
基于改进K-means聚类算法的战区内军事物流基地数量规划
2016-12-10 07:36张广楠杨祺煊
物流技术 2016年10期
张广楠,荀 烨,杨祺煊
(军事交通学院,天津 300161)
基于改进K-means聚类算法的战区内军事物流基地数量规划
张广楠,荀 烨,杨祺煊
(军事交通学院,天津 300161)
以战区军事物流基地数量规划问题为研究对象,考虑战区内军事物流基地同后方仓库的业务关系,利用改进K-means聚类算法,对战区内后方仓库进行空间聚类,并对聚类结果进行分析,以聚类结果中的聚类个数作为战区内军事物流基地数量规划的依据。研究表明,该方法比较科学合理,具有应用价值。
K-means聚类算法;军事物流基地;数量规划
1 引言
目前,我军后勤保障体制包含联保基地、联保中心、联合投送基地、军事物流基地等多种后勤保障力量,但总体上来说,传统的后方仓库仍是我军后勤保障体制的基础。尽管传统后方仓库在规划、建设等方面已不能满足我军对后勤保障的新要求,在新成立的各大战区中,原有的后方仓库仍以绝对的数量和广泛的分布发挥着保障作用。在战区内规划建设军事物流基地可以对传统后方仓库的保障能力产生聚合作用,将原本孤立的后方仓库联系起来,构成战区内联动后勤保障网络。
2 战区内军事物流基地数量规划问题分析
数量规划是战区内军事物流基地建设的基础,不仅要立足于战区后勤保障的实际情况,还要充分考虑军事物流基地建设模式的选择。目前,有关军事物流基地的研究主要将其建设模式分为三种:基于后方仓库群的建设模式;基于军用物资采购站的建设模式;基于军种保障基地的建设模式[1]。其中,以后方仓库群为基础,整合选取现有后方仓库规划军事物流基地的建设模式是战区内军事物流基地建设的主要模式。为了体现战区内军事物流基地规划问题的系统性和整体性,对其数量规划应从战区保障网络中各节点间业务流程入手。
2.1 战区保障网络业务流程
战区内保障体系主要由各类传统后方仓库构成,这些仓库大多基础设施落后,业务功能单一,在实施保障任务时彼此之间缺少协调联系。规划建设军事物流基地后,基地联动仓库形成覆盖全战区的保障网络,其业务流程如图1所示。
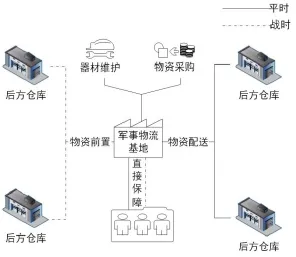
图1 战区保障网络业务流程示意
该保障网络中军事物流基地同后方仓库之间的业务关系可分为平时和战时两种状态。平时,基地担负着一定数量战储物资和周转物资的存储;通过采购功能将采购的战储物资和周转物资组套包装,分送到保障区域内的各后方仓库;将日常生活、训练所需的保障物资直接配送到保障区域内的需求点;满足保障区域内发生的综合技术保障需求。战时,根据作战需要将后方仓库中的物资前置到基地中,通过基地直接送达需求点。
2.2 战区后方仓库分布特点
战区内军事物流基地作为保障网络中的关键节点,坐落在仓库群中,其数量规划必须考虑到战区内后方仓库的分布特点。目前,我军后方仓库大致按之前军区的部队部署进行布局,但是在漫长的建设过程中,我军后方仓库集中部署的方向也随着军队战斗战略方向的改变而改变。总结其布局特点有:按原有七大军区地域划分布局;向各时期的战略方向集中布局;绕中心城市和交通枢纽布局。结合战区内后方仓库的布局特点,对其进行聚类,将聚类结果中类的个数作为战区内军事物流基地数量规划的依据,并为之后的选址工作打下基础。
3 带约束的K-means聚类分析
