
基于先验显著性信息的道路场景目标检测
2023-11-20 10:58王钲棋
计算机工程与应用 2023年21期
王钲棋,邵 洁
上海电力大学 电子与信息工程学院,上海 201306
道路场景目标检测指对道路上的行人、车辆进行定位和识别,是自动驾驶技术中的核心算法之一。在车辆行驶途中,准确地定位和识别道路目标,可以为车辆提供路况信息,帮助车辆做出决策,保障车辆的行驶安全。
随着深度学习的快速发展,道路场景目标检测取得了巨大的进步。但是基于计算机视觉的道路场景目标检测算法也面临诸多困难,总结为以下几个方面:(1)汽车行驶途中路况复杂,难以精准地检测到目标;(2)道路上的目标种类较多,目标边框的大小差异明显;(3)检测信息需要及时地传输回汽车的控制系统辅助汽车做出判断,对算法的推理速度要求较高。
目前主流的目标检测算法主要分为两类。一类是双阶段目标检测,先预测出可能存在检测目标的区域再对预测出的区域进行分类和位置回归并计算得到检测框,经典模型包括Faster RCNN[1]、Mask-RCNN[2]、Cascade-RCNN[3]等。Bhargava[4]提出了一种跨域的Faster RCNN[1]模型,针对每个域设计了单独的分类器/检测器,多种不同的信息交互,丰富特征信息,增强了网络的泛化能力。Wei 等[5]则在MS-CNN[6]模型的基础上利用反卷积运算并通过融合特征图的方法提取更丰富的特征信息,提高检测精度。文献[7]提出一种融合了语义分割的目标检测框架,将语义分割掩膜与共享层特征融合,增强目标特征,减少漏检和误检情况。Shan等[8]将无监督循环一致性生成对抗网络CycleGAN[9]与Faster RCNN[1]网络结合,利用CycleGAN[9]网络生成与晴朗白天的图像对应的夜晚图像,设计了一种端到端的训练方式,通过融合不同域的信息,增强网络的泛化能力,提高检测精度。 双阶段目标检测方法虽然能达到较高的精度,但检测速度较慢,无法满足道路目标检测任务实时检测的要求。
另一类是单阶段目标检测,不需要对候选区域进行预测,而是通过一个统一的CNN 网络完成目标的定位等一系列运算,因此拥有比双阶段方法更快的检测速度,标志性模型有YOLO V3[10]、SSD[11]和YOLO V4[12]等。Wu 等[13]将交通目标检测、可驾驶区域分割和车道检测三个任务同时整合在一个YOLO V4网络上,分别构建三个解码器处理不同的任务并成功将模型移植到嵌入式设备上。类似的,Vu等[14]构建了一种多任务融合网络,利用两个独立的解码器处理不同的任务。单阶段方法的优势是检测速度较快,能够实现目标的实时检测但是检测精度低于双阶段方法。
道路场景复杂,目标大小不一,种类繁多,有大量的无关因素对网络的检测产生影响,因此道路目标检测的难点在于:如何排除无关物体的干扰,在复杂的场景中准确地检测到目标类。目前YOLO 系列最新提出的YOLO V5网络在COCO数据集上达到了检测精度和检测速度的平衡,在实现较高检测速度的同时还能保证检测精度,但是在道路场景下YOLO V5网络在处理形状相近的目标(如自行车和摩托车)和密集目标时检测效果并不理想。
针对在道路场景目标检测任务中YOLO V5 网络特征提取不充分导致的漏检误检情况,提出一种利用显著性信息增强检测效果的道路目标检测网络,将显著性信息与卷积层特征融合,增强目标的位置信息,提高检测准确率,解决漏检误检问题。同时采用检测速度都较高的YOLO V5s模型作为主干网络,更好地满足了道路目标检测的实时性要求。
