
基于Transformer的道路场景点云分类与分割方法
2024-02-05 01:35马庆禄黄筱潇王江华
激光与红外 2024年1期
马庆禄,孙 枭,黄筱潇,王江华
(1.重庆交通大学交通运输学院,重庆 400074;2.重庆奉建高速公路有限公司,重庆 401120)
1 引 言
三维道路场景点云数据的精准分类与分割技术,是智能网联汽车进行实时控制决策的前提。然而,与传统2D图像相比,3D点云图像具有更复杂的结构以及更多的检测信息,在三维空间中以不规则和无序的方式分布[1]。因此,为了更好地分类与分割,国内外学者围绕优化深度学习网络以实现高效的全局特征提取方面做了大量的研究。康自祥等[2]提出一种基于Transformer的体素化激光点云目标检测算法,提高了运算效率,目标检测的准确率达到88.5 %。梁志强等[3]利用图卷积提取点云基于位置信息的低维局部特征,并通过注意力机制提取点云基于语义高维局部特征,同时使用多层感知机提权全局特征,通过多个特征融合来提高精度。Qi等[4]提出了PointNet方法,以点的方式实现点云特征学习。PointNet由几个核心模块组成:刚性变换(T-Net)、共享多层感知器(MLPs)和最大池(maxpooling),这些模块保证了网络对点排列和形状旋转的不变性[5],之后通过引入局部特征提取,提出了几个变体来提高PointNet的性能。Li[6]等提出的PointCNN,类似于图片的卷积操作,充分考虑了局部信息。Wu[7]等提出将PointConv扩展到反卷积,以获得更好的分割结果。Wang等[8]提出了DGCNN设计了EdgeConv,可以很好地集成到多个已经存在的点云处理的pipeline中。
谷歌公司所提出的Transformer[9]具有显著的全局特征学习能力,来代替网络中的所有卷积运算,以便更好地表达全局特征。尽管Transformer架构目前在机器视觉研究的各个领域都得到了应用,但它们在3D点云处理中的应用仍然非常有限。在目前基于Transfomer结构的点云研究中留下了一个空白。首先Transfomer已被证明对输入数据中的排列具有本质上的不变性,这使其成为集处理任务的理想选择;其次,现有大多数深度学习方法处理的3D点利用局部特征来提高性能。这些技术在局部尺度上处理点,以保持它们对于输入排列不变,导致忽略点表示之间的几何关系,并且所述模型不能很好地捕捉全局概念[10]。
为解决上述问题,提出了一种基于双随机Transformer的点云分类与分割模型,并将其命名为DRPT,利用Teansformer模型获取全局变量,并将双随机代替Transformer的行随机以获取更多点特征。在多个3D点云数据集上评估DRPT,用于分类、部分分割和语义场景分割任务。通过实验结果表明,DRPT可以作为各种点云处理任务的准确有效的主干。
2 点云注意机制研究
2.1 Transformer网络函数定义
Transformer网络依赖于多头注意力与使用单一注意函数不同,多头注意首先使用单独的前馈网络从不同的子空间学习关系,多头注意首先将Q、K、V分别投影h次到dv,dk,dm维。然后,注意力平行应用于每个投影。使用前馈网络将输出连接起来并再次投影。因此,多头注意力可以定义如公式(1)所示:
(1)

AMH(X,Y)=LayerNorm(S+rFF(S))
(2)
S=LayerNorm(X+Multihead(X,Y,Z))
(3)
公式(2)中AMH表示多头注意力机制的输出,取决于查询矩阵X的顺序。LayerNorm是层归一化,rFF为向前反馈层因此其不具备置换不变性。S表示多头注意力的中间结果,公式(3)是S的具体计算过程。公式(3)中,X是查询矩阵、Y是键矩阵、Z是值矩阵,Multihead是多头注意力函数,它将查询、键和值作为输入,并输出它们的加权和。无论输出顺序,每个点相对应的输出值始终相同,因为AMH仅由矩阵乘法和求和组成。
2.2 Transformer点云中的应用
Transformer通过ViT来提高学习全局特征的能力,所以当前的点云处理倾向于使用变换器来替换网络中的所有卷积运算,以获得更好的特征表达。基于Transformer的点云分类方法,是为通过Transformer获取点云的全局特性。PCT(Point Cloud Transformer)采用了PointNet架构,其中共享的MLP层被替换为标准Transformer块。通过利用偏移注意机制和邻域信息嵌入,PCT在点云分类中实现了最先进的性能。Han等人提出了另一种逐点学习全局特征的方法并将其命名为PT(PointTransformer)。具体来说,他们设计了一个多级Transforme来提取具有不同分辨率的目标点云的全局特征,然后将这些特征串联起来,并将它们输入到一个多尺度Trans fformer中,以获得最终的全局特征。Point Transformer不是以逐点方式提取全局特征,而是将Trasnsformer层应用于点云的局部邻域,并通过向下转换模块分层提取局部特征。最后,通过全局平均池操作可以获得全局特征。然而,由于Point Transformer块应用于每层的所有输入点,此方法可能会产生信息冗余。此外,纯Transformer体系结构(无CNN),由于变压器中存在大量线性层,可能会导致较高的计算和内存成本。现有的模型包括PointTransformer和Point Cloud Transformer,PointTransformer在点上使用单个头部的自我注意,以创建通过K-NN和最远点采样获得的局部补片的排列不变表示,Point Cloud Transformer将偏移注意块应用于3D点云。两种模型创建了一种新颖的Transformer模块,该模块对输入执行特征方式以及点积关注,以实现精确有效的处理。
3 DRPT网络构建

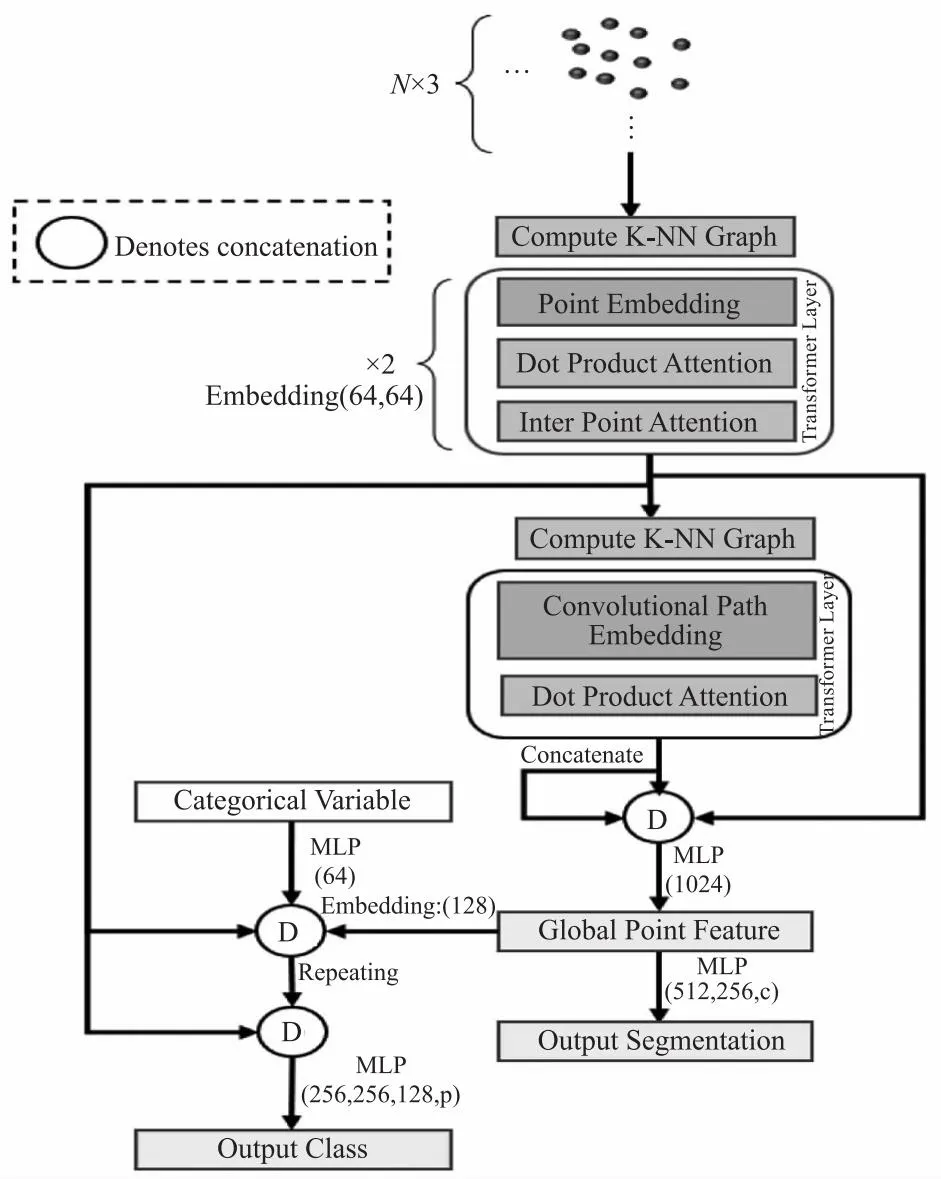
图1 DRPT模型结构
