
决策树技术在高职学生就业信息库中的应用
2015-05-12 05:06林沣
广西教育·C版 2015年3期
林沣


【摘 要】以现有的数据挖掘决策树算法作为理论支撑,从就业数据出发,按照数据挖掘的基本步骤和方法,执行C4.5决策树算法对数据进行分类和预测,从积累的大量数据中得到以就业类别为属性的分类规则,以此为学校领导机构提供决策支持,提高就业水平,对就业指导工作具有一定的现实意义。
【关键词】C4.5 数据挖掘 决策树 就业信息库
【中图分类号】 G 【文献标识码】 A
【文章编号】0450-9889(2015)03C-0181-03
随着高校的大规模扩招,学生人数逐年递增,毕业生的大量输出给社会带来巨大的压力,学生就业管理工作趋向于复杂化,如何能够有效地提高毕业生就业率在高校中已经成为一个急待解决的问题。然而我们通常做的都只是表面的去统计毕业生的就业数据,不进行深层次的数据分析,得到的往往也只是表面信息。合理利用现代化的信息手段整理过往毕业生的就业数据,从中寻找影响用人单位录用毕业生的关键要素才是解决问题的关键所在。
有效利用数据挖掘技术对大学毕业生就业信息进行分析,将信息中内在的联系挖掘出来,这是传统的、表层的评价方法无法做到的。本文将选取决策树C4.5算法构建就业决策分类树抽取规则知识,原因是就业数据具有分类的预知性、离散性的特点。
一、决策树算法
决策树方法的原始启蒙来源于概念学习系统,属于数据挖掘核心技术算法之一,有一定的优势。它的特点是基于实例数据,将大量数据有目的地分类,把一个复杂的问题分成更简单的问题并重复使用这一技巧,找出潜在的、对决策有利用价值的信息,决策树算法多数情况下应用在预测模型中。如果引用信息论中的说法,就是在选择决策节点属性时,用信息增益来进行判定。
所谓决策树,实际上是一种形象的叫法,它是由决策节点、分支、叶子和连接线组成,其形状类似倒长的树型结构。决策树的节点一般用矩形表示,代表一个非类别属性,每个叶子用椭圆形表示,代表一个类别。矩形和椭圆形的连接线代表一条分支,每条分支代表着这个属性可能出现的值。每一条从根节点到叶子节点的路径则代表着一条分类规则。
目前众多决策树算法中最为著名的是Quinlan在ID3算法的基础上进行改进提出来的C4.5算法。C4.5算法的先进性体现在:C4.5算法比ID3算法先进的方面在于选择属性时采用的是信息增益率去替代信息增益,使得在属性选择时不会对取值多的属性带有更强的偏向性,所得出的计算结果更准确;分析连续型属性是C4.5算法又一改进,并且当在样本集中出现空缺的属性值时,C4.5算法也能进行处理,从而提高结果的准确性;C4.5算法能够直接将连续值属性进行分割,分别计算信息增益率,并选取结果当中信息增益率最大的分割为属性标准,从而转换为离散的二值属性,完成对连续型属性的离散化处理;C4.5算法在构造树的过程中采用后修剪枝叶的方法,能有效的控制决策树的高度,同时,相对其他的算法而言C4.5生成的决策树分枝也有所减少。
为了能使用最小的信息构造最为简单的决策树,在对训练样本子集进行分类时,在选取当前节点的测试属性时,就必须把具有最高信息增益的属性找出来。具体方法如下:
假设有训练样本数据集S,类别属性C可以取k个不同的值,将训练样本数据集S分为k个不同的类Ci (i=1,2,……,k),Ri为数据集S中属于Ci类的子集,用ri表示子集Ri中的样本数量。
用Pi表示任意样本属于类别Ci的概率:,|S|表示集合S中的样本数量。样本集合S的平均不确定性和纯度的高低是通过信息熵反映的。如果熵值越小,平均不确定性越低,纯度越高。
每个属性的信息增益率都可以由上述的公式计算出来,这样集合S的决策树的根节点就可以根据计算出来的信息增益率最高的属性来确定,并以该属性作为标记属性,对属性的每一个值创建分枝,并据此划分样本。
二、数据预处理
(一)数据准备
在本研究中,选择毕业生的就业信息作为研究数据,通过分析毕业生在校的学习情况、专业及专业类别等信息,挖掘出用人单位的行业性质。在进行构造决策树时,必须对数据进行规格化处理,能保证数据的高质量和一致性。同时还要对用人单位行业性质的文字描述进行量化和对学习情况等决策属性进行离散化。
(二)数据的转换
