
基于高斯混合模型和自适应簇数的文本聚类
2023-11-30 10:23程宏兵王本安陈友荣张旭东吴前锋
浙江工业大学学报 2023年6期
程宏兵,王本安,陈友荣,张旭东,吴前锋
(1.浙江工业大学 计算机科学与技术学院,浙江 杭州 310023;2.浙江树人学院 信息技术学院,浙江 杭州 310015; 3.浙江省经济信息中心,浙江 杭州 310006)
随着互联网的快速普及与发展,日常生活中会产生海量文本数据。面对海量的文本数据,如何有效将与日俱增的文本数据转化为有价值的信息成为一个重中之重的研究方向。因此,文本数据挖掘技术应运而生,在大量文本数据处理分析方面产生越来越重要的作用,受到学术界和工业界的广泛关注。在早期文本数据挖掘发展阶段中,主要采用数据库管理方式实现数据的分析,然而存在管理不规范和效率低下等问题。现阶段,主要采用深度学习、信息抽取和基于统计的机器学习等文本数据挖掘方法[1-3]。深度学习方法训练所有文本信息并分类导致计算复杂度较高,同时需要通过人工进行标签标注,时间成本较高。信息抽取方法虽然能对每段文本进行信息提取,但是没有充分考虑文本语义表达,会抽取出一些无关信息,影响文本处理效果。机器学习中的部分方法虽然具有效率高的优点,但存在无法确定分簇数,准确度低,未考虑样本相似度导致离散样本无法有效划分等问题。而文本聚类是根据文本的相似度将海量文本进行聚类分析[4],其由于无需训练过程及手工标注类别,自动化处理能力较强。文本聚类作为处理和管理海量数据的一项关键技术,不仅在数据分析与挖掘当中承担着重要的角色,而且与主题归类、信息检索以及文本挖掘等其他数据挖掘基础任务密切联系。目前,国内外研究学者提出基于划分、密度和层次的聚类等聚类算法实现文本聚类,然而基于划分的聚类算法非常依赖初始聚类中心的选择,同时针对大数据的情况下未能找到全局最优;基于密度的聚类算法对于设定的半径及其最小包含点数非常敏感,若选择不当会直接影响聚类的效果;基于层次的聚类算法虽然较灵活,但是计算量及其时间复杂度较高,大量数据集会对簇内相似度的判断存在较大的误差。其他聚类算法不仅仍存在无法确定具体分簇数量,聚类准确度低等问题,而且存在未考虑样本相似度导致分散文本无法有效划分等问题。
针对上述问题,为了自动和准确地进行文本聚类,考虑文本中的关键词频率和普适性,并权衡条件概率和相似度,提出一种基于改进高斯混合模型和自适应簇数的文本聚类算法(Text clustering algorithm based on improved gaussian mixture model and self-adaptive number of clusters,TCA)。