
基于轨迹重构的城市路网OD估计方法
2021-12-23 03:33黎文皓季彦婕戚心怡郑岳标
东南大学学报(自然科学版) 2021年6期
黎文皓 季彦婕 戚心怡 卜 卿 郑岳标 张 凡
(1东南大学交通学院, 南京 211189)(2东南大学道路交通工程国家级实验教学示范中心, 南京 211189)(3School of Informatics, Computing, and Cyber Systems, Northern Arizona University, Flagstaff, AZ 86011, USA)(4Les International (Minsk) Information Technology Co., Ltd., Minsk 220030, Belarus)(5南京莱斯信息技术股份有限公司, 南京 210000)
实时、全样本机动车OD需求是交通规划和主动城市交通管理的重要输入,但是其获取非常困难[1].早期通过进行大规模的居民出行调查来获取OD需求,不仅耗时耗力,且获得的OD信息缺乏时效性.自20世纪80年代起,部分学者利用观测得到的路段流量数据进行OD估计[2].近40年的研究进展,经历了从简单的路网[3-4]逐步拓展到真实的道路网络[5]、从考虑单一路段观测流量到融合多种新兴移动数据的过程[6-7].但这些方法无法精确描述真实路网上的路径选择规律,且往往因为模型约束不足而导致解不唯一.
传统的OD估计方法一般可以分为基于非分配的方法和基于分配的方法.基于非分配的方法[8-9]根据交通网络进出流量之间的关系和交通流量守恒定律来估计.这类方法不能描述复杂的路径选择行为,因此只适用于封闭路网(如简单的高速公路网络).城市路网的大部分研究通常采用基于分配的方法,这类方法使用静态或者动态的交通分配过程来描述OD需求和观测交通流之间的关系,常用模型包括广义最小二乘模型[3, 10]、最大熵模型[11]、贝叶斯理论[12]以及状态空间模型[13-14].基于分配的方法在一定程度上描述了出行者的路径选择行为,但交通分配过程需要基于某一预定路径选择假设来生成一组潜在路径.
近年来,基于轨迹的OD估计方法受到国内外学者的关注,这类方法通过提取准确的单个车辆的运动信息,可以直接捕捉司机的路线感知,克服了前2种方法的缺点.大部分研究[15-16]从观测到的车辆轨迹中提取交通流量计数,用作传统的OD估计方法的输入数据,以提高OD估计的准确性.尽管这些方法能够取得相对可靠的结果,但本质上没有充分利用轨迹中的路径选择信息.此外,为了使估计的OD需求与路网的真实出行分布正确匹配,也有研究通过分析车辆轨迹特征导出路径流信息,以此映射到OD流.如Antoniou等[17]使用从轨迹数据获得的路径流代替路段流,找到了路径流与OD流之间的关系.Rao等[18]利用车牌识别数据实现了高精度的城市路网轨迹重构,并将重构后的路径流量直接统计生成OD流.这些方法都需要路网拥有足够高的检测器覆盖率,而这在现实情况下难以实现.
针对现有研究的局限性,本文提出了一种宏观-微观集成OD估计框架.该框架在微观层建立基于粒子滤波器的轨迹重构模型以考虑个人的路径选择行为,宏观层的OD估计模型利用了随机用户均衡(SUE)原理,补充因检测器缺失造成的流量损失.基于粒子滤波器的轨迹重构模型通过3个观测模型(行程时间一致性模型、流量分布模型、检测器比重模型)更新状态空间概率曲线以重建车辆路径,并进一步合并重建路径,形成OD估计模型中的流量约束.而修正后的OD估计模型可以最大程度地降低SUE目标,并通过考虑重构路径流量约束来反映详细的路径选择行为,从而提高OD估计精度.
1 OD估计方法
本文所提出的OD估计方法主要包含2个核心算法:① 借鉴Feng等[19]和Yang等[20]研究成果设计的基于粒子滤波器的轨迹重构算法;② 考虑车辆轨迹重构路径流约束的OD估计模型.