本文的主要贡献如下:
(1)提出了一种语义先验信息融合的方法。利用语义先验信息生成显著性图像,为网络提供空间上的位置信息,有效增强了目标特征,抑制了背景信息的干扰,提高了检测的准确率。
(2)针对引入的显著性信息,提出了一种有效的网络结构。该结构在融合显著性信息时仍保持原有的网络特性。通过消融实验证明在原始YOLO V5s 网络中有效的即插即用模块(CBAM)在新的模型中依然有效,并未因为网络结构的改变影响模型的整体稳定性。
(3)在Cityscapes 数据集中,对于7 类常见目标物(汽车、自行车、行人、骑手、摩托车、公交车、卡车)本文改进的Sa-YOLO V5s模型与YOLO V5s相比mAP_0.5提高了0.083,mAP_0.5:0.95提高了0.067;与BshapeNet+[15]模型相比mAP_0.5 提高了0.024:与DIDN[16]模型相比,mAP_0.5提高了0.072,在Cityscapes数据集上达到SOTA(state of the art)。在推理速度方面达到了33 FPS,满足实时检测的要求。
1 本文算法
本文提出的Sa-YOLO V5s 道路目标检测框架基于YOLO V5s 算法,首先对显著性信息提取模块(SaBlock)进行讲解,其次介绍了针对引入的显著性信息构建的一种新的网络结构。Sa-YOLO V5s网络结构框架如图1所示。
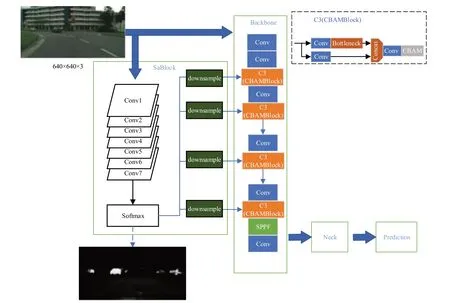
图1 Sa-YOLO V5s网络结构Fig.1 Sa-YOLO V5s network structure
1.1 显著性信息提取模块(SaBlock)
显著性目标检测主要通过划分前景和背景,检测出显著性场景中最具吸引力的物体,已经被广泛地应用于图像分类[17-18]、语义分割[19-20]、机器人导航[21]等方向。在道路目标检测任务中,人眼通常最关注的是道路上的行人和车辆,因此本文将私家车、行人、公交车等7类常见目标设置为显著性目标。
1.1.1 语义分割网络SaNet
为了分割前景和背景从而提取出图片的显著性信息,本文参考文献[22]设计了语义分割网络SaNet,该网络结构如图2所示。

图2 SaNet网络结构Fig.2 SaNet network structure
在车辆行驶过程中需要实时的对道路上的目标进行检测,因此选择处理速度更快,参数量更少的全卷积结构作为SaNet 的网络结构。SaNet 由6 个3×3 卷积和一个8×8 卷积组成,为了保证图像尺寸不变,除最后一层卷积外,在所有的卷积层执行padding 补0 操作。在每一个3×3卷积后都添加批量归一化(batch normalization,BN)层和激活函数(rectified linear unit,ReLu),在最后一层卷积对输出值进行L2标准化(L2 normalized),用以生成具有128 维单位长度的描述符进行损失函数计算。
利用SaNet对Cityscapes数据集中的19类目标进行逐像素预测。通过归一化指数(Softmax)层将每个类的得分映射到(0,1)区间内得到每个像素属于类的概率,再从所有的类中取出道路上常见的7类目标,将其合并为前景,剩余的类别作为背景得到显著性图片。图3中从左往右依次是原始图片、逐像素语义标记的显著性标签和预测得到的显著性图片。比较图3(b)和图3(c)可以看到利用SaNet 网络可以较为清楚地预测出目标物体。由于显著性图片只是用来辅助检测,为卷积特征提供显著性信息,因此对于一些难以检测的小目标不需要对其形状进行精准预测,只需要确定大概范围并勾勒出基本轮廓,就可以帮助网络获取其位置信息增强网络的检测能力。

