
检测JavaScript 类的内聚耦合Code Smell∗
2021-11-09 02:45黄子杰陈军华高建华
软件学报 2021年8期
黄子杰 ,陈军华 ,高建华
1(上海师范大学 计算机科学与技术系,上海 200234)
2(华东理工大学 计算机科学与工程系,上海 200237)
JavaScript(简称JS)是一种使用弱类型和动态类型的解释型编程语言,JS 程序的结构和变量类型在运行时才会明确,因此,大量为Java 等强类型语言设计的静态分析手段难以奏效,导致其代码质量缺乏工具保障.同时,它还包含诸多增强语言灵活度(flexibility)的特性,例如原型链、闭包、头等函数等,它们形成了复杂的代码组件继承、组合方式.因此,编写JS 程序颇具挑战性,期间易产生Code Smell 和Bug[1,2].
Code Smell 是软件程序中存在不良设计和不良实现的征兆[3],其强度可由度量指标(metric)量化.正确地检测和量化Code Smell 可以指导软件重构,提高软件的可用性和可靠性.
然而,现有Code Smell 度量不足以理解JS 程序的复杂性和程序质量,常见的Code Smell 度量很少被JS 相关的研究使用[4],需对其进行开发或改进,以适应JS.目前已出现面向JS 的Code Smell 检测工具,例如SonarQube,JSNose[1],它们仅面向微观层面上(即函数、语句)的内聚或耦合问题.
JSNose 主要讨论了函数、代码块及对象内部的Code Smell,并引入了3 种通用类Code Smell 的检测方式来检测对象内部的问题,例如过大对象和不当的继承,但研究不涉及多个对象间的设计问题.研究还提及了一种文件层面的Code Smell,它面向JS,HTML 和CSS 这3 种语言在代码中混写的耦合问题.Saboury 等人[5]根据语言标准的新变化,扩充并修正了JSNose 的定义,此类修正主要发生在语法和语句层面上,涉及作用域和闭包等问题.该研究还就Code Smell 对JS 代码易错性(fault-proneness)的影响排序,结果显示,部分涉及不当赋值的Code Smell 更易引发程序错误.
上述微观研究可以提出程序实现的重构建议、局部提升程序的质量,但无法有效分析粒度更大的(例如类、模块)设计问题.Palomba 等人[6]发现:因为大粒度的代码组件过于复杂,模块和类层面的Code Smell 相比函数Code Smell 更难被有效地识别,解决这类问题的效率和成功率极低,因此需要理论和工具辅助.
类(class)是JS 的一种常见设计模式,在Silva 等人[7]抽选的60 个JS 程序样本中,68%使用了类,34%较频繁或频繁地使用了类.优秀的类设计体现为高内聚和低耦合[8],内聚(cohesion)和耦合(coupling)可用于衡量面向对象程序功能分布的合理性,内聚是软件组件内功能的关联程度,耦合是软件组件间交互的频繁程度.
由于JS 类的信息检测存在困难,导致部分Code Smell 的通用检测方法难以复用,因此Code Smell 的相关工作仍未充分涉及JS 类的常见设计问题.提出一个JS 类的内聚耦合Code Smell 检测方式是迫在眉睫的任务.
本文的主要贡献为:
(1) 结合代码的文本和结构信息,提出了一个检测JS 类的内聚耦合Code Smell 的静态分析方法JS4C,它可以量化Blob、Feature Envy(简称FE)和Dispersed Coupling(简称DC)这3 种Code Smell,并检测JS开源软件中的内聚耦合问题.
(2) 细化并改进了类耦合Code Smell 的检测方式:首先,根据耦合、内聚的设计问题对Fowler 定义的22种Code Smell 进行了分类,对比并区分了FE 的两类检测方式;其次,引入了DC 细化耦合问题检测的粒度,改进了其CDISP 度量,以适应JS 的弱类型语言特性.
(3) 指出了文本信息源对JS Code Smell 检测的重要性.实验发现,引入文本特征可以提升Code Smell 的检测效果.
本文第1 节介绍本文所涉研究领域的相关工作以及其中存在的困难和问题.第2 节介绍本文所涉3 种Code Smell,简述检测的各个阶段,包括预处理、检测和结果输出,是对检测流程的概览.第3 节研究3 种Code Smell的文本和结构方式检测算法,并给出一个综合判定策略.第4 节给出实验,以验证检测结果的准确性,并探究对检测准确性造成负面影响的因素.最后得出结论,并讨论今后的工作.
1 相关工作
1.1 检测JS类及相关信息
图1 为3 个拥有相同属性和方法的Rental 类,图1(a)的程序是一个Java 类,其余两段程序为JS 类,JS 类的实现参考了Fowler 的影音店案例[9,10]和JS 类检测的文献[7].

