
基于阵列处理器的SVDC算法并行设计与实现
2023-11-02 12:36黎瑞金
计算机应用与软件 2023年10期
蒋 林 黎瑞金 曹 非
1(西安科技大学计算机科学与技术学院 陕西 西安 710600)
2(西安科技大学电气与控制工程学院 陕西 西安 710600)
0 引 言
近年来3D视频在各行各业中有着广阔的应用场景。在基于3D-HEVC的三维视频编码技术中,编码模式的选择采用了率失真优化方法,深度图的失真会导致合成视点的失真,所以我们可以通过测量合成视点的失真来替代深度图的失真,保证虚拟合成视图的质量[1]。因此,Tech等[2-4]针对深度数据的失真度量提出了应用3D-HEVC的视点合成失真变化算法。这种算法具有高级视图算法的所有基本功能,例如像素变化、差值、空洞填充以及融合,使得编码端可以在率失真优化过程中直接计算合成视点失真。但是,这种方法需要在编码过程中执行基于像素级的视点合成与失真值计算操作,引起频繁的访存操作,导致过高的编码复杂度以及较低的算法性能。为了解决SVDC这种数据密集型算法的计算复杂度过高的问题,Ma等[5]提出了一种通过设置三种合成视点零差异条件下提前终止SVDC计算过程的模型,但是传统处理器串行化的计算方式仍使得SVDC算法的性能提升有限。
针对上述问题,本文基于阵列处理器的SVDC并行算法,采用分布式共享存储结构(Unified addressing Distributed Shared Memory Structure,UaDSMS)[7]实现了多视点并行计算。充分利用了阵列处理器的并行特性进行算法映射,并根据算法的访存特性做出优化,使得SVDC算法的性能得到较大提升。
1 阵列处理器及分布式共享存储结构