DRPT的总体架构如图1所示。本文主要改进为在点云Transformer中加入点嵌入模块和具有卷积注意投影的点间注意模块并将其应用于3D点云识别与分割。具体表现为当一个size为N×3的输入点云通过该体系结构时,通过基于欧几里德距离寻找其K-NN来计算点近邻图。然后,将计算结果将通过点嵌入层传递,该层将输入数据映射到隐式包含点的最近邻域表示中。这其通过2D卷积运算完成的,注意力机制选取的每个点的重叠程度可以通过步幅的长度来控制。将点积注意力操作应用于该嵌入表示,然后插入式注意模块。点积注意力可以看作是学习嵌入点的相关特征,作为其K近邻的函数。这种注意机制学习关注点的特征,而不是点本身,也就是说,对于批次中的一组点,它学习加权单个特征变换。
另一方面,插入点注意可以解释为在一个批次内学习不同点之间的关系(按点嵌入而不是按点的单个特征操作的行矩阵注意)。这形成了DRPT的一层。我们在InterPoint Attention操作之后更新近邻图,然后将其传递到下一个DRPT层使用特征空间嵌入维数较高的第三层也是最后一层DRPT层来学习点云的表示,无需插入注意。深层的插入注意并不能提供很多继续你,因为Transformer最终可以学习超越其点集嵌入维度的位置的关系。这也意味着,与共享加权MLP相比,Transformer能够在更深的层中可视化超出其有限感受野的输入,使其成为特征空间嵌入的更好选择。将此注意模块添加到更深的层只会略微提高性能,但会显著增加计算量。然后将每个变压器层的输出串联起来,并通过最终的共享加权MLP。然后将其合并为全局最大值,以获得形成点云表示的全局特征向量。然后通过一系列MLP进一步处理该表示,以对点云进行分类,或为点云中的每个点获取语义点标签。
3.1 点积及双随机点间注意力机制嵌入
具有点嵌入的PCT是提取全局特征的有效网络。然而,它忽略了在点云学习中同样重要的局部邻域信息。点积注意力操作被应用于嵌入后,点积注意力可以被看作是学习作为其M个最近邻函数点嵌入的相关特征。这种注意机制学习关注点的特征不是点本身,即对于一批中的一组点,它学习的式加权各个特征变换。之后是点间注意模块。点间注意力可以被解释为在邻域中学习不同点本身之间的关系,点间注意力采用逐行矩阵注意力针对每个点嵌入操作,本文将行随机矩阵注意力改为双随机矩阵注意力,其能够增加点之间的交互,增强特征提取。将Softmax被Sinkhorn的输出所代替,然后将它传递给下一个DRPT层。使深层的点间注意力能够提供信息,Transformer最终可以学习跨越其嵌入维度的局部性的关系。这也意味着Transformer能够在更深的层中可视化超出其有限感受野的输入,与共享加权的MLPs相比,这使它们成为特征空间嵌入的更好选择。将这种关注块添加到更深的层仅略微提高了性能,但是显著增加了计算如图2所示。

图2 邻域嵌入架构
每个Transformer层的输出然后被连接并通过最终的共享加权MLP。然后对其进行全局最大汇集,以获得形成点云表示的全局特征向量。然后,通过一系列MLP进一步处理该表示,以对点云进行分类,或者获得点云中每个点的语义点标签。如在传统的Transformer模型结构中一样,在关注层之后使用剩余连接层标准化以及MLP层。
3.2 Point Transformer卷积层构建
使用点积注意力和自注意力的组合,通过网络传播输入中最重要的特征。DRPT通过使用卷积层对注意力矩阵进行采样。利用卷积的能力来学习3D点的相关特征集。因此用形成卷积投影的深度方向卷积层替换关注块中的原始全连接层,以获得注意矩阵,如图3所示。
