
基于机器视觉和机器学习技术的浙贝母外观品质等级区分
2023-12-29 08:43董成烨李东方冯槐区龙思放奚特周芩安王俊
浙江大学学报(农业与生命科学版) 2023年6期
董成烨,李东方,冯槐区,龙思放,奚特,周芩安,王俊
(浙江大学生物系统工程与食品科学学院,浙江 杭州 310058)
浙贝母(Fritillaria thunbergii)是一种百合科(Liliaceae)贝母属(Fritillaria)草本植物,是传统中药材之一,主要药用成分为生物碱类、皂苷类,具有镇咳、祛痰、抗炎、抑菌、抗肿瘤等功效。据统计,2017—2018 年中国浙贝母总产量已超4 000 t,种植产值约为60 亿元[1]。根据T/CACM 1021.24—2018《中药材商品规格等级 浙贝母》,浙贝母在满足无霉变、无虫蛀、无破碎的情况下,按直径分为特级、一级、二级[2],而霉变、虫蛀、破碎的浙贝母不能入药,需剔除。然而,目前对浙贝母的分级通常利用筛网、圆柱辊等实现[3-6],由于浙贝母形状不规则,分级效果往往不理想,此外,筛分过程易对浙贝母造成机械损伤,也无法筛分出霉变、虫蛀、破碎的浙贝母。因此,开发精准检测浙贝母外观品质及直径的算法,并研制一种快速、无损的分级生产线十分必要。
目前,针对农产品的无损检测主要依靠声学、光学、电磁、电子鼻和机器视觉等技术[7]。机器视觉是利用摄像机和电脑代替人眼对目标进行识别、跟踪和测量的技术,具备准确、快速、经济等特点,因此,浙贝母的外观品质及直径的检测与分级可通过机器视觉技术实现。机器学习是处理机器视觉任务的重要工具[8],包括统计学习与深度学习。统计学习是利用研究人员的先验知识对数据进行硬编码,以更简单的方式来表示数据,从而分析、挖掘数据内部潜在的规律,但是其特征需要手动提取且数量有限,因此很难快速、高效地利用原有数据,并且操作过程复杂、耗时[9]。
深度学习是一种以人工神经网络为架构,对数据进行高层抽象的算法。深度学习与统计学习的关键区别在于前者可以从数据中自动学习更为深层的特征,所以深度学习更易建模,且能高效利用数据。目前,基于深度学习的目标检测算法分为一阶段(one stage)型和两阶段(two stage)型,前者以YOLO(you only look once)系列算法(YOLO、YOLO-V2、YOLO-V3、YOLO-V4、YOLO-V5、YOLO-X)为代表[10-14],后者以R-CNN(region-based convolutional neural network)系列算法(R-CNN、Fast R-CNN、Faster R-CNN)为代表[15-17]。上述目标检测算法已应用于农产品检测领域,在田间或生产线上苹果[18-19]、冬青果[20]、茶芽[21]、番茄[22-23]、小麦[24-25]、青椒[26]等的检测任务中均取得了较好的效果。然而,不同于其他物料对象,浙贝母等级较多,且特级、一级和二级的外观特征相近,因此实现对浙贝母的精准检测具有一定难度。目前,还鲜有研究将目标检测算法应用于浙贝母的外观品质及直径的检测与分级中。
