
基于PSO-SVR 的重型柴油车NOx 排放预测
2023-11-30 06:30王志红董梦龙张远军
内燃机学报 2023年6期
王志红,董梦龙,张远军,胡 杰
(1. 武汉理工大学 汽车工程学院,湖北 武汉 430070;2. 襄阳达安汽车检测中心有限公司,湖北 襄阳 441004)
随着全国经济的增长,我国汽车保有量也有所增加.汽车是污染物排放的主要来源,其排放的CO、HC、NOx和PM 占比超过90%,其中重型柴油车NOx排放占汽车NOx排放总量的83.5%.因此,加强对重型柴油车排放的监管变得尤为重要.目前,车载NOx传感器主要为电化学式,均存在NH3交叉敏感问题,一旦出现NH3泄漏的情况,下游NOx传感器的测量结果将高于实际值[1],因而建立整车NOx排放预测模型来进行辅助监管成为排放监管重要的研究方向.当前大部分NOx排放预测模型研究都是针对柴油机来进行的,Wang 等[2]利用互信息(MI)和back propagation(BP)神经网络建立了柴油机NOx排放预测模型,与静态Map 预测相比,该方法建立的预测模型使得平均绝对误差(MAD)和均方根误差(RMSE)均降低了15%左右.胡杰等[3]建立了基于神经网络偏最小二乘法(NNPLS)的柴油机NOx排放预测模型,用于选择性催化还原(SCR)技术的控制,该模型的训练均方根误差和测试均方根误差分别为30×10-6和62×10-6.Samet 等[4]针对某款混合燃料柴油机,以发动机负荷、发动机转速和燃油混合比为输入,采用人工神经网络(ANN)方法建立了发动机性能和排放预测模型,该模型的回归系数在0.964 0~0.987 8 之间.
以上排放预测模型主要是基于柴油机的台架试验数据建立的,目前对于整车的排放预测模型大多处于宏观预测阶段.Wu 等[5]基于Mobile-China 模型研究了北京市15 a 内的车辆排放,分析了机动车排放受减排措施的影响.宏观排放模型虽然可以评估某个时间段内一定范围区域所经过车辆的总体排放情况,但无法对某一车辆排放进行计算.
基于此,笔者将参照柴油机排放建模经验建立重型柴油车整车排放预测模型.与柴油机排放预测模型不同,实际道路行驶的车辆NOx排放会受到排气后处理系统的影响,在建模时要将排气后处理系统的工作参数考虑在内.另外,考虑到实际道路试验成本较高,每辆车测得的数据量有限,笔者将基于车载便携式排放测试设备(PEMS)测得的实际道路试验数据,以及车载诊断系统(OBD)读取到的车辆工况数据,采用适合小样本数据建模的机器学习算法—支持向量回归(SVR)算法建立重型柴油车NOx排放预测模型.
1 试验及数据
1.1 道路试验
试验在湖北省襄阳市周边进行,试验设备采用日本Horiba 公司的OBS-ONE.图1 为PEMS 安装示意,PN 模块用于测量颗粒物数量,GA 模块用于测量CO、CO2和NOx气体浓度,GPS 用于测量车辆的经纬度和海拔.采用外部电源对PEMS 进行供电,试验车辆为某N2类柴油车,车辆参数如表1 所示,试验用油为满足车用柴油(国Ⅵ)标准的0 号柴油(GB 19147—2016).笔者根据《重型汽车污染物排放限值及测量方法(中国第六阶段)》[6]中附录K“实际道路行驶测量方法(PEMS)”的规定,进行了实际道路测试.N2类车辆(城市车辆除外)测试时运行道路组成依次为:45%的市区路、25%的市郊路和30%的高速路,试验运行道路占比及平均速度见表2.

表1 测试车辆参数Tab.1 Vehicle specifications

表2 路况占比及平均速度Tab.2 Proportion of road conditions and average speed

图1 PEMS安装示意Fig.1 Schematic of installation of PEMS
1.2 数据获取及预处理
在进行实际道路排放测试时,测试设备由多种系统组成,由于各系统之间的响应时间不同,因而在试验结束后对试验过程中记录的数据进行对齐,其中,一类数据之间的时间对齐使用CO2体积分数和颗粒物数量(PN)浓度进行对齐;一类数据与二类数据的时间对齐使用CO2体积分数和排气质量流量进行对齐;一、二类数据(PEMS)与三类数据(发动机数据)的时间对齐使用CO2体积分数和发动机燃油消耗量进行对齐,或使用GPS 车速和ECU 车速进行对齐.试验数据可分为3 类[6],一类数据为分析仪数据,即NOx、CO、CO2、PN、HC、THC(对于柴油车是可选项)和PM 浓度(可选项);二类数据为排气流量计数据,即排气质量流量和排气温度;三类数据为发动机数据,即转矩、转速、温度和燃油消耗率,来自ECU 的车速.
