
基于深度学习的车辆目标检测算法综述
2022-02-21 03:16杜学峰
汽车实用技术 2022年2期
杨 伟,杜学峰,张 勇,高 越
基于深度学习的车辆目标检测算法综述
杨 伟,杜学峰,张 勇,高 越
(长安大学 汽车学院,陕西 西安 710064)
车辆目标检测是自动驾驶环境感知的重要组成部分。近年来随着深度学习在目标识别领域取得重大突破,基于深度学习的车辆目标检测算法逐渐成为该领域的研究热点。论文对当前主流的两阶段车辆目标检测算法和单阶段车辆目标检测算法进行简要介绍,分析了其中几种具有代表性的卷积神经网络算法的优缺点,最后总结目前车辆目标检测存在的问题以及未来的发展方向。
深度学习;卷积神经网络;车辆检测;目标检测算法
前言
当前自动驾驶已成为智慧交通研究领域的热门方面。环境感知、行为决策和运动控制是自动驾驶的三大任务,而车辆目标检测作为自动驾驶环境感知的重要组成部分,为后续车辆的决策规划、行为控制等高层任务提供基础支撑。从静态图片或者动态视频中检测出车辆目标及其在图片中的位置等特征信息,并对车辆类型进行分类是车辆目标检测的主要目的。
传统的车辆检测算法是基于人工特征提取的思想,存在很多缺陷。人工提取特征直接影响算法的准确性,而且滑动窗口方法的复杂度高,存在大量的冗余计算,势必导致运行速度难以提升。因此传统的车辆检测算法逐渐被需要高准确性和高实时性的自动驾驶所抛弃。基于深度学习的车辆检测算法针对传统车辆检测需要手动提取特征和滑动窗口遍历的缺陷,提出具有自主学习目标特征的神经网络模型,特别是基于卷积神经网络(CNN)的检测算法的提出使得车辆检测的准确率和实时性达到了新的高度[1]。
本文主要介绍了应用于车辆检测算法的几种主流的卷积神经网络模型,并对其优缺点进行简要分析,最后讨论了当前车辆目标检测存在的难点问题以及未来的发展方向。
1 两阶段车辆目标检测算法
两阶段的车辆目标检测算法继承了传统检测算法的滑动窗口思想,整个算法分为两部分:候选区域的选取以及分类。该算法的优势在于选取多个候选框可以充分提取车辆目标的特征信息,检测结果的准确性较高,同时可以实现精确定位,但由于分两步进行,导致运行速度较慢。
1.1 R-CNN算法
R-CNN算法由Girshick R等人在2014年提出[2],该算法在目标检测领域取得巨大成功,为后续该系列检测算法奠定了基础。R-CNN算法的结构如图1所示,主要由四个部分组成:第一步输入图像;第二步利用选择性搜索算法SS(selec-tive search)从图像上提取出2 000左右的候选区域;第三步将每个候选区域裁剪变形统一成227×227的图像并送入卷积神经网络提取出特征向量;第四步通过SVM(support vector machine,支持向量机)分类器进行分类得出检测结果,最后通过非极大值抑制算法去除多余的候选区域,得到目标的最佳预测框。
虽然R-CNN算法在VOC2007和VOC2012数据集上取得了较好的成绩,但是对候选区域的裁剪变形会损失部分图像的特征信息并且扭曲目标的位置信息,间接影响了检测的精度,同时每张图像需要对2 000个候选区域进行卷积运算,使得计算冗余增加,检测速度较慢。

图1 R-CNN结构
1.2 SPP-Net算法
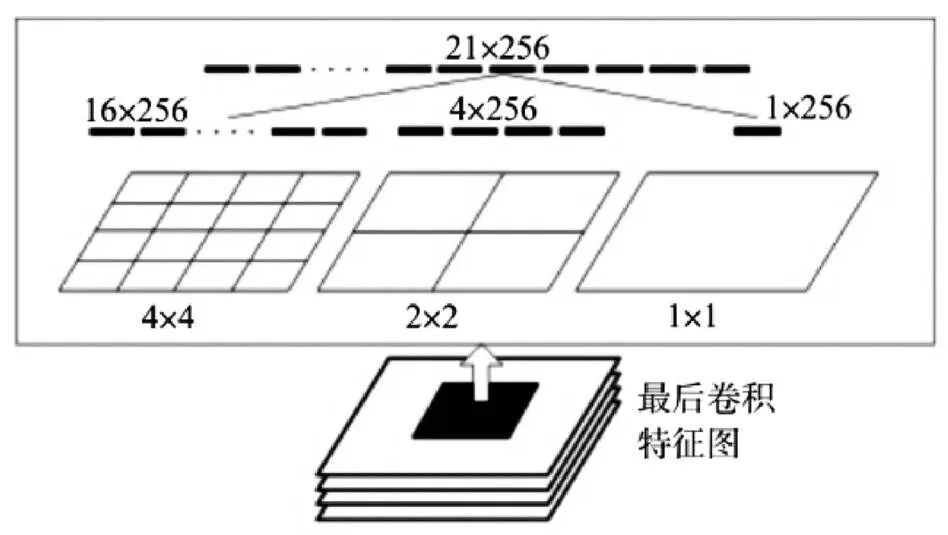
图2 金字塔池化模型