在所采集的数据中选取4项作为实验样本。选取学习成绩、外语水平、实践能力、就业方向构成四维向量表。数据选择如下:学习成绩(CJ)采集学习成绩的平均值分段划分为三级,中等(CJ<75),良好(75≤CJ≤85),优秀(CJ≥85)。外语水平(WY)划分为两级,通过全国英语等级B级,通过全国英语等级四级。实践能力(SJNL)划分为三级,优秀(实践能力强),一般(实践能力一般),差(实践能力差)。就业方向(JYFX)划分四级,国有企业事业单位(V),外资企业(X),私营企业(Y),自主创业(Z)。
三、构造决策树
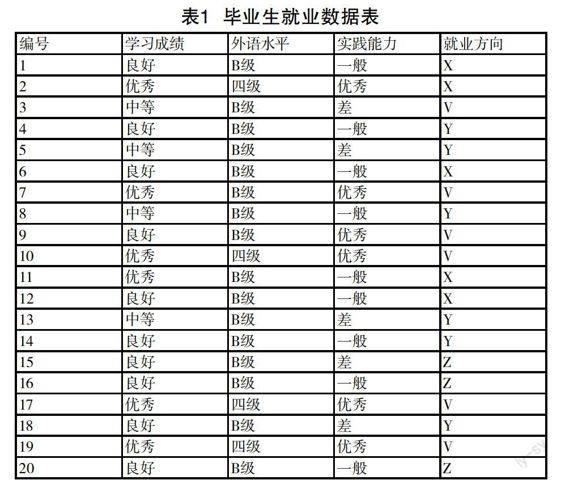
选取决策样本数据集,如表1所示:
第一步,将样本训练集中的分类标志属性选出来,本例中选择“就业方向”作为分类标志属性,而“学习成绩”“外语水平”“实践能力”则作为决策树的决策属性集。将毕业生就业数据表中“就业方向”分为4类:C1、C2、C3、C4分别代表国有企业事业单位:V;外资企业:X;私营企业:Y;自主创业:Z。毕业生就业数据表中的20条记录构建决策树的样本集S的20个元组,其中C1、C2、C3、C4类分别对应的子集的元组个数分别为r1=5,r2=5,r3=7,r4=3。要得出每一个决策属性的信息增益率,那么就要计算S的分类期望信息量:
从信息增益率值可以看出值最大的是“实践能力”属性,所以将该属性定为根节点构建决策树。
其余的分支点,我们可以通过重复上述的步骤得出,并生成最终的决策树,如图1所示。
根据决策树可以直接提取分类规则:
IF实践能力=优秀+英语水平=四级+学习成绩=优秀THEN就业类别=X/V。
IF实践能力=优秀+英语水平=B级+学习成绩=优秀或良好THEN就业类别=V。
IF实践能力=一般+学习成绩=良好+英语水平=B级THEN就业类别=X/Y/Z。
IF实践能力=一般+学习成绩=中等+英语水平=B级THEN就业类别=Y。
IF实践能力=一般+学习成绩=优秀+英语水平=B级THEN就业类别=X。
IF实践能力=差+英语水平=B级+学习成绩=中等THEN就业类别=V/Y。
IF实践能力=差+英语水平=B级+学习成绩=良好THEN就业类别=Y/Z。
从上述分类规则中我们可以发现,不同的能力和水平对于提高学生就业层次具有非常微妙的影响,如果全面加强学生成绩的培养,则提高毕业生进入国企就业的数量;如果重视加强实践能力和外语水平的双方面培养,则能提高进入外企就业的毕业生数量。当然我们还可以扩大训练样本集,添加更多的数据,这样所构建的决策树能反映数据之间更多的内在联系。
在当前复杂的就业形势下,文章提出了对就业数据进行挖掘,并建立数据挖掘模型,利用C4.5决策树算法,分析毕业生就业信息系统中的数据。并在通过算法建立的决策树模型中,最终得到以就业类别为属性的分类规则,进一步分析这些分类规则,能为学校的就业提供分析和决策。如能进一步完善基于就业分析模型决策树的分类器,将决策树技术引入高校学生就业信息中,寻求影响学生就业的主要因素,最终必将推动高校教育管理的改革与发展。
【参考文献】
[1] 张骏,王琴.C4.5算法在研究生就业信息库中的应用研究[J].信息技术,2009(11)
[2] 雷松泽,郝燕.基于决策树的就业数据挖掘[J].西安工业学院学报,2005(10)
[3] 邱瑾.决策树在高职学生就业数据分析中的应用研究 [J].柳州职业技术学院学报,2012(4)
[4] 利珊.数据挖掘在就业分析中的应用[J].兰州工业高等专科学校学报,2011(8)
[5] 张继美,桂红兵.R-C4.5决策树模型在高职就业分析中的应用[J].电脑知识与技术,2011(7)
[6] 何文秀.数据挖掘技术在高校就业工作中的应用研究[J].现代计算机,2008(3)
[7] 常志玲,王岚.一种新的决策树模型在就业分析中的应用[J].计算机工程与科学,2011(5)
【作者简介】林 沣(1982- ),男,广西南宁人,广西机电职业技术学院讲师,工程师,研究方向:数据库,数据挖掘。
(责编 丁 梦)
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
小朋友·聪明学堂(2019年2期)2019-03-13
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
新校长(2016年8期)2016-01-10
人间(2015年21期)2015-03-11
郑州大学学报(医学版)(2015年1期)2015-02-27
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