Fig.1 Demonstration code showing Java and JS class implementations图1 Java 和JS 类的实现代码示例
JS 类是基于JS 原型继承(prototype-based inheritance)构建的一种经典模型[11],它的实现可分为两类[12].
(1) 在早于ES2015 的语言标准中,类是基于函数的设计模式,实现方式不唯一,图1(b)是一种常见的实现.
(2) 如图1(c),ES2015 及更新的标准用糖衣语法(syntactic sugar)简化了类的实现方式.
检测JS 类首先需要定位构造器(constructor,例如图1 中的灰色高亮部分)和成员属性(例如_data),再遍历函数的原型链(例如图1(b)的Rental.prototype)搜索其成员函数和子类.构造器是类的显著特征,可用于创建对象.定位构造器,可通过查找类的实现函数,或查找构造器的调用语句(例如new 语句).目前,已有效果较好的、基于抽象语法树遍历的开源JS 类检测工具JSDeodorant[13]、JSClassFinder[7].
本文需要检测的JS 类信息为类的成员(即函数和属性)、类的函数及其签名、类引用的外部数据提供者(foreign data provider,简称FDP)和类引用的内部成员.某类的“外部数据”指的是软件系统中非本类的类成员.分析引用关系,可通过遍历代码中的访问操作(access)实现.访问操作是指对对象的引用、对其成员属性的引用(reference)或对其成员函数的调用(call).
检测JS 类及相关信息的挑战包括:
(1) 检测难以适用于所有的类实现方式.实现类的设计模式,有至少5 种较为常用的、适用于不同版本语言标准的方式[7,13],给软件组件的判定和标准化带来困难.
(2) 检测类与类间的关系困难.受JS 的语言特性限制,类成员属性的类型在静态分析过程中是未知的.类型信息的缺失,导致分析引用关系的困难.这种缺失无法使用动态分析完全弥补,因其依赖爬虫,不适用于运行在服务端的JS 程序.
1.2 结构分析
结构分析是最常见的Code Smell 检测方法,通常包括2 个阶段,即信息收集和检测判定:在信息收集阶段,分析工具通过遍历抽象语法树获取检测对象的结构信息;在检测判定阶段,需要根据度量的定义将收集得到的信息计算为度量值,再依据规则判定是否存在Code Smell.规则根据Code Smell 的定义设计,它通常由一系列度量阈值条件构成,规则也可以包含其他非数值型特征(例如函数名等文本特征)[14].
本文检测3 种Code Smell,包括Blob,FE 和DC.Blob 体现低内聚,其余二者体现高耦合,定义分别为:
(1) Blob 表现为一个类,它实现了系统中的多种不同职责、体积庞大且复杂,其函数间的内聚性低[6,14,15].
(2) DC 表现为一个函数,与其所在类相比,它更依赖多个非所在类的操作[16,17].
(3) FE 表现为一个函数,与其所在类相比,它更依赖某个特定的、非所在类的操作[6,15].
根据软件组件的粒度及设计问题类型,表1 给出了Fowler[9]定义的22 种Code Smell 的分类情况.其中,FE因同时涉及方法和类的耦合,故出现两次.God Class 亦称Blob,后文均使用Blob 的表述.
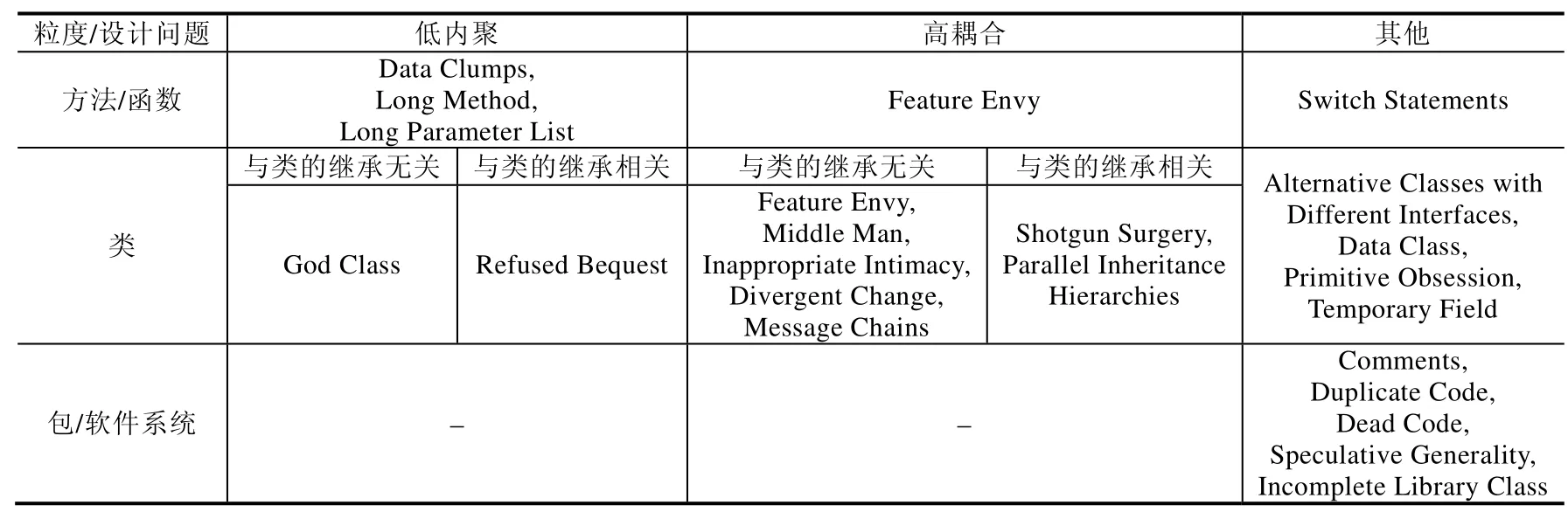
Table 1 Code Smell classification by the types of design problems and their granularity表1 以设计问题种类及其粒度为依据的Code Smell 的分类
Silva 等人[7]指出:JS 软件项目极少使用类的继承特性,在样本中仅占8%.故本文仅讨论与类继承无关的Code Smell.Palomba 等人[18]提出,Refused Bequest 同Message Chains 以及FE 同Inappropriate Intimacy 具有极高的同现性.故本文不涉及Message Chains 和Inappropriate Intimacy.林涛等人[19]指出:Divergent Change 与Shotgun Surgery 矛盾对立、存在权衡关系,且其检测过程需要对多版本进行分析.故不列入研究范围.Middle Man 是一种耦合Code Smell,表现为类代理(delegate)了过多其他类的操作,可视作FE 的一个特殊情况.
综上,在表1 的22 种Code Smell 中,本文聚焦Blob 与FE.因FE 的量化标准不一,故需分类讨论.根据表2,标准可分为两类:其一,确定被检类与一或多个类发生耦合,但不确定与其耦合的类;其二,确定被检类与一个类发生耦合,并确定与其耦合的类.为了细化耦合问题的检测,本文对FE 取后者的定义及检测方式.为了覆盖同多个类发生耦合情况,本文引入DC[16].
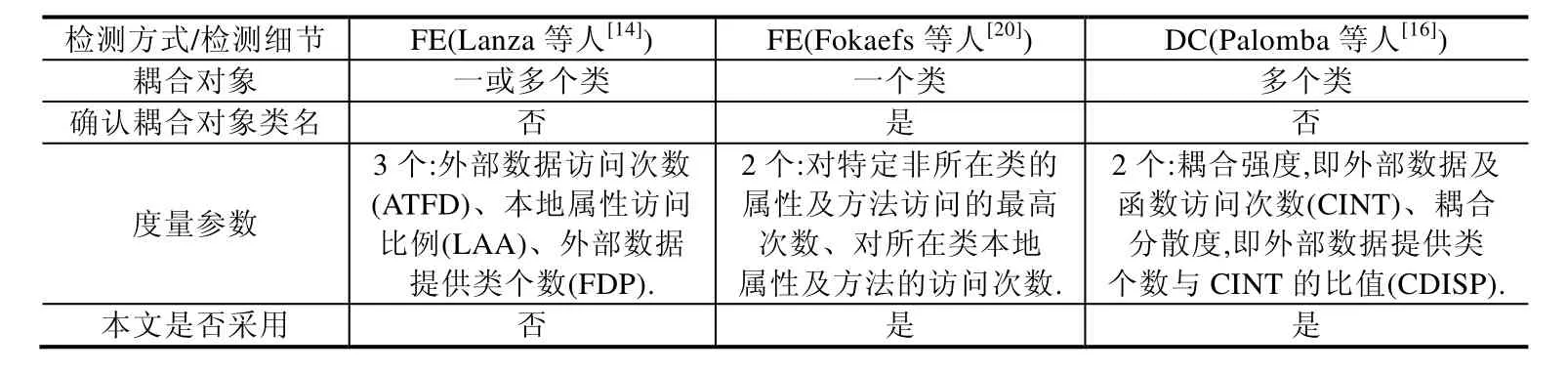
Table 2 Comparison of three Code Smells related to class coupling表2 3 种类耦合相关的Code Smell 对比
结构分析的挑战,是由JS 语言特性和Code Smell 度量指标的特性共同构成的,它们包括:
(1) JS 的语言特性导致结构分析所需的精确信息难以获取,检测耦合Code Smell 需要推断类型或依赖其他信息源.
(2) 部分Code Smell 的量化标准不一.
