
基于机器学习的信用卡交易欺诈检测研究综述
2023-11-20 10:58蒋洪迅江俊毅
计算机工程与应用 2023年21期
蒋洪迅,江俊毅,梁 循
中国人民大学 信息学院,北京 100872
信用卡当前持卡规模和使用频度,其日常交易已经成为一种海量流数据,人工验证解决信用卡反欺诈显然不现实,只能采用基于机器学习的全自动化检测[1],如图1所示。目前机器学习在人脸识别、无人驾驶等工程领域获得非常广泛的应用。然而,在信用卡反欺诈领域,由于有人的智力介入,机器学习所面临的挑战远比工程领域的难度更高。大规模信用卡交易欺诈犯罪通常与暗网、有组织犯罪、国际贩毒、恐怖组织融资等社会深层问题相关联,使得任务更加复杂困难。随着国际互联网以及移动网络的普及,新技术为欺诈者提供了更便利的匿名环境、更大的覆盖范围和更快的尝试速度。鉴于机器学习对于信用卡欺诈识别至关重要,制订适当的策略或开发智能判别算法,将合法交易与欺诈交易区分开来,以阻止潜在欺诈交易的完成。
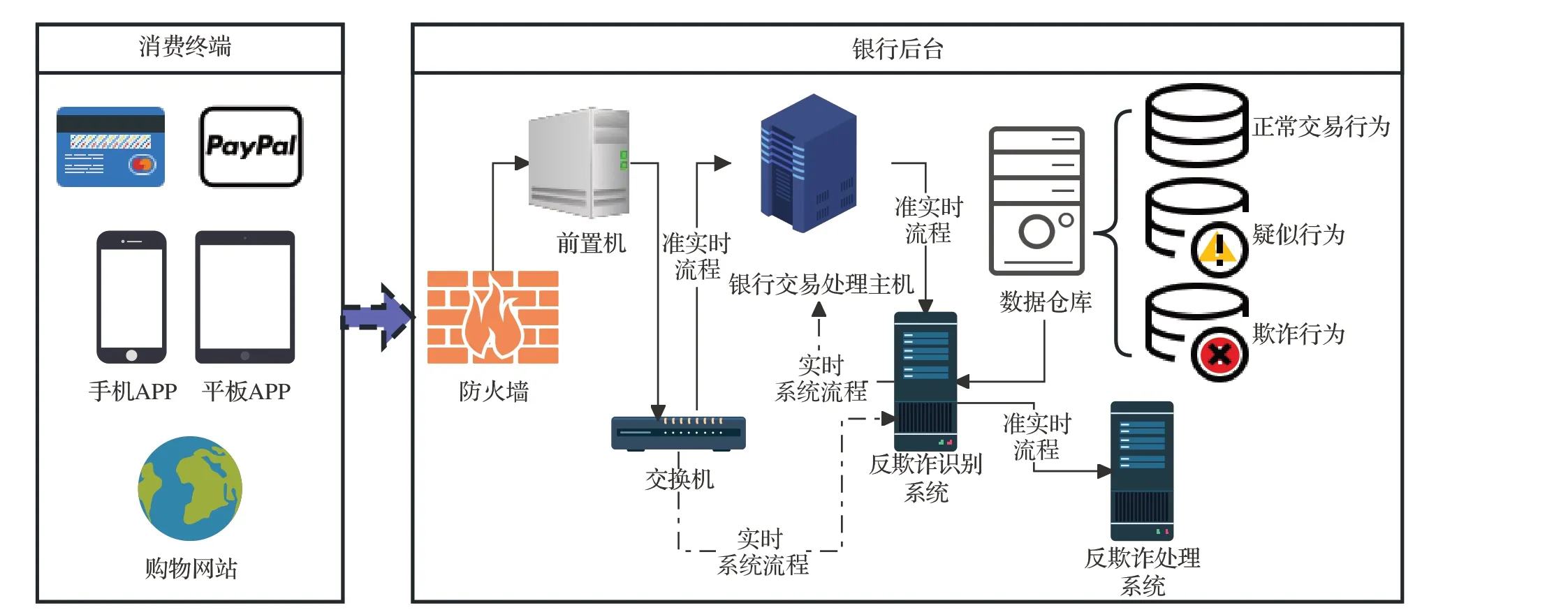
图1 包含反欺诈检测的信用卡交易过程Fig.1 Credit card transaction process with anti-fraud detection
信用卡交易欺诈检测的机器学习方法,是指在信用卡交易反欺诈场景中利用机器学习模型动态识别欺诈行为的计算机程序或软件系统,以阻断欺诈交易进行或中止结算,降低欺诈发生概率或减少欺诈产生的损失。信用卡交易反欺诈系统,按干预实时性划分,包含欺诈预防和欺诈识别两大部分,如图2所示。当新交易抵达时,欺诈预防自动执行一系列规则审查,诸如PIN 是否正确、信用额度是否充足等;欺诈识别属于深度检测,通过历史交易数据训练欺诈特征识别模型,一旦当前交易行为的欺诈概率超过预设阈值,系统将干预该交易[2]。比较而言,虽说欺诈预防采取了一些较高级技术机制,诸如数据加密、防火墙、地址验证、验证码等[1],但受制于实时响应要求,只能局限于有限规则而无法进行复杂运算,欺诈者只要采取针对性手段就能穿透系统。欺诈识别是更重要的反欺诈手段,按在线与否划分,将其分为在线和离线检测两个部分,前者通常是实时的、同步的即时反馈;后者是非实时的、异步的事后反馈[1]。在线即时反馈受到终端算力不足的限制和交易执行的即时性要求之间的矛盾,以及交易信息不完备性的影响,没有可能完成大量复杂计算,因此欺诈识别主要工作就只能交给具有巨大计算资源的后端非实时的离线系统[3]。

图2 信用卡反欺诈系统的交易检测一般过程Fig.2 General process of transaction detection for credit card anti-fraud systems
不同类型的信用卡欺诈,机器学习思维角度和训练方法亦有不同。以犯罪主体划分,信用卡欺诈分为两类,即第一方(持卡人)和第三方(非持卡人)欺诈[4]。第一方欺诈是指使用虚假信息申请新卡或持卡人本人的恶意透支;第三方欺诈是盗刷他人信用卡骗取财物的行为。基于欺诈规模性和组织性,本文重点研究第三方欺诈。第三方欺诈又可以具体分为盗卡欺诈、伪造卡欺诈、无卡欺诈(网络钓鱼)、卡ID盗窃欺诈以及未达卡欺诈等类型。不同类型欺诈行为也各具特征。譬如,盗卡欺诈通常会短时间内尽可能花多的钱,其特点是交易间隔通常很短;伪造卡欺诈通常次数不太频繁,尽量拖延受害者发现;电子交易中无需使用实体卡,欺诈者利用非法手段获得信用卡信息被称为网络钓鱼或无卡欺诈;当欺诈者非法接管他人信用卡账户时发生的欺诈称为卡ID 盗窃欺诈;当银行寄出信用卡之后到持卡人收到卡片之前被盗刷的现象称为未达卡欺诈。随着时代发展、用户习惯、外部环境改变,欺诈行为特征发生相应的变化。英国金融协会统计显示,各种类型发生比例差异很大,如表1所示[5]。20世纪70年代最常见盗卡欺诈;80 至90 年代,电话订购以及邮购兴起,伪造卡欺诈大行其道;近年来,消费交易逐渐在线化,无卡欺诈量逐年增加。

表1 信用卡欺诈的类别及占比Table 1 Types and percentage of credit card fraud单位:%
面向欺诈判别的机器学习主要面临以下几个方面的困难:第一是数据规模大且正负样本比例极端不平衡:刷卡交易数量巨大,且合法交易远远多于欺诈数量,许多研究[1,3,6]都提出欺诈比例低于0.5%;第二是犯罪有组织性,当前信用卡欺诈主流趋势已发展成为一种长期的、国际的、隐蔽的有组织犯罪行为,某张信用卡一旦被盗,将出现在多个欺诈或非法交易场景中,某些商户甚至发卡机构也深陷犯罪网络之中;第三个难点是特征重叠,欺诈者会竭力表现正常交易特征以掩饰非法交易[7];第四个难点是概念漂移,技术的发展、时间的流逝和消费者支出模式的改变,欺诈方式会随之发生变化。欺诈手段与反欺诈技术也是一个彼此演进的过程。随着各机构纷纷上线部署反欺诈系统,欺诈者也不断调整其行为模式以逃避监管[8],因此信用卡欺诈识别研究需要日益创新,是监管机构和学术界经久不衰的一个热点课题。
信用卡反欺诈领域虽然已经存在一些综述性文章,诸如文献[9-14],但它们或失于年代过于久远没有机器学习的最新进展[9-10]、或失于内容过于宽泛没有专精于信用卡欺诈检测[11,14]、或关注范围太窄只针对网络钓鱼[13]、或失于方法聚焦不够导致非计算机技术占用了篇幅太多[12]。本文专注于机器学习相关领域的新方法和新成果,综述信用卡欺诈检测的发展进程与变化趋势,对比分析各种模型算法的历史及现状,系统地刻画信用卡交易欺诈识别研究的总体发展情况,给出一个截至目前最新、最全面的研究综述。本文余下部分如图3所示。
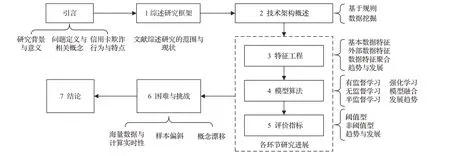
图3 本文各部分内容以及相互关系Fig.3 Content and their interrelationship of each part of this paper
1 综述研究框架
针对信用卡行为欺诈识别研究的机器学习领域文献,本文构建了一个包含研究定义层、方法层和分析层的综述框架,如图4 所示。在研究定义层,本文首先确定了以机器学习为中心的文献成果;其次,确定了预期目标是专注于信用卡行为欺诈识别这个唯一主题,梳理过去、综述现在和提议未来;基于此,选定2000 至2020年间发表的所有重要学术成果。在研究方法层面,根据前述研究定义层的输出—重要学术成果—确定了搜索范围及文章筛选条件,即以“机器学习”“信用卡欺诈”“credit card fraud detection”为关键词,检索范围为在中国计算机学会期刊会议目录和国家自然科学基金委员认定重要期刊上发表的学术成果,只考虑了长文而不包括评论、通信、技术说明、勘误表等形式的短文,在会议论文中只纳入了全文或长文,而不考虑会议上其他形式发表的论文,诸如短文、Demo、技术简报、摘要以及作为伴随会议的工作坊文章等。在保证源刊权威性之后,进一步手工剔除主题无关文章。基于此,本文最终获得101篇具有代表性的科学文献,可谓机器学习领域信用卡交易欺诈检测研究“近20 年来最重要的百篇文章”。在研究分析层面,本文提出了一篇好的综述文章应该分析、讨论并回答的具体问题,譬如,过往的此类研究都归结在哪些领域、研究范式经历了什么变化、这些变化发生的原因、各自的其高潮期与低谷期、各种方法优势和局限、该领域研究未来的发展趋势等。本文将在后续各节中逐一分析讨论这些问题,尝试给出该领域最新的趋势和进展分析。

