
基于指代消解的民间文学文本实体关系抽取
2024-01-27 11:33魏静岳昆段亮王笳辉
河南师范大学学报(自然科学版) 2024年1期
魏静,岳昆,段亮,王笳辉
(云南大学 信息学院;云南省智能系统与计算重点实验室,昆明 650500)
民间文学是指民众在生活文化和生活世界里传承、传播、共享的口头传统和语辞艺术,是中华文化的重要组成部分.民间文学包括神话、民间传说、民间故事、韵文的诗歌等体裁的民间作品.传统的民间文学神话诗歌多以文本为载体,或以口头传唱的方式讲述神话故事,不易开展后续的研究和保护工作.随着大数据和人工智能技术的快速发展和不断普及,数字媒介成为民间文学传播的重要载体,是民间文学文本保护和传承的重要方式[1-2].将民间文学文本与自然语言处理相关技术结合,以揭示神话故事蕴含的内在特征,建立对文本数据的整体认知,有助于研究者和民间文学爱好者对民间文学文本的了解和学习,为民间文学数字化提供了新型的技术支撑.
关系抽取(relation extraction,RE)是从文本中识别出实体,抽取实体间的语义关系,旨在将非结构化的文本数据转化为结构化数据[3].利用关系抽取对民间文学文本进行数字化处理,其处理结果可应用于民间文学文本中的诗歌修复,民间文学的领域知识图谱构建等实际应用.民间文学与新兴领域技术结合,增加民间文学的受众群体,有利于发扬和传承民间文学工作.此外,补全民间文学中诗歌的缺失部分,弥补了人员能力有限的缺陷,更大程度上确保了民间文学文化遗产的完整性.
民间文学文本以诗歌为载体,具有以下特点:(1)文本指示代词多,实体关系常由指示代词体现,在指示代词之间容易隐藏实体间的真实关系,是实体间关系识别的重要影响因素.(2)民间文学文本有着丰富的语义表达,在一段简单的文本描述中包含多个实体-关系三元组,且同一实体不只存在一种关系,可见如何处理关系重叠和实体重叠是民间文学文本关系抽取模型需要解决的问题.综上所述,民间文学文本有着指示代词较多,实体重叠和关系重叠的特点,故面向民间文学文本的关系抽取模型应具有更善于获取文本语义特征,实体与关系之间的交互信息特征及处理和利用文本中指示代词信息的能力.
但目前的方法[4-15]或是偏向较为宽泛的领域或是面向如医学、生物学等特定领域.若直接将模型迁移到民间文学文本关系抽取任务中,不能真正解决民间文学文本代词多、实体关系重叠带来的问题.
根据上述民间文学文本特点及当前实体关系抽取方法的研究进展,本文提出一种基于指代消解的民间文学文本关系抽取模型CR_RSAN.针对文本中指示代词较多、易造成实体关系不明的问题,引入指代消解[16]方法,通过不断学习文本中每个词语和可能存在的先行词的特征,计算文本中所有词的关联分数,得到指示代词及其对应实体的位置信息.在此基础上,设计指示代词替换算法,将指示代词和其对应实体进行替换,使实体关系明朗,帮助模型获取到更多的实体关系.
针对文本实体关系重叠的问题,本文采用序列标注的方式来获取实体间关系.经指示代词替换之后的文本比原文本有更强的实体关系表现力,故根据替换后文本中实体的位置分布信息,在BIESO标注方法结合新编码H和T[9]的基础上,调整头实体和尾实体的编码位置,将指示代词替换后提供的有效信息与实体关系间的交互信息用序列标注的方式结合,提高模型获取语义特征的能力,将实体关系的重叠问题转化为序列标注问题,以提高模型关系抽取性能.
在民间文学文本上的实验结果表明,CR_RSAN在精确率、召回率和F1值上均优于现有模型.
1 相关工作
在早期的研究中,基于核函数的关系抽取方法,需要大量的人力来标注数据,且特征提取中存在误差,影响实体间关系的抽取效果[17].目前基于深度学习的实体关系抽取方法成为研究关系抽取的重要方式[18],一些方法[19]将实体命名识别和关系抽取任务分开进行,造成实体识别任务出现的错误累积到关系抽取任务中,影响了关系抽取的效果[3].
为了缓解实体命名识别任务造成的错误累积,研究者们相继提出将实体命名识别和关系抽取联合进行的方法.KATIYAR等[4]通过共享编码层特征表示联合提取实体和关系,但实体识别任务和关系抽取任务是单独解码,这导致实体与关系之间的交互信息易被遗漏.为了利用该信息,研究者们设计了不同的标记策略.ZHENG等[5]提出采用端到端的模型直接对实体-关系三元组建模,但该模型无法解决关系重叠问题.ZENG等[6]通过复制机制(copy mechanism)生成后续的两个对应实体的关系,解决了关系重叠的问题,但抽取结果不完整.WEI等[7]提出二进制标记的方法解决相同实体对之间包含多重关系的问题,但对语义较为复杂的文本数据,该模型学习特征的能力有限.YAN等[8]提出将神经元划分,但其划分规则忽视了实体特定区域中与关系特征的相关信息.YUAN等[9]提出改进BIESO标注,将关系信息作为先验知识,减少模型对无关实体的关注,解决了实体关系重叠的问题,但忽视了某些关系发生的真正主体.
在医学领域,宁尚明等[10]采用多通道注意力机制与卷积神经网络相结合,但是将实体识别任务与关系抽取任务分开进行,忽略了两者之间的依赖.LI等[11]采用共享双向长短记忆网络编码层,XUE等[12]采用共享BERT模型[20]的编码,实现实体命名识别任务和关系抽取任务的参数共享,但两个任务分开解码忽略了实体与关系之间的交互信息.在文学领域,秦川等[21]利用主题、模板信息和押韵信息实现秘密信息的隐藏,YI等[22]提出利用分解子空间进行对抗训练以区分不同风格的诗歌.
基于上述研究,现有的关系抽取模型侧重于研究如何利用实体信息、关系信息和实体与关系之间的交互信息以提高模型性能,但是抽取结果不尽如人意,特征信息不能完全利用,同时未对文本数据中的指示代词进行处理,若直接将这些方法迁移到民间文学文本关系抽取任务中,并不能真正解决指示代词带来的问题.LEE等[16]提出一种端到端的指代消解方式,把文本中的所有词语视为潜在实体,通过学习指示代词与先行实体之间的相关性,确定指示代词与先行实体的位置关系,解决文本中指示代词与对应实体的指代问题.因此,针对民间文学文本指示代词多,实体关系重叠的特点,将指代消解和关系抽取相结合给民间文学文本关系抽取任务提供了新思路.
2 CR_RSAN模型
2.1 问题描述
设民间文学文本为D,实体-关系三元组表示为(eh,rs,et)(eh,et∈E,rs∈R),E和R分别表示实体集合和关系集合.

