
基于集成学习的高原山区水稻种植信息提取
——以云南马龙区为例
2023-11-02 12:36王加胜苗旺元
计算机应用与软件 2023年10期
陈 波 王加胜 王 刚 苗旺元
(云南师范大学信息学院 云南 昆明 650500)
(西部资源环境地理信息技术教育工程研究中心 云南 昆明 650500)
0 引 言
水稻是全球最重要的粮食作物之一[1],更是我国约65%的人口的食物来源[2]。水稻的产量关系到社会稳定,同时也是农业遥感研究的重要内容[3]。遥感具有效率高、成本低、覆盖范围广、多时相、空间连续等特点,可用于作物面积估算、土地利用及覆盖识别等领域[4-5]。遥感提供的技术与方法,让准确、快速获取水稻时空分布成为可能[6]。邬明权等[7]利用多源时序遥感数据提取了大范围的水稻种植面积;张峰等[8]用光学和微波遥感影像对泰国水稻面积月变化进行遥感监测;陆俊等[9]融合时空数据提取了汉江平原水稻种植信息。目前水稻种植信息提取的研究中,研究区大多是平原地带,较少学者将其研究区定位在地形崎岖、作物种植种类繁多的高原山区。
准确获取高原水稻种植信息仍然是一大挑战,提取精度受目视解译采集的样本点的准确率及分类提取方法双重影响。高原山区地形复杂,依赖光谱特征分类精度不理想,而机器学习领域的智能分类方法会比单一地依赖光谱特征分类更理想[10]。不同的机器学习分类方法各有优缺点,而集成学习通过结合多个分类器来完成学习任务,能够在一定程度上综合各分类器的优点、克服自身缺点,比单一的分类器泛化性能好,已广泛应用于混合像元分解、植被监测、变化检测等领域[11-13]。Foody等[14]利用分类器集合实现了目标分类与制图,分类精度均高于每一个单分类器。柏延臣等[15]在《结合多分类器的遥感数据专题分类方法研究》一文中表明多分类器结合的方法能够提高总体分类精度。
在云计算、大数据、人工智能的冲击下,线下分类方法存在不足,基于遥感提取植被信息的方法迅速发展,云平台(GEE)也获得国内外学者的青睐[16]。Patel等[17]利用GEE从Landsat遥感数据自动提取了城市区域并且进行了人口分布制图。徐晗泽宇等[18]通过GEE平台,使用随机森林算法提取了柑橘果园,分类平均总体精度为93.15%,Kappa系数0.90。谭深等[19]利用GEE平台,采用随机森林分类器提取海南省2016年水稻种植范围,总体精度为93.2%。因此,机器学习领域的智能分类方法与云计算的结合将会进一步提高高原山区作物的分类精度和效率。
