
文本对抗验证码的研究
2023-11-20 10:58李剑明
计算机工程与应用 2023年21期
李剑明,闫 巧
深圳大学 计算机与软件学院,广东 深圳 518052
验证码(completely automated public turing test to tell computers and humans apart,CAPTCHA)作为一种反向图灵测试,常用于区分计算机程序和真人,进而防止刷票、论坛灌水、恶意密码爆破等脚本攻击行为[1];人能够很轻易地解决验证码中的问题,例如文字识别、图像识别等,但这对机器来说却是一项艰巨的任务,而随着深度学习的发展,以卷积神经网络(convolutional neural networks,CNN)[2]为代表的深度学习模型在图像识别方面的能力已经超越了人类,传统的验证码能够被深度学习模型轻易识别、进而绕过[3],安全性大幅下降。
近几年来,许多研究人员致力于研究更加安全的验证码。例如,从验证码类别上进行扩展[4],诞生了短信验证码、语音验证码、拖动式验证码甚至是通过分析IP地址、鼠标移动轨迹、鼠标点击等数据进行判别的NoCAPTCHA reCAPTCHA[5]。但是,文本验证码仍然是主流的验证码类型,相比于新型验证码,这类验证码容易生成,并且人机交互性较好,能够在不过度影响用户体验的情况下,提升网站的安全性。但文本验证码的缺点也非常明显,即安全系数低,容易被破解,因此通常会通过添加噪点、干扰线,或者增加字符间连接距离、旋转角度等方式来提高模型识别的难度;虽然提高了安全系数,但相应的,这些额外的操作会导致用户的体验下降。
早在2014 年,Szegedy 等研究者[6]就发现存在一种微小的扰动,人类的视觉系统对其不敏感,但是神经网络却对其过于敏感而产生错误的分类结果,于是提出了对抗样本的概念。对抗样本可以在不被人察觉的情况下,严重误导模型的分类,它的存在揭露了现有深度神经网络的一些缺陷,表明表现良好的模型可能存在着巨大的安全隐患。例如,攻击者可以在脸部添加少量人类难以察觉的伪装,欺骗人脸识别系统。
在面对不断发展的深度学习时,传统的文本验证码已经显露出疲态,无法很好地进行防御,扭曲字符、添加噪点等方式虽然能降低被识别成功的概率,但同时也降低了用户的体验。将对抗样本生成技术应用在文本验证码上,利用对抗扰动极其微小的特性,在不被用户察觉的情况下,误导神经网络的识别,使传统的文本验证码安全性得以提升,重新适应当下的环境。
此外,文本验证码的生成频率非常高,如何加速对抗验证码的生成以匹配原始验证码的生成速度,该问题的解决能使文本对抗验证码更具应用价值。现提出的大部分对抗样本生成算法都是针对特定样本一对一生成特定扰动,无法实现对抗样本的实时生成,文本对抗验证码的应用也因此受阻。为此,需要针对验证码的这一特点,采用新的对抗样本生成算法。
本文的主要贡献包括以下两点:
(1)为增强传统文本验证码抵御神经网络模型识别的能力,将已有的10 种对抗样本生成算法应用到文本验证码上,比较其白盒识别率、黑盒识别率、扰动大小和平均耗时。
(2)在FUAP 算法的基础上尝试进行改进,得到I-FUAP算法,使得其在保证攻击效果不变的情况下,能更快地生成对抗扰动,更好地应用在生成频率较高的验证码上;通过调整算法的应用方案,实现实时的文本对抗验证码的生成。
1 对抗样本生成技术
对抗样本最早可以追溯到2014年Szegedy等人在其文章中提出的一个关于深度神经网络的特性,其发现存在一种对人类的视觉系统并不敏感的微小扰动,将它附加到原始图像后却能引起神经网络的过度敏感进而以高置信度产生错误的识别结果。于是提出了对抗样本的概念。
