
基于Anchor-free的图像全景分割算法研究
2023-11-02 12:36秦怡芳张艳硕
计算机应用与软件 2023年10期
陈 颖 秦怡芳 张艳硕
1(北京电子科技学院 北京 100070)
2(西安电子科技大学计算机科学与技术学院 陕西 西安 710000)
0 引 言
近十年很多基于图像认知的应用得到了学术界和资本界的青睐,最典型的落地场景有智慧安防、自动驾驶等。在这些图像认知应用中,图像语义分割、实例分割、全景分割是智能体感知外部环境的重要手段。其中,全景分割是最全面和最具有落地意义的,它要求对图像中的每一个像素点赋予一个唯一的语义类别和实例识别号。现有的图像全景分割网络基本都沿用了语义分割和实例分割子分支融合形成全景输出的结构。其中实例分割子分支大多数都采用了基于anchor的策略,如著名的Mask R-CNN。这种方式依赖于人为预先设置的不同尺度和不同宽高比的anchor,且由于anchor和RPN的存在,会生成大量冗余的检测框,计算量往往很大。本文基于卷积神经网络架构,对图像进行了全景分割理论研究和实践。设计一种立足于极坐标系对实例轮廓进行数学建模的anchor-free的实例分割网络,摆脱人为预设的anchor限制,将其集成到全景分割架构中去。
1 相关研究
1.1 语义分割
经过语义分割模型训练后,图像每一个像素点都被赋予一个唯一的类别标签。语义分割一直是学术界研究的热点。2014年全卷积神经网络FCN[1]实现了端到端,引入了跳跃连接。剑桥大学提出的分割模型SegNet[2]是编码器-解码器结构,其中池化时标记位置一定程度弥补了FCN的定位缺陷。2015年Ronneberger等[3]提出的U-net网络结构,编码解码中间存在不同抽象层次的特征拼接。2017年Jégou等[4]提出的FC-DenseNet包含一个降采样和一个升采样模块,降采样用来提取图像特征,升采样被用来在输出结果中逐渐提升分辨率。各种语义分割网络层出不穷,学者们在特征提取和多尺度融合方面做足了研究,取得的成果也十分瞩目。
1.2 实例分割
语义分割只区分类型,而实例分割对同一类的不同个体也进行细分。实例分割只对前景的物体类别进行预测,背景区域的道路、天空和树木等不予考虑。实例分割的目标是检测出每一个可数物体的所有像素点,并对其赋予一个所属的实例ID。现在的实例分割研究有基于anchor的和基于anchor-free的。
