
楚辞知识库构建与网站实现研究
2010-04-18 02:12钱智勇周建忠
图书馆理论与实践 2010年10期
●钱智勇,周建忠,贾 捷
(南通大学 a.图书馆,b.楚辞研究中心,江苏 南通 226019)
1 研究背景
1.1 楚辞文献研究特点及楚辞文献知识库构建的意义
中国文化源远流长,先秦时代确立的文化品格对后世有着极其广泛而又深远的影响。对屈原及楚辞的研究,自汉以来绵延不衰,薪火相传。历史证明,不仅在古代文学领域,楚辞研究的价值历久弥新,即便在网络技术飞速发展的今天,楚辞依然是魅力无穷、炫目斑斓的人文渊薮。
目前,楚辞文献研究的特点是:①内容丰富,包括楚辞的校勘、目录、版本、注释、今译、考据、辑轶、辨伪等等,类型多样、资料翔实,因而利用价值极高。②楚辞研究方法多样,具有文本研究与学术史研究相并重,文学研究与文化背景相融通,出土文献与地上文献相结合,域外文献与国内文献相参照等特点。
鉴于楚辞版本及楚辞研究文献资源数量的日益激增,以及网络上知识体系分散无序和楚辞学科缺乏规范的专业分类体系的现状,对楚辞文献知识的组织与开发势在必行。通过语义网技术对楚辞知识有效组织,建立楚辞研究知识库和网站检索系统,使不同需求的网民能够运用方便、快捷、高效的新形式语义检索服务,链接到关于楚辞的分类知识,便于世界各地读者了解我国丰富的楚辞文化遗产,推动楚辞文学对国内外学人的影响,促使楚辞文化在世界的传播。同时,楚辞知识库的构建提供了文学领域语义知识库、知识检索的构建方法和具体构建成果,推动知识组织原理技术在文学领域的数字化、网络化研究。此外,在教学科研方面,为楚辞研究学者和楚辞爱好者提供个性化信息服务,帮助他们进行楚辞研究的知识挖掘和知识发现。这不仅是计算机技术运用于楚辞与楚文化保存和普及的新尝试,更是对古代文学学科的计算机辅助研究与教学的前瞻性探索。
1.2 语义知识库研究概述
语义知识库是对领域知识的模型化描述。实现基于知识的相关性与智能检索是近年来文献学和信息科学的研究热点之一。电脑科技进入英美文学研究大约开始于20世纪60年代。1996年结合人文与电脑咨询的期刊《Computersand the Humanities》创刊,开启了文学(西方)研究者以电脑来处理文学文本的学术研究。在语言学方面,世界上已建设的代表性语义知识库项目有:①美国普林斯顿大学1985年开始建设的WordNet(采用手工构建,包含20716个概念词及其语义关系);[1]② 美国微软公司1993年开始构建的NindNet(采用自动构建,建成约16万词汇的语义关系描述);[2]③英国剑桥大学的ILD(采用手工构建,提供语义分类、语义特征、语义角色与选择限制等);④美国加州大学1997年开始的FrameNet(采用手工构建,包含625个框架、8900多个词语、13.5万条例句等) 等等。[3]
语言学因其独有的形、音、义相结合的特质而被专家较早引入计算机科学技术,上世纪90年代以来,我国大陆及台湾地区对语义知识库的研究也在如火如荼的开展着,许多学术专家正在进行知识库模型和应用的理论研究与实践探索,其中包括对语言学、历史学、农学、医学等众多学科的知识库构建研究。[3]与人文领域相关的有:中国人民大学、清华大学手工构建的“现代汉语术语动词机器词典”;北京大学的CCD(手工构建,语义知识表述了近6万个概念)并开发“中国古代诗词电脑辅助研究系统”,其中包含“唐宋诗之词汇自动分析及应用”;董振东项目组的HowNet(采用手工构建,包含81062个汉语词汇、95690个汉语语义项、24089个概念)等项目;台湾元智大学中国语言学系罗凤珠教授与清华大学共同致力于研制“汉语诗的本体知识与语义检索”。[4]在中国大陆与台湾地区的古代文学数字化研究是基于中国古代诗歌语料库的计算机语言学相关研究为基础的,缺少对中国古代辞赋语料库的研究。
