
基于感知监督和多层次特征融合的去雾算法
2023-11-20 10:58吴峻江
计算机工程与应用 2023年21期
吴峻江,储 珺,卢 昂,冷 璐
1.南昌航空大学 软件学院,南昌 330063
2.南昌航空大学 江西省图像处理与模式识别重点实验室,南昌 330063
雾是一种常见的大气现象,悬浮在空气中的颗粒物会引起光的散射和衰减,因此在有雾天气下所拍摄到的图像质量严重下降,出现对比度低,颜色失真等问题。不仅严重影响视觉效果,也对后续的高级视觉任务如目标检测[1]、目标跟踪[2]、视频监控等产生影响。图像去雾作为底层视觉领域的一项子任务受到了极大的关注。
单幅图像去雾的方法可以分为两大类:基于先验信息的图像去雾方法和基于深度学习的图像去雾方法。基于先验信息的图像去雾方法主要是在大气散射模型[3]基础上,利用图像固有的先验信息属性来估计出大气散射模型中的传输图与大气光值。如He 等人[4]提出了一种暗通道先验算法。算法假设在无雾图像的非天空区域,至少有一个颜色通道会有很低的值,通过此先验知识结合大气散射模型进行去雾。Zhu等人[5]提出了一种颜色衰减先验算法,通过对大量有雾图像分析发现雾的浓度随景深的变化而变化,雾浓度越大,景深越大。根据该先验信息实现投射率的估计和无雾图像的恢复。Berman等人[6]提出了一种非局部先验算法,算法假设在RGB空间中,清晰图像中的每个颜色簇都变成了雾线,然后通过先验公式对清晰图像进行线性恢复。这类算法通常具有较低的时间复杂度,但在实际应用场景下,很难找到一个通用的先验知识,因此会违背先验假设,对透射图的估计不准确,导致去雾不彻底、颜色失真。
基于深度学习的图像去雾方法主要分为两类:第一类基于大气散射模型,使用网络学习并生成透射图,随后估计出大气光值,并通过大气散射模型推导出去雾结果。如Li等人[7]提出的AOD-Net,它利用重新规划的大气散射模型,将大气光值和透射率融合成一个新值K,并通过卷积神经网络估计K值,然后将K代入大气散射模型得到去雾图像。Cai等人[8]基于CNN提出DehazeNet,它以有雾图像作为输入,以学习的方式来估计透射率,然后通过简单的像素操作恢复出无雾图像。上述基于大气物理模型的深度学习方法虽然取得了不错的效果,但和基于先验信息的传统图像去雾方法一样,它们依赖大气散射模型。
第二类是端到端的直接去雾的深度学习方法。其中有基于生成对抗网络(generating adversarial network,GAN)去雾算法和基于编解码结构的去雾算法。基于GAN 的方法有:如Qu 等人[9]提出增强型Pix2pix GAN。利用增强器对生成图像在颜色和细节方面进行增强。Dong 等人[10]提出一个带有融合判别器的端到端GAN。融合判别器在训练阶段将频率信息作为额外的先验因素进行整合。基于编解码结构的方法是图像去雾领域的主流方法,通过卷积神经网络学习有雾图像到无雾图像的映射。如Ren 等人[11]提出一个基于编解码的门控融合网络(gated fusion network),对输入图像先做预处理(即白平衡、对比度增强、伽马矫正),处理得到的三个图像作为网络输入,并采用多尺度结构对去雾结果进行细化。Wu等人[12]提出一种基于知识迁移的编解码结构网络。算法利用无雾图像训练教师网络,用它监督中间特征,利用特征相似性鼓励去雾网络模仿教师网络进行去雾,并在两个网络的最后一层卷积前都使用增强模块来融合不同感受野层的特征。Feng等人[13]受U-Net[14]和ResNet[15]的启发,设计了基于U-Net 的残差网络。