图3 基于SaNet生成的显著性图片Fig.3 Saliency pictures generated based on SaNet
经过浅层卷积输出的特征图具有较高的空间分辨率,包含更多像素信息,深层卷积产生的特征图具有丰富的语义信息,但是会损失部分位置信息。因此将SaNet生成的显著性图像进行下采样后与不同尺度的卷积特征融合,使得显著性信息与卷积特征充分结合,帮助特征提取网络更好的定位目标,增强对目标的特征提取能力。
1.1.2 损失函数
在SaNet网络中,使用了一种基于尺度不变特征转换(scale-invariant feature transform,SIFT)的度量损失[23]。该目标函数模仿SIFT的匹配规则,生成n对有着相同特征点的匹配对X=(A1,P1,A2,P2,…,An,Pn)并通过描述符构建它们之间的距离矩阵,分别寻找与A最相近的不匹配块以及与P最相近的不匹配块,选出距离更小的不匹配块作为负样本,分别得到匹配对(A,P)的描述符和负样本N的描述符,利用三元损失函数计算损失。具体计算过程如下:

在该损失函数的计算过程中,min(d(ai,pjmin),d(akmin,pi))已经预先计算得到了,因此与随机三元损失函数相比,只需要进行距离矩阵的计算和最小值的计算,大大地减少了计算开销,提高了程序运行速度。
1.2 融合显著性信息的网络结构
1.2.1 网络结构
如图1所示,为了在不改变原有网络特性的基础上更好地融合显著性信息,构建了一种新的Sa-YOLO V5s网络。
该网络主体部分由显著性信息提取模块(SaBlock)和YOLO V5s 特征提取网络(backbone)组成。将网络读取到的图片,同时输入显著性信息提取模块和特征提取网络,在显著性信息提取模块中使用语义分割网络(SaNet)提取图片中的语义信息,生成显著性图像,获得图片的空间信息;在特征提取网络中利用卷积层和残差结构充分提取图片的全局特征。为了更充分地利用显著性信息,对显著性信息提取模块生成的显著性图像进行双线性插值下采样。将显著性图像下采样到不同尺寸,与多种尺度的卷积特征融合,为特征图提供空间上的注意力,帮助网络更好地确定目标所在的区域。
为了验证显著性信息提取模块并未影响模型的整体稳定性,新的网络结构还保持原始网络的结构特性。使用即插即用的注意力模块(CBAM)对Sa-YOLO Vs网络进行结构稳定性测试。
1.2.2 网络稳定性测试
Woo 等[24]提出了一种包含通道注意力和空间注意力的卷积注意力网络(convolutional block attention module,CBAM),其中通道注意力模块(channel attention module,CAM)对于输入的特征图,首先采用进行基于宽(W)和高(H)的全局最大池化(global max pooling)和全局平均池化(global average pooling)操作提取通道特征,将得到的两个1×1×C的特征图送入一个两层的多层感知机(multilayer perceptron,MLP)。而后,将MLP输出的特征进行加和操作,再经过激活函数(sigmoid),生成最终的通道注意力特征,具体结构如图4。
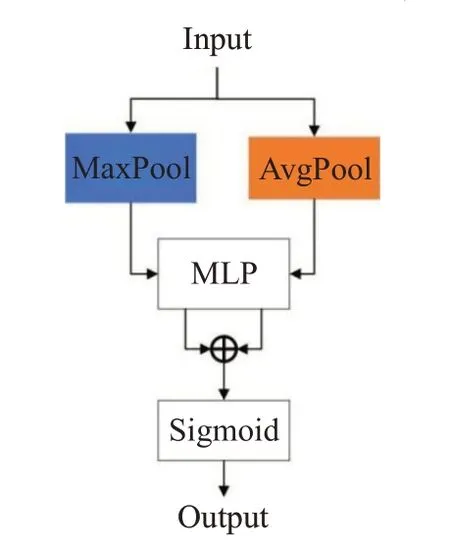
