
Vision Transformer的瞳孔定位方法*
2024-01-02 07:43王长元
西安工业大学学报 2023年6期
王 利,王长元
(1.西安工业大学 光电工程学院,西安 710021;2.西安工业大学 计算机科学与工程学院,西安 710021)
人眼包含了与人类行为相关的大量信息,是人类感知周围世界、表达自身意图以及情感交流的重要线索。人们可以通过人眼追踪对人类的行为进行分析。随着计算机视觉技术的飞速发展,人眼追踪技术在人机交互[1-3]、医学诊断[4-6]、虚拟现实[7-8]、识别系统[9-10]等多个领域都发挥了巨大的作用。视线估计是人眼追踪的重要步骤之一。在视线估计的过程中,需要使用瞳孔中心、瞳孔椭圆等瞳孔特征[11-17]来估计注视点的位置或注视的方向。瞳孔定位的准确性会显著影响视线估计的最终精度[18-19]。因此,研究如何实现快速、精准的瞳孔定位具有重要的意义。
传统的瞳孔定位方式主要根据瞳孔的形状结构、灰度信息来实现瞳孔的定位。例如文献[20]将改进的霍变换算法应用到瞳孔中心点的检测中,实现了较好的瞳孔定位效果,但是该方法仍然存在需要手动设置算法参数、灵活性差的缺陷。文献[21]利用人眼的灰度信息定位人眼区域。该方法的优点是计算量小,缺点是定位精度较低。文献[22]首先通过直方图的谷值得到的阈值分割出瞳孔轮廓,再根据瞳孔灰度的梯度特性和亚像素定位算法实现瞳孔边缘点检测,最后采用椭圆拟合得到瞳孔中心。这种方法存在对瞳孔图像质量要求较高且椭圆拟合速度较慢的问题。文献[23]通过灰度积分投影和最大类间方差对人眼图像进行粗略分割,然后借助多团块筛选条件分离出瞳孔图像,再使用改进的径向对称变换方法得到瞳孔中心。此算法虽然自适应性良好,但是不适用于变形瞳孔的检测。
近年来,由于深度学习的飞速发展,基于卷积神经网络(Convolutional Neural Network,CNN)的瞳孔定位技术受到越来越多的关注。这类方法都是将大量的训练样本输入到卷积网络中进行学习,从而拟合出人眼外观与瞳孔参数之间的关系。例如,文献[24]提出一种级联的卷积神经网络定位瞳孔中心位置。此网络采取从粗到细的定位策略,先识别出瞳孔的粗略位置,再进一步细化得到瞳孔中心。这种方法在瞳孔受到遮挡时效果较差。文献[25]设计了一种名为DeepEye的瞳孔检测框架。虽然它在多个数据集中的5像素误差内的瞳孔检测率均超过70%,但算法的鲁棒性不佳。文献[26]在提出的瞳孔检测与跟踪的混合网络中,提出一种基于CNN的名为VCF的网络共同确定瞳孔的位置。该方法虽然在5像素误差内的获得较高的瞳孔检测率,但是网络结构复杂,且在1像素误差内的检测效果较差。
基于深度卷积神经网络的瞳孔定位方法在检测精度和鲁棒性上都优于传统的方法,但是它忽略了图像内部的长距离依赖关系。这些关系能够增强图像的语义表示能力,从而提高瞳孔定位的准确性。因此,为了丰富瞳孔图像的语义特征、提高瞳孔定位的精度,提出了一种基于混合视觉转换器(Vision Transformer,ViT)网络的瞳孔定位方法。该方法使用CNN从人眼图像中学习局部特征映射,再将这些特征送入ViT的编码器中捕获全局关系,最后进行瞳孔中心的精确预测。
1 实验方法