通过混合卷积与HSV颜色空间损失函数来学习有无图像和无雾图像之间的残差图像,实现去雾。Mei 等人[16]提出了一种有效的类U-Net结构的编解码网络,通过渐进式特征融合的方式逐渐恢复图像细节。Liu等人[17]提出了一种具有网格状的去雾网络,直接重建清晰的图像。通过注意力机制有效地缓解传统多尺度融合去雾方法中的瓶颈问题。Yang 等人[18]提出基于内容特征和风格特征融合的图像去雾网络,通过学习内容与风格特征去雾的同时保持原始图像的色彩特征。Dong等人[19]提出了一个多尺度的增强密集特征融合去雾网络,网络总体采用U-Net架构,利用反向投影技术设计了一个密集特征融合模块,利用非邻近特征的同时也纠正高分辨率特征中缺失的空间信息。Chen 等人[20]提出了一个基于门控融合上下文信息的编解码网络,并利用门控机制融合不同层次的特征,但是缺少对编码阶段与解码阶段的特征进行信息交互。Yang 等人[21]提出一种结构类似于字母Y的多尺度特征聚合的编解码网络,但是在网络编码阶段连续下采样过程中没有保留不同尺度特征信息,导致图像特征丢失,影响图像高频细节的恢复。
上述端到端的方法在网络设计时没有充分提取与利用不同分辨率层次的多尺度特征信息,以及在特征转换阶段没有对不同空间上下文层次的特征进行有效的提取与融合,特征感受野大小的不足导致图像去雾不彻底,雾气存留在图上。而且在训练阶段,大多数图像去雾算法只考虑了逐像素点的恢复,并没有考虑重建的图像是否符合人类视觉感知,因此恢复出的图像虽然峰值信噪比指标高,但是图像不符合人眼的视觉感知,且有一定的颜色失真。
针对上述问题,本文提出了一个基于感知监督和多层次特征融合的图像去雾网络。网络结构是类UNet结构的编解码去雾网络。本文主要创新点包括:
(1)设计多层次特征融合模块,包括分辨率层次特征复用与融合模块,以及空间下上文层次特征提取与融合模块。通过分辨率层次特征的复用与融合在编码阶段提取每个不同分辨率层次的丰富特征,为重建图像提供更多的不同尺度纹理信息;通过空间上下文层次特征提取与融合模块,提取不同层次的空间上下文特征,并且通过层次特征融合模块学习和融合不同层次的特征,使得网络能够更加关注重要的特征信息。
(2)引入感知损失和多尺度结构相似度损失。在训练阶段,引入感知损失和多尺度结构相似度损失,和平滑L1 损失组成联合损失函数对网络训练过程进行监督,使网络学习更多亮度,对比度等人类视觉感知属性。去雾后图像保证高的评价指标的同时也更符合人类视觉感知。
1 本文算法
算法网络为类U-Net结构的编解码网络,构建了分辨率层次特征复用与融合模块(resolution hierarchical feature reuse and fusion module,RHFRF),空间上下文层次特征提取与融合模块(spatial context hierarchical feature extraction and fusion),以及自适应特征融合模块(adaptive feature integration module,AFIM)。网络结构如图1所示。
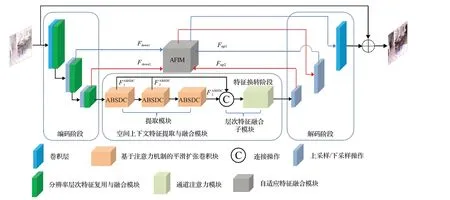
图1 网络结构图Fig.1 Network structure
在编码阶段,与传统的类UNet 编解码网络在每次下采样后使用普通的卷积层或残差块提取特征不同,本文在每个卷积层后使用一个分辨率层次特征复用与融合模块,提取的特征包含更多不同尺度的结构细节信息,有更强的表达能力;在特征转换阶段,相比于以往用多个普通残差块级联来提取深层特征的方式,本文利用多个级联的基于注意力机制的平滑扩张卷积块,提取不同扩张率层次的空间上下文特征,并且自适应学习与融合不同层次的特征;最后在解码阶段,利用自适应特征融合模块代替通用编解码网络中的跳跃连接,实现上下采样阶段的特征交互,补充丢失的信息,再逐渐上采样回到原始分辨率。