本文基于GEE平台,以云南省马龙区为研究区,通过集成学习的方法应用Landsat 8影像提取高原山区水稻种植信息。在Google Earth Pro历史影像上选择训练样本点,以分类回归树、支持向量机、最大熵模型为个体分类器,采用投票法结合策略把三个个体分类器集成一个强分类器对研究区进行水稻信息提取;然后对比分析对各种分类方法遥感提取的结果并进行精度评估。
1 研究区
1.1 研究区概况
本文以云南省马龙区为研究区(图1),马龙区位于云南省东部,介于东经103°16′~103°45′、北纬25°08′~25°37′之间,属于低纬高原季风型气候,冬春季干旱,夏秋季湿润,干湿季节分明,雨量充沛。年平均日照1 985 h以上,年平均降雨量1 032 mm,城区年平均气温13.4 ℃,每年无霜期241天,适合种植各种农作物和经济作物。马龙区属云贵高原滇东北丘陵地区,地处金沙江水系与南盘江水系的分水岭,四面环山,中间山谷、丘陵、河流纵横,被分别流入长江和珠江的7条河流分割为11个8 km2以上的小坝子,在地形与作物分布方面具有较好的代表性。
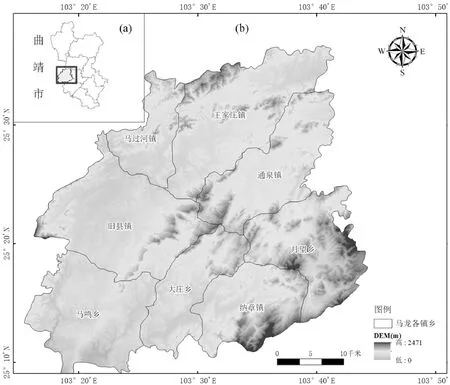
图1 研究区位置示意图
1.2 水稻生长期
马龙区水稻为一年一熟,基本都是农户种植,断断续续大部分播种从5月开始最晚不超过6月份、收获期从10月份开始最晚不超过11月份。掌握研究区水稻生长时间可以为特征选择提供参考和依据。研究区水稻播种期到完熟期等10个阶段如表1所示。

表1 马龙区水稻生长期
2 实 验
作物物候是反映农作物生长发育状况的现象。水稻生长期间,地表覆盖类型呈现出裸土—水体—植被—裸土的变化现象,其生长过程中对水的需求是分类的关键因素,体现于分蘖期和齐穗期。通过构建的光谱、纹理、地形和物候特征,以分类回归树(Classification and Regression Tree)、支持向量机(Support Vector Machine)、最大熵模型(Maximum Entropy Model)为个体分类器,最后利用集成学习方法集成三种分类器为一个强分类器,提取研究区水稻种植信息。本文提取水稻种植信息过程如图2所示。