《楚辞》之香草纷呈、喻义各别,是艺术的高妙之处,也是难以把握之处,由此激发了利用计算机中的知识组织和知识描述对其原本隐藏知识进行挖掘,探知楚辞及辞赋的文字、章法、修辞和表现技巧。[5]同时,在知识库构建中又深入到具体知识的关联层面,将楚辞的作品表与楚辞作者表、楚辞地名表、楚辞版本表、楚辞事件表、屈原时代表、屈原家族表、楚辞植物表、楚辞音像数据库、专家学者知识库、楚辞论文索引、兰文化知识库和中国古代辞赋简论表相互关联。反之,在楚辞知识库的内部知识推理和外部阅读与检索工具中,亦能从楚辞的单片论文出发,延伸到楚辞的作品表及相关性的知识,从而极大丰富读者的知识获取。
2 基于本体的楚辞知识库结构设计与实现
2.1 楚辞研究文献信息资源的调查、收集和数字化
多途径、多渠道搜集自汉以来的楚辞文献和楚辞研究信息资源,包括古籍文献、研究专著、研究论文、图片和音像资料等,进行数字化处理。目前,我们已完成超过7000篇题录和1000多篇论文、100种楚辞专著和数百种图片、音像资料的数字化,同时对楚辞文献进行主题分析,为楚辞研究知识库的构建提供文献保障和准备。我们在楚辞语料整理、入库与标注时,保持了语料保存的统一性和规范性。在楚辞专家的鉴定下确保了录入楚辞相关及相似语料的正确性。
2.2 建立楚辞原始文本库和楚辞研究文献库
经过聚类技术对楚辞用户进行分析发现:读者在网上搜寻到的楚辞信息需要进一步分层次处理。以《楚辞》中的《橘颂》为例,从楚辞爱好者的基本认知层面来分析,他们关心的是每行诗句的注音、注疏及内容诠释。从楚辞知识理解和赏析的层面来看,他们关注的是楚辞的作者、楚辞的文化背景,屈原的家族渊源、有关楚辞的音像、考古等知识需求。从楚辞研究者整体访问楚辞知识的层面来说,他们更在意与楚辞相关的其他引申的相似信息,例如楚辞专家、楚辞论著、楚辞论文、辞赋源流等其他信息。基于此,我们将楚辞的信息分为楚辞原始文本库和楚辞研究文献库,用基于本体的元数据进行分层管理。标准参照《我国数字图书馆标准与规范建设》中有关元数据与知识组织标准。元数据可应用于不同层次,或者说,可以定义楚辞全局的元数据,也可以定义关于楚辞知识某一层次资源的元数据,并最终以一种统一、稳定的楚辞描述方式和组织存储在不同介质上的信息,有助于查找和描述信息资源,从而改进对资源进行检索、管理和利用的途径。楚辞原始文本库包含楚辞作者表、楚辞地名表、楚辞版本表、楚辞作品表、楚辞植物表、楚辞音像表、中国辞赋发展表等核心概念集与扩展概念集;楚辞研究文献库中将包括楚辞影响表、楚辞与考古表、楚辞论文表、楚辞专家学者表等核心概念集。以上划分极大解决了楚辞的内部知识系统,并为语义标注和语义推理提供可行性的方案。图1是在元数据分层管理的基础上,以《橘颂》为实例的系统构思图。[6]
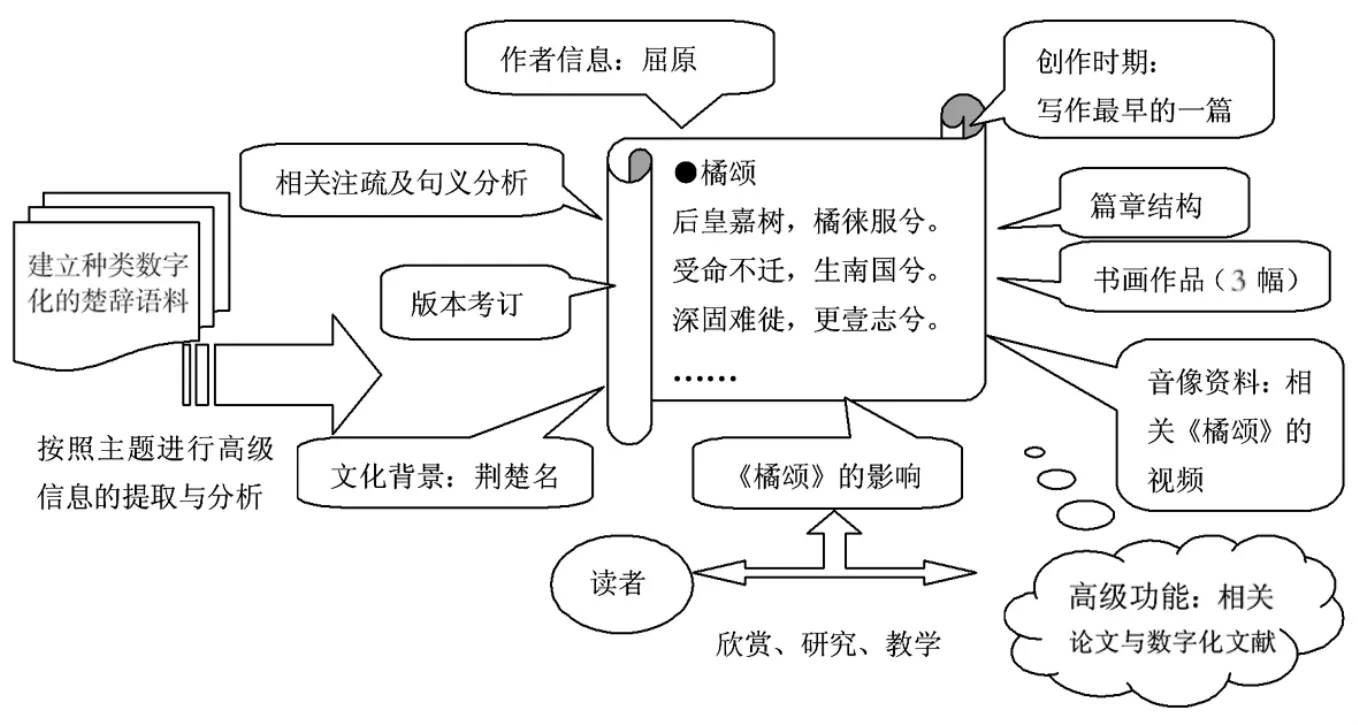
图1 以《橘颂》为实例的系统构思
2.3 楚辞研究知识抽取与语义处理
