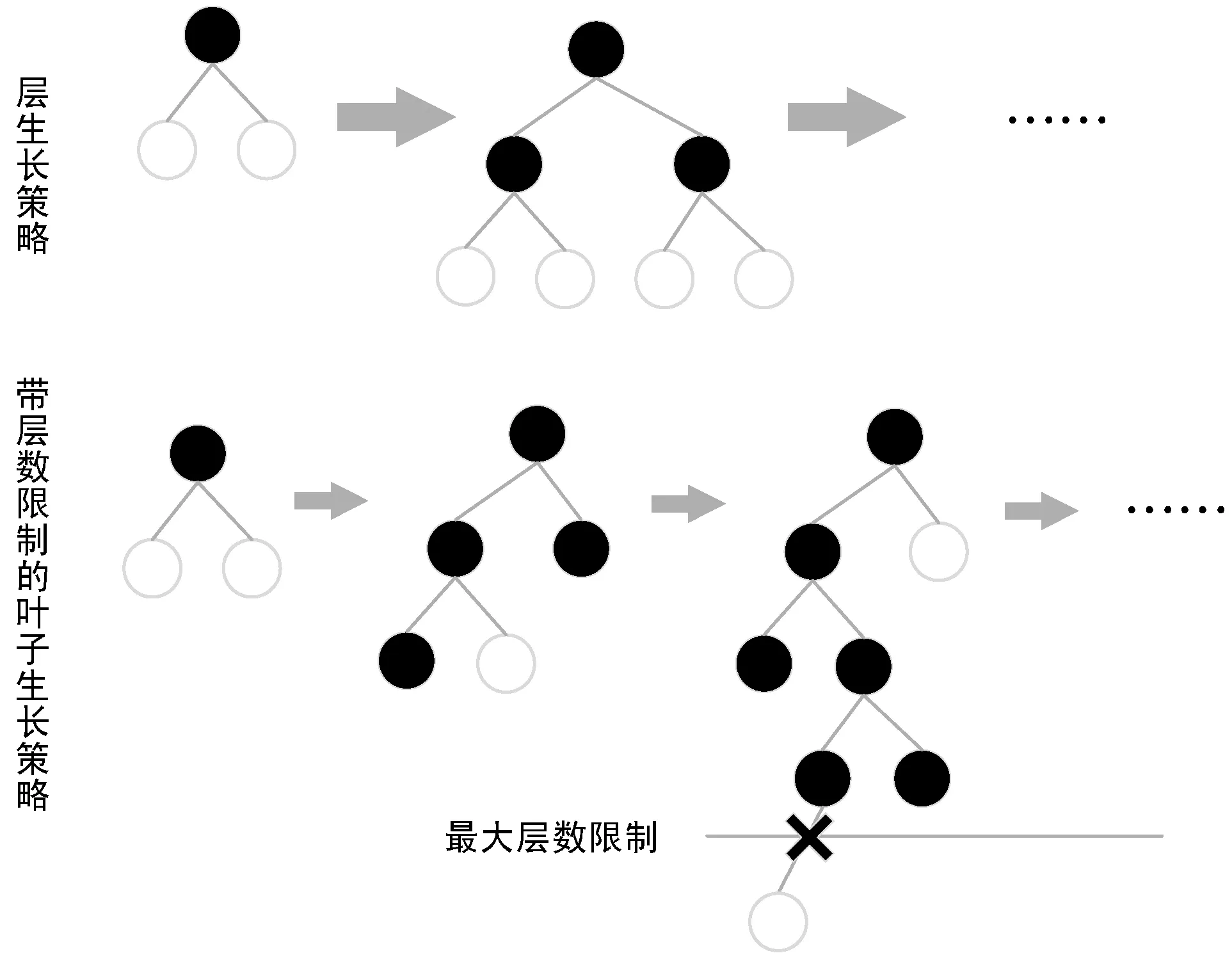
图2 LightGBM树生长策略改进
1.3 基于LightGBM的LoRa指纹算法
将指纹库训练数据(rssigw1,rssigw2,…,rssigwn)当作特征输入,以地理位置信息(xn,yn)作为标签输出,使用LGBMRegressor做监督学习,通过K折交叉验证(K-Fold Cross Validation)调参就训练出该区域的算法模型。K折交叉验证是将总体样本集分成k份,分别使用其中的(k-1)份作为训练集,剩下的1份作为交叉验证集,最后取每次的平均误差来评估这个模型。
最适合判断平面地理位置信息准确率的损失函数是欧氏距离,因此算法采用RMSE作为损失函数,其公式定义如式(4)所示。
(4)
式中:f(Xi)表示i点处的算法预测值(xi,yi),而Yi代表真实的地理位置(xi,yi)。