图4 本文的研究框架Fig.4 Research framework of this paper
根据作者团队、研究机构以及国家划分,观察20年来信用卡行为欺诈检测的101 篇文献,图5 展示了各国学者发文量及其相互间合作关联图,显示出在信用卡欺诈检测领域中国学者的发文总量独占鳌头,美国学者次之、印度第三。从合作关系角度讲,美国学者仍然处于这个领域的研究中心位置,具有更多的跨国合作关联。从核心作者角度看,Oliver、Gianluca、Liu、Jiang 等学者的成果数量领先,其中Oliver处于本领域研究合作网络的中心点位置,Shamik、Gianluca、Andrea 和Yann-Ael 也处于各个区域网络的领导者地位。相比之下,Liu、Jiang等中国学者自成体系且发文量较多,领导了一个独立的合作子网,能够在严格的同行通信评审中录用并发表颇具规模的科研成果,显然也具有较强的科学影响力。
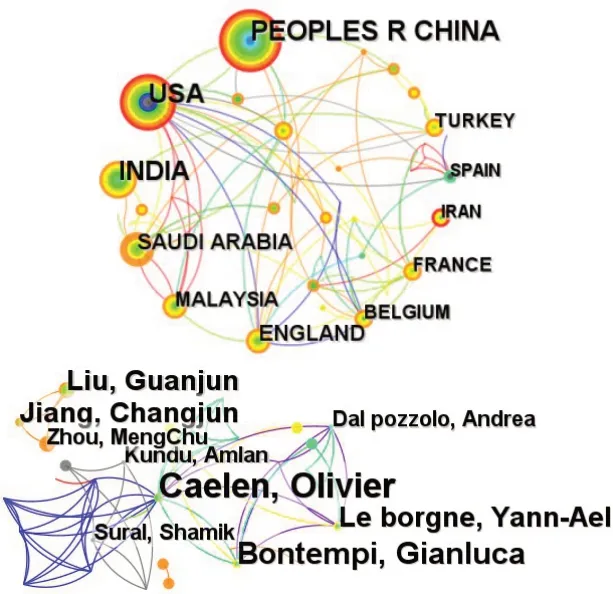
图5 信用卡欺诈检测领域各国学者间合作关系统计Fig.5 Statistics on cooperation between academics in credit card fraud detection field of various countries
基于发表年份分布统计,可以发现2015 年前后研究进入高峰期,如图6所示,相关文章频发、成果数量井喷。究其原因,首先得益于信用卡应用不断扩大;其次是研究方法不断进步。前者来源于电子商务、移动支付、互联网金融的快速发展,大量业务带来大量交易,为行为欺诈检测提供了数据积累;后者得益于大数据驱动的机器学习算法兴起,人工智能新算法为信用卡行为欺诈检测提供了新的研究契机。从图6 历史发展时间线来看,本领域研究从十几年缓慢积累期逐渐步入了最近几年的一个突破期,未来若干年这个领域还应处于一个持续高原期。
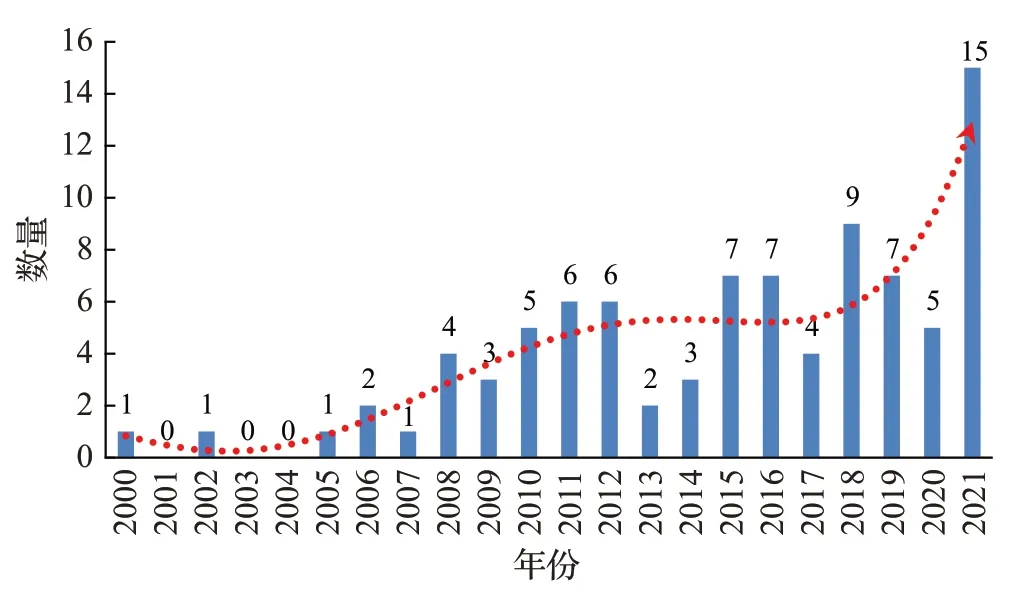
图6 文献年度发表量分布图Fig.6 Distribution of annual publication volumes of literature
分析信用卡欺诈检测研究文献引用关系,如图7所示,冷色为较早期文献,暖色为近期文献,可以发现高被引论文、高影响力文献集中出现在2016—2021 的五年间,其中Bahnsen、Jurgovsky、Fior等学者的研究成果,是信用卡欺诈检测领域研究的新热点。

图7 文献引用统计分析Fig.7 Statistical analysis of literature citations
对文献关键词进行聚类分析,如图8 所示,可以看出信用卡欺诈检测研究始终围绕机器学习算法、代价敏感性学习、异常检测、概念漂移等主题,近期的文献也开始凸显大数据信息安全相关的视角。
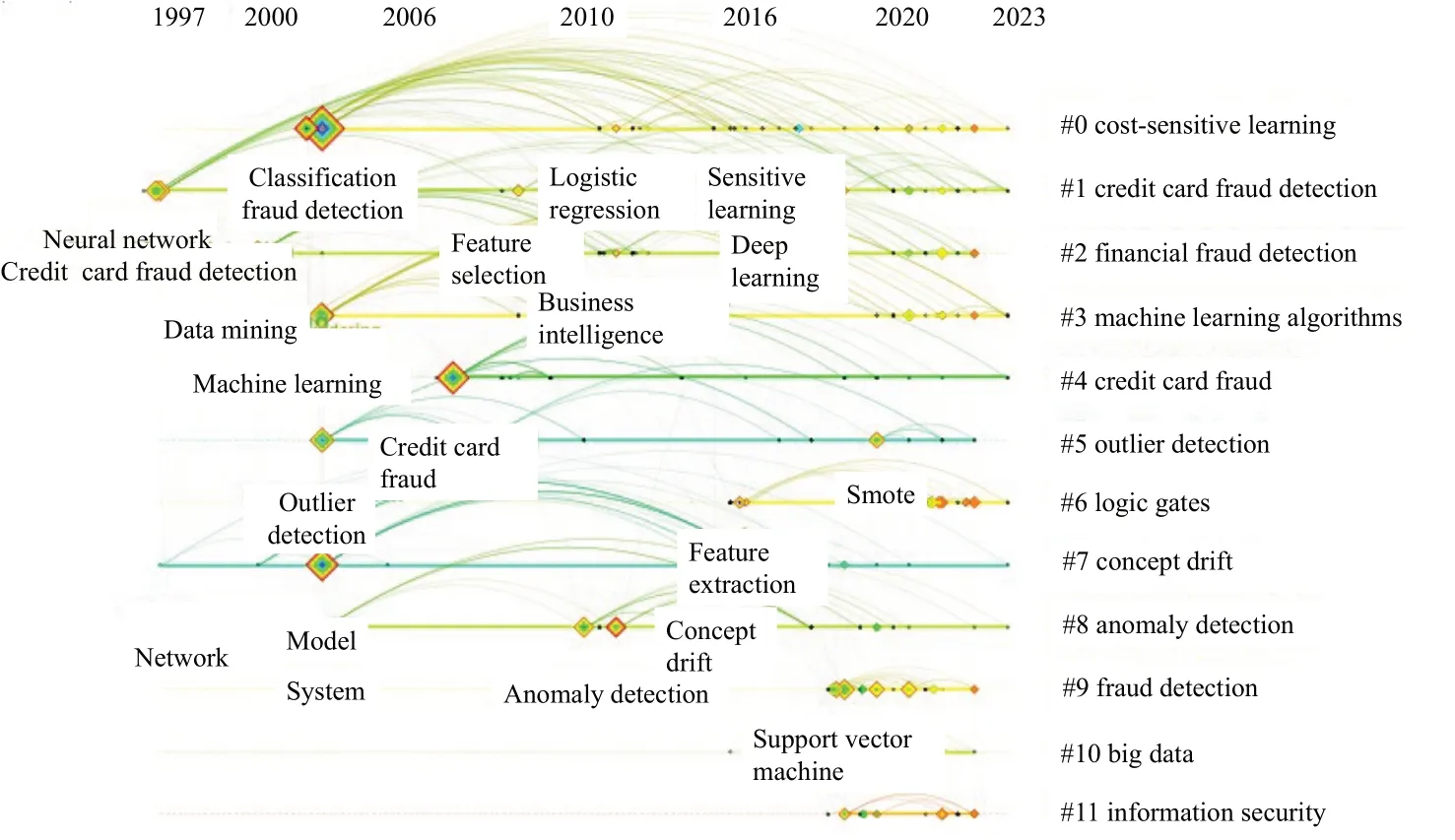
图8 信用卡欺诈检测文献关键词聚类分析Fig.8 Keyword clustering analysis of credit card fraud detection literature
对关键词进行突现分析,如图9 所示,自1997 年起神经网络便是研究者关注的热点且经久不衰,而数据挖掘与异常检测方法主要流行于2000至2010年间。最近10年来,集成模型和特征工程方面的研究突现,譬如特征选择和特征融合,并逐渐成为信用卡欺诈检测领域的若干热点方向。
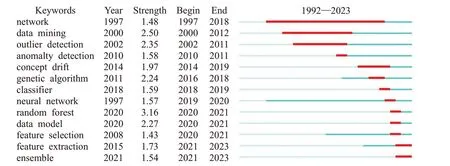
图9 信用卡欺诈检测文献关键词突现分析Fig.9 Analysis of keyword emergence in credit card fraud detection literature
2 技术架构概述
纵观信用卡欺诈检测系统的发展历史,欺诈检测的技术架构可分为基于专家知识或基于数据驱动两种类型,如图10所示。前者判定的规则由领域专家制订,基于理论解释和领域知识判别欺诈行为,适合于特定欺诈场景;后者从大量历史数据中挖掘交易行为模式,捕获欺诈行为特征。随着发卡规模不断扩大,持卡人日益多样性,刷卡交易量剧增,依赖于专家知识的规则检测系统难以为继,再加之电子商务应用场景多样化,传统经验显然无法适应快速发展的需要,大数据驱动的欺诈识别方法日益成为学界和业界的主流体系。
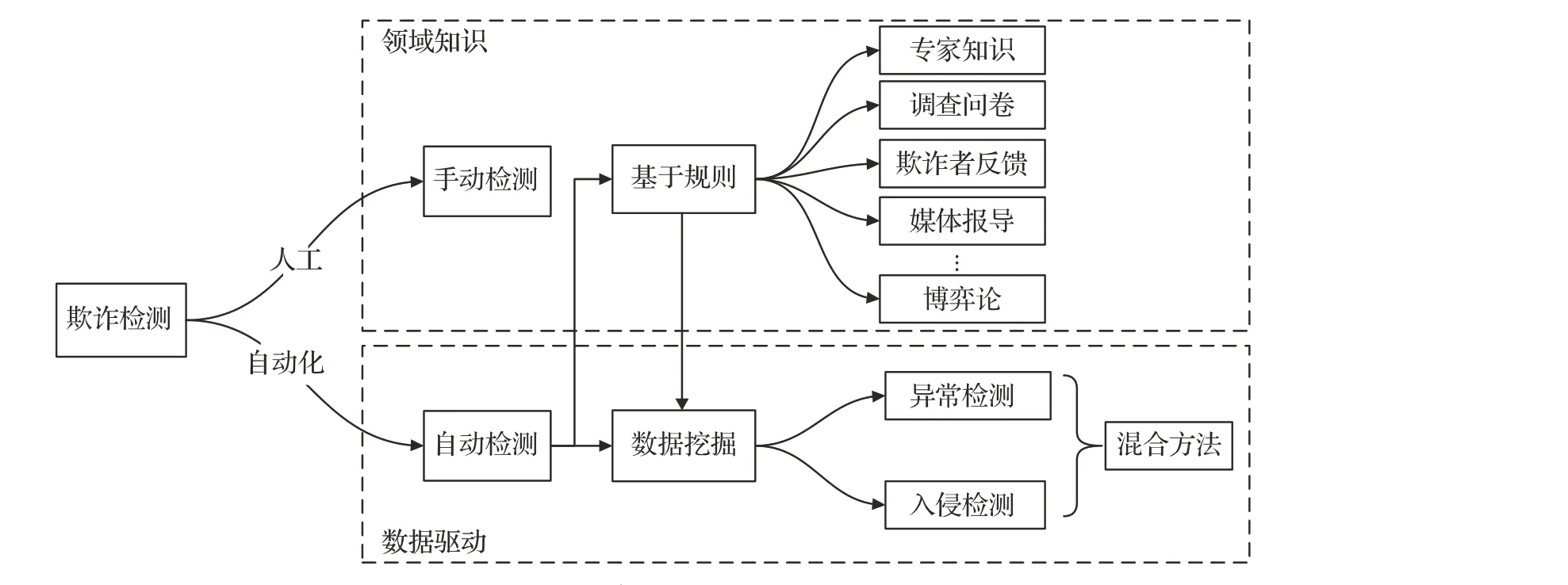
图10 欺诈检测技术架构分类与发展Fig.10 Fraud detection technology architecture classification and development
2.1 基于专家规则的架构
信用卡反欺诈早期多数是基于规则的专家系统架构。判定规则一般是“if-then”或“if-else-then”触发条件[15]。专家系统将规则集成在规则池,一个规则池内通常包含几百甚至数千条规则,通过AND/OR运算符对其进行集成或汇总。规则数量越多,欺诈鉴别的覆盖范围也就越大,召回率越高。20 世纪90 年代欺诈申请检测系统TRAP 和信用卡欺诈识别系统Fraudwatch 均是基于专家规则构建的系统,这类专家系统结构比较简单,通过可重用的专业知识模型库,短时间内即可从大量交易中筛选出可疑交易,在当时信用卡反欺诈中获得了很大的成功[16]。
随着时代发展、技术变化、应用多样性,欺诈模式也不断改变,系统需要不断调整规则池,以维持分类性能和效率。其中,博弈论为探索新规则提供了一个重要思路。Vatsa等学者将欺诈者与反欺诈系统建模为两个对手之间的多轮次交互重复博弈,以试图最大化其收益。然而并非规则越多越好,数量越多计算复杂度越高,系统需要在分类性能、计算效率以及系统敏捷性之间进行权衡[17]。Gianini 等研究了欺诈检测规则的效率管理问题,提出一种基于Shapley值的有用性量化原则,即对每条规则的贡献进行排名以解决于规则库管理与规则评估问题[15]。总之,专家规则算法的优点和缺点都非常明显。其优点是以较低的精度实现了较高的召回水平;其缺点是预定义专家规则没有办法识别出新涌现的欺诈模式。
2.2 基于数据挖掘的架构
数据挖掘是实践证明更加卓有成效的欺诈检测方法。相比于专家规则,数据挖掘具有一些独到优势[18]:从历史数据中自动捕获欺诈模式;刻画每个交易“潜在欺诈”的概率,从而安排对可疑案件调查的优先级;挖掘出未定义的新欺诈类型。实践中欺诈行为普遍存在多样性和复杂性,需要数据挖掘开发不同的应对方法[10]。
面向信用卡反欺诈的数据挖掘方法可以划分为六类,包括分类、聚类、预测、回归、异常检测和可视化等。从趋势上讲,近年来反欺诈数据挖掘逐步向基于入侵和异常的检测方法发展,或二者相集成[19]。所谓入侵检测,是指针对欺诈签名而其他特征正常的特定交易[20],通常利用基于规则的统计揭示可疑交易;所谓异常检测,是对每个持卡人行为模式进行建模,以监控当前交易行为是否偏离规范,也可称为离群值检测[21]。异常行为特征数据挖掘包含三种类型,即监督、无监督和半监督的异常检测[22]。基于异常的检测方法实践中表现强大的潜力[21,23-25]。有些学者集成异常和入侵两类检测方法以期获得更好效果,既克服入侵检测不擅发现新模式欺诈的缺陷,又规避异常检测欠缺泛化能力和误报率较高的弊端[8,26]。
面向欺诈检测的数据挖掘流程包含特征工程、模型选择、效果评价等三个主要环节。表2总结了在这三个环节上最近20年来发表的文献数量其发展趋势。在特征工程环节,采取恰当的技术处理、转换或汇总原始交易记录的行为信息,筛选数据和提取特征。鉴于隐私保护的需要,交易记录往往字段简单、特征单一,需要系统采集更多、更广义的相关数据,挖掘数据间的关联,以期构造出新的特征变量。特征工程这部分涉及计算机智能技术、经济管理科学、统计学、法学、心理学、数学等众多理论与方法,不同理论研究框架可以解释和解决不同的问题,从各个侧面为欺诈检测提供思路。其次,在模型训练及选择环节,探寻高精度、高性能算法以自动判别交易记录流中的异常个案。在效果评价环节,重点在于评价指标的设计,为模型改进明确优化的方向。好的评价指标不仅能无偏反映模型效果,还适应信用卡欺诈的特殊应用场景,即权衡准确率、召回率以及模型效率(即算法复杂度),还需考虑欺诈检测的成本与收益。
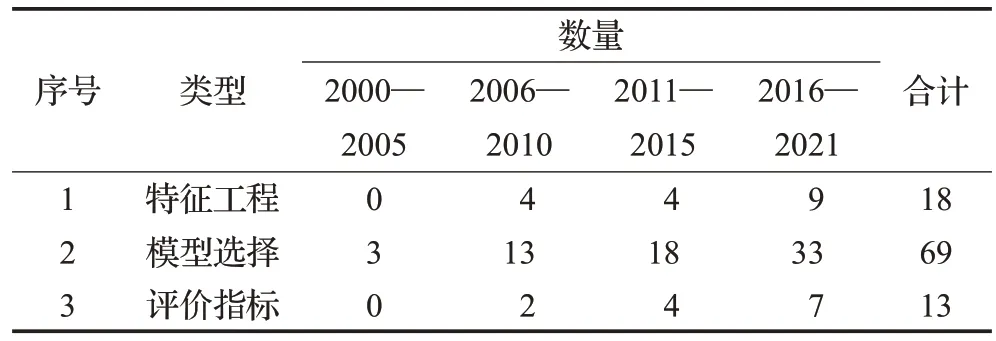
表2 各环节研究情况及其年度分布Table 2 Research by segment and its annual distribution
总的来说,数据驱动的、日新月异的机器学习方法已经成为信用卡反欺诈检测算法中一种中坚力量,也是此领域未来最重要、最有前途的发展方向。特征工程、模型选择、效果评价等环节是所有数据挖掘算法的一般性过程,后面各节将依次展开专题性文献综述,以清晰梳理基于数据挖掘的机器学习检测模型的历史沿革、最新进展和未来方向。从技术架构的发展趋势上看,信用卡欺诈检测系统的相关研究反映了三大特点:其一是从小数据处理到大数据处理能力的演进;其二是从检测功能的实现,到准确率的考量,再到算法效率的追求;其三是数据处理能力与模型性能的演进,以及对提升样本集利用率和概念漂移等复杂因素的考虑。
3 特征工程
特征质量对于机器学习模型性能至关重要,全面采集、仔细筛选、精心创建捕获异常的特征,是启动信用卡欺诈检测的一个重要步骤。然而,信用卡交易具有其特殊性。为了保护用户隐私和持卡人资产安全,信用卡发卡机构与结算平台都竭力限制信息披露的范围和程度。目前各种研究数据即便来源不同,手段也各异,但是都是从信用卡支付记录和持卡人账户等基础信息出发。由于原始数据字段稀少、特征单一,特征工程的一个直观改进方向,就是挖掘新类型特征,诸如视频、图像、声音、文字等多模态特征融合及其网络特征;亦或对现有特征进行不同维度的聚合,各种角度挖掘交易行为的同质与异质性、动态变化等特点,以发现当前数据字段所隐含的、尚未能解释的潜在行为特征,如图11所示。
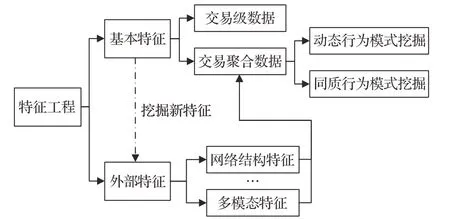
图11 面向交易欺诈检测的特征工程架构Fig.11 Feature engineering architecture for transaction fraud detection
3.1 基础数据特征
信用卡交易基本特征包括该交易的支付记录、持卡人账户以及商家信息。表3 总结了典型信用卡交易原始特征。基于交易支付记录的基础特征,判断一单交易是否异常,例如,某张卡在特殊时间(诸如深夜时段)与特定商户(诸如在线博彩)突然发生一笔大额交易,就会引起怀疑。初级数据挖掘也是直接利用交易数据构建欺诈检测特征,例如文献[27]直接选取一小部分历史交易记录训练神经网络模型,既未考虑关联帐户的历史数据,也未考虑其他的类似交易。当然,从现实的可行性看,在当时技术条件下直接采用所有帐户所有历史数据训练模型是不可行的,若仅拣选部分交易数据训练模型,又势必导致历史交易中的关联信息丢失。基于持卡人账户信息的基础特征,反欺诈系统根据持卡人在一段时间内的交易行为数据刻画其“行为模式”以鉴别异常交易。例如客户X消费习惯都是线下实体店刷卡,若某个时刻帐上突然出现一笔大额在线交易,因不符合其以往行为模式,将被归于可疑交易。不过,这种行为模式策略仅仅考虑帐户历史记录,实质上是行为特征变化的检测,而非欺诈识别,某些情况下持卡人正常行为改变也可能导致误报。

