
自适应聚类中心策略优化的密度峰值聚类算法
2023-11-20 10:58徐童童张喜梅张春昊
计算机工程与应用 2023年21期
徐童童,解 滨,3,张喜梅,张春昊
1.河北师范大学 计算机与网络空间安全学院,石家庄 050024
2.河北师范大学 河北省网络与信息安全重点实验室,石家庄 050024
3.河北师范大学 供应链大数据分析与数据安全河北省工程研究中心,石家庄 050024
聚类是根据样本之间的相似性度量,将数据集划分为多个类簇的过程。聚类结果使相同簇中的样本具有高度的相似性,不同类簇的样本具有较大的相异性。聚类是机器学习中一种重要的无监督数据分析方法[1],借助聚类可以揭示数据中隐藏的规律,已广泛应用在社会网络、统计学、模式识别和信息检索等领域[2-5]。
在过去的几十年里,许多学者针对不同的应用开发了大量的聚类算法。包括基于划分、基于层次、基于网格、基于密度以及基于图论的聚类算法[6-9]。基于划分的K-means[10]聚类算法在凸球形结构的数据集上取得了良好的聚类效果,但其参数k需要预先指定,且严重依赖于初始聚类中心,无法找到任意形状的簇,聚类容易受到噪声或离群点的影响。基于密度的DBSCAN[11]算法对不规则类簇有很好的聚类结果,且不容易受到噪声点和离群点的影响,但处理密度差异较大的聚类和高维数据,聚类结果较差。此外,聚类结果对半径Eps和密度阈值MinPts的选择较为敏感。近邻传播算法聚类算法AP(Affinity Propagation)[12]将每个样本点看作图的一个顶点,通过反复迭代传递近邻样本之间的信息,寻找最优类簇集合,该算法不需要预先设置中心点数目,但不能发现任意形状的簇且时间复杂度较高。
2014年Rodriguez等人[13]在Science上发表了基于密度聚类的密度峰值聚类(density peaks clustering,DPC)算法。与传统聚类算法相比,该算法可识别出任意形状的簇,能够直观地找到聚类中心,并高效进行样本点分配和离群点剔除,聚类准确率和计算效率均得到明显提高。此外,该算法参数唯一,无需迭代,具有很好的鲁棒性。然而,DPC 算法也存在一些不足,如对于数据集规模不同,采用的局部密度度量方式不统一;参数截断距离dc的选取会在一定程度上影响聚类结果;利用决策图选择聚类中心点具有很强的人为主观性;单一分配策略也使非聚类中心点分配时容易产生连带错误。
针对DPC 算法的不足之处,近年来有关于DPC 算法的优化算法不断涌现[14-17],这些优化算法主要表现在局部密度的重新度量、聚类中心的自动确定以及分配策略的优化。谢娟英等人[18]提出了一种结合k近邻信息的KNN-DPC算法,将DPC算法度量样本局部密度的两种准则进行统一,提出新的适应于不同规模数据集的统一的、没有截断距离影响的样本局部密度度量准则,同时在对非聚类中心点进行分配时,引入样本k近邻信息,采用两步分配策略,极大地提高了聚类的准确率。然而在选择聚类中心时,仍按照决策图主观选择。Liu等人[19]提出了基于k近邻的自适应密度峰值聚类算法(ADPC-KNN),该算法基于k近邻的思想重新定义截断距离dc和局部密度ρ,扩大了每个核心对象的密度与边界区域其他对象的差异,实现了初始聚类中心的自动选择,但对k近邻引入的参数k所带来的不确定性还是不能避免。李涛等人[20]提出了一种自动确定聚类中心的密度峰聚类算法(ADPC)。