
基于GAN的不平衡负荷数据类型辨识方法
2021-07-01 07:13卢锦玲张梦雪郭鲁豫
电力科学与工程 2021年6期
卢锦玲,张梦雪,郭鲁豫
(华北电力大学 电气与电子工程学院,河北 保定071003)
0 引言
随着智能电网的发展,越来越多的传感器和智能电表安装到配电网络中,用来监控和预测电能的使用。从负荷监控点收集的随时间变化的功率损耗数据形成负荷曲线。客户的负荷曲线显示了其电力消费行为,通过对负荷曲线分类,提取用电模型,对于电力系统的负荷预测、风险预警、需求响应分析等具有重要意义。
负荷分类问题的研究在国内外已经取得了一定成果。总体来说,负荷分类方法包括以K-means、模糊 C 均值聚类(fuzzy C-means,FCM)、自组织映射(self-organizing maps,SOM)等为代表的无监督聚类和以BP神经网络、支持向量机(support vector machine,SVM)等为代表的有监督分类。文献[2]结合多种聚类算法构建用户的用电模式分析模型,并提出一种新方法来评估聚类效果,实现了典型用电模式的自动识别。文献[3]结合深度学习中的卷积自编码器,提出了一种多维模糊C均值聚类方法,对日趋海量的负荷数据进行了有效的分类。文献[4]基于牵引负荷实测数据,提出了一种改进的自适应 FCM方法,以自动获取最佳聚类数,提高了牵引负荷分类的精度。文献[5]提出了一种基于遗传算法优化的BP神经网络负荷分类方法,采用遗传算法对BP网络的初始权重和阈值进行优化,得到了较好的分类效果。文献[6,7]采用高斯混合模型聚类和SVM算法相结合,提出了一种利用负荷数据进行用户辨识的方法,并验证了算法的有效性。文献[8]首先通过无监督算法获得负荷数据的标签,然后采用稀疏自动编码神经网络学习负荷曲线的特征,实现了负荷曲线的高精度分类。然而,上述研究都是在假设负荷类别相差不大的前提下展开的,均没有考虑负荷类别不均衡这一问题。
不平衡分类属于分类问题的一种,即不同类别的样本数目存在较大的差距。近年来,类别不平衡问题在机器学习分类任务中日益凸显,如欺诈识别、垃圾邮件检测等。欺诈交易与垃圾邮件样本较少,属于小样本类别,其分类是否正确对结果影响巨大。负荷曲线的随机性较强且模式多样,但是各个模式下的负荷样本数量不均衡,传统的分类模型往往对于不平衡的负荷数据分类具有较大的偏向性,即产生小类样本负荷数据错分或被大类负荷数据吞噬等现象,进而导致分类效果欠佳[9]。针对不平衡分类问题,传统方法一般对数据进行过采样或欠采样处理,其中随机过采样和随机欠采样只是简单的随机复制小类样本或丢失大类样本,因而对于分类效果的提高往往不理想。为此本文提出一种基于生成式对抗网络(GAN)的小类负荷样本的过采样方法,首先基于K-Means算法为负荷数据加上标签,然后采用GAN对小类负荷数据进行样本扩充,最后使用SVM算法进行分类建模。
1 K-means聚类
采用神经网络对负荷数据分类时,需要对训练数据进行学习以获得良好的分类性能,本文采用K-means聚类为局部数据添加类别标签,并通过基于聚类结果 GAN方法扩大训练数据中的小样本类簇数据规模。
聚类是无监督学习算法的一种。聚类分析是在缺乏足够的先验知识,难以人工标注类别的情况下,通过样本的某些特征,以相似性为基础,利用某种度量准则,可以对未知类别的数据进行自动模式识别的一种分析方法。K-means算法以其简单、运算速度快、时空复杂度低等优点,在聚类分析领域得到了广泛的应用[10]。其基本思想是最小化所有样本到聚类中心的距离平方和。最小化损失函数为:
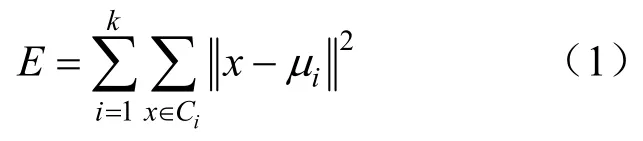
式中:Ci为第i个簇;μi为簇Ci的中心。
具体步骤如下:
步骤1:随机选取k个样本点作为各个簇的中心点{μ1,μ2,・・・,μk}。
步骤2:计算所有样本点与各个簇中心之间的欧式距离,对每个样本点进行分类,并将其划分到距离最近的一个簇中[11]。

