
面向局部学习的点云分割分类网络
2024-02-05 01:32冯锦梁温智成叶森辉
激光与红外 2024年1期
冯锦梁,王 蕾,温智成,叶森辉,马 晗
(东华理工大学,江西 南昌 330013)
1 引 言
在各种3D对象表示中,点云越来越受欢迎,成为最基本的3D数据表示方法之一。这种流行源于立体匹配算法的发展和三维传感器的日益普及,比如激光雷达,它可以产生点云作为原始输出。高质量的点云是连接虚拟世界和现实世界的桥梁。例如,语义信息可以丰富周围的信息。点云的语义分割、分类任务是计算机视觉[1-3]、智能驾驶[4]、遥感测绘[5-6]、文物古迹[7-8]等研究的基础。与图像不同的是,点云是无序的、无结构的,在不同距离上密度分布不均匀,这些特征使得现有深度学习在点云语义分割与分类方法上比图像更加困难。现有深度学习方法在点云分类分割上具有效率低、局部细节识别易混淆等缺点[9]。如何有效地对三维点云模型进行高精度识别成为一个亟待解决的问题[10]。
2 相关工作
针对深度学习下的点云分割或分类,目前存在有几种方法。它们可以大致分为基于多视图的方法、基于体素的方法和基于点的方法。
基于多视图的方法首先使用虚拟相机捕捉不同位置下多个视角的图,然后通过卷积层与池化层聚合输出,如多视图卷积神经网络(Multi-View CNN,MVCNN)[11],不过该方法不能动态选择视图,导致丢失大量关键的几何空间信息。后续针对MVCNN的不足,Feng等提出组视图卷积神经网络(Group-View CNN,GVCNN)[12],该方法将多视图先按内容分组,再投影到指定的2D平面上,然后应用2D FCNs(Fully Convolutional Networks)来识别3D对象。不过这类方法没有充分利用数据,因为在二维投影中丢失了第z维的信息,限制了他们在3D场景中分析复杂3D物体的能力。
基于体素的方法将点云离散在体积3D网格上,使用标准3D FCNs进行形状语义分割。如VoxNet[13]、VoxelNet[14]与将体素简化为pillars(即仅在平面中进行体素化)的PointPillars[15]等网络,这类方法需要进行数据转换,由于网格结构的分辨率有限,导致了额外的计算成本和信息损失。此外,基于体素的方法对GPU内存的要求也很高,因此限制其应用于单个对象和小场景领域中的发展。
与上述两种方法相比,基于点的方法直接将点云作为网络的输入,在各种数据集上都表现出了良好的性能。2017年,Charles团队推出的PointNet[16]网络是该方向的第一个成功尝试,它采用了一系列多层感知器(mlp)和max-pooling算子解决点云的无序问题以及学习全局特征,在3D形状分类和场景分割的场景中取得了巨大成功。但是,PointNet针对的是孤立点的学习,忽然了点与点之间的联系关系,因此该网络在不同尺度上提取局部信息的能力较弱。针对PointNet网络出现的不足之处,Charles团队后续推出了PointNet++[17]网络,它提出了一个新颖的Set Abstraction模块,该模块对点云进行子采样,对邻域进行分组,通过一组mlp提取局部信息,然后通过约简层(即池化)聚合局部信息,并且PointNet++通过度量点与点之间空间的距离,能够利用上下文尺度的增长学习局部特征,使得精度进一步提升。Yang等人[18]提出Point Attention Transformers(PATs),该方法通过其自身的绝对位置和相对于其相邻的相对位置来表示每个点,并通过MLPs学习高维特征。然后由集体重新排序注意力模块(Group Shuffle Attention,GSA)来捕获点之间的关系,使用Gumbel子集采样层(Gumbel Subset Sampling,GSS)来学习分层特征。Zhao等人[19]基于PointNet++提出的PointWeb网络,通过利用学习局部邻域上下文信息与Adaptive Feature Adjustment(AFA)模块来自适应的调整特征。Yan等人[20]提出的PointASNL中,利用自适应采样模块(Adaptive Sampling,AS)来自适应调整最远点采样算法(Furthest Point Sampling,FPS)所采样的点的坐标和特征,并提出一个local-non local(L-NL)模块来捕捉这些采样点的局部和远距离依赖性,进一步减少噪声对模型的影响。
