
3种机器学习算法对维持性血液透析病人衰弱风险预测性能比较
2024-01-22 11:12汪丹丹姚侃斐祝雪花
护理研究 2024年1期
汪丹丹,姚侃斐,祝雪花
浙江中医药大学护理学院,浙江 310053
维持性血液透析(maintenance hemodialysis,MHD) 是终末期肾病病人主要的治疗方式[1]。但MHD 不能替代正常肾脏所有复杂的代谢和内分泌功能,长期血液透析的病人易出现一系列并发症,衰弱是最常见的并发症之一,其发病率为46%~50%[2-3]。有研究显示,衰弱会增加MHD 病人跌倒、骨折、功能障碍、死亡等的风险,与多种不良健康结局密切相关[4-5]。因此,对MHD 病人进行衰弱风险的早期预测从而降低病人衰弱的发生率、提高其生活质量至关重要。Logistic 回归、决策树CART 和随机森林是机器学习算法中的重要分类器,被广泛应用于风险预测研究中。3 种机器学习算法均能有效预测疾病的风险因素,但由于运算方法不同,3 种算法的预测性能有所区别。本研究利用Logistic 回归、决策树CART 和随机森林3 种算法分别构建MHD 病人衰弱风险的预测模型,并对比分析3种模型的预测效果,确定适用于MHD 合并衰弱的风险预测模型,以期为预防和早期干预MHD 病人并发衰弱提供参考依据。
1 对象与方法
1.1 研究对象
选取2021 年10 月—2022 年3 月于杭州市2 所综合性医院血液净化中心接受MHD 治疗的485 例病人作为研究对象。纳入标准:符合慢性肾脏病(CKD)/终末期肾病(ESRD)诊断标准;年龄≥18岁;规律血液透析治疗≥3个月 (≥3次/周),每次透析治疗时间≥3 h;具有一定的认知能力和沟通能力,能配合阅读、书写或回答问题;知情并自愿参与本研究。排除标准:意识障碍或有精神疾病病人;调查前2 个月内发生重大外伤 (脑外伤、骨折等)和严重后遗症,或合并有严重危及生命的原发性疾病者;病历数据不全者。本研究已获医院伦理委员会批准(批准号:20211014-3)。
本研究样本量按7∶3 划分为训练集和测试集。经理论研究整合发现可能的危险因素有16 个、MHD 病人衰弱的发生率为46%~50%,Logistic 回归模型要求阳性事件数是自变量的10 倍以上,决策树CART 及随机森林模型要求样本量大于解释变量的2 倍,故本研究采用Logistic 回归模型的样本量估算方法,纳入训练集病人341 例、测试集病人144 例。
1.2 研究工具
1.2.1 临床观察指标收集表
结合文献回顾和临床专家意见自行设计,主要调查病人的一般资料,如年龄、性别等,生活方式如吸烟史、饮酒史等,疾病用药情况如血液透析情况等,实验室指标如血管通路类型、血清清蛋白等。