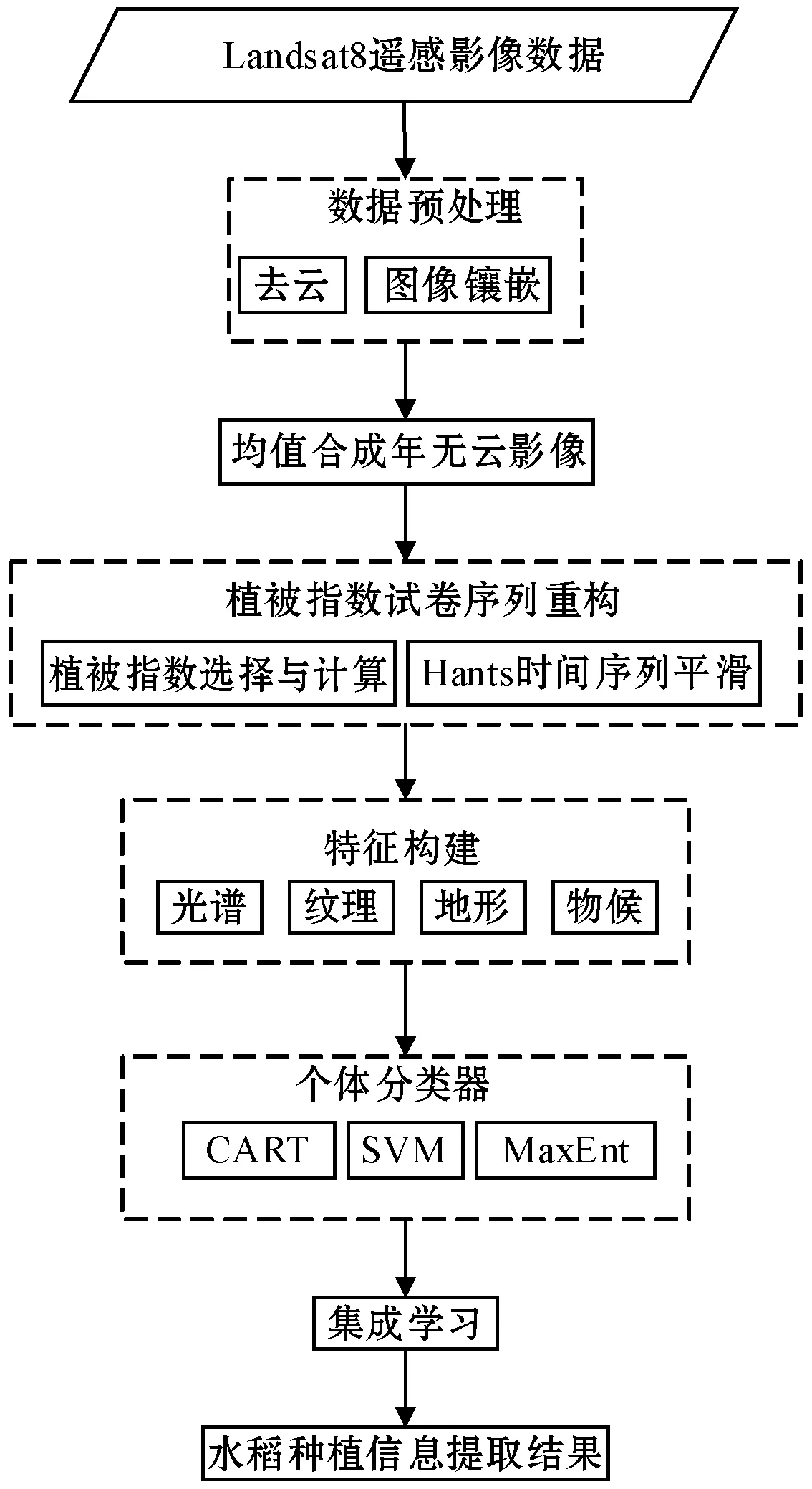
图2 水稻种植信息提取过程
2.1 实验环境
实验通过GEE云平台在线编程实现,这是一个专门处理卫星图像和其他地球观测数据云端运算平台(图3)。该平台提供丰富的API以及工具帮助方便查看、计算、处理、分析各种影像等GIS数据。Earth Engine编程包括JavaScript版的API和Python版的API两个接口,本实验使用的是JavaScript API在线编辑器,编辑器界面如图4所示。
图4 Earth Engine在线编辑器界面
2.2 实验数据
Landsat 8数据可以更好地区分植被和非植被区域,短红外波段可应用于云检测。Landsat 8上的遥感器具有指向偏离航迹一个角度获取信息的能力,可以收集到本来要后面的轨道圈才处于卫星下面的地面信息。有助于及时获取需多时相对比研究的图像。
因此本文使用遥感数据Landsat8 OLI/TIRS,通过GEE平台在线调用、处理。样本点数据来源谷歌地球历史数据。水稻种植的区域都是比较平缓,因此还用到了DEM高程数字模型数据。
2.3 数据预处理
Landsat8 OLI/TIRS影像产品,已经过辐射矫正、几何矫正和大气矫正等数据预处理。2019年内覆盖研究区的影像总共有35幅。因研究区水稻生长期间(5月到11月)多云雨,云的存在影像质量不高,必须对影像进行去云处理。GEE在线编程中,去云采用CFMASK算法,调用updateMask(mask)函数。Landsat8 OLI/TIRS影像产品去云代码如图5所示。

图5 Landsat8去云代码
对其进行云量筛选后,去云的地方就会有数据缺失,出现了“空洞”现象,通过扩大时间范围(5月到12月)填补缺失的数据选取了覆盖研究区的21幅影像,然后通过平均值合成年内无云影像(图6)。

图6 均值合成代码
2.4 样本点
根据实地考察,研究区主要地物类型为林地、建筑用地、水体、草地、耕地,其他地类很少或没有,不宜参与分类,会降低分类精度。