根据样本γ值绘制排序图,通过确定“拐点”,将大于该点的γ值对应的点作为潜在聚类中心点,最终,从潜在聚类中心中“筛选”出实际聚类中心,但在处理密度不均匀数据集时,无密度峰簇内聚类中心难以发现。王万良等人[21]提出了自动确定聚类中心的快速搜索和发现密度峰值的聚类算法(CFSFDP),确定密度和距离阈值上限,根据决策函数实现中心点的自动选择。然而该算法没有考虑截断距离dc对局部密度度量的影响,以及切比雪夫不等式引入了新的参数ε,不同的数据集ε选取可能会不同,不具有普适性。Liu等人[22]提出了一种基于共享近邻密度峰值聚类算法(SNN-DPC),该算法基于共享近邻提高了DPC算法在多尺度、交叉缠绕以及变化密度数据集上的优越性能,但无法避免选择聚类中心的人为主观性。张新元等人[23]在SNN-DPC基础上引入放大因子重新定义样本局部密度,提出了共享k近邻和多分配策略的密度峰值聚类算法(SKM-DPC),改进了分配策略,聚类性能较SNN-DPC 有所提升,但还无法避免选择聚类中心的人为主观性。
针对上述DPC 改进算法的不足,本文提出了自适应聚类中心的密度峰值聚类算法(ADPC)。重新定义了局部密度,通过斜率差分和决策函数确定潜在的聚类中心,根据DPC 算法中聚类中心点之间距离较大原则进行筛选,最终自动确定真实聚类中心,同时优化了非聚类中心点的分配策略,避免非聚类中心点分配时产生连带错误,算法适用于不同分布类型数据集。
1 DPC算法
1.1 DPC算法基本思想
DPC 算法的关键是通过决策图能够快速识别数据集样本的聚类中心,实现任意形状数据集样本的高效聚类。理想的聚类中心基于两个假设:(1)其局部密度大于围绕它的邻居的局部密度;(2)不同聚类中心点之间的距离相对较远。
对于数据集中任意样本点xi,DPC 算法需要计算两个变量,即样本点xi的局部密度ρi和相对距离δi。样本点xi的局部密度ρi,定义如公式(1)所示:

相对距离δi为样本点xi到比其局部密度更高且距离最近的点的距离,定义如公式(3)所示:
相对距离δi和局部密度ρi的乘积为γi,定义如公式(4)所示:
DPC算法以局部密度ρ为横坐标,相对距离δ为纵坐标绘制二维决策图,依据DPC 算法中理想聚类中心的两个假设,将具有较高ρi和δi的样本点标识为聚类中心。在决策图中,选择位于决策图右上方的点作为聚类中心。如图1 所示,可以直观得到Jain数据集的两个中心点22 和109,选择出中心点之后,采用一步分配原则将非聚类中心的点被划分到距离其最近的高密度邻居所在簇中。在DPC 算法中,为消除离群点对聚类过程的影响,定义边界区域,即属于该簇但是距离其他簇不超过dc的点的集合,将边界区域中密度最高的点定义为ρb。簇中密度小于ρb的对象被视为离群点。
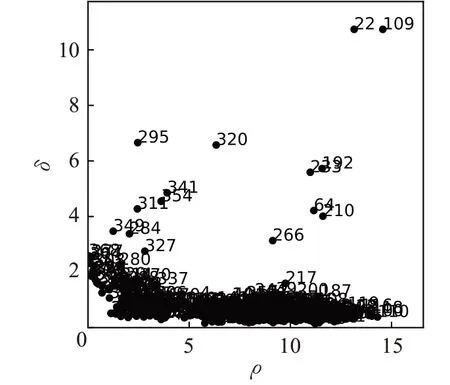
图1 Jain数据集决策图分布Fig.1 Decision graph distribution of Jain
1.2 DPC算法缺陷分析
利用决策图选择聚类中心点人为主观影响较大,且对于密度分布不均匀以及差异性很大的数据集来说,直观选择中心点较为困难。如图2所示,在无监督聚类过程中已经无法通过在决策图直观选择聚类中心,过多过少地选择聚类中心都会导致最终聚类准确率降低。
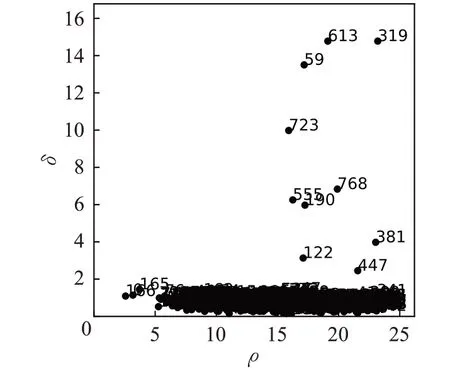
图2 Aggregation数据集决策图分布Fig.2 Decision graph distribution of Aggregation