首先,提出一种权衡关键词频率和普适性的关键词提取方法,包括采用无意义符号去除,基于齐次马尔科夫假设的文本分词和停用词去除等数据分词和清洗方法,同时结合关键词频率和普适性的情况,提取文本有效关键词;然后,提出基于改进高斯混合模型的文本聚类算法,包括计算衡量文本相似度与条件概率的文本权重,获取适用于当前分簇数量的最优模型参数,从而提高文本聚类准确率;最后,提出分簇数量的自适应,根据特定领域数据集,计算每个分簇数量所对应的最大随机文本损失与实际文本损失的差值,确定差值最大的分簇数量作为最优分簇数量,将相似度较高的文本结合关键词特征被聚类到同一个簇中心,使得簇内文本更加靠拢,不同簇之间差别更大,提高真实标签中被正确聚类的文本个数,提高TCA的召回率。
1 相关工作
目前,为实现文本聚类,许多学者对划分、密度和分层等聚类算法展开一系列的研究。其中,部分学者侧重于研究基于划分的文本聚类,如Yuan等[5]通过在每次迭代中删除一个簇(减号)、划分另一个簇(加号),并迭代应用聚类提高K-means的求解质量,从而实现快速、准确的文本聚类;Chen等[6]针对常见协同过滤推荐方法中不能充分利用所有用户评分信息的问题,提出一种基于K-medoids的聚类推荐算法,从项目评分概率分布的角度利用基于散度的所有评分信息实现目标聚类;Jia等[7]采用高斯混合模型聚类算法(Gaussian mixture model,GMM)对自行车站点进行分簇,并分析每个簇群在未来一段时间内的租金和回报数量;Yuan等[5]、Chen等[6]和Jia等[7]的研究虽然都能够高效划分出簇,但是初始聚类中心的选择仍需要改进,且在大数据的情况下未能找出全局最优。因此部分学者侧重于研究基于密度的聚类算法,如Li等[8]针对基于密度的聚类算法没有先验知识,自动准确识别聚类中心困难的问题,提出一种基于改进的密度值算法的两阶段聚类方法,首先使用基于蝙蝠优化的改进密度值算法生成初始聚类,然后通过密度峰值与确定的聚类中心来实现密度聚类;Jin等[9]提出一种用于社区检测的聚类算法,结合密度聚类算法并选择各类参数进行聚类,从而提升算法的有效性。然而Li等[8]和Jin等[9]的研究对设定的半径及其最小包含点数非常敏感,若选择不当会直接影响聚类的效果。部分学者侧重于研究基于分层的和其他聚类算法,如Fedoryszak等[10]设计用于实时事件聚类系统,实现事件动态聚类更新;李鼎宇等[11]提出短文本的跨域情感分类算法(Cross-domain sentiment classification algorithm for short Text,CSCA),利用谱聚类方法依次对两个领域的共享特征和特有特征进行聚类,根据所得的聚类信息进行特征扩展来提高准确率;Wang等[12]提出改进的层次聚类算法进行主题发现,并对短文本内容的微博进行短文本扩展,解决微博内容较短,基于传统话题模型的微博话题发现效果较差等问题;Janani等[13]提出一种具有粒子群优化的谱聚类算法来改进文本聚类。