
求解多目标柔性作业车间调度问题的混合自适应差分进化算法
2023-12-11 13:04陈永灿周艳平
制造技术与机床 2023年12期
陈永灿 刘 宇 周艳平
(青岛科技大学信息科学技术学院,山东 青岛 266061)
车间调度问题是典型的NP-Hard 问题,调度问题解决的好坏影响着企业对市场的反应能力和竞争力。柔性作业车间调度问题[1](flexible job-shop scheduling problem,FJSP)是对传统作业车间调度问题更深入的研究,是比JSP 更复杂的NP-hard 问题。传统的FJSP 研究主要集中在单目标调度上,但多目标FJSP 更贴近人们实际生产需求[2]。目前,求解多目标优化问题[3](multi-objective optimization problem,MOP)的方法分为两类:根据每个目标函数的权重将MOP 转换为单目标问题;运用Pareto 优化策略[4]。
差分进化算法[5](differential evolution,DE)是Stom R 和Price K 提出的一种随机的并行直接搜索算法,因其具有结构简单、易于实现、收敛速度快、鲁棒性强等特点被学者们广泛使用。郭丽[6]提出了一种自适应DE 算法,通过对参数的改进来解决MOP;侍倩[7]将混合选择机制和Archive 群体更新应用到DE 算法中,提高了DE 算法在解决MOP时搜索Pareto 最优解的质量与速度;张敬敏等[8]将混沌优化策略与DE 算法相结合来解决算法早熟的问题,并在多目标FJSP 中解决了收敛性能与早熟之间的矛盾;Wisittipanich W 等[9]为提高最优解的质量,用5 种具有不用搜索行为的变异策略解决MOP 问题;Qian B 等[10]将一种最小阶值规则解决MOP 问题。在以上的研究中可以发现,学者们都是将DE 算法的参数进行各种自适应改进或将DE算法与其他算法相融合,从而提高DE 算法性能。
本文介绍了多目标柔性作业车间调度模型,提出了一种结合Pareto 支配关系的精英选择策略和模拟退火(simulated annealing,SA)算法[11]的混合自适应差分进化(hybrid adaptive differential evolution,HADE)算法,通过测试函数证明了HADE 算法的优良性能,并通过仿真实验证明了HADE 算法是解决多目标FJSP 的有效方法。
1 多目标FJSP 模型
1.1 多目标FJSP 描述