两参数在进行对齐时,需要计算参数之间的相关性系数,以其中一个参数为基准,平移另外一个参数,当参数之间的相关性系数最大时,表示两个参数已经对齐.相关性系数R可表示为
式中:xi、yi为参与相关性计算的两组数据;分别为xi、yi的平均值;n为剔除无效数据前数据组数.
图2 为试验的一、二类数据与三类数据对齐过程,为了直观展示,只取前400 组数据进行可视化.可知,对齐后两参数之间的变化趋势更加相近.图3 为相关性系数与平移时间的关系.本次试验将燃油消耗率曲线数据平移3 s 后相关性系数达到最大值.

图2 对齐前、后数据对比Fig.2 Comparison of data before and after alignment
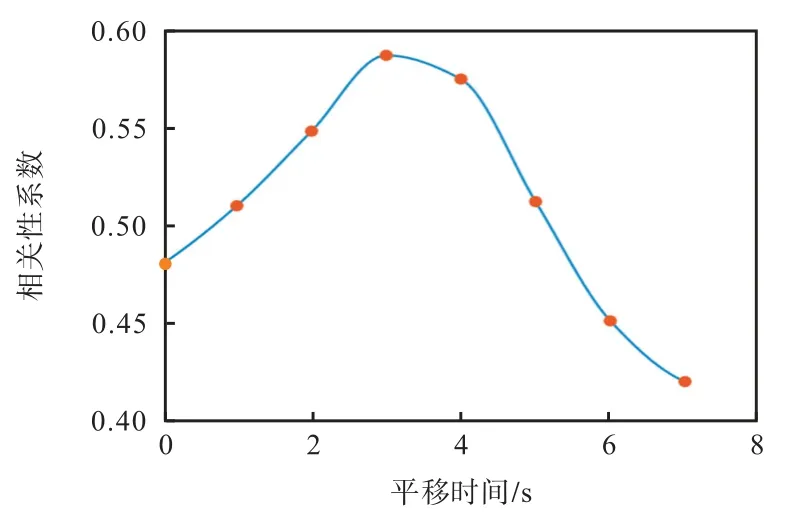
图3 相关性系数与平移时间关系Fig.3 Relationship between correlation coefficient and translation time
国Ⅵ排放法规在进行实际道路排放结果判定时,将设备检查以及零点漂移核查期间的数据、海拔超过2 400 m 或环境温度低于-7 ℃的数据及冷起动期间的数据称为无效数据,在进行排放计算时无效数据将会被剔除[7].
除法规未对无效数据进行限制以外,无效数据点的NOx排放通常变化较为剧烈,引入无效数据进行预测可能会影响模型的预测效果,因而剔除无效数据.
剔除无效数据后,剩余9 300 组数据,每组数据记录了16 个参数,其中包括需要预测的参数(NOx排放)、需要输入的OBD 参数(冷却液温度、发动机转速等)以及排气环境温度、湿度和排气温度,部分试验数据见表3.表3 中数据为初步筛选的参数,其中的一些参数可能对NOx实际排放的影响并不强,直接使用初步筛选的参数作为输入可能会引入大量噪声数据,影响预测结果的准确性.因而笔者通过灰色关联分析法进行输入参数的筛选,灰色关联分析法的原理介绍和计算方法参见文献[8].