另外,DPC算法在分配非聚类中心点时采用的一步分配策略,即直接将非聚类中心点分配到比其密度更大且距离更近的点所在的簇中,这种分配策略易产生连带错误,一个样本分配错误,比其密度低且距离最近的点相继都会分配错误,降低聚类准确率。如图3 所示,PathBased 数据集分为三个簇,两个密度相对较大的簇被一个密度较小的环状簇所包围,可以看到密度较小的环状簇两边点的密度也相对较小,一步分配策略导致该簇很多点被错误分配到密度较大的两簇中。

图3 PathBased数据集在DPC算法上聚类结果Fig.3 Clustering of PathBased on DPC
2 自适应聚类中心策略优化的密度峰值聚类算法
为克服DPC 算法与其优化算法的不足,本文对样本点局部密度度量、选择中心点方式以及分配策略进行改进,重新定义了局部密度度量,通过函数变换加大了γ分布图中聚类中心与非聚类中心的区分度,决策函数确定潜在聚类中心,利用距离均值定义实现自适应选择聚类中心,优化了非聚类中心点的分配。
2.1 算法思想
采用共享近邻定义两点之间的相似性度量,用样本k个近邻点之间的相似性和与k个近邻点的距离之和重新定义了局部密度,在γ分布图上采用从右向左的方式根据相邻两点之间斜率差分寻找“拐点”,并在“拐点”附近对样本的γ值进行“拉伸”,采用γ决策函数尽可能多地选择出潜在的聚类中心点,通过DPC 算法中聚类中心特点筛选出真实聚类中心,实现聚类中心的自适应确定,并对非聚类中心点逐级分配。
定义1(样本间相似性)利用共享近邻来定义样本点之间的相似性,对其运用指数核的形式重新定义,如公式(5)所示:

DPC算法在Iris数据集上的γ降序分布图如图4所示,本文ADPC 算法在Iris 数据集上通过Max-Min 归一化的γ降序分布图中如图5所示。从图中可以看出,具有明显密度峰的样本点极少,大多数样本点的γ值较小,而且,对于稠密的簇来说,可能会存在多个γ值偏大的点,在图4中从左向右寻找斜率突变的点容易造成其他聚类中心的漏选,尤其是低密度簇。因此本文引用“拐点”概念,在图5 中从右向左寻找第一个满足公式(7)的点作为“拐点”。“拐点”位置为图中ap,由此可见,当从右向左寻找“拐点”时,在此处斜率存在明显变化,且“拐点”前后样本点γ值存在差异。
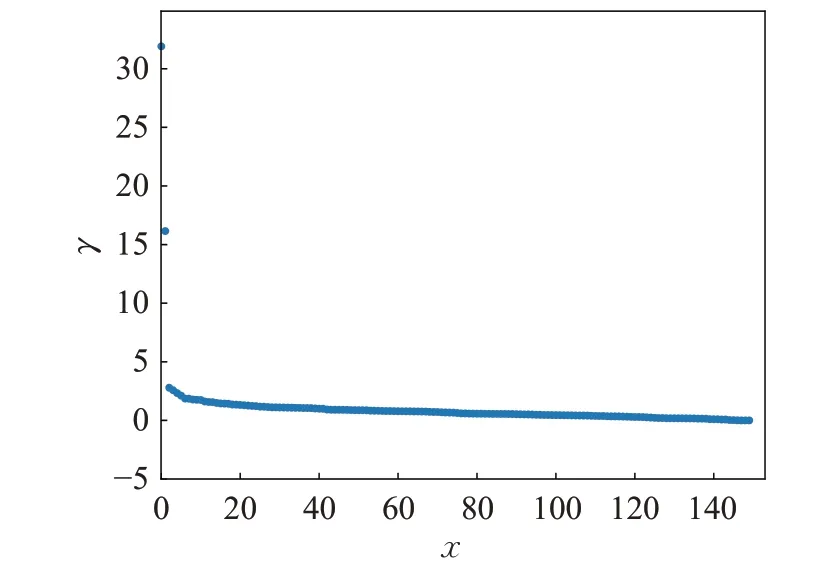
图4 Iris数据集在DPC算法上的γ 分布图Fig.4 γ graph distribution of Iris on DPC

图5 Max-Min归一化后的Iris数据集γ 分布图Fig.5 γ graph distribution of Iris after Max-Min normalization

根据DPC算法中选择γ值较大的点作为聚类中心点的思想,为防止漏选,ADPC算法以“拐点”为中心,将“拐点”附近的点“拉伸”变换,使“拐点”前后的γ值区分更加明显。结合数据样本特点,定义变换后的γ如公式(9)所示:
其中,γ为Max-Min 归一化后每个样本点的升序排列,γap为“拐点”对应的γ值。以Iris数据集为例,每个样本点Max-Min归一化后的γ值经公式(9)变换后的连续函数图像如图6(b)所示,每个样本γ值分布如图6(c)所示。“拐点”变换后的γ~ap=0.5,相比较于图4,原来γ值大的点变换后依旧保持优势,相对中间的点通过变换使“拐点”附近的点γ值明显增大,潜在聚类中心与非聚类中心点之间区分度也增加。可以避免直接在图4中寻找突变点选择中心点造成的漏选问题。比较于Max-Min归一化后的γ分布,ap附近的点被“拉伸”,ap前后的点存在明显差异,进一步拉大潜在聚类中心和非聚类中心的差异,也使得γ分布图中的突变点更加直观。
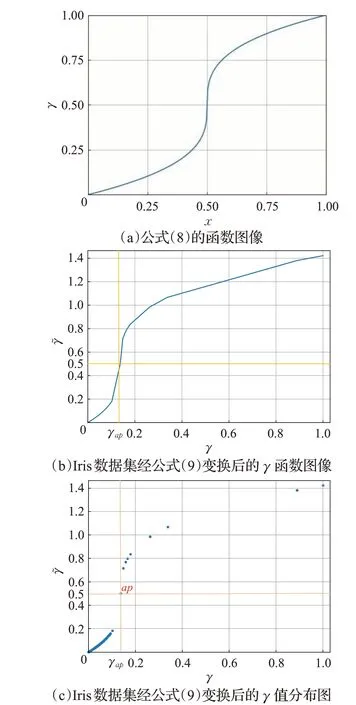
图6 函数可视化图像Fig.6 Functional visualization images
图7和图8分别为DPC算法和ADPC算法在Aggregation 数据集和R15 数据集的γ降序分布图,根据γ值结果分析,图7(a)按γ值降序排列后第7、8样本点基本重合,即γ值相差不大,造成聚类中心点难于选取。图8(a)中前14 个样本点与后边样本点γ值存在差异,但选取中心点时造成漏选。通过对比,可以看到ADPC算法的γ图中γ~ =0.5 处的“拐点”位置前后存在差异。相比较于DPC算法,通过更多点γ值被拉伸,潜在聚类中心点的γ值变换后变大,与非聚类中心点差异增加且避免聚类中心点的漏选。
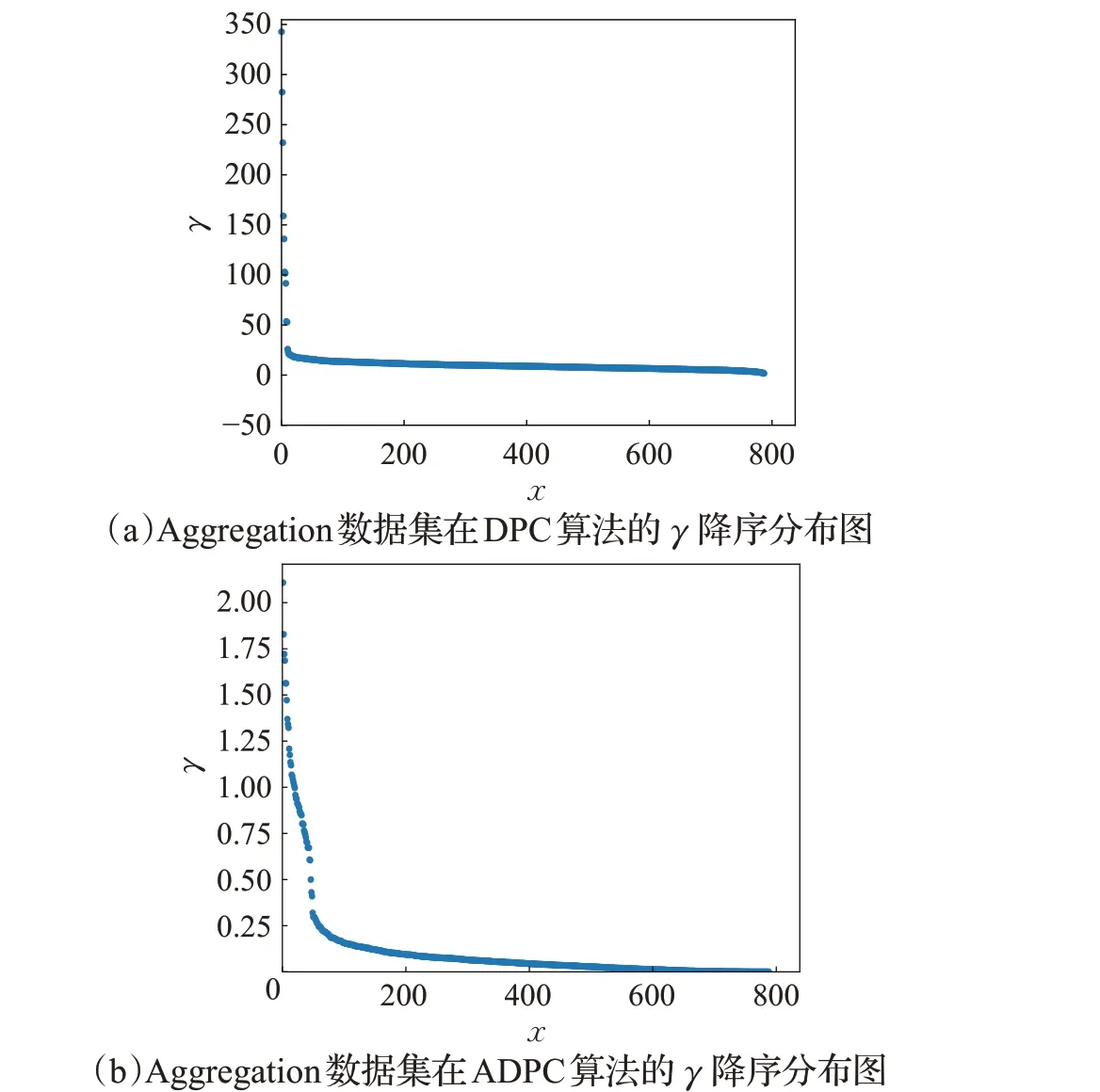
图7 Aggregation数据集的γ 降序分布图对比Fig.7 Comparison of γ descending graph distribution on Aggregation
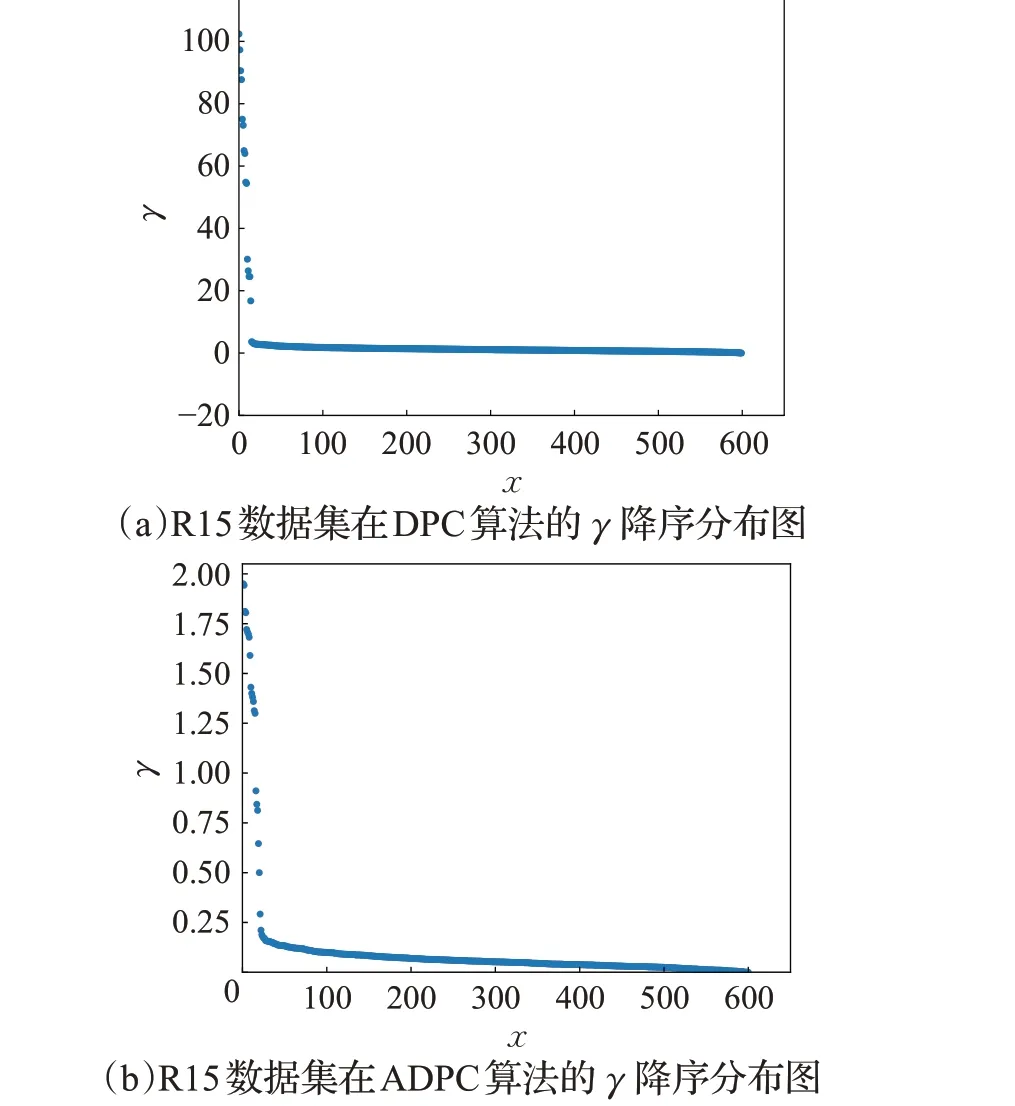
图8 R15数据集的γ 降序分布图对比Fig.8 Comparison of γ descending graph distribution on R15
定义4γ~ 决策函数。γ~ 决策函数定义如公式(10):
其中,μ(γ~ )为变换后的γ~ 的平均值,σ(γ~)为标准差,公式(10)可以将“拐点”之前的点以及靠下一些的点都选为潜在聚类中心,使之可能多地选择出潜在聚类中心,可以避免较稀疏密度簇的中心点的漏选。设潜在聚类中心集合为dcenters={c1,c2,…,cs}。
基于DPC 算法关于聚类中心点的两个假设,提出自适应聚类中心策略优化。首先,将潜在的聚类中心点中密度最大的点作为第一个真实聚类中心cc1,然后按照公式(11)选择第二个真实中心,即两个聚类中心点之间的距离要大于等于潜在中心点样本两两之间距离均值的1/2。设最终聚类中心点集合fcenters={cc1,cc2,…,ccm}。
其中,ci,cj∈dcenters,ccp∈fcenters,经多次实验验证,该筛选公式选取所有距离均值的1/2 时筛选结果最佳,可以将属于同一簇中的潜在中心点剔除,确定最终聚类中心。
ADPC 算法依据公式(6)计算样本点局部密度,公式(3)计算样本间相对距离,针对DPC 算法的缺陷,不采用局部密度和相对距离决策图直观选择聚类中心,而是通过确定“拐点”,对样本γ值进行变换,使聚类中心与非聚类中心γ值差异相对较大,利用决策函数,选择出潜在的聚类中心点;根据DPC算法两个基本假设,对潜在聚类中心点进行筛选,实现聚类中心的自动确定,无需人工干预。
2.2 ADPC算法详细描述
输入:数据集X,样本近邻数k。
输出:聚类结果Clu。
步骤1 初始化聚类Clu[xi]=-1。
步骤2 计算数据集样本点之间的欧式距离,根据公式(5)计算样本间相似性。