聚类通常是指根据数据的相似性将数据集合划分成不同的组别,并对其标号,其中最具代表性的算法就是K-means聚类分析。虽然K-means聚类算法被提出已经超过50年,但目前仍然是应用最广泛的划分聚类算法之一[2]。
3.1 K-means聚类算法目标函数
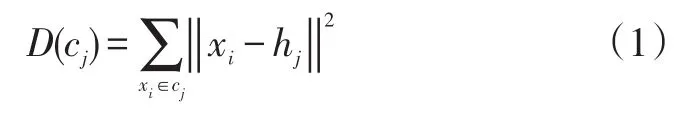
当各类总的距离平方和D(c)达到最小时,聚类结束:
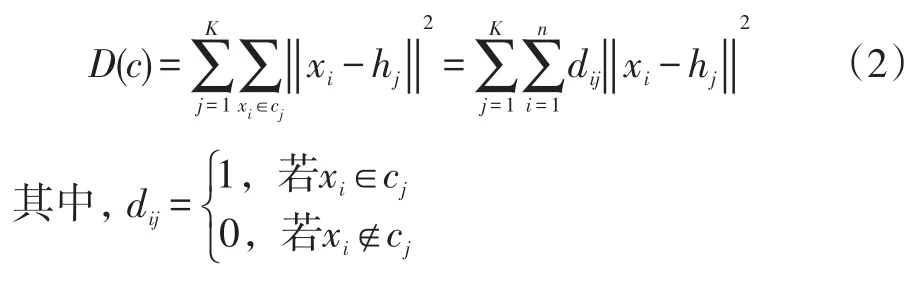
K-means聚类算法距离平方和与参数K的取值有着直接关系,当K增加时D(c)不断减小。
3.2 K-means聚类算法流程
K-means聚类算法是以取得D(c)最小为目标反复迭代的过程,其主要流程如图2所示。
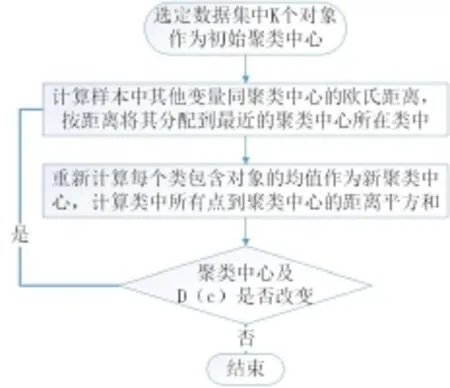
图2 K-means聚类算法流程
3.3 K-means聚类算法改进
目前,大多数学者认为,对于一般数据维数m和类别个数K,K-means聚类算法是一个NP难优化问题[3]。从算法的前提条件来看,参数K以及初始聚类中心的选择将影响到最终的聚类结果。文章将K-means聚类算法应用到战区内军事物流基地的数量规划问题中,通过
不断增加K值,分析D(c)随K的变化曲线来确定K取值,通过多次重启K-means聚类的方法解决初始聚类中心的选择问题。改进后的K-means聚类算法流程如图3所示。

图3 改进后K-means聚类算法流程
4 算例分析
假定某战区内军事物流基地需进行数量规划,现使用改进后的K-means聚类算法对该问题进行解决。采集战区内后方仓库的位置信息,通过一系列处理将真实位置转化为虚拟坐标,见表1。
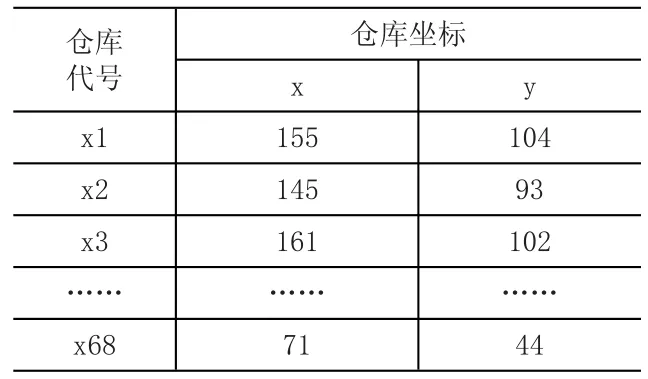
表1 部分后方仓库位置虚拟坐标
使用Matlab软件对战区内68个仓库虚拟坐标进行改进K-means聚类,得到D-K关系曲线如图4所示。
通过分析各类数据点到各聚类中心总的距离平方和D(c)随K的变化情况可以了解到,当参数K≥5时,D(c)的变化趋于缓和,最终聚类结果的K值不宜过大,因为K值代表着对军事物流基地数量的规划结果,其值过大会造成建设成本过高,军事物流基地效能下降。这里我们将K的取值设定为5,继续进行多次重启K-means聚类,我们将重启次数设定为10,图5显示的是最优聚类结果。
对该战区后方仓库进行聚类,合理K值为5,即在战区内规划5座军事物流基地。从聚类结果中可以看出,采用改进后的K-means聚类算法对战区内后方仓库虚拟坐标进行聚类并没有产生明显的噪声,输出结果比较理想。一方面是因为战区内后方仓库的分布具有一定的规律性,另一方面是因为改进后的K-means聚类算法在K值选取以及初始聚类中心的设定上更加科学合理,更加具有应用价值。

图4 D-K关系曲线
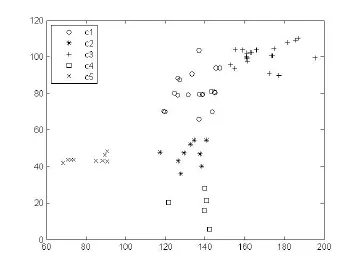
图5 最优聚类结果
5 结语
本文以战区内军事物流基地数量规划问题为研究对象,通过改进K-means聚类算法对该问题进行解决。在保障需求难以科学估算的背景下,本文从战区保障网络中军事物流基地同后方仓库的业务关系着手,军事物流基地是以后方仓库群为基础进行建设,所以对战区内后方仓库进行聚类,其结果中的聚类个数可作为军事物流基地数量的规划。后方仓库聚类结果不仅解答了军事物流基地建设数量的问题,还为之后军事物流基地在后方仓库中的选址问题提供了解决思路。在后续的研究中可以将后方仓库的聚类结果结合保障需求、保障时效等要素对军事物流基地的建设规划做进一步的研究。