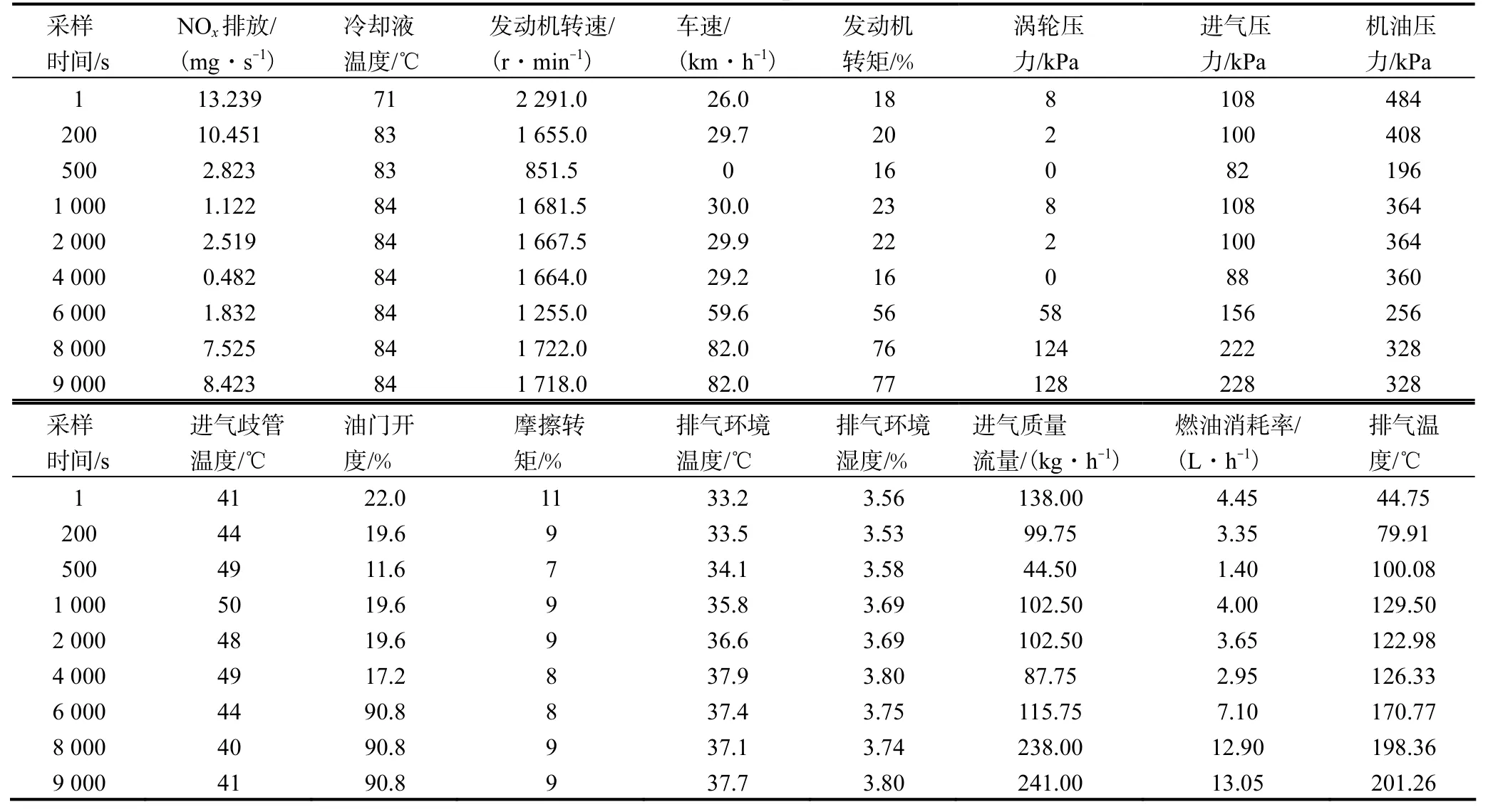
表3 部分PEMS试验数据Tab.3 Test data of partial PEMS
图4 为各影响因素与NOx排放之间的关联度.可知,冷却液温度、发动机转速和车速等8 个影响因素的关联度在0.90 以上(蓝色条柱对应的参数).另外,因为所有参数的关联度均超过了0.70,且输入参数与NOx排放之间并非是线性映射关系,所以简单通过取关联度较大的参数作为模型输入并不严谨.为此,将确定关联度大于0.90 的参数作为模型输入后,采取以下方法确定其余输入参数:首先将模型的3 个超参数分别设置为固定值(C=35,ε=0.1,g=0.5),依次筛选关联度在0.90 以下的参数,若删除某参数后使得模型的预测精度降低,则保留该参数作为模型输入.反之,不将该参数作为模型输入.经过计算,当保留进气压力、燃油消耗率和排气温度3个参数(红色条柱对应的参数)时,模型的决定系数R2达到最大值(0.813 8).最终确定11 个参数作为模型输入.