图4 通道注意力模块Fig.4 Channel attention module
空间注意力模块(spartial attention module,SAM)对于输入的特征图,分别采用基于通道的全局最大池化(global max pooling)和全局平均池化(global average pooling)操作,得到两个H×W×1 的特征图,然后对这2个特征图进行通道拼接(ConCat)通过一个7×7 卷积操作,降维为1 个通道,即H×W×1。再经过激活函数(sigmoid),生成空间注意力特征,具体结构如图5。
借着老婆和闺密们没完没了地煲电话粥的机会,我又仔细地想了下王姐这个人,虽说现在还谈不上什么了解,至少也该对她有个评价了,那就是这个女人不寻常。虽说套用样板戏的台词,但绝对没有贬意。
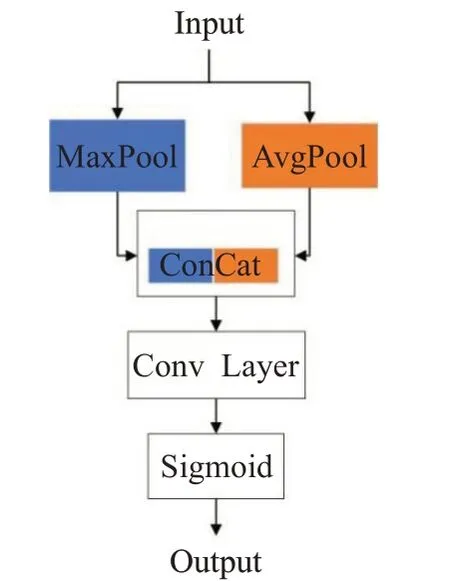
图5 空间注意力模块Fig.5 Spatial attention module
将CBAM注意力模块添加到每个C3模块的后面如图1所示,分别训练原始YOLO V5s网络和融合了显著性信息的Sa-YOLO V5s网络,结果如表1所示。

表1 网络稳定性测试Table 1 Network stability test
从表中可以看到在添加了CBAM 模块后,原始的YOLO V5s 网 络 在Cityscapes 数 据 集 上mAP_0.5 和mAP_0.5:0.95 分别提高了0.016 和0.009。引入显著性信息的YOLO V5s 网络在添加了CBAM 模块后mAP_0.5和mAP_0.5:0.95分别提高了0.015和0.007。
CBAM 模块在原始YOLO V5s 网络上的效果要略好于引入了显著性信息的YOLO V5s 网络这是因为显著性信息本身就包含了位置信息,为网络提供了空间上的注意力,因此CBAM 模块中的空间注意力模块难以再向网络提供更丰富的空间信息,导致对网络效果的提升不如原始的在原始的YOLO V5s网络上明显。
由表1可以得到结论:在本文提出的针对引入的显著性信息设计的新的网络结构中即插即用的CBAM模块依然有效,网络特性并未因结构的改变而改变。在添加了显著性信息提取模块后网络依旧保持原有的稳定性。
2 实验及结果分析
将改进后的算法应用在CityScape 数据集上,并与文献[15]提出的BshapeNet+算法、文献[16]提出的DIDN算法和原始YOLO V5s 算法进行对比实验。本文主要选取道路上常见的7 类物体作为目标包括汽车、自行车、行人、骑手、摩托车、公交车、卡车。
2.1 实验设置
采用道路场景数据集Cityscapes 进行训练,包含从50个不同城市的街景中记录的各种立体视频序列。本文选取5 000帧像素级注释作为数据集,其中包括2 975张训练图、500 张验证图和1 525 张测试图,每张图片大小都是1 024×2 048。
实验环境使用Windows 操作系统,显卡为Nvidia RTX3080,显存大小为10 GB,CUDA 版本11.0,cuDNN版本8.0.5,Pytorch 版本为1.9.0,编译语言为Python3.8,总迭代次数为40次,迭代批量大小设置为18,优化器选择SGD。
2.2 评估指标与模型训练
式中,TP 是正确检验个数、FP 是误检个数、FN 是漏检个数。AP 为P-R 所围成的曲线面积,N是检测类别,mAP 是所有类别AP 的均值。mAP 的值越大检测效果越好。