表3 信用卡交易数据的基本特征举例Table 3 Examples of basic characteristics of credit card transaction data
随着特征工程技术的发展,仅采用基础特征的反欺诈研究已非主流趋势。少量专精算法设计的研究仍在使用这些朴素的基础数据特征[20,26,28-29],究其原因,既是受制于周边数据可获取性的局限,也是为了统一数据维度以方便各类模型间性能的对比分析。
3.2 外部数据特征
外部数据特征是指超出支付记录、持卡人账户的、来自外部数据源的额外特征。从内容角度讲,外部数据内容非常广泛,不一而足;从形式角度讲,主要分为网络结构特征和多模态特征。网络结构特征是指持卡人、商户、支付平台和发卡机构之间的一个异构网络,如图12所示,通过信用卡交易记录相互关联。在现实中欺诈交易通常集中于特定商户或特定持卡人,针对网络特征挖掘显然可提供有利信息。Van Vlasselaer 等[1]构建了一个二部图网络,以指数衰减方式定义时间特征,提出了一种迭代评分算法以计算结点的风险敞口并判定交易的可疑性。随着网络深度学习的快速发展,基于图神经网络结合预设传播的这类算法,可以通过挖掘结点风险敞口以预判潜在的交易风险,未来有望能取得更广阔的研究前景。
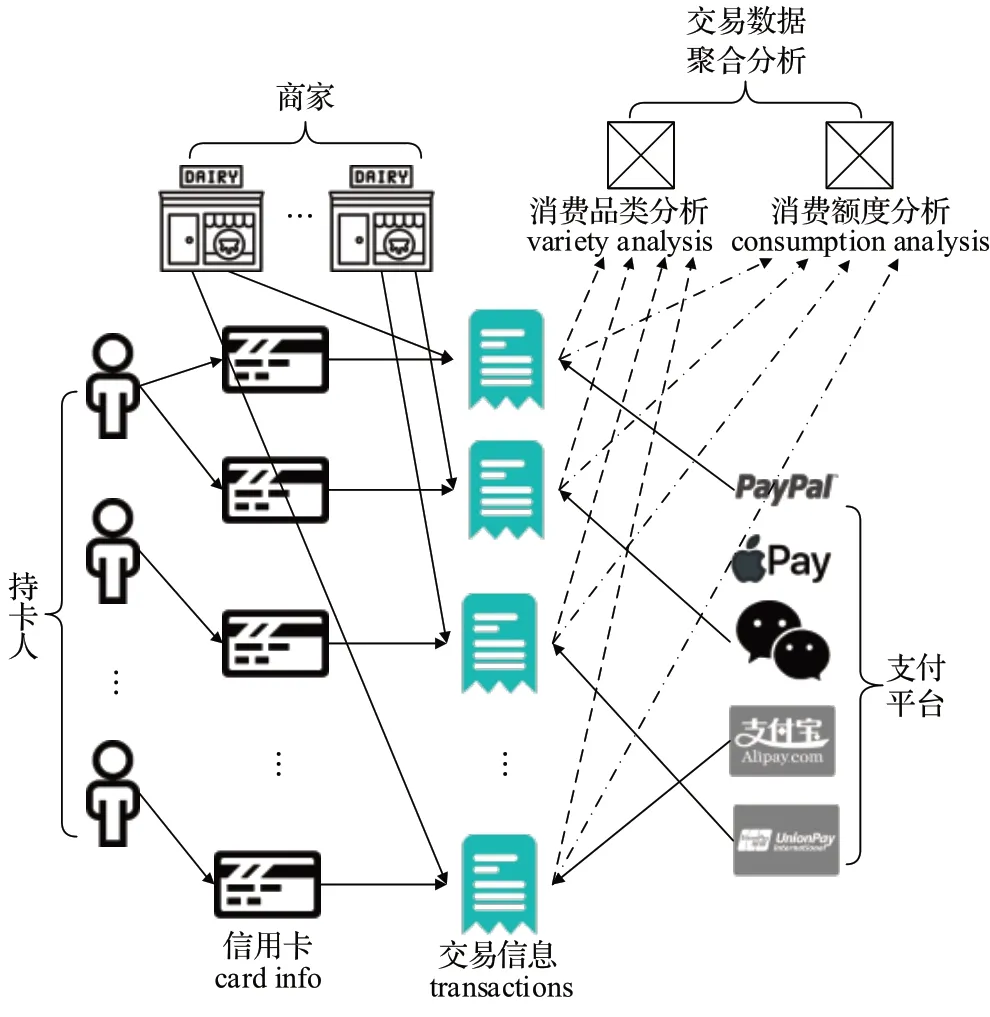
图12 信用卡交易的异构网络Fig.12 Heterogeneous networks for credit card transactions
多模态特征是指不同格式、不同来源的信息融合,可为欺诈检测带来新的增量信息。多模态机器学习(multi-modal machine learning,MMML)具有处理和理解图像、视频、音频、文本等多模态特征的能力,已逐渐成为内容分析与理解的主要手段。Li 等[30]借助社交媒体分析分析客户评论情感和对商户广告主体建模,来识别违规商户,捕获违规商户在诸如产品类型、付款方式、联系渠道等方面特征,以防止潜在欺诈行为。Nascimento等[31]利用订购电话声音分析得到九个声学指标特征,结合买家基本信息构造欺诈分类器,结果表明声学特征加入能够提高检测准确性。多模态特征为欺诈检测带来新的思路,但受限于用户隐私保护,很多数据难以获得,此类研究目前相对比较稀少。
3.3 数据特征聚合策略
对于行为欺诈的识别,一组交易数据显然能够比相互隔离的单个交易记录提供更多信息。比如,连续数笔可疑交易比单独一笔更易发现其中的欺诈行为。对于反欺诈系统来说,随着时间推移和历史交易数据不断累积,系统的判断应该变得更加准确和可信。例如某在线商户突然出现大额充值并紧接一系列购买操作,显然可能存欺诈,如果割裂开单独来看,无论充值还是采购的每一笔交易并无可疑之处。在一定时间间隔内针对某些账户、平台收集数据,挖掘跨交易之间关联特征中通常能发现更多有价值的信息。批量交易整合采集数据特征,即数据特征聚合。通过一段时间内一系列交易数据的汇总统计可获新特征,如最大值、平均值和标准差等。此类研究最早可追溯到Whitrow等[32]的交易聚合策略,该策略在不同时间窗按不同维度(商家类型、交易发生的国家/地区)汇总每张信用卡交易量和金额。结果表明,3 天或7 天时间窗的随机森林模型可获得最好预测效果。许多研究验证了交易特征聚合策略的有效性[33-35],表4 列举了常用的多模态融合特征和交易聚合特征。通过交易聚合截取特征,具备与时俱进的优势,即特征随时间流逝不断更新,譬如不同时间窗内摄取持卡人行为特征快照;还具备不需要精确标记的优势,对持卡人群漂移(population drift)的处理更加稳健。然而,交易聚合策略并非万无一失,有些信息在汇总过程中难免会湮灭,譬如交易顺序信息。另外,交易聚合后单个欺诈交易遭到稀释,聚合时间窗越长则隐患越大。
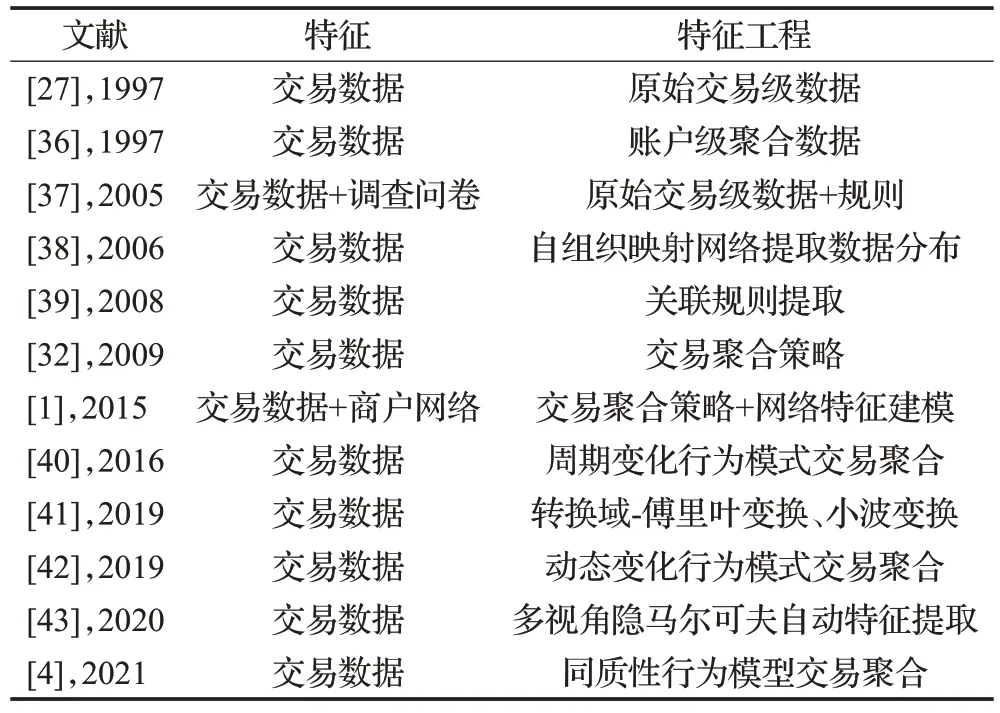
表4 各文献使用的特征工程举例Table 4 Examples of feature engineering used in each literature
动态行为模式特征挖掘。现实中欺诈行为通常是人为设计的、策略性的和动态性的,欺诈者经常更改其行为,对欺诈检测研究提出了新的挑战。尽管交易聚合可以提供持卡人行为快照,但它无法捕获行为动态变化。Bahnsen等[40]认为人们往往在相似时间进行特定交易,交易聚合采用交易时间算术平均值并不恰当,没有考虑时间特征周期性。他们将交易时间建模为周期变量,应用Von Mises分布提取周期性行为特征,显著提高了检测性能。当然,Bahnsen 方法仅捕获了固定周期行为(例如每周末固定消费),也忽略了其他与时间相关的非规律行为(例如大笔交易后若干小笔交易)。Wu等[42]通过函数型特征分析算法(functional data analysis,FDA)捕获持卡人随时间变化的动态行为模式,使用一条曲线来估算每张卡交易量的动态变化,并提取曲线主成分作为新特征,实验结果表明,行为快照和动态特征的结合可以获得更优性能。不过,该FDA 方法核心是主成分分析(principal component analysis,PCA),显然对动态行为模式的分析缺乏良好的可解释性。
同质性行为模式特征挖掘。多数特征聚合都使用三个维度,即频率(Frequency,给定时间窗内发生的交易数量)、金额(Monetary,给定时间窗内交易总金额)、新近度(Recency,给定时间窗内前后两次交易之间的时间间隔)。Van Vlasselaer 认为该策略符合营销学的新近度-频率-货币模型框架(recency-frequency-monetary,RFM)[1]。RFM 框架作为一种营销分析手段,适合于分析消费者的历史购买行为。信用卡应用有所不同,其交易是异质性的,存在支付、退款、提现和积分换购等多类型交易,不同的交易类型应该对应不同的行为模式[44]。正常情况下,提现交易频率显著低于支付交易频率。不加选择地分析用户所有类型交易,既耗时又徒劳。交易聚合如果忽略了交易异质性,反而会给特征工程带来更多的噪声。同质性行为模式特征挖掘应运而生。Zhang等[4]提出了一种面向同质性的行为分析(homogeneityoriented behavior analysis,HOBA),针对具有相同类型的历史交易进行行为分析。它将信用卡交易视为由交易特征、时间、地理空间和货币价值构成的超空间中一个点。在同一子空间中,HOBA应用交易聚合和基于规则的策略提取历史交易数据的特征变量,获得1 410 个变量输入深度学习模型。实验结果表明HOBA 相比于RFM 框架为欺诈预测提供了更好的特征变量。不过,鉴于该框架构造了更大的变量集,势必耗费更多的计算资源,从而影响其实践应用的可行性,但该研究中没有明确评估HOBA特征工程框架的计算成本。
3.4 特征工程的趋势与未来
表5 列举了面向特征工程的文献统计。从趋势上看,早期研究多数采用基础数据特征,并未过多关注特征工程,只需致力模型改进便可带来可观效果;近年来特征工程研究逐渐进入高峰期,以2009年Whitrow的工作为标志,大量聚合策略研究不断涌现,在这个阶段特征工程带来的增量超过了模型改进的效果[32]。通过先验知识的加入,可以更加高效地贴近欺诈行为模式。信用卡欺诈检测的特征工程发展,反映了心理学、行为学等多学科理论的贡献,反映了当前机器学习研究中多学科融合的趋势。 特征工程发展的另一个趋势是发掘新的特征类。随着自然语言处理、复杂网络处理、多媒体技术的发展,更多含新信息量的多模态特征开始被大量使用,例如文本、图片、声音、视频以及网络关系等逐渐在特征工程研究中绽放异彩,多模态特征突破了传统数据形式的限制,进一步拓宽了信用卡欺诈检测的数据采集范围。
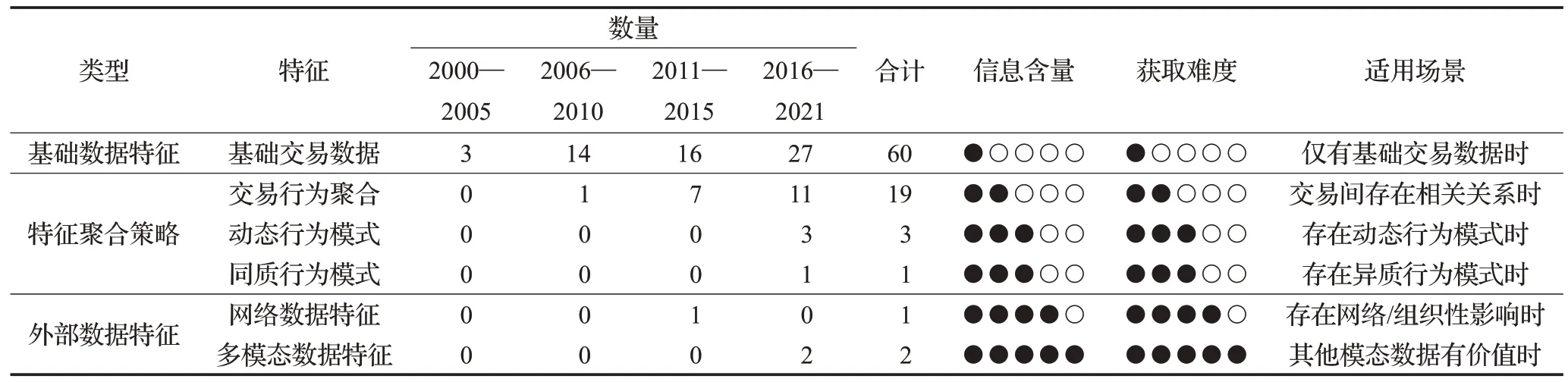
表5 面向特征工程的文献比较Table 5 Comparison of feature-oriented literature
特征重要性排序、冗余特征剔除也是特征工程研究的重点。特征并非越多越好,冗余特征降低了机器学习的效率,带来的噪声又影响模型的精确性。近年来并行计算和云平台的发展逐渐减轻了特征维度的限制。高维特征的自适应深度学习也有助于克服噪声、冗余的影响,可以获得更好的检测效果。
4 模型与算法
面向交易欺诈检测的机器学习,其核心是数据驱动的欺诈挖掘模型或行为识别模型。一般来说,机器学习的理论基础来自于统计学、信息论、控制论及其他学科,对数据依赖性很强,从历史数据中挖掘知识、学习经验,被称为“新经验主义”。通过挖掘欺诈者的行为模式特征,提高模型的欺诈识别能力。早期研究采用单一基础性模型,诸如逻辑回归和线性判别分析[9,33];后期文献广泛应用新型计算智能[26,45-47],诸如随机森林等;除了从经验中学习知识之外,还可以创造性地“跳跃型学习”,例如半监督甚至无监督学习;近年来人工智能算法备受研究者青睐,相关文献大量涌现[48-50]。人工智能模仿人类或其他生物的信息处理模式,包括人工神经网络、人工免疫系统等,使得模型在解决问题时能够“不依赖于量变”产生“质变”,达到更好的效果。
从解决问题角度,机器学习模型可以划分为分类、聚类、预测、异常值检测、回归等类别。分类指利用模型来预测未知对象的分类标签,以区分对象的类别,如文献[51];聚类用于将所有对象分为概念上的若干集群,群内的对象彼此相似,不同群对象差别很大,如文献[52];预测指基于数据集模式预估未来值,如文献[44];异常值检测指测量数据对象之间的“距离”以检测与其他对象不同或不一致的特殊对象,如文献[53];回归指揭示一个或多个自变量与因变量之间的关系,如文献[54]。
从数据标签角度讲,机器学习模型可以划分为监督学习、无监督学习和半监督学习,如图13 所示[55]。基于信用卡交易记录是否已标识为先决条件,使用标签数据训练模型称为监督学习,完全没有标签数据的训练称为无监督学习,使用少部分标签和大部分无标签的混合训练称为半监督学习。还有其他一些标签数据的使用方式,包括联邦学习、迁移学习和强化学习等。
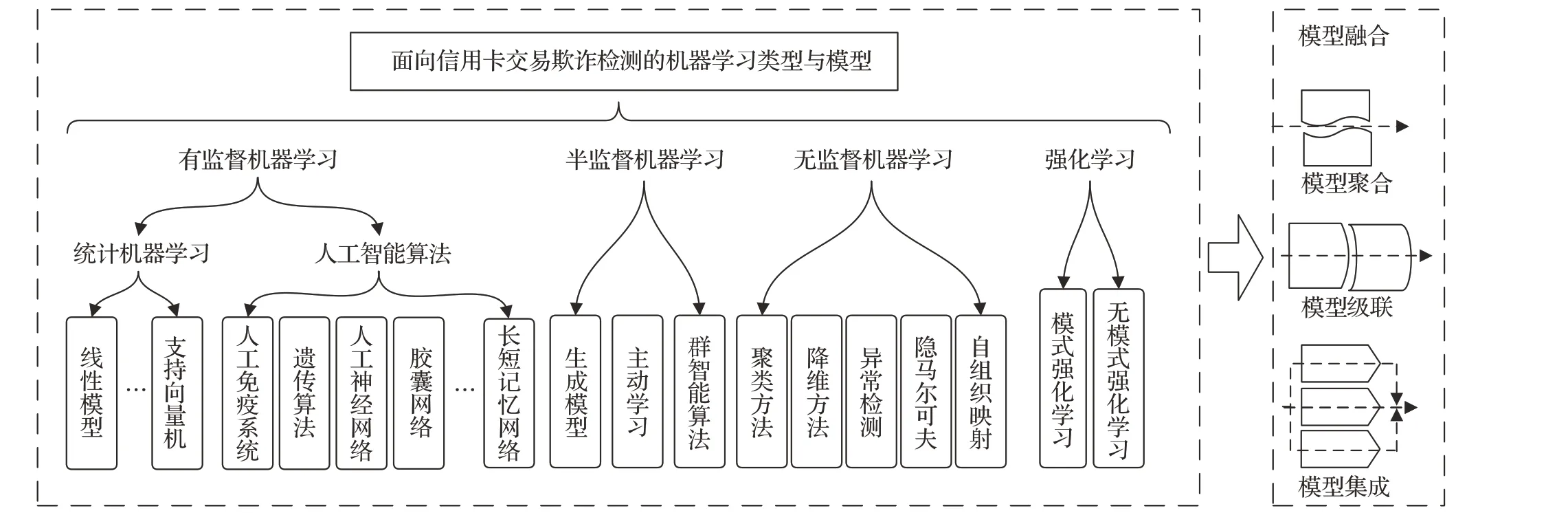
图13 面向信用卡交易欺诈检测的机器学习模型分类Fig.13 Machine learning model classification for credit card transaction fraud detection
4.1 监督学习
监督学习模型优势在于其输出是有意义、可解释的,劣势首先在于难以获得全标签数据集,数据量越大成本越大;其次有些场景下研究问题存在模糊性,对应不到合适的标签;再次,监督学习只能识别已知标签的欺诈模型而不能检测新型欺诈[9]。早期信用卡欺诈检测研究多采用统计机器学习方法,其简单、高效、具有较强解释性,但预测准确性相对不足,难以从复杂欺诈行为中捕获欺诈模式。表6 总结了面向信用卡欺诈检测的各类统计机器学习方法及其应用场景。