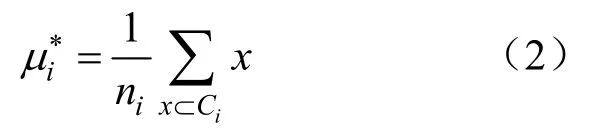
式中:i=1,2,・・・,k;ni表示簇 Ci中所包含样本点数;x表示簇Ci中的样本点。
步骤4:重复步骤2、3,直到簇中心在迭代过程中变化不大时停止,即得到最佳聚类结果。
2 GAN原理
GAN是Goodfellow在2014年提出的一种生成式模型,其思想源于零和博弈,由生成器和判别器构成,生成模型可以看作一个样本生成器,它负责学习数据样本的分布规律,通过输入随机噪声,产生新的样本数据,判别模型类似于一个二分类器,它负责判断输入数据是否为真实数据,并使准确率最大化。二者通过对抗训练不断提升各自网络的性能,最终到达二者之间的纳什均衡点。


图1 生成式对抗网络结构图Fig.1 Structure chart of generative adversarial network
对于生成器网络,从分布 Pz中采样的噪声数据z作为网络输入[13],然后生成器的输出G(z)是一个新的随机变量,其分布用PG表示,生成器优化目标生成可信样本来欺骗判别器,为了完成这项任务,需要定义损失函数LG来更新生成网络的参数θ(G)。LG最小化表示分布为PG的生成样本从判别器的角度来看几乎与真实样本相同。
对于判别器网络,其输入样本来自生成器或真实样本,输出一个连续值以测量输入样本,判别器网络和生成器网络交替进行训练[14],对于不同的输入样本,判别器的输出值如式(3)和式(4)所示:

判别器网络通过训练来区分Pr和PG,也就是最大化 E[D(・)]和 E[D(G(・))]之间的差异,类似的,需要定义一个损失函数LD来更新判别器的网络参数,当判别器区分生成样本和真实样本的能力很强时,LD的值应该很小。损失函数LG和LD定义如下:

式中:E表示计算期望;G(z)表示生成器生成的数据;D(~)为判别器网络的输出。
对于给定的判别器,最大化LD意味着最小化-E[D(G(・))],从而可得式(5)。对于给定的生成器网络,判别器网络应最大化 E[D(・)]同时最小化 E[D(G(・))],从而得式(6)。基于此,GAN式的训练过程其实是一个极大极小博弈问题,通过不断对生成器和判别器进行迭代优化,使二者达到纳什均衡[15],其博弈过程的目标函数为:

针对负荷曲线样本扩充问题,使用传统的过采样方法难以充分挖掘曲线的各种特征并建立模型,扩充的数据缺乏真实性和多样性。而采用GAN模型能够充分学习真实负荷数据的分布特征,并能同时保证生成数据的多样性。
卷积神经网络以其强大的特征提取能力在图像识别、分类等领域发挥着巨大潜力。本文采用卷积神经网络代替传统的多层感知器来构建生成器和判别器网络模型,以提高GAN的学习能力。生成器网络输入为100维噪声向量,由于负荷数据为一维时间序列,通过全连接层和1D上采样使维度碰撞,并采用1D卷积层对时间序列进行特征提取并对维度进行缩减,卷积核大小和数量根据实验进行选取,步长均取 1,填充方式取 valid,同时为了加快网络训练速度,提高网络的鲁棒性,每个卷积层后面均添加批量归一化(batch normalization,BN)层[16]。考虑到 BN 层会是输出规范化到 N(0,1)的正态分布,输出层后不添加BN层。为减少稀疏梯度的可能,输入层和隐藏层激活函数采用LeakyReLU,鉴于负荷数据均为大于0的数,输出层使用ReLU作为激活函数,将结果规范化到(0,1)之间。各层网络经过设计,输出为24维向量。
判别器的主要任务是对生成样本和真实样本进行特征提取并划分类别,因此判别器网络同样采用1D卷积层,生成器网络的网络结构和参数如表1所示,判别器网络的结构及参数如表2所示。