由于提取的是水稻种植信息,耕地中水稻须单独挑出来。若直接在谷歌地球水稻样本点采集是很难的,因此根据研究区种植水稻的时间、环境,以及实地采集的水稻样本点和现场观察,积累先验知识,并根据实地采集的样本点在谷歌地球影像上的特点,才开始在谷歌地球通过目视解译采集样本点。实地采集的少数样本点和利用谷歌地球采集的多数样本点共686个,其中:林地82个、建筑用地123个,水体94个、水稻143个、草地98个、耕地146个。实地考察到水稻基本都是农户种植,没有其他大规模的集中种植,地类的灵活性很强,水稻田可能会有其他作物地块混在其中,其他作物地块可能出现一小块水稻田,这些噪声信息会提高分类难度以及降低分类精度。样本点处理代码如图7所示。

图7 样本点处理代码
2.5 植被指数
本文分类中用到的指数包括:归一化植被指数(NDVI)[20]、陆表水指数(LSWI)[21]、归一化建筑指数(NDBI)[22]、改进的归一化水体指数(MNDWI)[23]、增强型植被指数(EVI)[24]和三角植被指数(TVI)[25],计算公式如表2所示,其中:NIR为近红外光反射;RED为红光反射;SWIR为中红外光反射;BLUE为蓝光反射;L为土壤调节参数;Green为近绿外光反射。
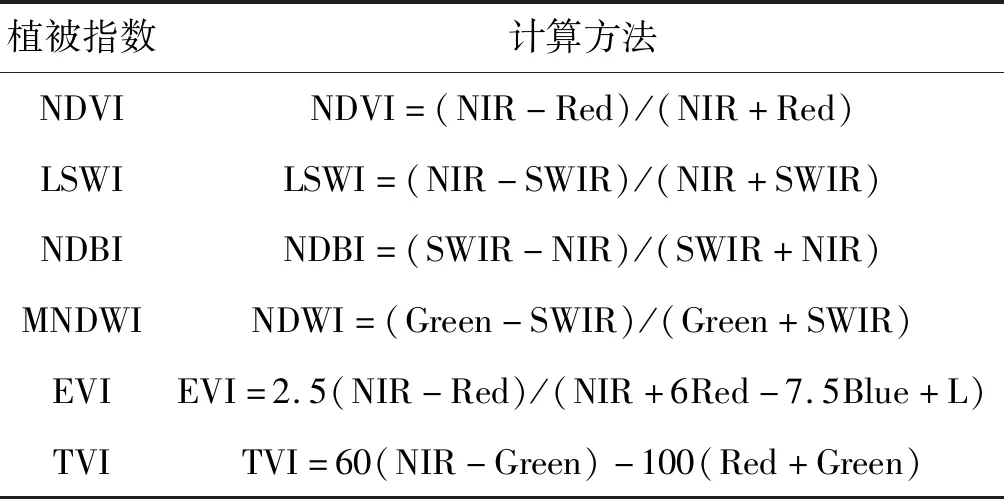
表2 植被指数计算公式
2.6 特征构建
本文在GEE云平台构建光谱特征、纹理特征、地形特征进行水稻信息提取。光谱特征包括11个原始光谱波段和6个植被指数作为一个独立的光谱波段添加到原始影像中;纹理特征选用相关性(CORR);地形参数包括坡度(slope)。
2.7 分类算法
(1) 分类回归树(CART)。CART可以用于分类和连续变量的预测[26]。当目标变量为离散值时称为分类树;当目标变量为连续值时称为回归树[27]。CART算法采用二分递归分割的技术,采用经济学中的基尼系数(Gini Index)作为选择最佳测试变量和分割阈值的准则[28]。基尼系数的数学定义如下:
(1)
(2)
(3)
生成的完整决策树必须进行修剪,然后再用测试数据对修剪以后的局册数进行测试[29]。GEE在线调用分类回归树代码如图8所示。