在训练过程中为了解决遮挡物体检测困难的问题,本文将NMS非极大值抑制算法修改为式(5)所示,用来剔除多余的目标框,其中通过DIoU[25]判断是否为同一物体的预测框。
本文采用的DIoU计算方法在原始的IoU计算过程中增加了对不同目标框中心点距离的计算,如式(6)所示:
从图6中可以看到黑色框与绿色框是两个不同物体的预测框,分别记为A,B。灰色虚线的外框是同时包住预测框A和预测框B的最小方框,其中c是外框对角线的长度,d是A框中心点与B框中心点的距离即式(10)中的ρ(A,B)。在计算DIoU时首先通过式(11)得到两个预测框之间的IoU(交并比)值,然后计算中心点距离d与对角线距离c的比值,最后用IoU减去比值得到DIoU。

图6 不同种类目标的预测框A和预测框BFig.6 Prediction box A and prediction box B for different types of objects
DIoU综合考虑了两个预测框之间的重叠率和中心点距离,当出现两个不同种类预测框距离很近时,DIoU可以同时保留两个预测框,减少漏检率。
如图7 所示,在训练过程中本文改进的Sa-YOLO V5s 随着模型收敛,验证集mAP 稳定上升。mAP 在阈值为0.5和阈值为0.5∶0.95的情况下都明显高于原始的YOLO V5s。在第10个epoch左右mAP值有些许下降,这是由于采用了Warmup预热训练,学习率变化导致的训练误差增大,随着后续学习率的调整,模型逐渐达到收敛状态。
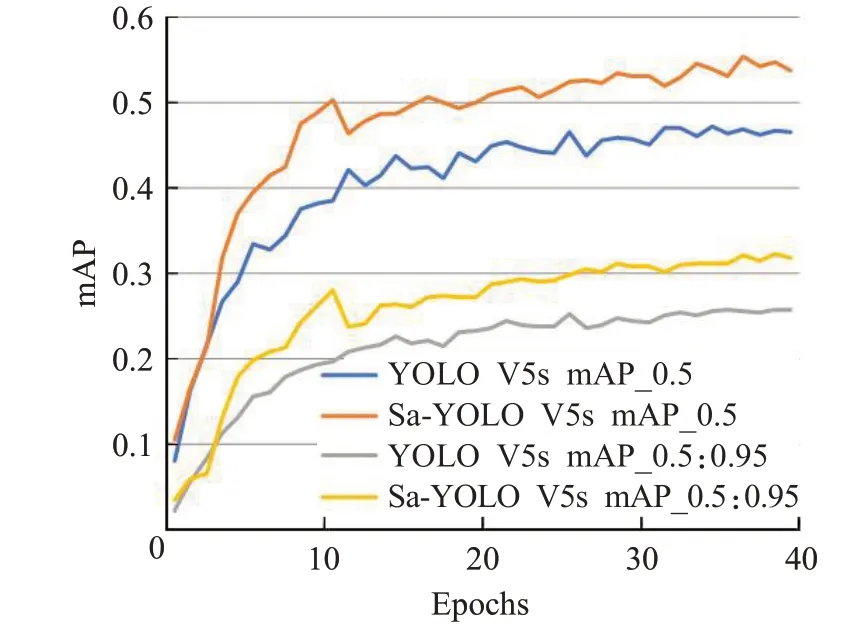
图7 验证集mAP曲线Fig.7 Mean average precision curve on validation set
2.3 消融实验
为了验证模型的有效性,在Cityscapes 数据集上进行消融实验。表2比较了Sa-YOLO V5s模型中不同组件对模型效果的影响。消融实验以YOLO V5s 模型为基础,统一输入大小为320×640 的图片,评估指标为mAP_0.5和mAP_0.5:0.95。

表2 在CityScape数据集上测试每个组件的消融实验Table 2 Ablation experiment of each component on CityScapes dataset
从表2 可以看到在添加了显著性信息后mAP 值得到大幅提升其中mAP_0.5 增加0.032,mAP_0.5:0.95 增加0.027;CBAM注意力模块也对结果有小幅提升;而针对非极大值抑制(NMS)算法的改进同样极大地提高了mAP 值。经过分析后认为DIoU-NMS 之所以可以大幅提高检测的准确率是因为道路场景中包含大量待检测目标,因此遮挡情况频繁出现。
DIoU-NMS 算法同时参考了不同预测框的IoU 值和中心点距离,成功避免了因遮挡导致的漏检,从而显著增强了网络的检测能力。
2.4 实验结果分析
如表3 所示,比较了原始YOLO V5s 网络,改进的Sa-YOLO V5s网络、BshapeNet+网络以及DIDN网络在CityScapes数据集上的表现,评估指标为mAP_0.5。

表3 不同算法性能对比结果Table 3 Performance comparison results of different algorithms
(1)从表3 中可以看出,与原始的YOLO V5s 模型相比,本文提出的Sa-YOLO V5s 方法mAP_0.5 提高了0.083,在大多数类上都取得了较好的效果。即使是在外观上高度相似的“自行车”和“摩托车”类别上也有了显著的改进,这表明Sa-YOLO V5s 网络可以过滤无关噪声的干扰,提取物体更细节的特征。