项目组前期开发的阵列处理器由多个处理单元(Processing Element,PE)构成,该PE的结构如图1所示[6]。每个PE分别由ALU单元、寄存器单元、左路数据选择单元、右路数据选择单元、fanout单元和配置单元组成。

图1 PE结构
此阵列处理器结构由16个PE组成一个簇,采用了4×4的矩阵结构,单个PE的数据访存位宽是16位。其中分布式共享存储结构如图2所示[7],此存储结构下层为16个同样排列结构512 bit×16 bit大小组成的RAM,中间是采用了全交换结构(Full Switching,FS)的高速访问单元,上层为16个PE组成的簇,这种结构是一种最直接且并行度最高的高速交换单元结构。

图2 分布式共享存储结构
分布式共享存储结构的主要优势如下:1) 从逻辑上分析,整个片上存储采用相同的编址方式。2) 从物理上分析,采用多个分布式存储块,实现片上存储的并行访问,支持簇内请求的无冲突并行访问。
根据以上分析,我们发现具有“逻辑共享、物理分布”特性的分布式共享存储结构所表现出的并行化设计优势,非常适合SVDC算法数据密集的特点。
2 SVDC算法并行化设计
2.1 SVDC算法并行性分析
SVDC算法可以通过联系合成视点失真与深度图失真,计算当前合成视点中由于深度值变化所产生的全部失真值,从而提升深度图编码的率失真优化效果,并且可以同时考虑当前深度图编码块周围像素的深度值变化情况。因此,SVDC算法被定义为计算两个合成视点的失真值之差:
(1)

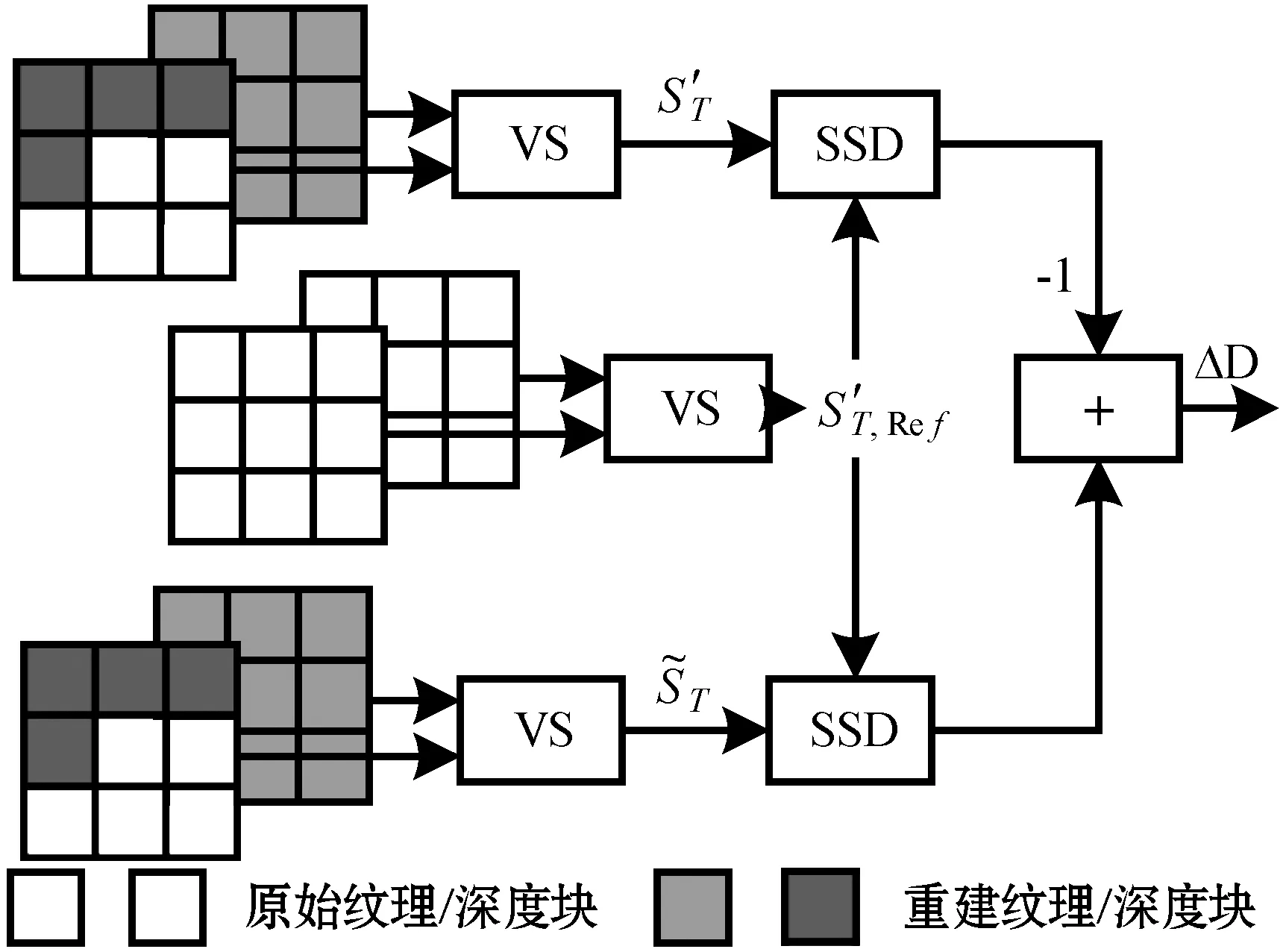
图3 SVDC算法流程
由图3可以看出SVDC算法在计算过程中,每一次SVDC计算都要经过三个合成视点进行SSD计算,其中每一个合成视点都是由原始纹理图帧、原始深度图帧和重建纹理图帧、重建深度图帧分别求得,大量的SSD计算会出现频繁的访存操作。传统处理器串行化的计算方式会使得算法的性能难以提升。针对以上的问题,本文将基于阵列处理器和分布式共享存储结构,实现多视点SSD并行计算,通过簇内PE阵列处理器的并行执行,实现对SVDC算法的加速。