1.2.2 Fried 衰弱表型
本研究以Fried 衰弱表型作为衰弱判定的标准,该量表为Fried 等[6]于2001 年基于临床大数据开发形成,是临床认可度高的衰弱测评工具,被广泛应用于血液透析及肾病病人群体中。量表共包含5 个条目,分别为不明原因的体重下降、自我报告的疲乏、躯体活动量降低、握力下降和步行速度减慢,符合5 个条目中任意3 个及以上即为衰弱,符合3~5 个判定为衰弱。
1.2.3 日常生活活动能力量表(Activity of Daily Living Scale, ADL)
该量表由Lawton 等[7]于1969 年编制,是国内外常用的用于测评病人日常生活能力的测评工具。该量表由躯体性生活自理能力量表和工具性日常生活能力量表两部分组成,共包含行走、吃饭、穿衣等共14 个条目。每个条目分别计1~4 分,总分为14~56 分,得分越高表示功能缺陷越明显,14 分为完全正常,>14~21分为ADL 轻度受损,>21 分为ADL 重度受损。
1.2.4 医院焦虑抑郁量表(Hospital Anxiety and Depression Scale, HADS)
该量表由Zigmond 等[8]于1983 年编制,主要应用于筛查综合医院病人的焦虑和抑郁情绪。相较其他焦虑和抑郁量表而言,该量表在医院中应用较多,更为贴合病人的实际情况,且题型精简,可同时测评病人的焦虑和抑郁水平,能较大程度地提高病人填写问卷的质量。该量表分为焦虑分量表和抑郁分量表两部分,分量表各7个条目,每个条目分别赋值0~3分,若分量表≥8 分即怀疑有抑郁或焦虑可能。
1.2.5 社会支持评定量表(Social Support Rating Scale, SSRS)
该量表由肖水源[9]基于国外较权威的评定量表制定,可较好地反映个体的社会支持状况,是国内评定社会支持水平的主要测评工具,较多研究证实该量表具有较好的信效度。量表包含客观支持(3 个条目)、主观支持(4 个条目)和对社会支持的利用度(3 个条目)3个维度共10 个条目,每个条目依据所选项分别计分,得分越高则社会支持度越高,≤31 分为社会支持不足。
1.2.6 查尔森合并疾病指数(Charlson Comorbidity Index,CCI)
该量表由Charlson 等[10]于1987 年为研究合并症与死亡风险之间的关系建立,研究证实共病是MHD 病人预后的强预测因子[11-12],该量表在血液透析病人并发衰弱的危险因素研究中具有重要作用。量表共19个条目,总分0~38 分,得分越高,合并疾病程度越重。
1.2.7 营养风险筛查评分(Nutrition Risk Screening,NRS-2002)