(3) 类的Code Smell 检测方式均针对以Java 为代表的非解释型语言,对于JS,需要改进部分度量.
1.3 文本分析
文本分析与结构分析的主要区别在于信息收集阶段,前者不依赖或较少依赖抽象语法树中的结构信息,而是将源码视作文本片段,并使用文本挖掘算法计算文本相似度等度量信息.
Palomba 等人[6,15,16]运用结构分析和文本分析,对Java 软件项目的多个历史版本进行了挖掘,研究分析了两种检测方式获取的Code Smell 强度,得出了其解决的难易程度、变化的趋向、产生的原因等性质.研究指出,基于结构方式和文本方式的检测算法互补,文本方式是重要的信息源,将两种信息源结合的工作较少.
因为结构分析方法在检测JS 变量的类型信息时,所能获取的信息远不如Java 项目详实,所以文本分析和结构分析的互补对JS Code Smell 的检测更为重要.
文本分析方法可分为有监督和无监督两类.有监督的文本分析需要额外的人工干预来预先标注文本,以形成带标签(Label)数据集,故不适用于Code Smell 的检测.在无监督的文本分析方面,Blei 等人[21]提出了潜在语义分析(LDA)算法,该算法被应用于Bavota 等人[22]检测Code Smell 的方法中;Le 等人[23]基于Google 开源的、运用深度模型的Word2Vec 词向量算法,提出了将文档用向量表示的算法.
LDA 是一种常用的文档主题生成式模型,包含词、主题和文档这3 层结构.LDA 使用词袋模型表示一个文档,并将一个文档视作隐含主题的有限混合,其中的每个单词由一个主题生成,文档之间的关联可以由主题间的关联决定.LDA 具备比LSA 等基础主题建模方法更强的拟合能力.
Word2Vec算法可利用神经网络语言模型训练过程中获得的权重矩阵参数,将词语转化为向量.Skip-gram是Word2Vec算法使用的一种语言模型,它根据当前词汇预测上下文.Skip-gram 模型共有3 层,即输入层、隐藏层(hidden layer)、输出层.神经网络通过调整隐藏层至输入层、输出层的权重矩阵进行训练,调整训练的过程可概括为:假如若干词具有近似的输出,则可反推词间具有较高的相似性.基于Skip-gram 模型,Mikolov 进一步提出了Doc2Vec,它基于词向量表示文档向量.本文采用PV-DBOW(distributed bag of words version of paragraph vector)模型,其设计思想和Skip-gram 相近,即:通过预测文档的内容训练一个矩阵,此矩阵即为文档矩阵.通过计算文档矩阵间的余弦相似度,可获取相似度特征.
2 检测流程
检测流程包括4 个阶段:信息抽取阶段、预处理阶段、检测阶段、判定阶段,如图2 所示.
(1) 信息抽取阶段:从软件项目的开源社区获取特定Release 版本的源码,配置类检测引擎的运行参数后开始类的检测.类检测引擎基于JSDeodorant[13]改进,JSDeodorant 是开源JS 类检测工具,文献报告其平均表现可达到95%的精确率和98%的召回率.在此基础上,本文借助Google Closure Compiler[24]分析源码所得的JS 语句类型信息,通过扩展对象类型推断[25],实现对类信息的检测.
(2) 预处理阶段:本阶段为检测阶段所需的输入做准备.对于结构分析,需对检测到的JS 类信息去重和计算频次,以便用于度量指标;对于文本分析,需将文本标准化.文本标准化的具体流程如下:
➢ 分词.对驼峰和下划线命名方式的变量名进行分词,将所有英语字符都转换为小写形式.
➢ 去除停用词.将与业务逻辑无关的保留关键字、英语停用词、特殊字符等内容剔除.
➢ 提取词干.去除单词的词缀,得到其词根.
(3) 检测阶段:本阶段对输入数据运行检测算法,并计算动态阈值,最终输出值域为[0,1]的强度值.其中,本文对FE 运用了Fokaefs 等人[20]提出的检测算法,对DC 运用了经改进的非严格NSCDISP 度量,对Blob运用了LCOM5 度量[26].在基于相似度的文本检测方面,本文对FE 和Blob 的检测使用了Doc2Vec算法[23],并以LDA算法的结果作为对照组.由于文本分析对DC 的检测效果不佳,故未予采用.
(4) 判定阶段:对于一个代码片段,检测阶段可输出多个强度值.根据Code Smell 之间的关联和结构和分析方法的特点、优劣,本文提出了一种综合判定策略,最终得出该代码片段的Code Smell 的种类及值域为[0,1]的强度值,强度值越高,Code Smell 越严重.
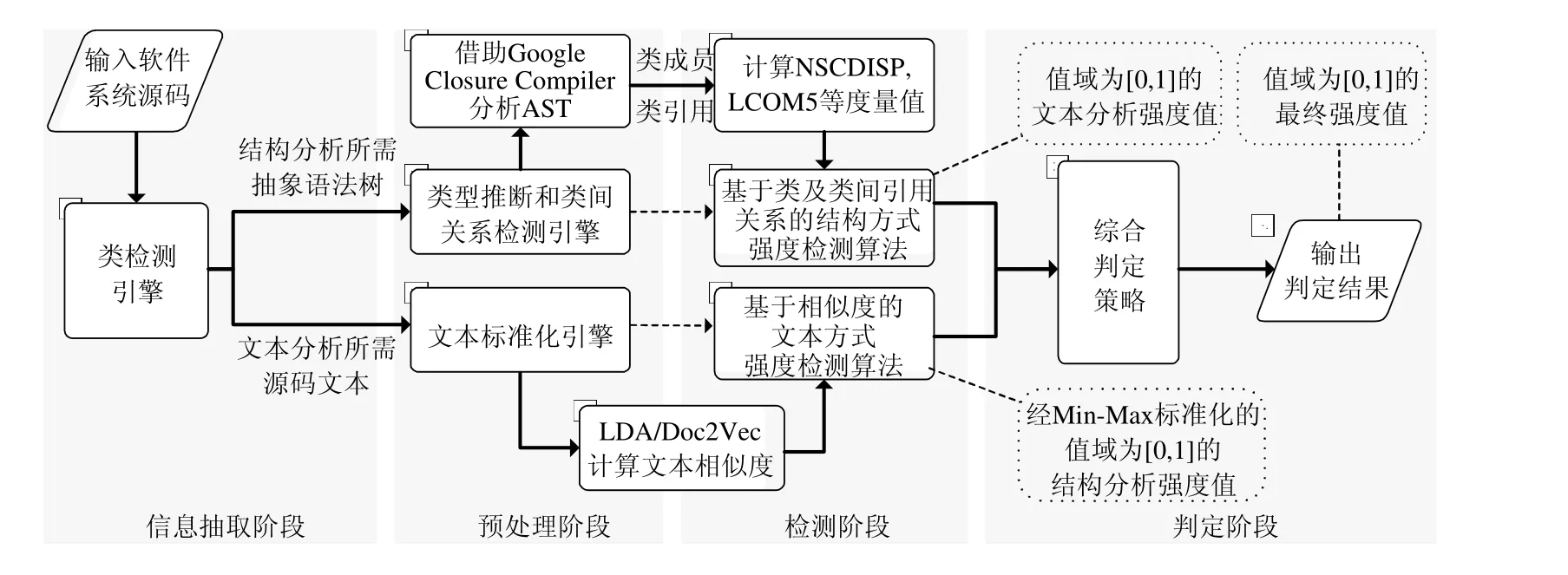
Fig.2 Code Smell detection process of JS4C图2 JS4C 的Code Smell 检测流程
3 检测算法和判定策略
3.1 基于结构分析的强度检测算法
Code Smell 检测的传统方法使用代码的结构信息作为信息源[6],图3 展示了本节涉及的结构信息和度量.
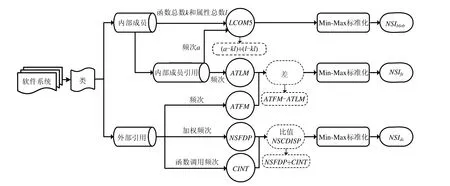
Fig.3 Overview of structural analysis图3 结构分析概览
3.1.1 结构方式检测DC
Palomba 等人[16]对Java 的DC 检测使用了CINT(coupling intensity,耦合强度)、CDISP(coupling dispersion,耦合分散度)和FDP(foreign data provider,外部数据提供类)这3 种度量.其中,CINT 为被检测函数中经去重的函数调用次数,FDP 指标用是所有被访问的数据所属类的去重集合.CDISP 的计算公式如式(1)所示.