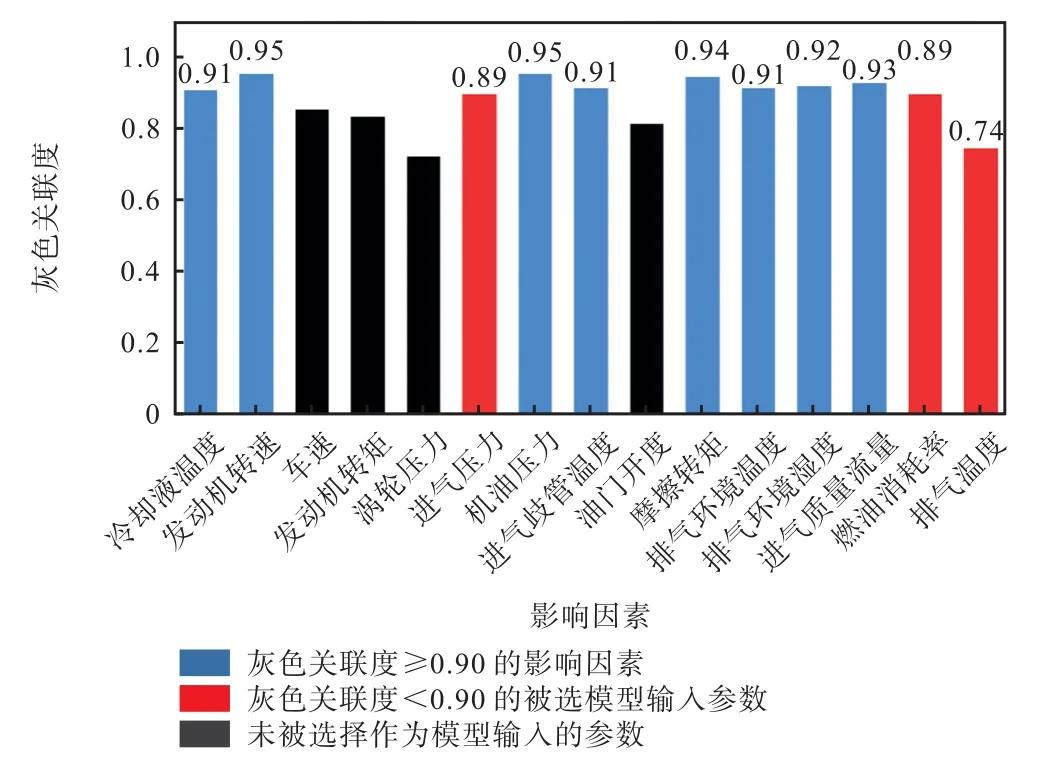
图4 灰色关联矩阵Fig.4 Gray correlation matrix
图5 为筛选出的11 个输入参数之间的相关性矩阵.可知,部分输入参数之间存在较强的线性依赖关系,如发动机转速与摩擦转矩、机油压力之间相关性系数分别达到了0.93、0.92,同时,进气压力与燃油消耗率之间的相关性系数也达到了0.96,表明输入参数之间可能包含冗余信息,参数中的冗余信息会影响模型的计算速度,因而笔者进行输入数据的降维,降低输入参数信息冗余度.

图5 输入参数的相关性矩阵Fig.5 Correlation matrix of input parameters
为了消除量纲对建模造成的不利影响,对数据进行标准化.实际道路试验的测试结果易受路况和驾驶习惯的影响,从而导致试验数据中存在明显的极大、极小值,将参数映射到[0,1]区间的归一化方法极易受到异常值的影响,因而进行数据标准化,标准化后的数据服从均值为0,方差为1.
式中:x ′ 为标准化后的数据;x 为原始数据;μ为原始数据的平均值;σ为原始数据的标准差.
采用主成分分析法(PCA)对数据进行降维,该方法可在降低模型输入维度的情况下尽可能地保留输入参数的原始信息.计算变量间的相关性系数矩阵及其特征值和特征向量,将特征值按照由大到小的顺序排列,并计算每个特征值的方差贡献率,方差贡献率代表该特征值对应的主成分所包含的原始特征信息比例.变量间的相关性系数矩阵为
式中:m为主成分分析的特征参数个数;n1为评价对象个数;rij为第i 个指标与第j个指标的相关系数.
每个特征值的方差贡献率为
累计方差贡献率[9]为
式中:λi为降序排列后的第i个特征值;ϕi为第i 个特征值的方差贡献率;λk为降序排列后的第k 个特征值;ϕ为前p 个特征值的累计方差贡献率.
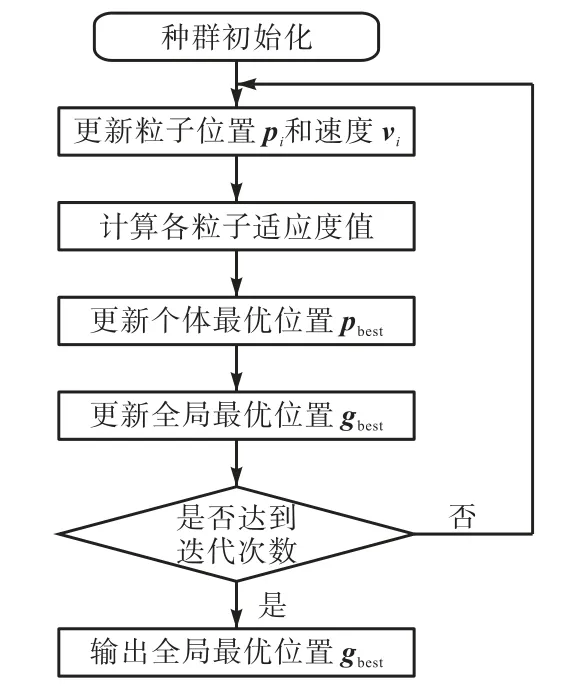
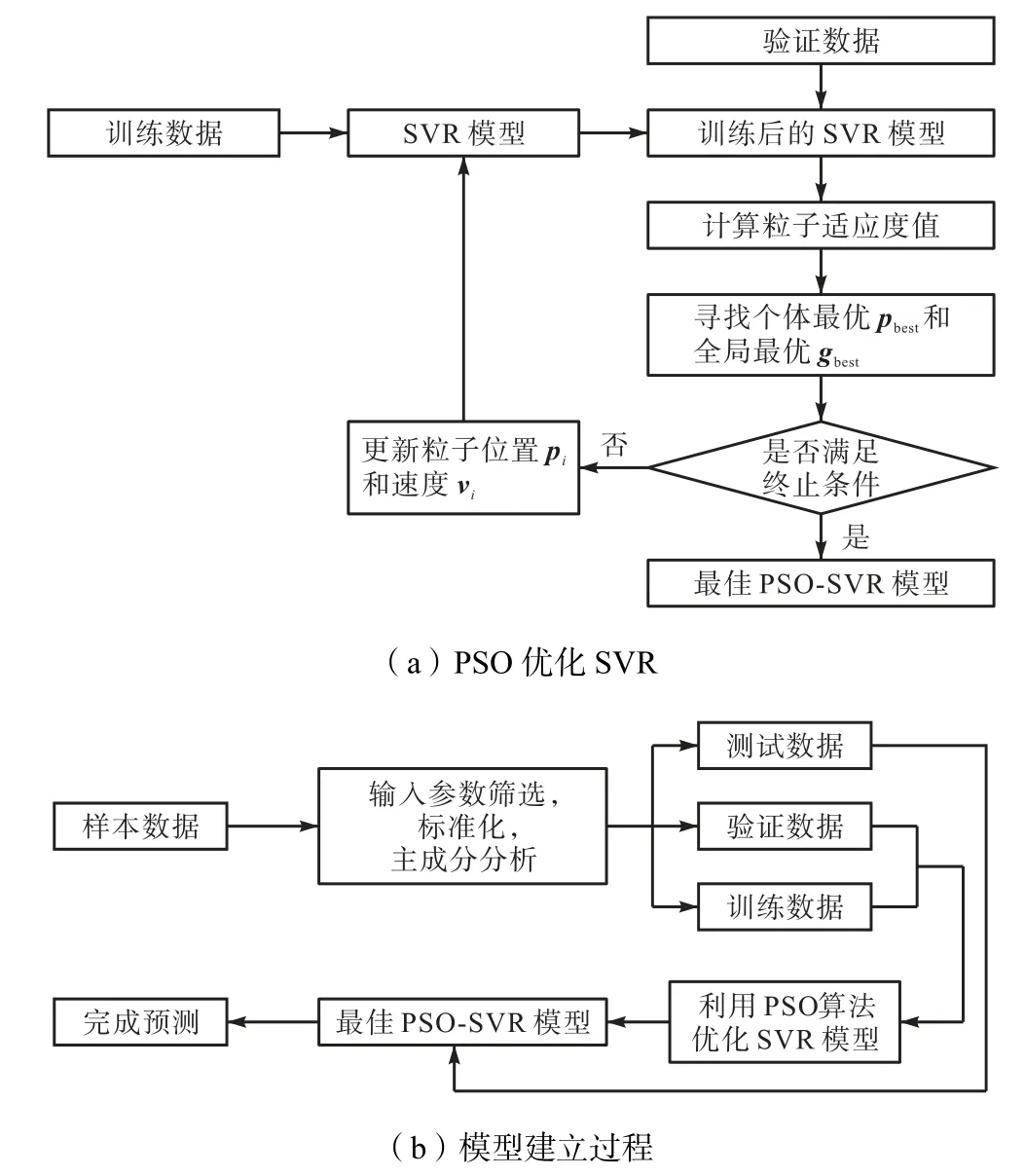
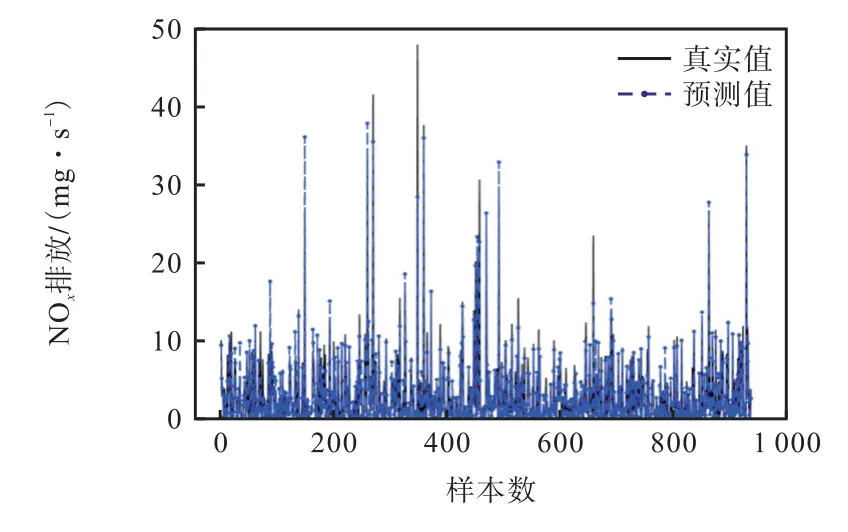
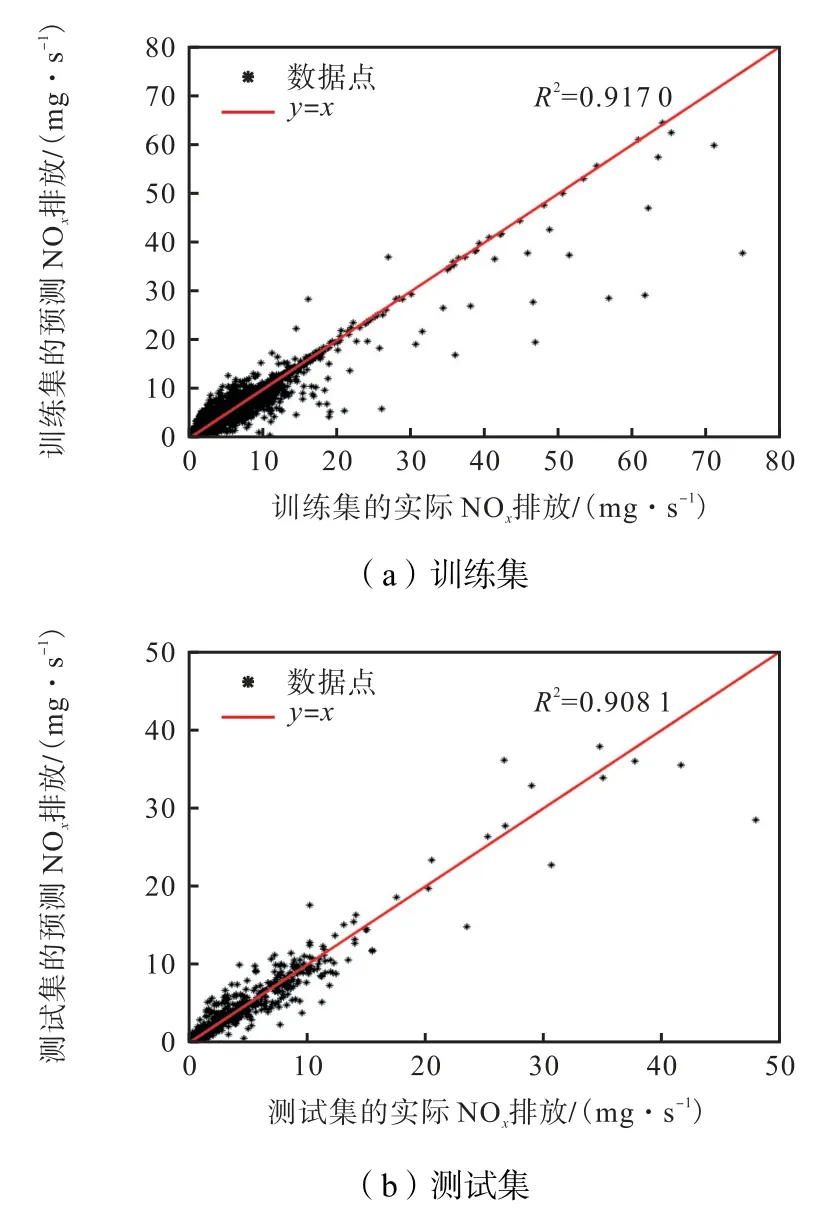