2.2 模型介绍
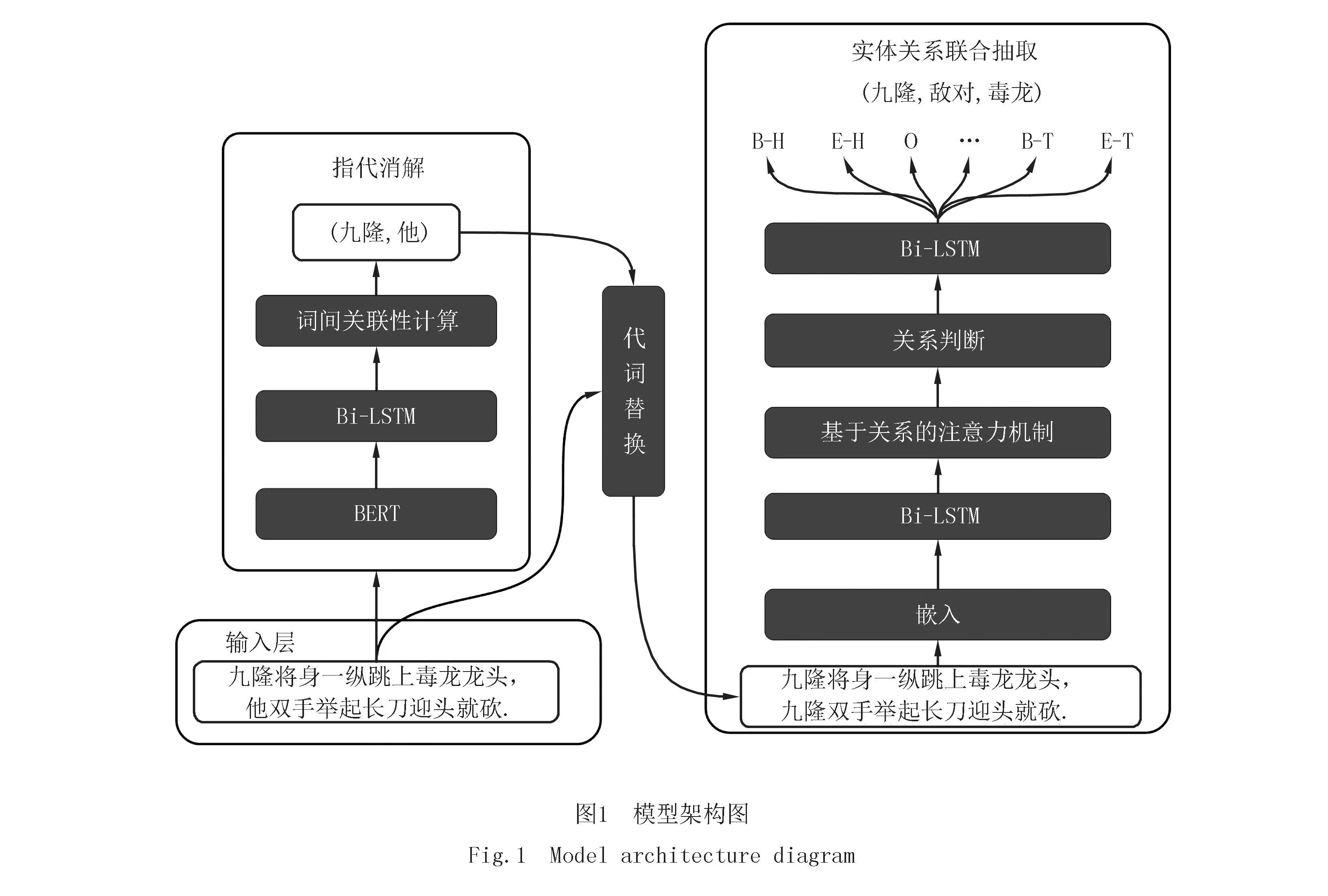
模型主要包括输入层、指代消解、指示代词替换,序列标注和实体关系联合抽取.
(1)输入层:原始的民间文学文本作为模型的输入.
(2)指代消解:对输入的文本数据进行词语划分,学习和计算每个词及其先行词的关联分数,识别文本数据中存在的指示代词及其对应实体.
(3)指示代词替换:按照指示代词替换算法对文本数据中的指示代词进行有效替换.
(4)序列标注:根据(3)中的替换结果制定新的序列标注方法,生成不同关系下的文本标注序列.
(5)实体关系联合抽取:利用基于关系的注意机制生成每个关系特定的文本表示,提取当前关系下存在的头尾实体.
以句子“九隆将身一纵跳上毒龙龙头,他双手举起长刀迎头就砍”.为例,CR_RSAN的总体架构图如图1所示.句子经过输入层进入指代消解部分,得到指示代词“他”和对应实体“九隆”的位置信息,利用该信息将文本中的指示代词进行替换生成新的文本,输入到实体关系联合抽取模型RSAN中,得到文本中包含的实体-关系三元组(九隆,敌对,毒龙)和(九隆,动作,长刀).
2.2.1指代消解
民间文学文本中包含较多指示代词,而指示代词会影响实体关系确定,因此利用指代消解方法获取指示代词对应的实体信息,有助于后续任务发现隐藏的实体间关系.指代消解的基本原理是:将文本D进行分词,分词后的文本表示为Dp={p1,p2,…,ph}(h≤n),pi(1≤i≤h)表示第i个位置上的词,计算任意两个词的关联分数(即代表相同事物的可能性),关联分数高的词语视为它们的指代相同,从而得到文本中的指示代词与对应实体的位置信息.
2.2.1.1词特征表示