1.2.1基于anchor的实例分割
基于anchor的实例分割是首先进行基于anchor的物体检测框回归,在得到了检测框之后,再分别对这些检测框里像素进行前背景分类,这有点类似于语义分割,最后得到实例分割的输出。这种算法的典型代表有Mask R-CNN[5]、Mask Scoring R-CNN[6]、Cascade Mask R-CNN[7]、PANet[8],基于anchor的实例分割后期需要对每一个候选检测框单独进行前景背景分类,计算量较大。
1.2.2基于anchor-free的实例分割
2019年10月基于anchor-free的实例分割模型PolarMask[9]被首次提出,该模型将目标检测、实例分割进行了统一化。它与anchor-free的目标检测架构FCOS[10]相似,是用一个n维度的向量来表示实例的掩膜边界(即极坐标系下的实例边界距离原点的距离)。它将实例分割问题转化为实例中心分类问题和稠密距离回归问题,并采用全卷积网络进行实现。
1.3 基于anchor的全景分割
实例分割不区分背景类,语义分割则是不对同一类的事物做个体细分。把这两者相结合,便是全景分割。全景分割的概念最早在2018年1月由Facebook人工智能实验室Kirillov等[11]提出。
全景分割是最细致最全面的场景理解,目前全景分割的主流架构有TASCNet[12]、JSIS-Net[13],它们都是沿用了图1的架构,即通过语义分割和实例分割子任务预测结果融合输出全景分割结果。这些模型实例分割分支都采用了基于anchor的方式,如著名的Mask R-CNN。
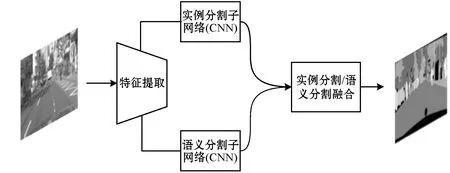
图1 主流的全景分割框架
这几年来有不少全景分割的网络架构相继被提出,有些是着重解决语义分割和实例分割边缘的重合问题[14-16],还有将注意力机制引入其中的[17]。纵观这些全景分割架构,都是通过设计更有效的共享卷积特征提取,然后研究更有效的子分支结果合并方法。但它们都需要人为预设不同尺度和宽高比的anchor。
2 基于anchor-free的图像全景分割
根据图1可以发现,将anchor-free的实例分割网络集成到全景分割架构中去便可以使全景分割任务不再依赖于任何人为设定的anchor。因此,本文接下来对anchor-free的全景分割模型进行研究。