通过考虑全局和局部优化函数,对初始种群进行随机化,将谱聚类与群优化相结合,以处理海量文本文档实现文本聚类。Fedoryszak等[10]、李鼎宇等[11]、Wang等[12]和Janani等[13]研究的聚类算法虽然较灵活,但是计算量及时间复杂度较高,针对大量数据集进行基于簇内相似度的聚类会存在较大的误差。综上,目前的聚类算法仍存在无法确定具体分簇数量、聚类准确度较低等问题,难以准确且高效地实现文本聚类。
2 TCA原理
TCA原理如图1所示。首先获取数据服务中心的文本数据,并进行数据分词和清洗;其次,提取文本信息的关键词并进行文本向量化操作,获取关键词的词向量;再次,通过分簇数量固定的文本聚类和最优分簇数量确定,将所有文本进行聚类;最后,输出聚类结果,为工作人员的服务提供准确数据。TCA需要解决以下3个问题:1) 如何对获取到的反馈数据进行预处理和关键词信息抽取;2) 如何合理确定最优分簇数量;3) 如何结合关键词等信息,提出一种权衡条件概率和相似度的文本聚类算法。
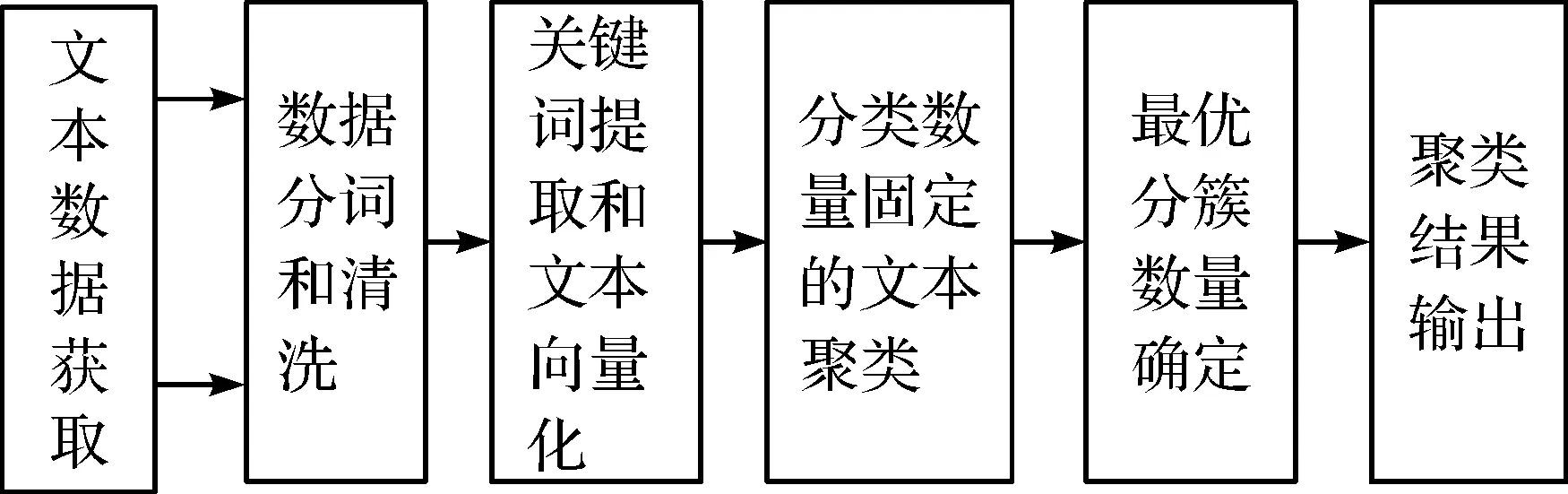
图1 TCA原理Fig.1 TCA principle
2.1 TCA数据分词和清洗
由于数据服务中心所提供的信息存在数据格式不一致的情况,因此会造成额外的复杂度开销以及算法效果等问题。首先,剔除非文本数据,避免无意义符号的影响;然后,采用基于齐次马尔科夫假设[14]的分词方法对文本进行分词;最后,对分词后的结果进行停用词去除,获得最优分词集合,进而节省存储空间和保证文本聚类的效果。
2.1.1 去除非文本数据
前期通过语音识别得到的投诉文本数据是非常杂乱的,包含大量没有任何有用信息的符号,如果不进行数据清洗,会增加计算的复杂度和计算开销,并对后续的算法实现结果产生一定的影响。因此需要去除语音转文本数据集中无意义的符号,如无用数字和标点符号等,类似“@#$%^&*()_+,./?”。
2.1.2 文本分词
剔除非文本数据过后,令Q={Q1,Q2,…,Qz},其中Q为文本数据集合,将每条文本Qz分词得到{w11,w12,…,w1n1;…;wm1,wm2,…,wmnm},m为第m种分词形式,nm,wmni分别为采用分词形式m时的分词数量和第ni个分词。由于涉及ni个分词的联合分布,需要统计所有分词结果,考虑分词概率计算时参数维度过多和条件概率较多,会导致计算复杂、难以提升精度等问题,因此引入齐次马尔科夫假设,并结合标准语料库,计算所有分词形式m的二元条件概率,计算式为
(1)
式中:wm(ni-1)为采用分词形式m时的第ni-1个分词;P(wmni|wm(ni-1))为已知第ni-1个分词前提下第ni个词出现的概率;freq(wmni,wm(ni-1)),freq(wm(ni-1))分别为在语料库中分词wmni与wm(ni-1)中相同分词和分词wm(ni-1)出现的总频数。考虑每一个分词出现的概率只与前面一个分词相关,计算文本数据Qz的第m种分词形式的概率P(wm),计算式为