1.1 基于粒子滤波器的轨迹重构算法
采用粒子滤波器估计非线性系统的隐含状态,其核心思想是使用随机抽样来表示概率分布,并使用给定的观测值来更新概率.对于特定的车辆e,xk={x1,x2,…,xi,…,xI}表示在时刻tk的候选轨迹向量,其中xi表示第i个候选轨迹,I为候选轨迹的总数,zk={z1,z2,…,zj,…,zJ}表示在时刻tk的状态向量(行程时间),其中J为测量的总次数.粒子滤波可以表示为
xk=fk(xk-1,vk-1)
(1)
zk=hk(xk,nk)
(2)
式中,fk(·)为状态转移函数;hk(·)为测量函数;vk-1为过程噪声序列;nk为测量噪声序列.vk-1和nk均假定为独立同分布的随机零均值噪声.
假设xk是候选轨迹向量X={x1,x2,…,xk,…}在tk时刻元素,zk是观测向量Z={z1,z2,…,zk,…}在tk时刻元素.Zk被定义为在时间tk的可用观测值,基于递归贝叶斯框架,候选轨迹xk的后验概率密度函数p(xk|Zk)可以有如下计算:
(3)
式中,p(zk|xk)为选择候选轨迹xk时观测值Zk的条件密度;p(zk|Zk-1)为标准化常数;p(xk|Zk-1)为tk-1时刻观测值为Zk-1时候选轨迹xk的概率密度函数.
(4)
式中,p(xk|xk-1)为状态转移概率,服从于式(1)的状态转移方程,由于p(xk|xk-1)满足一阶马尔可夫过程,因此p(xk|xk-1)=p(xk|xk-1,Zk-1).在该步骤中,可使用基于Chapman-Kolmogorov方程的状态转移函数从tk-1时刻已知的概率密度函数p(xk-1|Zk-1)递归预测p(xk|Zk-1).
(5)

(6)



⑥ 步长更新.令k=k+1并返回步骤②.
通过上述方法将所有不完整轨迹进行还原,可进一步将轨迹重构后的路径流表示为
(7)

为了提高轨迹重构的准确率,本文重要性采样过程基于行程时间一致性准则、流量分布准则、检测器比重准则这3个准则更新粒子权重.
行程时间一致性准则[18-19]用于分析2个连续检测器之间实际行程时间与候选轨迹行程时间的相似性.通过比较2个连续检测器之间的实际行程时间和平均行程时间来计算条件密度函数,计算公式如下:
(8)
(9)
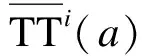
流量分布准则假设路径选择行为与路径的流量大小有关,大流量的路径经常反映那些更可能被车辆选择的路径.基于图论网络可靠性理论[21],可推导出如下公式:
(10)

检测器比重准则[18]将车辆在原始轨迹中通过的检测器数量(即车辆被捕获的次数nr)与每条候选轨迹中包含的检测器数量进行比较,它赋予覆盖更多与原轨迹相同检测器数量的潜在轨迹更高的权重,计算公式如下:
(11)

在所提出的方法中,起点和终点之间的潜在路径被定义为初始粒子.大部分文献通过Dijkstra算法[22]或者深度优先搜索算法(DFS)[23]确定道路网络上2个不同节点之间的潜在路径.这些方法需要遍历网络中的所有节点,因此非常耗时,尤其是在大规模交通网络中.本文采用改进DFS算法[19],基于行驶时间和道路拓扑搜索足够数量的路径,算法流程如下:
① 将网络中所有路段标记为“未使用”,对所有节点设置:k(a)→0,i→0,a→a0.
② 令i→i+1,k(a)→i.
③ 如果使用了连接到节点a的路段,则继续执行步骤⑤.
④ 如果连接到节点a的路段l未被使用,则应该选择该路段,使得l=a或者l=a′.如果k(a′)≠0,则进入步骤③或设置a→f(a′),a′→a,进入步骤②.
⑤ 如果k(a)=1,停止搜索.