每一个主成分都可看成原始特征参数的某种线性组合,从而达到利用h 维主成分尽可能多地表达m维特征参数信息的目的(h 式中:βi为降序排列后的第i个特征值对应的单位特征向量;Y为采用式(2)标准化处理后的原始特征参数矩阵;Fi为提取的主成分. 式(3)~(7)中,有m= 11、n1=9300,计算得到的方差贡献率和累计方差贡献率如图6 所示.当选取的主成分累计方差贡献率达到80%以上时被认为合理有效.但是为了提高模型精度,需要确定提取的主成分个数,在确定主成分时将超参数设置为固定值(C= 35,ε=0.1,g =0.5),依次提取主成分Nc=[3,4,5,6,7,8]作为输入,进行5 折交叉验证,交叉验证的结果如图7 所示.可以看到,当提取的主成分个数大于6 时,对于提高模型精度收益较小,因而综合考虑,选取前6 组主成分F1~F6作为模型输入. 图6 PCA主成分提取Fig.6 Principal component extraction based on PCA 图7 不同主成分输入的交叉验证Fig.7 Cross validation of different principal component inputs 支持向量机(SVM)算法[10]最早由Vapnik 提出,其在小样本问题上作用效果明显.按照车辆实际道路试验规范,每种车型试验数据量有限,同时,一部分试验数据将被用于模型验证和测试,因而研究中用于模型训练的数据符合小样本数据特点.SVM 利用非线性变换将原始变量映射到高维特征空间,在高维空间中构造线性分类平面,既保证了模型具有良好的泛化能力,又解决了“维数灾难”问题.SVR 是在SVM 的基础上引入了不敏感损失函数得到的[11],其不再是寻找一个最优分类面使得两类样本分开,而是寻找一个最优分类面使得所有训练样本与该最优分类面的误差最小. 以提取的前6 个主成分作为输入x,NOx排放作为输出y ,构成样本集合{(xi,yi),i=1,2, …,n},xi∈R6,是第i个训练样本的输入列向量,为对应的输出值.在高维特征空间构建的线性回归函数为 式中:φ( x )为非线性映射函数;w为权向量系数;b为偏差量. 定义线性不敏感损失函数为 式中:f( x )为预测值;y为对应真实值;ε为不敏感损失函数阈值.由式(8)可知,若f(x)与y之间的差≤ε,损失为0. 引入松弛变量ξi、ξ*i,可将上述寻找w、b最优化问题转化为 式中C 为惩罚因子. 