由于JS 的语言特性限制了类型检测,即便类型推断可确定部分类型,也无法确定全部函数的入参类型和数据访问操作的变量类型.CINT 和CDISP 的计算都依赖类型判定,若不作改进,检测难以进行.
据此,本文提出非严格的NSCDISP(non-strict coupling dispersion),它的非严格是针对FDP 和CINT 必须精确检测函数入参(input parameter)的类型而言的.尽管引用的对象类型难以精确检出,但类中的数据访问操作总数和类的成员尚可明确,仍可利用以上信息得知引用操作的数量.
CDISP 的计算依赖FDP 和CINT.本文对CINT 的检测不作改动,使用非严格的FDP 个数检测方式:对于不涉及函数入参的数据访问,沿用原FDP 的检测方式,若无法检测到所属类,则将其视作一个单独的FDP;对于涉及函数入参的数据访问,则计算WRFDP.
WRFDP(FDPwith weighted reference)是面向入参外部引用权重的度量,具体方式为:对于函数f,有入参集合Pf.计算f在所属类中被调用的总次数ntc(number of total calls).遍历Pf,对Pf的每个元素pfi,计算pfi被调用时入参形参的所属类为外部类的次数ncfp(number of calls as foreign param).计算ncfp 与ntc 比值,其值域在[0,1]之间.ncfp 计算的基本思路是:分析被检函数的每次调用,若调用的入参不源于所属类,则计入ncfp.
对于被检函数的每个入参,均计算其WRFDP,如式(2)所示.