2.2 SVDC算法并行化映射
SVDC算法主要可分为虚拟视点合成以及失真值计算两大部分。图4是SVDC算法的阵列处理器映射结构。共调用4个簇的资源,PE00簇负责预处理,PE01簇负责3D-warping,PE11簇负责空洞填充,PE10簇负责失真值计算,下面为各个簇的工作安排。
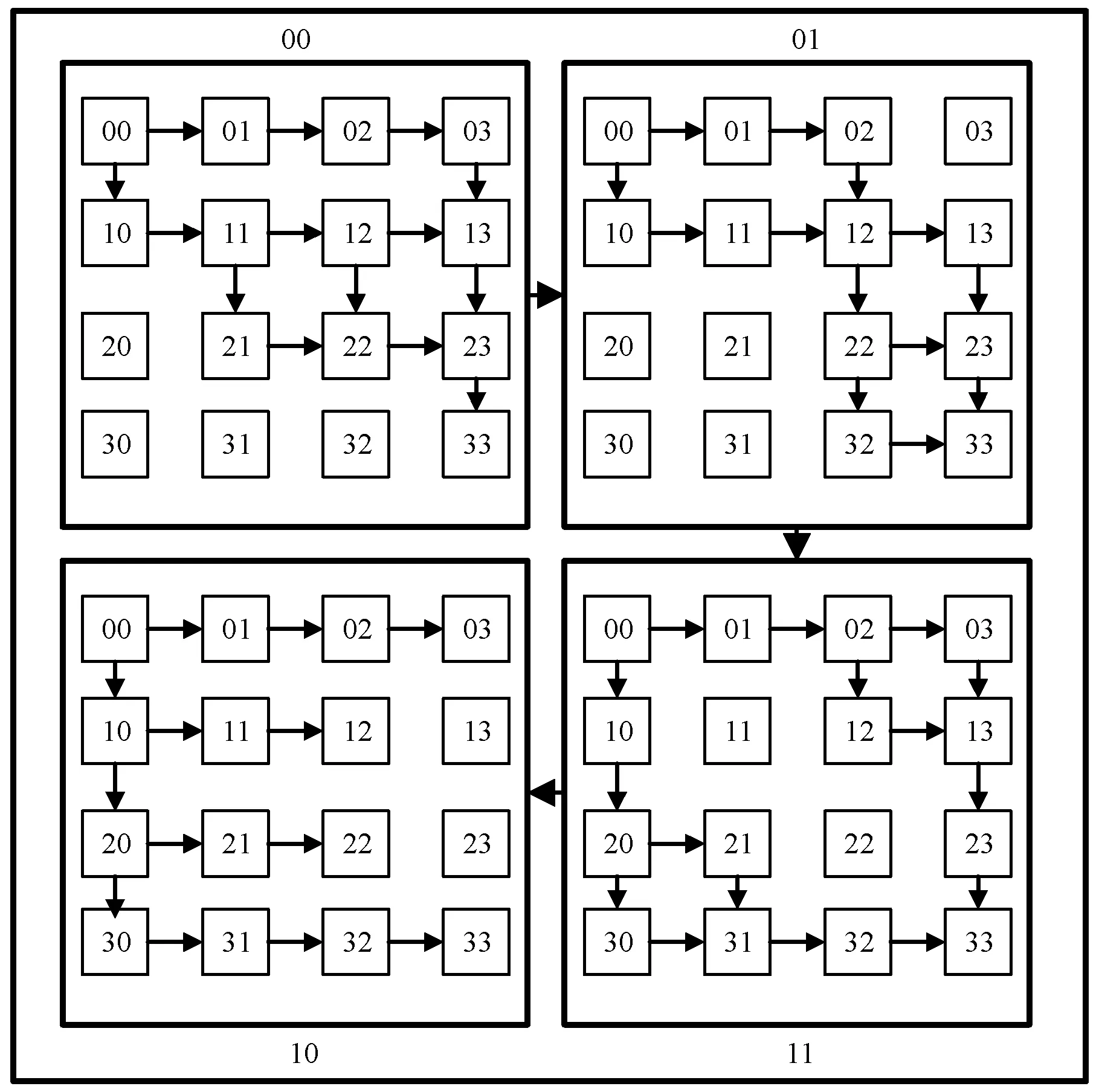
图4 SVDC算法映射结构图
PE00号簇:00号簇从外部存储设备加载相机参数并将数据暂时存入00号簇的RAM中。如图5所示针对深度图进行中值滤波预处理,使用01、02、03、11、12、13、21、22、23号PE,分为三步进行中值滤波。
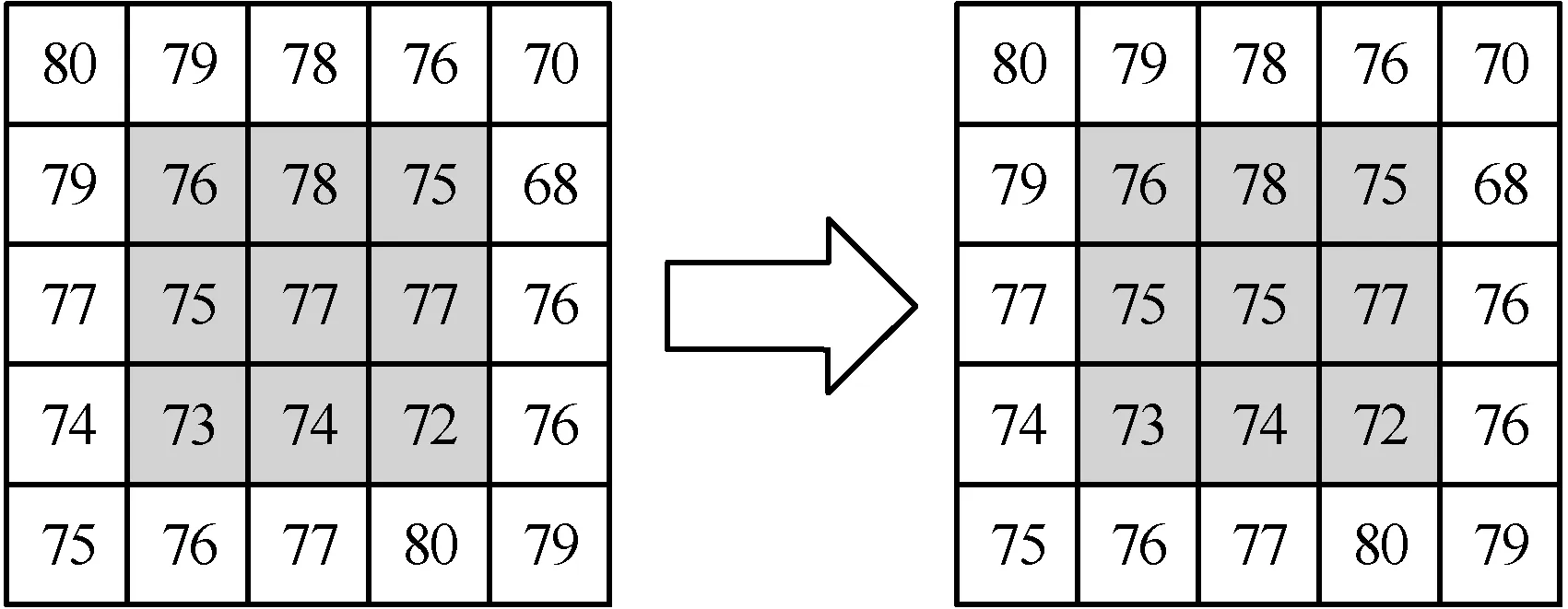
图5 预处理中值滤波
Step1:将从外部存储设备加载的数据以3×3的像素块为单位,每行从大到小排序,分别取得大、中、小三个值。
Step2:对大值行即第一列进行比较,对小值行即第三列进行比较,取其中的大值与小值。
Step3:把三行的中值与第二列相比较,再取一次中值。将小值、中值和大值进行比较与排序,获得的中值即为该像素块的中值。
PE01号簇:3D-warping是产生虚拟视点的核心技术,它将先提取图像帧的深度图信息,再根据深度图信息,把参考纹理图的视点信息投射至3D空间坐标,最后投射到2D空间坐标的目标视点。这种方法需要摄像机参数,其中内部相机参数用A表示,外部相机参数用R与t表示。
(2)
式中:r代表参考视点;Zr是参考视点在(ur,vr)位置的深度值,首先我们利用内部相机参数A将3D相机的坐标映射到2D空间的虚拟视点中去,再取一个参考视点的像素坐标(ur,vr),最后利用深度图信息将像素坐标映射到世界坐标中的(Xw,Yw,Zw)位置中。