在训练阶段,采用感知监督联合逐像素监督对网络训练过程进行约束。感知监督是通过具有人类视觉感知属性(亮度、结构等)的损失函数对训练过程进行监督。相比于只有逐像素的监督过程,感知监督能考虑去雾后的图像与Ground Truth之间的视觉差异,使得去雾后的图像在视觉效果方面变得更加符合人的视觉感知和审美。
1.1 分辨率层次特征复用与融合模块
通用的类UNet 编解码网络在编码阶段,采用普通卷积层进行下采样和下采样后的特征提取。普通3×3的卷积提取特征会不可避免地丢失了一些图像细节或纹理等结构信息。本文结合残差密集块设计分辨率层次特征复用与融合模块。如图2所示。

图2 分辨率层次特征复用与融合模块Fig.2 Resolution hierarchical feature reuse and fusion module
模块有四个卷积块和一层1×1 卷积构成。模块的前四层卷积块紧密连接在一起,用以学习当前分辨率尺度下更多的信息。其中每一层的输入都会复用之前所有层的特征,这样既保持了前馈特性,又同时提取到了不同尺度雾图的细节特征和局部密集特征。最后一层用连接操作按通道连接之前所有层的特征,并且用1×1卷积自适应融合不同层产生的特征图,将前四层融合后的结果Fres作为残差值与Finput相加得到最终输出。
根据文献[22]所述,本文将模块的增长率设置为16。并且为了平衡性能与计算复杂度,两次下采样分别将特征图的大小改变为原始分辨率的1/4和1/4,通道数分别为32和64。此结构可以充分利用当前分辨率下输入图像的所有分层特征,并且残差学习的结构有益于网络收敛。文献[23]证明了在底层视觉领域,批归一化(batch normalization,BN)对像素级别的图像重建任务作用很小,去除BN层有助于提高峰值信噪比性能并降低计算复杂度,但实例归一化能够加速模型收敛,保持每个图像实例之间的独立性,因此在模块中以实例归一化层代替BN 层,插入卷积层和ReLU 激活函数之间。操作表示如下:

1.2 空间上下文特征提取与融合模块
为了加深网络深度以提高网络性能,同时防止训练时由于梯度消失导致网络性能下降,之前许多工作[13,16]在特征转换阶段,也就是编码器和解码器之间的连接处,采用多个残差块级联的方式来提取深层次的特征。但是普通残差块的卷积层都是3×3的小尺寸卷积核,存在感受野不足,提取到的有雾图像特征上下文信息十分有限的问题。对于图像去雾这类像素级任务,需要更大的感受野来提取更多的空间上下文信息以保证结构信息的准确恢复。
因此为了在不进一步降低特征图分辨率以换取更小计算损耗的情况下,扩大感受野来提取不同层次的空间上下文信息,本文结合残差学习思想设计了空间上下文特征提取与融合模块。模块由三组级联的基于注意力机制的平滑扩张卷积模块以及层次特征融合子模块组成。基于注意力机制的平滑扩张卷积模块用以提取不同层次的空间上下文信息,获得不同感受野的特征;层次特征融合子网络用以融合三个不同层次的特征,提高特征的丰富性。
1.2.1 基于注意力机制平滑扩张卷积模块
特征转换阶段采用三组不同扩张率的基于注意力机制的平滑扩张卷积模块(ABSDC),提取三个不同空间层次的上下文特征信息。通过消融实验验证,三组ABSDC 的扩张率分别采用2、4、1。每个ABSDC 模块结构如图3 所示,由两个平滑扩张卷积块,两个残差块和一个通道注意力机制模块,通过局部跳跃连接和块全局跳跃连接构成。局部残差学习和块全局残差学习可以让网络跳过薄雾区域,低频区域,让网络更加关注有效的高频信息[24]。
