
小样本下基于决策树-SNN的恶意流量检测方法
2023-11-20 10:58李道全李玉秀任大用
计算机工程与应用 2023年21期
李道全,李玉秀,任大用
青岛理工大学 信息与控制工程学院,山东 青岛 266520
随着信息技术的迅猛发展,互联网已经成为重要的信息传播方式[1]。网络的发展实现了信息共享,但也无法避免地会受到许多恶意攻击的威胁[2],比如拒绝服务攻击[3],恶意流量便随之产生。为了给用户提供良好的网络服务,有必要对网络流量进行监管,及时检测出网络中的恶意流量。恶意流量检测[4]是指在网络中获取流量,通过某种技术构造一个分类器对流量进行分类识别,从而尽可能地检测出网络中的恶意流量,以便于尽快启动相应的防御措施来维护网络安全。由于真实的网络环境情况十分复杂,有些恶意流量的数量稀少,难以获取充足的研究样本[5],这给恶意流量检测的研究带来了许多困难。近年来,小样本下的恶意流量检测问题受到了广泛关注,研究者们主要通过机器学习[6]和深度学习技术[7]进行小样本下恶意流量检测的研究,但现有的研究方法还不够成熟。
基于机器学习的小样本恶意流量检测方法主要是依靠特征工程来筛选流量特征,然后通过机器学习算法实现恶意流量检测,但现有方法在多分类情况下大多准确率不高[5]。Chowdhury 等[8]将卷积神经网络(convolutional neural network,CNN)、支持向量机(support vector machine,SVM)和最近邻集成在一个分类器中实现了小样本下的恶意流量检测,但集成学习的明显不足是每个子方法的权重占比会严重影响检测效果。吴春琼等[9]通过粒子群算法对网络系统状态特征进行选择,找到最优模型参数和样本特征。实验结果证明了该方法在小样本下的可行性。文献[8]和文献[9]都是通过机器学习算法构建一个多分类器来实现小样本下恶意流量的检测,但是在多分类情况下准确率都较低。一些研究者提出将多分类问题转化为二分类问题,并与机器学习方法相结合,以提高多分类流量检测的准确度。张春艳等[10]利用聚类思想,将多种流量分类检测问题转化为多个二分类问题,并通过SVM 实现二分类。与传统SVM 进行多种流量分类检测的方法相比,该方法提高了准确率,但缺点是计算量大,并且特征选取的好坏会直接影响最终的准确度。
虽然机器学习方法在小样本下恶意流量的检测问题上有一定的可行性,但由于特征选取的好坏会直接影响模型性能,而传统的机器学习在特征的选取方面一直存在着许多挑战,因而准确度普遍不高。
深度学习技术是机器学习的子领域,近些年在自然语言处理、计算机视觉等领域发展迅速。深度学习中的多层学习结构可以在分布式的特征中发现高级的抽象特征,并能够通过训练学习来自主选择特征,解决了机器学习中的特征选取问题。但现有基于深度学习技术的小样本恶意流量检测方法存在着模型过拟合[11]和特征提取不足的问题[5]。Xu 等[12]提出了一种小样本下改进的深度神经网络架构,该架构由特征提取网络和对比网络组成,特征提取网络用来提取流量特征,对比网络用于确定流量类别,实验证明了该方法能够在小样本下取得良好的检测效果。Yu 等[13]将小样本学习(few-shot learning,FSL)应用于恶意流量检测,并提出了两种改进的深度神经网络和CNN,以使FSL 适用于序列数据。该方法首次将FSL应用于恶意流量检测领域,并取得了较高的检测精度。但是文献[12]和文献[13]的缺点是容易出现模型过拟合现象。He 等[14]将通道注意力融入CNN 和自动编码器中进行小样本下的恶意流量检测,该方法通过设置阈值来判断异常流量,但阈值的设置十分依赖于网络环境状态,这导致该模型的适应能力不强。Ye 等[15]提出了一种模糊循环方法来改进基于长短时记忆神经网络的分类器,有效提高了小样本下恶意流量检测的准确度,但是该方法需要在均衡的数据集下才能取得理想的检测效果。高浩寒等[16]通过孪生神经网络进行小样本检测,与传统的深度神经网络相比,孪生神经网络更适合处理小样本问题,但该方法的缺点是特征提取不够充分。