起初Szegedy 等人认为对抗样本的存在是因为神经网络的高度非线性和过拟合,导致模型并未学习到真正需要的泛化特征。然而,Goodfellow 等人[7]发现,即使将模型替换成线性模型族,只要它的输入有着足够的维度,那么就可以产生对抗样本。这一发现否定了对抗样本的存在是因为模型高度非线性的解释,同时Goodfellow等人还指出,对抗样本正是模型高度线性的结果,模型的线性让其更容易被训练,但缺乏防御对抗攻击的能力。基于对抗样本的线性解释,越来越多对抗样本生成算法被相继提出。
在生成对抗样本攻击模型的情形下,可以将攻击行为分为白盒攻击(white box attack)和黑盒攻击(black box attack),白盒攻击指攻击者可以获得目标模型的所有参数,包括架构、网络参数、梯度等信息,黑盒攻击指攻击者对目标模型了解甚少或者根本不清楚,他们无法对模型的内部进行探索。此外,按攻击目的可以分为目标攻击和非目标攻击,非目标攻击只需误导神经网络的输出跟原始分类标签不同即可,而目标攻击则是需要将输出误导为某一指定的分类。
白盒攻击方面,Goodfellow等人首先提出了快速梯度符号法(fast gradient sign method,FGSM),该算法能快速生成对抗扰动,但由于是单步攻击,成功率并不高,基于此衍生出了基础迭代方法(basic iterative method,BIM)[8]、投影梯度下降(projected gradient descent,PGD)[9]、多样化输入的梯度攻击(diverse input iterative fast gradient sign method,DI-2-FGSM)[10]等算法。除此之外,还有基于超平面分类的DeepFool[11]、基于优化的C&W攻击[12]和基于雅可比矩阵的显著图攻击[13]等白盒攻击算法。
黑盒攻击方面,零阶优化(zeroth order optimization,ZOO)[14]通过对目标模型梯度的估计来进行攻击;Dong 等人[15]提出的基于动量迭代的快速梯度符号法(momentum iterative fast gradient sign method,MI-FGSM)通过引入动量来使扰动的方向更平整,进而增强迁移性;Xiao 等人[16]提出以生成对抗网络为基础的AdvGAN攻击。
在最近几年提出的各种对抗样本生成算法中,有的是在算法迁移性上进行改进,例如Yang 等人[17]提出的RT-MI-FGSM通过引入图像亮度的随机变换消除对抗样本生成过程中的过拟合,提高了黑盒攻击能力;有的则致力于小样本的使用,例如王志勇等人[18]基于Wasserstein距离提出的新方法仅需少量样本即可定位ResNetXt网络的结构性弱点,生成对抗样本时对数据的需求大幅下降。为了解决对抗样本生成过程过于耗时的问题,许多研究者也在这方面进行了研究。Sarkar 等人[19]提出的UPSET 攻击方法能够生成通用对抗扰动,减少对抗样本的生成时间;Phan 等人[20]基于生成模型提出的CAG方法相比最新的迭代攻击(如PGD)可以加速至少500倍,实现了低成本、高速的对抗攻击。
2 文本对抗验证码的实现和性能比较
2.1 系统总体架构
为增强传统文本验证码抵御神经网络模型识别的能力,搭建实验系统,将基于梯度的7 种对抗攻击算法FGSM、BIM、PGD、MI-FGSM、DI-2-FGSM、TI-FGSM和SI-NI-FGSM,基于超平面分类的1 种对抗攻击算法DeepFool,基于DeepFool 的通用对抗扰动(UAP)生成算法以及FUAP算法实现,并应用于文本对抗验证码的生成,比较其白盒识别率、黑盒识别率、扰动大小和平均耗时。