NRS-2002 由欧洲肠外肠内营养学会专家基于临床随机对照试验结果推荐,用于评定住院病人的营养风险[13]。该量表既包含各营养指标,同时基于证据对疾病的严重程度进行评分以反映因疾病而增加的代谢和营养需求,可全面评定病人的营养风险,已广泛应用于肾病及血液透析病人中。量表共3个条目,“是”计1分,“否”计0分,总分0~3分,评分≥3分为存在营养风险。
1.3 资料收集方法
采用面对面问卷调查。调查前,2 名护理研究生接受相关知识的培训和考核,以熟练掌握各量表的评判标准。调查中,在征得研究对象的知情同意后,采用统一的指导语进行面对面资料收集,所有条目均现场填写,错填或漏填选项及时反馈、更正,问卷有效回收率为100%。体检相关指标从临床电子信息平台提取。调查过程中每周开展双人交叉审核。
1.4 统计学方法
采用SPSS 25.0 进行统计描述,符合正态分布的定量资料采用均数±标准差(±s)描述,不符合正态分布的定量资料采用中位数、四分位数[M(P25,P75)]描述,定性资料用频数和百分比(%)描述。采用R 4.1.2进行模型构建,以训练集数据进行建模,应用单因素Logistic 回归初步筛选影响因素,将P<0.05 的变量纳入后续研究。采用Logistic 回归、决策树CART 和随机森林算法分别建立风险预测模型,利用训练集和测试集数据分别对3 种模型的预测性能进行比较分析。
2 结果
2.1 MHD 病人衰弱的发生情况
共纳入MHD 病人485 例,其中并发衰弱者205例(42.27%)。485例病人中,男318例(65.6%),年龄25~91[62(52,71)]岁;原发疾病:慢性肾小球肾炎185 例(38.14%),糖尿病肾病144 例(29.69%),高血压肾病28例(5.77%),其他128 例(26.39%)。训练集纳入病人341 例(70.31%),测 试 集 纳 入 病 人144 例(29.69%)。训练集和测试集各基线资料比较差异均无统计学意义(P>0.05),两组的衰弱发生率比较差异无统计学意义(χ2=0.958,P=0.328),提示训练集和测试集的各项指标较为均衡。
2.2 MHD 病人衰弱危险因素的单因素分析
根据病人是否并发衰弱,将训练集划分为衰弱组(n=149)和非衰弱组(n=192),对两组病人的一般状况开展单因素分析,结果显示,两组病人年龄、性别、体质指数(BMI)、文化程度、职业、婚姻、吸烟史、每日睡眠时间、日常锻炼情况、原发疾病、多重用药情况比较差异均有统计学意义(P<0.05);对两组病人的实验室指标进行比较,结果发现,两组血肌酐(Scr)、血管通路类型、总蛋白(TP)、清蛋白(ALB)、前白蛋白(PAB)、C反应蛋白(CRP)比较差异均有统计学意义(P<0.05);两组病人SSRS 得分、CCI 得分、ADL、焦虑、抑郁、NRS-2002比较差异均有统计学意义 (P<0.05)。详见表1~表3。