综上,目前关于小样本下恶意流量检测方法存在着准确度低、特征提取不足和模型过拟合问题。针对这些问题,本文提出了一种小样本下基于改进决策树-孪生神经网络的恶意流量检测算法。该算法不仅实现了小样本下流量的快速检测,而且在准确度上有着出色的表现。本文的主要贡献如下:
(1)基于类间中心距离构建二叉决策树,拆解多分类任务,降低多分类任务难度,提高检测准确度。
(2)将孪生神经网络的对比分支设计为三支一维卷积神经网络(one-dimensional convolutional neural networks,1D-CNN)并行的结构,解决小样本下特征提取不足问题。
(3)通过池化策略和一维卷积操作对SE 模块进行优化,并将优化后的SE模块引入1D-CNN中,以减少小样本下模型过拟合问题。
1 基于决策树-SNN的恶意流量检测算法
为了解决小样本下恶意流量检测准确度低、特征提取不足和模型过拟合问题,本文提出了一种小样本下基于改进决策树[17]-孪生神经网络的恶意流量检测算法。假设将五种流量进行分类检测,流量名称用数字代替,本文提出的算法框架图如图1所示。其中,二叉决策树结构是利用类间中心距离将多分类任务转化为二分类任务,降低多分类任务难度,从而在一定程度上解决了小样本下多种流量分类检测准确度低的问题。其次,孪生神经网络(siamese neural network,SNN)通过改进对比分支结构,扩大了训练次数,间接扩充了训练样本数量,以改善小样本下特征提取不足问题。此外,在SNN的子网络中引入优化后的SE模块来缓解小样本下产生的模型过拟合问题。

图1 基于改进决策树-SNN的恶意流量检测算法框架图Fig.1 Framework diagram of malicious traffic detection algorithm based on improved decision tree-SNN
如图1 所示,每个分裂结点处设置了一个SNN 模型,用来完成当前结点的二分类任务,每个叶结点代表一个流量类别。流量检测过程实际上是走了一条从根到叶的SNN结点路径,经过层层的二分类过程,最终确定流量类别。
1.1 构建二叉决策树结构
本文选择类间中心距离来确定二叉决策树中各个分裂结点的二分类任务。类间中心距离指的是不同类别的类中心之间的距离,类间距离越大说明区分两类越容易,分类精确度也会越高[6]。文献[17]指出,决策树中离根结点越近的分裂结点的分类精度越高,则分类性能越好。因此只要将分类精度越高的分类任务放在离根结点越近的分裂结点上,就可以使模型的分类性能越好。
通过计算类中所有数据的平均值来获得类中心,类中心向量中第K个特征值的计算公式如下:
其中,cik代表第i条数据的第k个特征值,类中心表示为(C1,C2,…,Cm)。
确定各类别的类中心后,利用K-means 算法[6]将给定的类中心集合按照数据点间的距离大小聚类为两个子类,并使子类内的数据点间距尽可能小,从而使两个子类之间的距离尽可能大。然后递归的将子类进行二分类,直到所有子类里只有一个类中心数据。本文选择n维空间欧氏距离计算类间中心距离,公式如下:
先完成的二分类任务说明其类间中心距离较远,类别容易区分,分类精度较高,这种分类任务要放在靠近根结点的分裂结点上。后进行的二分类任务说明其类间中心距离较近,类别不易区分且分类精度较低,这样的分类任务要放在远离根结点的分裂结点上。
经过上述过程,可以确定各分裂结点的二分类任务,接下来,只需针对每个分裂结点构建一个SNN 模型,就可以建立起二叉决策树,从而实现本文提出的基于改进决策树-SNN的恶意流量检测算法。
