
基于事件-词语-特征异质图的微博谣言检测新方法
2023-12-06 03:59王友卫凤丽洲王炜琦侯玉栋
中文信息学报 2023年9期
王友卫,凤丽洲,王炜琦,侯玉栋
(1.中央财经大学 信息学院,北京 100081;2.天津财经大学 统计学院,天津 300222)
0 引言
随着社交媒体的发展,网络谣言给社会带来了严重的影响,并逐渐引起了公众关注,成为了国内外学者的研究热点。党的二十大报告中指出,“健全网络综合治理体系,推动形成良好网络生态”。可见,实现谣言检测对于促进网络空间建设、维护社会稳定快速发展具有重大的现实意义。
谣言检测任务通过模型将正常文档与含有谣言的异常文档区分开,属于文本分类领域中的重要子问题。谣言检测的相关方法可分为三类[1]: ①基于外部知识的方法; ②基于关系网络的方法; ③基于文本内容的方法。基于外部知识的方法主要利用专家系统或集体智慧对谣言文档进行判别,该方法需要耗费大量的人工成本建立知识图谱,因此相关研究较少。基于关系网络的方法通过消息的传播特点、传播者追加的评论文本以及传播者的社会背景对谣言进行检测[2]。但是,此类方法的检测准确度与传播时间成正比,无法在谣言传播的初期对其进行较好的识别。基于文本内容的方法认为谣言与非谣言在表达习惯、讨论主题以及行文风格上存在一定差别,因此可以通过从文本中提取可供分类的向量化信息实现谣言检测。基于文本内容的检测方法可进一步分为基于传统分类器的检测方法与基于深度学习的检测方法两类。前者方法通过匹配文本中出现的人工特征来构建文本内容的one-hot向量,之后将特征向量输入支持向量机(Support Vector Machine, SVM)、随机森林(Random Forest, RF)、逻辑回归(Logistic Regression, LR)等机器学习模型,以此实现对谣言信息的识别。此类方法中最常用的特征是文本极性以及组合特征,如通过人工词典构建的情绪特征和语言学家构建的句式特征等[3]。但此类方法在提取特征时单纯依靠规则或者人工经验,因此相对于基于深度学习的检测方法而言无法较好地表征文本中的潜在语义信息。
近年来,基于深度学习的文本分类方法已被广泛应用于谣言检测任务中。Nguyen等[4]与Singh等[5]分别将谣言数据的向量化结果带入到卷积神经网络(Convolutional Neural Network, CNN)与循环神经网络(Recurrent Neural Network, RNN)中,相对于传统分类器而言有效提高了谣言检测的精度。Ma等[6]提出了一种基于RNN的评论上下文学习方法,通过学习微博事件的连续表示来实现谣言信息检测。Song等[7]和王友卫等[8]将所有转发信息视为一个序列,通过CNN实现可信早期谣言检测研究,有效缩短了谣言检测的时间跨度。Chen等[9]结合知识图谱提出一种基于图的谣言文本生成模型G2S-AT-GAN。该模型使用基于注意力的图卷积神经网络(Graph Convolutional Network, GCN)和生成对抗网络(Generative Adversarial Network, GAN)来生成不同主题的谣言文本,在解决谣言数据不平衡问题的同时提高了谣言检测的性能。但上述方法大多仅关注源信息和评论信息的内容,并没有有效利用评论、用户之间的相互关系,为此,杨延杰等[10]利用消息转发关系构建评论转发图,通过两个融合门控机制的图卷积网络模块来聚合邻居节点信息以生成节点的表示,有效利用了源博文的影响力与任意帖子之间的多角度影响。Wu等[11]提出了基于图神经网络全局嵌入的谣言检测模型和基于图神经网络集成学习的谣言检测模型。通过在有限时间步内在相邻节点之间交换信息来更新节点表示,有效提高了谣言检测的准确性。Bian等[12]提出了一种双向图卷积网络(Bi-GCN),根据谣言的转发关系建立自上而下和自下而上的图传播结构,较好地实现了谣言信息的嵌入表达,不足之处在于图中每个评论节点只能融合一个传播方向上的邻居节点信息。为了更好地考虑用户信息的影响,Lu和Li通过引入文本发布者的社交关系进行谣言检测[13]。Zhang等[14]借助立场检测任务,提出了一种基于多模态融合和元知识共享的谣言检测方法。该方法使用注意力机制计算评论权重,较好地区分了不同评论的重要性。