图2给出了本文的全景分割网络架构,该网络中包含语义分割和实例分割两个分支,采用了经典的全卷积网络架构U-Net[3]搭建其backbone。
U-Net分为降采样和升采样两个模块,其中降采样是对输入图像特征提取,而升采样类似于解码结构。本文无论是语义分割还是实例分割均采用了U-Net做特征提取,它利用同等宽高的数据块进行拼接使得不同尺度的特征图(Feature Map)组合,然后再逐层往后进行卷积计算。从图2中可见,搭建的U-Net骨干网络有4个池化,也对应4次反卷积操作。这4个池化本质上是对不同尺度下的特征进一步提取,而拼接操作是多尺度特征糅合,这样的操作贯穿了整个U-Net骨干网。
2.1 语义分割子分支
如图2左侧分支所示,语义分割的网络结构仅是在U-Net后多加了一层卷积,因为语义分割任务相对比较简单,不需要过多的卷积核来学习图像特征,该U-Net骨干网是简化过的U-Net,输入图像进入网络之前首先需要进行尺度收缩,将其调整为512×512×3,语义分割的输出维度为512×512×Cstuff(这里包含实例的种类),用Sseg表示其输出。所有卷积后都默认连接的ReLU非线性激活函数,只有语义分割最后一层是级联的Softmax计算单元。语义分割输出Sseg[i][j][c]表示的是输入图像[i,j]位置像素的属于第c类stuff的概率,满足:
(1)
2.2 实例分割子分支
图2右侧的实例分割网络中,包含像素级实例分类、实例中心点回归以及实例掩膜边缘回归三个子网络,三者共享同一个U-Net骨干网。相比左半支的语义分割,实例分割骨干网的卷积核数量明显增加,原因是实例分割网络中决策多,需要学习的特征也多。
2.2.1实例分类和实例中心点回归
实例分割子网络中,U-Net后级联了卷积层conv18~conv23,如图3所示。这些卷积层是对像素进行分类和进行中心点回归的,其架构细节如表1。其中conv22卷积层后连接的是Softmax,目的是将各像素实例类别的概率预测进行归一化,即对于conv22的输出数据块Icls,Icls[i][j][c]表示的是对应输入图像[i,j]位置上的像素属于第c类实例的概率。其满足:
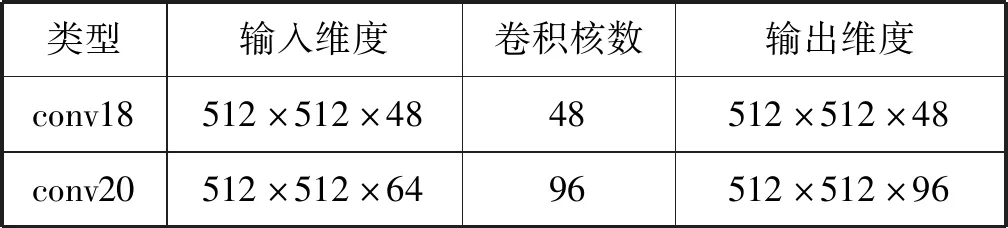
表1 conv18~conv23(卷积3×3,步长1)

图3 实例分支head
(2)