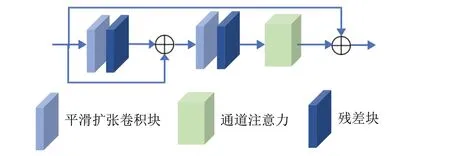
图3 ABSDC模块与残差块结构Fig.3 Architecture of ABSDC module and Res Block
为了解决使用扩张卷积所带来的网格伪影现象,根据文献[25],在扩张卷积层前增加一层可分离共享的卷积层,提高输入特征像素点之间的交互,减缓网格伪影现象。残差块也采用扩张卷积,扩张率和平滑扩张卷积块相同。通道注意力机制模块的卷积核大小仍然为3×3。
设输入当前第i个ABSDC 块的特征为Fi,则第i个ABSDC块的输出可以表示为:
其中,FABSDCi表示第i个ABSDC 模块的输入特征。φ表示经过一组平滑扩张卷积块和一组残差块的特征输出。Fresi表示当前ABSDC块的全局残差。CA表示通道注意力模块[24]。
1.2.2 层次特征融合子模块
融合不同层次的特征对于底层视觉的恢复任务是有益的,因此本文对三个不同扩张率的ABSDC 输出特征进行融合,利用通道注意力机制自适应地学习不同重要性的融合权重。实现具体过程如下:
首先,将来自ABSDC 模块的三个不同扩张率层次的输出F1ABSDC、F2ABSDC、F3ABSDC在通道方向上连接起来,得到连接后的特征向量FC∈RC×H×W,其中C表示连接后的特征图通道数。
然后,将连接后的特征FC使用全局平均池化函数把维度从C×H×W变为C×1×1。为了得到不同通道的权重因子,将经过全局平均池化函数的特征图再通过两个卷积层和ReLU 激活函数后,由sigmoid 函数得到带有不同权重的特征向量F′C。
随后将F′C按通道划分为三个不同重要程度的特征向量,记作w1、w2、w3。将ABSDC 模块的三个输出与权重相乘得到最后的输出。设经过层次特征融合模块后的输出为FHFFM,输出结果公式表示如下:
通过权重机制,能够让网络更加关注高频纹理等有效信息,且抑制冗余信息,使去雾效果更加好。
1.3 自适应特征融合模块
在编码阶段中,提取特征的过程时常伴随着下采样。下采样会减小图像的分辨率,增加特征图的通道数。这个过程导致图像高频信息丢失。解码过程由于缺乏特征图所携带的高频信息,解码得到图像缺乏细节纹理等高频信息。
之前有很多的工作[13,16]对编解码同层级特征相加,或在通道方向上进行串联,但是这些方式的跳跃连接平等对待编解码的同层级特征。但是编码阶段的下采样提取更多的局部细节特征,这一部分对重建图像细节保持很重要。因此本文构建自适应特征融合模块,希望网络能够根据不同信息的重要性自适应地融合上采样与下采样层的特征。融合后的特征既包含来自编码阶段(下采样)的浅层高频特征,也包含解码阶段(上采样)的深层低频特征。模块结构如图4所示。
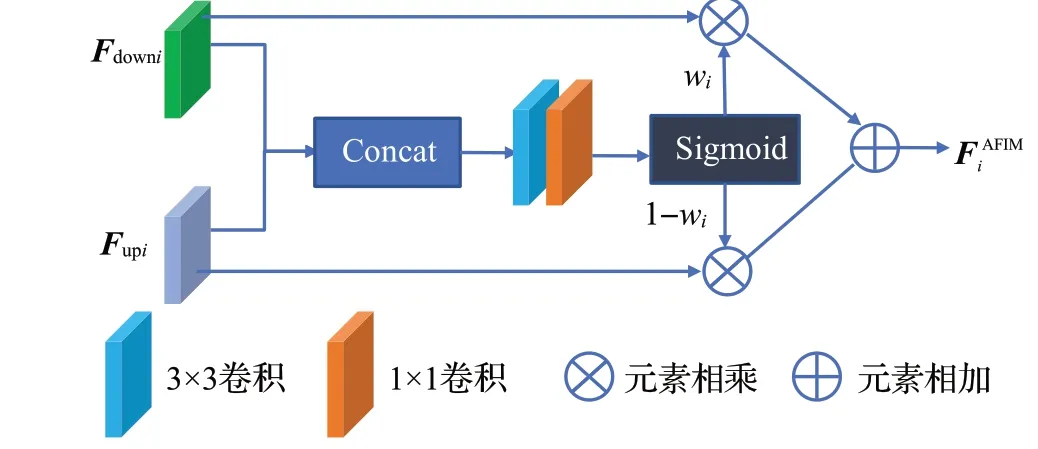
图4 自适应特征融合模块Fig.4 Adaptive feature integration module
自适应融合后的特征为:
其中,wi是可学习的参数,它的值由两个输入按通道方向连接后,经过3×3 卷积,1×1 卷积后由sigmoid 函数σ得到。
最终的去雾结果由一个全局的残差学习与自适应特征混合模块的最终输出相加得到,表示如下:
其中,Fhazy表示整个网络的输入,FAFIM1表示整个自适应特征融合模块的最终输出,Fdehazed表示最终的去雾结果。