为解决R-CNN算法只能对固定大小的图像进行卷积运算导致特征信息损失以及运算速度慢的问题,He等人于2015年提出了SPP-Net算法[3]。该算法提出一种新的池化层模型,即空间金字塔池化模型(Spatial Pyramid Pooling, SPP),其结构如图2所示。空间金字塔池化模型使用4×4、2×2、1×1三种不同尺寸的方框对卷积后的图像进行池化操作,从21个方框中提取出一个21维特征向量输入全连接层。SPP-Net算法通过引入SPP来避免重复进行卷积运算,在保证同样或者更好地检测精度的同时,极大地提升了检测速度,相比R-CNN算法快24倍~102倍。但此算法依然存在耗费大量存储资源和多阶段训练等问题,而且空间金字塔池化模型的多尺度使得无法对之前的卷积层进行微调。
1.3 Fast R-CNN算法
2015年Girshick等人提出Fast R-CNN算法[4]。该算法对R-CNN进行了改进,在卷积计算部分使用VGG16网络代替Alex-Net网络。同时借鉴SPP-Net算法的空间金字塔池化思想,将多尺度金字塔池化模型简化为单尺度,解决了卷积层不能微调的问题。该算法采用多任务训练的方法,使用SoftMax分类器代替SVM分类器,同时进行分类和回归任务,降低了存储资源的耗费,提升检测精度的同时加快训练速度。
2 单阶段车辆目标检测算法
单阶段车辆目标检测算法省去了候选区域的选取步骤,使网络结构得以简化,极大地提升了算法的检测速度,但同时导致特征提取不充分,牺牲了一定程度的准确率,以及出现检测目标定位精度降低等问题。
2.1 YOLO算法
2016年Redmond等人第一次提出YOLO v1算法[5],将目标图像输入神经网络,直接得到目标的边界框和分类结果。如图3所示,YOLO算法首先将目标图像划分分为S×S的方格,如果某个目标物体的中心点落在某个方格中时,便围绕该方格预测出N个边界框,并计算出每个边界框所围目标的置信度,最后利用非极大值抑制算法(NMS)去除单个目标多余的边界框,得出检测结果。与其他算法相比,该算法的最大优势就是检测速度快,可以实现每秒检测45帧,能够很好地区分背景与待测物体,但同时损失了一定的准确度而且对小目标的检测效果欠佳。
YOLO v2算法为解决YOLO v1算法检测精度低的问题,在每个卷积层后增加BN(batch normaliza- tion),应用多尺度训练的方法来提高可检测目标的数量以及使用高分辨率的数据集在预训练的CNN上做微调。YOLO v3算法引入残差模块和9个锚框进行检测,在保证检测速度的同时,提升和小目标的检测精度。YOLO v4算法使用更好的Mish激活函数,还引入了SPP模块,进一步提升了检测效果。YOLO v5算法几乎与YOLO v4算法同时提出,在性能上稍弱于YOLO v4,但在灵活性与速度上远强于后者。
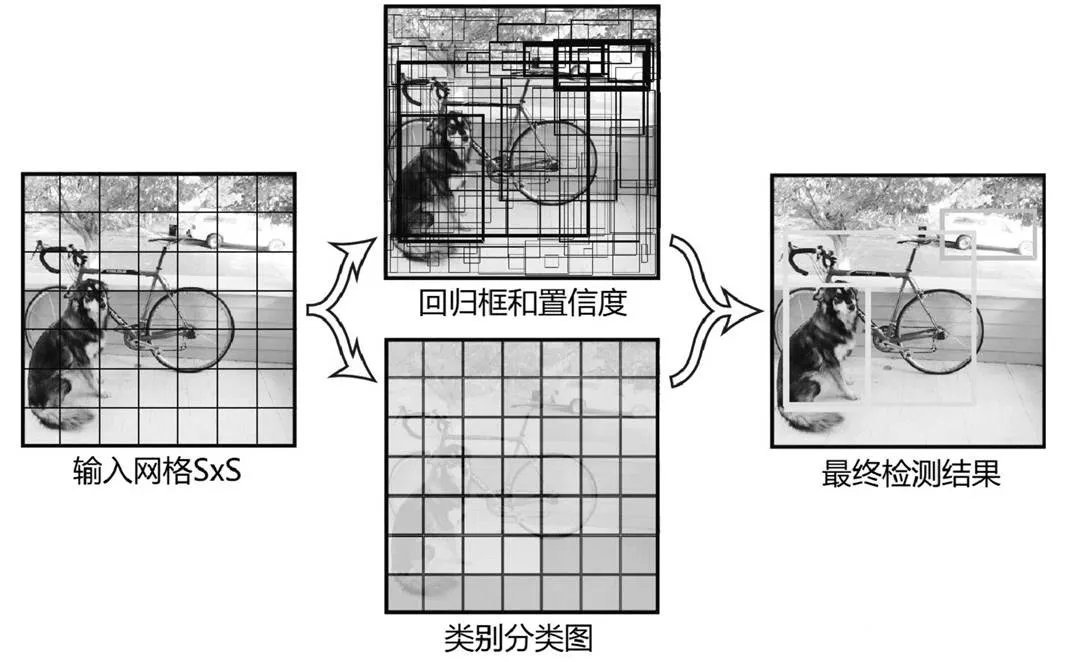
图3 YOLO算法结构
2.2 SSD算法
2016年,Liu等人提出SSD(single shot multibox detector)算法[6]。该算法结合了YOLO算法中的锚框设计方法,采用VGG16的卷积层作为主干网络,并在此基础上新增加了6个卷积层,从而获得更多的特征图。SSD算法将多尺度特征图进行融合,可以更好地提升检测速度。但由于特征图的表征能力不够强,对小目标的检测效果仍然不理想。
3 总结与展望
本文阐述了当前应用于车辆目标检测任务的几种卷积神经网络算法,对各个算法的优缺点进行简要分析。目前车辆目标检测技术日趋成熟,但是依旧存在不少难点问题:(1)针对弱光或者夜间条件的车辆目标检测无法到达实际应用的要求;(2)更深层次的神经网络所带来的大量参数和计算对计算机硬件资源的消耗更大;(3)实际应用需要设计轻量化的神经网络并可移植到嵌入式设备上。