图8 调用分类回归树分类器代码
(2) 支持向量机(SVM)。支持向量机是一种具有最大间隔的线性分类器,可以通过核函数解决非线性的问题。支持向量机是一种重要的统计学习算法,它是一种基于结构风险最小化、优化和核函数的线性分类器。SVM是一种非参数方法,即使数据不符合标准概率密度分布,也可以工作。SVM分类器泛化能力强,样本数据的数量不需要太多,适用于遥感分类[30-31]。GEE在线调用支持向量机代码如图9所示。
(3) 最大熵模型(MaxEnt)。生物学家Jaynes[32]在1957年第一次提出了最大熵模型原理,他把最大熵问题当作是一个带约束条件的最优化问题。近年来,最大熵模型逐渐被应用到遥感领域,在已知条件下,熵最大的地类最接近它的真实地类,因此最大熵模型可以用于遥感图像分类。GEE在线调用最大熵模型代码如图10所示。

图10 调用最大熵模型分类器代码
(4) 集成学习(Ensemble Learning)。集成学习通过构建多个学习器来完成学习任务,有时也称为多分类器系统(Multi-classifier System)、基于委员会的学习(Committee-based Learning)等。通过结合多个学习器,集成学习通常可获得比单一学习器显著优越的泛化性能。要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有 “多样性”,即学习器间具有差异[33]。集成学习过程如图11所示。在线编辑集成学习代码如图12所示。
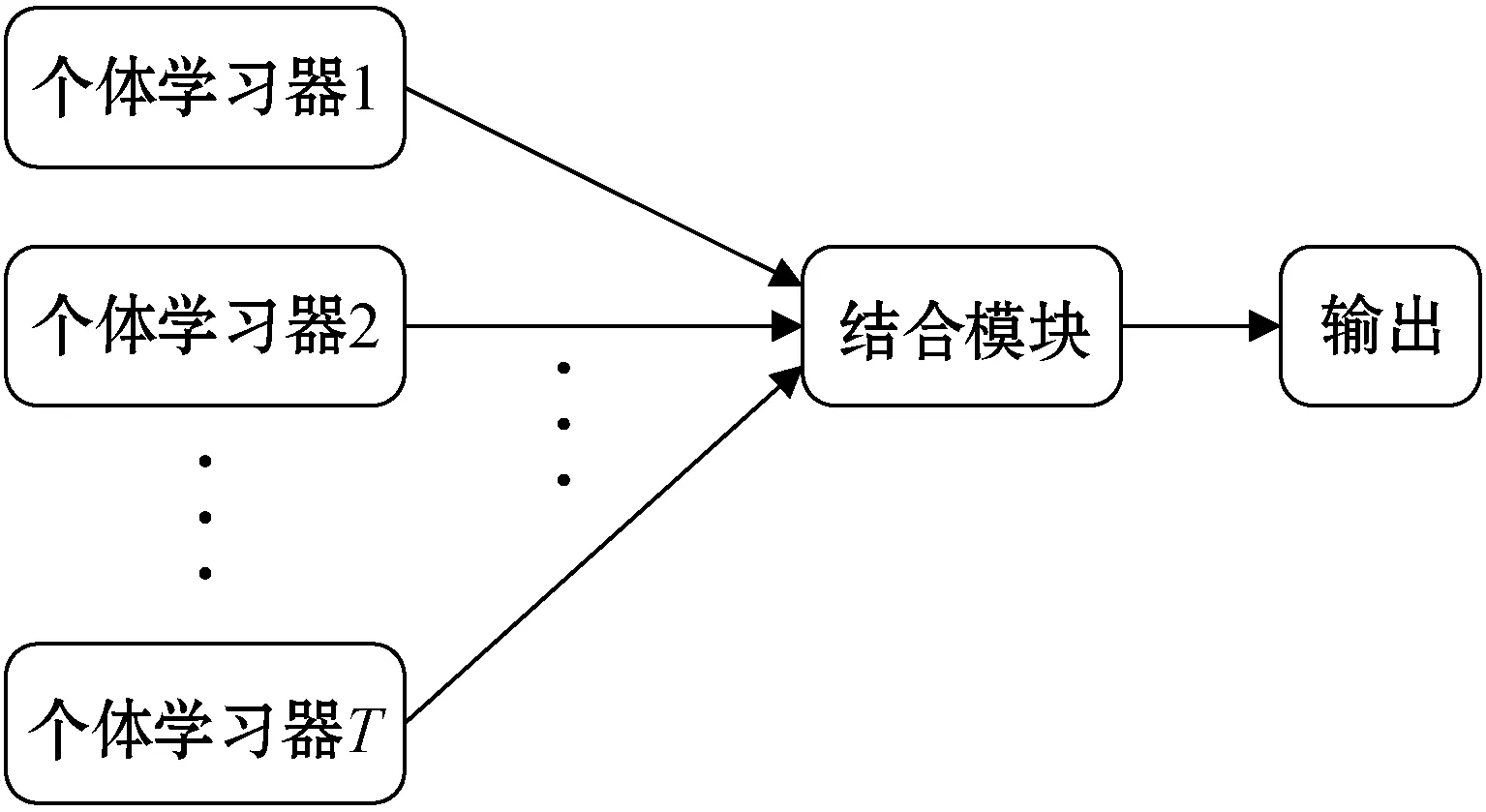
图11 集成学习过程示意图
图12 集成学习代码
3 结果与分析
3.1 植被指数时间序列分析
水稻容易和耕地混淆,需要构建容易区分这两类地类的特征,根据水稻的生长特点,结合归一化植被指数NDVI和陆表水指数LSWI能够有效区分水稻和耕地。在GEE平台上选择每类地类各7个样本点,对每类地物各时相进行了均值计算,得出研究区2019年的5月到12月的NDVI、LSWI变化曲线如图13(a)和图13(c)所示,可以看出变化曲线出现了异常点、断点的情况,这是由于植被指数会受到外界因素的干扰。因此有必要对NDVI和LSWI变化曲线进行平滑处理,尽可能达到降低噪声、减少误差影响的目的[34]。本文采用谐波分析HANTS(图14)对研究区的NDVI和LSWI进行平滑处理,结果如图13(b)和图13(d)所示,经过平滑处理后的曲线更接近真实地类的变化规律。