表1 MHD 并发衰弱一般状况相关危险因素单因素分析(n=341)
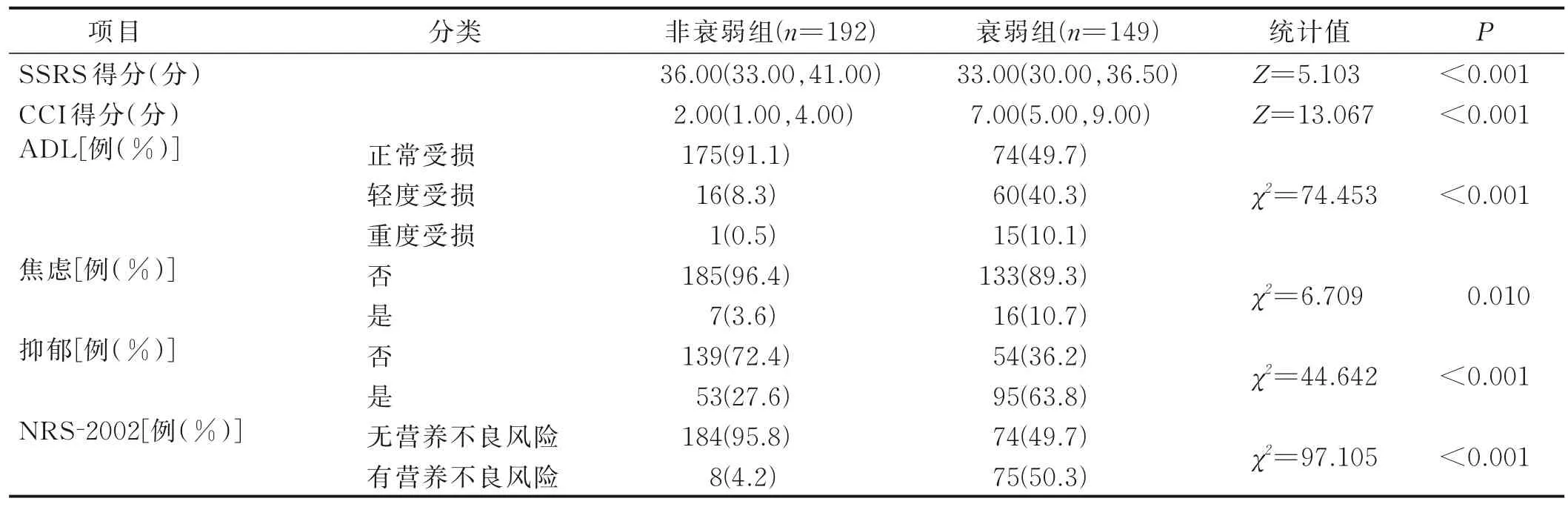
表2 MHD 并发衰弱其他危险因素的单因素分析(n=341)
2.3 MHD 病人衰弱风险的3 种预测模型
2.3.1 Logistic 回归模型
将单因素分析筛选出的具有统计学意义的22 个变量作为自变量,进行向后逐步回归分析构建模型。连续性变量以原值输入,分类及等级变量赋值见表4。根据赤池信息准则(AIC)原则,以最小AIC=164.3 为最优值,此时多因素Logistic 回归结果显示,年龄、性别、日常锻炼情况、ALB、SSRS 得分、CCI 得分、ADL、NRS-2002 是MHD 病人发生衰弱的独立危险因素,详见表5。

表4 多因素Logistic 回归赋值情况

表5 MHD 并发衰弱危险因素的Logistic 回归分析结果
2.3.2 决策树CART 模型
将单因素分析所筛选出的22 个变量作为预测因子纳入决策树CART 模型,以基尼系数为基础进行树的生长,选择最小代价复杂度剪枝法对决策树CART进行后剪枝,生成的决策树CART 模型见图1。该树形图包含5 层,5 个终末节点,其中CCI 得分、抑郁分级、NRS-2002 分级、年龄、SSRS 得分、性别是决策树CART 模型的6 个重要解释变量。
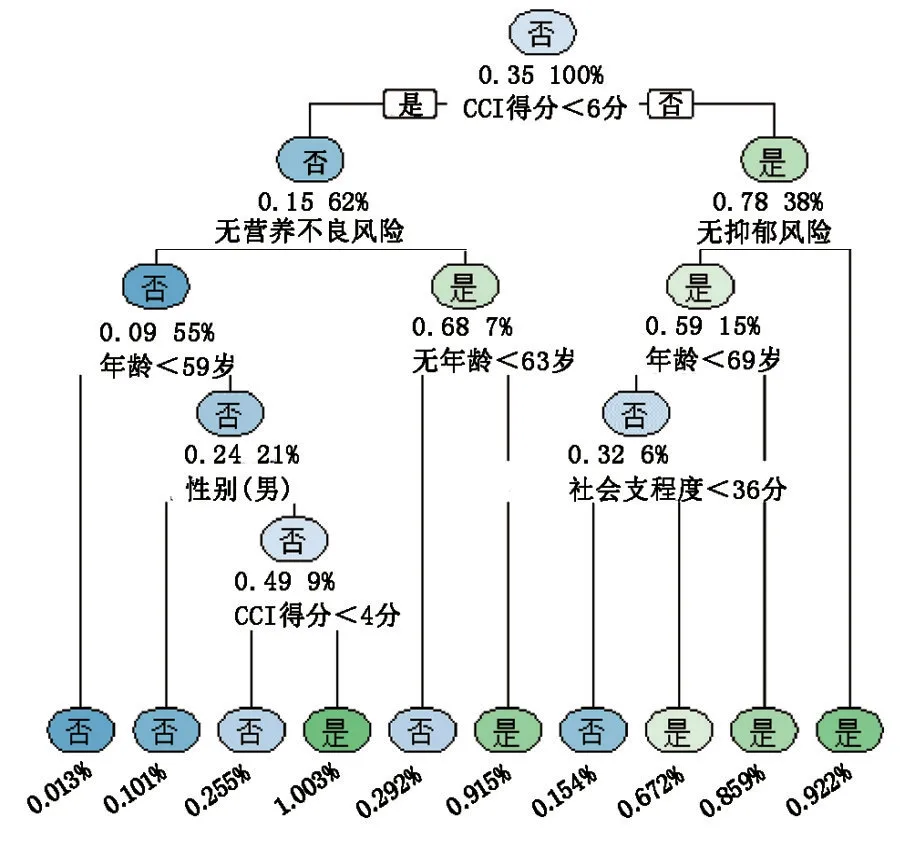
图1 MHD 病人衰弱危险因素的决策树CART 模型
2.3.3 随机森林模型
采用R 语言实现随机森林算法的拟合,经过模型验证,总样本量误差最小时树的数量为442,此时OOB误差为12.32%,模型的精确度较高。采用平均准确度降低量衡量模型变量的重要性,并采用重复5 次的十折交叉验证对变量进行取舍,结果显示当变量数为7时OOB(out of bag)最小,故选取前7 个重要的变量对初始随机森林模型进行优化,重要性评分居前7 位的变量分别为CCI 得分、年龄、NRS-2002 得分、性别、抑郁分级、日常锻炼情况、吸烟史。变量的重要性排序见图2。
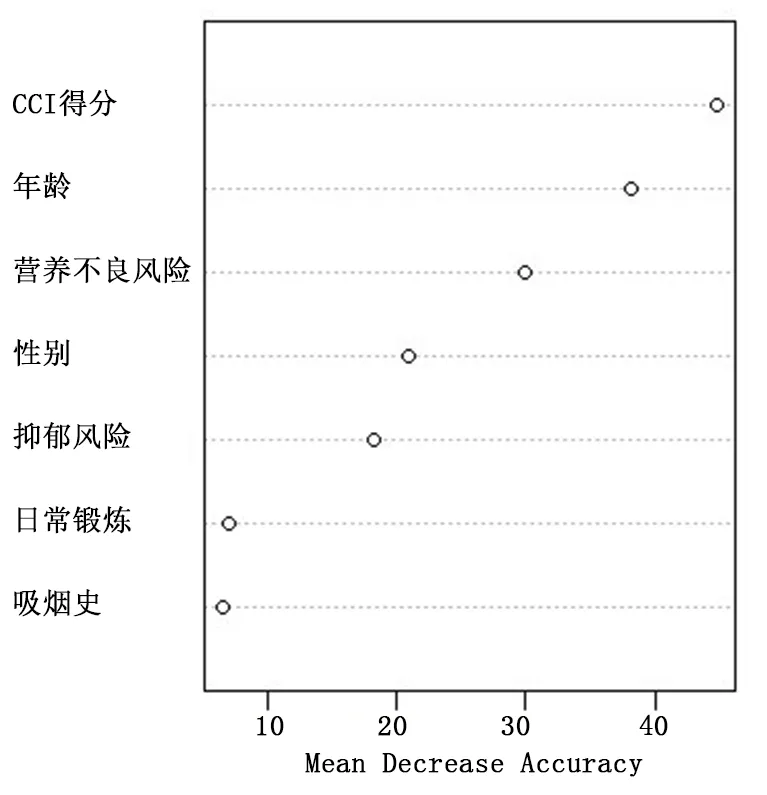
图2 随机森林模型
2.4 3 种风险模型的预测性能比较
2.4.1 训练集风险模型预测性能比较