1.2 孪生神经网络
传统神经网络在小样本下容易造成特征提取不足和模型过拟合问题,从而使分类器的效果较差[16]。在这种情况下,文献[18]提出通过对比样本间相似度并扩大训练次数的是一种可行的方法。当训练样本数量为n时,每次向SNN模型输入两个样本,可以对模型进行C2n次有效训练,因此SNN 能够有效扩大模型的训练次数。由于样本组的随机选取特性,扩大模型的训练次数相当于间接扩充了训练集内的总样本数量,从而可以解决因样本数量过少造成的特征提取不足问题[19]。此外,SNN能够通过挖掘不同样本之间的关联关系,减少因样本数量不足导致的模型过拟合问题[18]。
为了解决小样本下特征提取不足和模型过拟合问题,本文从优化分支结构和加强特征效果的角度对传统SNN进行了改进:
(1)将SNN 的对比分支设计为三支基于改进SE 模块的1D-CNN并行的结构,解决特征提取不足问题。
(2)对SE 模块进行优化,并将优化的SE 模块引入1D-CNN 中建模通道间的依赖关系,解决模型过拟合问题。
1.2.1 基于改进对比分支结构的SNN
传统SNN 是一个双分支结构,由两个结构相同且权重共享的神经网络拼接而成,以两个样本为输入,输出样本相似度[18]。
为了进一步扩大模型训练次数来解决小样本下产生特征提取不足问题,并充分挖掘样本间的关联信息来避免小样本下的模型过拟合问题,本文将传统SNN 的对比分支进行了改进,设计为三支基于改进SE 模块的1D-CNN并行的结构,如图2所示。
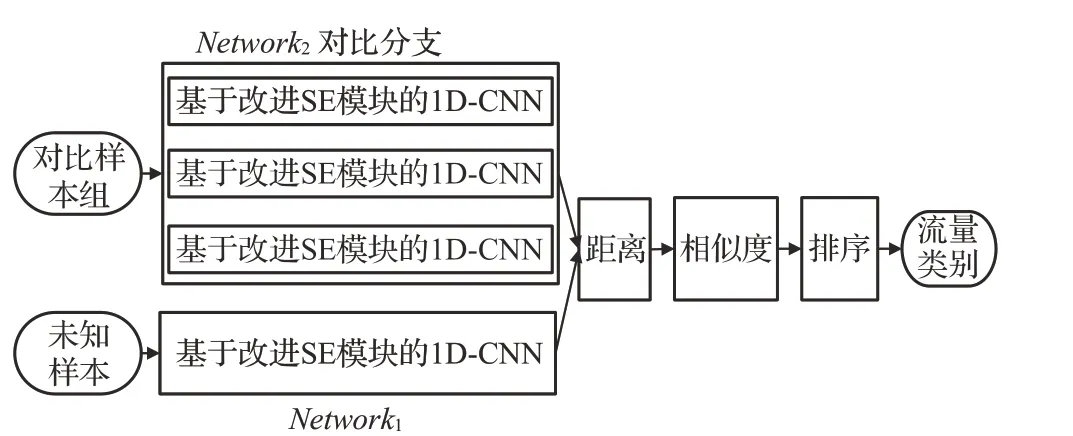
图2 改进的SNN网络模式Fig.2 Improved SNN network mode
如图2 所示,Network1和Network2是权值共享的两个分支网络,分别由不同数量的同一个基于改进SE模块的1D-CNN 构成。Network1由一个基于改进SE模块的1D-CNN构成,Network2是对比分支,由三个并行的基于改进SE模块的1D-CNN构成。
本文所提出的SNN 模型的输入是个三元组,即{X,Y,Z}。其中,X代表任一训练样本;Y(y1,y2,y3)代表对比样本组,其中包含三个不同的对比样本,这三个对比样本的类型相同;Z代表标签,当X与Y为同类样本时,Z为1,反之,Z为0。
未知样本X经过Network1映射为一维特征fx,对比样本组Y(y1,y2,y3)经过Network2映射为一组一维特征(fy1,fy2,fy3),Y中三个不同的对比样本分别由Network2中的三个1D-CNN 映射为一维特征。然后计算出fx与(fy1,fy2,fy3)的平均欧式距离,通过这个平均距离来拟合样本间的相似度差异,距离公式如下:
本文所提出的SNN 模型的输出是样本的相似度。将平均欧式距离的计算结果放入全连接层。然后经过输出函数得到样本的相似度,结果介于0到1之间,越接近于1 表示两个输入数据越相似,反之则代表越不相似。输出函数的计算公式如下:
其中,V代表相似度,σ代表Sigmoid 函数,MLP代表全连接操作,D代表距离函数。
本文使用的交叉熵损失函数,公式如下:
其中,Z是标签,P代表n次对比中类型相同的概率。
流量检测时,通过改进对比分支的SNN 模型得到未知样本和全部对比样本组的相似度,对相似度进行排序,相似度最高的对比样本组属于哪个类别,就把未知样本归为哪一类。