1.4 联合损失函数
图像去雾网络的训练最常采用L2损失函数或L1损失函数[26-27]。L1和L2损失函数逐像素计算重建后图像与真实值Ground Truth之间的差值,在训练过程中监督模型更好地重建像素点。但是这种逐像素比较容易造成高频细节信息的丢失[28]。为此本文引入了感知损失函数与多尺度结构相似度函数对训练过程进行感知监督。
通过感知损失比较图像特征方面的差异保证重建更多的细节。多尺度结构相似度损失函数考虑了亮度、对比度以及结构三个指标,这符合人类视觉感知,生成的结果也更符合人类视觉系统[29]。因此本文的损失函数由三个不同的部分组成。去雾后的图像、Ground Truth和有雾图像分别定义为I^ 、Igt、Ihazy。
第一个损失函数为平滑L1损失。本文将平滑L1损失作为主损失函数,目的是确保去雾后的图像能够更好地接近无雾图像。平滑L1损失函数是一个比L1损失更加鲁棒,并且被证明比L2损失函数更加适用于图像恢复任务[30]。因为L2损失函数对于异常值点特别敏感,会放大异常像素点的误差,不利于图像重建。平滑L1损失的定义如下:
其中,I^c(i)和Igt c(i)代表像素i在第c个通道的强度。N代表所有像素点的个数。
第二个损失函数是感知损失。人类视觉模型指出基于逐像素误差的损失并不适合于对损坏图像的感知质量评价[31]。针对这一缺陷,本文将感知损失作为总损失的第二个损失函数。感知损失是由文献[32]提出,并且在图像风格迁移中得到了广泛的应用。该损失能在高层特征空间对特征提供额外的监督,通过感知损失的训练,可以让模型更好地重建细节,生成的图像也更加符合人类的视觉感官。本文使用的感知损失是在ImageNet[33]上预训练好的VGG-16 模型的权重。感知损失函数定义如下:
其中,Cj、Hj、Wj分别表示在骨干网络中第j层特征图的通道数、高和宽。φj表示第j层的激活函数。
第三个损失函数为多尺度结构相似度损失(multiscale structure similarity,MS-SSIM)。感知损失主要从高层特征空间来对图像重建过程进行监督,而多尺度结构相似度损失更加关注重建图像与GT 之间结构相似度之间的差异,让网络学习生成视觉上符合人类感知的图像。
O和G分别代表去雾后的图像和无雾图像的两个大小相同的窗口,窗口以像素i为中心。然后将高斯滤波器应用于O和G,计算出均值μO、μG,标准差σO、σG以及协方差σOG。MS-SSIM定义如下:
其中,C1、C2表示两个稳定变量,用弱分母运算来稳定除法运算。l(·)表示亮度,cs(i)表示对比与结构措施。α和β表示默认的参数,M表示尺寸总数。
本文提出的联合损失函数可以表示为如下,且根据经验将λ1、λ2分别设置为0.05与0.5:
2 实验与结果分析
为了说明本文方法的有效性,在数据集RESIDE[34]上与主流方法进行定量和定性比较,并对本文所提出的模块进行消融实验。
2.1 数据集与实验设置
RESIDE数据集是图像去雾领域的一个大型的基准数据集,自该数据集提出之后,便成为了评判图像去雾工作有效性的一个基准。本文选择RESIDE 数据集中的室内训练数据集(ITS)和室外训练数据集(OTS)作为训练集。ITS 包括1 399 张清晰图像和13 990 张有雾图像,大小都为620×460。根据大气光值范围在[0.7,1.0]与散射系数在[0.6,1.8]的不同组合,每一张清晰图片使用大气散射物理模型产生10 张雾浓度不同的有雾图像。OTS 数据集的生成方式与ITS 类似。OTS 共有296 695 张有雾图片。测试采用合成客观SOTS 的室内测试集和室外测试集,分别含有500张室内有雾图像和室外有雾图像。