(3)
(4)
式中:v表示8比特的深度值,其中z、Znear和Zfar都被设定为正值或负值。如式(4)所示,其中(Xw,Yw,Zw)是式(2)映射到3D空间的坐标,3×3的旋转矩阵R与3×1的平移矩阵是摄像机参数。
PE11号簇:空洞填充作为虚拟视点合成中的难点,长期以来影响着该领域的发展[9]。本文通过人工识别空洞点的方式,通过汇编指令向PE下发指令,针对空洞部分采集邻近像素点的信息,再逐步进行空洞点的像素填充。这里共调用10个PE,首先由00号PE将数据分发至02、03、12、13、20、21、30、31号PE,然后各PE采集邻近像素点的信息,并将其填充进空洞部分,最后各PE将结果传送到33号PE,准备送入10号簇进行失真值计算。
PE10号簇:失真值计算,由于失真值计算涉及大量合成视点的SSD计算,存在频繁的访存操作以及冗余的编码复杂度,本文利用阵列处理器及分布式共享存储的并行设计优势,实现了多视点SSD并行计算。
2.3 失真值计算设计与优化
失真值计算作为SVDC算法的核心步骤,频繁的访存操作会使得算法出现大量的数据移动。本节作者在使用单元级SSD计算映射方案实现后,通过优化访存时序,提出了像素级SSD计算设计。
(1) 单元级SSD计算设计。以8×8像素点的图像块为例,具体操作如图6所示。
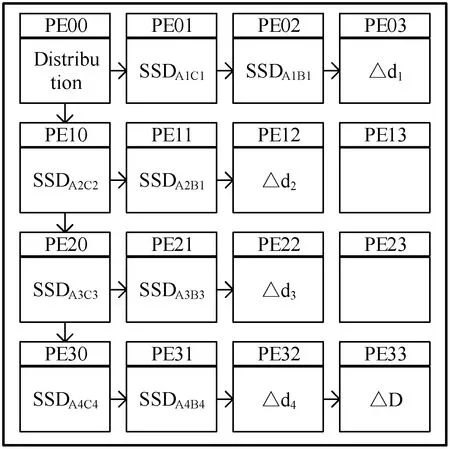
图6 单元级SSD计算
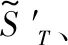
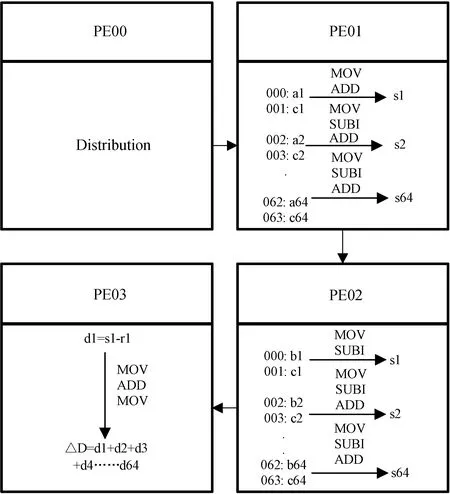
图7 像素级SSD计算设计结构图