步骤3 根据公式(3)和(6)计算δ、ρ。
步骤4 根据公式(4)计算样本γ值,并进行Max-Min归一化。
步骤5 根据公式(7)确定归一化后γ降序分布图的“拐点”,用公式(9)对归一化后的γ升序排列进行幂函数变换。
步骤6 根据公式(10)得到潜在聚类中心集合dcenters={c1,c2,…,cs}。
步骤7 根据公式(11)对潜在聚类中心集合中的点进行筛选,自动确定聚类中心集合fcenters={cc1,cc2,…,ccm}。
步骤8 样本点分配。
(1)给聚类中心分配簇标记;
(2)非聚类中心点的分配:
①分配聚类中心的k个近邻点,若ccp∈fcenters,b∈KNN(ccp)且ccp∈KNN(b),则Clu[b] =Clu[ccp];
②对其他未分配的点,将其分配到其k近邻点中最多点所在的某簇中;
③若还有未分配点,即Clu[xi]=-1,采用DPC 算法的一步分配,即分配到密度比其大且距离最近的点所在的簇中。
2.3 ADPC算法时间复杂度分析
在本节中,设置样本数n,近邻个数k,潜在聚类中心数s,聚类中心数m,s<<n且m<<n,ADPC 算法各部分时间复杂度分析如下:
(1)计算样本点的距离,时间复杂度为O(n2)。
(2)计算样本间相似性,时间复杂度为O(n2)。
(3)计算样本点间相对距离,时间复杂度为O(n2)。
(4)计算样本点局部密度,时间复杂度为O(kn)。
(5)计算样本γ值,并进行Max-Min归一化,时间复杂度为O(n)。
(6)确定“拐点”,时间复杂度为O(n)。
(7)γ值进行幂函数变换,时间复杂度为O(n)。
(8)计算潜在中心集合,时间复杂度为O(n)。
(9)自动确定真实聚类中心,时间复杂度为O(sm)。
(10)样本点分配,总时间复杂度O(n)。其中分配聚类中心点,时间复杂度为O(m),分配聚类中心点的k个近邻点,时间复杂度为O(mk),其他未分配点数量最坏情况下为n,时间复杂度为O(nk),但实际要小于O(nk)。
综上所述,ADPC 算法时间复杂度约为O(n2),与DPC算法时间复杂度量级相同,且都主要来源于计算样本间的距离、计算所有样本的局部密度以及计算每对样本之间的相对距离。
3 实验结果与分析
3.1 实验环境与数据
选用人工数据集(Aggregation、Flame、Spiral、Far、G2_2_30、R15)和UCI 数据集(Iris、Seeds、Glass、Ionosphere、Knowledge、Planning)对本文提出的ADPC 算法进行性能测试。数据集详细信息见表1和表2。

表1 人工数据集Table 1 Synthetic datasets

表2 UCI数据集Table 2 UCI datasets
ADPC算法与SNN-DPC算法、DPC算法、SKM-DPC算法、DBSCAN算法、AP算法以及K-means算法进行对比实验。其中SNN-DPC 和DPC 算法来源于Github 源代码,SKM-DPC 算法和K-means 算法为自己复现,DBSCAN算法和AP算法直接从Sklearn库中调用。实验环境为Windows 64 bit操作系统,PyCharm Community Edition 2021.3.1软件,4 GB内存,Intel®Core™i5-6200U CPU@2.30 GHz 2.40 GHz。
3.2 评价指标