本文所提出的SNN模型不仅解决了小样本下特征提取不足问题,而且能够在一定程度上避免模型过拟合现象并减少偶然性误差。假设训练样本量为n且正负样本数量相同,由于该模型需要在训练集中选取三个同类样本构成对比样本组,所以针对每个训练样本可以有2C3n2组对比样本,从而能够对进行2nC3n2次训练。因此,通过优化SNN的分支结构,进一步扩大了模型的训练次数,等同于间接的扩充了训练样本数量,从而解决了小样本下产生的特征提取不足问题。其次,在训练过程中不仅对样本本身的特征进行学习,还对同类样本间的相似特性和非同类样本间的差异特征进行了学习,深度挖掘了样本间的关联信息,从而改善了小样本下模型过拟合的问题。此外,本文采用平均欧式距离拟合输入样本间的相似度差异,可以减少因对比样本中的异常值产生的影响,在一定程度上消除了因随机选取样本产生的偶然性误差,从而使分类器更加稳定。
1.2.2 基于改进SE模块的1D-CNN
SNN的子网络一般是CNN,文献[20]指出1D-CNN更适合处理序列数据,而网络中的流量数据正是序列类型数据。因此,本文选择了1D-CNN 作为SNN 的子网络,从流量数据中提取一维特征。
在传统卷积池化操作过程中,将特征图的各个通道视为同等重要,但事实上各个通道的重要性并不相同[14]。SE模块[21]是一种轻量级通道注意力机制,通过全局平均池化和两个全连接层来学习特征图中各个通道特征的作用程度,实现对通道特征的校正,增强有效特征的作用,抑制低效特征。然而,SE模块使用全局平均池化,并未考虑到特征图中各个特征值所包含信息的重要性并不相同。另外,利用两次全连接对通道特征进行映射,参数量较大,而大量的网络参数使得网络很容易陷入过拟合[16],导致网络性能下降。
为了解决小样本下模型过拟合的问题,有效提升1D-CNN 的网络性能。本文针对SE 模块存在的不足,对其进行了改进,并将其引入1D-CNN 中,从而提出了基于改进SE模块的1D-CNN,如图3所示。

图3 基于改进SE模块的1D-CNN模型Fig.3 1D-CNN model based on improved SE model
为了挖掘输入数据的复杂特征,本文设计了两个卷积层,利用窗口滑动对输入进行一维卷积操作提取抽象特征,每次卷积后生成1×W×C的特征图F。
本文分别对SE 模块的挤压和激励部分进行了改进,对卷积后产生通道特征进行选择,分配通道权重。
为了减少信息流失,提高池化效果。本文将SE 模块挤压阶段的全局平均池化替换为全局最大池化、全局平均池化和全局加权池化三种池化方法并行的方式。全局加权池化指的是为每张特征图的每个特征值添加一个可学习的SoftMax权重系数,然后加权求和。通过各个特征值分配权重系数,能够有效区分特征图中各个特征值所包含信息的重要性。公式如下:
其中,Poolavg、Poolmax、Poolwei分别代表全局最大池化、全局平均池化和全局加权池化,W代表一行特征值的数目,uc代表第c个特征图中的特征值,λ代表Soft-Max权重系数,θ代表学习参数。
为了减少参数量,防止模型过拟合。本文将激励阶段的两个全连接层替换为一维卷积操作,卷积核的大小设为通道数C。因为卷积层的参数是共享的,所以通过一维卷积来聚合通道特征,不会生成大量参数。
卷积后生成的特征图F经过池化得到1×1×C的特征图,再通过一维卷积操作提取C维特征,然后进行特征融合,最终由Sigmoid 函数激活生成最终的通道权重,公式如下:
其中,M代表通道权重,CNN代表一维卷积操作,σ代表Sigmoid函数。而后只需要将通道权重与特征图F按通道相乘,就可以实现通道特征加权,从而得到加权特征图。
经过两次卷积和通道加权操作后,将得到的加权特征图输入到池化层进行降采样,减少冗余信息,获取多个一维特征。最后在Flatten层进行特征一维化,从而将输入数据映射为最终的一维特征。
SE 模块能间接进行抽象特征的选择,选取具有泛化能力和区分能力的样本特征,有利于解决小样本下模型过拟合问题[21]。本文通过采用全局最大池化、全局平均池化和全局加权池化并行的池化方式,可以对通道特征图中每个位置赋予不同的可学习权重,使得SE 模块能够提取更具有区分能力的特征,并且减少了重要信息的流失。另外,使用一维卷积聚合通道特征,在保证结构轻量化的基础上大大减少了参数量,从而能够有效避免模型过拟合。本文将改进后的SE 模块融入到1D-CNN 中,提取中间特征图通道间的互信息,使得SNN的子网络能够提取到更具有泛化能力的样本特征,从而在一定程度上解决了小样本情况下产生的模型过拟合问题。
