
基于质粒模型的DNA计算机算法求解背包问题
2010-11-30 07:15王剑波
湖南人文科技学院学报 2010年4期
王剑波
(湖南人文科技学院 计算机科学技术系,湖南 娄底 417001)
基于质粒模型的DNA计算机算法求解背包问题
王剑波
(湖南人文科技学院 计算机科学技术系,湖南 娄底 417001)
DNA计算机在求解大型科学问题中DNA链数呈纯指数增长的瓶颈亟待解决。本文提出一种将分治策略应用求解背包问题的新的基于质粒DNA计算机算法,使DNA链数可达到亚指数的O(1.414n),其中n为背包问题的维数。与已有文献结论进行的对比分析表明: 本算法将穷举算法中所需的DNA链数从O(2n)减少至O(1.414n),利用本算法将可破解的背包公钥的维数在试管级水平上从60提高到120。
DNA计算机;质粒模型;背包问题
1 DNA计算机求解NP完全问题
到目前为止,一个测试试管已可产生1018个DNA链,它可使1018位数据以数据并行的方式并行运行。因此,DNA计算机可提供相当于1018个处理单元的并行性和O(1018)的存储空间。即DNA计算的本质是将传统计算机求解NP完全问题的时间代价转换为DNA计算的空间即生物分子数目代价,因此,在基于穷举的DNA计算机算法中,纯指数阶(O(2n))的时间转化成了纯指数量级的DNA链数,这也是目前求解难解问题的DNA计算机算法中的DNA链数为(O(2n))的原因。
就DNA计算而言,用DNA计算机求解NP完全的图和组合优化问题的的一个关键问题是DNA计算模型的选择。虽然DNA计算模型一直在不断的发展,从最初的剪接系统模型发展到目前常用的剪接系统模型、粘贴模型、表面计算模型、基于质粒的DNA计算模型和基于图的自组模型以及最近的禁止-强迫模型(forbidding-enforcing,fe)等,这些模型在生物操作所出现的伪解等方面较最初的模型均有较大改进。但现有的这些模型均存在一定不足: 基于粘贴的DNA计算模型能实现二进制的各种算术运算,理论上可解决许多NP完全问题,而且在运算过程中不需要DNA链的延伸和酶的作用,但算法必须通过杂交、退火和探针的设计来完成。由于杂交及退火的不完整性,会导致大量的伪解出现。表面计算可解决一些如最佳匹配问题等NP完全问题,但基于该模型的算法中仍然存在杂交和酶切等生物操作,因而依然无法避免大量伪解的产生。基于质粒的DNA计算模型成功解决了最大权团等NP完全问题,该模型虽没有复杂的自身退火单链DNA 或PCR扩增步骤造成的麻烦,可确保计算过程免受其它酶的干扰,从而保证计算的准确性和稳定性,但受其自身特性的影响,该模型实现算术减法、乘法和除法操作目前均有难度。基于图的自组模型和fe模型尽管可成功求解小规模SAT问题,但满足条件的图的建造有时却相当困难。
为了提高DNA计算机算法可扩展性,扩大使用DNA计算机算法解决难解问题的规模,1996年,Eric Bach等[1]首次提出了一种将Adleman和Liptom的DNA计算模型相结合的改进DNA计算模型,在此基础上将求解3着色问题和独立集问题传统计算机算法的基本思想应用于该模型,在理论上实现了DNA链数为O(n1.89n)的求解3色问题的DNA算法,和链数为O(1.67n)的求解独立集问题的DNA计算机算法。但是,由于使用经典Adleman和Liptom计算模型,该模型中杂交、退火和探针的设计使得求解过程中错解和伪解率过高,理论上,生物操作数也明显复杂得多,因而难于走向实践。