在训练集中,3 种模型的准确率均在90%以上,其中随机森林模型的准确率(97.95%)、灵敏度(99.32%)、特异度(96.91%)、阳性预测值(PPV,96.05%)、阴性预测值(NPV,99.47%)和Kappa 值(0.958)均高于其他模型。AUC 值由大到小依次排序为:随机森林模型(0.998)、Logistic 回 归 模 型(0.971)、决 策 树CART 模 型(0.954),3 种模型AUC 值的两两比较结果显示,Logistic回归模型与决策树CART 模型比较差异无统计学意义(P=0.219),而随机森林模型与Logistic 回归模型、决策树CART 模型比较差异均有统计学意义(P<0.001)。具体见表6、图3。

图3 训练集ROC 曲线
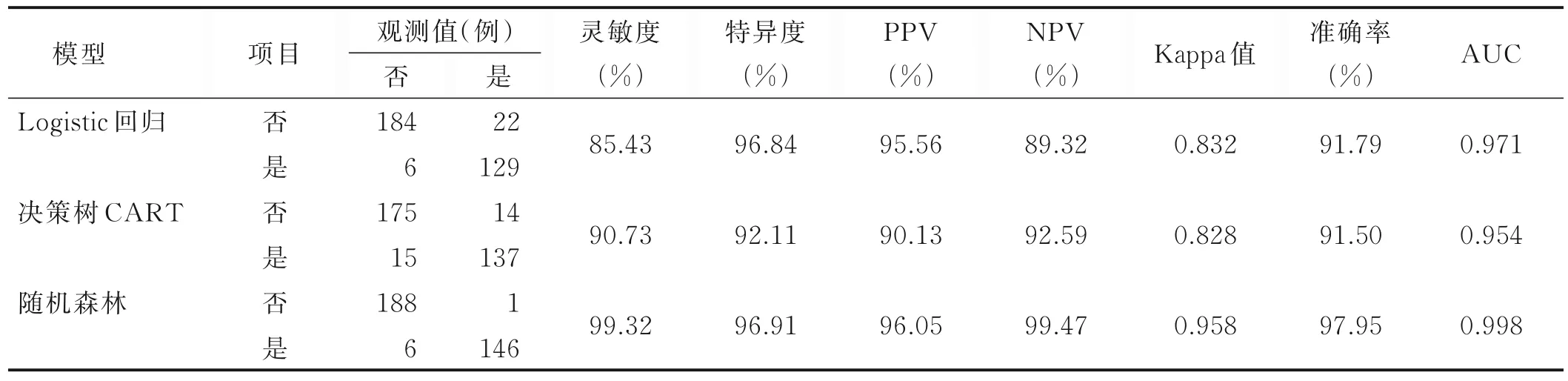
表6 训练集中3 种模型的预测性能
2.4.2 测试集风险模型预测性能比较
在测试集中,3 种模型的准确率均在80%以上,其中随机森林模型的准确率(88.19%)、灵敏度(87.50%)、NPV(93.41%)和Kappa值(0.741)均高于其他模型,Logistic回归模型的PPV(81.03%)高于其他模型。AUC 值由大到小依次排序为: Logistic 回归模型(0.957)、随机森林 模 型(0.934)、决 策 树CART 模 型(0.870),3 种 模 型AUC 值的两两比较结果显示,Logistic 回归模型与随机森林模型之间差异无统计学意义(P=0.367),而决策树CART 模 型 与Logistic 回 归 模 型(P=0.014)、随 机 森 林模型(P=0.002)比较差异有统计学意义。见表7、图4。

图4 验证集ROC 曲线

表7 测试集中3 种模型的预测性能
3 讨论
3.1 MHD 病人衰弱现状
总体而言,各国家或地区的MHD 病人衰弱的发生率仍处于较高水平。本研究发现MHD 病人衰弱的发生率为42.27%,与Lee 等[2]的一项系统评价结果相近(43%),但低于MHD 病人衰弱的发生率(46%~50%)。究其原因可能与研究对象相关,本研究中男性比例高于女性,女性仅为34.3%,且本调查中受试者的年龄跨度较大,年龄范围为25~91 岁,而既往研究表明,性别与衰弱存在一定的关联,女性MHD 病人衰弱的发生率高于男性[14],此外,既往研究也证实年龄是衰弱的重要影响因子,年龄越高则衰弱程度越高。另外,由于各研究的地域环境、样本选择均存在差异,在一定程度上也会使衰弱的发生率有所不同。因此,早期识别衰弱发生的MHD 高危人群,可有效加强医护人员对MHD 并发衰弱的早期预防和及早干预,从而提高病人的生活质量,改善疾病预后。
3.2 Logistic 回归、决策树CART 和随机森林模型的共同预测因子