训练使用RGB图像作为输入,并且在ITS的训练上使用数据增强,将图片随机旋转角度(90°,180°,270°),水平翻转。整个网络使用AdamW优化器对模型进行训练,指数衰减率β1为0.9,β2为0.999。初始学习率设置为0.001,网络训练的批大小设置为8。网络在ITS上共训练100 个epoch,学习率每经过30 轮训练衰减为原来的0.1倍。在OTS上不做数据增强,共训练20个epoch,学习率每经过6 个epoch 衰减为原来的0.1 倍。实验基于Pytorch框架实现,硬件为RTX 3090GPU。
2.2 与SOTA算法的对比
将本文算法与几种基于单幅图像去雾的SOTA 算法在合成数据集上进行定量和定性的比较。用于定量比较的方法有最为经典的传统去雾方法DCP[4],以及当前先进的基于深度学习的方法:AOD-Net[7]、DehazeNet[8]、EPDN[9]、GCANet[20]、GridDehazeNet(GDN)[17]、GFN[11]、URNet[13]、MSBDN[19]。这些都是图像去雾领域最为经典且具有代表性的工作。其中AOD-Net 与DehazeNet属于基于大气散射模型的深度学习去雾方法,利用网络学习大气光值与透射图。而GCANet、GridDehazeNet、URNet、MSBDN都是属于端到端的深度学习去雾方法,利用编解码结构网络直接学习有雾图像到无雾图像的映射。EPDN则是基于GAN的端到端去雾算法。
2.2.1 SOTS定量分析比较
定量比较采用图像处理中最常用的两个质量指标,即峰值信噪比(peak signal to noise ratio,PSNR)和结构相似度(structural similarity,SSIM)来评估不同方法的性能。实验结果表1所示。从表中可以看出,与其他几种SOTA图像去雾方法相比,本文算法在室内有雾数据集上的两个评价指标均好于其他方法;在室外有雾数据集上,SSIM指标略低于GridDehazeNet算法。

表1 本文算法与其他SOTA算法在SOTS测试集上定量比较Table 1 Qualitative comparisons among proposed algorithm and other SOTA algorithms on SOTS indoor dataset
2.2.2 SOTS定性分析比较
为了验证本文算法去雾视觉效果以及对图像细节的恢复能力,本文对室内数据集以及室外数据集的上去雾图像进行定性分析比较。室内测试集上的去雾效果的定性比较如图5 所示。从图中可以观察到由于对雾的厚度的估计不准确,DCP 不能成功去除雾,而且恢复的图像存在颜色失真的情况,通常比GT 更暗,如图5(b)三、四行所示。AOD-Net 会在物体边界周围造成光晕现象,而且在五幅图像上均存在去雾不干净。GCANet产生的结果能生成视觉上令人满意的图像,但是对于厚雾浓雾仍不能完成去除,墙壁颜色也会比原图更黑。MSBDN恢复的图像也有着不错的质量,但是仍然会产生一点灰色杂色的伪影,如图5(g)第三行图片椅子边所示,而且在图5(g)第四行图片浴室远处门缝里依然存在大量去雾没有去除。相比之下,本文算法与以上SOTA算法相比,生成的图像要更贴近于人眼感观,比较自然,而且细节复杂以及厚雾区域表现出色。

图5 在SOTS室内数据集上不同方法的定性比较结果Fig.5 Qualitative comparison results of different methods on SOTS indoor dataset