本研究将机器学习应用于浙贝母的无损检测中,创建浙贝母数据集,并在该数据集上训练、测试若干统计学习算法和基于深度学习的目标检测算法。为改善检测效果,本研究根据浙贝母数据集的特点,在YOLO-X主干特征提取网络的末端添加空洞卷积(dilated convolution)结构,并通过可视化中间激活的方式,从直观的角度对比、分析改进前后模型学习特征的差异,以实现浙贝母的无损检测,也为后续在线检测平台的搭建提供科学依据。
1 材料与方法
1.1 试验样品
本研究所用浙贝母产自浙江省金华市磐安县(28°57´05″—29°01´58″ N,120°28´05″—120°33´40″ E;海拔319 m)。浙贝母表面呈类白色或淡黄色,形状呈扁圆形,其稳定的摆放姿态有2 种,分别为正面(鳞叶开合一端)朝上和背面(鳞叶带梗一端)朝上(图1A1~A6)。特级、一级、二级浙贝母在形状、颜色、纹理等特征方面差异较小,主要以直径划分,直径越大,等级越高(图1A1~A3);霉变、虫蛀的浙贝母形状与正常浙贝母类似,但前者因微生物在其内部或表面大量繁殖,导致其外观呈深灰褐色(图1A4),后者表面有多个虫孔且常伴随絮状物,其外观颜色偏淡黄色(图1A5);破碎的浙贝母形状不规则、特征多变,很难利用固定的模型或阈值来进行表征(图1A6)。

图1 数据集部分图像(A1~A6)及图像采集设备(B)Fig.1 Partial images of data sets (A1-A6) and image acquisition equipments (B)
1.2 图像采集
为模拟浙贝母实时在线检测场景,本研究采用DigiEye System-700mm Cube 数字电子眼系统(英国VeriVide 公司)作为图像采集设备,其硬件由D7000 单反相机(日本Nikon 公司)、带有反光涂层的黑箱、条形光源和盛放样本的底板组成(图1B)。为使图像最大程度地还原浙贝母真实的颜色、形状以及纹理等特征,减少物料表面由光源所造成的高光区域,经反复试验,本试验光源采用漫反射光照模式,拍摄距离为45 cm。基于上述条件,对2 种摆放姿态下的6 类浙贝母各拍摄200 张图像,共计拍摄2 400 张单目标图像,部分图像如图1A1~A6所示。为丰富数据集种类,提高目标检测模型的泛化能力,本研究还拍摄了400 张多目标图像。为平衡不同级别浙贝母的数量,多目标图像中各类不同摆放姿态的浙贝母数量相同,且呈单列化分布。
1.3 研究方法
本研究总体思路如图2所示。首先准备浙贝母数据集,用于训练和测试不同的统计学习算法和目标检测算法;然后在检测效果最好的预选算法的基础上,针对浙贝母数据集的特点对算法进行相应的改进与优化,以改善模型的检测效果。
1.3.1 数据集制作
目标检测算法有固定的输入尺寸,一般为32的倍数,当输入图片不满足要求时,会调整其大小,以满足尺寸要求。为适应神经网络的输入,将图像从4 928×3 264剪裁成3 200×3 200,以便目标检测算法对其进行等比放缩,避免对图像中的感兴趣区(region of interest, ROI)造成拉伸、扭曲,从而使图像保留原来的形状、尺寸等特征。利用Labelimg软件对图像进行标注,并将带注释的标签文件以扩展名为xml 的格式保存。图像数据集共包含“superfine”“level one”“level two”“moth-eaten”“mildewed”和“broken”6类标签,分别对应特级、一级、二级、虫蛀、霉变、破碎浙贝母,每类浙贝母均有800 个标签,因此浙贝母图像数据集共有4 800个标签。该数据集的ROI占比较大,但图像数量较少(共2 800个),因此训练集、验证集、测试集按6∶2∶2 的比例划分,即训练集1 680个,验证集560个,测试集560个。