通过研究发现,虽然上述方法已获得较好的谣言检测效果,但仍存在以下问题: ①大多数方法在利用评论文本内容时仅关注词语特征信息,忽略了词语情感特征、语法特征、语言特征等重要因素的影响; ②现有算法普遍根据原始博文和转发评论之间的关系建立图结构,忽略了原始评论之间的语义关联性,因此难以针对新发布的博文进行检测,限制了模型的泛化能力。
为解决上述问题,本文以微博为研究对象,利用图神经网络在图表示学习任务方面的优势,提出了基于事件-词语-特征异质图的微博谣言检测新方法RD_EWF。具体而言,本文创新点如下:
(1) 综合考虑情感特征、语法特征以及语言特征对于谣言检测的影响,在评论内容信息基础上提出文本特征的概念。在此基础上,将微博事件、文本词语、文本特征作为节点构建事件-词语-特征异质图,解决了传统方法单纯利用文本内容信息导致的模型表达能力不足的问题。
(2) 综合考虑事件-事件之间、评论-词语之间、评论-特征之间以及词语-词语之间的相互作用,提出基于GraphSAGE和异质图注意力网络(Heterogeneous Graph Attention Network, HGAT)的图节点表示学习方法GS_HGAT,以此区分不同类型节点的影响,实现对微博事件节点的归纳式表达,提高模型的泛化能力。
1 相关理论
1.1 图神经网络(Graph Neural Network, GNN)[15]
GNN是被广泛应用于图分析任务的一类神经网络,现已广泛应用于社交网络、推荐系统、生物科技等领域。给定一个属性图G=(V,E)(V为节点集、E为边集)及其特征矩阵X={xi},其中xi是节点vi∈V的d维特征向量,GNN的目标是学习每个节点vi的表示hi,考虑第m层GNN,节点vi在第m层的表示向量定义为:
(1)
(2)
1.2 中文语言查询和词数统计(Chinese Linguistic Inquiry and Word Count, C_LIWC)[16]
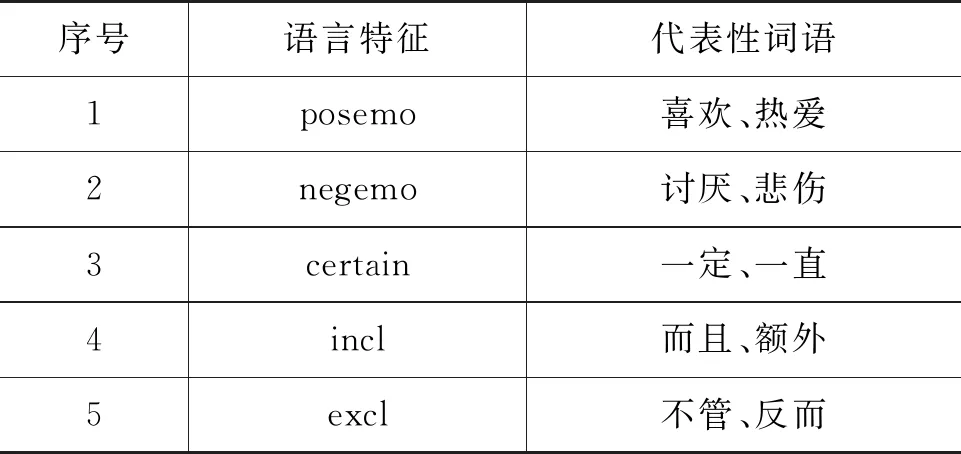
C_LIWC词典是在语言查询和词数统计词典(Linguistic Inquiry and Word Count, LIWC)基础上形成的词典。Pennebaker等人研究建立的LIWC词典主要用于对文本描述中的单词进行统计分析。该词典包含约4 500个从社会学、健康学以及心理学方面挖掘的情绪和认知方面单词,现已成为英文情绪分析研究应用的重要依据。台湾科技大学人文社会学科研究人员根据中文特性将LIWC词典翻译改编为中文版本C-LIWC。C-LIWC包含语言特征30类(如副词、介词等)、心理特性42类(如正向情绪词、负向情绪词等),共72个类别、6 862个词。其中,与情绪相关的类别包括positive emotion、negative emotion、anxiousness、anger和sadness。C_LIWC词典中每个词都有一个或多个类别属性,如“担忧”同时属于Negative Emotion类和Anxiousness类。
2 研究方法
2.1 问题描述
以微博为研究对象,相关定义如下[8]:
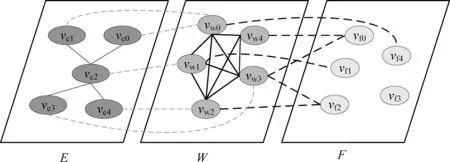
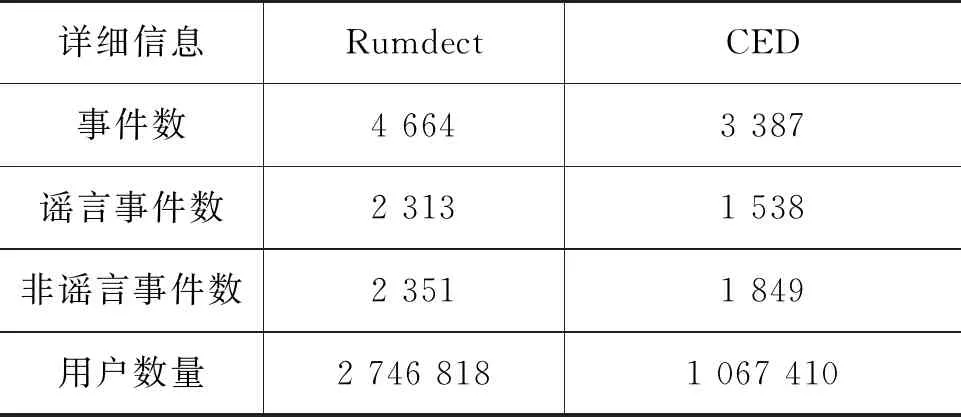
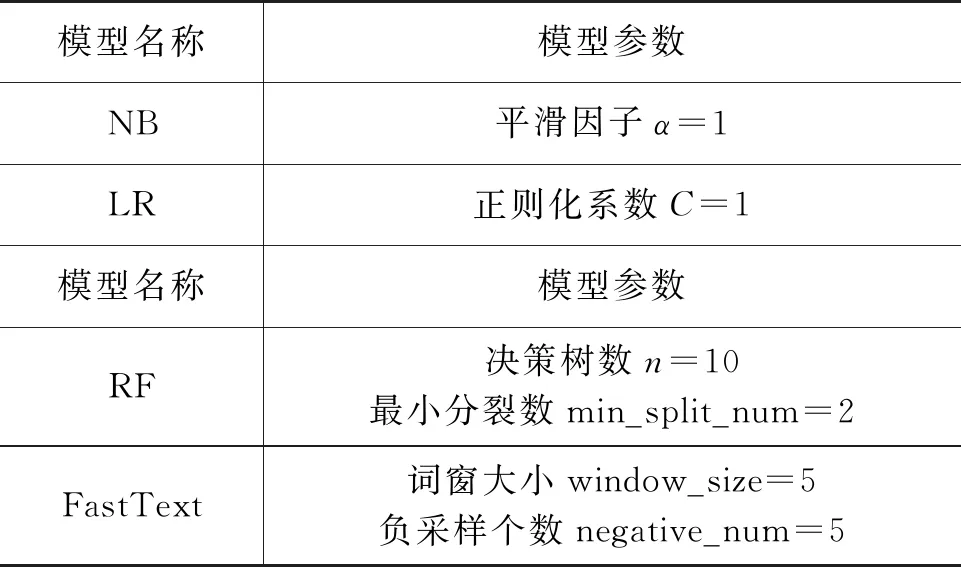