非严格的NSFDP 的计算公式如式(3)所示.

本文将非严格的NSCDISP 作为DC 的强度(intensity)值Idc,其计算公式为

NSCDISP 和CINT 的检测阈值(文献[16]中的HIGH)取系统检测结果的平均数(AVG)与标准差(STDEV)之和[17],未达到阈值的相关度量值将被改为0,下同.
在计算出软件系统内的全部Idc后,对于该系统的全部函数{f1,f2,f3,…,fi},可以得到一个集合SIdc={Idc(f1),Idc(f2),Idc(f3),…,Idc(fi)},对所得结果进行Min-Max 标准化,使其值域落入[0,1]区间,得出最终的强度值集合NSIdc(normalized structural intensity),如式(5)所示.

3.1.2 结构方式检测FE
对于被检类Ccurrent,遍历系统的类全集C.对于C中的每个元素Ci,检测Ccurrent对Ci成员(函数、属性)经去重后的访问次数ai,并依据ai的值对C中的类从大到小排序,若排序第一的类Ctop不等价于Ccurrent,则判定存在FE.将Ccurrent对Ctop的成员访问次数atop记为ATFM(access to foreign members),将Ccurrent对自身的成员访问次数acurrent记为ATLM(access to local members),FE 的强度为式(6)[20].

若Ife>0,即可判定FE 存在.用类似第3.1.1 节的方式对所得结果进行Min-Max 标准化,得到结果集合NSIfe.
3.1.3 结构方式检测Blob
利用结构方式检测Blob 有两个角度:类的体积和类的内聚性[26].前者根据代码长度或类成员的总数,后者采用LCOM5(lack cohesion of method 5)度量.由于本文的主题仅和内聚、耦合相关,且类体积相关的度量需指定固定的阈值,故不将类的体积纳入检测考虑的因素.
对于类C,获取其函数成员总数k、属性成员总数l、被访问的自身成员(函数、属性)经去重后的总数a,定义LCOM5 为式(7),其值域在[0,2]间,检测阈值取第三分位点(75%)的值[27].