本文采用的评价指标为聚类中常见的准确率(Acc)、调整互信息(AMI)、调整兰德指数(ARI)以及FM指数(FMI)。
准确率(Accuracy,Acc)是被正确聚类的样本数占样本总数的比值,准确率越高,算法聚类性能越好。
调整互信息(AMI)是对互信息(Mutual Information,MI)的一种改进。AMI取值范围为[-1,1],值越接近1,聚类性能越好。
调整兰德指数(ARI)由兰德系数(Rand Index,RI)转化而来。ARI 在[-1,1]范围内取值,ARI 取值越接近1,表明算法的聚类性能越好。
FM指数(fowlkes and mallows index,FMI)是成对精度与召回率的集合均值,FMI 取值范围是[0,1],值越大,聚类效果越好。
3.3 参数(Par)设置
本文实验各算法参数及设置见表3。ADPC 算法、SNN-DPC 算法以及SKM-DPC 算法的参数为样本近邻数k,该参数根据不同的数据集选择不同,实验在5~20之间择优选取,DPC 算法参数为截断距离选取时的占比,选择范围为0.5%~2%,大多数据集在取2%时效果最优。DBSCAN 算法参数为邻域半径Esp和最少样本数MinPts,邻域半径Esp一般在0.1~2.0 之间取值,但在G2_2_30 数据集取值为18 时较优,最少样本数MinPts在3~30 之间取值。AP 算法参数为preference,指样本xi作为聚类中心的参考度,实验采用欧式距离平方的相反数作为相似度。K-means 算法参数为随机选取的聚类中心数k,实验取20 次重复实验的最优结果取值。
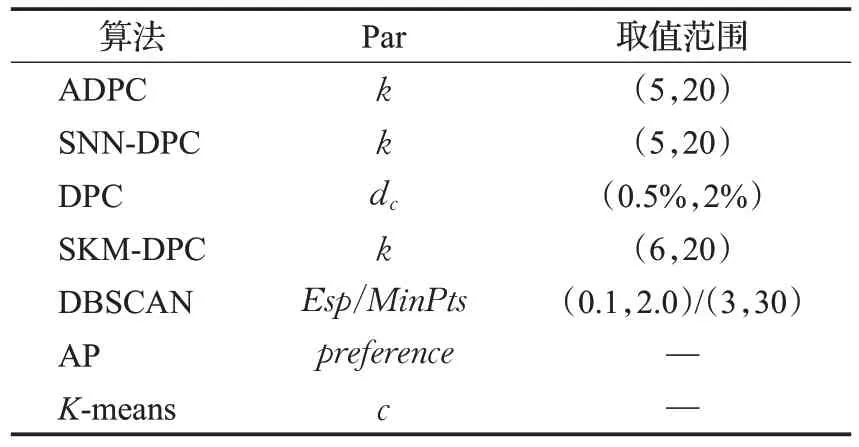
表3 各算法参数设置Table 3 Parameter settings of each algorithm
3.4 人工数据集实验结果分析
类中心的位置与聚类结果可视化,并与SNN-DPC算法和DPC 算法进行可视化聚类对比。对比结果如图9~图14所示。其中红色星形为聚类中心位置。

图9 三种算法在Aggregation数据集上的聚类中心位置Fig.9 Cluster centers of three algorithms on Aggregation
图9~图14 表明,针对所选六个人工数据集,ADPC算法都可以自动确定出聚类中心位置,且可以正确聚类。图9显示,Aggregation数据集有两个簇存在轻微连接,ADPC算法可以选出合适的聚类中心,且聚类结果比SNN-DPC 算法好。图10,Flame 分为上下两簇,簇与簇存在小部分连接,ADPC算法、SNN-DPC算法和DPC算法都可以正确选出聚类中心,但是图10(b)中SNN-DPC算法在簇与簇连接部分存在小部分点分配错误的情况。图10(c)中DPC算法由于采用一步分配,产生了连带反应,造成下半部分簇的大多数点分配错误,聚类准确率降低。图11为Spiral环形簇,三种算法均可以正确选出聚类中心,并能准确聚类。图12 为具有相对独立的簇的数据集4k2_far,由聚类结果可以看出,三种算法对4k2_far 数据集可以正确选出聚类中心,正确聚类。图13 为数据集G2_2_30 的聚类结果,该数据集样本数为2 048,分为两个比较稠密的簇,三种算法针对相对较大规模数据集均可以正确选出聚类中心。图14为数据集R15 的聚类结果,该数据集样本数为600,但分为15个簇,ADPC算法、SNN-DPC算法以及DPC算法均可以正确选出聚类中心。