除了在室内测试集上做了定性分析,也在SOTS室外测试集进行了定性的比较,结果如图6所示。DCP算法在三幅图像的天空区域都出现了颜色失真的问题。原因是DCP对天空区域的大气光值与透射率的估计不准确。AOD-Net在三幅室外图像上表现很差,基本上没有去除雾,而且有一定的颜色失真。同样DehazeNet在天空区域也有一定的颜色偏移,如图6(d)所示。GCANet在图6(e)的第一幅和第三幅图的天空区域都有光晕现象产生,尤其是在第三幅图片上特别显著,光晕将天空的蓝色和背景白色割裂开。GridDehazeNet(GDN)在第一幅图树叶处的细节纹理没有处理好,而且在第二幅图远处大楼的墙壁上存在雾没有去除,与GT相比,颜色更浅。MSBDN与本文算法产生的结果相似,但本文算法在天空区域的颜色比MSBDN 恢复得更好,更加柔和,符合人类视觉感观。

图6 在SOTS室外数据集上不同方法的定性比较结果Fig.6 Qualitative comparison results of different methods on SOTS outdoor dataset
2.3 在真实有雾图像上的实验结果
为了进一步验证本文模型的泛化性与有效性,本文使用在RESIDE 室内训练集上训练的模型用于对真实世界有雾图像进行测试,并且与SOTA 算法进行比较,去雾结果如图7所示。

图7 在真实有雾图像上不同方法的定性比较结果Fig.7 Qualitative comparison results of different methods on real hazy images
从图7(c)可以看出,AOD-Net在两幅图上都不能很好去雾,特别是在浓雾区域。DehazeNet 方法对远景处的去雾效果不好,如图7(d)所示。GirdDehazeNet 处理的结果整体很黑,出现颜色失真的问题。在第一幅图中,其他算法在右上角白色娃娃处以及左上角绿色帽子处都存在雾残留和细节模糊。在第二幅图右上角远处的沙包处,其他算法都不能去除远景的雾,且沙包的轮廓恢复不清楚,相比之下本文算法结果较好,如在第一幅图上远景的浓雾处理比较好,同时在远景处的沙包上细节轮廓恢复较好。从以上实验结果来看,本文方法能有效去除薄雾区域的雾,浓雾和厚雾区域也能较好地去除,同时保持了图像原有的色彩以及细节纹理,更符合人类视觉感知。
2.4 消融实验
为了验证本文所提出的图像去雾网络中每个子模块的有效性,将提出的各模块在SOTS室内测试集上进行消融实验,讨论各模块对峰值信噪比和结构相似度影响程度,实验结果如表2所示。移除四个组件的基础网络的峰值信噪比和结构相似度为29.85 和0.979。本文的模型比基础网络的峰值信噪比提高4.59 dB。此外本文所提出的每个组件都能对基础网络的性能带来改善,特别是ABSDC 模块,能在峰值信噪比上超越基础网络2.88 dB,主要原因是其能够有效提取多个层次的丰富上下文特征用以融合。由于特征感受野的提升,对图像结构以及细节恢复是有益的。并且从表中两个指标可知,与只加入分辨率层次特征融合模块或空间上下文层次特征融合模块的效果相比,逐渐加入多个层次的特征融合模块能够很好提升去雾表现,这说明各个多层次的特征融合模块的去雾效果是相互促进,比单一层次的特征融合要好。

表2 在SOTS室内数据集上各个组件的消融实验结果Table 2 Ablation results of various components on SOTS indoor dataset
2.4.1 ABSDC模块分析