用类似第3.1.1 节的方式对所得结果进行Min-Max 标准化,得到结果集合NSIblob.
3.2 基于文本分析的强度检测算法
图4 展示了文本分析的方式,以经文本标准化引擎处理的全部程序文本为训练集,将每一个类作为一篇文档,训练Doc2Vec 模型.通过该模型,可计算任意两组代码段文本的余弦相似度.余弦相似度的值域落在[−1,1]间,负值的物理意义即为负相关.由于负值偶发,且本文不关注代码段负相关的信息,参照Positive PMI[28,29]对类似问题的处理方式,将余弦相似度的负值视为0,即对于文本段Ta,Tb,其中a与b为任意代码片段,其相似度定义如式(8)所示.


Fig.4 Overview of textual analysis图4 文本分析概览
本文采用类似的方式,利用LDA 计算文本的相似度,并将其作为对照组,相似度值域为[0,1].
本文参考Palomba 等人[18]使用系统内全部非零度量值的中位数(non-null median)作为TIfe和TIblob的阈值.
3.2.1 文本方式检测FE
此方法的基本思路是:对于被检函数f,若存在一个非所属类,它与f的相似度比f同所属类的相似度相比更高,则存在耦合,可判定检出FE.定义f所属的类为CO,计算f所有类的集合SCALL中每个类的文本相似度.即:对于任意Ci∈SCALL,计算PSIM(f,Ci),记录最大值为MaxPSIM,如式(9)所示.
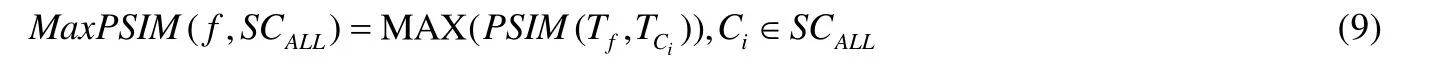
对于FE,定义Code Smell 的强度[6]为式(10).
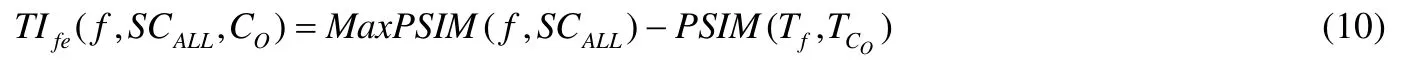
3.2.2 结构方式检测Blob
此方法的基本思路是:类的函数间越不相关,则类的内聚性越低,Blob 的强度越大.
对于被检类C及其函数成员的集合F,如式(11)所示,定义Code Smell 的强度[6]为

其中,ClassCohesion 为类函数间的相关性计算函数,其定义[15]如式(12)所示.
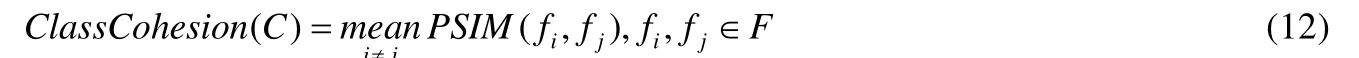
3.3 综合判定策略
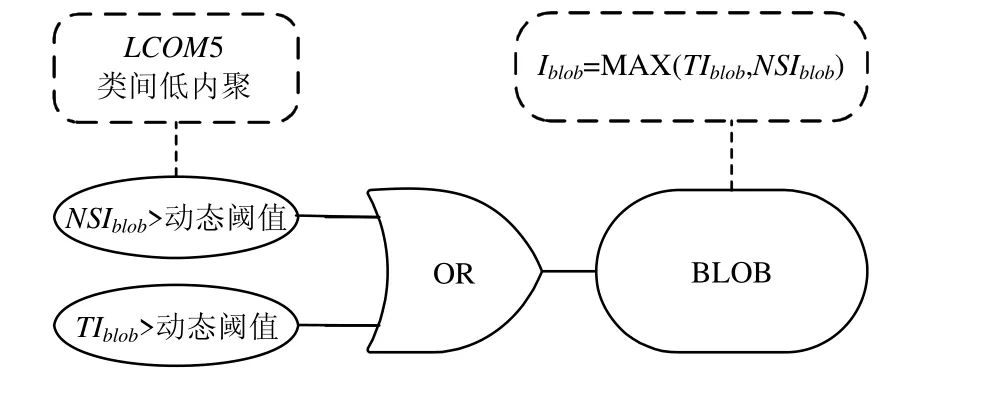
本文按设计问题将Code Smell 分为内聚类和耦合类,图5 中的Blob 属于内聚类,图6 中的DC 和FE 属于耦合类.
判定分为两个步骤:首先,筛选Code Smell 度量强度超过阈值的检测对象;其次,根据文本和结构方式的强度确定Code Smell 的最终强度.对于Blob,通过结构和文本分析检测到的Code Smell 之并集识别.如式(13)所示,强度值Iblob取两者的最大值:

对于DC,本文采用结构分析识别,即NSIdc>动态阈值,如图6.强度值Idc取结构分析的强度如式(14)所示.