表1 生成器结构及参数Tab.1 Structure and parameters of generator

表2 判别器结构及参数Tab.2 Structure and parameters of discriminator
3 支持向量机分类模型
Vapnik首先提出使用支持向量机(support vector machine,SVM)进行模式识别和分类[17]。基于统计学原理,SVM以一个或一组高维超平面的形式实现其功能,相比于神经网络等传统机器学习方法,具有更小的泛化误差。
SVM的基本目标是寻找一个超平面来分离n维空间中不同类的数据点。超平面与训练数据点之间的距离称为函数间隔,函数间隔用来表示分类结果的可信度。作为最大间隔分类器,SVM得到的超平面与最近训练数据点的函数间隔最大,具有最优的分类效果。
如图2所示,以线性可分的二分类问题为例,假定T={(xi,yi)}为训练集,其中xi为n维特征向量,yi为类别标签,其取值+1或-1,表示不同的类别。寻找其最优分类超平面可转化为式(8)优化问题的最优解。
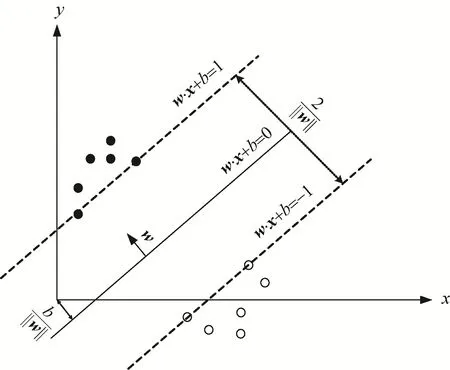
图2 SVM示意图Fig.2 Diagram of SVM

式中:ω为超平面的法向量;||・||表示 L2范数;b为超平面的截距。
显然求得其最优解即可得最优分类超平面和决策函数,然而式(8)为一个包含不等式约束的凸二次规划问题,为方便求解,引入拉格朗日乘子,并将其转化为对偶问题,如式(9)所示。

式中:αi、αj为拉格朗日乘子;〈,〉表示内积运算。
求解对偶问题的最优解 α*、b*,可得决策函数如式(10)所示。

上述分析是在假设数据线性可分的前提下展开,然而实际的样本数据并不一定是线性可分,因此需要采用更复杂的分类方法。针对线性不可分问题,SVM首先引入惩罚系数和松弛变量[18],优化的目标函数如式(11)所示。

式中:C为惩罚系数;ξ为松弛变量。
然后将样本数据映射到更高维的空间,并在高维空间中寻找最优分类超平面[19],决策函数改写为:

式中:ϕ表示原始低维空间到高维空间的映射。
由于高维空间中的点积运算是复杂的,难以显示表达,因此定义合适的核函数来隐式表示,核函数应满足:

常用的核函数有高斯核函数、径向基核函数、多项式核函数等[20]。
4 基于GAN的负荷类别平衡模型
负荷数据的类别不平衡性会导致机器学习算法在训练的过程中无法充分学习不同类别样本之间的差距,进而造成较差的分类结果。因此针对此问题,本文提出一种基于GAN-SVM不平衡负荷数据分类模型。模型的总体框架如图3所示。