值得注意的是,平面位置信息是二维数据。但是包括XGBoost、LightGBM在内,相当多的深度学习流行算法使用回归树作为基分类器,导致其无法进行多输入多输出(MIMO)。因此,本文使用多输出回归器(MultiOutputRegressor)对LGBMRegressor进行包装组合从而使得算法框架能够训练并输出多维标签,整个算法框架的流程如图3所示。
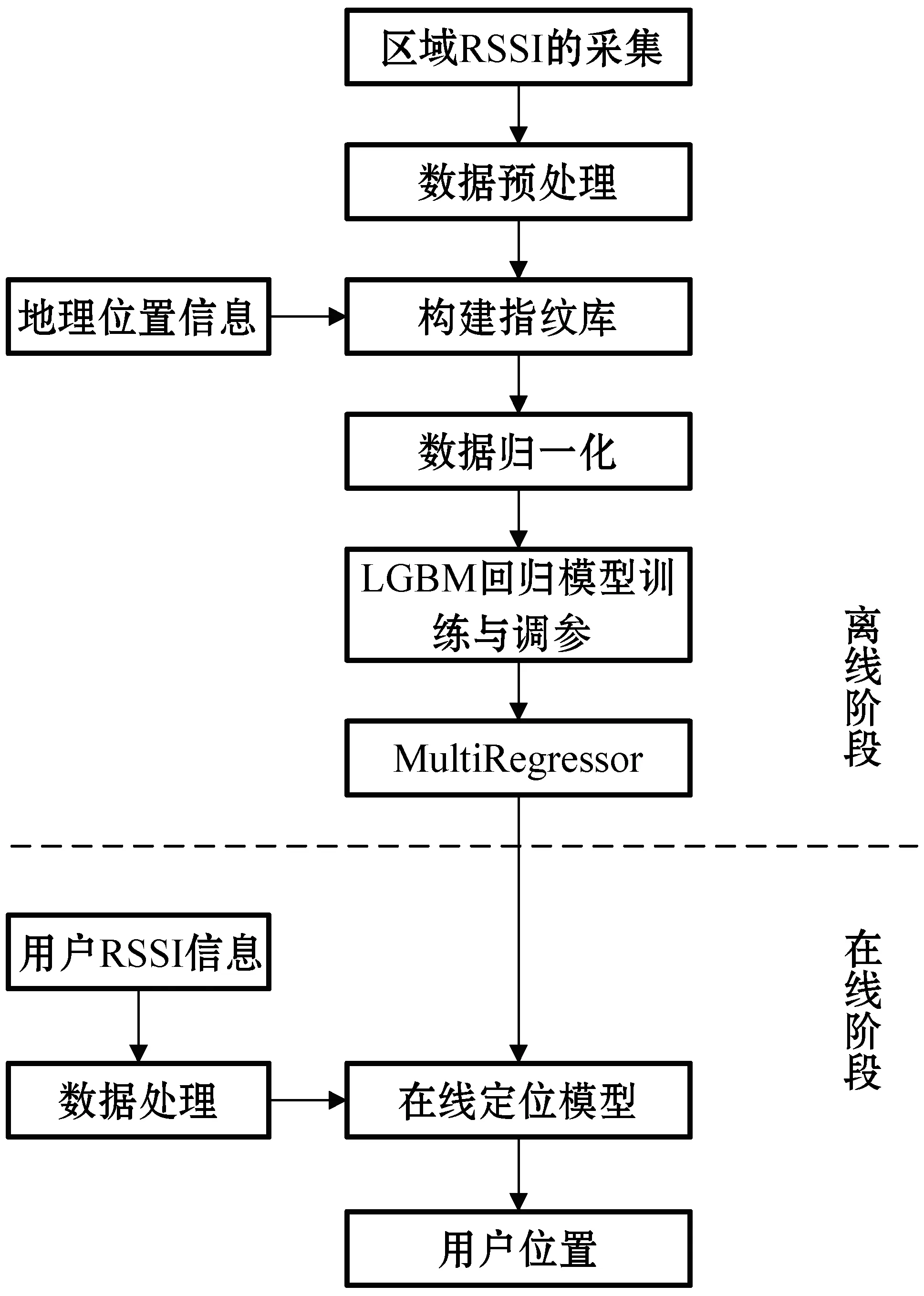
图3 算法框架流程
2 实验及结果分析
本文于上海电力大学浦东校区内部设置了约800 m×500 m的实验区域,区域内包括楼宇、人员、车辆等其他各种障碍物,对其他的场地也具有一定代表性。选取学校靠近边角的4栋楼楼顶上安装了ZTE-IWG200的LoRa网关如图4所示。