P(wm)=P(wm1)×…×P(wmni|wm(ni-1))× …×P(wmnz|wm(nz-1))
(2)
式中:P(wm1)为采用分词形式m下的分词概率,循环计算文本数据Qz的所有分词概率,构成文本数据Qz所对应的概率集合P(z)={P(w1),P(w2),…,P(wz)}。通过argmax函数输出P(z)最大时所对应的分词形式,并获取对应的第z条最优文本分词集合Wzbest,计算式为
R=argmaxP(z)
(3)
式中R为P(z)最大时所对应的分词形式。若所有文本数据计算完成,则获得最优文本分词集合Wallbest={W1best,W2best,…,Wzbest},否则返回上述步骤重新计算最优文本分词集合。
2.1.3 去除文本停用词
文本分词结果集合R中会存在如“了”“的”“是”等使用频率过高、无意义的语气助词和副词等,会浪费存储空间与计算资源。为了缩减内存消耗和提升文本聚类的效果,通常将这些文本中的停用词进行去除,更新文本分词结果集合R。
2.2 关键词提取和文本向量化
针对处理大量文本信息存在时间复杂度、泛化性能力和冗余等问题,需要对上述一系列预处理后的词语进行关键词提取,尽可能提高后续分簇算法的准确性。目前,基于主题模型的关键词抽取方法存在抽取的关键词较宽泛,未能良好地反映文本主题信息等问题。TextRank等算法涉及复杂的网络构建和随机的迭代算法,导致效率较低。有的学者虽然根据词频进行关键词提取,但是一些通用词汇不能体现关键词,反而一些频率出现较少的词能够表达文本的主要含义。由于单纯使用词频进行关键词效果较差,需要考虑关键词中的普适性,因此提出基于词频和普适性的关键词抽取统计方法,进行文本分词后的关键词提取。令根据2.1.2节处理后的最优文本分词集合中的第z条文本集合为Wzbest={r1,r2,…,ru,…,rz},其中ru表示集合Wzbest中第u个分词。权衡关键词频率和普适性的关键词权重TFIDFu的计算式为
(4)
式中:TFu为第u个分词在文本数据Qz中出现的频率;NW为所有分词数量;IDF为第u个分词的普适性;L为标准语料库总量;L(ru)为标准语料库包含关键词ru的文本总量。通过式(4)进行权重降序输出,选择前j个分词作为文本数据Qz的关键词信息。若最优分词集合计算完成,得到所有文本数据的前j个关键词信息;否则,返回重新计算关键词权重。通过word2vec将所有关键词信息转为维度为dim的词向量。
2.3 基于改进高斯混合模型的文本聚类
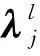
(5)