SNN的具体参数如表1所示。

表1 SNN的超参数表Table 1 Hyperparameter table for SNN
1.3 恶意流量检测方法
本文所提出的基于决策树-SNN的恶意流量检测方法主要包括两个部分,分别是构建二叉决策树结构模型和恶意流量检测,具体如下。
第一步:构建二叉决策树结构模型,步骤如下。
首先,确定类分离次序。具体步骤:(1)通过计算各类流量中所有数据的特征平均值来获得各类的类中心,并组成类中心集,每个类中心代表一类流量样本;(2)创建二叉决策树的根结点;(3)通过K-means 算法计算各个类中心间的欧式距离,同时将类中心集分为类间中心距离最远的两个子类;(4)创建左右孩子结点与两个子类相对应;(5)递归的将各个子类进行二分类,并创建其对应结点的左右孩子结点,直到所有结点中只有一个流量类别结束。
其次,构建各个分支结点上的SNN 模型。具体步骤:(1)根据分裂结点内的流量种类,准备相应类别的训练样本;(2)根据左右孩子结点的流量种类,将训练样本分为正负两类;(3)根据各个分裂结点处的正负样本训练SNN模型。
第二步:恶意流量检测,步骤如下。
输入待测样本,从根结点的SNN模型开始预测,如果能够确定样本类别则输出类别预测结果,否则根据结果进入下一个分裂结点的SNN 模型,重复这个过程直到确定流量类别。
1.4 算法复杂性分析
接下来,对本文提出的基于决策树-SNN 的恶意流量检测算法进行复杂性分析。当类别数量为K时,平均需要进行lbK次二分类过程。每次通过SNN进行二分类时,需要遍历全部对比样本组,以找到相似度最高的对比样本组。因此,该算法在整个过程所需要的时间复杂度为O(NlbK),空间复杂度为O( 1) ,其中,K表示样本的类别数量,N表示全部对比样本组的数量。
2 实验和结果分析
2.1 实验环境
本文所提出的算法基于tensorflow 框架进行实现,并在i5-8300H 的CPU,GTX1050Ti 的GPU 服务器上进行训练与验证,具体实验环境和配置如表2所示。

表2 环境与配置Table 2 Environment and configuration
2.2 数据集来源
采用公开数据集NSL-KDD数据集[22]作为本文模型的测试数据集,NSL-KDD 数据集是在KDD CUP99 数据集的基础上改进的一个数据集,删除了KDD CUP99数据集中的重复数据。因此,在该数据集上训练的分类模型不会偏向于训练集中的重复数据。NSL-KDD数据集中的数据含有41个特征,其中有38个数值特征和3个非数值特征。数据集中大体分为5种流量类型,分别用NOMAL、DOS、PROBE、R2L和U2R表示,其中NOMAL标识代表正常流量,其他4种标识分别代表不同的异常流量。数据集的详细信息如表3所示。
2.3 数据预处理
NSL-KDD数据集含有的3个非数值特征不利于执行K-means算法;其次,数据集中有41个特征,但特征间的尺度并不相同,在计算欧式距离时,其结果会受大尺度特征的影响较大,而小尺度特征的作用会被忽略掉,为了消除特征间尺度差异的影响,有必要对特征进行归一化处理。数据预处理的过程如下。
步骤1 特征数值化。将3个非数值特征用数字1、2和3代替,将5种流量标识用数字1、2、3、4和5代替。
步骤2 特征归一化。通过离差标准化操作将所有特征值归一化到[0,1]之间,公式如下:
其中,x代表当前值,xmin代表最小值,xmax代表最大值。
2.4 结果分析