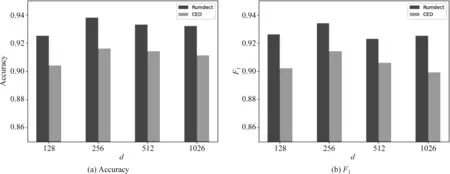
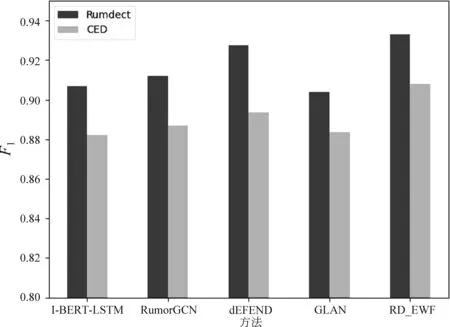
定义1 微博事件定义微博事件集合E= {Ei}(0≤i 定义2 源微博源微博是指最开始发出的微博,该微博不回复其他任何微博。mi,0表示第i个微博事件的源微博。 定义3 评论评论是指直接回复源微博或回复与源微博相关微博的微博。mi,j(1≤j≤ni)表示第i个微博事件的第j条评论。 给定微博事件Ei,本文方法的目标是学习一个分类模型CM以输出Ei是否为谣言的判定结果,即:y=CM(Ei,θ)(θ为参数集)。如果y=1,说明Ei为谣言事件,否则Ei为正常事件。 首先,对微博语料库中的微博事件进行中文分词,获得其中所有的事件及其对应的词语;然后,引入情感、语法、心理等方面知识,构建文本特征集,在此基础上挖掘事件-事件之间、事件-词语之间、词语-特征之间以及词语-词语之间的相互作用,构建事件-词语-特征异质图;最后,为区分不同类型节点的影响,提出基于GraphSAGE和异质图注意力网络的节点聚合方法,以此获得事件节点的向量表达。本文方法RD_EWF执行流程如图1所示。其中,M为事件总数,N为词语总数,S为特征总数。具体介绍如下: 图1 RD_EWF执行流程 2.2.1 文本特征构建 为了综合考虑不同类型特征对谣言检测结果的影响,本文将构建以下三种文本特征: 情感特征、语法特征以及语言特征。具体如下: (1) 情感特征 情感特征来自DUTIR实验室构建的Emotion Ontology情感词典[17]。该词典是大连理工大学信息检索研究室在林鸿飞教授的指导下整理和标注的一个中文本体资源,从不同角度描述一个中文词汇或者短语,包括词语词性种类、情感类别、情感强度及极性等信息。如表1所示,该词典将词语情感共分为乐、好、怒等7个大类,21小类,共计27 466个词语。为了体现不同情感倾向对于谣言检测结果的影响,本文使用该词典中的21个情感小类作为情感特征集Fs。 (2) 语法特征 对于信息含量较少的微博文本而言,词性、实体等语法特征可能包含人物、地点、时间、机构、数量、方位等多类信息,其中的部分信息可以作为检测谣言文本的重要依据。一般而言,信息描述越模糊,其为谣言的可能越高。例如,“某大学教授称……”“某知名人士称……”“研究者发现……”等文本并没有明确的人物、机构等名称,因此它们为谣言的可能性较大。中文词法分析(Lexical Analysis of Chinese, LAC)模型[18]是百度研发的一款联合的词法分析工具,能有效实现中文分词、词性标注、专名识别等功能。鉴于LAC模型在处理中文文本方面的优势,本文使用该模型获得词性标签 24个、专名实体类别标签4个,以此构建语法特征集Fg。 (3) 语言特征 语言特征由评论中与用户心理、情绪、认知、用词习惯等相关的词语所归属的类别构成。此类特征能较好地反映用户的情绪变化、心理状态、用词习惯等特点,因此包含与谣言检测相关的重要信息。本文根据C-LIWC中文语言分析工具[16],将其整理的6 862个词语所归属的72个类别作为语言特征集Fl。部分语言特征及其代表性词语如表2所示。 表2 部分语言特征 2.2.2 谣言检测异质图构建 首先,从训练集中获取事件集E、词语集W、文本特征集F={Fs,Fg,Fl}。在此基础上,建立由E、W、F构成的异质图G={V,A},A为G中节点对应的邻接矩阵,如图2所示,其中,V={E,W,F},vea∈E(0≤a<5)、vwb∈W(0≤b<5)、vfc∈F(0≤c<5)。