
基于PSO-BPNN的精矿品位预测模型研究与应用
2024-02-01 01:29王昌敏闫海鹏王训洪
中国设备工程 2024年2期
王昌敏,闫海鹏,王训洪
(1.内蒙古双利矿业有限公司,内蒙古 巴彦淖尔 015000;2.广西科技大学经管学院;3.广西工业高质量发展研究中心,广西 柳州 545006)
精矿品位是选矿厂的最终产品,直接影响企业的经济效益。精矿品位的测算一般通过抽样化验,但由于化验耗时长,滞后性较大,使生产操作工很难及时调整生产工艺参数来保证精矿品位稳定。为弥补上述不足,拟构建精度更高的精矿品位预测模型。选矿过程复杂,机理不清,使用机理较难建立高精度的精矿品位预测模型,大多数采用数学方法建立模型。文献[2]采用规划方法构建了精矿品位的预测模型,并采用概率密度函数计算了最优参数。文献[3]结合支持向量机和小波极值方法建立精矿品位的预测模型,该预测模型所需样本数量大,使模型运用受到一定限制。文献[4]采用人工神经网络方法对精矿品位预测进行了研究,并通过案例应用,验证了人工神经网络应用于精矿品位预测的有效性。在上述文献中,验证了人工神经网络拟合性能良好,但其仍存在一些不足为:收敛速度慢、易陷入局部极值。然而,粒子群算法一般通过改变粒子位置和速率进行全局优化,其优势具有高鲁棒性、快收敛速率和较好的全局优化能力。为弥补人工神经网络的上述不足,结合2种方法,构造基于PSO-BPNN的精矿品位预测模型,以提高精度为目的,为预测精矿品位提供帮助。
1 研究方法
1.1 人工神经网络基本原理
人工神经网络借用物理设备模拟生物神经网络结构,被广泛应用于控制、分类、非线性预测、优化等诸多领域。在20世纪70年代初,Werbos创立了反向传播神经网络(Back-Propagation Neural Network,BPNN),利用分布式存储,其具有自学习能力强、并行处理和自适应能力强等优势,是目前广泛应用算法之一;BPNN按误差反方向传播,是多层前馈神经网络,主要由输入层、输出层和隐含层组成;其通过改变连接权重,提高自学习能力和拟合性能,网络图如图1所示。
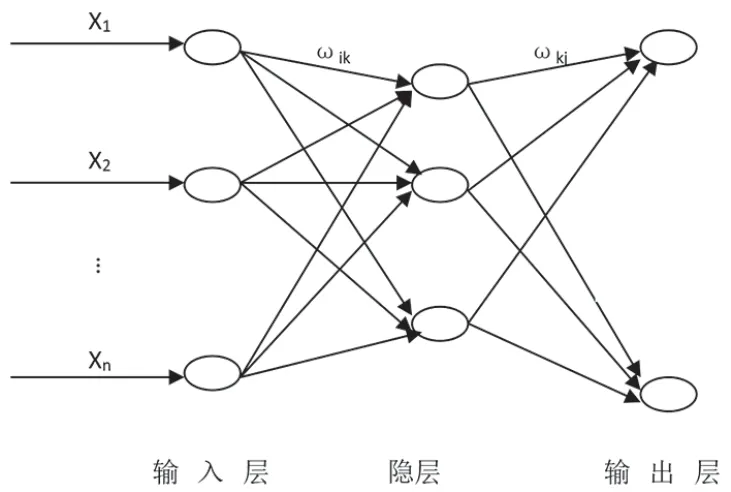
图1 BPNN结构图
1.2 粒子群算法基本原理
20世纪90年代,Eberhart和Kennedy[9]创立了粒子群优化(Particle Swarm Optimization, PSO),其借用早期受鸟类群体寻食行为,利用种群中个体信息共享和协作进行优化。在PSO算法中,粒子代表潜在解和在解空间里搜索,并通过不断迭代寻找最优解。迭代过程中,粒子依赖两个最优值改变自己。一个为个体最优解,另一个为全局最优解。
假设一个群体共有m个粒子,每个粒子的信息由n维向量表示。设第i个粒子位置为Xi=(xi1,xi2,…,xin),其现在个体最优解为Pi=(pi1,pi2,…,pin),现在群体最优解为G=(g1,g2,…,gn),该粒子变化率为Vi=(vi1,vi2,…,vin)。依据粒子群算法的原理,粒子更新公式如下:
式中,w、t分别为惯性权重和迭代次数;i=1,2,…,m,j=1,2,…,n;c1、c2为加速因子,分别表示粒子走向现在个体最优解和群体最优解的步长;r1,r2为随机数,0~1内。
公式(3)是为了降低粒子在迭代过程中离开解空间的可能性,使粒子变化率限制在[-vmax,vmax]内。
1.3 PSO优化BPNN预测模型
由于BPNN易收敛局部极值和收敛速率较慢,且初始连接权重和阈值等参数敏感。而PSO算法通过更新粒子位置和速度来搜索全局最优解,其具有快收敛性、高全局搜索性能和强鲁棒性等优点。PSO-BPNN是将PSO和BPNN相结合,利用粒子群算法改善BPNN易收敛局部极值和收敛速率较慢等缺点。PSO-BPNN通过粒子群算法优化BPNN中的初始连接权重和阈值,优化最优的初始连接权重和阈值,然后将这两个参数值传给BPNN,最后进行预测。PSO-BPNN的预测模型过程如下:
(1)构建BPNN,设置参数,初始化连接权重和阈值。目前,隐含层节点个数确定通常使用经验公式,本文经验公式如下:
式中,hi、hj、hk分别为输入层、隐含层和输出层节点个数。
(2)设置PSO算法的参数,主要包括群体数量、学习因子、惯性权重、最大迭代次数、适应度误差和粒子维数等参数。大多数参数是根据经验和精度设置,但粒子维数是由如下公式确定:
(3)初始化个体位置和速度。
(4)使用均方误差为PSO的适应度函数,计算公式为:
式中,M表示样本个数;N表示粒子维数;yij和分别为样本i预测值和实际值。
(5)对每个粒子,比较该粒子的适应值和历史最优适应值、粒子历史最优适应值和全局最优适应值,若前者大于后者,则用前者替换后者。
(6)依据公式(1)、(2)和(3),对每个粒子进行更新。
(7)判断是否满足结束条件(适应度值小于适应度误差限、迭代次数大于最大允许迭代次数),若满足,则停止迭代,输出连接权重和阈值;否则,迭代次数增加1,返回流程(4)。
(8)根据流程(7)输出的连接权重和阈值对BPNN进行训练和测试,检验预测模型的预测和泛化能力。
2 精矿品位预测实例
2.1 实例样本选取
通过分析选矿过程中各生产关键指标与精矿品位的影响,选取对精矿品位影响大的指标作为输入变量,分别为入选品位和选矿比,输出变量为精矿品位。本文收集某矿山选矿厂2015年3月~2017年12月的入选品位、选矿比和精矿品位的日数据,共500组数据,部分数据如表1所示。在精矿品位预测模型建立时,分别将前400组数据和后100组数据作为模型的训练和测试样本,对预测模型的精度进行验证。
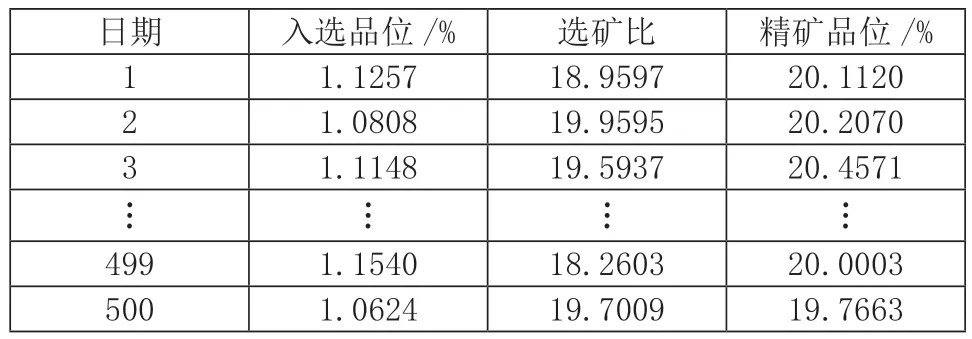
表1 某矿山的部分选矿数据
2.2 PSO-BPNN结构参数初始化