实验系统通过Python的captcha库生成大量随机验证码作为数据集,然后使用PyTorch搭建ResNet-18卷积神经网络并进行训练,得到识别率较高的模型后,基于该模型复现已有的若干种对抗样本生成算法,从模型识别率、扰动大小等方面进行比较。同时搭建ResNet-IBN卷积神经网络进行训练,作为黑盒模型,比较对抗样本的白盒攻击效果和黑盒攻击效果。
图1说明实验系统总体架构。
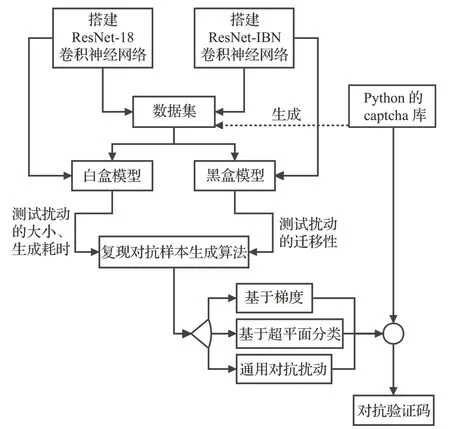
图1 实验系统总体架构Fig.1 Overall architecture of experimental system
2.1.1 实验数据集
Python的第三方库captcha能基于给定的字符集来创建文本验证码,可以自定义验证码的宽度、高度、字符个数、颜色和背景色等属性,其默认方式创建的验证码自带若干噪点和一条干扰线,与实际使用的文本验证码相似。在实验中,规定验证码图像的宽度为160 像素、高度为60 像素,包含4 个字符;为了避免相似字符间的混淆,规定验证码的候选字符集为“2345678abcdefhijkmnpqrstuvwxyzABCDEFGHJKLMNPQRTUVWXY”,长度为52,从中剔除了数字“019”、小写字母“glo”和大写字母“IOSZ”。生成的验证码如图2所示。

图2 基于候选字符集的随机文本验证码Fig.2 Random CAPTCHA based on candidate charset
通过这种方式得到的验证码可以作为训练神经网络的数据集;创建100 000 张文本验证码作为训练集、5 000张文本验证码作为测试集,就可以开始训练模型。
2.1.2 实验环境配置
训练模型所涉及到的具体环境配置如表1所示。

表1 实验平台与环境配置Table 1 Experiment platform and environment configuration
2.1.3 搭建卷积神经网络并训练
基于前面得到的数据集,拟搭建卷积神经网络并进行训练,得到文本验证码的分类器。这里选取ResNet网络模型是因为它通过引入残差模块很好地解决了深层网络的退化问题,网络性能优于传统的其他网络模型。
搭建的ResNet-18 卷积神经网络结构如图3 所示。该ResNet-18 卷积神经网络由输入层的一层卷积(7×7卷积核)、3层残差网络结构和最后的全连接层组成。3层残差网络结构中,每层包含两个残差模块(Basic-Block),每个残差模块由两个3×3 卷积核的卷积层组成,其中Layer2和Layer3在第一个BasicBlock之后都会进行一次下采样,而Layer1没有进行下采样。
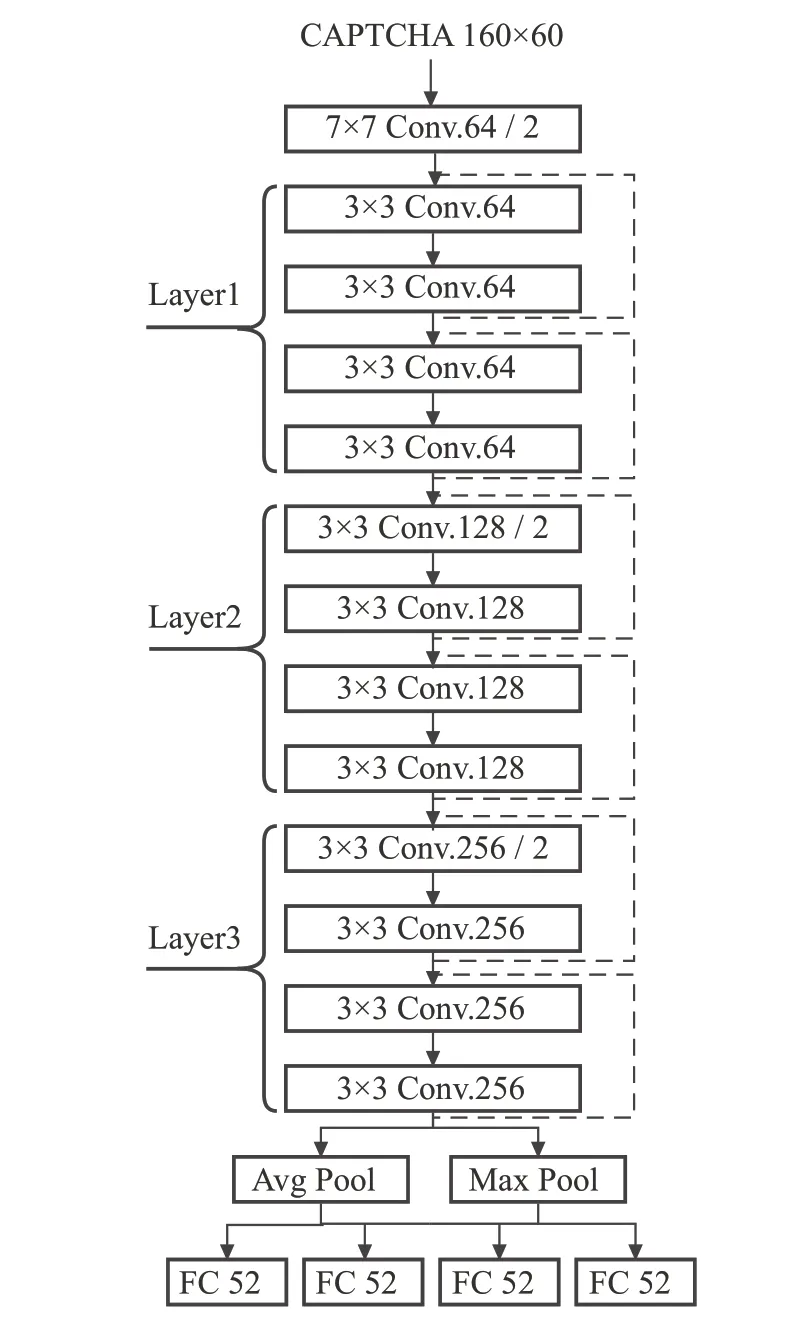
图3 适应生成的验证码数据集的ResNet-18网络结构Fig.3 ResNet-18 network structure adapted to generated CAPTCHA dataset
在训练该卷积神经网络时,以前面生成的100 000张验证码作为训练集,设置学习率为3E-4,进行训练;在600轮训练过后,筛选出其中在测试集上识别率最高的模型,最高的识别率达到94.9%。
同样的,搭建一个ResNet-IBN卷积神经网络,基于相同的数据集进行训练。在这里,选取ResNet-IBN 进行训练主要是为了后续对各种对抗样本生成算法的迁移性进行测试,将其作为黑盒模型,对比对抗样本在误导白盒模型ResNet-18 进行识别的同时,是否仍在另一个模型ResNet-IBN 上保持对抗性;可以选择其他的模型作为测试,只要保证与ResNet-18 结构不同即可。经过同样超参数的训练,ResNet-IBN最终取得86.8%的准确率。