表6 各类有监督统计机器学习方法对比总结Table 6 Comparison of supervised statistical ML methods
基于人工智能的先进信用卡欺诈识别方法,通过复杂的非线性模型架构对数据进行分类、分组和分段,检测可疑行为的类别、集群和模式,以搜索海量信用卡交易以查找模式检测欺诈,具体包括人工神经网络、人工免疫系统、遗传算法、卷积神经网络、胶囊网络、长短记忆网络等。
4.1.1 人工免疫系统(artificial immune system,AIS)
AIS是一种生物学自然免疫模式的人工智能方法,通过模仿生物免疫系统检测抗原行为起作用。AIS 包含否定选择、克隆选择、免疫网络和树突状细胞四个算法,应用真实数据将欺诈交易检测模拟为抗原检测行为,通常可实现较高检测精度。文献[48]将疫苗接种的理念引入AIS,为每个异常实例保留一定数量的内存检测器,开发了一种保持检测器类型的适当比率算法,对特定类别的异常交易进行分布式免疫接种,适应了亲和力成熟和体细胞超突变机制,通过交叉反应进化为防御机制,最大限度地减少了信息的丢失。类似地,文献[56]对改进了信用卡欺诈检测的人工免疫系统,在生成存储单元时纳入了否定选择和模型更新,更改了距离函数以及数据集属性,显著提高了预测精度同时降低了计算成本和系统训练时间。
4.1.2 遗传算法(genetic algorithm,GA)
GA 是一种不需要利用先验的领域知识,通过使用种群进化不断迭代地检测交易之间潜在关系的解决方案。文献[23]将GA和分散搜索(scatter search,SS)两种元启发算法结合,构建GASS模型用于信用卡欺诈检测,大幅提高分类性能;文献[57]则利用遗传规划(genetic programming,GP)识别异常模式,从序列数据中构建候选特征集实现自动特征设计;文献[47]也利用GA 实现了信用卡交易最优聚合特征的自动化选择。
4.1.3 人工神经网络(artificial neural network,ANN)
ANN是由一组相互连接的神经元和突触构成的模仿人脑功能的算法。神经网络将输入变量建模为顶点层,为图中每条边分配权重,将其他顶点置于单独级别反映其与输入节点的距离,并通过反向传播更新权重以对信用卡交易实现最终的分类或聚类。文献[27]提出了一种基于神经分类器的在线信用卡欺诈检测系统,结合使用非线性Fisher 判别分析以应对不平衡问题;文献[58]构建了一个收益驱动的神经网络,基于实例个体的重要性在ANN 中引入一个新的惩罚函数,为信用卡交易的错误分类提供可变的惩罚,实现了最优的利润驱动的绩效指标;文献[35]提出了基于ANN级联集成的一个端到端的欺诈检测解决方案,解决了样本不平衡数据的影响。神经网络的不足之处在于参数较多,需要选择、调整网络结构;对于超大型输入数据,训练神经网络非常耗时、耗资源;反向传播训练的多层感知器容易过拟合;ANN分类器是一种“黑匣子”,其结果也难以具备可解释性。
4.1.4 卷积神经网络(convolutional neural network,CNN)
CNN是一类深度结构且包含卷积计算的前馈神经网络,按其阶层结构对输入信息进行平移不变分类,适合账户、用户、时间、空间等关联性的二、三维数据形式。文献[4]实证了CNN 在信用卡反欺诈领域的有效性。卷积神经网络主要包括卷积计算层、池化层和连接层三层结构,如图14 所示。卷积计算层的组成元素是若干卷积单元,通过反向传播不断更新优化参数,提取局部特征;池化层也称为下采样层,通常采用均值采样和最大值采样,通过压缩数据规模、特征降维避免过拟合,提高模型的训练速度和容错性;全连接层将前述获得的二维特征按行展开连接成向量,以便最终分类。CNN局限在需要大数据集,若数据量较小会无法收敛;“平移不变性”池化策略忽略了局部与整体之间关联性,对关键对象的平移、缩放、旋转都不敏感;CNN没有记忆功能,对交易时序数据的学习处理能力较差。
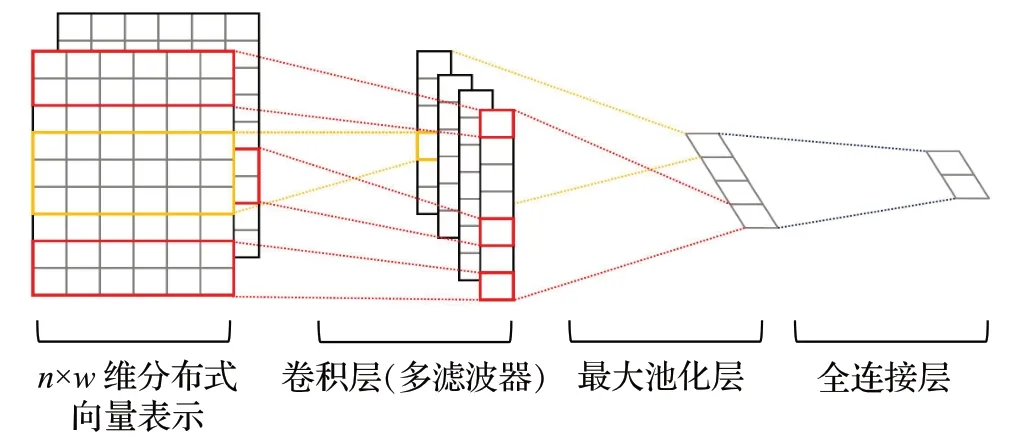
图14 卷积神经网络示意图Fig.14 Convolutional neural network diagram
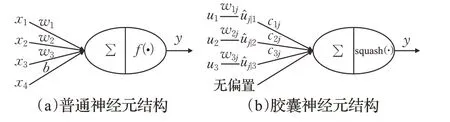
图15 神经元结构比较Fig.15 Comparison of neuronal structures
4.1.5 胶囊网络(Capsnet)