基于浙贝母图像,本研究提取了浙贝母形态(M)、颜色(C)和纹理(T)特征,建立了浙贝母特征数据集F=[M,C,T]=[M1,M2,M3,M4,M5,M6,M7,M8,M9,C1,C2,C3,C4,C5,C6,C7,C8,C9,C10,C11,C12,C13,C14,C15,C16,C17,C18,T1,T2,T3,T4,T5,T6,T7],其中:M1~M9代表形态特征,包括周长、面积、长轴、短轴、直径、矩形度、圆形度、紧凑度和细长度;C1~C18代表颜色特征,包括图像在RGB(红、绿、蓝)、HSV(色调、饱和度、亮度)颜色空间下各通道的一、二、三阶矩;T1~T7代表纹理特征,包括基于灰度共生矩阵提取的能量、对比度、相关度、熵、同质性、均值和标准差。因此,特征数据集F 的属性空间为34 维,样本量为2 400个。由于样本较为稀疏,本研究使用Origin 9.1软件对浙贝母特征数据集进行降维处理。降维后的属性空间为9维,信息保有量为原来的96.56%。
1.3.2 预选算法
本研究利用决策树(decision tree, DT)和支持向量机(support vector machine, SVM)对降维后的浙贝母特征数据集进行建模。DT是一种监督学习方式的分类和回归模型,利用数据特征对数据进行一系列条件判定(if or else)与划分,以提高划分后数据子集的信息纯度。DT通过训练集确定划分属性及其在决策树中的位置,从而产生一棵处理未见示例能力强的决策树。SVM 是一种监督学习方式的分类模型,在样本空间中寻找一个超平面wTx+b=0,使其最近的正负样本(支持向量)到该超平面的距离(间隔)最大,从而区分不同类别的样本。其中:x为样本特征向量,w=(w1,w2,...,wd)为超平面法向量,T为矩阵转置,b为位移项。
本研究利用浙贝母图像数据集训练和测试了YOLO 系列(YOLO-V3、YOLO-V4、YOLO-V5 和YOLO-X)和Faster R-CNN 目标检测算法。其中,Faster R-CNN会在图像中生成大量可能包含待检测物体的建议区域(region proposal, RP),然后通过分类器判别每个RP内是否包含待检测物体,并对物体及其位置进行分类和回归,从而得到待检测物体的边界框(bounding box),再过滤掉置信度不高或重叠的建议区域,进而得到检测结果。YOLO 系列为实现更快的检测速度,采用预定义建议区域的方法,将生成候选区和检测目标合二为一,直接在输出层回归建议区域的位置和所属类别,并通过将建议区域划分成不同尺寸网格的方式,检测不同尺度的目标。YOLO 系列含有主干特征提取网络(backbone)、特征金字塔网络(feature pyramid network, FPN)、预测结构(YOLO-head)3 个模块。表1 为本试验所选YOLO系列主干特征提取网络的特点总结。利用主干特征提取网络提取图片特征,并在特定的位置将其输入到FPN 中,以进行进一步的特征提取与融合,其输出张量的通道数(D)按照公式(1)计算:

表1 YOLO系列的主干特征提取网络特点Table 1 Characteristics of backbone feature extraction network of YOLO series
D=s×n×(p+xoffset+yoffset+h+w+1).(1)
式中:s为建议区域被划分成网格的数量;n为每个网格中存在的边界框数量;p为属于某一类标签的置信度;xoffset、yoffset为网格中心点调整参数;h、w分别为网格高和宽的调整参数。将FPN 的输出结果输入YOLO-head 模块,以整合特征并调整通道数,最终获得预测结果。
1.3.3 训练设备及策略
试验采用相同配置的计算机来训练上述预选算法。计算机的操作系统为Windows 2019;中央处理器(central processing unit, CPU)型号为英特尔9900k;图形处理器(graphics processing unit, GPU)型号为NVIDIA Tesla V100-SXM2(32 GB DDR4 RAM);通用统一计算设备架构(compute unified device architecture, CUDA)的版本为11.2,CUDA 深层神经网络库(CUDA deep neural network library,cuDNN)的版本是8.1.1;编程语言采用Python 3.7;深度学习框架采用PyTorch 1.7。
DT 主要有信息增益、信息增益率和基尼指数3种选择最优划分属性的方法,其代表算法分别为迭代二叉树3 代(iterative dichotomiser 3, ID3)、C4.5 和分类回归树(classification and regression tree, CART),CART可处理分类和回归任务。由于浙贝母特征数据集的属性取值为连续型数值,因此本研究采用CART决策树方法进行试验,并使用基尼指数来选择划分属性,使其生成叶子节点较小的树。为避免过拟合,本研究对决策树进行剪枝。经前期试验发现,当决策树的深度增加时,过拟合现象就会更严重,其深度为5 时拟合状态最佳。利用SPSS PRO 软件进行模型训练。核函数的选择是SVM性能的关键,本研究基于浙贝母特征数据集,训练并测试了不同核函数以及不同多分类融合策略的模型。
深度学习采取微调训练策略,即将视觉目标分类(visual object class, VOC)数据集或上下文中常见对象(common objects in context, COCO)数据集中预训练好的模型权重作为预选算法的初始权重,并在浙贝母训练集上进行迁移训练。理想的模型是其训练损失曲线不再有大幅波动或刚好介于欠拟合与过拟合之间,为找到该界限,经多次试验发现,当训练总轮次达到200 时,模型的训练损失曲线不再有大幅波动,趋向平缓,说明此时模型接近收敛或已收敛。为优化训练策略,经多次试验发现,将冻结训练轮次设为50,解冻训练轮次设为150,学习率设为0.001,冻结批大小设为8,非冻结批大小设为4 时,训练损失曲线的下降速度最快。为找出训练所得的最优模型,本试验保存了每轮次训练所得模型的权重文件,待训练轮次满200后,从中挑选出训练损失函数值最小的模型作为对应算法的最终训练所得模型。