1997年,Fu等[2]应用传统串行算法设计技术,将所求问题先通过计算机做一定变化,以改变问题的初始解空间,达到降低DNA分子数的目的,并相应提出了几种DNA计算机算法: 链数O(1.497n)求解3-SAT问题算法、链数O(1.345n)三着色问题算法、O(1.229n)的独立集问题算法,而且,这些算法的时间或操作复杂性也均为多项式量级。但是,考虑到DNA分子计算的特性,缩小的初始空间在用DNA分子初始化时很难构造,使其可行性大大降低,而且,使用计算机来作DNA计算的部分计算工作的方式也与DNA计算机向全自动化、无外界干预的发展趋势不符[3]。
李源等[4]于2004年首次最大团问题的DNA计算中引入了进化算法,提出一种求解最大团问题的DNA计算机概率算法,该算法可在不显著增加DNA计算时间前提下,大大减少直接穷举方法试管中的DNA分子数目,对于具有顶点数为30左右的团的问题,该算法相当成功,因为它可以高概率找到问题的解,而且所需迭代的代数也不大,但对顶点数更多和连同度较大的最大团问题,该算法则很难以高概率求得问题的解[4]。
采用将电子计算机与DNA计算机相结合的方式,和在DNA算法设计中引入进化思想等,但这些方法的成功只限于小规模的局部个例,DNA计算机算法的低可扩展性问题仍然普遍存在。
本文采用传统的算法设计策略。将分治策略引入背包问题的DNA计算中,提出一种新的背包问题DNA质粒模型算法。在保持算法的DNA分子操作的计算时间(或操作次数)不变的条件下,本算法求解n维背包问题的DNA链数降低至达到了亚指数的O(1.414n)。
2 质粒模型
质粒是细菌细胞内一种自我复制的环状双链DNA分子,用于DNA重组技术的质粒大多是经过人工改造的,它通常具有复制子、克隆位点、选择标志等特征。
设P是一个质粒,s1,s2,… ,sk是P的K个相互不重叠的子段,k是正整数。对于每个i,核苷酸序列si不能出现在质粒P的其余位置上,并称si是质粒P的“位置”。每次计算都开始于盛水的缓冲器或试管中含有大量的具有相同的k个“位置”的质粒。在质粒在计算过程中不断地修改,一直到结果的读取。质粒的修改只在所谓的“位置”处进行,主要的方法是切割和粘贴。在计算过程中,每个核苷酸序列si1对应于一个计算的问题,可以通过一个实例更清楚地说明问题。假设用相应的限制性内切酶剪切了S1和S4位置的核苷酸片断,将每个操作后的外源DNA 序列分别用后面对应的数字序列表示,可以推断,步操作之后我们能够得到n阶完全序列(图1)。同时,由于每个核苷酸片断长度不等,外源DNA 长度也不尽相同,则插入的外源DNA相应地转化为一个带有权值的有权路径问题。不同的剪切和粘贴之后,质粒DNA的总长度必然地发生变化。根据这一结果,可以运用质粒DNA计算解决许多实际问题。
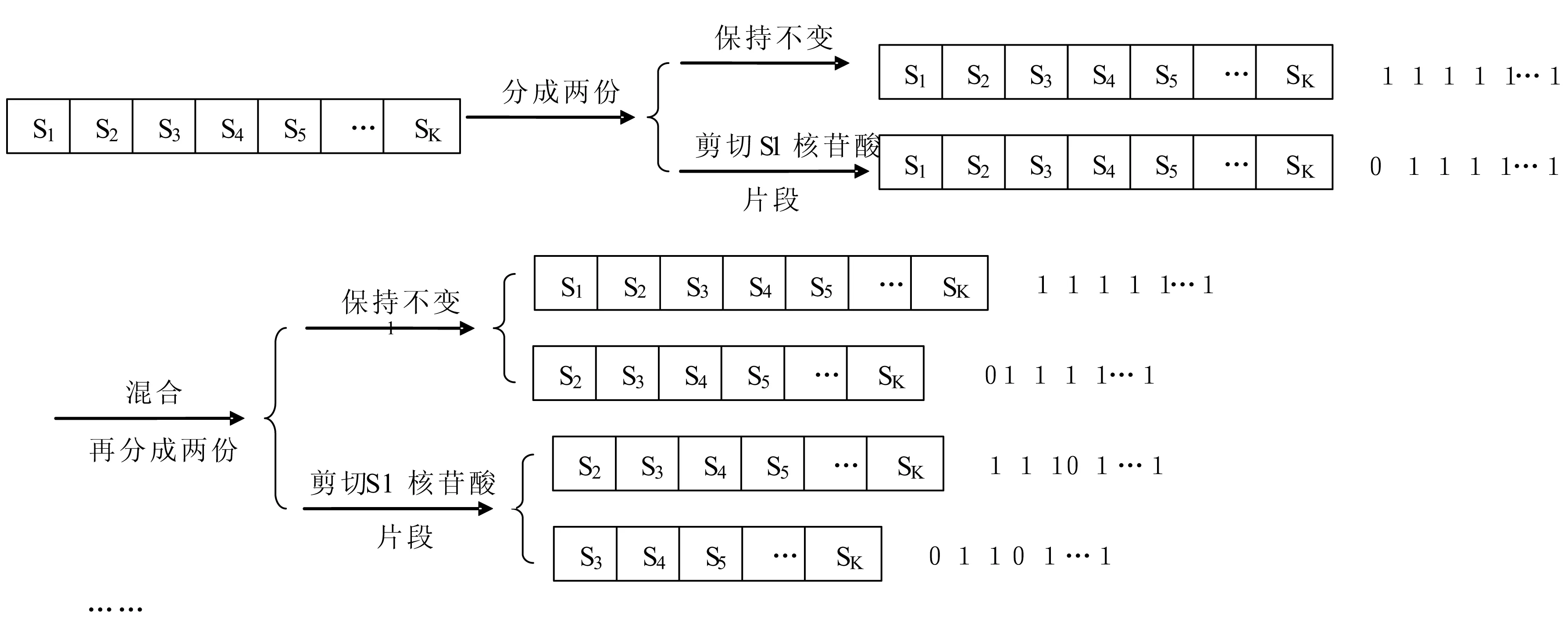
图1 质粒DNA的剪切计算模型
要么在质粒上要么不在质粒上,我们用1表示在质粒上,而用0表示不在质粒上。在某种程度上,它相当于电子计算机的k比特的存储器(图2)。本文正是利用质粒所具有的特征提出图的最大权团的DNA算法,其基本的生物操作包括连接(Ligating)、放大(Amplifying/ Copying) 、 酶切(cutting)、分离(Separation)、提取(Extracting)、检测(Dectecting)。
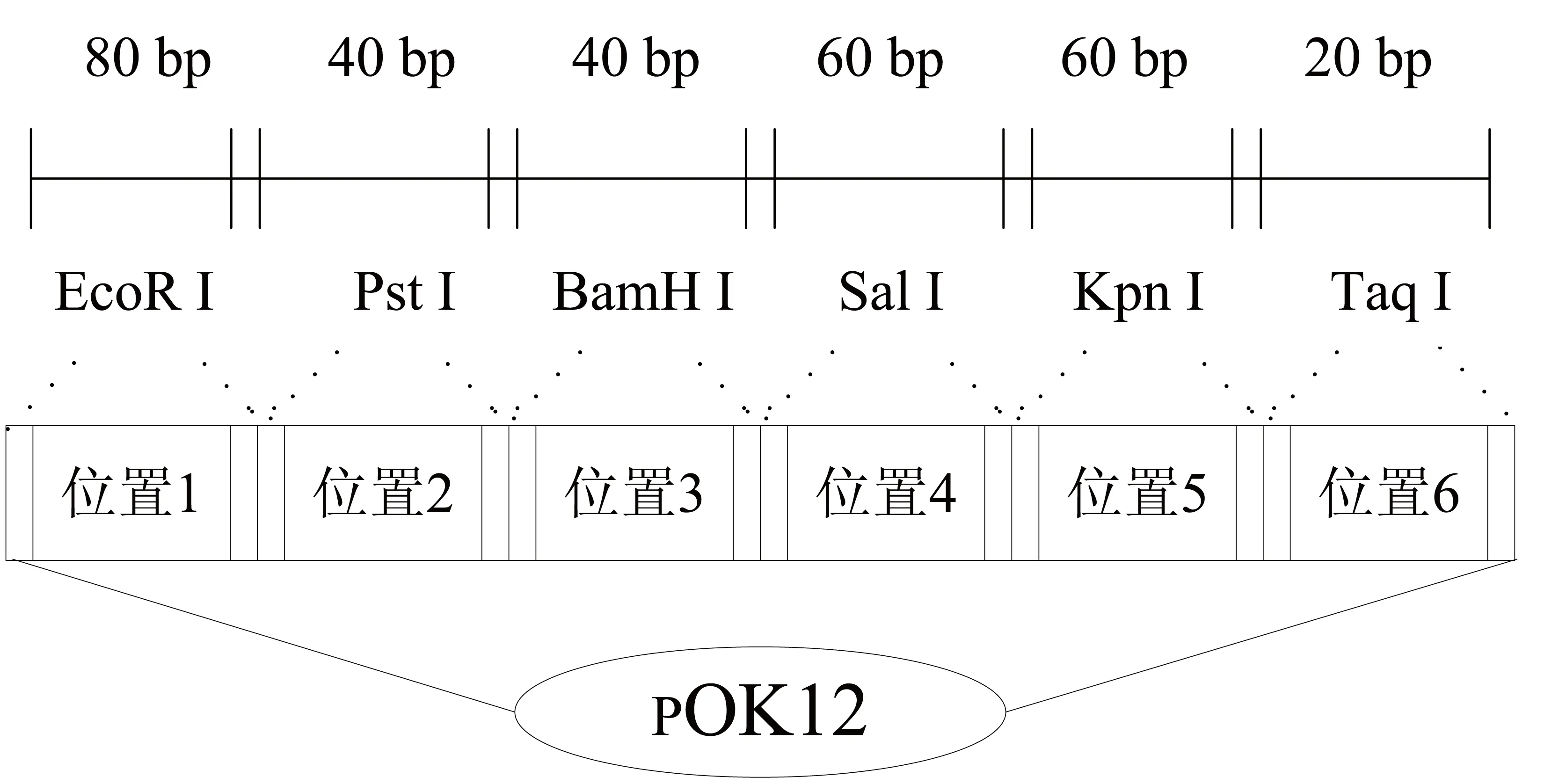
图2 质粒结构图
3 背包问题的DNA计算机算法