∝t=F(st),
(1)
(2)
(3)
(4)
START(pi)和END(pi)分别表示词pi开始位置索引和结束位置索引,ρ(pi)表示词pi的长度大小.
2.2.1.2关联分数计算
本文采用打分制来确定指示代词和其真实实体的位置信息.设pi的可能先行词为pj(1≤j≤i),pi和pj之间的关联程度越强说明pj是pi的先行词的可能性越大.故采用关联分数来表示词之间的关联强度.
将词的向量表示gpi通过前馈神经网络Fo得到其对应的数值形式scoreo(pi)用于后续计算;通过式(6)计算词pj是词pi先行词的分数scorea(pi,pj);通过式(7)计算词pi和词pq之间的关联分数score(pi,pj),即认为词pj是词pi的先行词,并且词pj和词pi同时存在才有关联的可能[16].通过计算词pi与先行词的关联分数得到每个先行词与其关联的可能性,可能性最大的先行词视为词pi的指代实体,最后得到文本中指示代词m和其对应实体mh的位置索引.φ(pi,pj)表示词pi和词pj之间的距离.
scoreo(pi)=Wo·Fo(gpi),
(5)
scorea(pi,pj)=Wa·Fa([gpi,gpj,gpi∘gpj],φ(pi,pj)),
(6)
score(pi,pj)=scoreo(pi)+scoreo(pj)+scorea(pi,pj).
(7)
2.2.2指示代词替换算法
指示代词使实体间关系不明显,若能将文本中的指示代词换成其对应实体,能帮助模型获取更确切的语义信息,提高实体关系抽取任务的性能.通过指代消解获取文本中指示代词与其对应实体的位置关系,利用该信息对指示代词和其对应实体进行有效替换.
本文将民间文学文本中出现的指示代词分为有效指示代词和无效指示代词.若文本数据中指示代词对应的实体是同一文本中实体-关系三元组中的头实体或者尾实体,则表示该指示代词与实体关系的确定有影响,将该指示代词视为有效指示代词;若文本数据中指示代词对应的实体不是实体-三元组中的头实体或者尾实体,则该指示代词视为无效指示代词.
如图2所示,情况二中实体间关系通过指示代词所在的短句体现和表达,将该指示代词替换成其对应实体,能增强实体与实体间关系的表现,有利于实体间关系抽取.