1.3.4 基于YOLO-X 的改进算法
前期预试验发现,目标检测模型对特级、一级、二级浙贝母的检测能力较弱,推测图像集中的ROI较大,导致目标检测模型对浙贝母的尺度特征不敏感。
目标检测模型对尺度特征的敏感度与感受野的大小有关,通常可通过调整网络深度来控制。一般而言,网络层数越深,感受野越大,目标检测模型的特征提取能力越强,检测效果就越好。但网络层数达到一定限度后,随着网络层数的增加,模型的错误率也会增加,信息丢失会更加严重;同时,网络层数加深可能会导致梯度消失和色散问题,从而影响模型的检测精度。此外,在训练过程中,当模型对特征图进行下采样时,也会丢失一些小目标特征信息,导致检测精度下降。空洞卷积是针对图像语义分割问题中因下采样导致图像分辨率降低、信息丢失而提出的一种卷积方法,能够在不增加卷积核数量或大小的条件下,提供更大的感受野,使之输出更大范围的信息(long-ranged information),也可避免因进行池化(pooling)而导致小目标信息丢失的情况。感受野大小按照公式(2)~(3)计算,带填充的空洞卷积输出图片的高和宽按照公式(4)~(5)计算。
式中:F1为正常空洞卷积的感受野大小;F2为带填充的空洞卷积的感受野大小;r为空洞率,其值越大,表示模型的感受野越大;k为卷积核大小;p为边缘填充值;Hin(Hout)和Win(Wout)分别为输入(输出)图片的高和宽;s为步距。
预选算法中YOLO-X的检测效果较好,因此本研究选择在YOLO-X主干特征提取网络的末端(主干特征提取网络输出层Dark5 处)添加一层空洞卷积结构(图3A)。为使所添加的空洞卷积结构与原模型相应位置的输入、输出张量尺寸相匹配,本研究选择带填充的空洞卷积作为嵌入结构。如图3B 所示,原Dark5 模块处输出张量尺寸为20×20×1 024,在经过空洞卷积处理后,根据公式(1)、(3)~(5)计算,其张量尺寸仍为20×20×1 024,与FPN对应接收端的张量尺寸保持一致,以便后续特征融合与重用。为探究最佳空洞率,本研究测试了空洞率为2、3、4、5、6时的空洞卷积结构。改进后的主干特征提取网络命名为CSPDarkNet53-DC,对应的目标检测算法命名为YOLOX-DC(图3)。
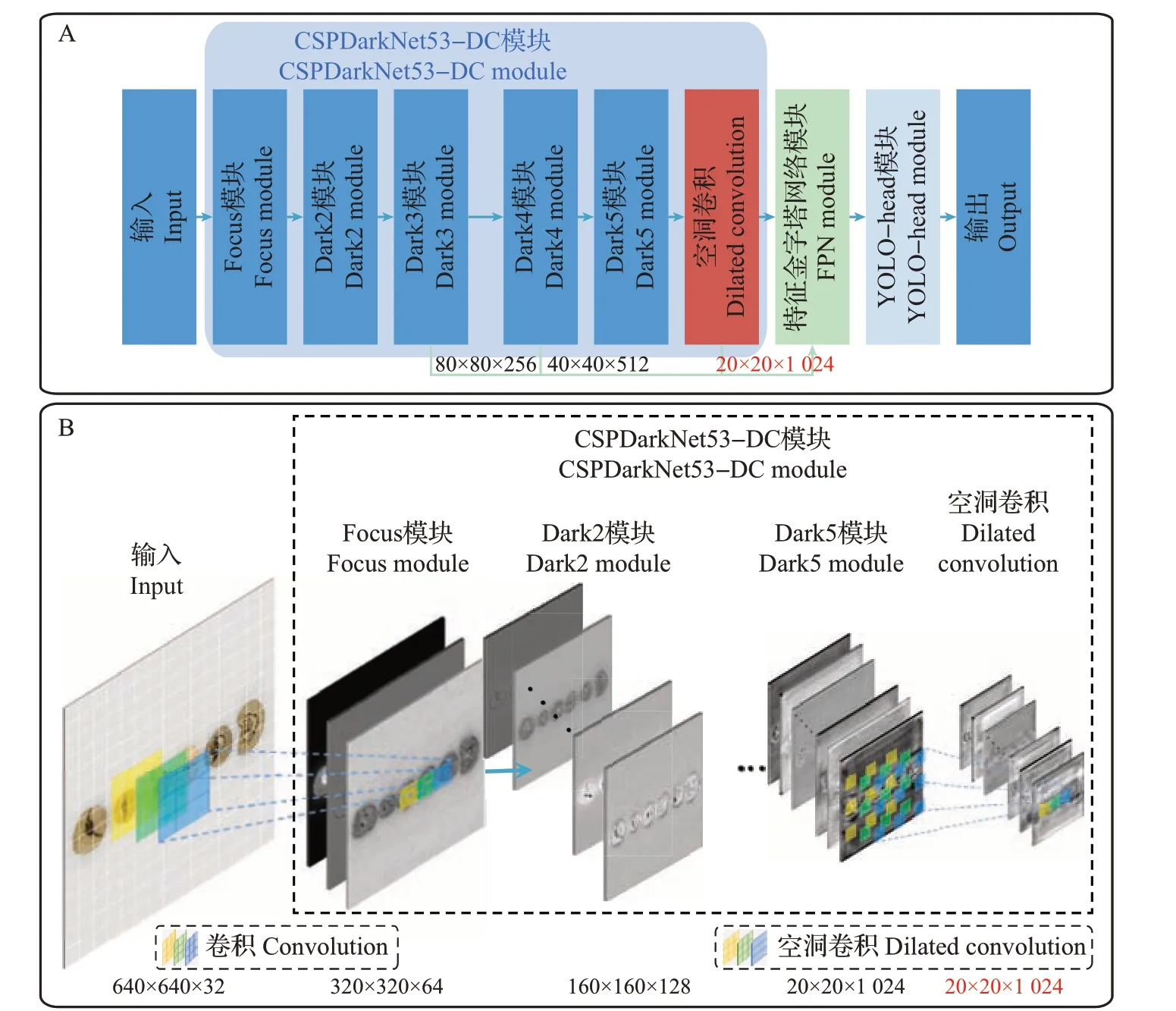
图3 YOLOX--DC结构(A)及其主干特征提取网络推断流程(B)示意图Fig.3 Schematic diagrams of YOLOX-DC structure (A) and its backbone feature extraction network inference process (B)
1.3.5 测试结果评价指标