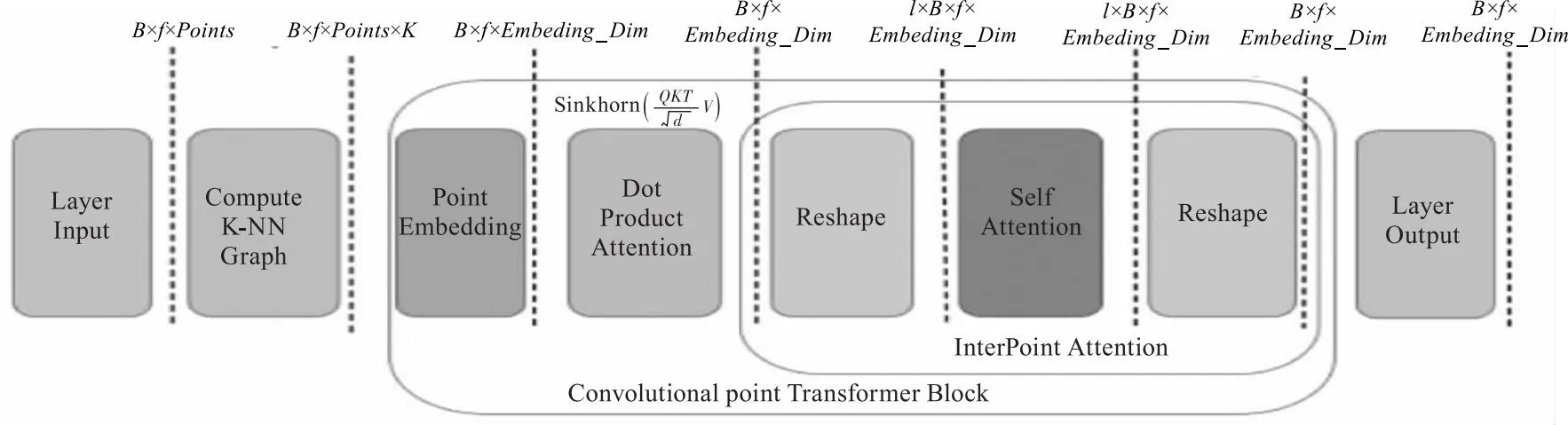
图3 点积注意力和点间注意力的Transformer块
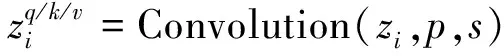
Sinkhorn(C)=argminK1n
=K
(4)
卷积运算是一种深度可分离的卷积运算,其元组为内核大小和步长。现在,将通过整个DRPT模块的数据流形式化为批量大小B的,可得点积注意力块输出如式:
(5)
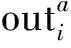
(6)

4 实验和结果
点云分类、零件分割和语义场景分割三个不同的数据集上对模型进行了评估。对于分类,使用基准ModelNet40数据集,对于对象部分分割,使用ShapeNet部分数据集。SemanticKITTI数据集进行语义场景分割。使用基于余弦退火的学习率调度器,不使用批量标准化衰减。在初始实验之后,定制的学习率计划被用于分段任务。ModelNet40数据集包含3D CAD模型的网格。共有311个模型可用于40个类别,分成468个训练测试集。使用所有的实验和数据集提供的官方分割,以保持公平的比较。在数据预处理方面,遵循与相同的步骤。从网格表面均匀采样1024个点,并重新调整点云以适应单位球,在训练过程中使用数据扩充。在增强过程中,用随机抖动和缩放来扰动这些点最终的检测结果如表1。其中将Class Accuracy,Instance Accuracy作为两项评价指标进行模型对比,将DRPT与其他先进算法进行对比。

表1 ModelNet40精度对比
从表1中可以看出,DRPT优于现有的分类方法,甚至略好于PointTransformer。当模型中采用图形计算方法时,与处理静态图形以及动态图形的其他方法进行比较,以进行点云分类。在这里,即使没有在每一层重新计算图形,DRPT也优于动态边缘条件滤波器(ECC),并且与DGCNN性能相当。每层之前的动态图形计算有助于DRPT超越现有的基于图形和非图形的方法的准确性其中包括略微超过现有的基于Transformer的方法。
4.1 ShapeNet Part分割结果
ShapeNetPart数据集包含来自16个对象类别,881个3D形状。总共有50个对象部分可用于分割。仅选取部分在数据集上的结果总结在表2中。

表2 ShapeNet Part分割对比
表2显示了按类别划分的结果,所使用的评估度量是部分精度和平均交集/并集,并针对整体和每个对象类别给出。结果表明,本文的DRPT比PointNet++和PCT分别提高1.9 %和0.6 %。DRPT以87.0 %的mIoU取得了最好的结果。在测试过程中,使用了多尺度测试策略,对于所有三个模型,批量大小,训练时期和学习率被设置为与正常估计任务的训练相同,最终通过对模型在ShapeNet数据集的可视化如图4所示。

图4 ShapeNet上的DRPT分割结果