式中:Sc为第c个簇的文本相似度信息熵;σtc为第t个文本在第c个簇下高斯混合模型生成的条件概率;τ为文本数量;Btc为第t个文本在第c个簇中的基础概率,可表示为
(6)
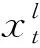
(7)
式中τ为文本数量。由于fc的更新需要对簇的平均条件概率和文本相似度进行权衡,即修改为
(8)
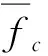
步骤1初始化最大迭代次数Emax,确定分簇数量K,当前迭代次数count=0等算法参数。任意选取一条文本信息作为第一个簇中心,并放入聚类集合CS。
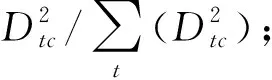
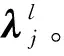
步骤4通过式(6)计算簇中每个文本信息的基础概率,从而结合权重fc得到每个文本信息由高斯混合模型生成的条件概率σtc,计算式为
(9)
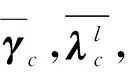
(10)
(11)

步骤6若当前迭代次数未达到最大,则跳到步骤4重新执行模型参数更新;否则,跳到步骤7。
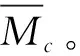
2.4 最优分簇数量确定
考虑到未来社区中文本聚类数量不确定且2.3节的文本聚类方法需要对分簇数量进行确定,才能提高算法的分簇效果,因此通过最优分簇数量的确定来自适应文本聚类。肘部法则是在观察分簇数量增大的过程中,确定每个簇中心与簇内样本点的平方距离误差和下降幅度最大的位置为肘部对应的值,然而其存在需要人工观察每个分簇数量的变化曲线,有一定的滞后性等问题。因此在肘部法则的基础上,寻找每个分簇数量所对应的最大随机文本损失与实际文本损失的差值。即依次选择分簇数量Ω=1,2,…,K,…,ξ,执行2.3节中基于改进高斯混合模型的文本聚类,通过式(12)依次计算分簇数量Ω=1,2,…,K,…,ξ中的损失函数εK,计算式为
(12)
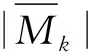
G(Ω)=E{log(εΩ)}-log(εΩ)Ω=1,2,…,K,…,ξ
(13)
式中:E{log(εK)}为log(εK)的期望值;ξ为分簇数量的最大值。从Ω=1,2,…,K,…,ξ中寻找G(Ω)值最大对应的分簇数量Ωbest,最终获得最优聚类数量Ωbest和最优聚类集合G(Ωbest)。
3 实验分析
实验采用Windows 10(64bit)操作系统,处理器为Intel®CoreTMi7-10700 CPU@2.90 GHz*2,内存为32 GB、显卡为NVIDIA GeForce GTX 1080TI默认超频版。
3.1 数据集和算法参数