针对V中任意节点对vi、vj(0≤i,j 图2 谣言检测异质图示意 (1) 若vi∈E并且vj∈E: 根据它们之间的语义相似性建立连边(图2中细实线所示),连边权重Aij为: 其中,cossim为余弦相似度函数,arccos为反余弦函数,xwk为词语wk对应的词向量,xi、xj分别为vi、vj两个事件中所有词语的词向量均值,nwi、nwj分别为vi、vj中的词语数。 (2) 若vi∈E并且vj∈W: 如果vj出现在vi中,则在vi、vj之间建立连接(图2中细虚线所示),权重Aij为vj在vi中的归一化TF-IDF值,即: (6) 其中,nij为词语vj在事件vi中出现的数量,ncj为词语vj出现的事件数,M为事件总数。 (3) 若vi∈W并且vj∈W,则根据它们的共现情况建立连边(图2中粗实线所示)。采用点互信息(Pointwise Mutual Information, PMI)[19]来计算语料库中词语和词语之间的连接权重Aij,定义如下: 其中,p(vi)为词语vi在事件中出现的概率,p(vi,vj)为词语vi与词语vj在事件中同时出现的概率,ncij为词语vi、vj同时出现的事件数量。 (4) 若vi∈W并且vj∈F: 如果vi属于vj对应的词语集,则在vi、vj之间建立连边(图2中粗虚线所示),令Aij=Aji=1。 2.2.3 节点嵌入 (10) 其中,exp为以e为底的指数函数,σ为Relu激活函数,||为向量拼接操作,We1为参数矩阵,ek0为原微博vk0中所含词语向量的均值向量,ekl为原微博的第l条评论中所含词语向量的均值向量。在此基础上,获得事件vk对应的节点向量xek,如式(11)所示。 (11) 其中,We2为参数矩阵。由于xfj与xwi、xek维度不同,进一步通过前馈神经网络将其映射到一个维度相同的空间内,即: xfj=σ(xfjWe3+bf) (12) 其中,We3∈R|F|×d、bf∈R1×d为训练参数矩阵。 2.2.4 节点采样与聚合 由于2.2.2节所构建的谣言检测异质图G规模较大,直接在该图上使用节点分类算法将面临计算开销较大的问题。GraphSAGE算法[21]首先通过采样邻居的策略,将节点训练由全图训练方式转换为以节点为中心的小批量训练方式,使得大规模图数据的分布式训练成为可能。此外,GraphSAGE对邻居节点的聚合操作进行了拓展,提出平均聚合、LSTM聚合、池化聚合等方法以提高节点表达的准确性。本文利用GraphSAGE的上述优势,通过采样得到图G的子图实现一种高效、可归纳的谣言检测过程。如图3所示,针对每个事件节点vi,首先,在一阶(k=1)采样过程中我们将获取vi邻居中的全部词语节点并获得vi邻居中连边权重最大的ns(ns=10)个事件节点;然后,为控制节点集规模,在第二、三阶采样中,分别针对vi的一阶采样结果中的每个节点vj,通过随机采样方法获得vj的ns(ns=10)个邻居节点;最后,利用上述采样所得节点集Vi={Vij}(Vij为在第j阶采样过程中得到的节点集)及对应邻接矩阵Ai构建子图Gi。 如图3所示,RD_EWF采样方向按照阶段k=1,2,3依次向外,而节点聚合过程则与采样方向相反。由于每个节点的邻居节点可能类型不同(如事件节点的邻居可能为词语节点或者事件节点,而词语节点的邻居可能为词语节点、事件节点或者特征节点),HGAT[22]通过异质图注意力网络来考虑不同类型信息的异构性,并利用双层注意力机制捕获不同邻居节点和不同节点类型对特定节点的重要性。但是,该方法在所有节点上进行训练,因此难以适用于规模较大的图结构数据。为此,本文在GraphSAGE基础上结合HGAT来为不同类型节点连边赋予注意力权重,以此在提高节点计算效率的同时区分不同邻居节点对当前节点的影响。在子图Gi的第k层聚合过程中,本文基于GraphSAGE和HGAT的节点聚合过程(GS_HGAT)描述如下: (13) (16) 其中,Wh为训练参数矩阵。 2.2.5 谣言分类 (17) 其中,Wo为训练参数矩阵,hij为vi的第j个邻居节点vij的隐状态向量,BiGRU({hij})函数输出词语序列{vij}对应的句向量。