ResNet-18 在3 层的残差网络结构中每层都包含两个残差模块(BasicBlock),相比之下ResNet-IBN 则将BasicBlock 替换为Bottleneck,Bottleneck 的详细结构如图4 所示,网络结构的其余部分与ResNet-18 相同。与之前相比,残差模块在第一个Bottleneck 都会进行一次下采样,并且新增了IBN结构。
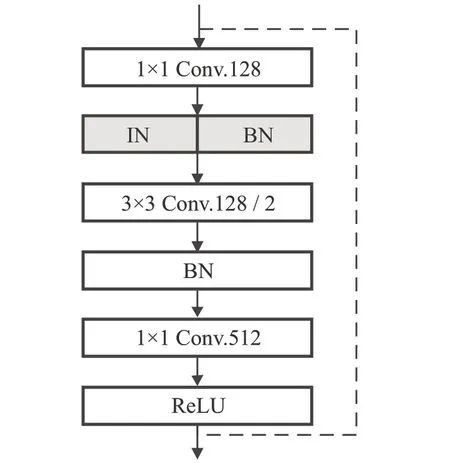
图4 ResNet-IBN残差模块组成单元Fig.4 ResNet-IBN residual module component units
2.2 对抗样本生成算法的实现和比较
2.2.1 算法实现与比较
通过对FGSM、BIM、PGD、MI-FGSM、DI-2-FGSM、TI-FGSM、SI-NI-FGSM 共7 种基于梯度攻击和Deep-Fool 共1 种基于超平面分类实现的对抗样本生成算法进行学习,将其应用到文本验证码上,生成对抗验证码。
首先生成规模为10 000的验证码数据集,基于该数据集去应用对抗样本生成算法,得到同样数量的对抗验证码,然后分别从平均时间开销、白盒识别率、黑盒识别率、扰动大小等方面去评估对抗样本生成算法的效果。白盒识别率数据的获取通过调用ResNet-18 模型去获得,黑盒识别率则是调用ResNet-IBN,扰动大小从两个方面进行评估:(1)L2范数;(2)L∞范数;L2范数表示的是图像上每个像素点的平均修改幅度,而L∞范数则表示单个像素点的最大修改幅度。
每种对抗样本生成算法得到的对抗验证码样例如图5所示,具体实验测试结果见表2。

表2 各种对抗样本生成算法的测试结果Table 2 Test results of various adversarial example generation algorithms

图5 各种对抗样本生成算法生成的对抗验证码样例Fig.5 Adversarial CAPTCHA sample generated by various adversarial example generation algorithms
通过统计各个算法执行的总时间,除以样本数量,得到每生成一张对抗验证码所需的平均耗时。可以看到,由于FGSM 是最基础的单步梯度攻击,因此在耗时上比其他算法要少一个数量级;而TI-FGSM 因为引入了多一步的卷积运算,耗时剧增。
在白盒识别率上,BIM 相比FGSM,通过迭代的方式计算得到更精确的扰动,进而对白盒模型ResNet-18的扰动效果更好,PGD 相比BIM 只添加了一层扰动的随机初始化,但实测效果并不好,可能是由于模型的原因。而后续的MI-FGSM、DI-2-FGSM、TI-FGSM 和SI-NI-FGSM 都是在对抗样本迁移性上面进行改进,所以在白盒识别率上有所牺牲。在黑盒识别率上,BIM由于更倾向于去拟合白盒模型的特征,故而降低了其迁移到其他模型上的能力,在迁移性方面BIM 不如FGSM。而在后面的改进中,TI-MI-FGSM以明显的优势优于其他算法,除此之外,相比FGSM,MI-FGSM、M-DI-2-FGSM和SI-NI-FGSM等都能增强对抗样本的迁移性。
实验中,将DeepFool 算法应用在对抗验证码时需要留意到,DeepFool在生成最小扰动的过程中需要遍历其他所有的分类。本实验采用的验证码包含4个字符,候选的字符集长度为52,倘若将这4个字符视为一个整体,那么一张验证码可以有524=7 311 616 种可能,也就是说DeepFool算法需要计算原始样本到其余7 311 616-1=7 311 615 种分类的距离,再从其中选择一个最小的,而这只是一张文本验证码在一次迭代过程中的计算量,很显然是不合理的。