为了验证TCA的有效性,采用2.1节文本数据获取方法采集某物业公司的社区业主与客服对话的线上音频数据和线下文本数据作为实验数据,通过语音识别将音频数据转换成文本数据,获得共4 200条文本数据。根据每条文本中的漏水、楼道垃圾和电梯等关键词信息进行场景分类,从而获得TS1(漏水场景)、TS2(垃圾场景)、TS3(电梯场景)、TS4(漏水与垃圾场景)、TS5(漏水与电梯场景)、TS6(垃圾与电梯场景)和TS7(漏水、垃圾与电梯场景)共7组群诉事件的数据集。通过仿真实验计算算法的评价指标,其中算法参数如表1所示。

表1 仿真参数表
3.2 评价指标
为了分析和比较文本聚类的效果,将聚类准确率和召回率作为模型评价指标。其中,聚类准确率的表达式为
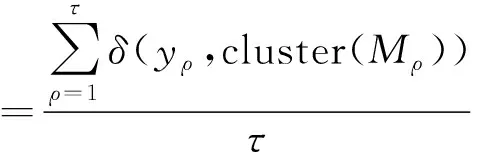
(14)
式中:τ为文本数量;Mρ为算法结合文本xρ分配到的簇标签;yρ为文本xρ的真实标签;cluster(Mρ)为TCA得到的簇标签;δ(a,b)为判断函数,用于判断算法得到的类别标签与真实标签是否相同,若相同则为1,不同则为0。聚类准确率表示聚类出的结果与真实标签一致的比例,准确率越高,聚类效果越好。
召回率的表达式为

(15)
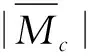
3.3 参数分析选择
分析7个场景下词向量维度、分簇数量和权重参数对TCA性能的影响,并以场景TS7为例说明算法的有效性。
首先,选择词向量维度分别为20,30,40,50,60,70以及表1中实验参数,分析词向量维度对文本聚类的聚类准确率和召回率的影响,具体情况如图2所示。随着词向量维度的不断增加,TCA的准确率和召回率逐渐提高,且当词向量维度为40时,TCA的聚类效果优于其他维度的聚类效果。这是因为:随着词向量维度不断增加,词向量模型能够更好地体现文本关键词特征,促使文本聚类更加准确。然而当词向量超过一定维度时,算法需要处理更多的向量且词向量信息出现一定的冗余,从而影响算法的时间复杂度,导致聚类准确率和召回率2个指标出现一定程度的下降,因此超过一定维度的词向量设置均会影响文本聚类的有效性。总之,当TCA选择词向量维度为40时,具有较好的时间复杂度与聚类效果。
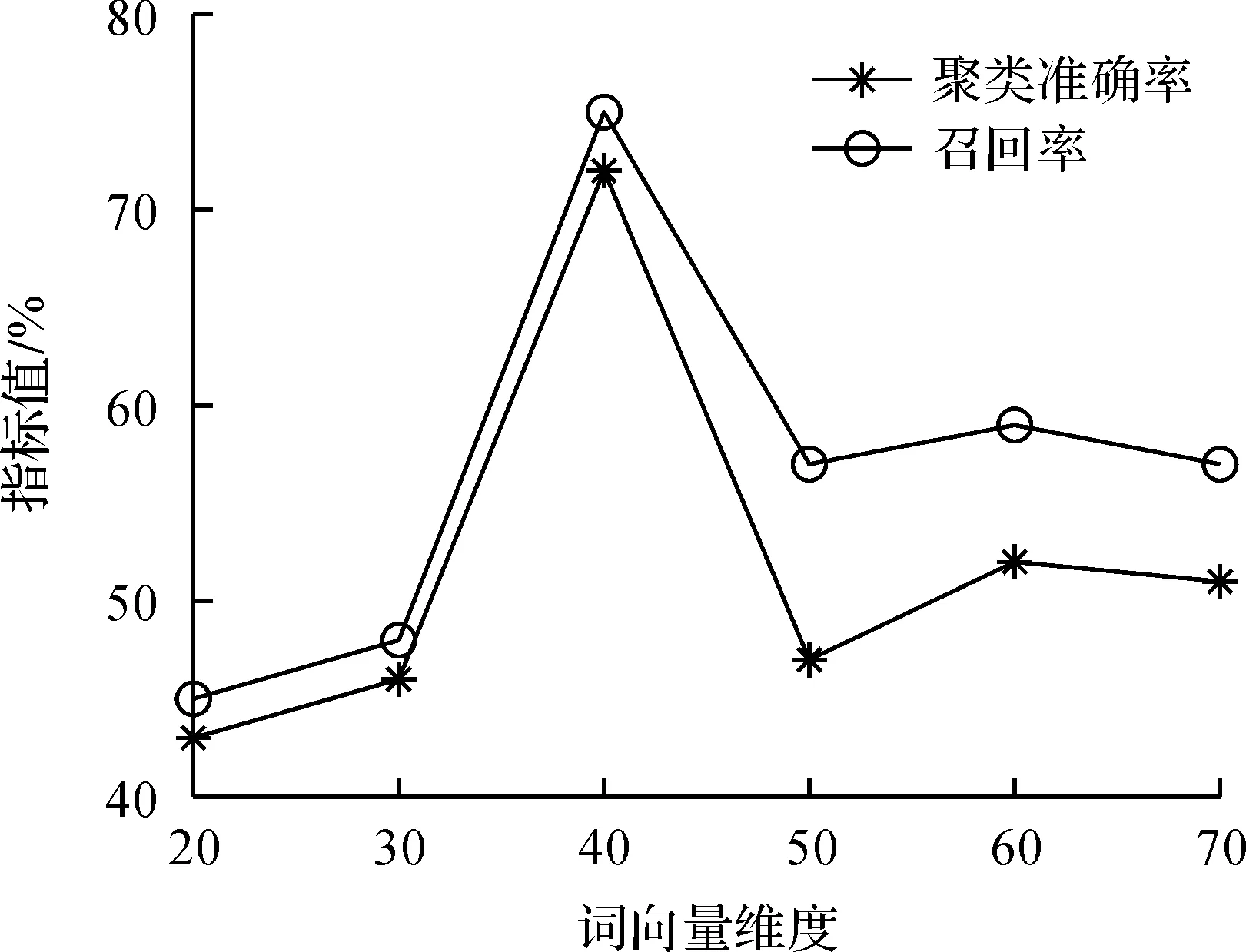
图2 不同维度下的聚类指标值Fig.2 Clustering index values in different dimensions