在此基础上,将hi输入到全连接层中,并结合其实际类别及交叉熵函数来使损失最小化,如式(18)、式(19)所示。 可见,为提高模型针对图节点的学习能力,RD_EWF综合考虑了事件、词语、特征三类节点之间的相互影响,通过引入情感、语法、心理等方面的知识,解决传统方法单纯利用评论词语信息导致的模型表达能力不足的问题。此外,为保证模型的高效性及针对新评论的学习能力,本文通过随机采样构建谣言检测子图,利用基于GraphSAGE和HGAT的节点聚合方法(GS_HGAT)在区分不同类型节点影响的同时提升了模型的泛化学习能力。 如表3所示,本文使用Rumdect[24]和CED[7]两个公开数据集验证模型的有效性,采用7:1:2的比例将数据集切分为训练集、验证集与测试集。 表3 实验数据集 为验证RD_EWF在谣言检测领域的有效性,将其与11个典型基准方法进行对比,具体包括: ①传统机器学习方法: 朴素贝叶斯(Naive Bayes, NB)[25]、逻辑回归(Logistic Regression, LR)[26]以及随机森林(Random Forest, RF)[26]; ②基于深度学习的方法: FastText[27]、TextCNN[28]、BiGRU-CNN[29]、TextGCN[30]、TextING[31]、I-BERT-LSTM[32]、dEFEND[33]、Bi-GCN[12]、RumorGCN[34]及GLAN[35]。实验参数设定如下: 节点丢弃率Dropout_rate=0.5,轮次Epoch=100,学习率Learning_rate=0.005,批大小Batch_size=100,词向量维度Word_dim=256。为了避免实验误差,针对每种方法取50次实验平均值作为最终的实验结果。 上述方法的参数设置如表4所示。 表4 参数设置 本文采用准确率(Accuracy)与F1值来衡量谣言检测方法的分类效果,定义如式(20)、式(21)所示[35]。 式(20)中TP是预测为谣言且实际为谣言的样本数,FN是预测为非谣言但实际为谣言的样本数,FP是实际为非谣言但被预测为谣言的样本数,TN是实际为非谣言且被预测为非谣言的样本数。式(21)中精确率(Precision)与召回率(Recall)指标定义如式(22)、式(23)所示。 为获得最优的隐藏层维度d,分别令d=128、256、512、1 024,并统计RD_EWF在Rumdect与CED数据集上对应的Accuracy值和F1值,结果如图4所示。由图知,当隐藏层的维度小于256时,本文对应的Accuracy值和F1值均呈现上升趋势;当d=256时,本文在Rumdect数据集上获得最大Accuracy值(0.938)和F1值(0.934),在CED数据集上获得最大Accuracy值(0.916)和F1值(0.914);当隐藏层的维度大于256时,模型对应的结果呈现下降趋势。究其原因,过低的嵌入维度可能使得隐藏向量包含的特征信息较少,导致模型的特征表达能力不足,而过高的嵌入维度将使得模型出现过拟合或者欠拟合问题,继而降低了算法的分类性能。由于当d=256时本文获得最高的Accuracy值和F1值,因此这里设定默认隐藏层维度为256。 图4 隐藏层维度的影响 为验证本文提出的基于GraphSAGE和HGAT的图节点聚合方法(GS_HGAT)在提升节点表示方面的有效性,这里将其与以下两种方法进行对比: (1)GS: 使用本文采样方法获得节点子图,然后直接使用基于LSTM聚合器的GraphSAGE算法[21]生成图节点表达。 (2)GS_GAT: 使用本文采样方法获得节点子图,然后使用图注意力网络(Graph Attention Network, GAT)[36]生成图节点表达。 