为此将这4个字符视为是单独的个体,在遍历其中一个字符的时候,其余字符不变。这种改变使得单个文本验证码在一次迭代过程中只需计算到其余52×4-1=207 种分类的距离,计算量大大减少。这样做的理由是,假设计算得到的扰动r′能同时改变至少两个字符的分类结果,那么一定存在扰动r(r<r′,且r是r′的部分取值)只改变其中一个字符。由于DeepFool 计算的是最小扰动,那么r′不是最终的计算结果,因为还有比它更小的r。基于此,只需遍历改变了一个字符的207种分类即可,无需遍历完整的7 311 615 种其余分类。这一操作大大减少了将DeepFool应用到文本验证码上的计算开销。
DeepFool 由于需要遍历计算其余分类的超平面距离,所以耗时相对久;白盒攻击效果较强,白盒模型的识别率只有6.81%。由于DeepFool是白盒攻击算法,因此黑盒攻击效果一般,但DeepFool生成的是最小扰动,从数据上可以看到,相比于其他基于梯度攻击的对抗样本生成算法,DeepFool 生成扰动的L2 范数只有其1/4,而L∞范数较大,表明DeepFool 可能在个别像素点上进行较大幅度的修改,但总体不会造成视觉上的影响。
综合以上横向比较的结果可以得知,FGSM由于是单步攻击,生成对抗样本的速度最快;BIM 通过迭代的方式去生成更精确的对抗图像,白盒攻击效果最好;而TI-MI-FGSM 通过结合平移不变性(translation invariant)和引入动量稳定方向,得到最好的黑盒攻击效果。DeepFool 由于原理的不同,计算的是最小扰动的近似,所以扰动大小最小。
2.2.2 通用对抗扰动
对抗扰动是神经网络模型的缺陷而不是数据集的缺陷,为此Moosavi-Dezfooli等人通过研究,提出了通用对抗扰动(universal adversarial perturbation,UAP)[21]的概念。传统的对抗样本生成算法都是针对单个输入产生对应的对抗样本,原始样本和对抗样本之间是一对一关系,但UAP的提出表明,可以针对一批原始样本生成一个通用对抗扰动,该通用对抗扰动作用在其中的任意一个原始样本,都能令其产生对抗攻击效果;并且该通用对抗扰动能作用在其他数据集上。
通用对抗扰动可以作用在验证码上,以便更快速地生成对抗验证码。测试表明,无论是基于梯度还是基于超平面分类,所涉及到的对抗样本生成算法都是针对一张验证码图像,生成对应的扰动,该扰动无法迁移到其他图像上,具有唯一性。从前面的分析可以发现,哪怕是耗时最少的FGSM 也达到了每张0.026 4 s,在实际的验证码应用场景中,验证码的请求频率较高,无法做到一边生成验证码、紧接着立刻生成对应的对抗验证码,生成验证码与生成对抗验证码的耗时相差过大。
而计算出验证码的通用对抗扰动后,只需将通用对抗扰动与原始的验证码进行一次加法运算,即可得到对抗验证码,极大地减少了所需的耗时,并且能保持较高的扰动攻击效果。具体将UAP应用在验证码的方案见图6。

图6 通用对抗扰动应用在验证码上的方案Fig.6 Universal adversarial perturbations scheme applied to CAPTCHA
方案分为三层:第一层是正常的验证码生成接口;第二层则是基于通用对抗扰动对验证码进行扰动的添加,这个过程只是一次简单的叠加,耗时较少,并不影响验证码生成的正常速度;第三层则是相对独立的通用对抗扰动的生成,通过生成一批新的验证码作为数据集,调用卷积神经网络模型生成新的通用对抗扰动,并进行更新。通过对UAP 的定期更新,能进一步增强对抗验证码的安全性。