(2)结合图8 中的标签数量分布可以看到虽然“公交车”“卡车”只有少量注释,但其性能相比YOLO V5s也得到了显著的提高。这是因为SaBlock和注意力模块帮助网络更好地注意到目标的位置,从而使得网络在处理图片的时候在目标位置投入更多的精力。在“卡车”类上YOLO V5s 和Sa-YOLO V5s 网络的表现均不如DIDN网络,这与DIDN网络的训练方式有关。DIDN网络在训练过程中引入了Foggy Cityscapes,BDD100k等多个不同的数据集,大大增加了“卡车”类标签的数量,从而获得了更好的效果。
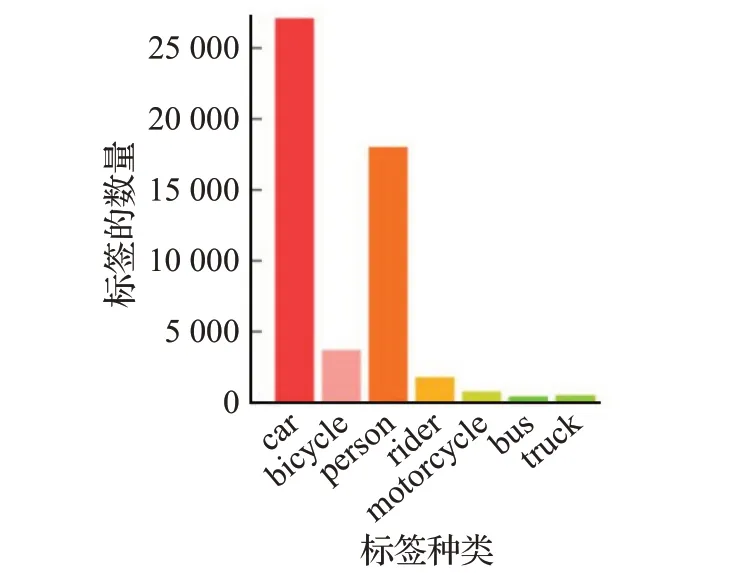
图8 CityScapes数据集中的标签分布Fig.8 Label distribution in CityScapes dataset
(3)在所有的类别中,只有在“行人”类中Sa-YOLO V5s网络的表现不如基础的YOLO V5s网络。在对数据集进行分析后,这一现象的产生是多种因素共同作用的结果。“行人”类的目标框较小,而为了加快网络的处理速度,本文在输入时将尺寸为1 024×2 048 的图片下采样为320×640的大小,损失了一部分信息。因此在利用SaBlock对图片的显著性信息进行提取时有一定的概率将“行人”目标误判为无关的背景类,最终拉低了检测效果。
最后,结合所有类的AP值和最终的mAP值,Sa-YOLO V5s算法在Cityscapes数据集上的效果好于所有目前已知的目标检测算法。其中mAP_0.5达到了0.548,mAP_0.5:0.95达到了0.324,检测速度达到了33 FPS满足了实时检测的要求,在CityScapes数据集上实现SOTA。
3 结语
本文提出了一种基于显著性信息改进的Sa-YOLO V5s 网络,以CityScapes 为数据集,以YOLO V5s 为基础,提出了一种语义先验信息的融合方法,利用语义信息生成显著性图像,为网络提供空间上的注意力。针对提出的方法设计了一种有效的网络结构,在保持网络稳定性的同时,充分利用显著性信息,通过实验证明新的网络结构依然保持原网络的网络特性;使用DIoU-NMS算法过滤多余的预测框,有效地减少了漏检误检的概率。
实验结果证明,改进后的方法在CityScapes数据集上相比原始网络mAP_0.5和mAP_0.5:0.95分别提高了0.083和0.067,检测速度也达到了33 FPS,满足实时检测的条件。
下一步的工作准备在本文的算法基础上增强网络的鲁棒性和泛化能力,继续改进显著性提取模块Sa-Block,避免在处理小目标时出现误判成背景的情况,降低小目标检测的漏检率。将网络部署到移动端,与实际应用场景中结合,以更好地满足日常生活的实际需求。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
西南交通大学学报(2018年5期)2018-11-08
北京航空航天大学学报(2018年1期)2018-04-20
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20
知识产权(2016年8期)2016-12-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