在此基础上,我们将上述不同方法在不同数据集上进行比较,当采样邻居节点数量n取2、4、 6、…、20时统计不同方法对应的Accuracy值和F1值,结果如图5、图6所示。由图知,随着ns值的增大,不同方法对应的结果均呈现出逐渐增加的趋势,原因在于在图节点信息聚合过程中采样更多的邻居节点能够丰富节点语义信息,提高节点特征表示的完整性。但是,随着ns值继续增加,不难发现上述方法在不同数据集上的表现均呈现下降趋势,例如当使用CED数据集时,GS方法在ns=12时取得最大的Accuracy值和F1值,但当ns=20时,该方法对应结果下降了超过0.01。可见,适当增加ns值能提高节点表示学习的准确性,但是ns值过大容易带来较多的冗余特征信息,在提高算法计算开销的同时降低信息聚合效果。 图5 不同聚合方法在Rumdect数据集上的比较 进一步地,通过对比GS与GS_GAT发现后者对应的结果普遍高于前者对应的结果,这是因为GS方法在节点聚合过程中仅根据连边权重来获得邻居节点的加权结果,而GS_GAT方法则计算了邻居节点的注意力权重大小,继而能区分不同邻居节点对聚合结果的贡献程度,提高节点表示的准确性。对比GS_HGAT和GS_GAT时发现,前者对应的结果普遍偏高。例如,当使用Rumdect数据集时,GS_HGAT在ns=6时对应的Accuracy值比GS_GAT方法高出0.013;当使用CED数据集时,GS_HGAT在ns=20时对应的F1值比GS_GAT算法高出0.008,这说明在节点聚合过程中同时考虑节点权重与节点类型权重,能有效提高模型对于节点表示的学习能力,提升谣言检测效果。 这里在RD_EWF的基础上进行调整,衍生出以下几种变体方法并将其与本文进行比较: (1)RD_E_noC: 区别于RD_EWF,仅使用事件构建谣言检测异质图,并且在计算事件初始化嵌入表达时不考虑评论文本的影响。此外,利用基于平均聚合的GraphSAGE算法获得事件的最终嵌入表达,并利用公式(18)、(19)进行模型训练。 (2)RD_E: 区别于RD_EWF,仅使用事件构建谣言检测异质图。此外,利用基于平均聚合的GraphSAGE算法获得事件的最终嵌入表达,并利用公式(18)、(19)进行模型训练。 (3)RD_EW: 区别于RD_EWF,该方法仅使用事件及词语构建谣言检测异质图。 (4)RD_EW_senF: 区别于RD_EWF,该方法使用事件、词语以及文本特征中的情感特征构建谣言检测异质图。 (5)RD_EW_entF: 区别于RD_EWF,该方法使用事件、词语以及文本特征中的语法特征构建谣言检测异质图。 (6)RD_EW_linF: 区别于RD_EWF,该方法使用事件、词语以及文本特征中的语言特征构建谣言检测异质图。 在此基础上,我们统计了上述方法在不同数据集上对应的Accuracy值和F1值,结果如表5所示。由表5可知: 表5 本文方法与不同变体方法的比较 (1) 与未使用评论信息的RD_E_noC方法相比,RD_E对应的结果明显偏高。例如,当使用Rumdect数据集时,RD_E相对于RD_E_noC在Accuracy值与F1值方面分别提升0.039和0.043,这说明评论文本对于检测事件是否为谣言具有重要作用。 (2) 对比RD_EW和RD_E发现,前者在不同数据集上对应的Accuracy值与F1值相对后者均偏高,验证了本文使用BiGRU融合文本词语的上下文序列化信息对于提升事件节点表达精度的有效性。 (3) 进一步发现,与未使用文本特征的RD_EW方法相比,结合部分文本特征的RD_EW_senF、RD_EW_entF及RD_EW_linF方法对应的Accuracy值与F1值普遍偏高。