⑥ 如果k(a)≠1,继续执行步骤③并搜索下一个节点,其中步骤①~⑥中,a表示父节点,a′表示子节点,k(a)表示父节点a的DFS代码,f(a)表示父节点集合,从选定的f(a)到a的链接称为父子链接,a0表示根节点.
⑦ 使用基于行驶时间效益和道路拓扑的幂律分布计算权值.行驶时间效益表示行驶时间较短的路径,道路拓扑表示高等级道路的百分数.权值的计算公式为yi=e-u(xi),其中u(xi)为可能轨迹xi的效用函数,yi为效用函数下的权值.

另外,对于特定车辆,给定原始部分轨迹中的2个连续位置和相应的时间戳time(a)、time(a+1),则可以通过如下过程实现始粒子生成:
① 计算真实行程时间和行程时间阈值.通过式(11)计算这2个连续位置之间的真实行程时间TT(a)=time(a+1)-time(a),并使用Dijkstra方法计算点a和点a+1之间最短路径自由流的行程时间FFT(a)作为行程时间最小可接受时间,最大可接受时间可计算为Tb=λFFT(a),其中λ为大于1的系数,在这项研究中,建议使用特定连续点的真实行程时间除以FFT(a)计算λ的值.
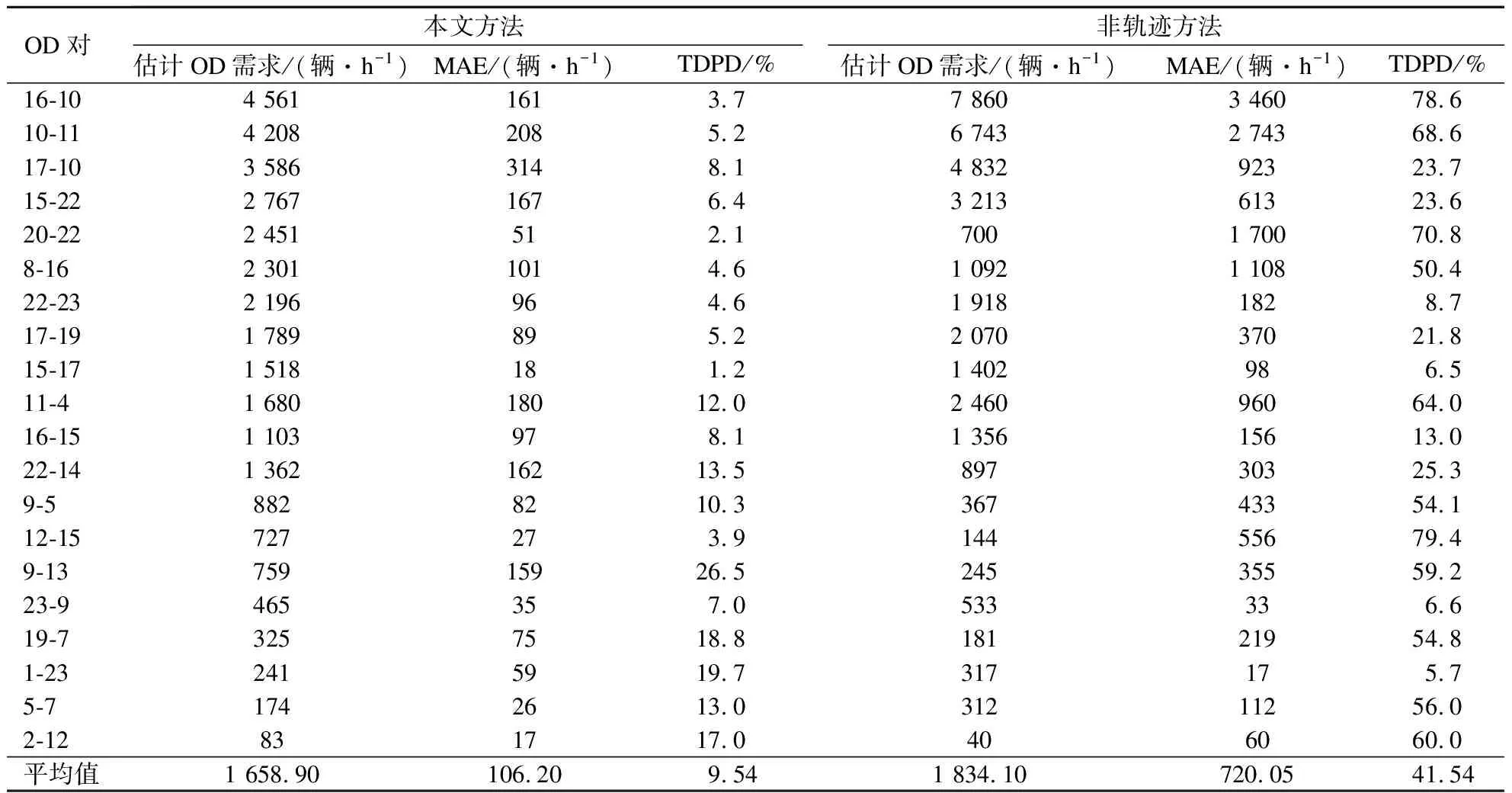
② 异常位置清洗.如果TT(a) ③ 停留位置和停留时间估计.如果TT(a)>Tb,则假设车辆停靠在点a,停靠时间为|TT(a)-Tb|,将点a标记为新的始发点/目的地,并重新分配Tb. ④ 估计2个相邻点之间的潜在路径.如果FFT(a)≤TT(a)≤Tb,估计2个相邻点之间的行程时间,使用改进的DFS算法搜索足够数量的路径,所有可行路径视为潜在路径,可行路径集合为PPS(a),表示点a和点a+1之间可能的路径集. ⑤ 位置更新.如果点a不是原轨迹序列的最后一个点,则令a=a+1,并返回步骤①,否则转到步骤⑥. 本节介绍如何利用部分路段、路径流量的组合数据进行OD估计,并提出一种通过车辆轨迹重构修正的OD估计模型.没有轨迹重构修正的OD估计模型与Lundgren等[24]提出的模型相似.模型决策变量为部分路径流量vp和可观测路段l的流量ol,其中上层建立广义最小二乘模型使路段流量、路径流量的估计值与观测值的距离最小;下层模型是基于Logit的随机用户均衡分配模型,该模型假设出行者对于路段阻抗的感知是主观的,并不一定选择实际上最小阻抗的路径,而是出行者自己认为阻抗最小的路径.该模型公式如下: s.t. Ws≤Ts∀s∈S s.t. 通过粒子滤波进行车辆轨迹重构建立的路径集克服了原有路径集中存在的错误、冗余、不完整问题.基于粒子滤波器的轨迹重构算法在给定重构路径集和路径流的情况下,对原模型下层模型进行修正,找到一个满足SUE模式的路径流解,同时满足重构路径集和重构路径流约束.添加轨迹重构补充集的改进OD模型如下: s.t. Ws≤Ts∀s∈S s.t. 