通过newff函数构建BPNN,newff函数如下:
式中,P、T、S分别为输入变量、输出变量、隐含层节点个数;TF和BLF为传递函数(tansig函数)和训练函数(trainlm函数)。
3层BPNN非线性拟合性能强,故采用3层BPNN。输入与输出节点个数分别为2和1。根据公式(4),隐含层节点个数可为1或2,通过比较网络调试结果,最终确定隐层节点个数为2。训练次数、学习率、训练目标误差分别设为100、0.1、0.001,其余参数选为默认值。
根据公式(5)计算粒子维数为9,粒子种群数和最大允许迭代次数分别设为30和20,c1和c2均为1.4,最大限制速度vmax=6。
2.3 PSO-BPNN对精矿品位预测及结果分析
根据上述样本数据和参数构建了基于PSO-BPNN的精矿品位预测模型。为了验证其预测性能的优越性,采用相同的参数与样本数据,对PSO-BPNN和BPNN预测模型进行了仿真和比较。图2~4分别给出了两种预测模型的网络性能、预测结果和预测结果误差的效果图。表2给出了两种模型的性能指标。
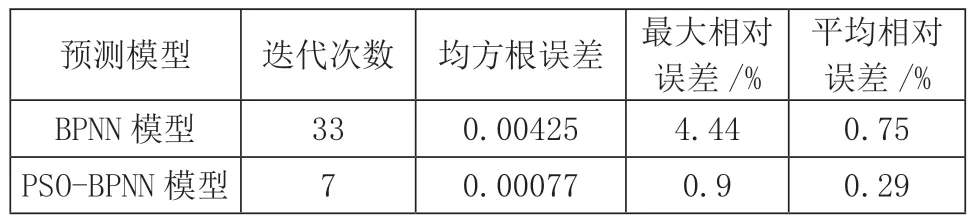
表2 2种模型的性能指标对比
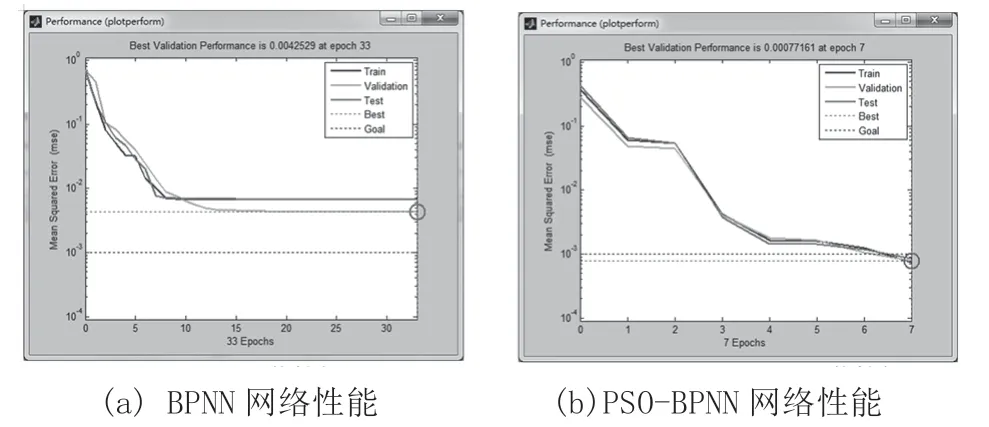
图2 精矿品位预测的网络性能
从图2可以看出,2种预测模型均达到收敛状态,且PSO-BPNN预测模型的收敛速度和收敛结果都优于BPNN。从图3、图4和表2可以看出,PSO-BPNN预测模型的预测精度胜于BPNN预测模型。PSO-BPNN预测模型的最大相对误差和平均相对误差分别为0.9%和0.29%,最大相对误差未超过1%,表明PSO-BPNN预测模型预测精度高,并说明该矿山的精矿品位具有可预测性。
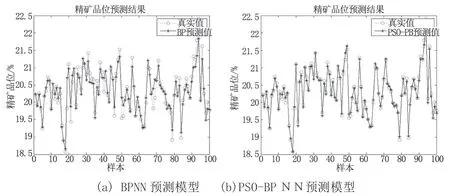
图3 精矿品位预测结果

图4 精矿品位预测结果误差
3 结语
融合PSO算法和BPNN,建立基于PSO-BPNN的精矿品位预测模型。将所建立模型应用于实际案例,最大相对误差和平均相对误差分别为0.9%和0.29%,均低于1%,表明PSO-BPNN预测模型预测精度高,可用于精矿品位的预测,能为选矿过程控制奠定基础,并具有一定的实用价值。
猜你喜欢
云南化工(2021年7期)2021-12-21
今日农业(2021年14期)2021-10-14
空间科学学报(2020年4期)2020-04-22
世界有色金属(2019年9期)2019-07-03
电子制作(2019年10期)2019-06-17
中国资源综合利用(2016年9期)2016-01-22
中国资源综合利用(2016年12期)2016-01-22
山东冶金(2015年5期)2015-12-10
建筑材料学报(2014年4期)2014-03-11
河南科技(2014年11期)2014-02-27