引入Largrange 函数,将式(10)转化为其对偶形式[12],即 式中:K(xi,xj)为核函数,K(xi,xj)=φ(xi)φ(xj);αi为Largrange 系数. 求解式(11)得到最优解α、*α,则可得到回归函数为 式中:(αi-)为支持向量系数;xi为支持向量. 由式(12)可知,SVR 的总体结构与神经网络比较相似,SVR 的输出可以看作中间节点之间的线性组合,各中间节点都对应一个支持向量,如图8 所示. 图8 SVR结构示意Fig.8 Schematic of structure of SVR 核函数 K ( xi, x )对模型的性能影响较大.在核函数的选择上,采用高斯径向基函数,其在建模过程中具有训练速度快、训练效果好的特点[13],即 式中:g 为核函数参数,控制函数的径向作用范围. 模型中的3 个参数C、ε和g 对模型性能影响较大,惩罚因子C越大则模型误差越小,但是C大于某一值会导致模型的泛化能力降低;参数ε增大,会使模型误差增大,反之,会使模型误差变小,过小的ε同样会导致模型泛化能力降低;参数g 对模型性能的影响与C类似,模型的精度会随着g 的增大而增大,但是g 过大时也会降低模型的泛化能力.因而引入粒子群优化算法(PSO)来优化3 个参数. PSO 是通过模拟鸟群捕食行为创造出来的随机优化算法[14].假设D 维空间中存在n个粒子,某粒子i 的位置可以表示为向量pi=(pi1,pi2, …,piD),速度可以表示为向量vi=(vi1,vi2, …,viD).PSO 寻优过程如图9 所示. 图9 PSO流程Fig.9 Flow chart of PSO 步骤 1随机初始化生成n个粒子 X,有X= (X1,X2,…,Xn),粒子Xi的初始位置和速度分别为、.记每个粒子的当前位置为个体最优位置,搜索到的全局最优位置记为. 步骤2在迭代过程中,按照式(14)和式(15)更新粒子速度及位置. 式中:ω为惯性权重;t 为迭代次数;为 t+ 1次迭代i 粒子速度;为 t+ 1次迭代i 粒子位置;c1和c2为非负常数,称为加速度常数,反映了个体和群体之间的信息交流程度;r1和r2为[0,1]之间的随机数. 步骤3位置更新完成后,计算各粒子适应度值,更新个体最优位置 pbest,更新全局最优位置 gbest. 