该双层规划模型采用Rostami等[25]提出的求解方法进行求解,该方法包括2个停止准则,即达到最大迭代次数或者目标函数差值在规定的迭代次数内下降到预定阈值.具体步骤如下: 1) 更新路段流量 ① 对初始的OD矩阵进行交通分配,得到所有路径流量.本文采用Liu等[26]提出的自适应平均法(MSWA)求解SUE交通分配问题. ② 令m=1. ③ 使用下式估计路段流量: (12) ④ 通过将观测的路段流量总和与估计的路段流量总和进行比较,可获得出行增长系数Gt,即 (13) (14) ⑥ 检查每一OD对间的行程数,如果低于需求下限值,则用OD需求下限值代替. ⑦ 对Tm进行交通分配,得到所有路径流量.如果Gt值接近1,那么进行步骤2),否则,用Tm代替T0,令m=m+1,并回到步骤③. 2) 更新路径流量 ① 令m=m+1. ② 使用下式估计部分路径流量: (15) ③ 基于一组可能的网络均衡路径来校正OD对流量,迭代公式为 (16) (17) ④ 检查每一OD对间的行程数,如果低于需求下限值,则用OD需求下限值代替. 3) 最优OD估计 ① 令m=m+1. ② 使用式(12)、(15)分别估算路段流量和部分路径流量. ③ 将路段流量、部分路径流量观察值与估计值之间的差值直接分配到包含它们的路径上,计算公式为 (18) ④ 使用调整后的路径流更新OD对间的行程数,计算公式为 (19) ⑤ 检查每一OD对间的行程数,如果低于需求下限值,则用OD需求下限值代替. 由于目前无法同时获得现实路网准确的OD需求以及自动车辆识别数据,在本研究中,建立了Sioux-Falls网络的VISSIM仿真模型.在VISSIM模型中通过设置虚拟检测器来模拟现实环境中的自动车辆识别系统,该网络拥有24个节点、76条路段和528个OD对,试验路网如图1所示.利用Sioux-Falls网络数据对仿真模型进行校正和验证,校准后的模型路径流量的平均相对误差为13%,旅行时间的平均相对误差为15%,仿真模型的精度满足试验要求. (a) Sioux-Falls网络拓扑结构 (b) VISSIM仿真模型 2.2.1 轨迹重构 本文通过轨迹重构来更新OD估计模型中的路径流,因此轨迹重构的准确性是影响OD估计性能的关键因素.虽然VISSIM模型可以直接获取车辆的完整轨迹,但是为了还原真实的交通环境,通过虚拟检测器数据完成车辆的轨迹重构过程.VISSIM模型直接提取的数据被用来标定模型参数,校准系数α和β分别设置为2.25和0.45,停留时间阈值设置为5 min.在试验区域内,设置的初始采样率为85%,意味着至少有85%车辆可以通过虚拟检测器捕获.试验结果显示每条轨迹的平均计算时间与粒子数量成正比,计算时间从86 ms到134 ms不等,轨迹重构速度满足离线OD估计要求[18].进一步使用平均绝对误差(MAE)和平均绝对百分比误差(MAPE)指标评价轨迹重构的路径流量估计性能,结果显示估计的路径流量MAE值在25~36辆/h之间,MAPE值为17.75%,该错误率意味着轨迹重构结果对于OD估计是准确的[18].