实例中心点回归网络输出通道数是1,它是对每个像素能否作为一个实例的中心点的得分score的回归,conv23卷积层的输出直接作为score的预测值。
2.2.2实例掩膜轮廓回归
图3实例分割掩膜轮廓回归网络其架构细节如表2所示,其最后一层的输出维度为512×512×M。其中512×512中每个像素均有一个描述轮廓向量的输出,该向量的维度为1×M,它是极坐标系中掩膜轮廓的数学表征(各个角度射线与轮廓交点距离原点的距离)。根据这些等旋转角度下的距离,可以将其转化为轮廓的坐标点,再进行首尾相接便可重构出实例的边界。M取值越大,则重构的实例边界越精细。
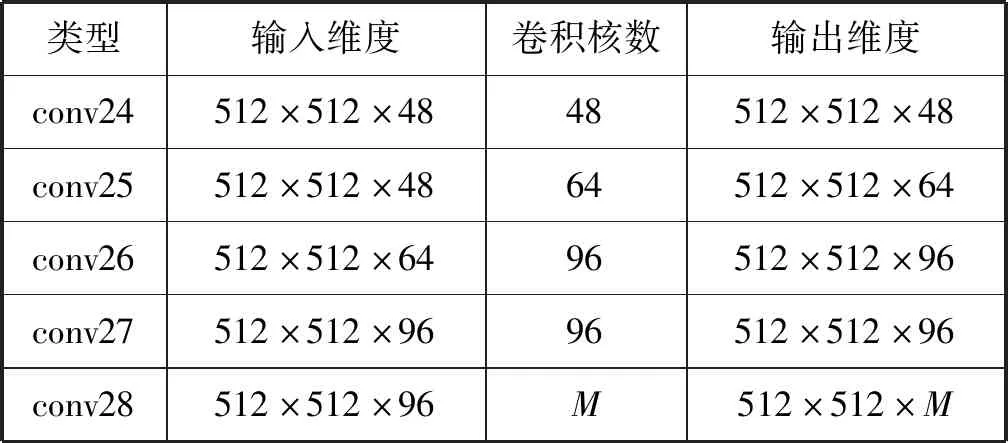
表2 实例掩膜轮廓回归子网络(卷积3×3,步长1)
2.2.3Soft-NMS后处理
根据实例分类、实例中心点回归、实例掩膜轮廓回归,便可以得到输入图像中的每一个像素作为中心点的实例轮廓,置信度以及实例类别信息。模型训练之后可以设定一阈值St,选取出所有的score>St的像素点,并将这些像素点对应的实例轮廓、实例类别从实例分割网络的输出数据块中提取出来,便可以定位实例、确定其类别,以及描述其轮廓形态。
对于某一个实例物体而言,其轮廓内部可能存在若干个高质量的中心点(作为极坐标系下的原点)被选出,故会重构出若干个实例轮廓,采用Soft非极大值抑制[18]对其进行处理,这也是目标检测、实例分割领域最为常用的去除冗余性检测框或实例掩膜的方法。
2.3 语义分割与实例分割融合处理
语义分割子分支和实例分割子分支结果有以下几种可能:
情况1:某像素实例分割和语义分割结果都类属类别cls。
情况2:某像素实例分支中被划为类别cls,语义分支中不属于cls。
情况3:某像素被实例分割网络划为背景类,语义分割划为实例类别cls。
本文采取了一个简单有效的方法对语义分割和实例分割的结果进行融合,如图4所示。

图4 子分支结果融合流程
3 实 验
3.1 数据准备
百度ApolloScape数据集[19]具有标注详细、包含不同困难级别等优点,同时图像丰富,包含多个城市、多样的天气条件,故选其作为本文全景分割算法的训练和测试集合。该数据集共包含143 906幅像素级别标注的图片,数据量十分巨大。从中随机取出9 600幅图像作为使用的数据集,并按照8∶2的划分比例将其划分为训练集和验证集合,训练集共计7 680幅图片,验证集共计1 920幅图片,所有图片均被调整为512×512×3的尺寸输入网络。ApolloScape数据集中的像素标签种类共计35种,其中不可数的填充物类型7种。