为了检验本文方法在解决小样本下恶意流量检测问题上的有效性,下面从类分离顺序和检测性能两方面来进行分析。
2.4.1 类分离次序分析
通过K-means算法对类中心集重复的进行二分类,从而确定类分离次序。K-means 算法是根据样本间的距离进行分类的算法,可以将当前类中心集分为距离最远的两个子类。因此,只需要利用K-means算法对类中心集重复进行二分类过程,便可以将各个流量类别按照由远及近的类间中心距离次序进行分离。在本实验中,通过K-means 对类中心集{NOMAL,R2L,DOS,PROBE,U2R}进行第一次二分类的结果为{NOMAL}和{R2L,DOS,PROBE,U2R},说明在该类中心集中{NOMAL}和{R2L,DOS,PROBE,U2R}是类中心距离最远的两个子类。第二次分类,将{R2L,DOS,PROBE,U2R}分为{PROBE,DOS}和{R2L,U2R},第三次是分别对{PROBE,DOS}和{R2L,U2R}进行二分类,从而将PROBE 和DOS 分离,R2L 和U2R 分离。类分离次序如图4所示。

图4 类分离次序Fig.4 Class separation order
图4 展示了通过各类流量的类间中心距离所确定的类分离次序。 NORMAL 和其他四类的分离被放置离根结点最近的位置上,这是因为NOMAL和其他类别的类间中心距离最远,最容易区分开且分类的准确度最高。而PROBE和DOS的类间中心距离较近,分类准确率低,因而被放置在末尾用于分离。同理,R2L 和U2R的分离也位于末尾。这样构造的类分离顺序可以确保在整个分类过程中,错误率越高,离根结点越远,从而将对整体分类性能的影响降到最低,进一步保证多分类决策树的性能。
2.4.2 性能分析
为了验证本文方法在小样本下进行恶意流量检测的可行性,首先在小样本条件下对本文方法进行性能测试,其次针对每个改进方案进行了消融实验,最后将本文方法与其他小样本下的恶意流量检测方法进行了对比。由于本文方法主要是为了提高在小样本条件下的检测成功率,因此采用准确率、精确率和误报率作为评估指标。
小样本通常指样本容量小于或等于30,有时样本容量小于或等于50 时也可以称为小样本[15]。为了体现本文方法在小样本下的有效性,参照文献[13]所选的小样本训练集,在NSL-KDD 数据集中随机选取了130 个训练数据,其中NOMAL、DOS、PROBE、R2L 和U2R 分别有50、35、22、18 和5 个样本。此外,随机选取了200 个样本作为测试数据,具体如表4所示。

表4 实验数据Table 4 Experimental data
首先,使用所选的实验数据对本文方法进行了多次测试,以检验该方法在小样本下恶意流量检测问题上的有效性,实验结果如表5所示。
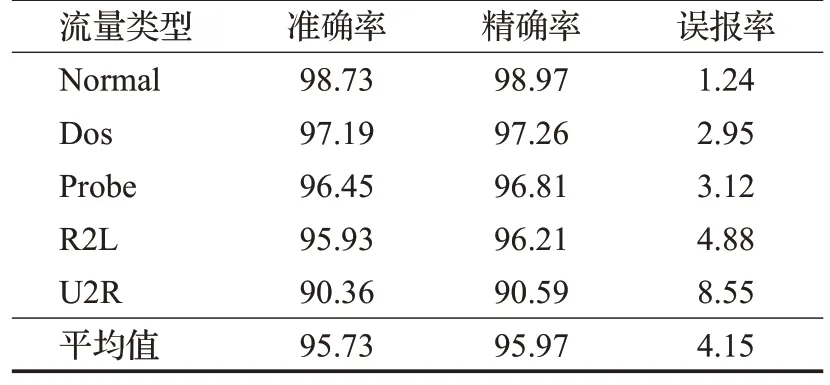
表5 本文方法性能测试Table 5 Performance test of this method单位:%
由表5可知,本文方法在小样本条件下普遍取得了优异的表现,在平均准确率和平均精确率上分别达到了95.73%和95.97%,平均误报率只有4.15%,证明了本文方法在小样本下的可行性。而PROBE、R2L 和U2R 三种小样本流量的准确率和精确率都达到了90%以上,尤其是PROBE 和R2L 这两种小样本流量,准确率和精确率都达到了95%以上,说明了本文方法在解决小样本下恶意流量检测问题上的有效性。
其次,为了探究各改进对模型的影响,设计了5 个消融实验,实验结果如表6 所示。在实验一中,去掉了二叉决策树,通过本文所提出的SNN 模型进行多分类流量检测,以验证二叉决策树在提升模型性能上的有效性;在实验二中,将本文方法中的改进对比分支的SNN替换为双分支并行的SNN,以验证对SNN 的改进能否提升模型的检测效果;在实验三中,去掉了改进的SE模块,以检测该模块对于提高模型性能的重要性;在实验四中,将本文所改进的SE 模块替换为传统SE 模块,以验证本文对SE 模块的改进是否有意义;实验五是对本文完整方法的测试。