图3 GAN-SVM模型框架Fig.3 The framework of GAN-SVM model
对日负荷曲线进行聚类后,首先判断是否存在不平衡问题,然后确定合成数据量,再通过GAN进行样本生成,之后将样本平衡后的数据集作为SVM模型的输入,从而实现对不均衡负荷数据的分类。本文样本不平衡问题的判断依据为:其中一类负荷数据的样本量小于最大类负荷数据样本量的十分之一。
5 算例分析
本文算例采用Python3.7作为编程语言,在操作系统为Win10的PC机上进行仿真分析。其中GAN采用Goole工程师开发的Keras框架进行搭建。K-means、SVM 等其他机器学习算法使用scikit-learn机器学习库进行搭建。
实验数据采用爱尔兰智能电表2009年11月~12月的实测用户用电数据,共包含6 370个用户,数据采集频率为30 min,将对每个用户用电数据进行归一化处理后的月平均(除去周末)负荷曲线作为该用户的典型日负荷曲线,归一化后的所有负荷曲线如图4所示。
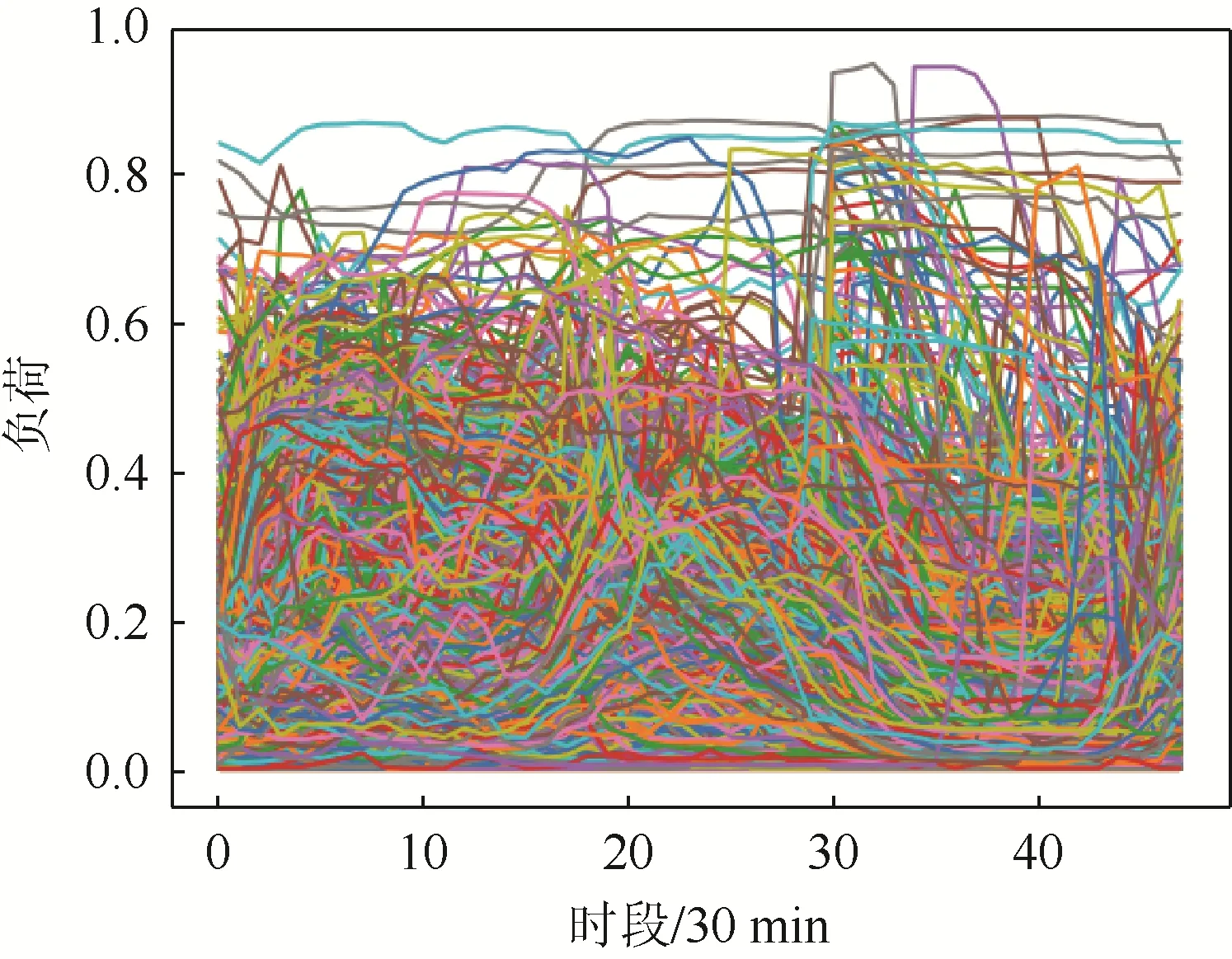
图4 归一化后的日负荷曲线Fig.4 Curve of normalized daily load curve
5.1 负荷曲线聚类
5.1.1 聚类结果评价指标
本文选用轮廓系数(silhouette cofficient,SC)和Davies-Bouldin指数(DBI)作为聚类结果的评价指标。
SC指数综合了聚类的类内凝聚度和类间分离度,取值范围[-1,1],SC值越接近边界值表示聚类效果越佳,计算方法如式(14):

式中:SC(i)表示第i个样本的轮廓系数;ai表示样本i到同一类内其他样本的平均距离;bi表示样本i到非本身所在类的其他样本的平均距离。
DBI指数表示任意两类别的类内样本到类中心平均距离之和与两类中心点之间的距离的比值,取最大值。DBI越小则类内距离越小,类间距离越大,同时聚类效果也最好,计算方法如式(15):

5.1.2 聚类结果展示
由于实际的用户用电数据缺乏真实类别,因此在对用户日负荷曲线进行分类时,首先采用K-means算法对负荷曲线数据集进行聚类,为数据建立标签,以获取训练数据集。聚类结果的DBI与SC指数随聚类数K的变化如图5所示。

图5 不同聚类数K下的DBI与SC指标Fig.5 The indexs of DBI and SC under different cluster number K
综合考虑DBI最小、SC最接近边界值时的K值作为最优聚类数。根据图5,K=4与K=7时相比,虽然DBI指数较小,但是此时SC指数离边界值较远,因此综合考虑DBI与SC指数,确定最优聚类数为K=7,各类负荷的均值中心如图6所示。