我们的步骤是利用具有语义功能的概念图模型搭建楚辞原始文本库与研究文献库之间的对应关系,并进行语义标注与推理,完成楚辞知识抽取库的构建。一方面,由楚辞研究专家指导专业人员利用语义标注工具进行语义化处理。这需要考虑3种情况:同义词、概念的歧义、概念的上下位关系。另一方面,我们主要借助人工参与及结合现有的分词工具,设计楚辞研究文档分析器嵌入知识库系统当中,进行语义提取、组织和处理,进而通过概念的上位概念或是下位概念亦能检索到潜在的有用信息。
2.4 楚辞研究知识本体构建
利用本体开发工具构建楚辞研究知识关联的过程如下:①由楚辞专家指导定义楚辞研究概念的层次结构。②定义楚辞研究概念术语及属性、关系及关系属性。③本体编码。④楚辞研究知识概念实例化。包括实例声明、实例描述和关系关联三部分;生成不少于1000个本体类、关系属性、推理属性和实例。⑤构建楚辞研究语义概念词典。建立楚辞研究知识库的抽词词典,以词汇作为楚辞研究知识的自动标引、自动分类的工具和楚辞研究知识检索的入口词表。[7,8]其中每个概念都将能被清晰地定义和拥有可机器处理的语义。
3 楚辞知识库网站前台实现
知识库网站前台显示使用了web2.0理念,结合了具有楚文化底蕴的展示页面。我们在设计整个知识库系统的时候,考虑到“楚辞知识库”网站的整体感,对知识库的前台页面设计也进行了VI整合,以便楚辞专业学者或是感兴趣的用户在进行知识检索和学习的同时,感受楚文化古韵的视觉冲击。
在前台设计中,为了使用户使用更加方便,降低用户楚辞学的专业门槛,我们将楚辞知识库中的5个大类内容分别做了聚合功能。在用户不知从何处入手了解楚辞的时候,只要点击左边的5大类内容,就可以轻而易举地获取楚辞知识。这里的聚合功能不同于传统网站的简单分类,而是用了“类聚合”的概念。使用“类聚合”,可以把无数条相关记录放到N个不同的类中,这样可以降低数据库存储容量,提高数据检索的效率,并让内容录入者减轻负担,以此提高工作效率和系统利用率。
在前台显示检索结果的时候,如前所述,其结果会通过推理机自动生成4个不同的属性标签,即论文、著作、知识库、图片,另一种“类聚合”的表现形式,其以不同属性的“类聚合”来展现我们知识库的体系内容,可以让用户在获取信息时更加灵活、方便地收集楚辞信息。
4 楚辞知识库构建过程中的难点与解决构思
选用计算机语义网构建辅助文学研究的知识库还处于起步阶段。因而,以此为代表的基于本体的楚辞知识库构建还有很多问题需要关注和突破。目前需要突破的重点、难点主要有以下三个方面:
(1)楚辞研究知识中核心概念和扩展概念语义关系网的构建。我们拟根据IFLA的书目记录功能需求FRBR,利用实体——属性方法组建一个揭示楚辞书目结构和关系的概念模型,从而构建基于本体的楚辞文献知识描述体系(见图2)。
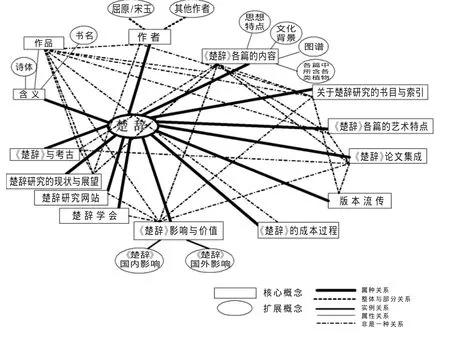
图2 楚辞知识描述体系关系图
在利用Protégé进行开发时,所建立元类中的槽必须涉及FRBR的10个关键实体。以楚辞作品这项核心概念为例,元类中的槽需要包含:一组(作品、内容表达、载体体现、单件)、二组(个人、团体)、三组(概念、实物、事件、地点)。
(2) 在知识库构建过程中,需解决以下两个问题:①在楚辞研究领域内,由于地域和习惯的不同,对同一事件或过程的表述存在结构上的差异,需建立一个经过论证的、具有一定扩展性和概括性的标准结构来规范数据的输入和存储;同时,数据的存储模型和国际本体标准OWL要可以相互转化,从而保证知识的可交换性,避免因结构不同导致的重复工作。②由于语言内在的和固有的动态性,决定了楚辞研究知识库也是需要不断发展和更新的,因此,需特别设置一个本体代理来对本体知识库进行被动式扩充,从而保证知识库的可扩展性。[9]