对于统计学习模型,采用精确率(precision,P)、召回率(recall,R)、F1和准确率(accuracy,A)作为评价指标;对于目标检测模型,采用平均精确率(average precision, AP)、平均精确率均值(mean average precision, mAP)、F1和 每 秒 传 输 帧 数(frames per second, FPS)作为评价指标[27]。试验根据预测结果对正负例(正负样本)划分的正确性将所有样本划分为4 种类型,分别为真正例(true positive,TP)、真负例(true negative, TN)、假正例(false positive, FP)、假负例(false negative,FN)。其中,TP代表被正确分类的正样本,即某类浙贝母被正确分类的数量;TN代表被正确分类的负样本,即其余类别浙贝母被正确分类的数量;FN代表被错误分类的正样本,即某类浙贝母被错误分类的数量;FP代表被错误分类的负样本,即其余类别浙贝母被错误分类的数量。
利用上述4类数据对P、R、A进行定义。P的具体含义为在预测结果是正样本的所有样本中,模型预测正确的比例。R的具体含义为在真实结果是正样本的所有样本中,模型预测正确的比例。A的具体含义为在总样本中,模型预测正确的比例。P、R、A分别按照公式(6)~(8)计算。
F1为P和R的加权调和平均数,综合考虑R和P,F1按照公式(9)计算。
将所有样本按其分类的置信度进行排序,并计算每个样本所对应的置信度作为正、负样本划分阈值中的P和R,对不同置信度下的P和R作图,得到精确率-召回率(precision-recall,P-R)曲线,P-R曲线与坐标轴所围的面积为AP,且AP 按照公式(10)计算。
mAP 为所有类别AP 的平均值,且mAP 按照公式(11)计算。
式中,c、C为样本类别数量。
FPS 用来反映模型处理图像的速度,且FPS 按照公式(12)计算。
式中,N和Tn分别表示模型在一段时间内处理图像的数量以及处理该帧数图像所用的时间。
2 结果与讨论
2.1 预选算法测试结果
试验拍摄了2 800张浙贝母图像作为原始数据集,并基于该数据集训练并测试DT、SVM、YOLOV3、YOLO-V4、YOLO-V5、YOLO-X 和Faster RCNN算法。以P、R、F1、A、AP、mAP和FPS作为模型的评价指标。
DT 和SVM 对破碎浙贝母的分类能力普遍较弱,但对其余类别浙贝母的分类更为准确。推测是由于破碎的浙贝母形状不规则、特征多变,因此很难利用固定的特征或阈值对其进行表征。此结果也验证了传统机器学习的局限性,即当原有数据的规律不明显以及研究人员无法充分提取有效特征时,数据便无法被有效利用,最终导致模型分类效果不佳。
对于目标检测算法,训练过程中特级、一级和二级浙贝母的训练收敛速度慢于虫蛀、霉变、破碎浙贝母,且所得模型对仅直径不同的特级、一级、二级浙贝母的检测能力普遍较弱,其AP 和F1均低于虫蛀、破碎、霉变浙贝母的对应指标(表2)。其中,YOLO-X对特级、一级、二级浙贝母的整体检测效果优于其他算法,其AP分别为98.39%、72.22%、96.59%,F1分别为0.90、0.63、0.84,但仍不及该模型对虫蛀、破碎、霉变浙贝母的检测效果。推测是因为虫蛀、破碎、霉变浙贝母颜色、形状和纹理等特征的差异可被目标检测算法有效识别,从而进行区分,而特级、一级、二级浙贝母在上述特征方面相似,所以只能以直径尺度为特征进行区分。此外,本研究的图像数据集中的ROI占比较大,模型的感受野相对较小,导致其对直径尺度特征不敏感,并且一级浙贝母的直径刚好介于特级浙贝母和二级浙贝母之间,所以模型容易将一级浙贝母误判为特级浙贝母或二级浙贝母,最终导致对一级浙贝母的检测效果不佳。这也说明在农产品检测领域,此类算法可能更适合检测以形状、颜色、纹理等为差异特征的产品。在检测速度方面,各目标检测算法的FPS 均能满足实际检测要求。