例如,当使用Rumdect数据集时,RD_EW_senF相对于RD_EW_noF在Accuracy值与F1值方面分别提升0.006和0.002,RD_EW_linF相对于RD_EW在Accuracy值与F1值方面分别提升0.013和0.011,说明在事件、词语等信息基础上考虑情感特征、语法特征或者语言特征能从一定程度上提高谣言检测效果。并且,不难发现RD_EW_linF相对于RD_EW的性能提升程度较另外两种方法更为明显。究其原因,RD_EW_linF方法使用事件、词语以及文本特征中的语言特征构建谣言检测异质图,其抽取的语言特征中除包含情感特征外,还包含心理特征、认知特征等重要信息,因此相对于RD_EW_senF(RD_EW_entF),单纯使用情感特征(语法特征)而言更有助于提高节点信息的聚合效果。 当对比RD_EWF与其他算法表现时发现,RD_EWF在不同数据集上的结果均明显高于其他算法,这说明在谣言检测过程中综合考虑词语的情感特征、语法特征、语言特征后的方法性能要优于单纯使用其中一种特征时的方法性能,进一步验证了本文引入的文本特征对于提升谣言检测效果的有效性。 本文将RD_EWF与13个典型方法进行对比,结果如表6所示。其中,所有方法中的最优结果用粗体表示,次优结果使用下划线表示。由表6可知: 表6 不同方法的实验结果 (单位: %) (1) 基于深度学习模型的文本分类方法在不同数据集上的表现均优于NB、LR、RF等传统分类方法,原因在于前者方法能更好地挖掘谣言信息的隐含特征,而传统分类方法只是使用简单的词袋模型表示事件文本,丢失了文本上下文语义、词语顺序等重要信息。进一步发现,I-BERT-LSTM结果相对于TextCNN、BiGRU-CNN、TextGCN、TextING等方法普遍偏高,这是由于TextCNN等方法直接将整个微博事件对应的文本信息作为模型输入,而I-BERT-LSTM利用TextRank算法获得微博事件对应的文本摘要,因此能有效避免截取有限长度序列带来的关键信息丢失问题。 (2) 当将dEFEND与TextCNN、TextGCN、I-BERT-LSTM等方法比较时发现,前者对应结果明显偏高,说明将原始微博划分成句子并结合互注意力机制细化句子与相关评论的关系能较好地提升谣言检测效果。 (3) 相对于Bi-GCN,RumorGCN对应结果均有所提升,这是因为Bi-GCN仅仅考虑传播树中父子节点之间形成的层间依赖关系,而RumorGCN共同显式建模层间依赖关系和兄弟节点之间形成的层内依赖关系,因此能聚合不同依赖关系下的局部邻域信息,继而学习到更准确、更丰富的传播结构特征。 (4) 通过比较RD_EWF和其他方法发现,前者除在CED数据集上的Accuracy值低于dEFEND方法对应结果外,在其他情况下均获得最优实验结果。究其原因: ①本文构建的谣言检测异质图在传统评论、词语信息的基础上引入情感、语法、心理等知识,综合了事件、词语以及文本特征三方面之间的相互影响,丰富了节点向量表达中所含的特征信息; ②本文提出的基于GraphSAGE和HGAT的节点聚合方法不仅能区分不同邻居节点的重要性,还考虑了不同节点类型对于聚合结果的贡献,避免了TextING、Bi-GCN、RumorGCN等方法单纯考虑邻居节点重要性而导致的节点表示不准确的问题。 由于谣言传播较为迅速,因此能否及时地对尚未被评论或者较少被评论过的微博事件进行正确检测是衡量谣言检测算法性能的重要标准。为此,这里根据3.6节结果选取了4种表现较好的谣言检测算法I-BERT-LSTM、RumorGCN、dEFEND和GLAN,并将它们与本文RD_EWF方法进行对比以分析评论数量对不同方法的影响。为了仿真那些尚未被评论或者较少被评论的微博信息,我们随机选择测试集中10%的微博事件,然后针对每个事件只保留其中10%的评论信息。在此基础上,我们在数据集Rumdect与CED上统计了每种方法对应的Accuracy值和F1值,结果如图7、图8所示。 