然后,选择文本分簇数量分别为1,2,3,4,5,6以及表1中的实验参数,分析文本分簇数量对随机文本损失与实际文本损失差值G的影响,具体情况如图3所示。当分簇数量为3时,其值符合TS7的漏水、垃圾与电梯这3类场景,因此实际文本的损失相对较小,随机文本的损失与实际文本损失之差达到最大,即G达到最大。这是因为:当分簇数量小于3时,随着分簇数量的不断增加,每个样本能够更好地通过关键词特征被聚类到同一个簇中心,G不断上升。当分簇数量为3时,符合TS7的实际场景,G达到最大,有利于相似的文本最大化被聚类到同一个簇中心,从而提升后续文本聚类的召回率。当分簇数量大于3时,由于事件发生域较为狭窄,过多的分簇数量划分会导致细粒度较少,造成聚类特征稀疏、丢失等情况,因此会影响文本聚类的有效性,G逐渐下降,导致相似文本被误判,从而影响后续文本聚类的召回率。因此3.5节确定最优分簇数量,是符合分簇数量对G影响的规律,可自适应寻找到最优分簇数量。同时,针对3.1节中所提到的7个场景,TCA通过最优分簇数量方法可正确聚类出7个场景的分簇数量,具有较好的普适性。

图3 不同维度下的GFig.3 G values in different dimensions
最后,选择权重参数βu分别为0.2,0.4,0.6,0.8,1.0,权重参数βa分别为0.2,0.4,0.6,0.8,1.0以及表1的实验参数,分析权重参数对聚类准确率的影响,具体情况如图4所示。当βa=0.6,βu=0.6时,文本聚类的聚类准确率达到最大值。这是因为:随着βu不断增加,簇内样本相似度的权重值会不断增加,在文本聚类过程中可有效结合簇内关键词样本的相似度和关键词信息,使其聚类准确率逐渐提高。随着βa不断增加,簇的平均样本条件概率的权重值逐渐增加,TCA可充分综合簇的平均文本条件概率与簇内文本的相似度信息进行分簇,从而提高文本聚类的有效性,使其聚类准确率逐渐提高。然而,当βa>0.6或βu>0.6时,簇内文本相似度的权重值与在聚类权重参数的更新中所占比重相对较少,分簇过程过于侧重簇的平均文本条件概率权重值,无法确保文本聚类的效果,导致出现文本聚类准确率有一定的下降。因此TCA选择βu=0.6和βa=0.6,可较好地实现文本聚类。
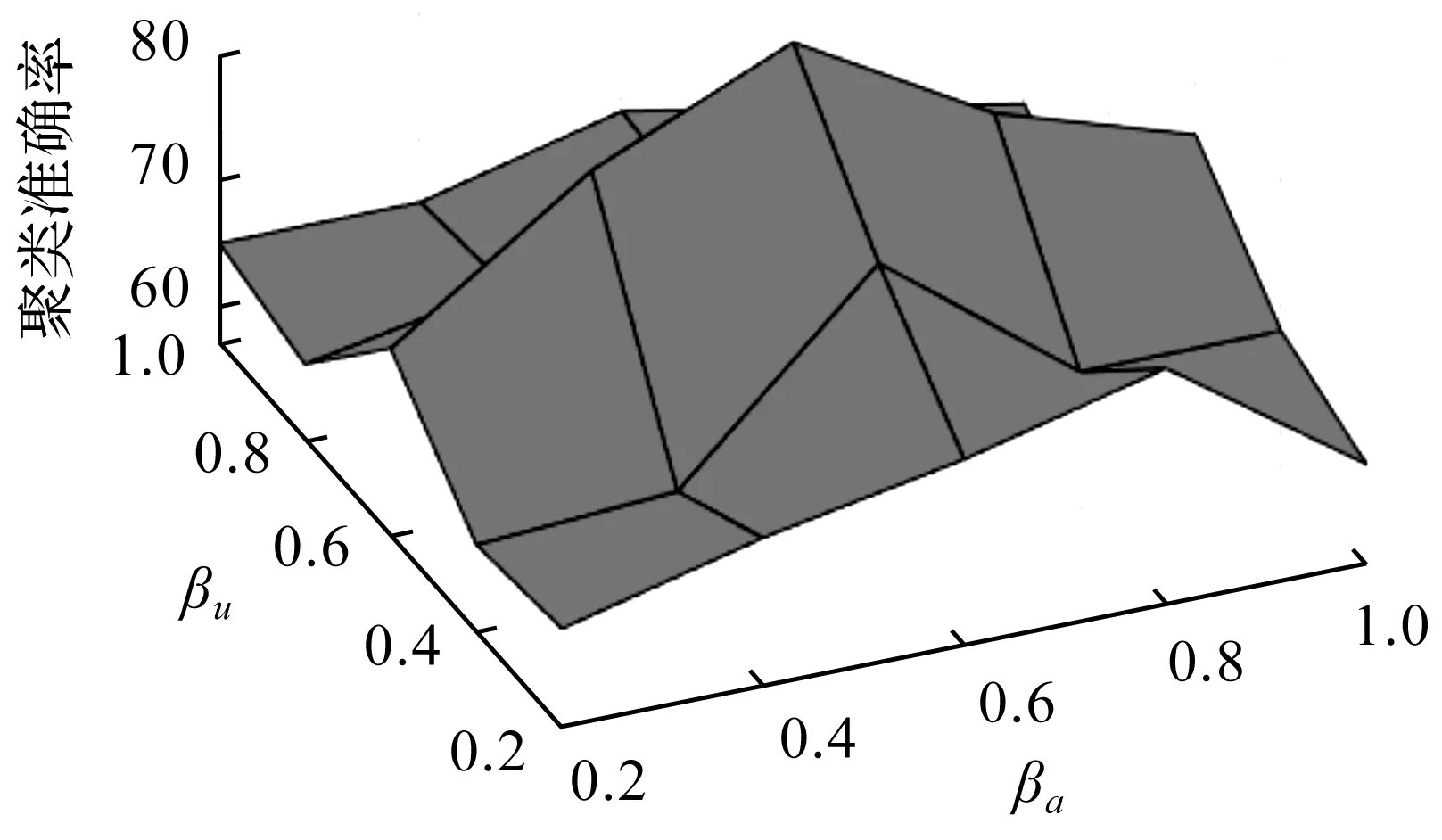
图4 权重参数对聚类准确率的影响Fig.4 Effect of weight parameters on clustering accuracy
3.4 算法对比
选择表1的实验参数,分析7个场景下TCA,K-means,GMM和CSCA的聚类准确率,具体情况如图5所示。由图5可知:无论文本数据如何变化,TCA均能够准确聚类文本,不仅聚类准确率变化较小,而且明显高于K-means,GMM,CSCA的聚类准确率。这是因为:TCA综合考虑每个簇的平均文本条件概率和文本相似度,能够根据文本的最大条件概率完成分簇,同时引入文本相似度使得同一个簇中的文本内容非常接近,不同簇中的文本内容相似度较低,因此不论文本数据如何变化,都能够聚类出文本,其聚类准确率始终高于91%。而GMM算法仅考虑文本属于某类的概率,虽然生成新的聚类中心点,但是未权衡每个簇的文本条件概率和相似度,其聚类准确率略差于TCA。K-means算法无法给出一个文本属于某类的概率,且无法结合条件概率生成新的聚类中心点,因此聚类效果不稳定,其聚类准确率变化较大。CSCA对于文本聚类不具有良好的泛化能力,当数据类型存在簇之间元素个数相差悬殊时,无法正确聚类,因此其聚类准确率最差。