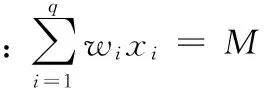
Horowitz和Sahni在1974年提出了著名的二表算法[6],该算法是至今为止被认为最有效的求解最大团问题等背包类NP完全问题的算法之一。受二表算法设计原理启示,将分治策略引入到DNA 分子算法设计中。
本算法的核心为:利用分治策略,将背包分量集W={w1,w2,…wn}平均分成两部分W1和W2,分别求出两部分的全部各O(1.414n)个子集和,使用减法操作对背包容量M与其中一个子集W1的所有子集和做减法运算,即将二表算法中二表求和后与数M的比较以判断是否有解转换成先求M与一个子集所有子集和的差,然后将之与另一部分的子集和作比较以判断问题是否有解,这种方法不仅可克服排序和解搜索的DNA操作只能串行的局限性,而且还将降低DNA操作的难度。另外,由于本算法仅需保存1.414n个的DNA链,而非穷举法中数目为2n的所有子集和组合,因此,,算法中的DNA分子链数在不明显提高DNA操作时间或次数的条件下由文献[5]中的2n减少至2×1.414n。
DNA 计算在解决问题时主要可分为三个阶段: (1) 对问题进行适当的编码,也就是将要求解的问题映射到DNA 链上;(2) 生物实验,依照算法模型的步骤完成各种实验操作,生成问题的解;(3) 解的提取。为了求解背包问题,首先假设所有的背包分量wi和M的最大公约数为m,则wi=mli。M=mpj,本算法用DNA分子操作的基本实现过程根据其处理特性描述如下:
算法:背包问题的DNA计算机算法(the algorithm frame of DNA computer for knapsack problem)
首先将集合W= (w1,w2, ….,wn)按升序排列,并将其分成两个元素个数相等的子集W1和W2。W1取按升序排列好后的W中的前n/2个元素,而W2取按升序排列好后的W的后n/2个元素。用W1,i表示W1的第i个元素,W2,i表示W2的第i个元素。
Step 1 输入,在实验杯T0中,分别对每个W1,i、W2,i-W1,i及M分量的值进行编码。
对每个W1,i、W2,i-W1,i及M分量的值编码:将所有W1,1,W1,2, …,W1,n/2及所有M分量1 , 2 , …依次编码在一条DNA双链上,W1的背包分量i都用20libp的核苷酸片段编码,并且仍用i表示该片段;每个背包分量的两端都有相同的特殊酶切位点的限制性内切酶。不同的相邻背包分量之间都有两种不同的内切酶,这两种酶之间也可夹一些寡聚核苷酸片段;W2,i-W1,i用20libp的核苷酸片段编码,并且仍用i表示该片段;M分量编码在背包分量之后,用20pjbp的核苷酸片段编码,并且用j表示该片段;编码方式同W1,i。
Step 2 把T0产生的DNA片段插入到开口的质粒中,在形成闭环状质粒后放入到大肠杆菌中扩增该质粒。
Step 3 分别对背包分量集W1和W2把初始化。
将T0中的质粒分成两个等量的杯子T1和T2。
在杯子T1中分别加入切割W2,i-W1,i的内切酶,再把切割下来的小片段和质粒分离出来,并使质粒重新环化后合成一个杯子。此时,质粒上的DNA片断后n/2段被切割,则质粒上的DNA片断前n/2段,分别表示背包分量集W1的n/2个分量值。
在杯子T2中每个W1,i和W2,i-W1,i长度之和唯一表示背包分量集W2中第i个背包分量值。
Step 4 生成W1中所有子集,并计算M与背包分量集W1中所有子集和的差。
将T1中的质粒分成两个等量的杯子T3和T4。