步骤4检查是否达到最大迭代次数,如果未达到最大迭代次数则返回步骤2,若达到最大迭代次数,则到达全局最优位置 gbest. 粒子数目一般取20~40,笔者取值为20,加速度常数c1和c2一般取值为2,极限速度vm设定为1[15].惯性权重ω采用式(16)进行更新,保证在程序运行前段ω衰减速率较慢,有利于进行全局搜索避免陷入局部最优,在程序运行后段ω衰减速率较快,可以更好的进行局部搜索. 式中:ωs为初始惯性权重;ωe为迭代次数达到最大时的惯性权重;t为当前迭代次数;Tm为最大迭代次数.笔者取ωs=0.9,ωe=0.4. 在进行参数优化的过程中,以RMSE 的负数来计算适应度值,即 式中:f为适应度值;N为验证样本数量;f(x)为实际值;为预测值. 图10 为试验得到的NOx瞬时排放.将样本数据随机打乱并分为训练集、验证集和测试集,比例为7∶2∶1.根据对参数C、ε和g 的特性分析将其参数更新范围分别限定在(0,50]、(0,1]及(0,2],最大迭代次数设置为20.模型搭建过程如图11 示. 图10 NOx 瞬时排放Fig.10 Instantaneous emission of NOx 图11 PSO优化过程及预测模型建立过程Fig.11 Optimization process of PSO and establishment of prediction model 步骤1将训练集导入完成初始化的PSO-SVR模型中进行训练,生成初代模型. 步骤2将验证数据代入训练后的SVR 模型中后计算粒子适应度值,记下此时个体最优pbest和全局最优gbest. 步骤3判断是否满足终止条件,若不满足,则更新粒子位置和速度,并代入到模型中进行训练后重复步骤2,直至达到终止条件得到最佳模型. 步骤4将测试数据代入优化好的模型中进行预测,得到预测结果. 在对超参数进行优化之后,得到粒子最优位置为(C,ε,g) =(7.008,0.079,0.737),将参数代入模型训练,并在测试集上检验训练好的模型预测精度,图12 为测试集真实值与预测值的对比,RMSE 为1.381 6 mg/s,MAPE 为19.88%. 图12 测试集真实值与预测值对比Fig.12 Comparison of real and prediction values on the test set 图13为训练集和测试集的真实-预测NOx排放.