
非平衡情感数据背景下基于边界度的过采样方法
2023-11-17 02:45郑森ZHENGSen齐晓轩QIXiaoxuan柳亿霖LIUYilin
价值工程 2023年31期
郑森 ZHENG Sen;齐晓轩 QI Xiao-xuan;柳亿霖 LIU Yi-lin
(①沈阳大学机械工程学院,沈阳 110000;②沈阳大学应用技术学院,沈阳 110000)
0 引言
情感分类是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[1]。随着互联网技术的普及,越来越多的用户会在网络平台上发表带有主观情感的评论,对用户情感以及需求的分类成为网络平台重点关注的技术之一。情感分类是对文本作者倾向性观点、态度的划分,所以又被称为观点分析、倾向性分析等。其目的是根据文本所表达的含义和情感信息将文本划分为积极或消极的两种或多种类别,机器学习是目前解决情感分类问题的主流方法[2]。现实中收集到的情感数据往往存在数据不平衡问题,即不同类别的样本数量相差较大。在面对不平衡数据集时,传统分类方法为了确保整体分类性能最佳,往往会将少数类样本错分为多数类[3]。
SMOTE 算法[4]通过合成新样本的方式使得数据集达到平衡。但该方法未对少数类样本进行区分,导致合成样本质量不佳,造成数据冗余。针对SMOTE 算法存在的问题,本文提出一种基于边界度的过采样方法(BDSMOTE)。将BD-SMOTE 算法与SVM 分类器相结合,解决了不平衡情感数据分类问题,验证了该算法的有效性。
1 相关工作
1.1 情感分类方法
目前解决情感分类问题主要通过机器学习或深度学习的方法。陈璐[5]采用KNN 和SVM 对公司年报文本进行分类,验证了年报舞弊行为在文本语义分布的差异化。Xue[6]等用LDA 主题模型实现了对2200 万条Twitter 信息中与新冠肺炎相关的主题及情感的识别。孙铁铮[7]等构建了CNN、RCNN、FastText 和Transform 四种深度学习模型,通过实验证明了深度学习对问政文本具有较为理想的适用性。许浪[8]等提出了一种基于BERT、CNN 和BiLSTM 的医学文本分类模型CMNN,实现了网络问诊平台的自动准确科室推荐。
1.2 文本向量化
文本为非结构化数据,需要事先将文本转化为数值形式才能被计算机所处理。本文使用空间向量模型来表示文本:
其中,v 代表一段文本的向量,fi代表文本的第i 个特征属性,n 代表向量纬度,即字典长度。
TF-IDF 又称为词频-逆文档频率,是信息检索领域中常用的一种文本表示方法,用以评估词对文本的重要性。TF-IDF 认为一个词的重要程度与它在文档中出现的次数成正比,与它在语料库中出现的频率成反比。因此,TFIDF 可以很好的实现提取文档中关键词的目的,避免了纬度灾难。本文使用TF-IDF 对情感数据集进行文本向量化处理。
2 基于边界度的过采样方法
BD-SMOTE 算法的具体流程主要由三部分组成:首先,根据少数类样本xi的多数类最近邻和少数类最近邻计算xi的边界度;其次,根据边界度计算每一个少数类样本的采样权重;最后,根据权重自适应确定每一个少数类样本需要生成新样本的数量。