3 种模型均将年龄、性别、CCI 得分和NRS-2002分级列为共同预测因子,且4 个预测因子在随机森林模型的预测准确性排序中位居前列,可见这4 种因素对于MHD 病人衰弱预防的意义重大,值得临床医护人员重视。
3.2.1 年龄
本研究结果显示,年龄是3 种风险预测模型的重要组成要素,在Logistic 回归模型中OR=1.171,P<0.001;在决策树CART 模型中位于第3 层;是随机森林模型的第2 重要因子。高龄是MHD 病人并发衰弱的独立危险因素。随着年龄的增长,个体的许多生理机能都会衰退,身体成分也会发生变化,导致其生理储备、抗应激能力、认知功能、免疫功能等下降,脂肪量和肌肉质量也随之减少,从而加速衰弱进展[15]。此外,终末期肾病会加重MHD 病人体内的尿毒症毒素累积,增加蛋白质能量消耗和氧化应激,进而加速病人的衰老过程[16]。
3.2.2 性别
本研究结果显示,性别是3 种风险预测模型的共同预测因子,在Logistic 回归模型中OR=15.581,P<0.001;在决策树CART 模型中位于第4 层;是随机森林模型的第4 重要因子。在所有的年龄组中,女性发生衰弱的可能性更大,衰弱程度也更高。分析原因可能是:1)肌肉质量是衰弱表型的重要组成部分,与衰弱密切相关,而与男性相比,女性的体重普遍较轻,骨骼肌质量较少,肌肉力量较弱,而且女性的活动水平较低,更容易发生肌肉减少症,增加了衰弱发生的可能性[17]。2)男女之间存在社会和行为领域的差异,女性对疾病的感知更为敏感,也倾向于规避风险,更愿意报告自身的健康问题,使得其衰弱检出率高[18]。3) 由于基因不同,男女之间的内分泌有所差异,女性更容易发生痴呆、抑郁、骨折等慢性疾病,在慢性疾病的影响下衰弱的患病率也更高[19]。
3.2.3 CCI 得分
本研究结果显示,CCI 得分与衰弱呈正相关,在Logistic 回归模型中OR=1.936,P<0.001;为决策树CART 模型的根节点;是随机森林模型的首要重要因子。MHD 病人的CCI 得分越高则衰弱的发生率越高,这与范炯同[18]的研究结论相同。CCI 评分常用于评估病人的生存与多种疾病状态,是一种可有效预测临床病人长期死亡率的评估工具[20]。因为终末期肾病行MHD 病人常合并其他的基础疾病或诱发疾病,这些疾病多无法治愈,大大加重了MHD 病人的共病负担和经济压力,使得病人长期处于慢性消耗状态,生理储备持续下降,不同程度地限制病人的活动能力,增加病人的负性情绪,加速衰弱发展。
3.2.4 NRS-2002 分级