DeepFool产生的是最小扰动,在计算到其他分类的距离后,只会选择其中距离最小的分类去计算对应的扰动。通用对抗扰动的生成算法是基于DeepFool 的,其在遍历所有样本点的时候直接对获得的最小扰动进行累加、裁剪,并没有考虑到扰动向量方向的问题,导致生成通用对抗扰动的速度非常缓慢,扰动成功率长时间处于起伏状态。为此,Dai 等人[22]提出了快速通用对抗扰动(fast-UAP,FUAP)算法,通过修改扰动向量的选择标准以加快生成速度;具体优化做法是:引入余弦相似度,在每次迭代过程中不选择最小的,而是选择与当前通用对抗扰动方向最相似的扰动进行累加、裁剪(公式(1)),使得两个扰动的聚合幅度被最大化,通用对抗扰动始终朝着某一方向稳定进行更新,能更快地达到指定的扰动成功率。
是当前通用对抗扰动,r是本次迭代计算得到的扰动,为使r与有最相似的方向,计算两者的余弦相似度,计算得到的结果越大,则表明越相似。
实验表明,原通用对抗扰动生成算法的耗时过长,扰动成功率始终处于大幅度波动的状态,原因就是不同方向扰动的相互叠加“抵消”,使得扰动一直难以有较大的变化。通过引入余弦相似度,更改扰动的更新方式,能够快速生成UAP。
3 快速通用对抗扰动(FUAP)的改进
3.1 FUAP的不稳定性
由于引入了余弦相似度,FUAP 在每次迭代的过程中会选择与当前通用对抗扰动方向最相似的扰动进行累加,使得通用对抗扰动的生成更稳定,但是观察到,通用对抗扰动最开始是被初始化为0的,随后在计算第一张文本验证码的第一个分类时,由于这时的通用对抗扰动为0,无法计算出余弦值,所以在算法中采取的操作是直接将其对应的扰动赋值给通用对抗扰动。而在FUAP中,通用对抗扰动可以视为是始终朝某一方向进行稳定更新,也就是说,这一“方向”直接由第一张文本验证码第一个分类对应的扰动决定。
为了更好地计算出通用对抗扰动,在每轮迭代开始之前都会对所有的输入图像进行顺序打乱(Shuffle),通过实验发现,在不同随机数种子的情况下,FUAP 算法在生成时间上表现出较大的不稳定性。实验首先生成规模为1 000 的验证码数据集,然后基于该数据集多次运行FUAP算法,其中每次运行前设置不同的随机数种子,从0到9,其余所有超参数均保持不变。测试的结果见表3。

表3 通过仅修改随机数种子测试FUAPTable 3 Testing FUAP by modifying only random seeds
从表3 中可以看到,在仅修改随机数种子、保持其他超参数不变的情况下,基于相同数据集,最快只需493.54 s 就完成了通用对抗扰动的生成,而最慢的却达到了1 214.42 s,相差近2.46倍,并且后者比前者多进行了一轮迭代的计算,原因是后者在首轮迭代中未达到预先设置的扰动成功率0.8。耗时更多生成的通用对抗扰动并不意味着效果更好,从结果来看,随机数种子设置为3 时,耗时最短,但生成的通用对抗扰动白盒攻击效果是最好的、扰动大小也是最小的。
产生这种不稳定性的原因主要是:随机数种子不同,首张被计算的验证码图像就不同,而通过前面分析可知,通用对抗扰动更新的方向就取决于首张验证码的首个分类对应的扰动,在某些方向上通用对抗扰动的生成速度较快,但是在某些方向上则较慢;生成耗时与扰动效果并不呈现正相关的关系,部分情况下,耗时较短生成的通用对抗扰动得到的白盒攻击效果更好。从中可以看出通用对抗扰动被初始化时取值的重要性,影响着FUAP的性能。
3.2 基于已有的通用对抗扰动进行初始化