1.1 残差网络
残差网络(Residual Network,ResNet)[27-28]是一种经典的卷积神经网络。残差网络增加了网络的深度,使得它的特征提取能力大大增强,同时也使梯度下降的问题得到了一定程度的缓解。但是,随着网络的进一步加深,优化网络的难度加大,残差网络仍然不能根除梯度下降的问题。为此,出现了对ResNet进行改进的带有Split-Attention的深度残差网络(Residual Convolutional Neural Networks with Split-attention,ResNeSt)[29]网络。ResNest网络添加了Split-Attention 模块,能够加深跨通道之间的相互作用,增加所提特征的多样性。
ResNeSt的block结构如图1所示,总体流程如下。
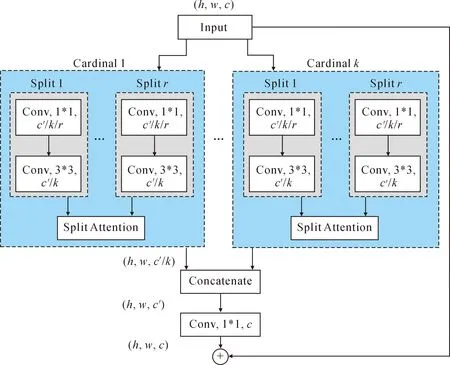
图1 ResNeSt的block结构图
① 将输入的特征图分成K个基数组,再把每个基数组又分成R个小组,因此输入的特征图最后被划分为K*R组。
② 对每个基数组内的R个小组执行1×1和3×3的卷积运算,将得到特征图组送入Split-Attention模块。Split-Attention 模块结构如图2所示。Split-Attention 模块先对R个特征图小组进行全局平均池化,得到各通道的c维的权重向量。之后对各通道权重向量使用BN+ReLU以及softmax操作进行修正。在这个过程中,用两个全连接层实现注意力机制方程。最后将修正后的权重向量与输入的原始特征组相乘,并对相乘后的结果求和可以获得对应基数组的输出。
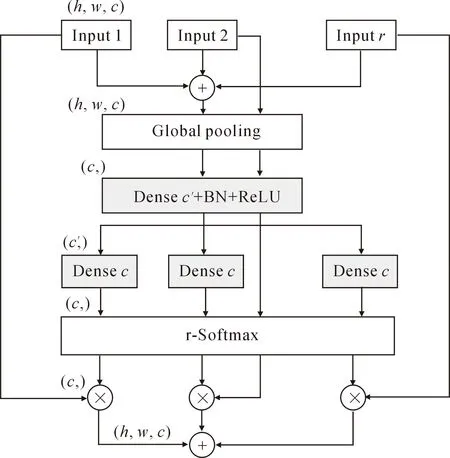
图2 Split-Attention 结构图
③ 将全部的基数组经过Split-Attention 模块后获得的通道权重通过concate操作连接起来。
④ 执行1×1卷积运算,并将ResNeSt Block的原始输入特征融合进来。
1.2 Vision Transformer网络
Transformer[30]模型在自然语言处理领域中具有里程碑式的意义。随着研究的不断深入,Transformer架构开始应用于计算机视觉任务中。2020年文献[31]提出了一种完全基于自注意力机制的图像分类模型即ViT,成为计算机视觉技术的重大突破。
ViT为了将图像转化成 Transformer 结构可以处理的序列数据,引入了图像块的概念。因为标准的Transformer的输入必须是一维Token Embedding序列,所以ViT先把图像分割为固定大小的块,并生成这些块的线性嵌入序列,然后就可以作为Transformer的输入。此过程可描述如下:
已知F∈RH×W×C,这里(H,W)为图像的分辨率,C为通道数。F被分成N个扁平的2D块XP∈RN×(p2·C),其中N=HW/p2。将每个块通过可学习的投影矩阵E映射成一个D维的嵌入向量,并在D维的嵌入向量之前添加额外的标记Xtoken。Xtoken也是D维可学习的嵌入向量,能够更好的表示全局信息。之后引入位置编码Epos,加入块的位置信息。最终,就得到了块嵌入z0,
(1)