胶囊网络的优势包括所需训练数据较少,较少的数据即可得到泛化,使其更接近人类的大脑行为;胶囊网络结构明确,网络训练中能保存细节信息,微小的改变会带来输出值的变化;胶囊网络有效识别重叠对象,通过高级胶囊获得多重叠类别更清晰的解析。文献[59]采用胶囊网络挖掘信用卡欺诈的深层特征,在时间维度上扩展交易特征以描述正常用户和欺诈者的不同支付习惯。针对于信用卡欺诈检测中广泛存在的标注数据少、交易行为模式复杂多变以及数据重叠等的问题,胶囊网络有望在未来研究中发挥更大的作用。
4.1.6 长短期记忆网络(long short-term memory,LSTM)
LSTM是一种在RNN基础上的升级改造,引入了输入门、输出门和遗忘门三类门控单元,如图16 所示,分别有对应RNN记忆控制以建立信用卡交易序列的长短期依赖。 遗忘门以一定的概率Zf控制遗忘上一层隐藏单元状态Ct-1;输入门处理当前序列位置的输入以更新单元状态,由sigmoid激活函数的输出Zi和tanh激活函数的输出Z两者结果相乘;输出门通过Zo来控制哪些状态输出。将遗忘门和输入门的结果相加,得到传输给下一个单元状态的Ct。
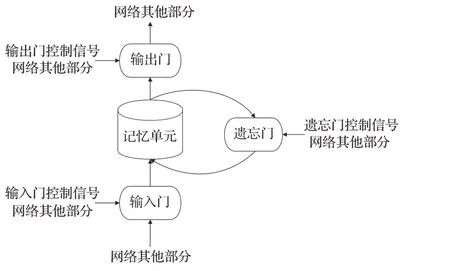
图16 LSTM门控机制概念图Fig.16 Conceptual diagram of LSTM gating mechanism
在LSTM状态更新中h为短期记忆单元,C为长期记忆单元。当梯度流经h时经历ht→Ct→ht-1连环相乘路径,该路径随时产生梯度爆炸并导致记忆的消失;梯度通过C时存在一条无连环相乘的路径以避免梯度消失,并有遗忘门避免激活函数和梯度饱和,从而很大程度上解决了RNN长期依赖问题,LSTM整体结构如图17 所示。 LSTM 网络对时序数据学习的优化,使其成为目前应用最主流且最成功的循环神经网络模型。文献[49]构造了一个LSTM模型并验证了时序特征深度挖掘对信用卡欺诈检测的作用;文献[60]结合LSTM 与概率图模型(probabilistic graphical model,PGM),挖掘交易、标签间隐藏顺序依赖性,显著改善了欺诈检测的效果。
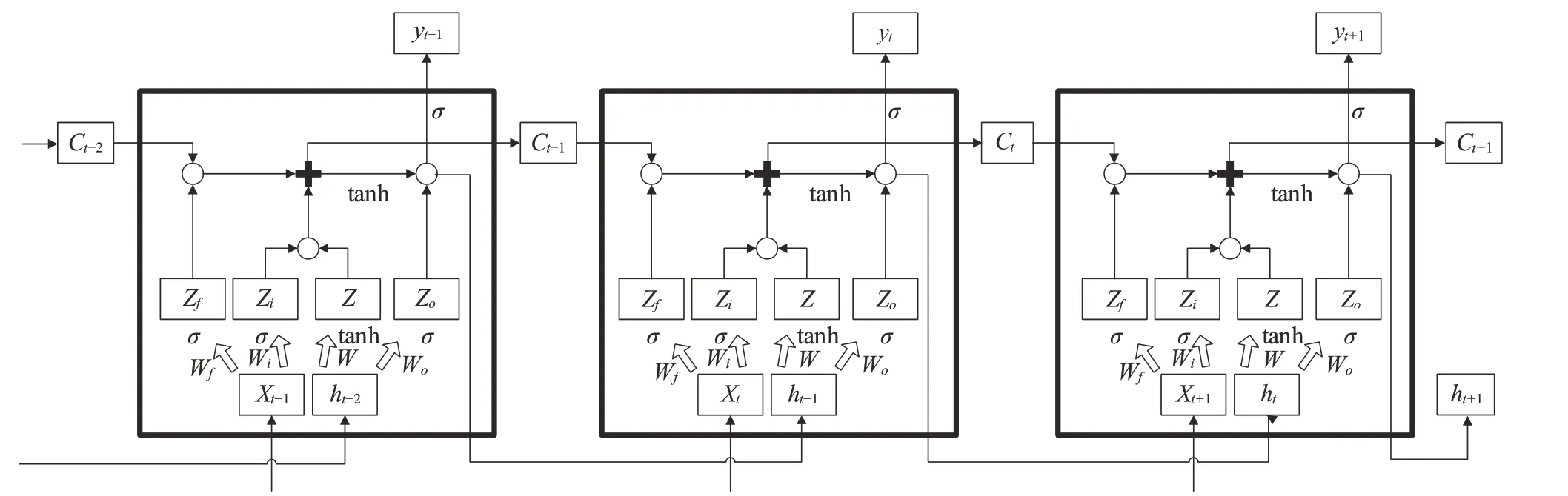
图17 长短期记忆神经网络LSTM示意图Fig.17 Schematic diagram of LSTM, long and short-term memory neural network
当序列长度超过一定限度后,LSTM模型的效率和效果都会急剧下降。对LSTM的优化包括并行化计算、减少门的数量等等。其中门控循环单元(gate recurrent unit,GRU)网络是其中一种,它没有记忆单元,只有更新门(update gate)和重置门(reset gate)两个门,具备更少的参数量。文献[61]分别构造了LSTM与GRU模型,基于深度模型投票实现了面向欺诈检测的集成模型的更优效果。
4.1.7 注意力机制(attention mechanism)
Attention 借鉴了人类视觉研究中的注意力机制以解决信息处理瓶颈的问题。人类通常先快速扫描全局,获得需要重点关注的目标区域,对这一区域投入更多注意力以获取目标的更多细节信息。在深度神经网络中引入注意力机制,在算力有限情况下使网络获得更专注于特定子集的能力,为信用卡欺诈检测的信息超载问题提供了新思路。文献[62]在欺诈检测深度学习中引入了分层注意力机制,在连续空间中嵌入分类特征,使用注意力机制将特征组合为单个向量,通过序列级别注意力执行欺诈检测。文献[63]基于时空注意力提出了一种用于欺诈检测的神经网络(spatial-temporal attentionbased neural network,STAN),通过注意力和三维卷积机制,集成信用卡交易的空间和时间行为信息共同学习注意力权重,取得了良好的效果且具备很好的可解释性。
表6、表7 分别总结并比较了各类面向信用卡欺诈检测的有监督统计机器学习方法与人工智能算法,其中统计学习模型大多有着良好的解释性计算快捷,但普遍精度不及人工智能算法,其当前与未来的发展方向聚焦于通过代价敏感性改造以适应信用卡欺诈检测任务、与其他模型融合发展提升精度及增进算法解释性的研究;而人工智能算法有着清晰的发展思路,例如人工神经网络为扩展邻域感知效果发展出CNN,为克服CNN 的数据计算与泛化的缺点发展出Capsnet,为获取时间序列信息开始采用RNN,以及克服RNN 长期依赖而发展LSTM/GRU 等,总体是向着广度、深度、效率等多方面进行发展。无监督学习则主要致力于利用降维、HMM、异常检测等发现信用卡欺诈检测数据中的隐藏行为模型,发展趋势是将无监督模式发掘与有监督模型分类相结合,以得到更好的检测效果。