在杯子T3中加入切割W1,i的内切酶,再把切割下来的小片段和质粒分离出来,并使质粒重新环化后合成一个杯子。之后放入入大肠杆菌扩增该质粒。将扩增后的T3分成相同容量的两个杯子T5和T6。
在杯子T4中放入切割W1,i的内切酶,再把切割下来的小片段和质粒分离,并使质粒重新环化合成一个杯子。然后,逐步加入切割与W1,i等值的M分量的内切酶,并使质粒重新环化后合成一个杯子。转入大肠杆菌扩增这样的质粒。将扩增后的T4分成两个等量的杯子T7和T8。
此时,将T5和T7合并到T3中,T6和T8合并到T4中。当所有n/2个背包分量都完成上述操作后,再将T3和T4合并到T1中。
Step 5 生成W2中所有子集,并计算背包分量集W2中所有子集之和。
在T2中分别加入切割所有M分量的内切酶,再把切割下来的小片段和质粒分离出来,并使质粒重新环化后再合成一个杯子;
Step 6 用凝胶电泳技术找出链长相等的质粒;
Step 7 确定链长相等的质粒所含的背包分量的并集即是背包问题的解;
Step 8 输出结果。
4 小结
DNA计算机是解决背包问题等NP完全问题的方法之一,但目前DNA计算机算法多基于穷举法,这种方法使得DNA计算机具有纯指数量级的DNA链数而受到极大的限制。进化算法等现代算法是解决该问题的有效方法之一,但该方法尚难以高概率找出对于变量数较多的NP完全问题的解。本文提出一种求解背包问题的DNA计算机算法,将DNA分子计算中使用分治策略,应用质粒模型,可以令DNA分子链数从文献[2]的O(2n)减少到亚指数O(1.414n),从而求解背包问题DNA分子计算的维数从60扩大到120。
[1]BRAICH R S, CHELYAPOV N, JOHNSON C, et al. Solution of a 20-variable 3-SAT problem on a DNA computer[J]. Science, 2002, 296(19):499-502.
[2]FU B. Volume bounded molecular computation[D]. New Haven: Department of Computer Science, Yale University, 1997, 55-68.
[3]LAIH C S, LEE J Y, HARN L, et al. Linearly shift knapsack public-key cryptosystem[J]. IEEE Journal on Selected Areas Communications, 1989, 7(4): 534-539.
[4]LIPTON R J. DNA solution of hard computational problems[J]. Science, 1995, 268(28): 542-545.
[5]LI K L, LI R F, LI Q H. Optimal parallel algorithm for the knapsack problem without memory conflicts[J]. Journal of Computer Science and Technology, 2004, 19(6): 760-768
[6]HOROWITZ E, SAHNI S. Computing partitions with applications to the knapsack problem[J]. Journal of ACM, 1974, 21(2): 277-292.