z0被送入ViT的编码器中,由层归一化(LayerNorm,LN)、多头注意力机制(Multi-Head Self-Attention,MSA)及多层感知器(Multilayer Perceptron,MLP)顺序处理。处理过程如式(2)~(3)所示。
(2)
(3)
将层归一化应用在多头注意力机制模块和多层感知器模块之前,将残差连接应用在多头注意力机制模块和多层感知器模块之后。
1.3 瞳孔定位模型
提出的瞳孔定位模型如图3所示。将卷积神经网络作为特征提取器提取人眼图像的局部特征。此卷积神经网络的主干框架是ResNeSt结构。然后,将提取的局部特征输入到Transformer的编码器中以此获全局跨位置信息。最后,通过全连接层输出人眼图像的瞳孔中心。
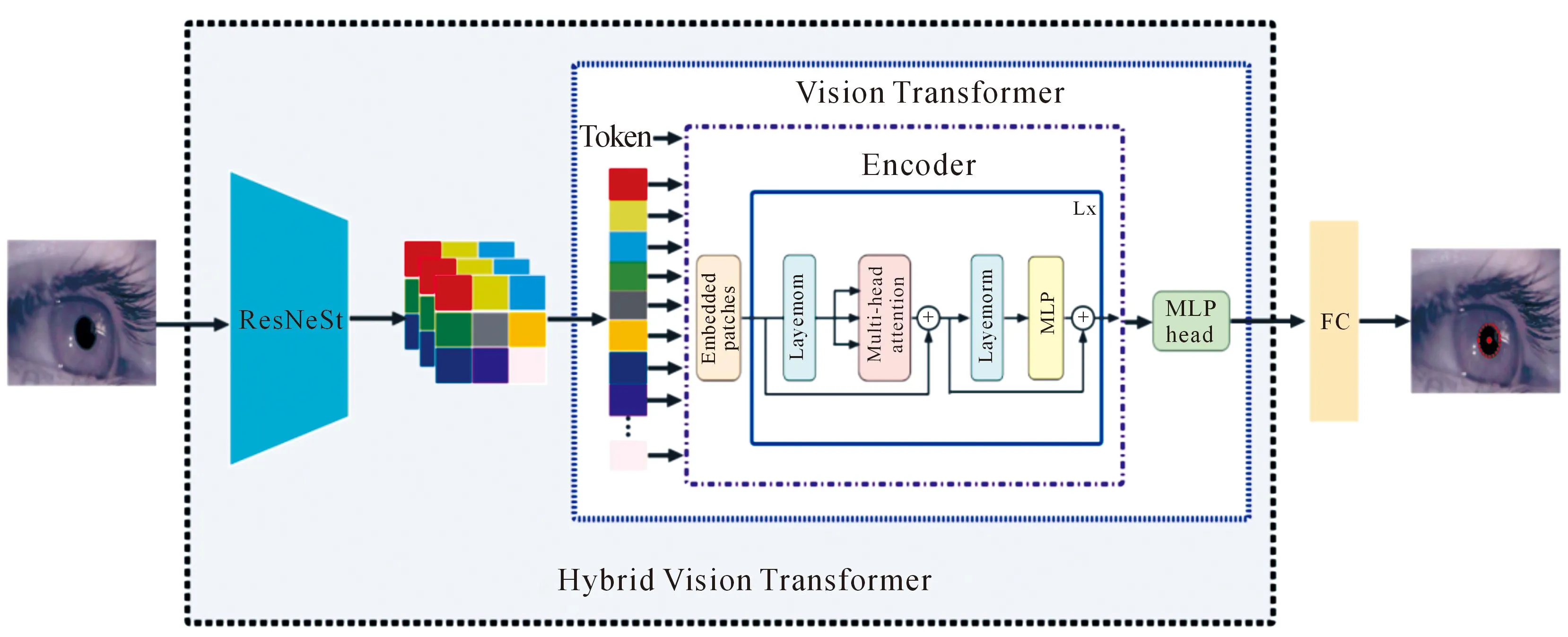
图3 瞳孔定位模型
2 实验及结果分析
2.1 实验数据
实验使用了两个数据集,分别命名为数据集A和数据集B。数据集A是Tonsen团队建立的数据集(Labelled Pupils in the Wild,LPW)。该数据集记录了22个参与者在注视移动的红球过程中的眼球运动的视频图像。此数据集共有130 856张图片,部分图像示例如图4(a)所示。
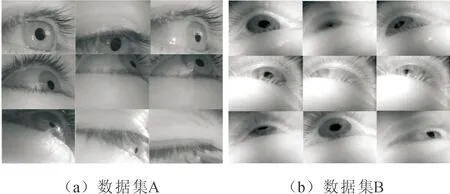
图4 数据集的图像示例
文中从LPW数据集中随机选取了5 000张图像。其中,前80%作为训练集,后20%作为测试集。数据集B是Swirski团队收集的用于瞳孔跟踪的数据集。它有3 760张眼睛图片,其中手工标记了600张图片。图像示例如图4(b)所示。将标记的600张图像的前80%作为训练集,后20%作为测试集。
2.2 模型训练参数及实验配置
每个实验的网络训练次数epochs为300,每次训练的batch size为32,学习率是可变的。前170 epochs是10-3,后130 epochs是10-4。模型训练的损失函数为L1-loss,其表达式为
(4)
L1-loss损失函数广泛用于深度学习网络,对于任何形式的输入样本都能保持稳定的梯度,能够避免梯度爆炸的问题。异常样本值对L1-loss结果影响不大,并在优化过程中,更利于快速找到全局最优解。
瞳孔检测网络模型的构建、训练与测试均在 Pytorch下完成。Pytorch是应用较多的开源深度学习平台。实验硬件及运行环境参数见表1。

表1 实验硬件及运行环境参数
2.3 消融实验结果及其分析
将所提瞳孔定位模型分别用在选定的数据集A和数据集B上。瞳孔中心定位的评估指标是网络模型的输出值与标签值之间的欧式距离。文中构建的瞳孔定位混合网络模型由ResNeSt模块、ViT模块以及全连接层共同构成,为了评估各个模块对网络性能的影响,通过不同对照组的消融实验来分析网络模块的有效性和贡献度。
消融实验的对照组组合为ResNeSt模块+全连接层、ViT模块+全连接层以及文中所提的完整模型。为了直观地展示对照组瞳孔定位结果,统计了它们在不同数据集上瞳孔定位误差小于5像素的图像的百分比。其瞳孔中心定位精度见表2。

表2 瞳孔中心的定位精度结果