表7 各类有监督人工智能方法对比Table 7 Comparison of supervised AI methods
4.2 无监督学习
无监督学习包括聚类、降维、异常值检测和隐马尔可夫模型等。它们优势在于避免了对海量数据标签的需求,而且有可能挖掘出新的欺诈类型;劣势在于较高的误报率。
4.2.1 聚类方法
聚类是指通过相似性度量将交易记录聚集到不同的类或者簇的过程,使得簇中对象相似性最大而簇间差异最大。虽然在欺诈检测中单独聚类并不很有效,但将其与其他监督学习方法结合使用,通常能获得较好效果[64]。文献[65]提出了一种对等组分析的欺诈检测模型,对类似交易进行聚类,任何开始偏离对等组的交易都会被标记为疑似交易,该模型不足是属性维度爆炸;文献[66]采用了噪声密度空间聚类方法(density-based spatial clustering of applications with noise,DBSCAN),结合Dempster-Shafer加法器、基于规则的筛选器以及贝叶斯学习器,相比于基准模型显著提升了信用卡欺诈检测的性能;文献[21]提出了一种改进的凝聚层次聚类异常检测方法(improved agglomerative hierarchical clustering,IAHC),实现动态调整最优聚类数,根据cophenetic相关系数确定最优聚类距离模式,在信用卡欺诈数据集上表现很强的敏感性且具备很好的泛化能力。
4.2.2 降维方法
交易特征的高维数据是欺诈检测的主要挑战之一,降维可以帮助识别其中最重要的特征,再基于这些特征聚类或分类交易记录,可以更加清楚地显示异常行为。降维变换的标准函数也可以用于进行欺诈疑似性的概率评分,包括主成分分析(principal component analysis,PCA)、独立成分分析(independent component analysis,ICA)、探索性投影追踪(exploratory projection pursuit,EPP)、多维标度(multidimensional scaling,MDS)等[67]。文献[68]使用PCA 从原始特征中提取满足累积贡献需求的主要成分,在保留欺诈有效关键特征的前提下减小了样本的维数,提高了模型训练效率;文献[69]提出了一种在线过采样的PCA 算法,不存储整个数据矩阵或协方差矩阵,根据产生的主导特征向量变化来确定目标实例的异常,适用于具有计算或内存限制的在线应用程序。
4.2.3 异常值检测
跳脱于任何已有聚类的游离观察值记录在数据集中被称为异常值。在欺诈检测中,异常值通常对应为疑似交易。文献[70]改进了基于距离(distance-based)的异常值检测,提出了一种基于单元(cell-based)的方法用于优化异常值检测中距离的计算;文献[67]通过总结了表征用户行为的多特征变量,将总距离度量定义为在每个特征上距离的线性组合;文献[71]基于模糊局部离群因子(LOF)提出了一种信用卡交易数据集的异常检测算法;文献[72]不同于传统基于密度的方法,提出了一种基于相互强化的局部异常值检测方法,未将局部异常值定义为噪声而是尝试在中心识别异常,实证表明了方法稳定性与解释性;文献[73]比较了基于距离、基于密度(density-based)两种异常值检验的区别,发现当数据集包含不同特征模式时后者优于前者,引入了一种基于连接(connectivity-based)的方案提升了基于密度方案的有效性;此外还有诸如快速分布式异常值检测[74]、基于边界和距离的异常值检测[75]、基于NADI(non-almost derivable itemsets)的异常值检测[76]、基于时空的异常值检测[77]、基于粒度计算和粗糙集的异常值检测[78]、基于自然离群因子的异常值检测[79]、基于平均散度差的异常值检测[53]等的研究。离群值检测算法的缺陷在于,无论基于密度还是距离的异常值检测都必须定义一个距离度量,然而海量数据高维点之间距离需要耗费大量计算资源。优化的距离计算性能是异常值检测相关算法研究的难点和重点。
4.2.4 隐马尔可夫模型
隐马尔可夫模型(hidden Markov model,HMM)是一种时序数据建模的概率统计模型,描述一组连续有限状态,每个状态与一个概率分布关联。在欺诈检测中应用HMM时,持卡人支出信息,包括每笔交易花费、商品购买时间、商品类型、商家名称和支付位置等都可以描述为一组有限的状态,HMM 根据持卡人的正常行为进行训练,若模型不接受新交易的状态数据,则该交易被视为疑似交易。文献[80]使用HMM对信用卡交易中操作序列进行建模,验证了HMM 的有效性。文献[81]引入HMM 实现了一个动态创建和更新交易行为的自动检测欺诈模型。文献[43]利用多视角HMM 方法,采用自动特征工程方法建模信用卡交易间的时间相关性,并结合其他基于专家的信用卡欺诈特征工程策略,提高了分类的有效性。
4.2.5 自组织映射神经网络
自组织特征映射神经网络(self-organizing feature map,SOM)是一种无监督学习的神经网络模型,适用于高维数据的分析和可视化。文献[52]利用SOM 的聚类和过滤功能检测信用卡交易欺诈,无需相关先验信息即可识别输入数据中新的隐藏模式,实现对用户交易行为的破译、过滤和检测。文献[82]提出了一种SOM用户帐户可视化的欺诈检测方法,在SOM 网格上可视化矩阵并结合基于somu 矩阵的检测阈值设置方法,实现对信用卡欺诈的有效识别。
4.3 半监督学习
半监督学习方法只需少量已标记数据和大量未标记数据来实现欺诈检测,即从标记和未标记的数据中训练分类器[83]。半监督学习的优势在于只需要少量标记的实例即可获得良好分类性能。由于输入数据多数是无标签的,半监督学习通常被认为更贴近人类的学习模式。文献[84]研究了非平衡分类问题中半监督学习的性能,使用数据代位法对少数类进行扩充以降低估计方差,在欺诈检测应用取得了良好的效果。
4.3.1 生成模型
生成模型的思想是半监督学习的重要分支之一,文献[29,85]分别训练了一个生成模型以输出少数类的模拟样本,将其与原始数据合并为一个增广训练数据集以提高分类有效性。实验表明,生成模型的效果优于欠采样或过采样等方法。生成对抗网络(generative adversarial networks,GAN)也是一种半监督学习领域中多层结构深度学习技术,由一个生成模型和一个判别模型组成,两个模型相互竞争进行零和minimax 博弈[86]。文献[87]为解决GAN训练不稳定以及采样限制的影响,引入WGAN模型(Wasserstein-GAN)实现了更好的效果。
4.3.2 主动学习
主动学习(active learning)是一种筛选训练数据的机器学习方法,通过算法查询最有用的未标记样本交由专家人工标记,训练模型提高分类精确度。在信用卡欺诈检测领域,邀请专家为数据标签成本过高。对比于全部数据人工标注,主动学习方法只需花费一小部分时间即可构建出更好的数据集。不同于被动的接受知识,主动学习能够选择性地获取知识来修正模型。文献[88]研究了主动学习策略对信用卡欺诈检测准确性的影响,分析和比较各种不同策略,包括标准主动学习、探索性主动学习、半监督学习及其组合应用,实验结果表明信用卡欺诈检测中无监督的异常检测准确性非常低;将欺诈行为的基线主动学习与随机半监督学习相结合,显著地提升性能。不过,数据中正负样本比例的高度不平衡,导致探索性主动学习未能改善欺诈检测的精确度。
4.3.3 群智能算法
群智能算法也是一种较强鲁棒性的仿生型算法,通常配合无监督学习选择实例以缩小范围,或结合监督学习减轻正负样本不平衡性。在信用卡欺诈检测的半监督学习研究中,群智能算法常用于模型的优化、参数调优等环节,还可采用分布式计算提高效率。文献[50]将K-means 和人工蜂群算法(artificial bee colony,ABC)结合,其中ABC 将邻域搜索与全局搜索相结合,解决K-means对初始条件敏感问题。实验结果表明,能够有效提高对可疑交易风险的分类准确率,且显著加快模型收敛速度。文献[89]利用蚁群优化实例选择算法(ant colony optimization instance selection algorithm,ACOISA)提出了一种SVM 速度优化的检测算法,采用ACOISA进行边界检测,采用KNN进行边界实例选择,既提高了SVM训练速度又没有显著损失分类质量。文献[90]将布谷鸟搜索算法(cuckoo search,CS)、粒子群算法(particle swarm optimization,PSO)用于SVM参数优化,有效提升了检测效率。
4.4 强化学习
强化学习(reinforcement learning,RL)来源于行为心理学的启发,代表着智能体(agent)和环境(environment)之间的交互问题。强化学习无须事先给定数据,而在通过接收环境对动作的奖励不断循环更新模型参数,以获取最大收益。目前,RL在信用卡交易行为欺诈检测领域也有着很大的用武之地。信用卡交易行为欺诈可以显然地建模为发卡行与欺诈者之间的博弈过程。通过模拟两者之间的交互可以动态地学习到欺诈行为的变化,以更好地解决概念漂移问题,发掘尚未发现甚至尚未发生的欺诈行为模型。文献[91]利用强化学习将欺诈者与发卡行之间的交互作为马尔可夫决策过程(Markov decision process,MDP),通过采取行动(交易)并获得奖励(与交易是否相关)来考虑与环境(商人和欺诈分类器)进行交互以模拟欺诈事件,研究发现,与静态分类器相比,定期细微更改欺诈分类器会改善智体学习最佳策略的能力。此外还可利用强化学习进行决策服务,通过对环境的监控和模拟,优化实时欺诈交易的拦截执行过程,在较短的时间内提供较好的决策。
马尔可夫决策过程是强化学习求解的基本思路。按照马尔可夫决策过程中的信息是否完全存储可以将马尔可夫决策过程分为两类,即基于模型的强化学习和无模型的强化学习,其中基于模型的强化学习已知全部马尔可夫决策过程的信息,可以用动态规划的方法对问题进行解决,而无模型的强化学习对上述信息未知,需要自行探索马尔可夫过程。在实际的问题中,状态转移信息往往无法获得属于无模型的强化学习方法,常用的方法有蒙特卡洛(Monte Carlo)方法和时序差分(temporal difference)方法,如图18 所示。三种选择最优策略中的第一个为动态规划方法,另外两个从左到右分别为蒙特卡洛方法和时序差分方法。图中白色的圆圈代表状态,蓝色的圆圈代表动作,绿色圆圈代表该状态为本次测试结束,蓝色的阴影部分为每次更新需要的信息。对于动态规划方法,在对策略进行更新时,需要获取整个模型的信息,这也是这种方法适用于基于模型的强化学习问题的原因。对于无模型的强化学习问题,蒙特卡洛算法需要的信息要比时序差分方法更多,蒙特卡洛方法需要知晓一个完整的样本,即一条完整的路径才可以对策略进行更新,每次只能更新一条路径。而时序差分方法所需要信息最少,只需要一条路径的部分信息即可以对策略进行更新,对于蒙特卡洛和时序差分方法来讲,模型都是未知的,这两种方法都是通过不断地尝试来对真实值进行近似。