(3)如何提高语义提取的准确率,关键是如何在对文档词语切分处理、术语的自动提取、概念间关系提取和句法内容分析时消除歧义。我们拟采用人工参与,结合现有的分词工具、词义消歧工具、术语及其关系提取,设计楚辞研究文档分析器嵌入知识库系统中,进行语义提取、组织和处理。[10]
5 结束语
无论从语义网研究实践来看,还是从计算机网络辅助文学研究、文化传承及教学开发来看,探索基于本体的文献学知识组织与知识检索理论、方法,并借助网络平台应用于中国古代文学学科中的楚辞学研究领域只是一个研究起点。尽管还有许多难点及待开发的研究领域,但更重要的是,它超越了原始数据库的简单检索,使基于本体的楚辞知识库在检索服务上实现了智能化。我们坚信,楚辞文献语义化研究和楚辞知识库的构建将是网络信息时代中国古代文学研究方式创新历程的必要环节。
[1] Princeton University.WordNet Program[EB/OL].[2009-12-11].http://www.cogsci.princeton.edu/~wn/.
[2] 微软研究院.NLP组 MindNet项目 [EB/OL].[2009-12-11].http://research.microsoft.com/nlp/.
[3] 美国加州大学.Framenet项目 [EB/OL].[2009-12-11].http://framenet.icsi.berkeley.edu/.
[4]罗凤珠,等.语言,文学与资讯[M].台湾:新竹“国立”清华大学出版社,2004.
[5]连登岗.祖国通用语言文字的特点和地位[J].南通大学学报(社会科学版),2009(1):76-82.
[6]罗凤珠,等.古代诗歌艺术数位博物馆的设计与实现及相关的计算语言学研究[M]//语言,文学与资讯.台湾:新竹“国立”清华大学出版社,2004:219-262.
[7] Wallg M,Nie J.ALatent Semantic Structure Model for Text Classification[M].Toronto:ACM-SIGIR-2003,Workshop on Mathematic/Formal Methods in Information Retrieval,2003.
[8] Shaw-Taylor J,CristianiniN,Kemel Methodsfor Pattern Analysis[M].China Maehine Press,2005.
[9]路耀华.思维模拟与知识工程[M].北京:清华大学出版社;南宁:广西科学技术出版社,1997.
[10]董慧,等.基于本体的数字图书馆检索模型研究(Ⅰ)——体系结构解析[J].情报学报,2006(3):269-275.
猜你喜欢
哈哈画报(2021年10期)2021-02-28
汉字汉语研究(2020年3期)2020-12-14
新世纪智能(高一语文)(2019年10期)2020-01-13
制造技术与机床(2019年6期)2019-06-25
语言与文化论坛(2019年4期)2019-03-29
中学语文(2019年7期)2019-03-27
制造业自动化(2017年2期)2017-03-20
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
图书与情报(2013年1期)2013-11-16