图7 微博评论数量对不同方法的影响 图8 微博评论数量对不同方法的影响 由图知,随着测试集中部分微博评论数减少,上述方法对应性能均呈现出不同程度的下降,说明微博评论中蕴含着较多与谣言检测相关的信息。进一步发现,dEFEND对应结果普遍高于I-BERT-LSTM、RumorGCN和GLAN,说明关注原始微博不同句子之间以及句子与评论之间的语义关联性能较好地保证谣言检测效果。与I-BERT-LSTM和GLAN相比,RumorGCN对应结果稍高,可能原因是前两种算法只关注评论信息之间的内容相关性,忽略了评论之间实际转发关系对谣言检测结果的影响。对比RD_EWF与其他算法发现,本文对应的Accuracy值和F1值在不同数据集上均获得最大值,虽然相对于表6中的表现有所下降,但所得结果仍明显高于其他算法。可见,由于本文在考虑原始微博和评论信息的基础上进一步结合了不同事件之间的相关性,因此能在评论较少的情况下根据事件之间的相互联系学习到对分类有用的重要信息,继而提高针对尚未被评论或者有较少评论的微博信息的检测能力。 本文提出了一种基于事件-词语-特征异质图的微博谣言检测新方法RD_EWF,主要贡献包括: ①在微博原文及评论内容信息基础上,引入了由情感特征、语法特征以及语言特征构成的文本特征的概念,将微博事件、文本词语、文本特征作为节点构建事件-词语-特征异质图,解决了现有方法单纯利用文本内容导致节点信息表达不充分的问题; ②综合考虑事件-事件之间、事件-词语之间、词语-词语之间以及词语-特征之间的相互作用,提出基于GraphSAGE和异质图注意力网络的节点聚合方法GS_HGAT,以此区分不同类型节点的影响,在保证模型可归纳的同时提高节点表示的准确性。在两个典型谣言检测数据集上的实验结果表明,RD_EWF相对于传统文本分类方法及深度学习方法在提升微博谣言检测准确性方面具有明显优势。未来计划将该方法推广至标题党识别、虚假信息识别等相关领域。2.2 方法描述

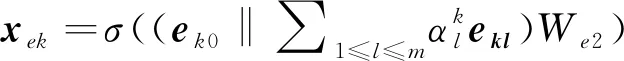
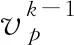
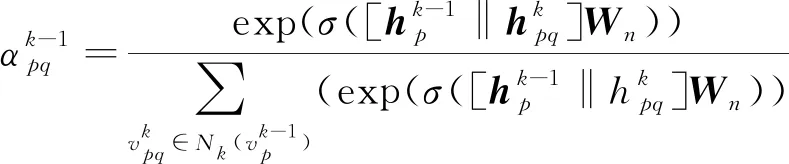
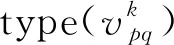
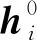
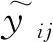
3 实验结果与分析
3.1 实验设置
3.2 评价指标
3.3 隐藏层维度取值影响
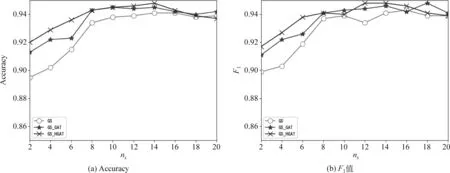
3.4 图节点聚合方法比较
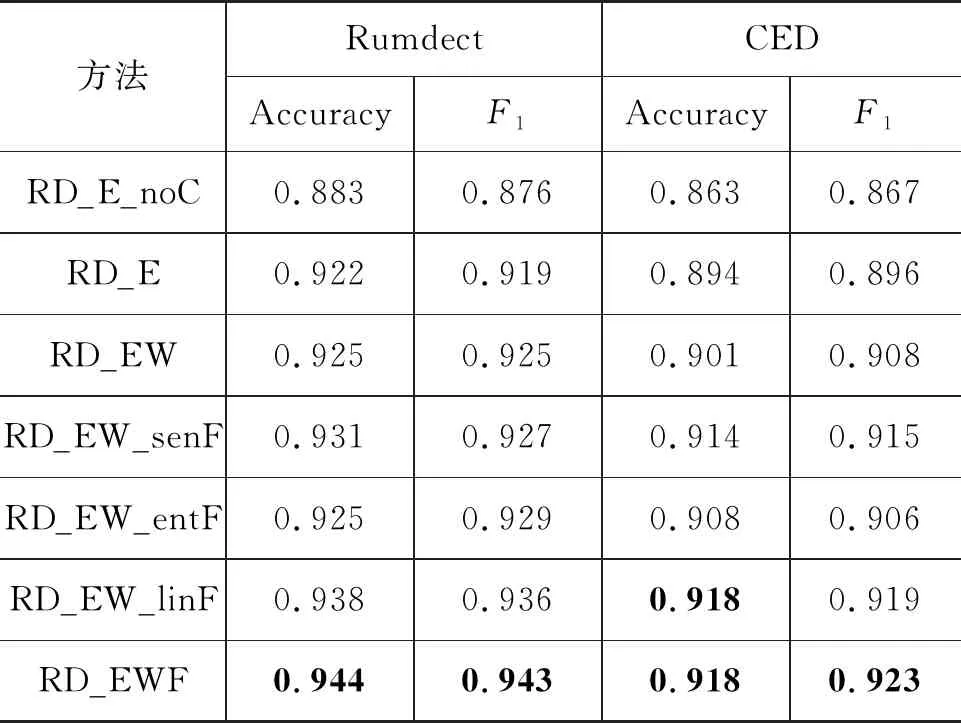
3.5 消融实验
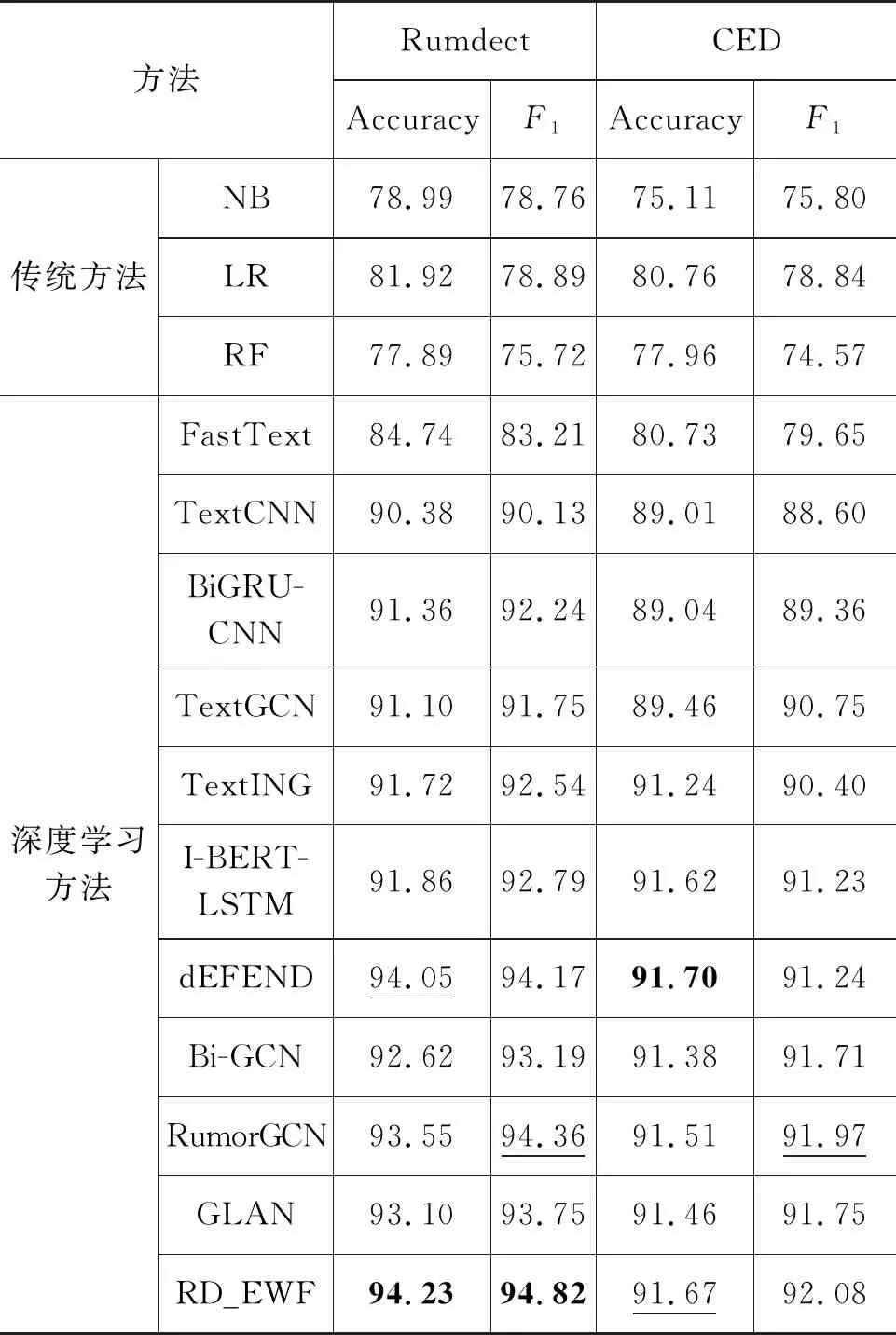
3.6 与现有典型方法的比较
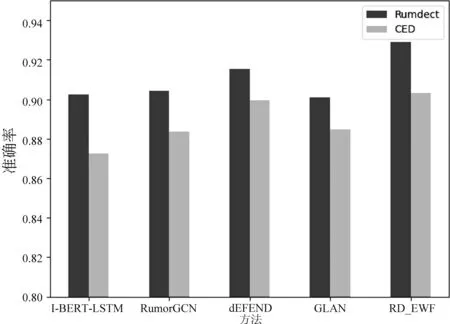
3.7 微博评论数量影响分析
4 结束语
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29机械工业标准化与质量(2022年6期)2022-08-12环球时报(2022-04-13)2022-04-13国际眼科杂志(2021年9期)2021-09-15小天使·一年级语数英综合(2020年4期)2020-12-16装备制造技术(2020年2期)2020-12-14中国盐业(2018年17期)2018-12-23民间文化论坛(2016年2期)2016-12-01学生天地(2016年32期)2016-04-16中国卫生(2015年12期)2015-11-10