NRS-2002 分级是3 种模型的共同预测因子,在Logistic 回归模型中OR=35.086,P<0.001;在决策树CART 模型中位于第2 层;是随机森林模型的第3 重要因子。营养不良与衰弱密切相关。营养不良可表现出身形消瘦、精神萎靡不振、四肢无力等症状,这些表现与衰弱表型中的体重减轻、疲乏和步速减慢3 个指标相重叠。此外,既往研究表明,机体的低营养状态可能导致蛋白质合成降解,使得肌肉质量下降并引起个体活动量减少,最终导致机体呈现衰弱状态,而由于终末期肾病的慢性消耗,MHD 病人需要满足更高的营养需求,才能防止或延缓蛋白质能量消耗的恶性进展[21-22]。
3.3 随机森林模型的预测性能最高
比较3 种模型在训练集和测试集的综合表现,可确定随机森林模型的预测效果最佳,这一结果与已有研究[23-24]应用机器学习算法预测临床结局的结果一致。从机器学习算法的特性分析,Logistic 回归分析因其可解释性较强,OR 值能直接反映指标的风险性大小而被广泛应用于危险因素研究,但在模型构建时由于该算法对样本量和数据类型要求较高,易出现模型性能不高、易受缺失数据影响等问题[25]。决策树CART 是一种可解释性很强的算法,对缺失变量及数据分布类型不敏感,能够通过树形图直观了解到分类或预测的过程,但模型结构往往较为复杂,易出现过拟合和泛化能力弱的问题。随机森林算法是一种集成学习算法,该算法的本质是将若干个决策树进行组合分析,使得单一树因各自差异性导致的不同分类边界变得更为合理,从而减少整体的错误率,实现更好的预测效果。并且随机森林算法对数据类型要求不高,能自动分析预测因子的交互作用和非线性效应,通过有目的的放回方式对数据进行充分利用,能够有效提高算法的预测精度,获得更为准确、稳定和强健的结果[24]。综上所述,随机森林模型是预测MHD 病人衰弱风险的最优选择。
4 本研究的不足
本研究的不足之处在于采用便利抽样法选取病人,仅对模型进行内部验证,因而存在地域性的局限性,也无法证明模型的泛化能力,今后应扩大样本量,开展多中心研究,并在实际应用中检验模型的临床应用性并完善模型,使本研究结果能为MHD 病人衰弱的预防提供可靠依据。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
神州·下旬刊(2019年1期)2019-02-11
电子制作(2018年16期)2018-09-26
中国神经再生研究(英文版)(2017年10期)2017-11-08
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
中国卫生标准管理(2015年1期)2016-01-15
心理学探新(2015年4期)2015-12-10
集美大学学报(教育科学版)(2015年5期)2015-02-28
济南大学学报(社会科学版)(2015年5期)2015-02-27
郑州大学学报(医学版)(2015年1期)2015-02-27