表2 预选算法训练所得模型在浙贝母测试集上的测试结果Table 2 Test results of models trained by preselective algorithms on the test set of F. thunbergii
2.2 YOLOX-DC 测试结果
根据预选算法的测试结果推测,如果要改善统计学习模型对破碎浙贝母的检测效果,就需要人为提取更多形态、颜色和纹理方面的特征;如果要改善目标检测模型对特级、一级、二级浙贝母的检测效果,则需要加强算法对尺度特征的敏感度。由于预选算法中YOLO-X所得模型的效果最佳,因此后续研究以YOLO-X为基础进行改进(改进后的算法命名为YOLOX-DC)。
目标检测模型对尺度特征的敏感度与感受野的大小有关,而空洞卷积可在不增加卷积核数量或大小的情况下提供更大的感受野,使之输出更大范围的信息,因此,本研究在YOLO-X 主干特征提取网络的末端分别添加了一层空洞率为2、3、4、5、6的带有填充的空洞卷积结构。结果(表3)表明:空洞率为4时,模型的检测效果最佳,其mAP达到98.95%,特级、一级、二级浙贝母的AP分别为99.97%、98.33%、98.47%,F1分别为0.99、0.92、0.94。与原模型相比,空洞率为4的改进后模型(以下简称“改进后模型”)的mAP 提高了4.95 个百分点,一级浙贝母的AP 提高了26.11个百分点,F1提高了0.29。原模型与改进后模型的检测效果如图4~5所示:前者对图像的误检或漏检多发生在特级、一级、二级浙贝母上;后者对各类别浙贝母的判别均正确,且置信度较高,预测框与浙贝母紧密贴合,呈现外接矩形状态,说明模型对其位置的回归也相对更为准确。

表3 不同空洞率的YOLOX-DC训练所得模型在浙贝母测试集上的测试结果Table 3 Test results of models trained by YOLOX-DC with different dilated rates on the test set

图4 YOLO-X的预测效果Fig.4 Prediction results by YOLO-X
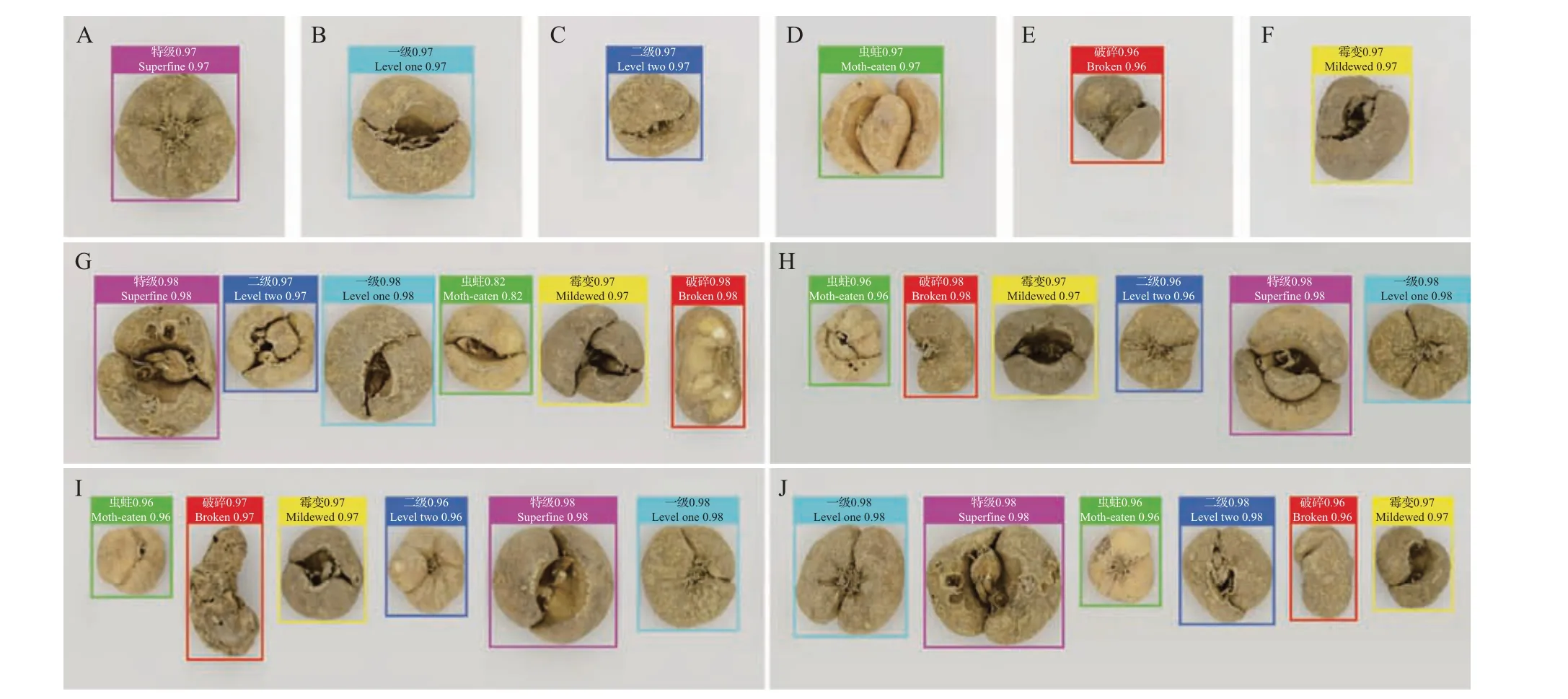
图5 YOLOX-DC(空洞率为4)的预测效果Fig.5 Prediction results by YOLOX-DC (dilated rate=4)
2.3 可视化中间激活
相较于手动提取特征的统计学习,深度学习可以自动提取更为抽象的特征。为分析原模型与改进后模型所学特征的差异,本研究通过可视化中间激活的方式加以探究。所谓可视化中间激活,即将网络中各卷积层和池化层等输出的特征图进行可视化展示。由于特征图数量庞大,本试验基于浙贝母单目标和多目标图像,将YOLO-X 与YOLOX-DC 模型每层输出的特征图间隔5 张进行可视化,并选择2 个模型的有效主干特征提取网络(Dark3、Dark4、Dark5)对应位置处的中间激活进行对比。