图2展示了车辆仅在节点3与节点19被虚拟检测器捕获情况下的轨迹重构过程.由于可行轨迹数量较多,图中显示粒子数量超过3 500,所有粒子权重均低于0.5.将重构结果与VISSIM模型直接提取的轨迹进行比较,发现轨迹重构模型在低检测器覆盖率条件下仍具有较高的可靠性. (a) 粒子滤波采样过程 (b) 轨迹的粒子权重 2.2.2 OD估计精度分析 对比了本文方法与非轨迹方法[24]的OD估计精度,使用MAE和总需求百分比偏差(TDPD)作为评价指标[25,27].随机选取了20组OD对的估计结果,如表1所示.结果表明,本文方法的MAE平均值和TDPD平均值分别为106.2辆/h和9.54%,远低于非轨迹方法的720.05辆/h和41.54%.本文方法在估计精度上相比较于传统的非轨迹方法具有明显的优势,自动车辆识别系统提供的大样本数据极大地提高了OD估计模型的可靠性,同时降低了模型收敛难度.尽管也有极少低需求的OD对(23-9、1-23)中非轨迹方法的估计精度优于本文方法,但总体而言非轨迹方法的估计精度极不稳定,尤其是在需求较大的OD对中(>3 000 表1 轨迹重构与无轨迹重构方法OD估计结果对比 辆/h)的估计误差较大,TDPD平均值为52.616 7%,而本文方法在不同的OD需求(100~4 400辆/h)下的估计精度比较稳定,TDPD值在2.1%~26.5%之间变化.同时可以看到,在OD对23-9、1-23中尽管非轨迹方法较优,但实际上本文方法与非轨迹方法的估计结果是相近的,这种优势实际上并不明显.进一步分析了非轨迹方法比本文方法估计精度高的情况,发现该区域检测器的覆盖率非常有限,这可能进一步导致异常的路径流量产生,影响了本文方法的检测精度. 2.2.3 检测器覆盖率影响分析 在现实场景中,自动车辆识别系统对所有车辆的捕获是具有挑战性的.研究发现,检测器覆盖率对于OD估计的精度有影响[18,28].因此,本文比较了所提出方法在不同检测器覆盖率(80%、70%、60%、50%、40%、30%)下的OD估计精度.图3显示了不同检测器覆盖率下的OD需求观测值与估计值的散点图.如图3(a)~(f)所示,随着检测器的覆盖率下降,拟合线斜率和R2均从1开始下降,表明检测器覆盖率越低,OD估计的精度越差.此外,当检测器覆盖率在60%~80%之间时,斜率波动较小,表明算法的置信度较高,而检测器覆盖率在30%~40%之间时,OD需求有被高估的趋势,算法的置信度较低. (a) 80%检测器覆盖率 (b) 70%检测器覆盖率 (c) 60%检测器覆盖率 (d) 50%检测器覆盖率 (e) 40%检测器覆盖率 (f) 30%检测器覆盖率 进一步分析了所有检测器覆盖率下OD估计的MAPE和均方根误差(RMSE),以及路段流量估计的MAPE,计算结果如图4所示.