本文受到点云语义分割网络RandLA-Net[21]的启发,将局部注意力机制加入基础框架PointNet++,使得网络可以自适应地筛选局部信息,关注更为重要的特征信息。同时加入增强局部信息模块,通过添加局部信息模块获取更为丰富的局部信息。两者通过增加点云的细粒度局部特征的学习能力,使得网络分割与分类精度进一步提升,本文将这种新型的网络命名为Con-PointNet++。
3 本文方法
3.1 基准模型PointNet++
PointNet++核心思想:在局部的区域区域内,重复的,迭代性使用PointNet。由于局部区域具有置换不变性,所以整体也具有局部不变性。PointNet++这个核心思想主要借鉴了CNN的多层感受野的思想。首先从小的局部区域捕获细粒度的局部结构来提取局部特征,之后局部特征被分组到更大的单元,通过迭代得到更为丰富的局部特征,最后获取到整个输入点集的特征。PointNet++包含了分割与分类网络,具体步骤如下:
1)其先通过sampling与grouping方法在整个点云的局部采样并划一个范围,将里面的点作为局部的特征;
2)用PointNet进行一次特征的提取;
3)重复完成上述两个步骤,即降采样操作,使得原本的点集个数变得越来越少,而每个点都带有上一层通过PointNet提取出来的局部特征,也就是降采样操作后每个点包含的信息变多了;
4)分类网络只需要将PointNet提取出来的局部特征进行最大池化,然后经过全连接层进行分类即可;而分割网络相对复杂,需要先使用编码器主簿提取局部特征,通过解码器逐步对特征进行上采样,并与对于编码器输出的特征进行连接,最后使用全连接层对输出结果进行预测。
3.2 增强模式下的局部特征学习
由于3D 点云数据规模庞大,PointNe++ 等系列网络模型均将原始输入点云数据划分成不同子区域,在对子区域中的原始点云采样后分批次输入卷积神经网络CNN中学习特征。PointNet++采用最远点采样法(Farthest Point Sampling,FPS)以维持子区域中点云数据的结构。但由于PointNet++基础框架只考虑点本身的信息,其点领域的信息并没有考虑,采样后不可避免丢失了中心点与其邻域的邻接关系,从而限制了局部几何特征的充分表达与网络对其的学习能力,从而导致模型的性能下降。
针对上述不足,本文使用增强局部信息的模块,在原有PointNet++基础框架中引入邻域信息添加模块,增加局部特征信息量,如图1所示。
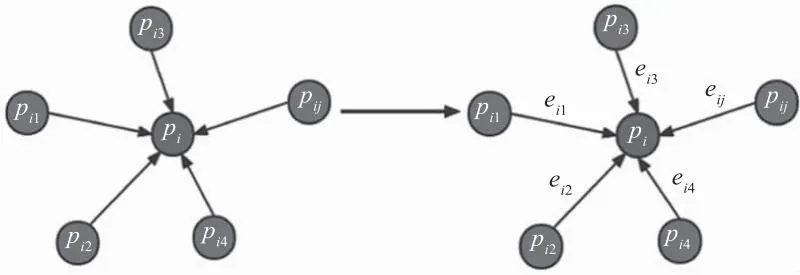
图1 增强局部信息模块
首先使用K近邻搜索算法(KNN)获取每个中心点(pi,fi)的相邻点(pij,fij),公式如下:
pij,fij=KNN(pi,fi)
(1)
然后分别计算相邻点坐标和对应特征与中心点坐标和对应特征的差值,并将两者结果在特征维度上进行拼接得到增强后的局部特征(faug),公式如下:
faug=concat(pij-pi,fij-fi)
(2)
最后使用MLP学习局部特征(Faug),公式如下:
Faug=MLP(faug)
(3)
如上述表达式所示,MLP为多层感知机,concat为拼接特征方法;pi为中心点坐标;fi为中心点特征;pi1,pi2…pij为领域点坐标;fi1,fi2…fij为邻域点特征。
3.3 局部注意力机制下的融合池化
现有的卷积神经网络通常使用最大/平均池化操作,可以通过集成邻域特征以生成全局特征向量,但是该操作很难整合到相邻点的特征,导致丢失大量特征信息。本文将注意力机制引入局部特征提取机制中,同时为了保持网络特征输出的平移不变性,将注意力机制下的细节特征与最大池化获取的显著特征进行融合操作,获取到特征信息更为丰富的局部特征,其结构如图2所示。

图2 局部注意力机制下的融合池化
局部注意力机制下的融合池化模块分为2部分,首先对该局部特征使用注意力机制自适应地学习到局部点的权重(score),表达式为:
score=Softmax(MLP(fij))
(4)
然后利用公式(3)得到的权重信息对局部特征进行加权求和获得局部注意力池化特征(fatten),表达式为:
fatten=MLP(Sum(score·fij))
(5)
同时将点云局部特征进行最大池化得到最大池化特征(fmax),表达式为:
fmax=Max(fij)
(6)