图4 网关3位置及移动测试终端
该网关在扩频因子固定为12的情况下灵敏度≤-140 dBm,保证了测试区域室外LoRa信号全覆盖不断流。测试人员通过手持ZTE-T20移动测试终端获得测试区域内各个样本点的RSSI值。
LoRa通信终端参数设置如表2所示。

表2 通信终端参数设置
实验总共设置了样本点300个。这些点涵盖了停车场、楼宇附近、田径场、室外篮球场、人行道等各种位置,对校园室外环境有充分的代表性。根据训练集和测试集的样本比例,我们设置了270个训练点以及30个测试点,样本的划分由train_test_split分配。图5所示范围为实验区域、样本点选取及其中一种划分方法的示意。其中标数字点位为LoRa网关,其他实心点位为训练点或测试点。

图5 实验区域示意图
在每一个测试点位,我们都将终端放于地面上测试,保证天线垂直向上。终端设置为每隔30 s与网关通信1次,在每点进行5次采集方便进行数据处理。为了保证参数的一致性,我们关闭了终端自适应功能(ADR)以确保扩频因子(SF)数值稳定为12。
为了方便分析和比较定位准确度和实时性,本文引入了其他常用的三种算法模型。它们分别为kNN、BP神经网络、XGBoost各自的回归模型。在二维平面上kNN通过计算测试样本与训练样本的欧氏距离,找出与测试样本距离最接近的k个训练样本,输出训练样本的平均位置。其特点就是原理简单高效。对比实验中kNN中的k值根据经验和Lemic等[8]的研究设置为4;BP神经网络是利用误差反向传播算法训练的多层前馈神经网络,作为目前应用最广泛的神经网络模型,其特点是极强的泛化能力和适应能力,在本实验中BP神经网络原生支持多维向量输出。对比实验中BP神经网络设置中间层为4层;XGBoost同LightGBM一样是梯度提升树模型的改进版本,相比传统梯度提升树,它将损失函数从平方损失推广到二阶可导的损失同时加入了L2正则化项,其影响力已经被许多机器学习和数据挖掘的比赛所广泛认可[13]。
上面的四种算法的对比测试一共分为10组,每组测试都采用train_test_split的方法将300组样本分别按照test_size等于0.1的分法分为270个训练集合和30个测试集。为确保每组四个算法间训练集测试集样本相同并且组与组之间不同,我们在不同组之间使用了不同的random_state种子使划分方法不一,测试结果如图6所示。

图6 四种算法误差结果对比
统计各个算法在10组样本上误差平均值如表3所示。

表3 各算法RMSE误差平均值 单位:m
其中LightGBM在最好的第4组平均定位精度为72.33 m,在最差的第8组平均精度为95.25 m,10组总共平均精度为90.29 m。
同时,针对指纹定位可能存在的线下指纹数量大、训练复杂耗时、线上定位对实时性要求高的特点,我们利用循环结构模拟了线上同时100个终端请求位置计算的训练时间以及线下一次数据集的训练时间。公平起见,四个算法统一使用CPU版本。平台CPU为Intel Core i7-9750H处理器,操作系统为Windows 10 64位家庭版。
线下训练四种算法的平均训练时间如表4所示。

表4 算法平均训练时间 单位:ms
可以清楚地看出kNN训练效率远超另外三种算法。而LightGBM与其他算法相比效率提高了不少,但还是在一个数量级。
线上定位时间如图7所示。
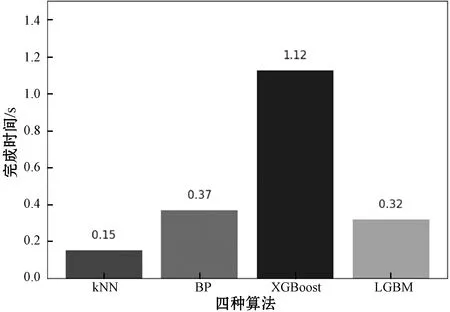
图7 四种算法计算时间对比
通过上面的数据我们可以清楚地发现此算法的位置误差,相比kNN和BP神经网络,分别缩小了37.2%和35.3%,相比XGBoost缩小了2.4%,相差不大。而根据图7的线上定位时间数据,在实时位置计算上该算法相较于XGBoost效率提升了350%,与BP神经网络相差不大,逊于kNN。
综合上述结果,基于LightGBM的LoRa室外定位是有效的,在较为准确地预计实际地点的同时通过采用直方图算法,与XGBoost相比效率得到了很大的提高。因此兼顾了优秀的实时性。尤其考虑到LightGBM原生支持并行计算并且有更高的内存使用效率,将来对有更多样本数据的训练相比XGBoost,线下训练的效率和线上定位的实时性会更加明显。
3 结 语
随着低功耗物联网的发展,应用LoRa或者ZETA、SigFox、NB-IoT的服务也会越来越多,同时对终端定位的需求越发强烈。本文针对LoRa使用传统RSSI传播模型在室外定位结果较为不准确的情况,提出基于LightGBM的LoRa室外指纹定位算法,在整片校园环境中精确度达到了90 m左右,相比传统定位方法准确度有提高的同时提高了计算效率。下一步可以通过以下几个方面来对进一步优化:(1) 空间中的定位需求可能不是相等的,一些热门位置应该分配更多样本点进行训练和测试;(2) 样本点数量相对Wi-Fi这种协议较少,尚不能发挥机器学习甚至深度学习的潜力;(3) 实验定位设备统一且规格较高,质量稍差的标签可能不具备本实验路测设备的发射功率从而影响基站RSSI的获取。而这些缺陷也是本文后续工作的重点研究方向。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
自动化学报(2016年8期)2016-04-16
移动通信(2015年18期)2015-08-24
青少年科技博览(中学版)(2015年7期)2015-08-12
太阳能(2015年7期)2015-04-12
组合机床与自动化加工技术(2014年9期)2014-03-01