这种不同于传统处理器串行访存特性的处理方式,完全依赖于本文所用到的阵列处理器与分布式共享存储结构。其中单个PE对本地RAM的无阻塞访问以及簇内无冲突的并行访问极大地提高了运算资源利用率。使用像素级SSD计算替代单元级SSD计算,可以使失真值计算提升39.3%的时间性能。
3 实验分析
3.1 验证方案
为了评估本文所提出SVDC算法并行设计的性能,我们采用3D-HEVC参考软件HTM-16.1[12]作为对比平台。选用四个JCT-3V小组建议的标准序列作为测试用例,包括“Balloons”“Kendo”“GTFly”“PoznanStreet”进行测试,量化参数(QP)为(25,34)。本文使用基于项目组提供的DPR-CODEC结构精简指令集经过转码后的二进制代码在modelsim中进行基本功能仿真验证。
3.2 实验结果与性能分析
将本文实现的SVDC算法计算性能分别与文献[4]、文献[5]与文献[10]的计算性能进行对比,如表1所示。其中ΔT表示本文在SVDC算法计算相比于HTM-16.1平台中计算节省时间百分比,Δt表示并行编码相比于串行编码节省时间百分比,ΔS表示像素级SSD计算相比单元级SSD计算节省时间百分比。
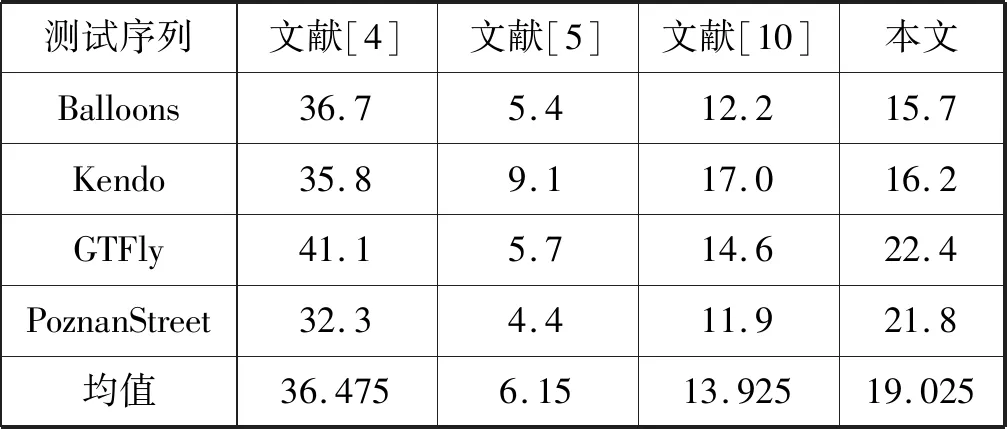
表1 不同方法的编码时间对比(%)
(5)
(6)
(7)
其中文献[4]所提出的RM渲染器在编码端将SVDC算法分为初始化、部分重渲染以及SVDC计算共三部分,通过RM渲染器在初始化后存储中间变量并进行快速重渲染过程,大幅度降低编码复杂度。针对深度图编码越复杂的测试序列,RM渲染器提升越大,与本文相比在视点合成部分有较大的编码优势。文献[5]提出的零合成视差模型考虑了深度-视差映射,纹理适应和遮挡三种效果用于视点合成优化。文献[10]提出了的视点合成优化方法,相比原方法增加了跳过零失真的较小模块或像素行的过程。