最后将公式(4)得到的局部注意力池化特征与公式(5)得到的最大池化特征进行拼接得到融合池化特征(result),既包含了更多有用信息,同时保证网络特征输出的平移不变性,表达式为:
result=fatten+fmax
(7)
3.4 Con-pointnet++网络结构设计
Con-pointnet++网络结构如图3所示,分割网络由Encoder层、Decoder层和分类器3部分组成;分类网络由Encoder层和分类器组成。
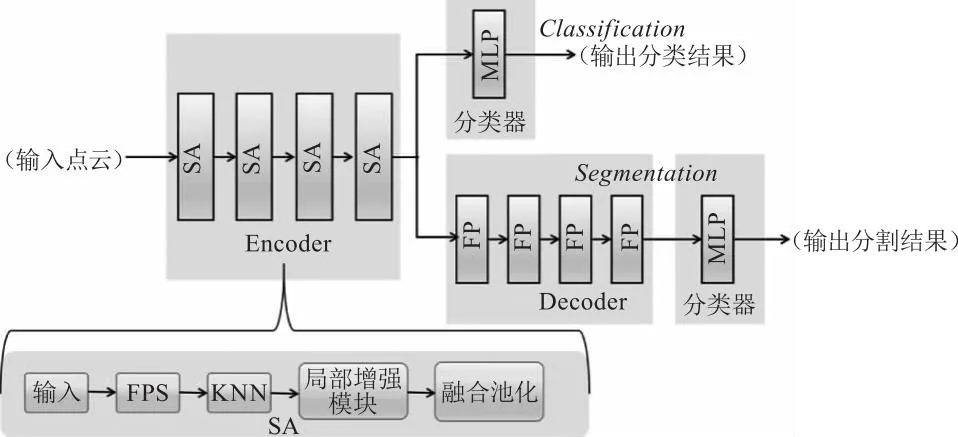
图3 Con-pointnet++网络结构示意图
(1)Encoder层包括点云数据采样、增强局部信息模块和融合池化层。数据采样层使用最远点采样法和邻域点采样法获取局部信息,同时增强局部信息模块将中心点的邻域信息考虑进来,组成更为丰富的局部信息。最后融合池化模块分别通过对局部特征进行最大池化与注意力池化,将二者拼接得到更为丰富的局部特征信息;(2)分割网络中Decoder层主要使用插值法来实现,首先计算出逆向距离的权重,得到插值后的点特征,再将该特征与Encoder层输出的特征进行拼接,最后经由分类器输出语义分割结果;在分类网络中直接使用分类器将Encoder层输出的结果进行分类。
4 实验与结果分析
4.1 点云分割实验配置
本文使用室内场景数据集 S3DIS与ModelNet40数据集分别评估Con-PointNet++的3D点云分割性能和分类性能,并在最后一小节进行消融实验,进一步验证增强局部信息模块与注意力机制下的融合池化模块对于Con-PointNet++模型的有效性。实验环境配置如下:硬件为显卡NVIDIA GeForce RTX 3080 10 GB GPU、 处理器Intel(R)Core(TM)i9-9900kCPU @3.60 GHz、内存32 GB;软件为 UBUNTU20.04 LTS+CUDA11.2+Python 3.6,深度学习框架为 Pytorch 1.12.1。
网络训练参数设置如下:采用余弦退火算法使学习率逐渐衰减;采用 Adam 优化器,初始学习率为0.01;选择使用ReLu激活函数。训练时,batch size 设置为 32;测试时,batch size 也同样设置为 32。分割网络训练 100个 epoch,分类网络训练 250个 epoch。
4.2 评价指标说明
网络语义分割精度评估指标采用平均交并比(mIoU)与(mAcc);网络分类精度评估指标采用平均类精度(mAcc)与总体分类精度(OA)。在三维点云分割与分类实验中,mAcc、OA和mIoU是最常用的衡量方法精度的指标[22]。mIoU指计算两个集合的交并比,在语义分割的问题中,这两个集合分别表示为真实值(ground truth)和预测值(predicted segmentation);mAcc用于计算每个类别的分类精度再除以类别数获取到平均类别精度;OA用于计算。用计算公式分别如下:
(8)
(9)
(10)
其中,k表示数据集中点云的类别个数(包含空类);有K+ 1个类,pij是类i隐含属于类j的最小单位(如像素、体素、网格、点),即pii代表真阳性,pij与pji分别代表假阳性与假阴性[22]。mIoU、acc和mAcc值越大,代表分割、分类效果越好。
4.3 实 验
4.3.1 室内场景S3DIS语义分割实验
本文语义分割实验以S3DIS数据集为研究对象,该数据集是斯坦福大学提供的大场景室内3D点云数据集,包含6个教学和办公Area,共有 271个独立房间,特征点超过了2.15 亿。
训练时将房间分为1×1(m)的块,随机对每块区域选取4096个点输入,其中每个点包含XYZ坐标信息、 归一化坐标和RGB颜色信息。以数据集中的Area_1、Area_2、Area_3、Area_4、Area_6为训练样本,Area_5为测试区域评估模型分割精度。结果如表1所示,可以看出,与基准网络PointNet++相比较,本文Con-PointNet++在mIoU上可提升5.2 %;与其他网络(PointNet、DGCNN、SegCloud、ASIS(Associatively Segmenting Instances and Semantics)和DeepGCN)相比,mAcc与mIoU都有着不同程度的提升,因此可以验证加入增强局部信息、与注意力机制下的融合池化模块下的Con-PointNet++在整体性能上明显优于其他3D点云场景语义分割网络。