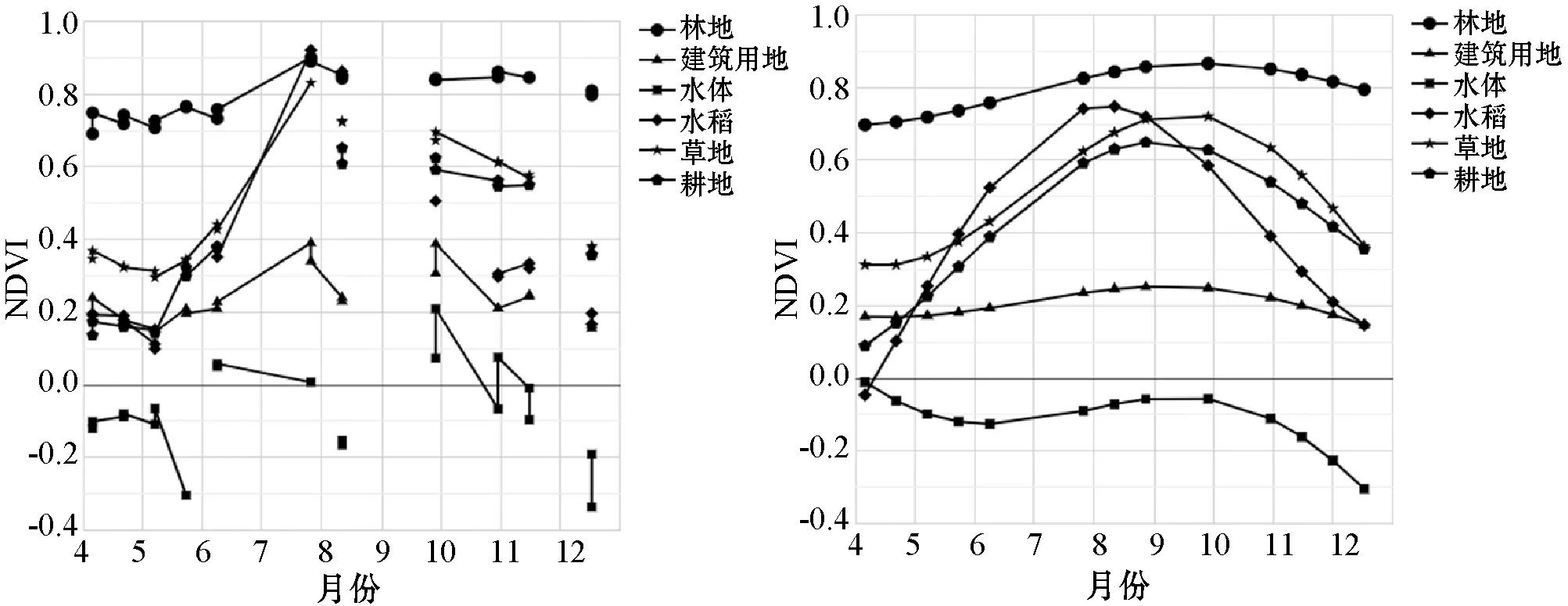
(a) 6类地物的NDVI曲线 (b) 平滑后的NDVI时间序列
NDVI反映了植被覆盖度,从平滑后的时间序列曲线可以看出,非植被(水体、建筑用地)在整个时间序列的值都较低,植被有明显的先升后降的趋势。林地一年四季没有太大变化,NDVI一直处于较高的状态。水稻、耕地、草地的变化趋势类似,4月份水稻田还在休耕状态,NDVI较耕地、草地低;6月份水稻移栽到水田,NDVI值呈现上升趋势,且上升速度快于耕地和草地;7月份达到最大值一直持续到8月份,且高于耕地、草地;9月份到10月份是水稻成熟的季节,水稻依次经历了乳熟、蜡熟、完熟,NDVI值呈现下降趋势,速度快于耕地和草地;11月份水稻前前后后收割完毕,NDVI较耕地、草地低。LSWI反映了土壤湿度和植被含水量,本文在利用NDVI提取水稻的基础上,还根据水稻特有的灌水移栽期,进一步提取水稻种植信息。
因此,可以综合利用水稻移栽期、生长期、收获期的NDVI、LSWI均值合成作为特征提取水稻种植信息。6类地类移栽期、生长期、收获期的NDVI均值合成图如图15(a)所示;6类地类移栽期、生长期、收获期的LSWI均值合成图如图15(b)所示。
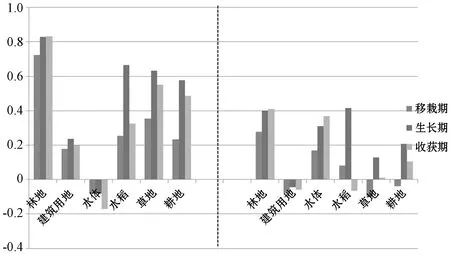
(a) 各地类NDVI均值 (b) 各地类LSWI均值图15 NDVI、LSWI均值合成
可以看出,移栽期水稻的NDVI均值和耕地的差别较小,和其他地类差别较大,LSWI均值和其他地类差别都较大;生长期水稻的NDVI均值和水体的差别较大,LSWI均值和建筑用地差别较大,NDVI和LSWI均快速增大;收获期的水稻NDVI、LSWI和其他地类的差别较大,且水稻收获期的LSWI已降为负值。
3.2 分类方法结果对比