文献[5]与文献[10]仍着重于对视点合成部分进行优化,但是失真值计算却依旧采用传统的串行编码方式。经过实验得到如表1所示实验数据,可以发现本文提出的SVDC算法并行化设计相比于文献[5]与文献[10]可以获得更快的编码时间,但是未能超过文献[4]的RM渲染器模型。相较于HTM原始算法,本文的算法性能平均可以提升19.025%。
为了证明并行编码方式的有效性,如表2所示对四个不同测试序列测试四个8×8的像素块,分别使用串行编码方式(单PE)以及并行编码方式(多PE)进行失真值计算,并行编码方式分为单元级SSD计算以及像素级SSD计算。实验结果可知,相比于串行编码方式,本文提出的并行编码方式可以提升57.6%的计算性能,串/并加速比平均可以达到2.36,相比于单元级SSD计算,本文提出的像素级SSD计算优化设计可以提升39.3%的计算性能。从表2中可看出,当像素块越复杂,像素级SSD计算的Δt就越大,这得益于像素级SSD计算设计通过重新划分计算与访存时序,提高了计算访存比,减少了PE单元的空闲时间。
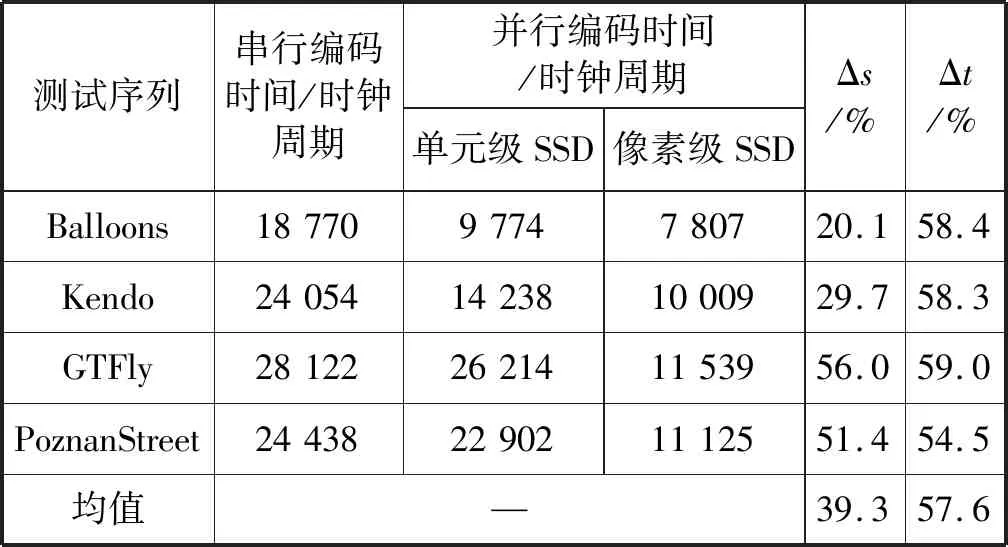
表2 串行编码与并行编码失真值计算性能分析
由于整个SVDC算法中涉及大量的SSD计算,阵列处理器以及分布式共享存储结构可以在簇内提供16个位宽为16位的数据读写访问通道,支持单个像素点的数据存取,其中单个PE拥有对本地RAM的优先访问权,读操作与写操作分别可以在1与2个时钟周期内完成,使得PE的数据访存难度降低,可以大幅度提高SVDC计算的性能。
如图8所示,对8×8的像素块使用不同处理器规模进行失真值计算性能分析。实验结果表明,当使用的PE核数增多时,算法并行度的提升将导致性能逐步提升,但是由于核数的增多、数据访存量的增大会造成算法并行化设计愈加复杂。后续的工作中将对于如何提高PE的资源利用率以及如何设计出更高并行度的算法映射方式展开研究。