为了说明ABSDC模块中使用平滑扩张卷积和普通卷积层的性能差异及扩张率的不同排列顺序对重建结果的影响,设置两组对比实验:(1)在ABSDC模块中,将平滑扩张卷积块替换为普通卷积层(即无扩张率的正常卷积),保持其他结构不变,结果如表3所示。(2)进一步量化不同扩张率层次的ABSDC模块的排列顺序对最终去雾效果的影响,结果如表4所示。

表3 平滑扩张卷积与常规卷积对比Table 3 Comparison between smooth dilated convolution and conventional convolution

表4 不同扩张率的ABSDC模块排列顺序对重建的影响Table 4 Influence of order of ABSDC modules with different expansion rates
从表4 结果来看,三个ABSDC 模块的几种排列顺序中,2,4,1 这种排列对重建效果是最好的。在三个ABSDC模块中,相对浅层的ABSDC的感受野相对比较小,使用较大扩张率的ABSDC 模块提取更加全局的信息;相对深层的ABSDC的感受野比较大,故使用较小扩张率的ABSDC模块提取不相关的背景信息。在去雾阶段,通过感受野的扩大有助于获得更多相邻像素的信息,这可以使图像去雾结果更清晰,并且利用不同层次的特征信息互补,提高了去雾效果。
2.4.2 AFIM模块分析
为了验证AFIM 模块对于编解码阶段特征信息融合交互的有效性,在基础网络上将AFIM模块与跳跃连接进行对比,结果如表5所示。相比于跳跃连接这种直接将上采样层与下采样层的特征直接相加的方式,AFIM模块通过学习上下采样层的一个权重因子来自适应地融合特征要比跳跃连接效果好。

表5 跳跃连接与AFIM模块比较Table 5 Comparison between skip connection and AFIM
2.4.3 联合损失对于重建结果的影响
为了进一步验证本文提出的联合损失函数对于重建效果的影响,在SOTS 室内数据集上进行对比实验,实验结果如表6 所示。无论是在基础网络上还是完整的网络上,相比采用L2损失函数,本文提出的联合损失函数都会明显提高图像重建后的性能。从图8 中的去雾结果可以看出,在不加任何子模块的基础网络上,使用L2损失监督网络训练与使用联合损失监督网络相比,使用联合损失训练出的网络恢复出的图像视觉效果更好,并且能更好地去除雾,例如图8 中左上角红色墙上的雾。

表6 联合损失函数与L2损失函数比较Table 6 Comparison of joint loss function and L2 loss function

图8 联合损失消融实验比较结果Fig.8 Comparison of ablation results of joint loss function
3 结束语
本文提出了一种有效的基于感知监督引导和多层次特征融合的图像去雾网络。网络通过有效的提取、融合不同分辨率层次的多尺度特征和不同扩张率层次的空间上下文特征增强了图像细节与结构信息,使得恢复后的图像细节保留更好,空间位置精确。并且在训练阶段采用平滑L1损失结合感知损失与多尺度结构相似度损失来监督网络训练,使得恢复的图片颜色保真且更加符合视觉感知。在合成有雾数据集以及真实有雾图像上做了广泛的测试,并与目前先进的单幅图像去雾方法进行了定量与定性比较。实验结果表明,该网络去雾后图像整体颜色和细节纹理更接近清晰图像。在客观指标上,也验证了本文方法的良好性能。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