FJSP 是研究如何在m台机器上加工n个工件的问题。每个工件包含多道工序,工件的工序数量不一定相等;同一工件的工序之间有确定的加工顺序;每道工序可在多台机器上加工[12]。在确定工序的加工机器及工件加工顺序的基础上,实现对最大加工时间、最大机器负荷和总机器负荷等调度目标的优化。
为了便于描述模型,本文涉及的参数见表1。
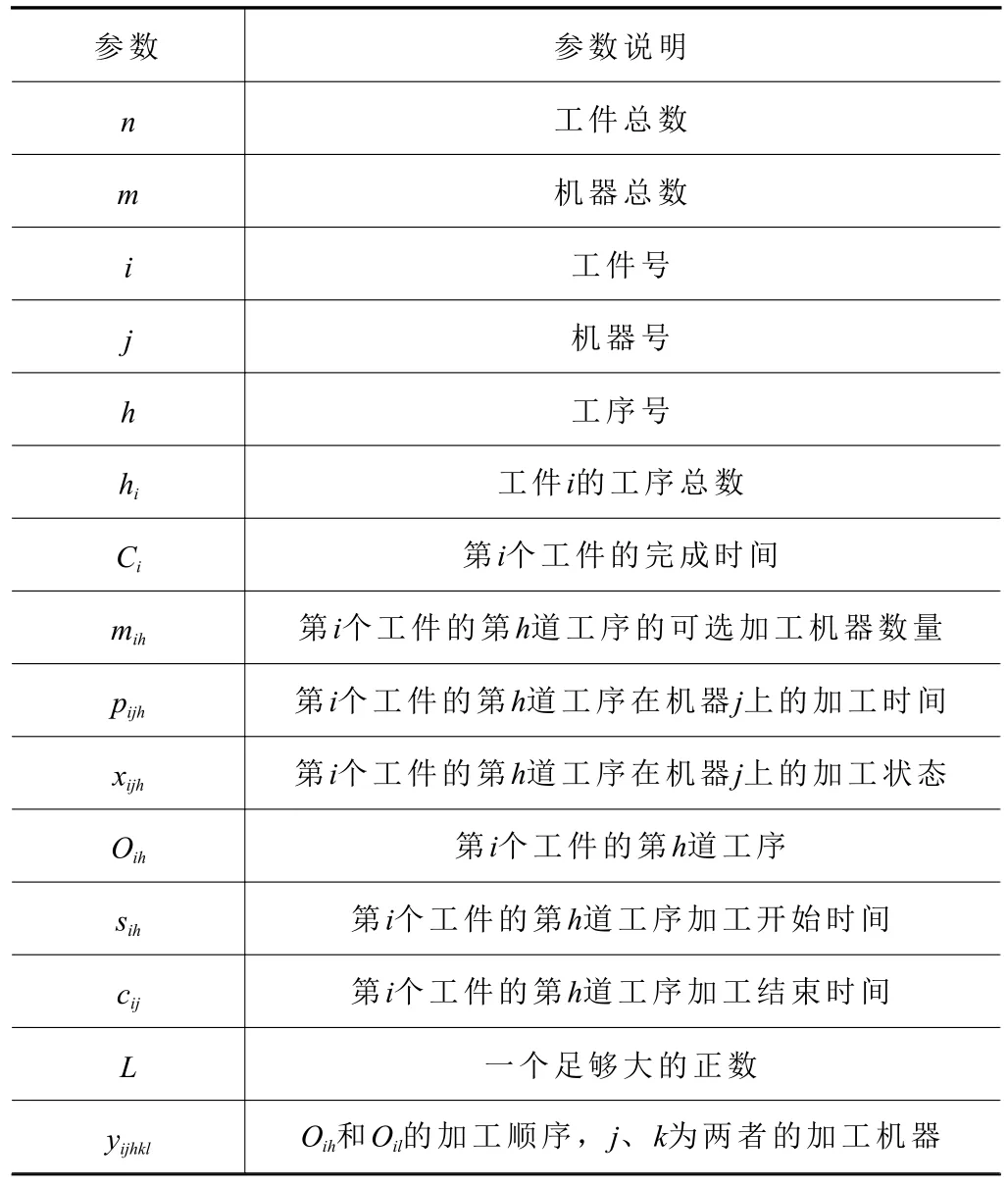
表1 模型参数表
1.2 目标函数及约束条件
本文模型共有3 个目标函数。
(1)最小化最大加工时间:
(2)最小化机器最大负荷:
(3)最小化总机器负荷:
约束条件说明:
(1)一台机器在某一时刻只能加工一道工序。
(2)任何工序在同一时刻只能被一台机器加工。
(3)任何开始加工的工序不能被中断。
(4)在零时刻,所有工件都可以加工,即所有工件具有相同优先级。
(5)同一工件的工序之间有先后约束。
2 HADE 算法
2.1 编码与初始化
HADE 算法采用一种整数编码MSOS,由机器选择(machine selection,MS)部分和工件排序(operations sequencing,OS)部分组成[13]。MS 部分中每个基因位用整数表示,依次按照工件和工件的工序顺序进行排列,每个整数表示当前工序选择的加工机器在可选机器集中的顺序编号。OS 部分用工件号直接编码,工件号的出现顺序表示该工件工序的先后加工顺序。与传统的集成编码、二进制编码等编码方式相比,MSOS 编码使染色体更易于表现,同时在进行变异、交叉等行为时具有更强的操作性。
如图1 所示,第一道工序可以选择5 台机器进行加工,但其对应的MS 部分的整数为3,则代表该工序所选择的加工机器为其可选择的5 台机器中的第3 台机器;OS 部分染色体为[1,2,3,1,1,3],则表示的加工顺序为O11→O21→O31→O12→O13→O32。
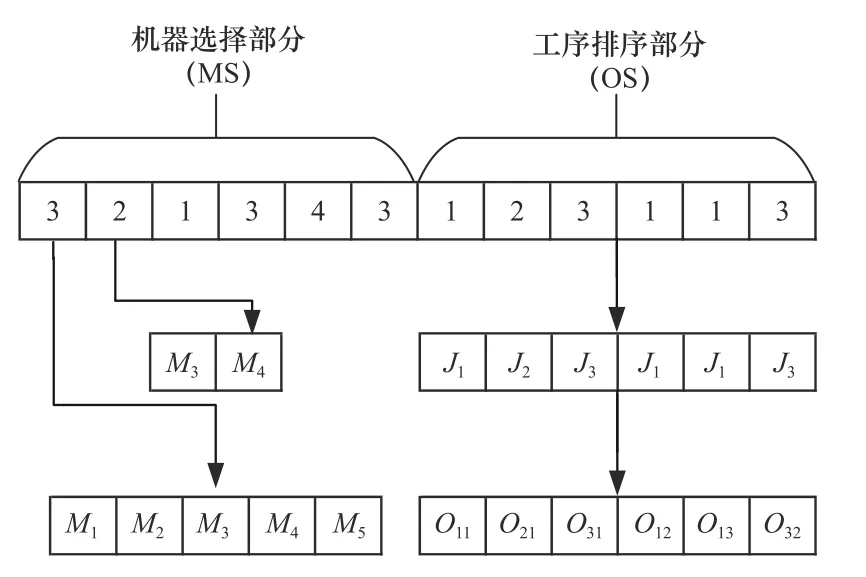
图1 MSOS 编码
DE 算法采用随机分布法产生初始种群,导致种群内个体多样性差,最优解质量与收敛速度并不理想。HADE 算法采用全局选择(global selection,GS)、局部选择(local selection,LS)和随机选择(random selection,RS)相结合的方式生成初始种群。GS 和LS 主要是为平衡被选择的各台机器的工作负荷,提高机器的利用率;RS 使初始种群分散于整个解空间。经测试,将GS∶LS∶RS 以4∶4∶2的比例生成初始种群。
2.2 变异操作