表1 不同方法在S3DIS Area_5中的结果对比
选取S3DIS 数据集中的 Area5_conferenceRoom_1、Area5_hallway_12和Area5_office_15三个房间作为可视化分割场景样本,将所提算法的可视化分割结果与基准模型PointNet++ 进行对比。图4(b)~(c)分别为Area5_conferenceRoom_1、Area5_hallway_12和Area5_office_15的原始点云、 真实分割结果、PointNet++ 分割结果和所提算法的分割结果可视化图,其中每一列表示一个场景,每一行表示对应方法的结果。

图4 Area5_conferenceRoom_1
由图4可看出,加入了增强局部特征模块与注意力机制下的融合池化模块后的网络,分割能力明显增强。本文所提方法与PointNet++相比较,在场景(a)中,椅子细节处、墙体与墙上的图画处分割明显更优,PointNet++几乎丢失了墙上的图画全部信息;在场景(b)中,PointNet++对于走廊两边的门框与墙上图画细节丢失较多,本文所提算法则相对精确的还原了真实分割场景;场景(c)是较为杂乱的办公室场景,PointNet++分割效果明显变差,左墙投影幕布部分识别成墙体,中间的办公桌错误识别成椅子,而本文所提算法识别精准,且相对PointNet++分割细节保留更多,在办公桌与椅子连接处的特征点识别精度明显更高。
4.3.2 ModelNet40上的分类实验
本文分类实验在标准公开数据集ModelNet40上进行,该数据集由普林顿大学提供,共包含12311个三维CAD模型,9843个模型用以训练,2468个模型用以测试,总共包含40个类别。同时为了让网络学习到旋转不变性、放缩不变性和对噪声具有一定的抗干扰能力,通过对数据进行随机旋转、放缩以及添加噪声进行数据增强,增强网络的鲁棒性。
结果如表2所示,可以看出,对于基准网络PointNet++,本文网络在整体分类精度达到91.2 %,提升约0.5 %,同时对于所提其他网络(PointNet、MVCNN与VoxNet)相比,因加入了增强局部特征模块与注意力机制下的融合池化模块,在OA与mAcc性能均有提升,通过实验结果可看出,本文所提网络在分类任务上同样具有较强能力。

表2 不同方法在ModelNet40中的结果对比
4.4 消融实验
为了更好地验证增强局部信息(+Loc)、 与注意力机制下的融合池化(+Mer)模块对Con-PointNet++的有效性,将基准模型PointNet++与不同模块组合,用以分析各模块对网络精度的影响。
分割网络保持在S3DIS Area_5上进行消融实验。如表3所示,相比于基准模型PointNet++的mIoU(约50.0 %),各个模块的加入均使得基准模型的3D点云场景语义分割能力获得明显提升。

表3 针对S3DIS Area_5数据的消融实验结果
分类网络保持在ModelNet40数据集上进行消融实验。如表4所示,相比于基准模型PointNet++的OA(约90.7 %),各个模块的加入也均使得基准模型的3D点云分类能力获得明显提升。

表4 针对ModelNet40的消融实验结果
5 结 语
针对PointNet++下采样时只关注点本身的信息以及使用最大池化导致丢失次最大值信息等问题,本文提出Con-PointNet++网络。通过加入增强局部信息模块将相邻点的信息添加关注;使用局部注意力机制下的融合池化,将最大池化获取的最大值信息与注意力池化自适应地获取细节信息进行融合,获取到更为丰富的局部特征信息。数据集S3DIS、ModelNet40的实验以及消融实验证明所提方法的有效性。最后,本文期望Con-PointNet++网络随着点云的发展能够释放更深层次的潜力。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
小雪花·成长指南(2022年1期)2022-04-09
软件导刊(2022年3期)2022-03-25
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
数学物理学报(2021年2期)2021-06-09
计算机技术与发展(2019年1期)2019-01-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
发明与创新(2016年38期)2016-08-22