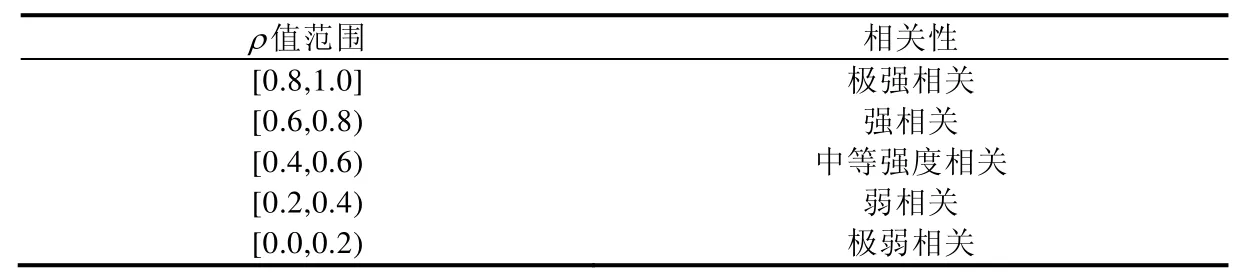
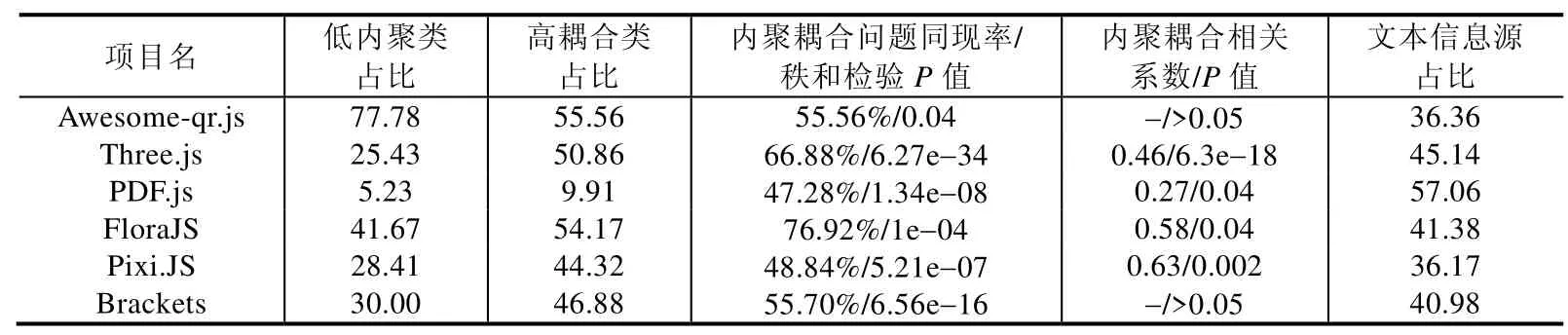
对于FE,本文将存在结构耦合(0 Fig.5 Unified identification strategy of cohesion design problem图5 内聚设计问题的综合判定策略 Fig.6 Unified identification strategy of coupling design problem图6 耦合设计问题的综合判定策略 本文的先进性体现在以下几处:在结构分析方面,本文讨论并选定了3 种Code Smell 的检测方式和阈值,针对JS 检测任务提升了DC 检测涉及的FDP 和CDISP 指标的宽容度,使其适应类型不明的情况;在文本分析方面,本文使用了更优的文本分析算法,并利于文本语义特征实现文本和结构分析的检测结果互补.针对两种分析方法的特点,本文制定了3 种Code Smell 的综合判定策略. 将文本分析和结构分析结合是可行且有效的. •一方面,代码组件的文本中蕴含业务逻辑和组件功能(例如service,manager)信息,这些信息在结构分析时往往难以被充分利用[30].已有学者尝试改善这一情况,例如:Moha 等人[26]检测Blob 时,在结构方式的基础上根据类名判断组件功能;Palomba 等人[15]通过实验得出文本和结构分析的检测结果互补,相互结合可以获得更好的检测效果,将两种信息源结合的工作较少. •另一方面,JavaScript 的类型系统和Java 等强类型语言不同,在变量声明时无需明确类型,导致传统的静态分析难以奏效,无法获得像强类型语言一样详实的类型信息. 判定Blob 使用文本和结构方式的最大值的原因是:(1) Blob 的结构方式只需要检测访问本地和外部数据的次数,对于外部数据的访问,无需明确操作涉及的类,因此获得的结构信息是完整的;(2) 本文的强度值均标准化至[0,1]区间,可以直接比对. 判定FE 时,之所以优先取文本方法的检测值,是因为结构方式检测FE 需要确定耦合对象所属的类.由于JS使用弱类型系统,变量的类型在分析中仅靠推断得出,因此这一结构信息可能检测不全.文本方式根据语义相似度确定是否耦合,不受此限制,因而更可靠. 判定FE 时,使用CINT 作为阈值的原因为:一方面,计算CINT 无需确定耦合对象所属的类,因此该度量的值是可靠的;另一方面,存在业务逻辑类似但实则毫无关联的代码,它们可能会导致文本方式的误判,例如将代码拷贝误判为耦合,使用CINT 阈值可以应对这种情况. 为了验证JS4C 的有效性,本文以表3 中的开源项目作为测试数据集,对JS4C 的检测结果进行评估对比.实验主要寻求以下几个问题的解答. Q1:JS4C 能否准确检测内聚和耦合的设计问题? Q2:JS4C 有哪些已知问题?是否仍有改进空间? Q3:文本检测算法是否提升了JS4C 的检测效果? Q4:哪些因素会影响实验评估结论的有效性? Q5:如何基于JS4C 给出JavaScript 类的重构建议,并实现其应用意义? Table 3 Open source project dataset used for experiment表3 实验所用开源项目数据集 为了保证基础数据的准确性,实验首先对基础度量数据进行了验证.由于缺乏对比的工具,本节实验参照同类Code Smell 的工作[1,3],将对比基准确定为人工检测.检测工作由本文的第一作者及一名拥有3 年工作经验的Web 应用开发者分别独立进行后,针对分歧讨论完成. 其中,Doc2Vec 和LDA 的相似度值分别使用Deeplearning4j 和JGibbLDA库计算,它们被软件分析相关研究[31]和开源社区广泛验证和使用,因此文本分析的人工验证仅涉及输入数据和运算的准确性.结构方式的度量值均源于抽象语法树的结构信息,验证工作将人工计算的结果与工具的结果进行了对比. 获取可靠的度量值后,实验需要进一步验证JS4C 对实际内聚、耦合设计问题的检测效果.本文对数据集中的项目采用了与度量值验证相同的人工检测流程,特别地,对于耦合问题,除了判定有无设计问题外,还需识别出所有人工判定发生耦合的对象,否则视为错判. 为了回答Q1 和Q2,本文使用精确率(precision)和召回率(recall)度量检测的效果,指标的数值越大,表明检测的效果越好.将Code Smell 检测视作一个二分类问题,将存在Code Smell 的类归为正样本类,不存在Code Smell的类归为负样本类.令预测为正的正样本数量为TP(true positive,正确率)、预测为正的负样本数量为FP(false positive,误报率)、预测为负的正样本数量为FN(false negative,漏报率),精确率和召回率分别如式(16)、式(17)所示: 本文对数据集中全部的项目进行了检测,本节以Awesome-qr.js 案例和Three.js 为例,说明实验过程.本节的度量数据在第4.2 节中的表7~表9 展示. Awesome-qr.js 的1.2.0 版本[32]约有1 500 行代码,可在客户端或服务端运行.它拥有两个工具类、7 个功能类,且多个类具有低内聚特征. 表4 列出了对该项目受FE 和DC 影响的全部函数及检测结果.由于上述函数的代码及变量命名均无显著的业务特征(例如mod 和multiply)或特征过多、分散(例如draw),甚至未出现在软件项目中,故文本分析难以确定目标的耦合类.然而,它们的确存在耦合问题,对于这类较为困难的任务,JS4C 体现出了良好的适应性. Table 4 Detection results and effectiveness of FE and DC in Awesome-qr.js表4 Awesome-qr.js 中FE 和DC 的检测结果和检测效果 表5 列出了该项目Blob 的检测结果.在上述检测结果中,对于QR8bitByte,文本分析未检测到Code Smell,而结构分析检出了最高强度的Code Smell.因为类中定义了多个未经函数成员访问的属性,内聚性不足,但函数成员的名称却与业务逻辑有关.对于AwesomeQRCode,它未包含任何属性成员,故结构分析会失效,但文本分析却可以检测出它实现了不相关的多种职责. Table 5 Detection results and effectiveness of Blob in Awesome-qr.js表5 Awesome-qr.js 中Blob 的检测结果和检测效果 Awesome-qr.js 的体积较小,在相关性分析中难以获取足够的有效数据,需要使用规模较大的软件演示后续步骤.Three.js[33]是利用WebGL 和HTML5 特性实现的开源浏览器端三维引擎,截至2018 年9 月,该项目已有近25 000 次代码提交(commit)、88 个发布(release)版本和近1 000 名代码贡献者(contributor).本文利用JS4C 对Three.js r95 版本代码中的232 个类进行了检测,并分析Code Smell 的分布规律及它们之间的关系,其中,共103个类涉及本文讨论的3 种Code Smell. 对于系统内所有的类,获取3 种Code Smell(Blob,FE,DC)强度的集合BLOB,FE,DC.本文利用Spearman 等级相关方法(Spearman’s rank correlation coefficient)[34]分析三者间的两两相关性,该方法可用于未知概率分布的两组顺序数据,取上述两组数据作为输入值,可输出其相关系数ρ及相关性的显著程度P.判定显著程度前,需要选定一个显著等级(significant level)值α,实践中,α通常取值0.05[6].在该取值下,当P<α时,可认为两组数据的差异具有显著性,即具有统计意义;当P<0.01 时,可认为两组数据的差异非常显著.相关系数ρ利用单调方程评价两个统计变量的相关性,它的值域为[−1,1].如表6 所示,ρ值可对应相关性,当数据中没有重复值,且两组变量完全单调相关时,ρ相关系数则为+1 或−1. Table 6 Spearman’s rank coefficient value ρ and its correlation level表6 Spearman 秩相关系数ρ的值及其相关性 本文对Three.js 的3 种Code Smell 检测结果进行两两分析,得出结论:FE 和DC 呈现弱强度的负相关性,其中ρ为−0.30(P=0.001);BLOB 和FE 呈现中等强度的正相关性;BLOB 和DC 的差异不具统计意义. 本文进一步探究耦合设计问题和内聚设计问题的关系. 将Code Smell 分为两类,令内聚Code Smell(Blob)为一类,令耦合Code Smell(FE,DC)为另一类.类低内聚的强度ILC取类的Iblob.一个类具有多个函数,因而具有多个FE 与DC 强度值,对于耦合Code Smell,本文取其均值mean(Ife),mean(Idc),类高耦合IHC的强度优先考虑同一个类发生耦合,即取mean(Ife),若mean(Ife)≤0,则取mean(Idc).对于系统内所有的类,可以获得低内聚强度的集合LC和高耦合强度的集合HC. 本文利用Spearman 秩相关系数分析LC和HC的相关性,仅考虑IHC,ILC均大于0 的情况,得到P值远小于0.05(6.3e−18),ρ为0.46.实验发现,该项目耦合和内聚的强度具有弱正相关性. 