变异操作通常是通过改变染色体的某些基因,对染色体进行较小的改动来生成一个新个体,在增加种群的多样性的同时也在一定程度上影响着算法的搜索能力。因HADE 算法采用MSOS 编码方式,所以变异分为MS 部分变异和OS 部分变异。
MS 部分变异:在MS 部分中随机选择x个位置,依次将这些位置所选择的机器设置为当前工序可选加工机器中加工该工序用时最少的机器。
OS 部分变异:采用部分随机变异。在OS 部分中随机选择一段基因,然后将这段基因重新排序后放回染色体中,如图2 所示。

图2 OS 部分变异
同时,变异算子F的取值大小对种群的进化也有十分重要的影响。F过大时,个体变化较大,算法不容易收敛;F过小时,种群多样性会降低,容易陷入局部最优解。为提高算法的收敛速度,保证种群的多样性,HADE 算法根据沈孝龙等[14]提出的一种自适应差分进化(adaptive differential evolution,ADE)算法进行了一定的改进,使F能够随着迭代的进行由大变小。ADE 算法中F的取值范围为[0.4,0.55],与F的一般取值范围[0,2]相比范围较小,为进一步提升进化前期种群的多样性,将F的取值范围扩大为(0.55,1],提高了种群前期的变异能力,如图3 所示。F具体公式如下:

图3 自适应变异算子对比图
其中:Fmax=0.55;Fmin=0.4;,G为总迭代次数,m为当前迭代次数。
2.3 交叉操作
DE 算法将变异后种群中的个体与原始种群中的个体进行交叉操作,好的交叉操作在提高种群的多样性的同时还能提高算法的收敛速度。HADE 算法的交叉操作分为MS 部分交叉和OS 部分交叉。
(1)MS 部分交叉
该部分交叉采用改进的均匀交叉的方式,具体步骤如下:
①随机生成一个大于1 并且小于所有工件的工序总数的整数l。
②按照随机数l再随机生成l个不相等的整数。
③根据步骤②中产生的l个整数,依次将原始种群染色体中对应l个整数位置的基因覆盖变异后种群染色体中对应位置的基因。
(2)OS 部分交叉
采用改进的POX 交叉方法,在每个染色体中对多个工件进行操作,能够较好地继承父代个体的优良特征,具体操作如下:
①在工件集{J1,J2,J3,···,Jm}随机选取任意数量的工件构成子工件集Jobset1。
②将原始个体中包含在工件集Jobset1 中的工件复制到新个体中,并保持它们的位置和顺序。
③将变异后个体中不包含在工件集Jobset1 中的工件复制到新个体中,并保持它们的顺序。
OS 部分交叉如图4 所示。
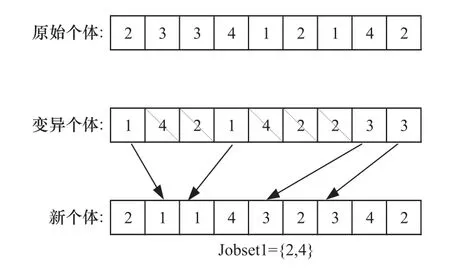
图4 改进POX 交叉
2.4 结合Pareto 支配关系的精英选择策略