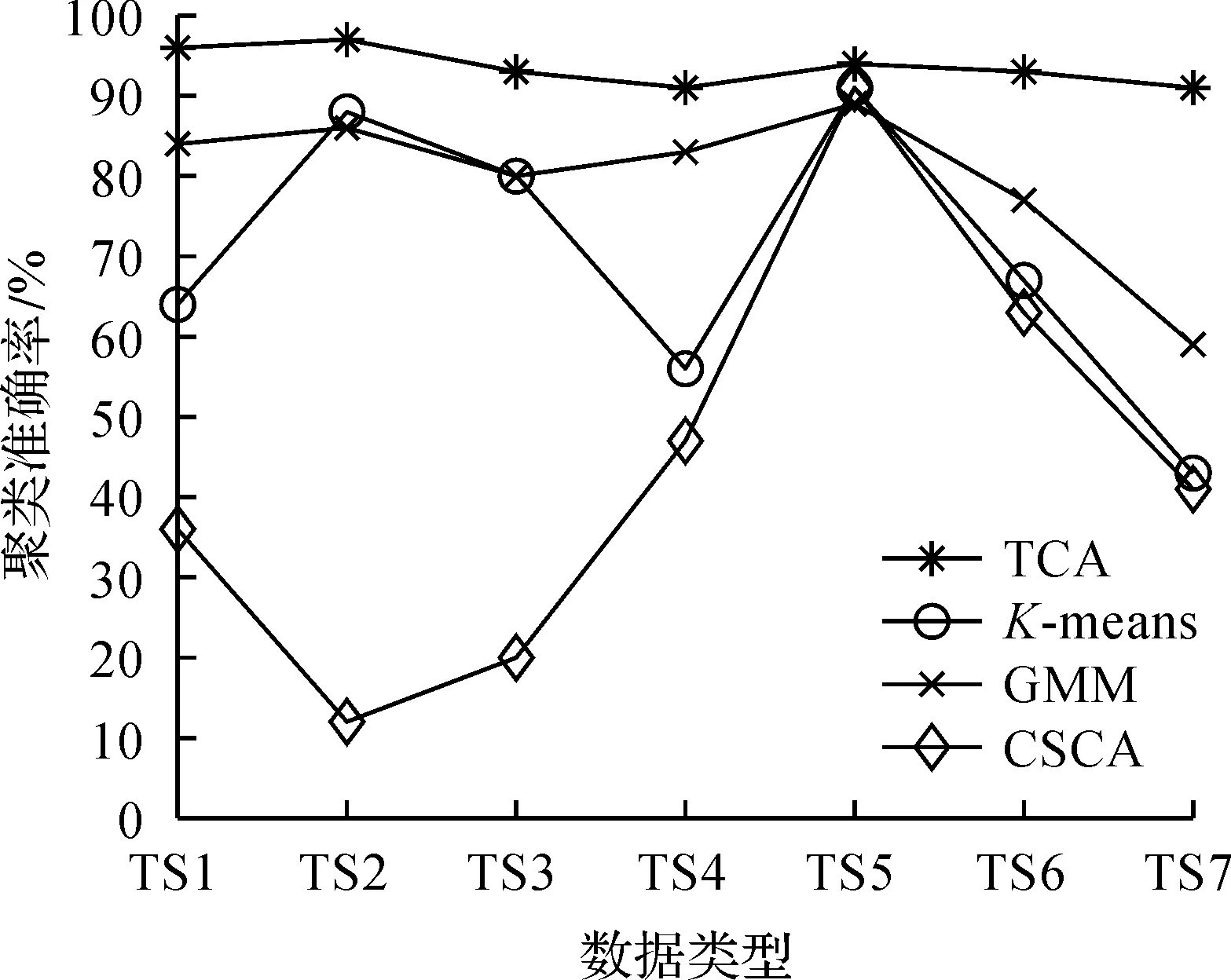
图5 聚类准确率比较Fig.5 Comparison of clustering accuracy
选择表1的实验参数,比较7个场景下TCA,K-means,GMM和CSCA的召回率,具体情况如图6所示。由图6可知:不管文本数据如何变化,TCA的召回率不仅变化较小,而且明显高于K-means,GMM,CSCA的召回率。这是因为:TCA结合文本的最大条件概率与相似度,且采用轮盘赌的方式选择下一类聚类中心,有效提升了在文本分簇中对正确关键词文本的聚类。同时,通过判定G能够确定文本的最优聚类个数,使得簇内文本更加靠拢,不同簇之间差别更大,利于聚类出正确的文本,从而提高算法的召回率,因此其召回率不受场景影响,能够保持在90%以上。而GMM算法针对文本中权重更新时仅考虑到簇内文本数,忽视了簇内文本相似度,并不能有效聚类正确样本。K-means算法不仅需要不断地进行文本聚类调整并计算调整后的新聚类中心,而且无法实现自适应确定文本分簇数量,导致时间复杂度较高和聚类效果差。当文本数量变化很大时,CSCA聚类效果会大幅度降低,从而影响簇中正确文本的聚类。
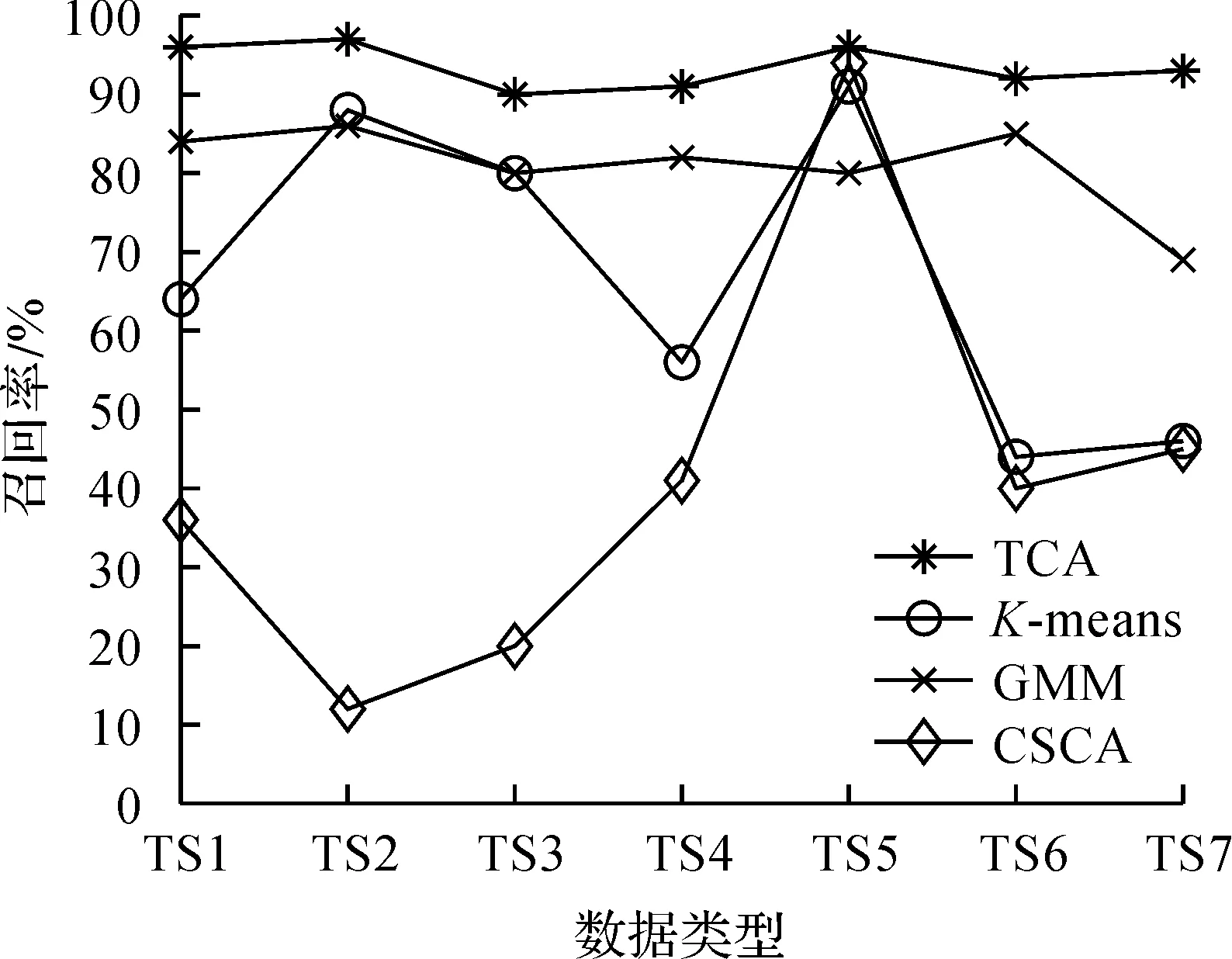
图6 召回率比较Fig.6 Comparison of recall
4 结 论
提出一种基于改进高斯混合模型和自适应簇数的文本聚类算法。首先,获取相关文本数据,结合文本的相关特点,提出一种数据预处理方法,实现文本的数据分词和清洗;其次,提出一种权衡关键词频率和普适性的关键词提取方法,进行关键词选择和文本向量化;再次,在高斯混合模型的基础上,引入文本相似度,提出权衡条件概率和相似度的文本权重方法和一种最优分簇数量的确定方法,实现分簇数量确定的文本分簇并确定最优分簇数量,从而获得分簇数量和其分布情况;最后,分析关键参数对文本聚类的影响,并比较TCA,K-Means,GMM和CSCA的性能。由于在聚类过程中部分关键词汇出现频率较低,从而影响聚类准确率,未来将探索一种基于关键词汇的数据增强方法以提高算法的聚类准确率。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中国交通信息化(2018年5期)2018-08-21
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