从表2可以看出模型的完整程度与检测精度存在正相关的关系,并且ViT模块对检测精度的性能影响要比ResNeSt模块大。
2.4 对比实验结果及其分析
为了评估基于混合ViT的瞳孔定位模型的性能,将其与DeepEye模型、VCF模型也用在文中的数据集上进行比较。5像素内的检测精度如图5所示。
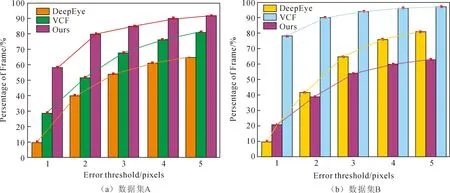
图5 瞳孔中心定位结果对比图
从图5可以看出文中模型在数据集A中的1像素误差内的检测率为58%,而VCF的检测率只有29%,DeepEye甚至不到11%。在小于5像素误差的范围内,文中模型的检测率为92%,比VCF高11%,比DeepEye高17%。在数据集B中,文中模型进行瞳孔定位时仅在1像素内的误差就高达78%,比VCF在5像素误差内的检测率还要高。虽然,DeepEye的检测率也高于VCF,但是与文中所提模型相比仍然存在较大的差距。图5的结果表明文中所提模型在进行瞳孔定位时的性能均优于VCF和DeepEye。
为了进一步对比模型的性能,计算了每个模型每次训练的平均运行时间,见表3。

表3 模型的运行时间对比
从表3可以看出,文中所提模型的运行时长位于DeepEye和VCF之间。这是因为DeepEye结构相对简单,所以运行时长较短,而VCF的模型结构最为复杂,所以运行时长较长。文中所提模型结构的复杂程度处于DeepEye和VCF之间,因此运行时长属于二者的折中。
3 结 论
使用深度卷积神经网络进行瞳孔定位不论是检测精度还是鲁棒性,都高于传统的瞳孔定位方法。但是,卷积网络的感受野范围有限,不能有效捕获全局特征。而Vision Transformer网络在计算机视觉的许多任务中都取得了优秀的成果,因此文中将其用于人眼的瞳孔定位中。为了提高瞳孔定位的效率,使用混合结构的Vision Transformer模型提取人眼图像的特征。混合结构的视觉转换器主要由卷积神经网络和Transformer的编码器两部分构成。它既能提取细粒度的局部特征,又能获取全局约束关系,能够学习到更加全面的瞳孔特征,从而提升瞳孔定位的精度。
为了验证文中方法的有效性,在两个公开数据集中测试了所提瞳孔定位模型的性能,并同其它瞳孔定位模型进行了对比。比较的结果显示文中方法在低于5像素误差的检测率都能达到90%以上,分别比主流的瞳孔定位模型DeepEye与VCF提升了30%和20%,取得了优秀的定位效果。由分析可知文中所提的模型实现了瞳孔精准定位的目标。但是,实验仍然存在实时检测能力欠缺的问题。在未来的工作中,将继续优化神经网络模型,使其在提高精确度的同时兼顾实时性的要求。
猜你喜欢
艺术家(2023年8期)2023-11-02
军事文摘(2023年20期)2023-10-31
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
快乐语文(2019年9期)2019-06-22
中学生数理化·八年级物理人教版(2018年11期)2019-01-31
青年歌声(2018年2期)2018-10-20
阅读与作文(初中版)(2017年6期)2017-07-05
优雅(2016年12期)2017-02-28
电影故事(2016年5期)2016-06-15