为加速算法收敛,保证种群最优解不会因变异操作和交叉操作的影响而消失,本文对迭代过程中的原始种群与交叉后的种群进行结合,采用基于Pareto 支配关系的非劣解快速排序方法对种群中的个体进行分类,将种群分为具有支配关系但互不相交的子种群,最后通过拥挤距离的计算得到新种群。传统的精英选择策略在处理MOP 时选择的最优个体很难满足多个目标函数;基于聚合的精英选择策略按照权重比将MOP 转换成了单目标问题,但该方法难以确定合适的权重比;基于准则的精英选择策略只能求出每个目标函数的最优个体,难以确定满足所有目标函数的个体。结合Pareto 支配关系的精英选择策略通过Pareto 支配关系的非劣解快速排序方法和拥挤距离计算,可以得到满足各目标函数的多个最优个体,该策略既可以保留算法在进化过程中的多个最优个体,还保护了种群的多样性,同时对算法的收敛速度有一定的提升。
结合Pareto 支配关系的精英选择策略的具体步骤如下。
(1)将原始种群与交叉后的种群合并为一个临时种群。
(2)根据整体规则和个体规则将临时种群生成新的种群。
①整体规则:按照从低到高的顺序排列用快速排序方法生成的Pareto 等级,根据Pareto 等级将种群中的个体按层划分,依次将每层种群中的个体放入新种群中,直到父代种群达到种群规模;
②个体规则:按照拥挤距离从大到小的顺序排列该层个体,依次放入父代种群中,直到父代种群填满。
2.5 融合SA 算法的选择操作
传统DE 算法的选择操作是将交叉后的个体与原始个体逐一对比,按照适应度值择优选择。这个方法的弊端是容易陷入局部最优解,为解决这一弊端,HADE 算法在选择操作中结合了SA 算法,对适应度值比原始个体差的交叉后的个体进行操作,尝试选出更好的个体替代原始个体,从而跳出局部最优解,具体步骤如下:
(1)将交叉后的个体与原始个体按照0.6∶0.3∶0.1 的权重比对最大加工时间、最大机器负荷、总机器负荷进行适应度值计算。
(2)判断适应度值大小。若交叉后的个体适应度值更低,将交叉后的个体替代原始个体;否则,对交叉后个体进行SA 处理。
(3)设置初始温度T0,T=T0。
(4)令T=λT,λ表示退火速率,λ∈(0,1)。
(5)对当前个体的OS 部分进行随机扰动,使其产生一个新个体,计算出原始个体与新个体的差值,若差值小于0,则接受该个体替换原始个体,结束循环。
(6)判断是否达到终止温度,若是,则结束循环,否则转到步骤(4)。
2.6 HADE 算法流程
HADE 算法流程如图5 所示。

图5 HADE 算法流程图
利用HADE 算法求解多目标FJSP 主要步骤如下:
(1)设置HADE 算法中种群规模、最大迭代次数、Fmax、Fmin、T等参数。
(2)根据调度问题将GS、LS 与RS 结合使用生成初始种群。
(3)对种群进行改进自适应变异操作和改进交叉操作。
(4)求交叉后种群与原始种群合并后的Pareto最优解,根据计算出的拥挤度距离择优保留。
(5)将新种群与原始种群根据权重比得到的适应度值进行选择操作,若新个体优于原始个体,则更新原个体;否则,进行SA 操作。
(6)判断是否达到最大迭代次数。若满足,循环结束;否则,转到步骤(3)。
(7)将输出的最优个体解码并转换成对应的调度序列,算法结束。
2.7 函数优化测试
根据刘昊等[15]对标准测试函数的描述,选取表2 中的两个函数作为本文的测试函数,验证HADE 算法相较于ADE 算法与DE 算法的优越性。对3 种算法设置相同的操作参数及相同的初始种群。图5 和图6 所示为DE、ADE 和HADE 三种算法在最大迭代次数为30、种群规模为100 时得到的最优解与迭代次数的变化曲线。

图6 3 种算法在测试函数1 中的性能比较

表2 测试函数
由图6 和图7 可知,HADE 算法比ADE 算法和DE 算法到达全局最优解0 需要更少的迭代次数;在迭代次数相同时,HADE 算法所获得的最优解要比ADE 算法和DE 算法更好。实验结果表明,HADE 算法的收敛速度和平均适应度都有一定的提高。
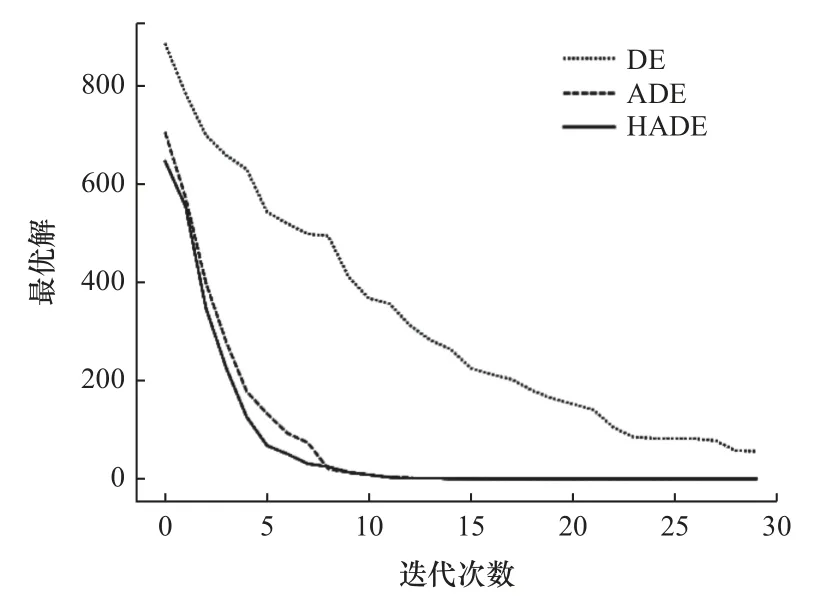
图7 3 种算法在测试函数2 中的性能比较
3 仿真实验及结果分析
本文使用Brandimarte P[16]所提出的Mk02(10个工件6 台机器)、Mk04(15 个工件8 台机器)、Mk08(20 个工件10 台机器)三种数据集,使用Python 编程,将Windows 10 运行平台下的Pycharm软件作为仿真环境。设置初始种群规模为40,迭代次数为80,T0为5,λ为0.8,将HADE 算法与混合差分进化(hybrid differential evolution,HDE)算法[7]、ADE 算法和DE 算法进行比较,为防止实验的偶然性,每种算法各运行10 次。选取最大完工时间最小的3 组解进行对比,实验结果见表3,其中(67,67,390)代表最大加工时间为67、最大机器负荷为67、总机器负荷为390。
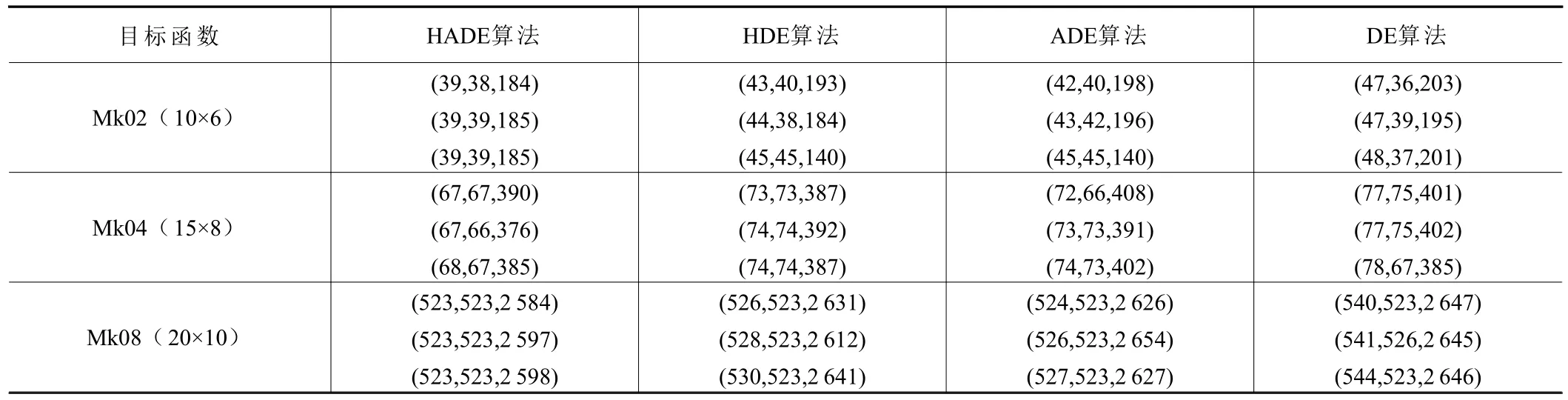
表3 实验结果比较