图6 聚类中心Fig.6 Clustering center
根据图5各负荷类型的均值中心可以看出,用户侧用电方式多种多样,不同负荷之间的差异较大。第1类、第2类、第3类、第7类负荷水平较低,不同的是类别1用电量相对稳定,日负荷曲线大致呈一条水平线,类别2和类别3的用户用电集中在10:00~15:00,而类别7则是上午时段较高,下午和夜间相对较低;第4类负荷始终保持在较高水平,尤其是5:00~12:00用电量偏高;第5类负荷上午用电量较高,下午时段用电量骤降,第6类则相反,上午时段处于较低水平,15:00左右负荷水平骤升,属于典型的夜间负荷。由此可见,K-means能够很好地划分不同类型的负荷。各类负荷的分布如表3所示。

表3 聚类结果Tab.3 Results of clustering
由表3可知,第1、3、7类负荷占比较多,第 2、4、5、6类负荷占比较少,其中最大类负荷为第1类。第1类负荷曲线数量与第5、6类的比值分别接近16:1、59:1,均判断为少数类。
5.2 基于GAN的类别平衡模型性能评估
本文通过对比GAN与随机过采样、随机欠采样、SMOTE等传统样本不平衡处理方法在负荷数据集上的表现以及不同样本不平衡比例分类精度的影响对所提方法进行有效性评估。
实验中使用经K-menans聚类后的电力负荷数据,由上文可知,负荷共有7种类型,其中第5、6类满足不平衡条件,采用WGAN算法分别对这两类负荷进行数据扩充(扩充至与大类样本量相当)。
考虑到负荷曲线的波动性,若将少数类所有样本均作为GAN的输入,则可能出现生成器受边界样本影响而导致学习不充分甚至失败的情况,因此本文采用欧式距离法,按照距离聚类中心的远近对所有样本进行排序,并最终选取占样本总数1/3且欧式距离最小的样本,作为GAN的输入。在模型的实际仿真中,本文采用每训练一次生成器,训练15次鉴别器的策略进行模型训练。设定epochs为20 000,当判别器判断准确率接近50%时停止训练,此时输入100维随机向量到生成器,就能得到所需的负荷样本。少数类的扩充样本如图7所示。

图7 扩充结果展示Fig.7 Extended result
从图7可以看出,GAN算法能够准确地学习原始负荷数据的分布,生成效果较好,而且生成的样本具有多样性,能够提高分类模型的泛化性。
接下来进行模型的性能评估,分别将扩充前后的数据集输入SVM分类器(其参数采用网格搜索法确定)。同时将本文所提出的方法同其他几种传统的不平衡处理方法(包括随机欠采样、随机过采样、SMOTE方法)进行对比,结果如表4所示。

表4 各模型分类结果Tab.4 Classification results of each model
从表4可知,与不进行平衡处理相比,这些方法均降低了数据集的类别不平衡度,并在一定程度上提高了分类准确率。在所采用的方法中,随机过采样与随机欠采样的分类准确率均低于80%,精度较差。SMOTE算法的分类精度较高,接近90%,而经GAN算法平衡后的数据集分类精度最高,达到了94.779%。
在传统的类别不平衡处理方法中,随机过采样是采用随机复制样本的策略来扩充少数类样本,实际上没有为模型引入新的样本,导致模型的泛化性不足,产生过拟合,从而分类准确度较低。随机欠采用是采用随机丢弃大量多数类样本的策略来减小不平衡的比例,同样存在过拟合问题。SMOTE方法是随机过采样的一种改进方案,其基本思想是分析少数类样本,人工合成新的样本并将其添加到数据集中,具有较高的泛化性。
6 结论
本文提出了一种适用于不平衡负荷分类的机器学习方法,以SVM算法为基础,配合GAN数据合成算法,为类别不平衡数据分类问题提出了一种解决方案。
通过算例分析,进行样本合成方法的分类准确率要明显高于简单的通过随机复制或丢弃样本来降低不平衡度的方法。而在样本合成算法中,本文所提出的基于深度学习中的 GAN进行自动生成样本的方法要优于 SMOTE等采用人工合成新样本的方法。
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
民族古籍研究(2018年1期)2018-05-21
雷达学报(2017年6期)2017-03-26
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
互联网天地(2016年1期)2016-05-04
新校长(2016年8期)2016-01-10
核科学与工程(2015年2期)2015-09-26
浙江大学学报(工学版)(2015年1期)2015-03-01
电子设计工程(2015年6期)2015-02-27