根据指示代词的分类,本文制定以下替换规则:若文本D中代词m对应的实体mh是民间文学文本中关系三元组(eh,rs,et)包含的头实体或尾实体,则将文本D中的代词替换为对应实体,否则对文本不作处理.根据不同的实体关系同一个句子采取不同的替换策略,算法1给出了指示代词替换的具体步骤.
算法1 指示代词替换
输入: 文本D,(eh,rs,et),(m,mh)

1. IFmh=ehORmh=etailTHEN
2. IFmh=ehTHEN

4. END IF
5. IFmh=etTHEN

7. END IF
2.2.3序列标注
YUAN等[9]将{H,T}并入BISO标注中作为实体标注的后缀,分别表示头实体和尾实体,与实体无关的用O表示.针对民间文学文本代词多、关系重叠的特点,本文在标注方法上做以下改进:
(1)未经过指示代词替换的文本,则对文本数据首次出现的头实体和尾实体进行BISO实体标注,并分别以H和T作为后缀,其他与首尾实体无关的部分用O表示.
(2)经过指示代词替换的文本数据分为以下两种情况:①若指示代词替换成对应实体的位置位于替换前文本中头实体首次出现和尾实体首次出现的位置之间,则对指示代词替换后的实体和文本中首次出现的尾实体进行BISO实体标注,并分别以H和T作为后缀,剩余部分用O表示;②若指示代词替换成对应实体的位置不在替换前文本中头实体首次出现和尾实体首次出现的位置之间,则对文本数据首次出现的头实体和尾实体进行BISO实体标注,并分别以H和T作为后缀,其他与首尾实体无关的部分用O表示.图2为本文制定的序列标注方法的示例.

(8)
(eh,r,et)=DECODE(S).
(9)
3 实 验
3.1 数据集
本文实验使用的数据集来自云南大学文学院提供的《千瓣莲花》《娥并与桑落》《傣族民间故事选》和《云南少数民族古典史诗》等书籍资料,共计30万字左右,指示代词占比约为4.28%,整理得到1 154条数据.CR_RSAN的训练部分包括了指代消解和关系抽取,故数据集应包含两部分的模型训练输入,数据集中每条数据采用如图3中实例的标注方法,其中,cluster表示文本中指示代词的位置索引,subtoken_map表示文本词语划分情况.

将数据集按照6∶2∶2划分为训练集、验证集和测试集.数据集中包含18种关系,每种关系对应的数量情况如表1所示.

表1 关系类型及数量情况Tab. 1 The type and quality of relations
3.2 对比方法
本文选取RSAN,Bias,PFN和CasRel模型与CR_RSAN进行性能比较.
Bias[5]:将BIESO标注与{1,2}(1,2分别表示实体1和实体2)相结合生成新标签序列,并将联合抽取模型转换为一个序列标注问题的方法.
CasRel[7]:提出采用联级二进制的方法标注数据,将关系抽取任务从关系分类转换为主体向客体映射的方法.
PFN[8]:将神经元分割成两个任务分区(实体分区和关系分区)和一个共享分区,任务分区相互独立,共享分区保证实体信息和关系信息的交互的方法.
RSAN[9]:一种新型标注方式,将头实体和尾实体信息{H,T}标注进标签中,保留实体与关系之间的交互信息的方法.
3.3 评价指标
本文采用精确率(Precision,P),召回率(Recall,R)和F1值作为方法模型的评价指标.用TP表示预测为真,实际为真的样本数;FP表示预测为真,实际为假的样本数;FN表示预测为假,实际为真的样本数;TN表示测试为假,实际为假的样本数.