[1]张志鹏,张亦兵.军事物流基地建设模式的选择[J].军事经济研究,2011,32(8):41-43.
[2]Anil K J.Data clustering:50 years beyond K-Means[J].Pattern Recognition Letters,2010,31(8):651-666.
[3]Aloise D,Deshpande A,Hansen P,et al.NP-hardness of Euclidean sum-of-squares clustering[J].Machine Learning,2009, 75(2):245-248.
Quantity Planning of Military Logistics Bases in War Zone Based on Improved K-means Cluster Algorithm
Zhang Guangnan,Xun Ye,Yang Qixuan
(Military Transportation Academy,Tianjin 300161,China)
In this paper,with the quantity of the military logistics bases in war zone as the objective and considering the business relationship between the bases with rear depots,we used the improved K-means clustering algorithm to have the spatial clustering of the rear depots in the war zone,analyzed the clustering result and proposed to make the number of the cluster in the clustering result as the basis for the planning of the quantity of the military logistics bases in the war zone.
K-means clustering algorithm;military logistics base;quantity planning
E234;F224
A
1005-152X(2016)10-0159-03
10.3969/j.issn.1005-152X.2016.10.037
2016-09-12
张广楠(1991-),男,黑龙江绥化人,军事交通学院研究生,研究方向:军事物流系统分析与优化。
猜你喜欢
小天使·一年级语数英综合(2020年11期)2020-12-16
学生天地(2020年34期)2020-06-09
生物骨科材料与临床研究(2019年4期)2019-09-09
军事运筹与系统工程(2018年3期)2018-03-26
军营文化天地(2017年10期)2017-12-05
小学阅读指南·低年级版(2017年4期)2017-04-24
小天使·四年级语数英综合(2015年3期)2015-04-20
军事文摘(2009年9期)2009-07-30
全国新书目(2009年24期)2009-07-17
军事文摘(2009年5期)2009-06-30