本文使用的精度评价方法是混淆矩阵,是一个用于表示分为某一类的像元个数与地面检验为该类的数的比较阵列。一般阵列中的列代表参考数据,行代表遥感数据分类得到的类别数据。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同方面反映了图像分类的精度[35-36]。
根据以上构建的水稻提取特征,进入分类器分类。利用谷歌地球采集到的686个样本点,验证分类结果。其中林地82个、建筑用地123个、水体94个、水稻143个、草地98个、耕地146个。本文选取的年份是2019年,缺少研究区2019年的统计年鉴数据,因此利用研究区2018年的统计年鉴数据与本文结果进行对比分析。根据统计年鉴,研究区2018年水稻总种植面积75 km2。以此数据为参考,分别计算5种方法的面积提取精度,面积精度计算公式为:
式中:Ai是遥感影像提取的面积;A0是统计年鉴数据。评价指标除了面积精度,还可以利用GEE平台提供的混淆矩阵进行精度评价。4种分类方法提取的水稻面积以及各种评价指标如表3所示。
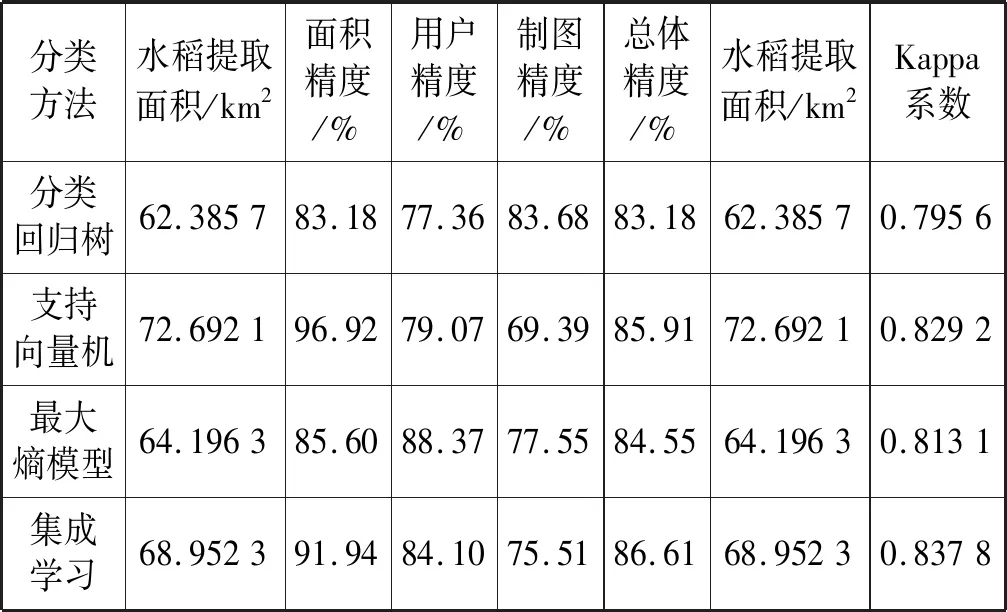
表3 水稻种植信息精度评价分析表
可以看出,集成学习相较于分类回归树、支持向量机、最大熵模型总体精度提高了3.43百分点、0.7百分点、2.06百分点。集成学习分类的面积精度91.94%、用户精度84.10%、制图精度75.51%、总体精度86.61%,集成学习较其他四种分类法稳定、可靠,能够有效区分水稻与耕地、草地等相似地类,因此利用集成学习方法提取研究区2019年水稻种植信息。用集成学习分类的混淆矩阵如表4所示。
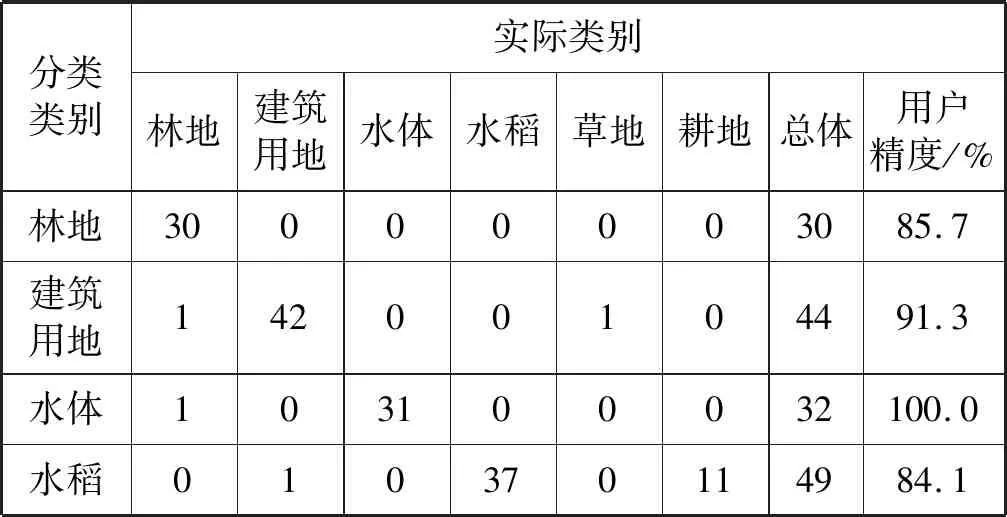
表4 随机森林分类混淆矩阵
本文使用的是Landsat 8影像,影像空间分辨率为30 m,研究区地块比较破碎,有可能出现影像一个像元内覆盖多种作物,加大了分类难度。“同物异谱”和 “异物同谱”的现象,严重影响分类精度,从混淆矩阵可以看出11个水稻样本点错分成了耕地,6个耕地样本点又错分成水稻,造成误分、漏分。
3.3 研究区2019年水稻种植空间分布
根据构建的分类特征,用集成学习方法提取研究区2019年水稻种植空间分布信息(图16)。
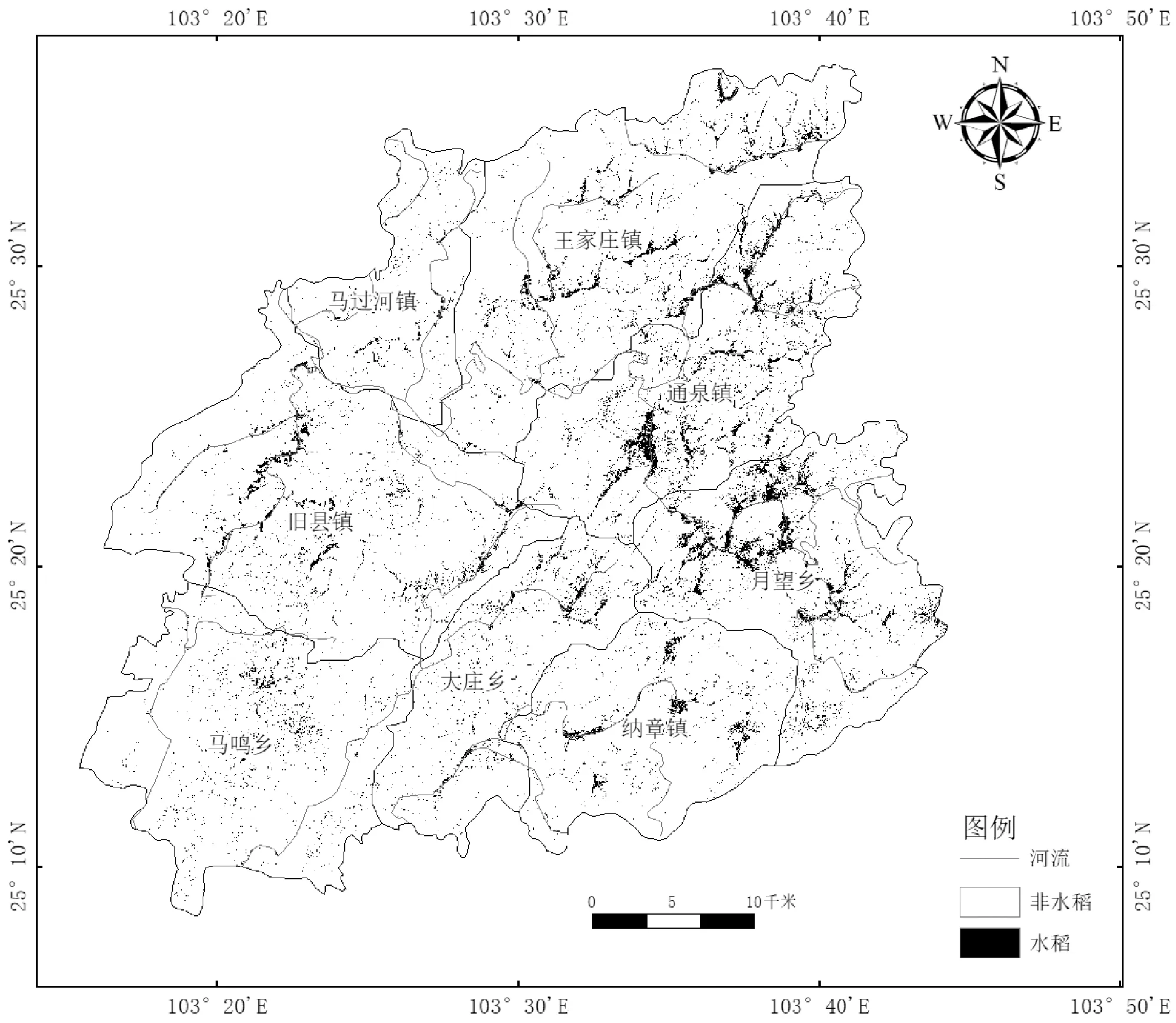