3.4 实验环境
实验平台使用Windows 10操作系统,配置为8核Intel i7-10700K处理器与32 GB内存,NVIDIA RTX 3070显卡.所有模型基于Python和Pytorch构建.
3.5 实验结果
为了验证CR_RSAN的有效性,将CR_RSAN与RSAN,PFN,Bias和CasRel模型进行性能比较,其对比结果如表2所示.

表2 模型的性能对比Tab. 2 The comparison of model’s performance
由表2可知,CR_RSAN引入指代消解,将文本数据中的指示代词根据相应算法进行替换,加强模型获取语义特征的能力以及含有当前关系类型的实体对之间的联系,使性能显著提升,与RSAN模型相比精确率提高了2.96个百分点,召回率提高了1.69个百分点,F1值提高了2.31个百分点;与Bias模型相比精确率提高了6.61个百分点,召回率提高了7.34个百分点,F1值提高了7.91个百分点;与CasRel模型相比精确率提高了12.06个百分点,召回率提高了12.29个百分点,F1值提高了12.54个百分点;与PFN模型相比精确率提高了13.39个百分点,召回率提高了14.29个百分点,F1值提高了14.98个百分点.以上实验结果,验证了CR_RSAN模型的有效性.
本文经指代消解之后,采用改进的序列标注方法对文本标注,为了验证改进后的标注方法的有效性,现将采用原有标注方法rr_origin和CR_RSAN模型进行比较,其对比结果如表3所示.

表3 序列标注方法对比Tab. 3 The comparison of sequence labeling method
由表3可知,改进后的序列标注方法结合了指示代词和对应实体之间的替换信息,使产生关系的两个实体能被标注,帮助模型获取实体间更明确的和贴切的语义信息.与采用原有标注方法的模型相比,采用改进后的序列标注方法的精确率提高了0.6个百分点,召回率提高了0.41个百分点,F1值提高了1.31个百分点.由此可见,改进后的序列标注方法对模型性能的提升作用.
3.6 民间文学文本实体关系抽取样例展示
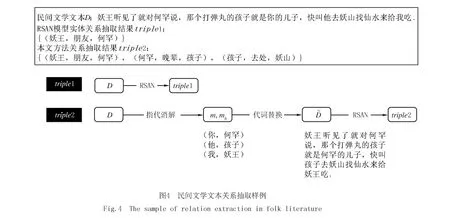
对民间文学文本关系抽取可以快速了解文本中人物、事件之间的联系,方便研究者和民间文学爱好者快速建立对文学作品的整体认知.使用CR_RSAN和不加指代消解的方法RSAN分别对民间文学文本进行关系抽取,以此展示两种方法在关系抽取过程中的差别,如图4所示.
4 结 论
本文提出一种基于指代消解的关系抽取模型CR_RSAN,用于民间文学文本的关系抽取任务.通过指代消解,获得指示词和对应实体的位置信息并对文本中的指示代词进行替换,并在RSAN模型标注方式上进行调整,将实体-关系抽取转换为标注问题.实验证明,模型在精确率、召回率和F1值方面都有显著提升,这也证明了CR_RSAN在民间文学文本关系抽取任务中的有效性.
但是模型的精确率,召回率和F1值均还有待提高,通过实验发现,该模型能很好地判断文本中含有什么关系,但是在抽取满足当前关系的实体对时会出现多字和少字的情况,因此降低了模型的精确率.在后续工作中,继续从数据集和模型优化着手,设计质量较高的数据集以及探索其他模型,学习其他模型的优点来改进模型,提高模型性能.
猜你喜欢
初中生学习指导·提升版(2023年9期)2023-10-08
科学咨询(2022年19期)2022-11-24
苏州教育学院学报(2022年2期)2022-06-27
苏州教育学院学报(2022年1期)2022-05-06
疯狂英语·初中天地(2021年11期)2021-02-16
疯狂英语·初中天地(2021年12期)2021-02-12
考试与评价·八年级版(2020年1期)2020-10-26
活力(2019年22期)2019-03-16
高中生·天天向上(2018年1期)2018-04-14
自动化学报(2017年11期)2017-04-04