训练集上决定系数为R2=0.917 0,测试集上决定系数为R2=0.908 1.可以看出,大部分数据点分布在y=x直线的附近位置,说明了该模型具有很强的非线性拟合能力.同时,均存在部分散点离y=x距离较远,笔者所搭建的整车NOx排放预测模型精度略低于以往学者[3,8]搭建的模型.这是因为与发动机台架试验等试验室工况相比,在进行实际道路试验时,路况更加复杂,发动机及车辆后处理系统工况变化更加剧烈,可能导致部分时间点位NOx排放发生突变;另外,尽管在试验结束后对各类测试数据进行了整体对齐,但是实际中仍会存在一部分异常点位的数据无法对正,从而影响模型精度,测试仪器的误差同样可能导致所测NOx排放无法反映某一时刻的真实排放情况,进而在测量结果中出现异常值. 图13 训练集和测试集的真实值和预测值Fig.13 Real and prediction values of training and test set (1) 以实际道路测试数据作为支撑,利用灰色关联分析选取模型输入参数,通过主成分分析降低输入参数维度,针对某款N2类重型柴油车建立了基于PSO-SVR 的NOx排放预测模型. (2) 在随机抽取的测试集上进行了验证,得到模型预测均方根误差为1.381 6 mg/s,平均绝对误差百分比为19.88%,说明该模型对于重型柴油车NOx排放具有较好的预测精度.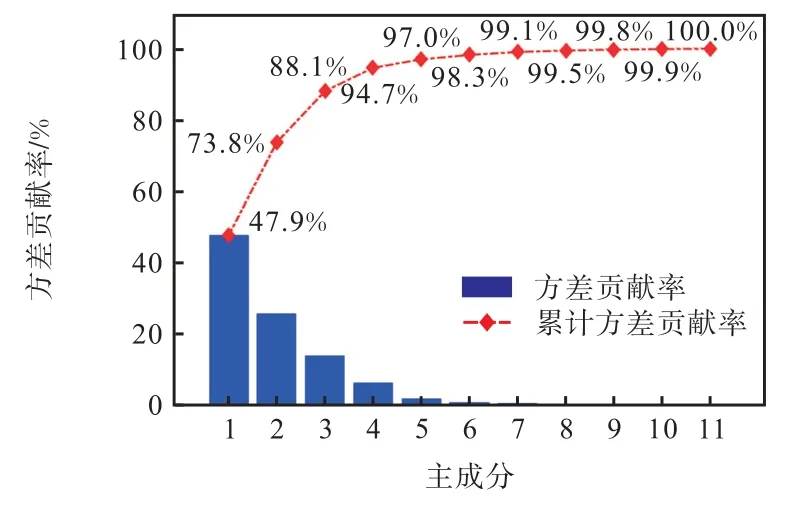

2 基于PSO-SVR的NOx 排放预测模型
2.1 支持向量回归算法

2.2 超参数对模型精度的影响
2.3 PSO及参数设置
2.4 PSO-SVR模型建立

3 预测结果分析
4 结 论
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
幽默大师(2020年11期)2020-11-26
摄影之友(影像视觉)(2019年3期)2019-03-30
摄影之友(影像视觉)(2019年2期)2019-03-05
摄影之友(影像视觉)(2018年12期)2019-01-28
世界汽车(2017年8期)2017-08-12
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
汽车与安全(2016年5期)2016-12-01