基于已有的快速通用对抗扰动(FUAP)算法,本文提出初始化的快速通用扰动(initialized fast universal adversarial perturbation,I-FUAP)算法。
通用对抗扰动与输入图像无关,它揭示的是卷积神经网络模型存在的缺陷。由于FUAP 算法更改了更新通用对抗扰动的选择标准,所以当通用对抗扰动被初始化后,后续都是选择与当前通用对抗扰动最相似的最小扰动进行更新;而前面的测试表明,不同方向初始化的通用对抗扰动,在生成时间方面差异较大,表现出不稳定性。为此,解决通用对抗扰动的初始化问题能加速FUAP算法的执行。
目前FUAP算法将通用对抗扰动初始化为0是不合理的,I-FUAP 基于已生成的通用对抗扰动来初始化FUAP 算法,使FUAP 在执行之初便确定一个较为稳定的方向,然后再基于现在的数据集去更新通用对抗扰动。I-FUAP算法具体流程如下:
算法1 I-FUAP

vi(i∈[0,9])中的任意一个通用对抗扰动都能应用在原始验证码图像上使其产生对抗攻击效果,但一旦对其进行比较微小的修改,就有可能破坏这种对抗效果;在本算法中,计算这10个通用对抗扰动的平均值后,平均通用对抗扰动不再具有令原始图像产生对抗攻击的效果。这一点可以通过实验来证明,计算出平均通用对抗扰动后,直接应用到原始数据集上得到生成数据集,而经测试,无论是白盒模型还是黑盒模型,都对生成数据集保持较高的正确识别率,表明平均通用对抗扰动不再具有对抗攻击效果。平均通用对抗扰动的唯一作用就是初始化,令通用对抗扰动的生成算法在一开始便确定一个较为稳定的更新方向,基于这个方向去生成通用对抗扰动,能够在更短的时间内结束算法。
3.3 FUAP与I-FUAP对比测试
I-FUAP 对FUAP 改进在通用对抗扰动被初始化时的赋值上,为了横向对比两种算法,首先生成10组规模为1 000 的随机文本验证码,每组都通过FUAP 算法生成通用对抗扰动,得到v0、v1到v9;然后进行对比测试。在每组对比测试中,都重新生成规模为1 000 的随机文本验证码,先通过FUAP基于该数据集生成通用对抗扰动,再通过I-FUAP 基于相同的数据集生成通用对抗扰动,I-FUAP将使用v0、v1到v9的平均值作为其通用对抗扰动的初始化。
共进行了10组对比测试,测试结果见表4。

表4 FUAP与I-FUAP对比测试Table 4 FUAP and I-FUAP comparison test
I-FUAP 对FUAP 的优化体现在生成通用对抗扰动的时间上面,基于相同的数据集,I-FUAP 相比FUAP 能更快地生成通用对抗扰动,并且生成的扰动在白盒识别率、黑盒识别率和扰动大小上并没有显著的差别。实验表明,I-FUAP较FUAP能将生成通用对抗扰动的耗时减少约30.22%。
I-FUAP 能够进一步加快通用对抗扰动的生成,它基于已存在的通用对抗扰动在算法开始之初进行初始化,确定了一个较为稳定的扰动更新方向,进而使得算法的总耗时减少。除了算法的时间开销外,由于扰动更新方向的改变,I-FUAP 在扰动成功率、白盒识别率、黑盒识别率和扰动大小上都与FUAP不尽相同,白盒识别率下降了约8.32%、黑盒识别率上升了约0.57%、扰动大小增大了0.73%。考虑到扰动在生成过程中具有的一定随机性,其表现出来的整体差异性较小,生成的通用对抗扰动都达到了与之前相当的攻击水平。而在视觉效果上,无论是FUAP 和I-FUAP 都保证了不会对肉眼产生太大的影响,图7 是使用ResNet-18 模型对三种验证码进行测试的样例结果。
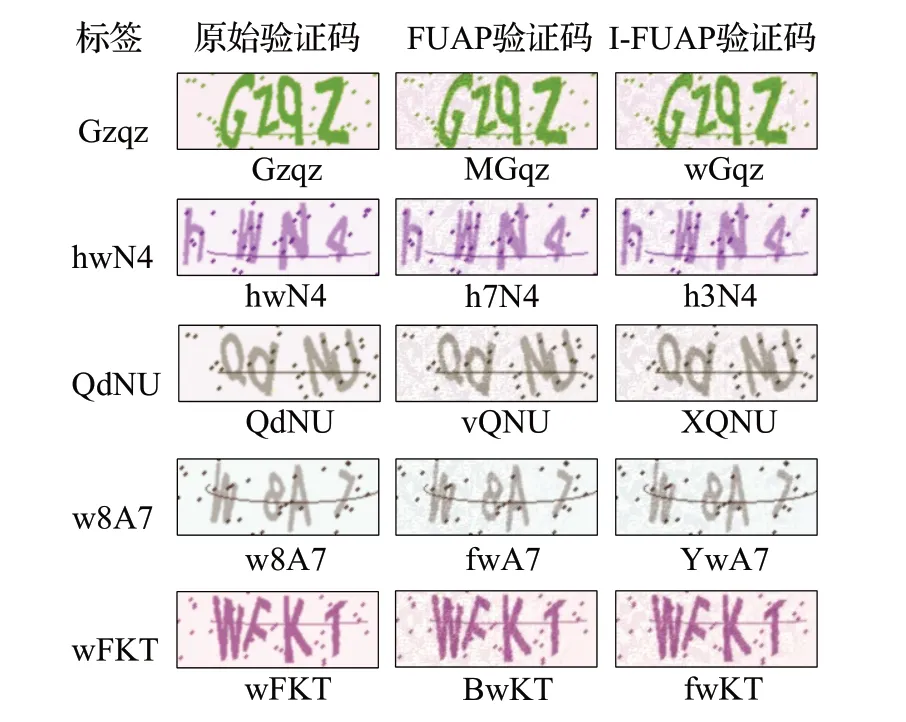