2.1 边界度
考虑位于分类边界附近的样本会携带更多信息,本文通过计算每个少数类样本的边界度来确定少数类样本在不平衡数据集中的分布。在后续过采样过程中,使靠近分类边界的少数类样本生成更多新样本,有效提高新样本质量。
给定一个不平衡数据集,如图1 所示,其中白色圆形为少数类样本,灰色圆形为多数类样本。对于每一个少数类样本xi,计算xi与最近的少数类样本间的欧式距离dist(xi,xmin)。以xi为圆心,以dist(xi,xmin)为半径形成的超球体称为xi的N 邻域,如图1 中的白色圆盘所示;类似的,计算xi与最近的多数类样本间的欧式距离dist(xi,xmaj)。以xi为圆心,以dist(xi,xmaj)为半径形成的超球体称为xi的J 邻域,如图1 中的灰色圆盘所示。N 邻域与J 邻域的并集称为NJ 邻域。
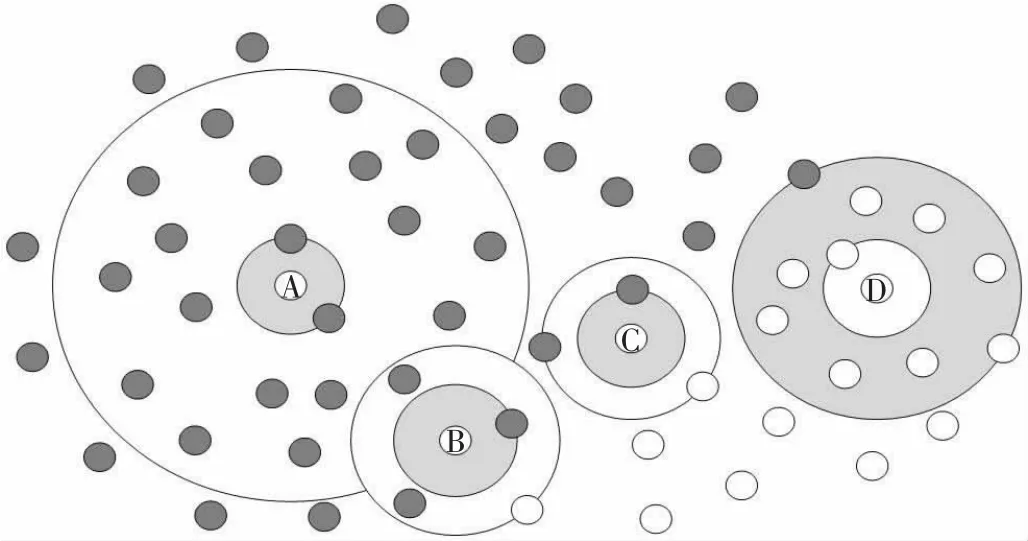
图1 少数类样本的邻域
xi的NJ 邻域内的多数类和少数类样本的数量可以反映xi在不平衡数据集中的分布。如果xi的NJ 邻域内少数类样本数量远大于多数类样本,则xi为安全样本,如图1中的D 样本;如果xi的NJ 邻域内多数类样本数量远大于少数类样本,则xi为噪声,如图1 中的A 样本;如果xi的NJ 邻域内少数类样本数量和多数类样本趋近相同,则xi为边界样本,如图1 中的B 样本和C 样本。基于上述分析,提出以下定义用于确定少数类样本xi在不平衡数据集中的分布:
定义1:边界度:少数类样本xi的边界度(si)定义为xi的NJ 邻域内少数类和多数类样本数量差值的平方:
其中,ai为NJ 邻域内少数类样本的数量,bi为NJ 邻域内多数类样本的数量。
2.2 自适应过采样阶段
针对SMTOE 算法未对少数类样本进行区分性选择,导致新生成样本质量不佳这一问题。本文提出了一种基于边界度的过采样方法,该方法根据少数类样本的边界度计算采样权重。在后续过采样过程中,通过权重自适应确定每一个少数类样本需要生成新样本的数量。
定义2:采样权重:少数类样本xi的采样权重(Wi)定义为xi的边界度的倒数:
其中,si为少数类样本的边界度,A 为修正参数,为了避免出现分母为0 的情况。
定义3:采样倍率:少数类样本xi的采样倍率(gi)定义为Wi与多数类和少数类样本数量差值的乘积:
其中,Wi为少数类样本xi的采样权重,G 为多数类和少数类样本数量的差值。
在后续过采样过程中,使用下式合成新样本:
其中,xnew为新生成样本,xi为种子样本,xn为候选近邻,rand(0,1)为0~1 的随机数。
由式(3)可知,少数类样本xi越靠近分类边界,其边界度越小,取倒数后式(3)的分子越大,那么xi的采样权重也就越大;相反,少数类样本xi越远离分类边界,其边界度越大,取倒数后式(3)的分子越小,那么xi的采样权重也就越小,因此,该算法不易受噪声影响。BD-SMOTE 算法确定了每一个少数类样本在不平衡数据集中的分布,并且不需要预定参数。在后续过采样过程中,BD-SMOTE 算法使靠近分类边界的少数类样本生成更多新样本,有效提高了新样本质量,避免数据冗余。BD-SMOTE 算法的具体流程如算法1 所示。