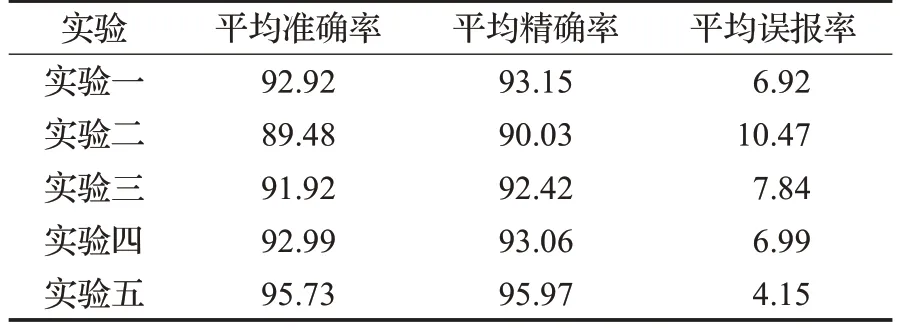
表6 消融实验结果Table 6 Ablation experimental results单位:%
由表6 可知,本文方法在准确率、精确率和误报率方面均优于其他对照方案,下面具体分析各个改进的有效性。
相较于实验一,本文方法的准确率和精确率分别提升了2.81 和2.82 个百分点,误报率降低了2.77 个百分点,这说明通过构建二叉决策树能够在一定程度上改善小样本下流量分类检测准确度低的问题。
相较于实验二,本文方法的准确率和精确率分别提升了6.25 和5.94 个百分点,误报率降低了6.32 个百分点,这说明改进对比分支的SNN 对于提升小样本下的流量检测性能有着较大的贡献。
相较于实验三,本文方法的准确率和精确率分别提升了3.81 和3.55 个百分点,误报率降低了3.69 个百分点,这说明改进的SE模块有效提升了模型的检测性能。
相较于实验四,本文方法的准确率和精确率分别提升了2.74和2.91个百分点,误报率降低了2.84个百分点,这说明相对于传统SE模块而言,改进的SE模块取得了较大的进步,更有利于提升小样本下的流量检测效果。
综上,本文的各个改进方法均使模型的检测性能有了不同程度的提高,体现了各个改进方案对于小样本下进行恶意流量检测的有效性。
另外,为了证明本文方法在小样本条件下进行恶意流量检测的性能,将本文方法与文献[12]以及文献[15]所提出的小样本下的恶意流量检测方法进行了性能对比分析,使用NSL-KDD数据集,实验结果如表7所示。

表7 NSL-KDD数据集上的方法比较Table 7 Comparison of methods on NSL-KDD datasets单位:%
由表7可知,相较于文献[12]中的方法,本文方法在准确率和精确率上分别提高了3.78和3.22个百分点,误报率降低了3.12个百分点。与文献[15]中的方法相比,本文方法只在误报率上提升了0.52个百分点,而在准确率和精确率上略微逊色,这是因为文献[15]中的方法需要在样本比较均衡的条件下才能达到上述的准确率和精确率,而现实网络环境中所收集到的样本数据很难做到恰好均衡。虽然该方法在准确率和精确率上表现较好,但为了达到样本平衡,需要先对训练样本进行样本不平衡处理,而本文方法不仅规避了这一问题,而且在准确率和精确率上也有着良好的表现。
此外,为了验证本文方法在不同数据集上的适用性,除了NSL-KDD 数据集外,另在UNSW_NB15 数据集[23]上对本文方法进行了测试,并进行了相应的分析,测试结果如表8所示。
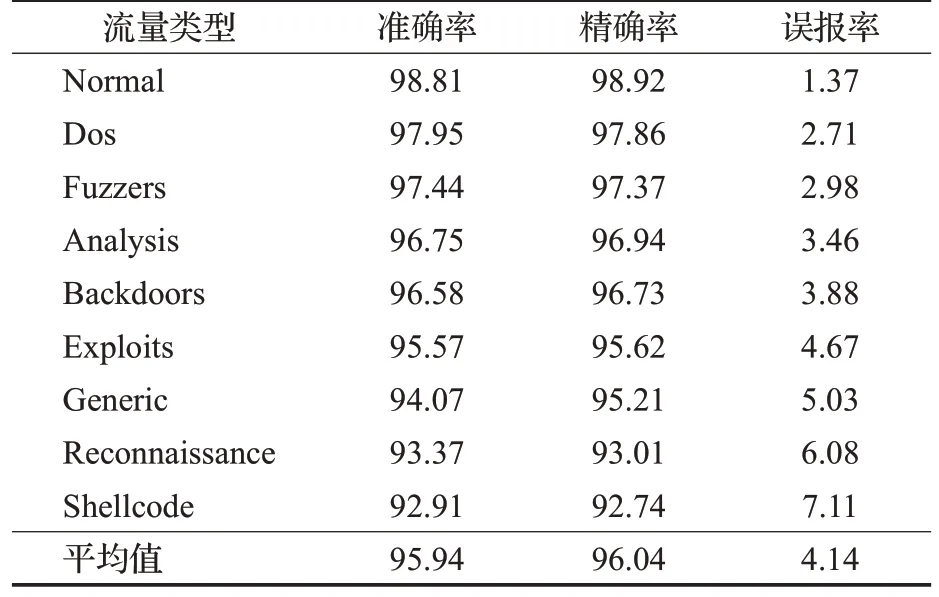
表8 在UNSW_NB15数据集上的性能测试Table 8 Performance test on UNSW_NB15 datasets单位:%
由表8可知,本文方法在UNSW_NB15数据集上普遍取得了良好的检测效果,各类流量的检测准确率和精确率都达到了92%以上。在平均准确率和平均精确率上分别达到了95.94%和96.04%,平均误报率只有4.14%,体现了本文方法不同数据集上的适用性,也再次证明了本文方法在解决小样本下恶意流量检测问题上的有效性。
与此同时,在UNSW_NB15 数据集上对文献[12]、文献[15]和本文中的方法进行了对比实验,实验结果如表9所示。
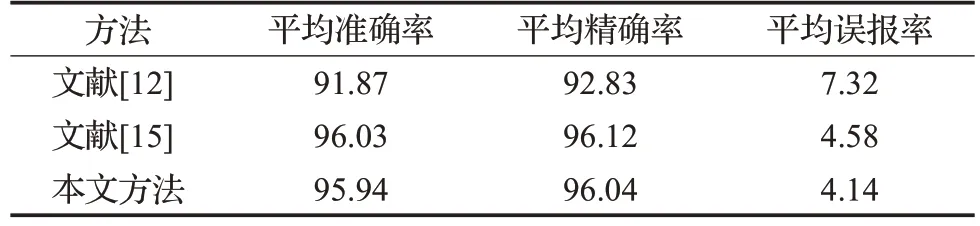