图16 2019年马龙区水稻空间分布
可以看出,提取出来的水稻种植信息比较破碎,因为研究区属云贵高原的滇东北高山丘陵区,农户种植的水稻分散、规模小。其次是大部分分布在王家庄镇、通泉镇、月望乡,聚集的部分基本是靠近河流以及人工水库,因为这些地方小坝子相对较多,相对于其他地方来说比较平缓,适合种植水稻,且人口比较密集,对水稻有需求。
4 结 语
本文基于GEE云平台,以机器学习领域的集成学习方法提取研究区水稻种植信息取得一定成效,说明本文方法可应用于地块破碎、种植作物类型复杂的高原山区作物种植信息提取。研究区属于云贵高原滇东丘陵区,地形复杂,水稻种植规模小、分散,很容易和其他农作物种植信息混在一起,构建分类特征是关键点。根据实验过程和结果,本文得出以下结论:1) 归一化植被指数(NDVI)、陆表水指数(LSWI)是区分水稻与其他地类的关键植被指数;2) GEE云平台与智能机器学习方法集成学习的结合能够快速、高效地提取研究区水稻种植信息,水稻提取面积为68.952 3 km2,总体精度86.61%,Kappa系数0.837 8;3) 马龙区水稻分布在王家庄镇、通泉镇、月望乡,聚集的部分基本是靠近河流以及人工水库地带。
但是,本文研究区水稻生长期间多云雨,去云之后很容易有数据缺失;采集样本点时很难获取到研究区水稻生长期的影像。虽然采用了集成学习方法,但是最终结果还不是很理想,地块破碎会造成误分现象,特别是水稻容易和耕地混淆,水稻的用户精度只达到84.10%,制图精度达75.50%。因此,今后可以考虑融合Landsat数据与高时间分辨率影像数据,以此融合的数据和本文的方法结合进一步提高分类精度。
猜你喜欢
农业机械学报(2019年6期)2019-06-27
水土保持研究(2018年5期)2018-10-12
电子制作(2018年11期)2018-08-04
中国农业信息(2018年2期)2018-07-28
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
测绘科学与工程(2016年5期)2016-04-17
西藏科技(2015年1期)2015-09-26
电子设计工程(2015年3期)2015-02-27