图7 原始验证码、FUAP和I-FUAP对比结果Fig.7 Comparison results of original CATPTCHA,FUAP and I-FUAP
3.4 I-FUAP的实际分析
将基于DeepFool 生成的通用对抗扰动应用在文本验证码的生成上,可以实现对抗验证码的实时生成。FUAP通过修改扰动选择的标准,稳定了扰动更新的方向,能够更快生成通用对抗扰动;而I-FUAP 在其基础上,设置通用对抗扰动的初始值,使得算法在开始之初便确立一个比较好的更新方向,进一步缩减了通用对抗扰动的生成耗时。
与其他算法相比,Sarkar等人提出的UPSET攻击方法虽然也能生成通用对抗扰动,但UPSET是定向攻击,在算法执行过程中会依次生成N个通用对抗扰动(N是类别个数),每个扰动对应一种定向攻击的结果,而在验证码方面,只需误导机器识别错误即可,不需要误导机器识别为特定的结果,在这点上,I-FUAP作为非定向攻击算法更有优势,计算开销更小;Phan 等人提出的CAG 相比最新的迭代攻击(如PGD)可以加速至少500倍,但这种加速还不足以适应文本验证码的生成频率,相比之下I-FUAP对原始验证码直接叠加通用对抗扰动的做法是几乎不产生额外耗时的,在速度方面更胜一筹,但CAG通过引入随机丢弃提高了扰动的迁移性,这是I-FUAP所没有的。
总的来说,基于DeepFool的FUAP算法生成的通用对抗扰动使得对抗验证码的实时生成得以实现,而I-FUAP 通过稳定扰动的更新方向,能够更快生成通用对抗扰动,提高了通用对抗扰动的更新频率,使得应用方案更有价值,但在黑盒攻击、扰动大小等其他方面I-FUAP 仍然有改进的空间,这也是未来可以作为研究的方向之一。
4 总结与展望
随着深度学习在图像识别领域的飞速发展,传统的文本验证码无法胜任区分计算机程序和真人的反向图灵任务,而对抗样本的发展为解决该问题提供了新的思路。本文将基于梯度的7 种对抗样本生成算法FGSM、BIM、PGD、MI-FGSM、DI-2-FGSM、TI-FGSM 和SI-NIFGSM,基于超平面分类的1种对抗攻击算法DeepFool,基于DeepFool 的通用对抗扰动(UAP)生成算法以及FUAP算法应用于文本验证码的生成,比较了这些方法应用到对抗验证码的实际效果。
分析FUAP算法,发现其通用对抗扰动的初始化存在不合理性,通过设置仅修改随机数种子的变量控制实验,揭示了FUAP的不稳定性。将已有的通用对抗扰动用作FUAP的初始化,提出了I-FUAP算法,通过对比实验表明,I-FUAP 较FUAP 能更快生成通用对抗扰动,平均耗时减少约30.22%。
本文针对文本验证码以及对抗样本生成相关的研究所提出的方案仍存在一定的不足。例如,通用对抗扰动的生成是基于DeepFool 这一白盒攻击算法的,所以得到的扰动对黑盒模型的攻击效果较差,难以迁移到其他攻击模型上,使用受限。对抗样本攻击算法的迁移性一直是对抗攻击领域的研究热点,许多优化算法的提出都是为了提高对抗样本的黑盒攻击能力,后续可以在增强通用对抗扰动的迁移性上做进一步的研究,引入模型集成等相关技术。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
网络安全与数据管理(2022年3期)2022-05-23
通信学报(2021年2期)2021-03-09
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
通信世界(2018年29期)2018-11-21
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
电测与仪表(2014年3期)2014-04-04