实验在完整形状和部分扫描上训练模型。结果显示,DRPT能够有最高87.0的mIoU。在图4中,给出了完整和部分数据的定性结果。可以看到,尽管部分数据区分复杂,但模型展示出的的预测是合理的。
4.2 SemanticKITTI点云分割
SemanticKITTI基于KITTI Vision Benchmark,为所有序列提供语义注释,涵盖了所用汽车LiDAR完整的360度视野。数据集包含28个类,包括区分非移动和移动对象。类别涵盖所有交通参与者,也包括地面功能类别,如停车场、人行道。用不同的类别注释了移动和非移动的交通参与者,包括汽车、卡车、摩托车、行人和骑自行车的人如图5所示,这可以推理场景中的动态对象。
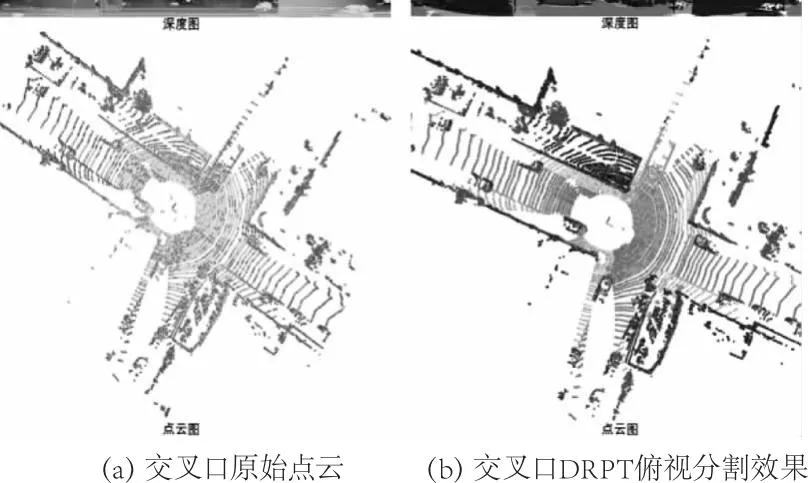
图5 SemanticKITTI分割图
由图5可以看出DRPT模型在道路场景中对于道路、车辆、植物等检测效果明显,能够有效将这些物体在点云图中进行有效分割。另外,从图5中DRPT算法处理后的深度图与原始深度图的对比能够看出,DRPT算法能进行高精度的分割,并且从点云图的效果能够看出在点云分割中对于道路以及道路周围环境和参与者的分割具有良好的效果,在分割完成后能够使得检测目标更为简单。按照官方提出的采用pIoU(Point Intersection over Union)作为评价指标进行实验。pIoU是点云语义分割任务中常用的评价指标,含义是所有真实标签和预测标签的交集与并集的比值,包括完全匹配和部分匹配的样本,其值越高代表模型处理点云能力越强。实验通过与基于雷达数据的基准网络PointNet,Voxel RCNN,VoxelNet,PointNet++,PointTransformer等经典网络进行对比,使用数据集对比结果如表3所示。

表3 Semantickitti精度对比
从表3中可以看出,DRPT的pIoU值为85.9 %,明显优于现有的分类方法,甚至略好于PointTransformer。DRPT加强了网络对于全局特征的提取,提高了模型对于整体检测精度,但对于小目标类的检测能力并未有明显提升。当模型中采用图形计算方法时,与处理静态图形以及动态图形的其他方法进行比较,以进行点云分类,并在距离检测方面展示优越性。
5 结 论
本文提出了DRPT,一种使用Transformers处理3D点云的方法。DRPT通过在每个中间网络层进行动态图形计算来优化点云处理。它使用点嵌入并将其转换为转换器友好的数据表示,然后使用双随机点间注意模块来促进点之间的串扰。DRPT优于现有的卷积方法,并在各种基准任务上与现有的基于Transformer的方法相比具有更好的性能。未来研究方向是学习沿着三维点云的流形均匀采样点以提高模型准确性。虽然DRPT可以作为点云处理任务的有效骨干,并扩展到各种应用,但是由于Transformer框架的计算量较大,处理速度较慢,需要进一步提高处理速度。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
金桥(2018年4期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2014年5期)2014-11-10