3.2 损失函数
全景分割损失包含语义实例两个子分支损失:
Ltotal=Lsemantic+βLinstance
(3)
式中:β为权衡参数。
(1) 语义分割损失函数。
(4)
式中:Lsemantic[i][j]表示的是单个像素语义分割的损失值,语义分割损失取所有像素的损失值平均。
(5)
式中:Yseg[i][j]是像素[i,j]对应的真值;Sseg[i][j][c]是像素[i,j]属于第c类填充物的概率。
(2) 实例分割损失函数。
Linstance=Lins-cls+Lins-score+Lins-polar-iou
(6)
其中实例分类损失Lins-cls与语义分割中损失定义一样,替换一下变量即可,不赘述。
实例中心回归损失Lins-score定义如下:
(7)
其中s[i][j]和s′[i][j]分别是对应像素作为实例中心点的得分真值和预测值。
极坐标系中实例轮廓回归损失Lins-polar-iou定义与PolarMask中保持一致,即:
(8)
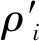
3.3 实验结果与分析
(1) 不同Backbone的全景分割性能比较与分析。对于图2的全景分割架构,本文是以自定义U-Net作为backbone的,因此对不同backbone网络对该全景分割架构性能的影响进行了实验验证。从表3中可以发现,自定义的U-Net性能与原生U-Net相当,优于SegNet和FC-DenseNets,但是相比FCN性能稍弱。
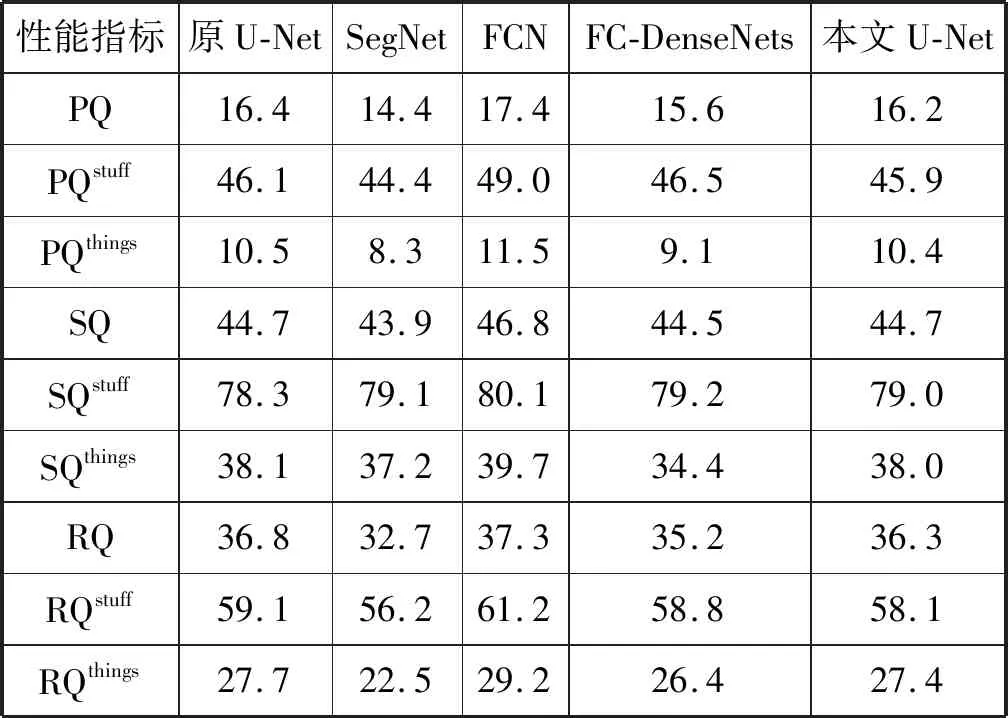
表3 基于不同Backbone的全景分割性能对比(Δθ=5°)
基于自定义U-Net的全景分割网络具有一定的性能竞争优势,但其最大的优势在于它是轻量级的。图5对主流的Backbone的参数进行了统计,可以发现自定义的U-Net骨架网虽然性能稍逊色于FCN,但是其网络参数相比于FCN则降低了约35%,适合低开销约束的面向于实时计算的应用场景。
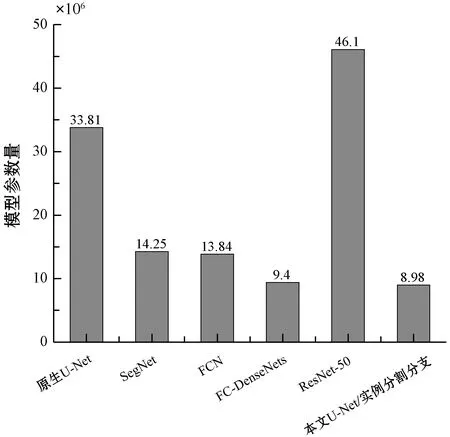
图5 不同骨干网络参数对比图
为了更直观地对比不同骨干网络的全景分割性能,图6用一帧街景图像来作示例。