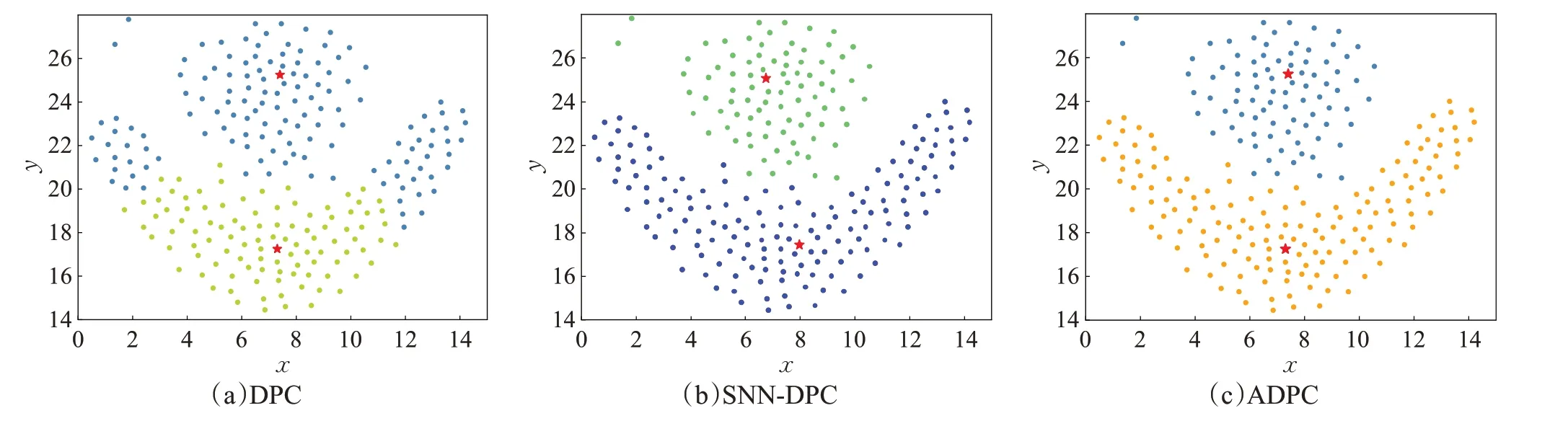
图10 三种算法在Flame数据集上的聚类中心位置Fig.10 Cluster centers of three algorithms on Flame
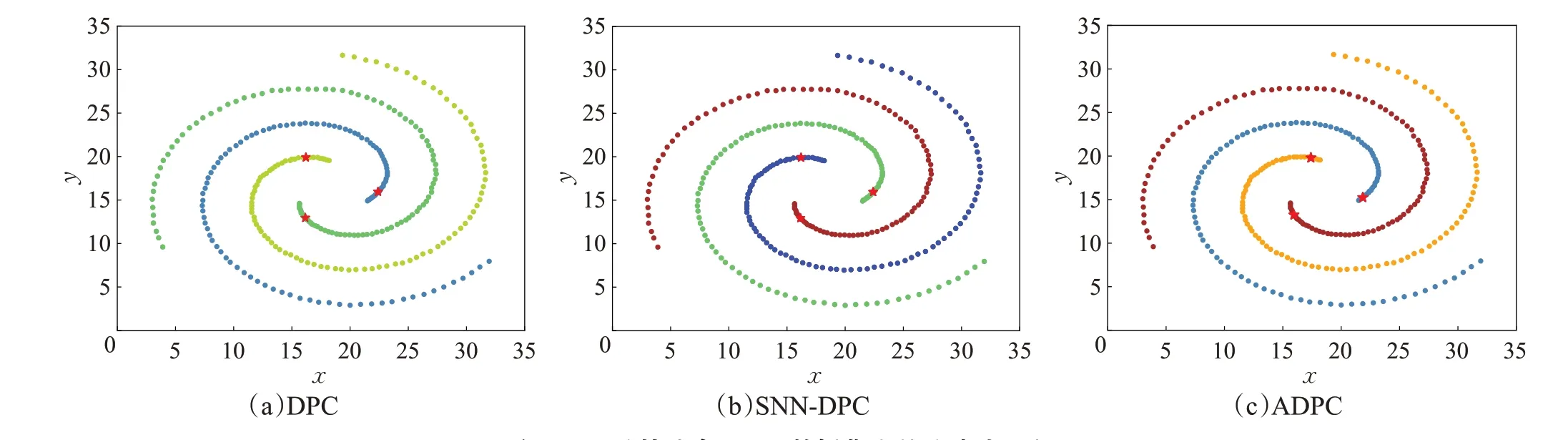
图11 三种算法在Spiral数据集上的聚类中心位置Fig.11 Cluster centers of three algorithms on Spiral
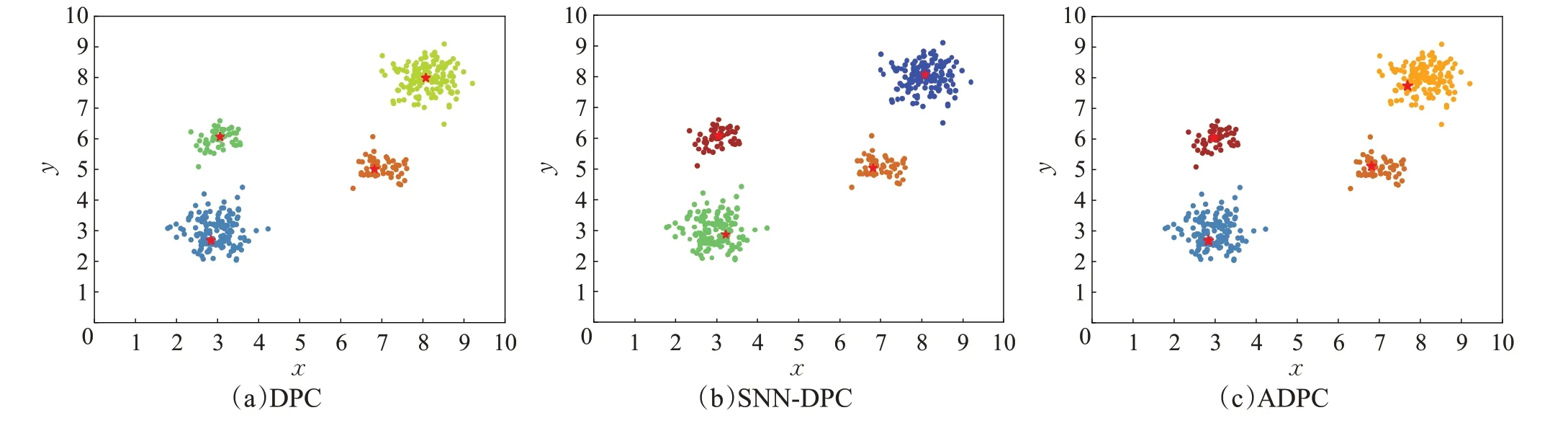
图12 三种算法在4k2_far数据集上的聚类中心位置Fig.12 Cluster centers of three algorithms on 4k2_far

图13 三种算法在G2_2_30数据集上的聚类中心位置Fig.13 Cluster centers of three algorithms on G2_2_30
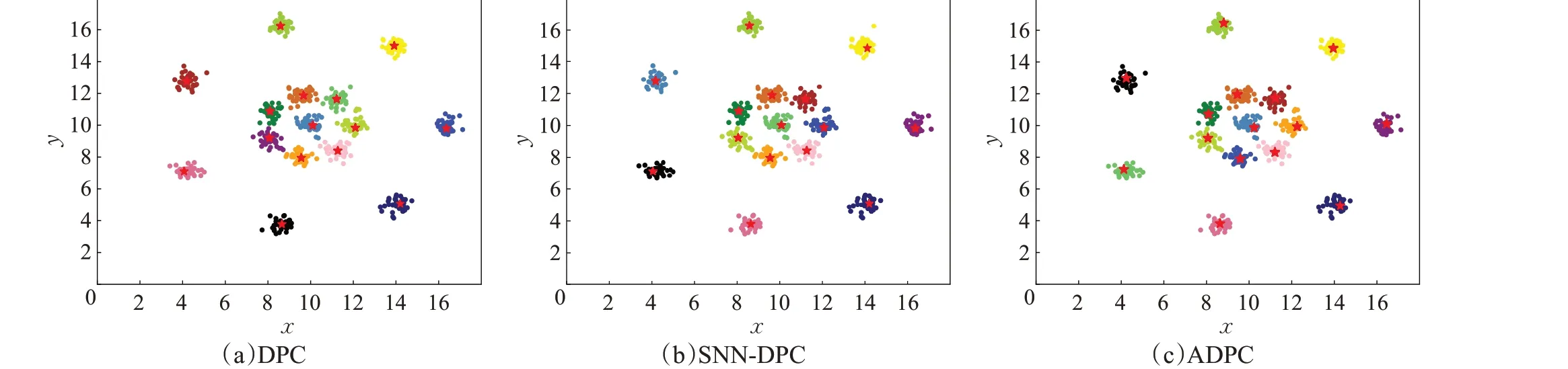
图14 三种算法在R15数据集上的聚类中心位置Fig.14 Cluster centers of three algorithms on R15
表4给出了ADPC算法在人工数据集上与SNN-DPC算法、DPC 算法、SKM-DPC 算法、DBSCAN 算法、AP 算法以及K-means算法在Acc、ARI、AMI以及FMI四个评价指标上的性能以及各算法的参数值,其中加粗字体表示性能较好的实验结果。
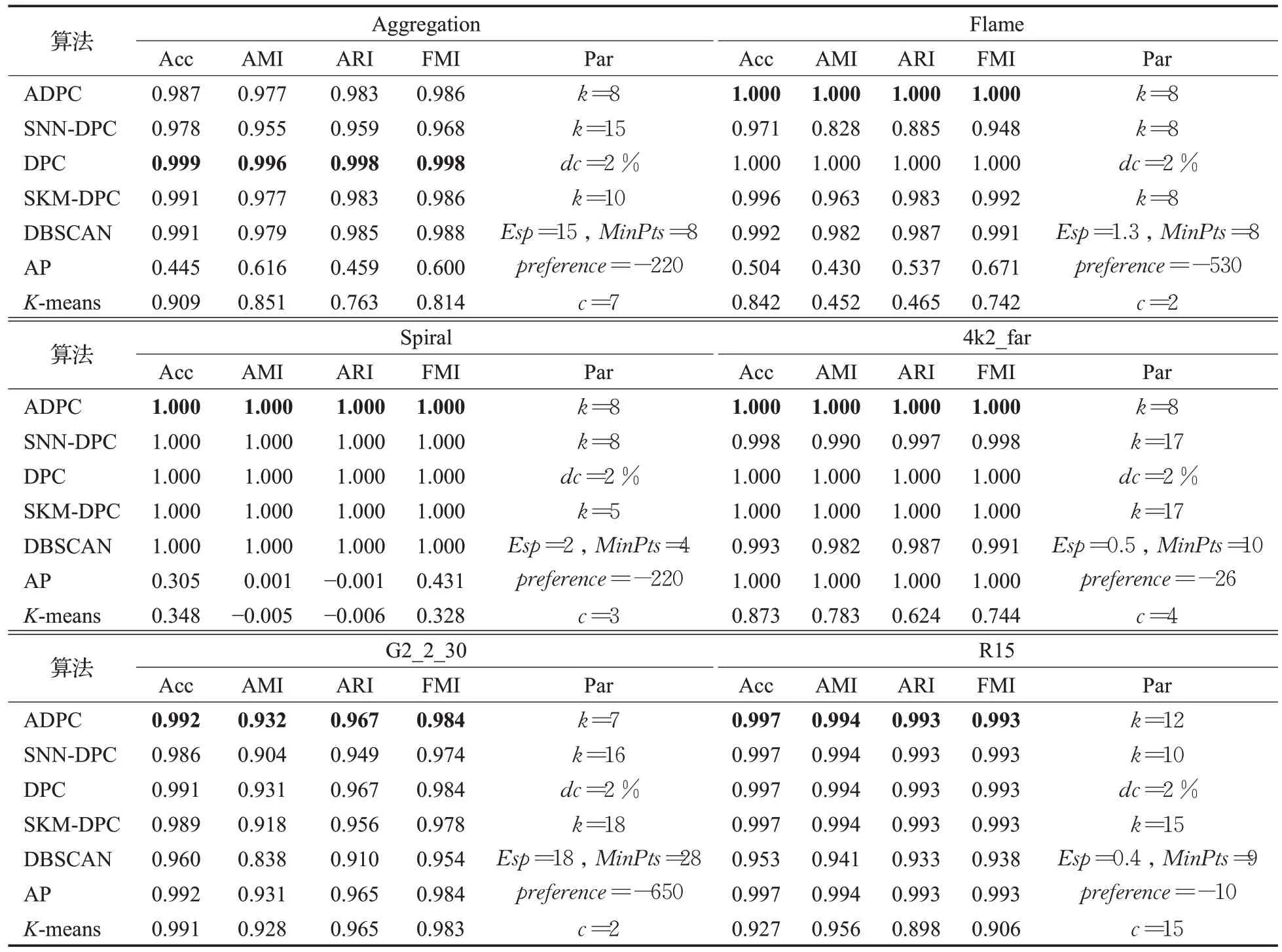
表4 人工数据集上聚类性能比较Table 4 Performance comparison of clustering algorithms on synthetic datasets
由表4 得出,在Aggregation 数据集上,ADPC 算法比DPC算法的聚类性能平均低1.4%,只比SKM-DPC算法的Acc 低0.4%,但比也应用了共享近邻的SNN-DPC算法的聚类性能平均高1.8%,AP 算法因无法找到准确的聚类中心,聚类效果不佳。ADPC 算法在其他5 个人工数据集上均可以与其他六个算法抗衡,其中在Flame数据集上,ADPC 算法与DPC 算法聚类性能相同,比SKM-DPC 算法与SNN-DPC 聚类性能平均高1.67%和9.2%。在Spiral、4k2_far 和R15 数据集上ADPC 算法与其他算法相比保持稳定优势,其中在Spiral 数据集上,ADPC算法、SNN-DPC算法、DPC算法、SKM-DPC算法以及DBSCAN算法聚类性能保持优势,K-means算法与AP 算法聚类性能较差。在4k2_far 数据集上,ADPC 算法、DPC 算法、SKM-DPC 算法以及AP 算法聚类性能存在优势,SNN-DPC算法、DBSCAN算法以及K-means算法聚类性能不佳。在R15 数据集上ADPC 算法依旧存在优势,DBSCAN算法与K-means算法的表现不佳。在G2_2_30数据集上,ADPC算法具有较好的聚类性能,比DPC算法平均高0.05%,AP算法虽聚类性能良好,但是在参数最优的情况下,一般来说,AP 算法难以参数寻优。由此得出结论,SNN-DPC 算法与其他算法相比在人工数据集上优势保持稳定且明显。