可以发现,OD估计的MAPE和RMSE值都随着检测器覆盖率的增加而减小.然而当检测器覆盖率小于60%时,MAPE值大于40%,RMSE值大于300辆/h,OD估计精度的衰变加速有以下原因:① 检测器覆盖率的减少导致车辆轨迹重构精度间接影响到OD估计精度;② OD估计模型没有足够的输入数据造成过大的估计误差.根据现有的分析结果,本文方法在检测器覆盖率大于60%的条件下可以得到较为可靠的OD估计结果.同时,可以看到,在不同检测器覆盖率下路段流量估计的MAPE始终稳定在10%~20%之间,表明轨迹重构方法即使在低覆盖率条件下依然可靠,这也进一步验证了本文方法的有效性. 图4 不同检测器覆盖率下准确性 1) 本文提出了一种基于自动车辆识别数据的宏观-微观集成的OD估计算法,并在基于Sioux-Falls网络的VISSIM仿真模型中得到验证.试验结果表明该方法在OD估计精度上明显优于传统的非轨迹方法,并且在低检测器覆盖率条件下仍然具有可靠的预测精度. 2) 基于粒子滤波的轨迹重构方法估计出的路径流与仿真模型中观测到的路径流吻合较好.该方法有效地利用自动车辆识别系统大样本数据集,微观层能够考虑司机在路线选择时感知的随机特征,宏观层的SUE模型补充因检测器缺失造成的流量损失,实现了高精度的轨迹重构与OD估计,可以应用于实际的交通管理场合. 3) 本文采用了Sioux-Falls网络数据和VISSIM仿真数据验证了所提方法,在以后的研究中可进一步在完全真实的交通环境中进行验证.此外,该方法可以与用于实时交通管理应用的在线OD估计方法相结合.数据质量是影响估计结果的关键因素,为了衡量试验区域内轨迹数据质量,可增加一些潜在的衡量标准,包括自动车辆识别系统的渗透率和识别率.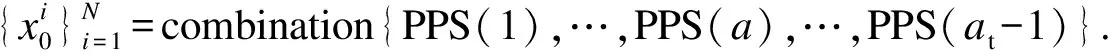
1.2 OD估计模型修正及求解算法
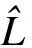



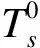






2 算例分析
2.1 研究区域与试验平台


2.2 OD估计结果分析









3 结论
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
今日农业(2022年15期)2022-09-20
测控技术(2022年4期)2022-04-27
雷达科学与技术(2021年5期)2021-11-29
今日农业(2021年21期)2021-11-26
北京交通大学学报(2021年4期)2021-09-26
西安电子科技大学学报(2021年2期)2021-04-30
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
科技风(2018年15期)2018-05-14