(责任编校:光明)
KnapsackProblemaboutDNAComputerSolvingBasedonPlasmidModel
WANGJian-bo
(Department of Computer Science, Hunan Institute of Humanities,Science and Techonology, Loudi,417001,China)
It’s an urgent question to solve that DNA chain presents pure index increasing while DNA computer solves large scale scientific problems. On the application of divide-and-conquer strategy into DNA numerator algorithm of knapsack problem, the paper introduces a new DNA computerized algorithm based on Plasmids model to solve knapsack problem. The algorithm DNA linkage numbers can reach subexponential O(1.414n) , whilenisdimensionality of knapsack problem.Through comparative analysis between new DNA computeri algorithm and document conclusion, the Algorithm decreases DNA linkage numbers in exhaust algorithm from O(2n) to O(1.414n). Hence, this algorithm proves to be a certain superiority on the tube's level increasing dimensionality of penetrable knapsack public key from 60 to 120.
DNA computer; plasmids model; knapsack problem
2010-07-15.
湖南人文科技学院青年基金项目(2008QN018).
王剑波(1978——),男,湖南新邵人,湖南人文科技学院讲师,硕士,研究方向:并行计算、电子商务。
TP301.6
A
1673-0712(2010)04-0077-03
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
小学生学习指导(低年级)(2020年10期)2020-11-09
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
农民文摘(2019年11期)2019-11-15
阅读与作文(小学高年级版)(2019年4期)2019-04-20
小猕猴智力画刊(2019年3期)2019-04-19
摄影之友(影像视觉)(2017年10期)2017-11-07
作文周刊·小学一年级版(2016年42期)2017-06-06
童话世界(2017年11期)2017-05-17