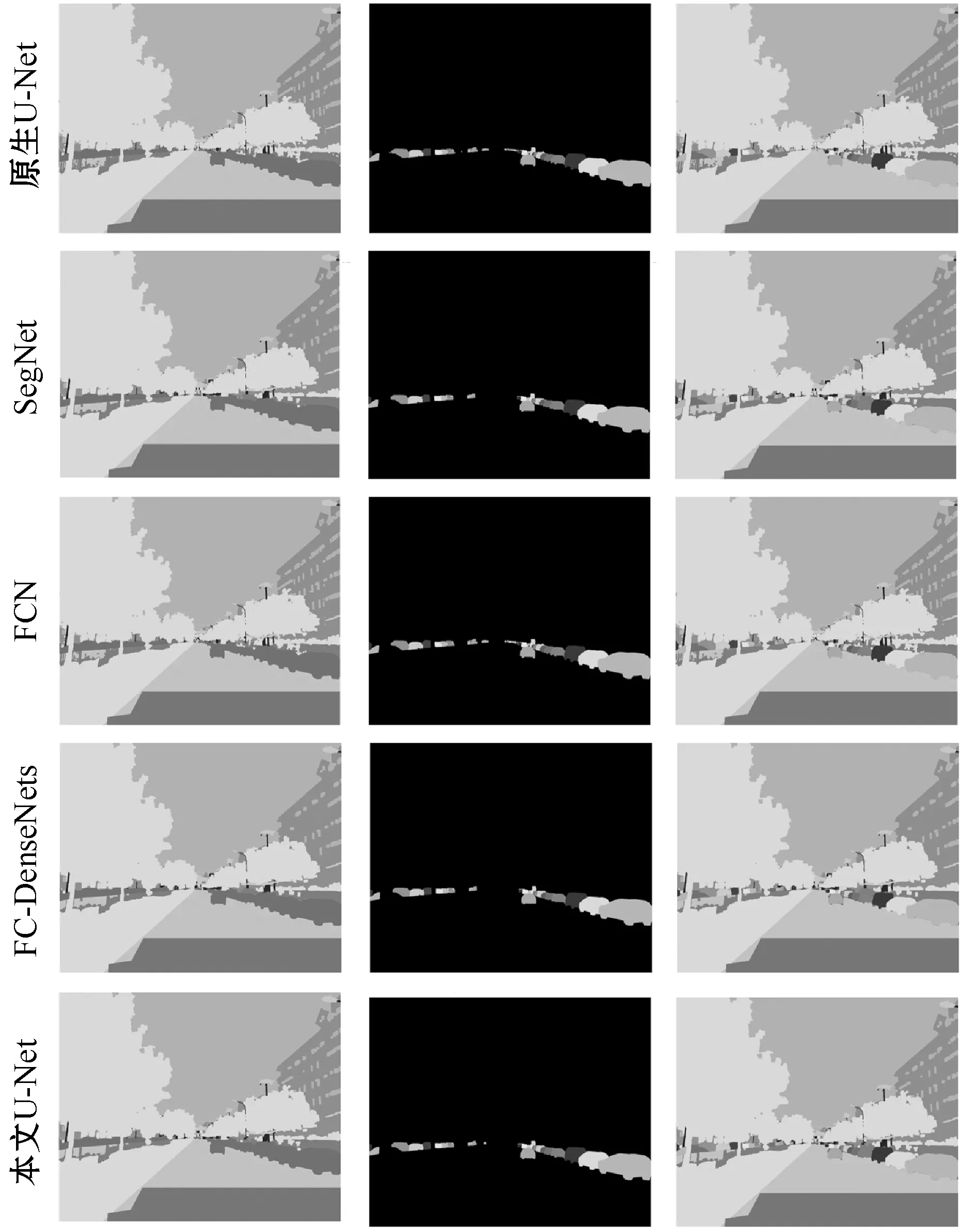
图6 同一幅图不同骨干网下的语义(左)、实例(中)和全景(右)输出效果对比
(2) 不同旋转角度全景分割性能对比。极坐标系中旋转角度间隔Δθ越小,采样点M越多,实例轮廓拟合程度越高,但同时模型参数会增加。对不同的旋转角度Δθ对全景分割网络的性能影响做了实验验证。如表4所示。
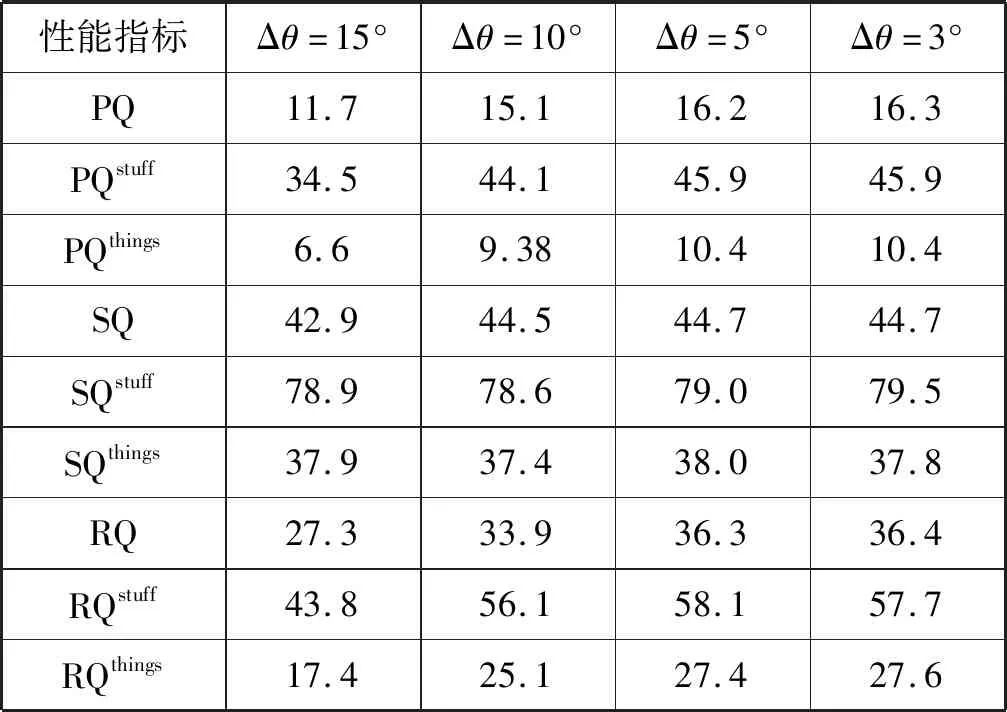
表4 不同旋转角度间隔采样的全景分割性能对比
可以看出,Δθ越小,性能越好,但当Δθ小到5°或更小的时候,性能趋于稳定。开始精度提高是因为当Δθ变小时,描述实例轮廓的采样点变多,轮廓拟合程度更高;但采样点过多时,性能会受到实例轮廓凹凸性的影响,如果原点发出的一条射线与实例轮廓有多个交点,则无论取哪一个交点重建轮廓都会有误差。
4 结 语
本文将基于极坐标系的实例边缘的数学表征模型,集成到全景分割神经网络架构中去,用anchor-free的回归替代了基于检测框的回归,端到端地实现了全景分割网络的训练和性能验证。
针对极坐标系中的轮廓表征方法,本文搭建了一个基于自定义U-Net版本的backbone,U-Net中的降采样和升采样过程将同等尺度的Feature Map进行拼接,有效地挖掘不同尺度的特征。对于本文的anchor-free的全景分割架构,设计了有效的损失函数,并基于百度ApolloScape开源数据集对模型进行训练,验证了不同backbone下以及不同采样粒度下的全景分割性能。实验证明,这种方式在相差不多的精度下,参数量大大减少,更适合低开销的面向实时的应用场景。后续可以通过特征金字塔等手段做进一步性能提升的研究。
猜你喜欢
家庭影院技术(2020年11期)2020-12-28
装备制造技术(2020年1期)2020-12-25
制造技术与机床(2019年11期)2019-12-04
英美文学研究论丛(2018年1期)2018-08-16
家庭影院技术(2017年12期)2017-02-06
特别文摘(2016年21期)2016-12-05
计算机工程(2015年4期)2015-07-05
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
舒适广告(2008年9期)2008-09-22