3 实验结果与分析
3.1 实验数据
为了验证BD-SMOTE 算法处理非平衡情感数据集的有效性,实验采用来自GitHub 的公开语料数据集Online-Shopping,语料包含书籍评论、电子产品评论、生活用品评论等,其中积极评论5000 条,消极评论2000 条,语料数据集部分样本如表1 所示。

表1 不平衡语料数据集部分样本
3.2 实验结果
为了验证BD-SMOTE 算法在处理非平衡情感数据时的性能,本文设计了5 种非平衡情感数据预处理与SVM分类器相结合的分类实验。实验1:原始不平衡数据集+SVM;实验2:原始不平衡数据集+SMOTE+SVM;实验3:原始不平衡数据集+Borderline-SMOTE+SVM;实验4:原始不平衡数据集+BD-SMOTE+SVM;实验5:原始不平衡数据集+SVM。非平衡情感数据选用Online-Shopping 语料数据集,其不平衡比率为2.5。使用二分类中常用的F1、G-mean和AUC 这3 个评价指标来评估分类效果。
由图2 可知,经过任何一种过采样方法预处理后的Online-Shopping 数据集的评价指标均优于原始数据集。所有过采样方法中,表现最差的为ADASYN 算法,经过分析得出原因,Online-Shopping 数据集中含有噪声,而ADASYN 算法易受噪声干扰;表现最好的为BD-SMOTE算法,证明了BD-SMOTE 算法解决非平衡情感数据分类问题的有效性。
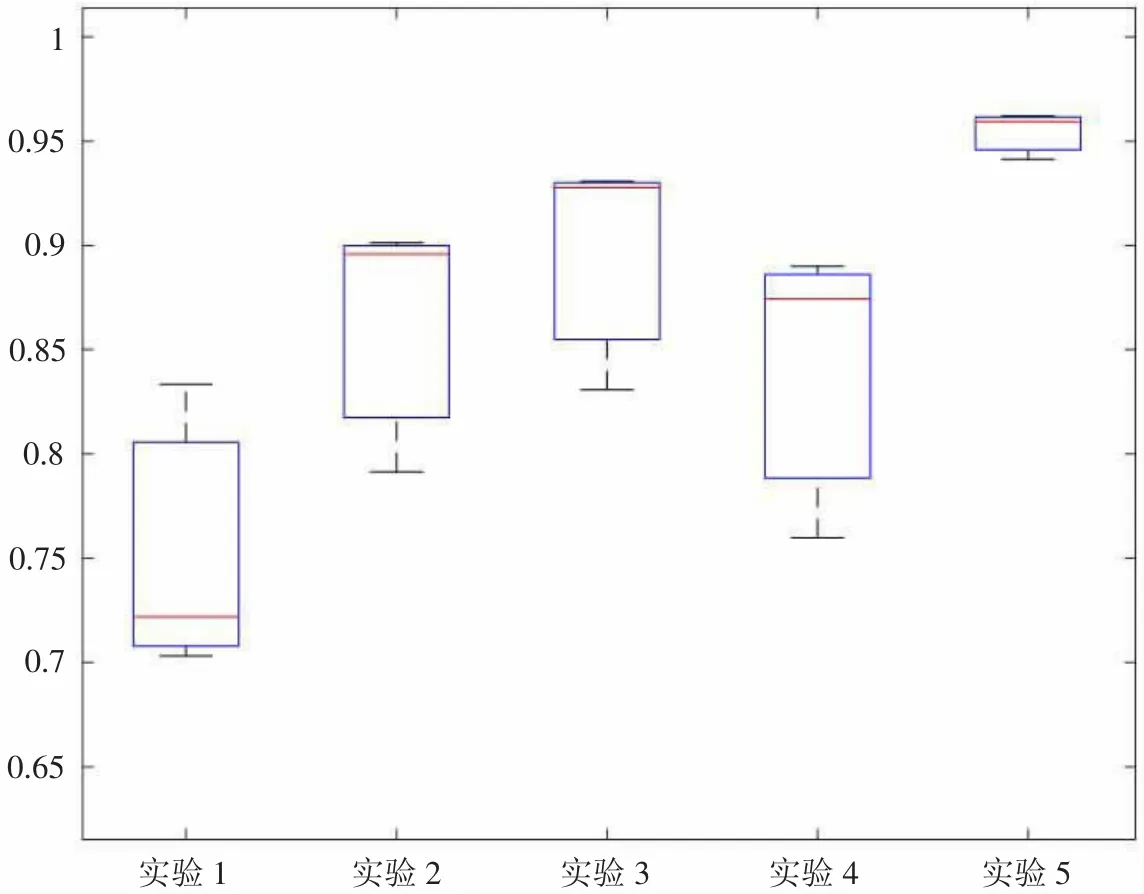
图2 非平衡情感数据分类实验结果
4 结论
本文提出了一种基于边界度的过采样方法。考虑位于分类边界附近的少数类样本会携带更多信息,选择为靠近分类边界的少数类样本生成更多新样本,有效提高新样本质量,并且该算法受噪声影响较小。实验结果证明提出的BD-SMOTE 算法在处理多个不平衡数据集时,其效果优于其他过采样算法,并且将BD-SMOTE 算法应用于不平衡情感数据集时,有效提高了分类准确率。未来可尝试将该算法应用到多类别的不平衡情感数据集当中,力求提升情感分类性能。
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
数学小灵通(1-2年级)(2021年4期)2021-06-09
吉林大学学报(理学版)(2020年3期)2020-05-29
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
证券法律评论(2018年0期)2018-08-31
自动化学报(2018年7期)2018-08-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
周口师范学院学报(2016年5期)2016-10-17
外语学刊(2014年6期)2014-04-18
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