由上述人工数据集的实验表明,ADPC算法在不同规模、不同形状和不同簇数的数据集上均可以正确选出聚类中心,且聚类性能也存在稳定优势。本文算法避免了DPC 算法在决策图上选择聚类中心点的人为主观性,同时结合了k近邻分配策略,也避免了DPC算法一步分配所产生的连带反应。
3.5 真实数据集实验结果分析
为进一步测试本文ADPC算法性能,本文选用UCI中六个真实数据集进行测试,六个数据集具有不同维度、不同簇数且不同规模。表5 给出了ADPC 算法在UCI 真实数据集上与SNN-DPC 算法、DPC 算法、SKMDPC 算法、DBSCAN 算法、AP 算法以及K-means 算法在Acc、ARI、AMI 以及FMI 四个评价指标上的性能以及各算法的参数值,其中加粗字体表示性能较好的实验结果。
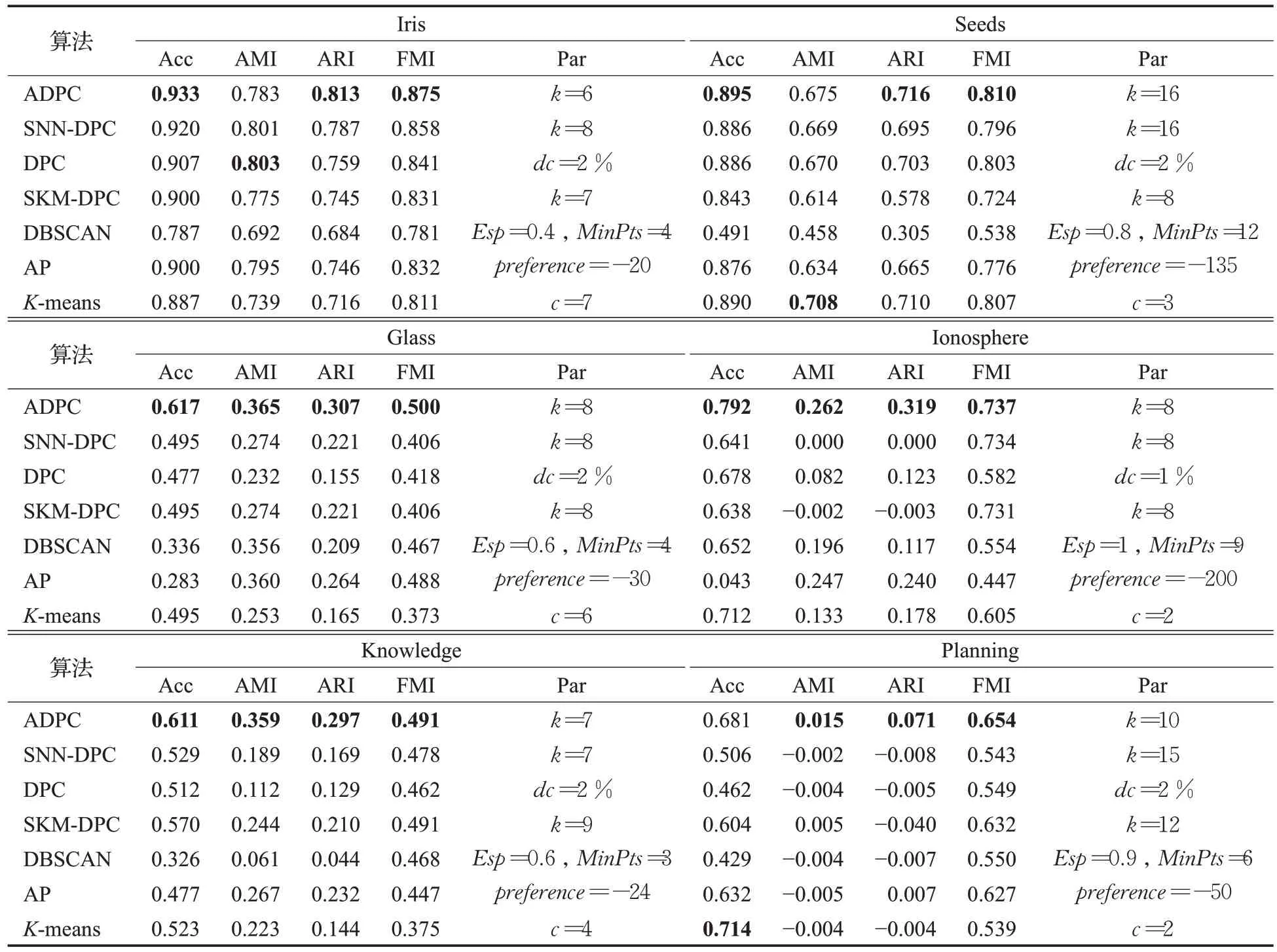
表5 UCI数据集上聚类性能比较Table 5 Performance comparison of clustering algorithms on UCI datasets
由表5中得出,在数据集Iris上,ADPC算法的Acc、ARI 和AMI 值均为最高,AMI 值比最好的DPC 算法低2%。在数据集Seeds上,ADPC算法的Acc、ARI和AMI值均为最高,AMI仅比K-means算法低3%,DBSCAN算法聚类效果最差。在数据集Glass、Ionosphere和Knowledge 上,ADPC 算法的四个评价指标优势明显,均为最高值。在数据集Planning上,ADPC算法在AMI、ARI以及FMI 性能最好,在Acc 上仅低于K-means 算法。因此,ADPC算法在UCI真实数据集上具有较好表现。
4 总结与展望
本文提出的ADPC 算法通过样本点之间的共享近邻定义样本的相似性,利用样本点的k个近邻点的距离之和与相似性的指数核函数定义局部密度,在Max-Min归一化后γ降序分布图上采用从右向左的方式利用相邻两点之间斜率差分寻找“拐点”,通过对样本点的值进行变换更好地得到了潜在的聚类中心,避免了聚类中心点的漏选,实现了真实聚类中心点的自动确定,解决了人为选择聚类中心的主观性问题。同时,优化了非聚类中心点的分配策略,避免非聚类中心点分配时产生连带错误。通过六个人工数据集验证了ADPC 算法自适应选择聚类中心的准确性。在六个UCI 数据集上的实验表明,ADPC 算法可以准确实现聚类中心的自适应的同时,样本点分配策略更加合理,聚类性能较DPC、ADPC、SKM-DPC、DBSCAN、AP 以及K-means 算法总体有所提升。然而,ADPC 算法样本k近邻中的参数k是提前给定的,如何实现k值自适应将在未来工作中进一步研究。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
电脑报(2020年12期)2020-06-30
数学物理学报(2019年6期)2020-01-13
电脑报(2019年4期)2019-09-10
中国惯性技术学报(2019年6期)2019-03-04
数学物理学报(2017年5期)2017-11-23
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
少儿美术·书法版(2016年1期)2016-02-06
大众摄影(2015年9期)2015-09-06