表9 UNSW_NB15数据集上的方法比较Table 9 Comparison of methods on UNSW_NB15 datasets单位:%
由表9 可知,在三个评估指标上,本文方法显著优于文献[12]中的方法,在准确率和精确率上分别提高了4.07 和3.21 个百分点,误报率上降低了3.18 个百分点。与文献[15]中的方法相比,两者在三个评估指标上相差不大,都保持在较高水平。综上可以得出,本文所提方案具有普遍适用性。
最后,为了进一步验证本文方法的有效性,使用NSL-KDD 数据集,在相同的实验环境下逐渐训练样本数量,观察文献[12]、文献[15]和本文所提出的方法在准确率、精确率和误报率上的变化情况,具体结果如图5~7所示。
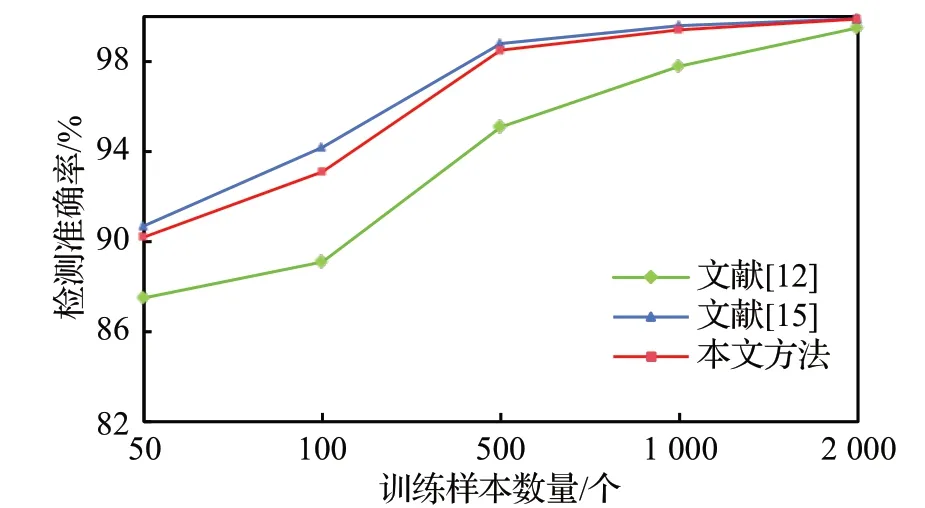
图5 检测准确率对比Fig.5 Detection accuracy comparison
图5所展示的是本文和文献[12]、文献[15]所提出的方法随训练样本数量增加,在准确率上的变化情况。由图可知,随着训练样本数量的增加,三种小样本检测方法的准确率都在提高。在整个过程中,本文方法的检测准确率略低于文献[15],但差距不大且最终趋于一致,而且明显高于文献[12]的方法。即使在训练样本数量仅有50的小样本下,本文方法仍能与文献[15]的方法一样,保持较高的准确率水平,充分体现了本文方法在流量检测准确率方面的优越性。
图6展示了随着训练样本数据的增加,三种方法检测精确率的变化情况。由图可知,随着训练样本数量的增加,三种小样本流量检测方法的精确率都在逐渐增加。在整个过程中,本文方法的检测精确率与文献[15]大致一样,且显著高于文献[12]中的方法,这突出了本文方法在精确率方面的有效性。
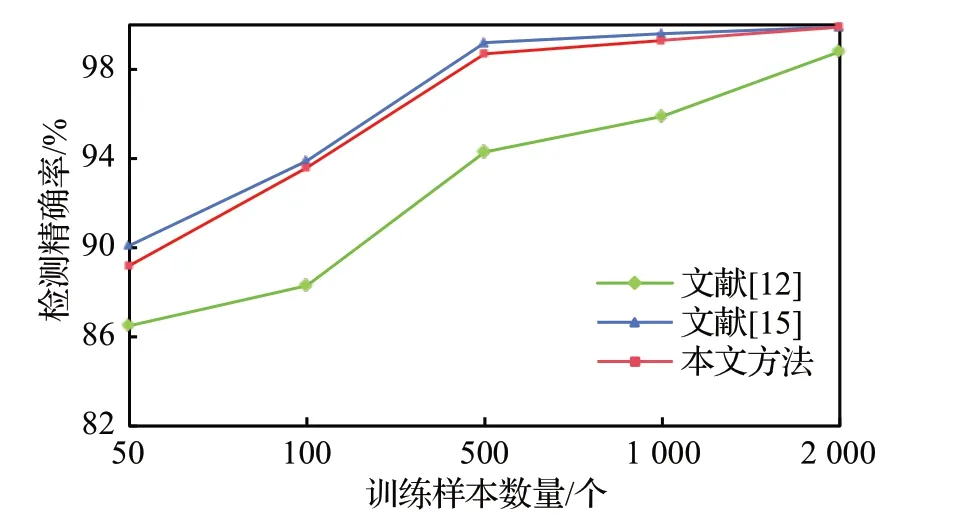
图6 检测精确率对比Fig.6 Detection precision comparison
图7展示了随着训练样本数据的增加,三种方法在误报率上的变化情况。由图可知,随着训练样本数量的增加,三种方法的误报率都在逐渐降低。在整个过程中,本文方法的误报率都低于其他两种方法,说明本文方法在流量检测误判方面要优于其他对照方法。
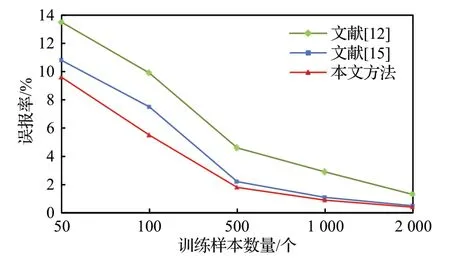
图7 误报率对比Fig.7 False positive rate comparison
3 结束语
本文介绍了一种小样本下基于改进决策树-SNN的恶意流量检测算法。首先确定各类流量的类间中心距离,建立基于SNN的二叉决策树模型,将多分类问题拆解为二分类问题,从而降低了小样本下进行多种流量分类检测的难度,提高检测准确度。其次,将SNN模型的对比分支中设计为三个基于改进SE模块的1D-CNN并行的结构,扩大了训练次数,解决了小样本下样本提取不足的问题。此外,本文设计了一种基于改进SE 模块的1D-CNN,先将SE 模块进行优化,减少模型参数,然后将其引入1D-CNN中,提取更具有泛化能力和区分能力的样本特征,在一定程度上解决了小样本下模型过拟合的问题。实验结果证明了该方法在小样本下的普遍适用性和高效性。在后续工作中,会采用考虑从剪枝的角度来简化本文所提出的算法模型。
猜你喜欢
玩具世界(2022年2期)2022-06-15
房地产导刊(2021年8期)2021-10-13
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
出版人(2020年4期)2020-11-14
中国交通信息化(2018年5期)2018-08-21
数学物理学报(2018年1期)2018-03-26
自动化博览(2014年12期)2014-02-28
电子设计工程(2014年12期)2014-02-27