将低内聚、高耦合类交集的元素个数与低内聚、高耦合类并集的元素个数的比值作为同现率,得出同现率为66.88%.本文进一步使用Wilcoxon 秩和检验(Wilcoxon rank-sum test)[35]分析两组数据的总体分布是否差异显著:若差异不显著,则相关性和同现率无实际意义.秩和检验亦输出显著程度P,显著等级取值和α相同.分析得出,LC和HC的分布显著不同(P=6.27e−34). 通过与第4.1 节类似的方式,本文对数据集中的所有项目进行了检测,检测结果在表7~表9 中列出.在表7和表8 中,为了验证文本方式对结果的贡献,实验单独列出了去除文本方式后的数据(即“纯结构”列).“重合度”为使用Doc2Vec 和LDA 作为文本算法的检测结果中重复的部分(交集)占全部检测结果(并集)的比重;“非重合部分占比”为去除重复部分的全部检测结果中,二者检测出的信息分别所占的比重. Table 7 Detection results of coupling design problems (%)表7 耦合设计问题的检测结果 (%) Table 8 Detection results of cohesion design problems (%)表8 内聚设计问题的检测结果 (%) Table 9 Other detection results (%)表9 其他检测结果 (%) 对于Q1,根据表7 和表8 中Doc2Vec 列的精确率和召回率数据,可见其总体表现与检测Java Code Smell的同类文献[15]相仿,JS4C 能够比较准确地检测和识别内聚和耦合问题.如表7 所示,使用Doc2Vec 作为文本检测算法的JS4C 在检测耦合问题方面的整体表现更好,在保持与其他方式相当精确率的前提下,大幅提升了召回率;如表8 所示,在检测内聚问题时,其优势更为全面和显著. 本文还参考相关文献得出的内聚和耦合问题的关联和性质,通过表9 中第4 列、第5 列的其他指标验证了其中的结论,以印证对Q1 的回答.Badri 等人[36]指出,内聚和耦合的度量间存在相关性.数据集的6 个项目中,有4个得出了类似结论,其中,Awesome-qr.js 相关性不显著的原因是数据不足.Chahal 等人[8]认为:“高内聚、低耦合”尽管在设计原则中并列出现,但实现高内聚不意味着低耦合,然而在复用性较差的设计中,二者会同时出现.根据秩和检验P值,可知内聚和耦合问题的分布显著不同,因此它们并不是同一种问题;通过同现率,可印证两种问题有较高概率同时出现. 对于Q2,JS4C 包含因上游软件和算法等特性较难排除的已知问题,以及针对软件的具体情况而排除的干扰因素,排除干扰因素可以有针对性地提升在特定项目中的表现,已知问题则需要在后续工作中持续改进. 已知问题包括:(1) JS4C 基于类检测工具JSDeodorant 扩展,检测效果受其制约,尽管JSDeodorant 是目前效果最好的JS 类检测工具,但由于实现类的方式多样,工具会漏检部分构造不规范的类(例如使用对象定义且没有构造器的情形),影响到了检测精度;(2) 文本过短会导致文本模型得出不合理的相似度,因此目前有较多代码行数较小的类被误判为低内聚类;(3) 由于JS 使用弱类型系统,目前使用被调用函数签名的特征推断对象的类,如果特征不明显,对象所属的类可能无法被准确推断,进而影响NSCDISP,ATFM 等结构方式度量计算. 除此之外,还有能因地制宜而排除的干扰因素. 在检测耦合问题的实验中,JS4C 在Three.js 和FloraJS 的例子中的精确率表现不甚理想,主要的错判包括2类情况. (1) 与浏览器支持的WebGL、Canvas 和页面事件等功能接口交互的类和函数中,JS4C 的结构方式将其识别为一种不明来源的耦合,它们实为对浏览器底层功能的封装.对于这类问题,可以通过建立浏览器底层功能函数库的白名单,并将这些函数列入文本检测流程中的“停用词”范畴,以优化检测效果. (2) 由于文本相似度检测的特性,FE 的检测会受到Duplicate Code(重复代码)的干扰.在Code Smell 优先级排序的相关研究中[37],Duplicate Code 优先于FE,该问题可通过Code Smell 排序的方式规避. 在检测内聚问题的实验中,受干扰导致的错判包括3 类情况. (1) 数据类(data class)或模型类(model)中与业务逻辑无关的存取和序列化等函数提高了结构方式内聚性的度量值、干扰了判断:一方面,JS 的存取函数并没有通用的模板代码,其命名和实现方式不遵循特定规则;另一方面,部分存取函数也包含少量的业务逻辑,因此不能简单地排除全部的存取函数. (2) 代码中存在大篇幅的、与业务逻辑无关的变量默认值,影响了文本方式的判断结果. (3) 部分工具类有低内聚的特性,易被判为低内聚类.对于该问题,一方面,工具类是否为反模式仍有争论;另一方面,若实有必要,可以通过工具函数的检测算法[38]将其排除. 对于Q3,文本检测算法提升了检测效果:一方面,在表9 中,易见文本信息源占据了约4 成的比例,是重要的信息源;另一方面,文本方式检测出了更多的、有效的信息.根据表7 和表8 中Doc2Vec 和纯结构方式的对比,易见前者使召回率有普遍提升,即检测到了更多的设计问题;Doc2Vec 检测出的额外信息没有对精确率造成严重影响,在内聚问题的检测中还使精确率有显著提升,即检测到了有效的信息. 在文本方式的算法中,Doc2Vec 方法的整体优于LDA.从表7 和表8 中的“重合度”可以看出,两种文本算法的检测结果具有一定相似性;但从“非重合部分占比”数据可以看出,在余下的不重合部分,Doc2Vec 方法普遍比LDA 能检测出更多不同的数据.根据Q1 的结论,可见这些数据显著提升了检测效果.因此,Doc2Vec 更适合作为本文的文本分析检测算法. 对于Q4,本文实验评估的有效性威胁包括以下3 点. (1) 数据集项目的选取问题.本文从GitHub 和JS 类检测的文献[7]中选取了运行环境多样、功能不同且将类作为主要设计模式的JS 项目用于验证实验结果,但仅涉及了6 个开源项目,无法涵盖JS 程序的全部应用领域. (2) 人工标注设计问题的主观因素.由于缺乏可供参照的同类工作和数据集,因此用于验证有效性的设计问题是人工标注的,存在主观因素.因此,本文参考其他学者[3]的做法,引入具备JS 开源项目经验的开发者合作标注问题,以期还原现实的软件开发和维护情境. (3) 动态阈值的选取问题.由于缺乏JS 类度量指标的统计数据,为了保障检测方法的适应性,本文不使用固定阈值检测.对于Java Code Smell 的文献中采用固定阈值的度量(例如结构方式的DC 和FE),本文根据阈值得出的方式针对每个项目分别统计,形成动态阈值.对于这类改为动态阈值的度量,图7 展示了全部数据集类中它们原始数值的分布,并用分别标注出了原始文献中的固定值(虚线)和统计数据集得出的值(实线).根据两者差值的绝对值同固定值的比值计算,可以得出不同度量的动态阈值与固定阈值有5%(LCOM5)~20%(CINT)不等的差异. Fig.7 Distributions and thresholds of 3 metrics图7 3 种度量的分布及阈值 对于Q5,JS4C 可以量化代码异味强度,通过提升JS 类的内聚、降低耦合来消除强度高的代码异味,进而实现高效的JS 类重构.然而,近期有研究指出:除了异味强度外,还有代码的运行环境、模块和组件的重要程度等情境因素影响代码异味的重构优先级[39],在特殊的情境下,代码异味可能不构成软件设计问题.因此,在实际应用场景中,未被纳入考虑的情境因素可能降低代码异味强度的参考价值.这一问题可以通过实现情境感知的代码优先级排序来解决,它综合考虑影响代码质量和重构优先级的多方面因素,代码异味强度是其中的一维特征[39]. JS 已成为最常用的编程语言之一,然而在JS 项目中,仍未充分实现常见类Code Smell 的检测.本文针对DC、FE 和Blob 这3 种Code Smell,结合文本分析和代码结构静态分析,提出了一个检测JS 类的内聚耦合Code Smell的方法JS4C,并在实验部分,通过对6 个开源项目的分析,证明了JS4C 对内聚和耦合的设计问题有良好的检测效果. 后续工作有3 个方向:其一,研究的范围可以拓展到基于浏览器端框架的业务代码,检测与框架设计相关的内聚耦合Code Smell;其二,对大量的工业软件项目进行大样本的检测,进一步提高检测工具的稳定性和表现,并对Code Smell 及耦合、内聚问题进行详细的质性分析;其三,可以将结构检测和文本检测的结合方法进一步改进,近期出现了基于深度学习模型、抽象语法树中的名称和结构特征及词向量分析代码功能的方法[40],其对Code Smell 检测的帮助也是值得研究的.

3.4 可行性分析
4 实 验

4.1 实验过程



4.2 实验结果


4.3 实验讨论
4.4 有效性威胁

5 结论和后续工作
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学物理学报(2022年2期)2022-04-26
数学年刊A辑(中文版)(2022年4期)2022-02-16
数学年刊A辑(中文版)(2019年3期)2019-10-08
电子制作(2019年16期)2019-09-27
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
中国学术期刊文摘(2016年1期)2016-02-13