图18 三种强化学习方法对比图Fig.18 Comparison chart of three reinforcement learning methods
在强化学习中也可以使用深度学习模型。将深度学习与强化学习结合后的机器学习方法被称作深度强化学习,对于一些复杂的深度强化学习算法,可以作为用来解决发展问题的通用智能,但聚焦到信用卡欺诈检测领域,该类研究还尚未涉足。
4.5 模型融合
模型融合是指集成多种模型的一种组合算法,通过拣选每种方法的有益属性,扬长避短、取长补短,构造针对特定问题的高效算法。常用的一种模型融合方法是混合级联方式,譬如将第一种方法的输出提供为第二种方法的输入[66],或者一种方法用作预处理步骤,修改数据以进行分类准备[92],亦或将算法的各个步骤交织在一起,从而创建出一些新的混合算法[23]。混合级联常用于针对单个问题域定制解决方案,针对提升模型性能的具体某方面,包括分类能力,易用性和计算效率等。在欺诈检测模型融合研究中,混合级联目前处于应用的上升阶段,文献[23]结合使用了散点搜索和遗传算法,在遗传算法架构上针对散点搜索的特性(例如较小的种群和重组)将其作为复制方法。文献[66]首先利用Depster-Schaefer 方法来组合规则,然后使用贝叶斯学习器来检测欺诈。一些研究人员应用模糊逻辑将变异引入样本,然后再部署另一种技术来实施欺诈检测[93],实验结果表明,对欺诈检测问题应用“模糊性”方法可以提高原方案的性能。
模型融合的另一个思路是集成学习,也就是分类器集成,构建多个学习器后通过合并来完成学习任务。通常按以下两个步骤操作:首先根据互补性选择一系列不同的算法,然后将各弱分类器的结果通过采用共识标准进行合并,例如多数投票、加权、置信和排名投票等。文献[94]提出一种基于深度信念神经网络的集成学习算法来解决信用欺诈问题,结果表明在处理极端不均衡数据时所提算法效果更优。文献[95]采用XGBoost 算法构建了一个信用卡交易欺诈预测模型,通过网格搜索的方式对XGBoost参数调优。文献[3]表明集成方法是有效解决类不平衡问题的最有效方法之一,集成模型显示出比非集成模型更好的性能。文献[96]研究了信用卡欺诈集成模型的投票机制,表明不同的集成方式(例如基于乐观、悲观、加权等)将导致不同结果,因此银行或监管机构可根据不同的需求选择不同的集成方式。文献[97]对比评估了集成学习方法与深度学习的效果,发现集成学习模型在准确性指标上不及深度学习,但集成学习模型具有更快的训练速度和更高的算法效率。文献[98-99]分别针对信用卡欺诈检测的数据分布、实例检测难度等问题,“因地制宜”地提出了基于数据分布的异构集成学习模型(heterogeneous ensemble learning model based on data distribution,HELMDD)以及基于实例难度不变性的boosting集成学习模型(boosting with instance difficulty invariance,BIDI),均表明了集成学习于信用卡欺诈检测场景的优越性。
4.6 检测模型的趋势与未来
表8展示了各类模型发表年份的分布,可以看出信用卡交易欺诈检测方法的总体趋势是逐步向深度与智能发展,同时表现出各种机器学习方法跨界使用、多类方法融合使用、多目标优化的趋势等。
表8 各类模型与算法的研究文献分布与比较Table 8 Distribution and comparison of research literature on models and algorithms
从各类机器学习范式来看,整体上反映了由“小数据”到“大数据”再到“小数据”的趋势。具体来说,早期研究使用的模型算法多集中于有监督的统计机器学习和无监督的异常检测中,主要由于早期模型相对简单、计算性能不足、可用数据有限,导致无法对于数据进行深度挖掘,只能利用少量的标签数据进行简单的有监督学习或进行无标注的异常检测;随着人工智能技术的发展、海量信用卡交易数据的积累以及计算性能的不断提升,面向信用卡欺诈检测的人工智能算法研究开始大量涌现,致力于从更大数据量、更广特征类型中深度挖掘有效信息并不断提升计算性能;而昂贵的有标注数据、正负样本极度倾斜、由于用户隐私带来的数据孤岛等问题始终存在,不断扩大数据广度和深度带来的边际效益在递减而成本在递增,此时半监督学习、联邦学习、迁移学习、强化学习等拓宽数据限制的机器学习范式给信用卡欺诈检测带来了新的思路和增量,不再追求“大数据”而回归“小数据”的深入研究,相信在未来,对于数据受限的前提下进行的深度挖掘仍旧大有可为。
从各类机器学习方法来看,模型的跨界融合已成为大势所趋。不仅体现于模型混合级联与集成,也表现在跨任务的模型借鉴与使用:例如信号处理领域经典运用的小波变换/傅里叶变换、计算机视觉领域常用的卷积神经网络/循环神经网络/注意力机制、自然语言处理领域的预训练迁移学习模型等均在信用卡欺诈检测任务中大展身手,未来的研究也可大胆尝试其他机器学习领域中的先进模型,加以在信用卡欺诈检测因地制宜地改进以发挥创新优势。模型算法的发展不仅是跨界融合,也在朝着各自细分领域的分化发展。例如目标是利用少数标签完成信用卡欺诈检测的半监督学习、解决数据孤岛和隐私问题的联邦学习、解决非平稳数据环境下快速复用的迁移学习、挖掘对抗博弈过程的强化学习、为解决概念漂移而产生的动态模型和增量学习,以及部分研究牺牲准确度换取更好的可解释性等的各种不同的新兴研究趋势。面向信用卡欺诈检测的机器学习算法与模型可谓是多点开花,未来的发展充满无限的想象空间与可能性。
5 评价指标
信用卡交易欺诈判别是一个二元分类问题。当被系统阻止的交易事后被证明非欺诈时,则为误报;没被阻止的交易时候被证明是欺诈时,则为漏报。漏报产生经济损失,误报导致损害用户体验、降低商誉。理想情况下,模型评价应该根据真实数据验证得出,然而现实世界中真实、全面、完整的完美标签数据集是不存在的。邀请领域专家为全部数据记录做标记,这是一个耗时、费力、昂贵的过程。作为一个折衷,多数研究使用部分标注的数据集评估模型,设定一个阈值以便控制标记数据量于可承受水平之内,即阈值依赖型指标,也可称为混淆矩阵指标。若每次交易的误判代价不同,又产生了代价矩阵指标。还有一些研究为了克服阈值设定的局限,进一步衍生出了非阈值依赖型指标,如图19所示。
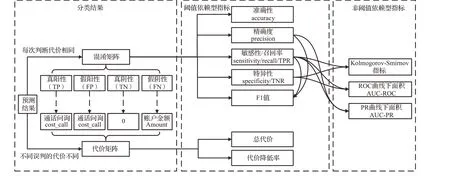
图19 面向信用卡交易欺诈分类的评价指标Fig.19 Evaluation indicators for classification of credit card transaction fraud
5.1 阈值型指标
在实践中欺诈检测系统中通常给定交易的风险概率而非二进制标签。鉴于交易核查人力有限,也避免对正常持卡人的过度骚扰,信用卡机构倾向于只核查少量的高风险交易,因此通常设定一个阈值以便控制警报数量,将其置于可承受水平之内。很多研究将可疑交易按概率降序排列,取前k个高风险交易分类,即“top-k方法”。显然该方法仅适用于一段时间内的累计,而无法实时评价,一般设定一个阈值δ来衡量效果。具体来说,设xi是第i个交易的特征向量,yi∈{0,1}表示其是否为欺诈交易。训练欺诈检测模型y^ =f(x),当欺诈分数y^ ≥δ时为欺诈,即{xi:y^i≥δ}则将标签ci记为1,即确定阈值δ之后,可得表9的混淆矩阵。

表9 欺诈识别的混淆矩阵Table 9 Confusion matrix for fraud identification
混淆矩阵指标包括准确性(accuracy)、精确度(precision)、召回率(recall)、特异度(specificity)、F1值等,其中召回率也被称为灵敏度(sensitivity)或真阳性率(true positive rate,TPR),特异度也被称为真阴性率(true negative rate,TNR)。大多数研究都使用精确度、召回率、特异度、F1 值[3,33,43,100]等评价指标。在信用卡欺诈场景中检测准确性不是一个合适单一指标[1,38,80],欺诈检测通常面对一个正负样本极度不平衡的数据集,即便取得了极高的准确性,也可能大比例漏报,即高准确低召回[97]。
混淆矩阵指标简单把分类错误视为等同代价,事实并非如此。欺诈检测的两种错误类型,一种是错误分类导致的误报(FP),另一种是遗漏欺诈导致的漏报(FN)。相比之下,后者代价要高得多。表10 列出了欺诈检测的代价矩阵,欺诈误判(CFP)成本为人工电话核实产生的代价(CCall),而漏报(CFN)成本为欺诈金额损失(li)。通常后者单次成本是前者百倍以上[40],不过,过于敏感的检测系统频繁误报会不断骚扰正常持卡人,导致机构商誉受损甚至市场份额降低。另外,漏报很可能是当前模型不能识别的新欺诈模式,其损失可能会持续发生,直到该欺诈模式被发现为止。总之,降低FN比降低FP更重要,即召回率Recall比精确度Precision更有经济价值。


表10 欺诈识别的代价矩阵Table 10 Cost matrix for fraud identification
5.2 非阈值型指标
非阈值型指标包括Kolmogorov-Smirnov 指标[101]、曲线下面积(area under curve)[2,3,102]等,如图20所示。

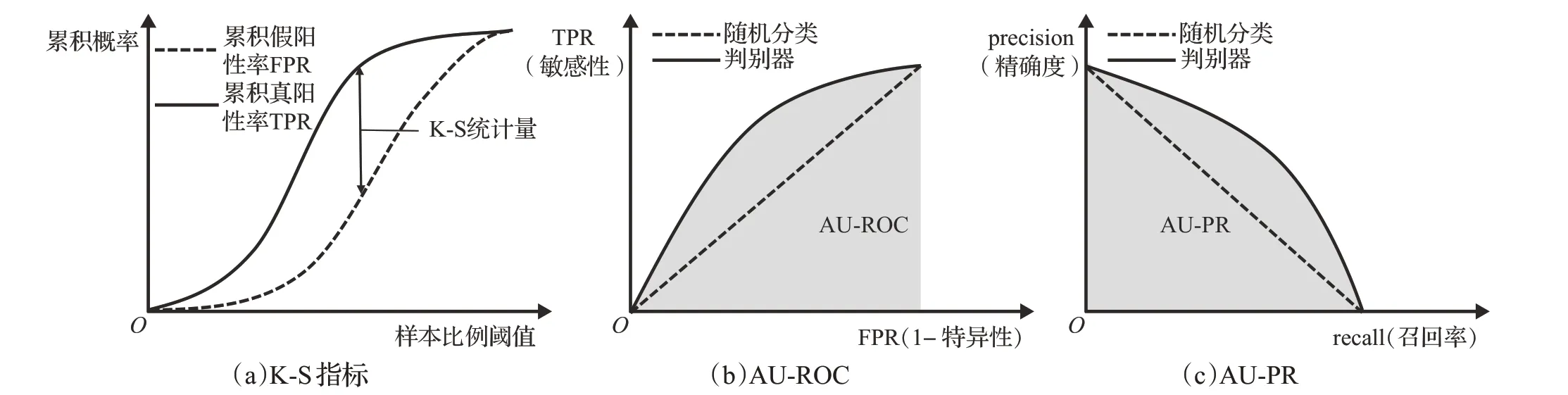
图20 非阈值型指标示例Fig.20 Example of non-threshold indicator
常用AUC指标包含AU-ROC与AU-PR。AU-ROC接收器操作特性曲线(receiver operating characteristic curve)通过构图揭示了灵敏度和特异度连续变量二者的相互关系,以灵敏度为纵坐标、(1-特异度)为横坐标绘制成曲线,如图20(b)所示。AU-ROC是x轴和曲线之间的归一化积分,范围介于0(最坏)和1(最好)之间,曲线下面积越大,则检测准确性越高。在AU-ROC曲线上,一个理想分类器应该在左上角(0,1)处,代表最完美的灵敏度和特异度;随机猜测则是一条对角线,如图中虚线所示。一般来说,AU-ROC值大于0.8,则可认为模型的欺诈区分能力较佳。AU-ROC 优点是不受正负样本分布比例的影响。但在信用卡欺诈检测情境中,交易数据集都是正负样本极度不平衡的,当负样本数量远超正样本,伪阳性FP大幅增长只能换来FPR微小改变。即便大量误报,ROC曲线却无法直观表现,呈现出一个虚假乐观的效果估计。AU-PR 曲线展示的则是Precision vs Recall 的曲线,如图20(c)所示,AU-PR 也采用曲线下面积来衡量分类器的效果。不同点在于AU-ROC 横坐标为FPR而AU-PR为recall,因此AU-PR曲线横纵两个坐标都聚焦于正样本。在信用卡欺诈数据集正负样本比例极度不平衡条件下,学者普遍认为AU-PR 指标优于AU-ROC。
综上所述,AU-PR 完全聚焦于正样本,而K-S 与AU-ROC比较兼顾正负样本,适用于评估分类器的整体性能。其中,K-S 值取TPR 和FPR 间最大差值,给出最佳的划分阈值;AU-ROC反映了模型判别正负样本的整体情况。若存在多个数据集且各自正负样本比例不同,则AU-ROC、K-S 比较适合;若考虑分类器对较少数量正样本的识别性能响,则AU-PR更为适合。
表11列举了上述各类评价指标的含义、计算方法、优劣势,以及使用场景。