如图6~7所示:随着神经网络层数的加深以及对输入图片的重复下采样,其中间激活的像素值越来越小,图像愈发模糊、抽象,但YOLOX-DC 模型的中间激活较YOLO-X 更加清晰,尤其在深度为Dark5 时,YOLO-X 输出的中间激活基本失真,而YOLOX-DC 输出的中间激活仍保有其外形轮廓。此外,对于单目标图像,YOLOX-DC 中间激活的ROI 普遍比YOLO-X 大(图6);对于多目标图像,YOLOX-DC 中间激活的ROI 外层普遍有一圈清晰可见的包络线(图7),说明改进后模型在对图像进行前向推断的过程中,与浙贝母之间保持着较强的联系,即改进后模型将多目标看作单一整体,避免了“盲人摸象”的情况,这也是感受野扩大的直观体现。以上可视化中间激活的结果直观地证明,向模型的主干特征提取网络嵌入空洞卷积的方式可以提高其对尺度特征的敏感度。受此启发,对于其他数据集而言,YOLOX-DC 也可根据其ROI 的不同设置不同的空洞率,以调整感受野大小,从而适应该数据集的尺度特征,进而更好地实现对主要以尺度为特征产品的检测。

图6 YOLO-X和YOLOX-DC基于浙贝母单目标图像对应位置的中间激活Fig.6 Intermediate activation based on the corresponding positions of single object images of F. thunbergii by YOLO-X and YOLOX-DC
3 结论
本研究将机器视觉和机器学习技术应用于浙贝母外观品质及直径的检测与区分中。首先对比了统计学习和深度学习算法对浙贝母分级的效果,结果显示YOLO-X所得模型的检测效果较好;其次针对浙贝母的特点,向YOLO-X主干特征提取网络的末端嵌入一层空洞率为4的带填充的空洞卷积结构,在不增加参数量、计算量或对原模型进行大规模改动的情况下,促进了改进位点处的特征融合与重用,扩大了模型的感受野,提高了模型对尺度特征的敏感度,从而更好地适应试验创建的浙贝母数据集。与其他目标检测算法相比,改进后算法所得模型(空洞率为4)针对浙贝母图像数据集的检测效果更佳,其特级、一级、二级、虫蛀、霉变、破碎浙贝母的AP分别为99.97%、98.33%、98.47%、98.71%、99.73%、98.85%,F1分别为0.99、0.92、0.94、0.97、0.99、0.97,mAP 为99.01%,FPS 为29.13。本研究还通过可视化中间激活的方式,直观地对比了改进前后模型所学特征的差异,从而对所作改进加以解释与分析。本研究为浙贝母无损检测平台的搭建提供了科学依据,有望推动浙贝母市场的发展。同时,本研究提出的方法还可为其他同类产品的无损检测提供思路。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
中成药(2018年5期)2018-06-06
北京航空航天大学学报(2018年1期)2018-04-20
中成药(2018年1期)2018-02-02
中成药(2017年9期)2017-12-19
中成药(2017年6期)2017-06-13
故事作文·高年级(2017年2期)2017-03-01
新闻传播(2015年20期)2015-07-18
电视技术(2014年19期)2014-03-11