图8 不同处理器规模下失真值计算分析
4 结 语
本文基于阵列处理器及分布式共享存储结构,提出了一种针对SVDC算法的并行映射实现方法。首先通过加载相机参数并进行中值滤波对图像进行预处理,其次进行3D-warping与空洞填充合成虚拟视点,最后进行失真值计算。以8×8的像素块为单位,进行多视点SSD计算,利用一个簇的运算资源得到4个块共计256个像素点的SVDC失真值。同时根据算法访存特性,使用像素级SSD计算设计替换单元级SSD计算设计以提高运算资源利用率与算法性能。实验结果表明,相比于HTM平台,本文所采用的阵列处理器实现的SVDC算法,其时间性能平均可以提升19.025%,所设计的失真值计算并行方案的串/并加速比为2.36,相比于单元级SSD计算,像素级SSD计算优化设计可以提升39.3%的计算性能。使用不同处理器规模对8×8的像素块进行失真值计算性能分析表明,随着处理器核数的增多,算法计算性能会逐渐提升,但是数据访存量的增大会造成算法并行化设计愈加复杂。后续的工作中将对于如何提高PE的资源利用率以及如何设计出更高并行度的算法映射方式展开研究。
猜你喜欢
计算机应用(2019年3期)2019-07-31
软件导刊(2016年9期)2016-11-07
科技视界(2016年2期)2016-03-30
河南电力(2016年5期)2016-02-06
新闻前哨(2015年2期)2015-03-11
中国水利(2015年5期)2015-02-28
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
上海大学学报(自然科学版)(2012年5期)2012-10-16
中国校外教育(上旬)(2009年6期)2009-08-04