表11 各评价指标对比Table 11 Comparison of evaluation indicators
5.3 评价指标研究的趋势与未来
表12 统计了20 年来领域文献采用的评价指标分布,混淆矩阵指标因其概念简单、计算方便而占据信用卡欺诈检测的评价主流,但近年来代价矩阵指标和非阈值依赖型指标正以极快速度发展逐渐占据了更大比例。究其原因,非阈值指标的多阈值、多角度综合评价,更能反映模型整体表现,更具客观性;代价矩阵指标真正关注信用卡欺诈检测初衷,即最大程度降低损失而非最多数量发现欺诈。目前多数研究都开始从降低损失总额角度提出模型的优化方向。此外,欺诈检测模型评价还有很多潜在的研究方向和角度,譬如模型评估维度、算法性能、持卡人用户体验等方面。其中评估维度改变是指现有研究大多数都是从交易维度而非信用卡维度评价模型。实际上,同一张卡多次疑似交易更应该被视为一次警报[34],实践中交易核查人员电话联系持卡人时,通常也会核实其最近所有交易。因为欺诈者获取信用卡信息后,伎俩一旦得逞,通常会持续盗刷。未来欺诈检测研究可以更多尝试在卡级别进行,一旦确认一笔新的欺诈交易,应该立即暂停支付以防止进一步损失。
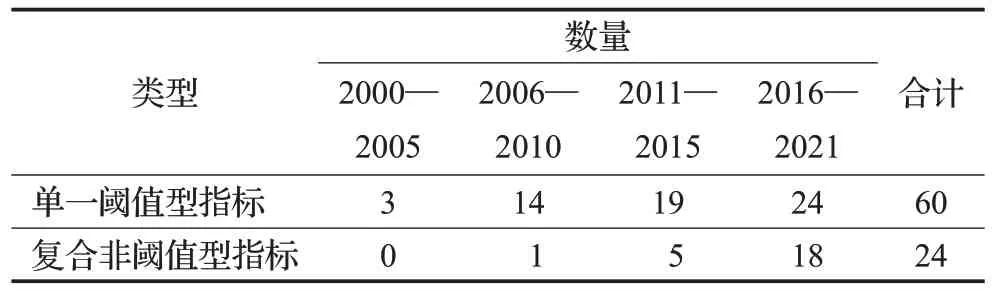
表12 主要评价指标分布Table 12 Distribution of main evaluation metrics
6 困难与挑战
基于机器学习的信用卡交易欺诈检测是一个非常困难的任务,诸多研究均面临着一些共同的挑战,包括海量数据产生的计算复杂性、正负样本极度不平衡的样本偏斜、欺诈模式随时间变化的概念漂移等问题。
6.1 海量数据与计算实时性
古人云“工欲善其事,必先利其器”。基于机器学习的欺诈识别方法普遍存在着过度消耗计算资源的弊端。由于交易流量的增加、算法结构的复杂,欺诈检测变得困难而复杂,严重拖慢了检测速度。然而欺诈检测实质上是一个时间价值函数[9],即欺诈识别速度越快,挽回的损失就越多。现有研究开始着力解决检测模型的效率问题,在不影响检测准确性前提下,采取适当手段约简数据、分布式计算以减少处理时间,如图21所示。

图21 在线欺诈系统应对海量数据的常用手段Fig.21 Common means for online fraud systems to cope with massive amounts of data
数据约简包括数据压缩、特征选择、特征构造和数据降维等手段,以减少计算时间、利于实时处理[103]。其中,数据压缩通过压缩技术以减少计算量[68];特征选择包括过滤器方法、包装器方法和嵌入方法,选择最重要、最相关的特征构建模型[47,51,97,104];特征构造是指从原始数据集中派生一小部分特征,使得数据以较小的形式表示,譬如交易聚合策略既能约简数据、又能有效捕获每笔交易之前的消费者购买行为,将这些聚合用于模型估计以识别欺诈交易[3,33-34];数据降维对原始数据进行约简降维,有效减少信用卡训练数据集的尺寸[68-69]。
面向分布式计算的机器学习算法研究日益增长,譬如Hadoop/MapReduce框架[105-107];有研究表明,在云计算架构下分配和处理数据利于加快知识提取过程[108];文献[56]使用云计算架构并行化处理数据,实现了基于人工免疫系统的信用卡欺诈检测系统,并测试了云服务性能,提供了准确性测量;文献[109]提出了一个分布式异常检测系统,使用批量同步并行模型(bulk synchronization parallel,BSP)改进嵌套循环算法(nested-loop,NL),有效提升了检测性能;文献[110]提出了一个可扩展实时欺诈检测(scalable real-time fraud finder,SCARFF)开源平台来处理和分析流数据,测试了190 万张信用卡/800万笔交易流数据,SCARFF能够在非平稳、类别不平衡、验证延迟的环境下提供较为准确的分类;另外一些文献[111-112]也考虑了系统性能限制,提出了各自的可扩展实现。
6.2 样本偏斜
正负样本比例极度不平衡也是欺诈检测面临的主要挑战之一。类别失衡严重的监督学习中,少数类的模式往往被多数类数据所淹没,严重影响分类效果[67]。欺诈交易在所有交易中所占比例很小,极大地影响了欺诈检测模型的性能。均衡正负样本比例失调问题的方法,按处理阶段的不同,可分为两个不同的研究方向,如图22所示,即数据级和算法级机制。比较而言,数据级方法的使用总体上要多于算法级方法,主要由前者更易于实现,也不会延长训练时间或加重计算负担。未来,主动学习、生成模型等半监督学习和自监督学习也有望给解决样本偏斜问题带来新的思路。
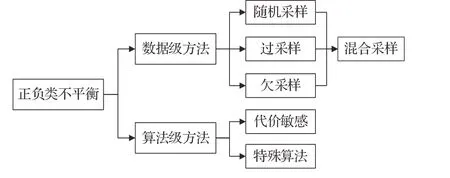
图22 不同类别的样本平衡处理方法Fig.22 Balanced treatment of different categories of samples
数据级方法是指在模型训练之前,预处理样本数据集以平衡正负样本比例。数据级平衡技术包括欠采样和过采样方法。欠采样指从数据集中剔除一部分多数类样本,以平衡两类样本比例[3,23];过采样指复制少数类样本以增加其在数据集中的比例[33]。欠采样的缺点是有可能丢失一些重要信息,影响分类器的学习;过采样的缺陷是大量重复样本容易导致对噪声的过拟合。许多学者转为研究二者的组合与更新。譬如,合成少数类的过采样技术(synthetic minority oversampling technique,SMOTE),在被观察样本附近生成额外的少数类样本进行过采样[28];还有先基于数据分布欠采样,再聚类创建平衡数据子集,以解决正负样本不平衡,取得了超越SMOTE 的效果[98];还有文献实验对比各种数据级平衡技术(Under、SMOTE、EasyEnsemble等),分析各种数据采样技术的有效性[6]。
算法级方法是指通过代价敏感改进算法,以应对有偏的样本分布。具体来说,创建代价矩阵以使模型有偏,假阴性或假阳性不同类型的误判,其代价不同,最终求解代价最小化或收益最大化。还有一些算法本身对类别失衡不敏感,或改进后使其对类别失衡不敏感,以应对样本的偏斜。文献[45]提出了一种成本敏感决策树方法,在选择每个非终端节点的分割属性时最小化误分类成本,实现了更好的准确率和真阳性率。文献[34]构造了一个成本敏感的随机森林,进一步提升了性能。文献[68]改造SVM 算法提出了一种不平衡类加权支持向量机(ICW-SVM)来处理样本不平衡。文献[82]利用SOM 矩阵分解,通过矩阵分类阈值设置应对样本偏斜。文献[113]基于对抗生成网络和集成学习方法,提出一种新的针对二类不平衡数据集的分类方法。文献[94]提出一种深度信念神经网络集成算法来解决类极度不均衡的信用欺诈问题。此外,一些异常检测模型[21,74]、集成模型[8,96]以及深度学习模型[4,60]均可有效减轻数据偏斜的影响。
6.3 概念漂移
概念漂移是指研究对象随着时间的推移其统计特性以不可预见的方式变化的现象,或是在动态环境中研究对象的行为不断变化所产生的各种问题[114]。在信用卡欺诈检测领域,由于各种外部原因持卡人行为可能发生变化,若系统无法正确处理,将误触警报中止正常交易;此外,各种欺诈新模式不断涌现,检测模型必须动态学习、自动适应、捕获新的欺诈类型。随时间流逝,输入数据特征与目标变量之间联系不断变化,概念漂移为监督学习模型构建带来了很大的挑战[114],特别是对于在线学习,新数据不断到达会导致模型产生更多误报。
自适应学习算法是面向求解概念漂移的一种先进的增量学习算法,能够随着时间更新流数据[65]。增量学习的每个时刻t,通过全部数据或部分Xhistory=(X1,X2,…,Xt)标记数据训练学习器Lt,如图23所示,当新进交易输入Xt+1时,其任务是预测标签yt+1。当标签yt+1变为可用时,增量学习过程将Xt+1成为后续预测Xt+2的历史数据的一部分。

图23 面向概念漂移的增量学习示意图Fig.23 Schematic diagram of incremental learning for concept drift
自适应学习器可分为基于进化的与基于规范的两类方法。基于进化的方法是指自适应学习器通过自动调整其行为,包括集成学习或特定的模型参数设置,来保持与数据流动态的最新行为模式。文献[6]在遗忘和每日更新的增量学习基础上提出了一种自适应的信用卡欺诈检测系统,比较了变化环境中处理不平衡问题前提下静态方法、更新方法和遗忘方法三种方法的优劣。文献[34]构造了一个反馈随机森林,在反馈和延迟的监督样本下训练分类器,能够自进化地学习概念漂移。文献[100]提出了一个交易窗口集成(transaction window bagging,TWB)模型,通过并行增量学习处理信用卡交易数据,有效解决概念漂移和数据不平衡。文献[61]使用深层序列神经模型和滑动窗口应对概念漂移。基于规范的方法是指构造概念漂移检测器,在欺诈模式变化时做标记再采取相应措施。文献[39]构造了一个关联规则分析器,提取正常和异常交易行为的关联规则,通过监控学习两种不同的关联规则来处理概念漂移。文献[92]构造了一个两阶段模型检测欺诈交易,第一阶段建立了一个交易时间相似性度量,为近期交易赋予更大的权重,在第二阶段应用动态随机森林算法结合最小风险模型检测欺诈行为。基于规范的方法的优势在于对概念漂移的具有适应性且提供了有关漂移的所需信息,但目前相关研究数量远少于基于进化的方法。
针对概念漂移,当前解决方式都是针对已发生的模式变化的挖掘,无法即时检测全新的欺诈模式。这就导致新欺诈模式出现初期持卡人势必产生损失。为了降低欺诈的金额和持续时间,系统需要投入大量资源不断更新模型。 概念漂移问题作为信用卡欺诈检测的重难点问题之一,基于迁移学习和基于强化学习的方法有望为问题解决带来新的思路和发展方向。
7 结语
本文回顾了面向信用卡欺诈检测的机器学习领域研究,从技术框架、特征工程、模型算法、评价指标等几个方面综述了最近20 年来国内外研究的最新成果,对比了模型算法的优劣与适用范围,归纳了发展过程并总结了发展趋势。就技术框架而言,从专家规则到机器学习的系统架构演进,从小数据处理到大数据分析的计算能力演进;就特征工程而言,文本、图片、音频、视频、网络等多模态特征突破了传统的数据形式限制,动态、同质性行为的特征聚合,拓宽边界、跨领域融合是研究关注的重点;就模型算法而言,数据挖掘模型呈现从“小数据”到“大数据”再回归“小数据”的趋势,各种机器学习算法跨界使用、多类方法融合逐步向深度、智能发展的趋势,在半监督学习、联邦学习、迁移学习、强化学习等各个细分领域和目标分化方向还有广阔空间亟待后续研究填补空白;就评价指标而言,基于混淆矩阵和代价矩阵的评价指标占据了当前研究的主流,面向商誉损失和用户体验的指标设计也是非常有潜力的研究方向之一。
本文归纳了信用卡反欺诈的机器学习研究必须面对的三个困难和挑战,即海量数据与计算实时性、样本偏斜和概念漂移的问题。本领域未来工作就是不断直面这些挑战、不断突破思维限制、不断扩展特征边界、不断改善分类模型、不断提升算法性能。此外,机器学习的生命之源在于大数据,而大数据价值的产生机理和转换规律具有高度的应用领域依赖性。每个领域的欺诈模式都有其独有的特点,有必要面向管理与决策情景将多源异构和非结构化大数据进行关联,开展全景分析、实时动态计算、挖掘模型构建等跨平台、跨学科、跨行业的研究融合。
对未来信用卡反欺诈可能出现的新场景和新问题,本文也提出几点设想:首先消费场景改变,电子商务与全球跨境贸易使得信用卡支付行为模式今时不同往日;其次商品本身的转变,未来更多的交易商品具备独特的纯数字属性而非实物或服务;再次信贷形式的改变,“白条”“借呗”等互联网小额借贷或成新的信用卡欺诈检测领域之一;第四货币性质的改变,数字货币与区块链的运用给信用卡欺诈检测带来新的变量和抓手;最后空间背景的改变,“元宇宙”纯数字场景下的消费、借贷与欺诈可能出现全新的命题。总之,面向信用卡欺诈检测的机器学习方法研究方兴未艾,技术上有不断探索的空间,应用场景上也存在无限可能,都会带来新的更大挑战,信用卡反欺诈也将是需要持续关注和研究的热点问题。
猜你喜欢
眼科新进展(2022年12期)2022-12-29
中国外汇(2019年16期)2019-11-16
中国外汇(2019年10期)2019-08-27
瞭望东方周刊(2017年35期)2017-09-22
股市动态分析(2016年23期)2016-12-27
中国防伪报道(2016年10期)2016-11-21
公民与法治(2016年24期)2016-05-17
公民与法治(2016年6期)2016-05-17
上海国资(2015年8期)2015-12-23
股市动态分析(2015年13期)2015-09-10