由表3 的Mk02、Mk04 结果可以看出,HADE算法对最大加工时间和最大机器负荷两个目标函数的优化明显优于其他三种算法,其中,DE 算法的优化效果是最差的。单看总机器负荷这一目标函数在Mk04 中的优化结果,四种算法的总机器负荷平均值为383.7、388.7、400、396,说明HADE 算法对这一目标函数的优化也是最好的,但相差不大。在处理较大规模数据集Mk08 时,HADE 算法虽比其他3 种算法更优,但无太大差距。总体来说,HADE 算法相较于HDE 算法、ADE 算法和DE 算法的优化效果更优,是一种适用于求解多目标FJSP的算法。
图8 所示为权重占比最高的最大加工时间在Mk04 数据集中四种算法的迭代过程曲线。当迭代次数相同时,HADE 算法的最大加工时间最小;当最大加工时间相同时,HADE 算法的迭代次数更少。综上所述,HADE 算法具有更好的寻优能力,在求解多目标FJSP 问题时具有一定优势。

图8 最大加工时间在Mk04 中4 种算法的进化曲线
图9 所示为对比4 种算法在Mk04 中得到的Pareto 解集,可以看出HADE 算法的寻优能力更强,能得到更好的解。

图9 去重Pareto 解集对比
图10 所示为使用HADE 算法对Mk04 数据集优化时得到的最大加工时间为67、最大机器负荷为66、总机器负荷为376 的调度结果甘特图。
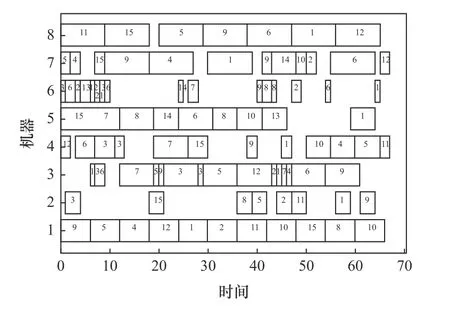
图10 调度优化结果甘特图
4 结语
本文提出了HADE 算法对多目标FJSP 进行求解,针对最小化最大加工时间、最小化机器最大负荷、最小化总机器负荷等目标函数进行优化,在Mk02、Mk04 和Mk08 这3 种数据集中与HDE 算法、ADE 算法、DE 算法进行仿真对比,最终表明本文算法收敛性更好,寻优能力更强,在求解FJSP 时效果更优。但在处理Mk08 等较大规模数据集时收敛速度相对较慢,后续工作将针对处理大规模问题时进一步提升算法的寻优能力和收敛速度。
猜你喜欢
今日农业(2022年15期)2022-09-20
趣味(数学)(2020年4期)2020-07-27
支部建设(2020年15期)2020-07-08
初中生世界·八年级(2019年6期)2019-08-13
红土地(2018年7期)2018-09-26
小学生导刊(低年级)(2016年6期)2016-07-02
百科知识(2015年18期)2015-09-10
计算机工程(2015年8期)2015-07-03
振动、测试与诊断(2014年6期)2014-03-01
当代畜禽养殖业(2014年10期)2014-02-27