[1] Acharya U R,Oh S L,Hagiwara Y,et al.A deep convolutional neural network model to classify heartbeats[J].Computers in biology and medicine,2017,89:389-396.
[2] Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmenta-tion [C]/Proceedings of the IEEE conference on computer vision and pattern recog- nition.2014:580-587.
[3] He K,Zhang X,Ren S,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE tran- sactions on pat- tern analysis and machine intelligence,2015, 37(9):1904-1916.
[4] GIRSHICK R.Fast R-CNN[C]/Proceedings of IEEE Interna- tional Conference on Computer Vision. Washington:IEEE Computer Soc- iety Press.2015:1440-1448.
[5] Redmon J,Divvala S,Girshick R,et al.You only look once: unified,real-time object detection[C]/Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016:779-788.
[6] Liu W,Anguelov D,Erhan D,et al.SSD:single shot mul tibox detector[C]/European Conference on Computer Vision-ECCV. Springer:In- ternational Publishing,2016:21-37.
A Review of Vehicle Target Detection Algorithms Based on Deep Learning
YANG Wei, DU Xuefeng, ZHANG Yong, GAO Yue
( School of Automobile, Chang'an University, Shaanxi Xi'an 710064 )
Vehicle target detection is an important part of automatic driving environment perception. In recent years, with the great breakthrough of deep learning in the field of target recognition, vehicle target detection algorithm based on deep learning has gradually become a research hotspot in this field. This paper briefly introduces the current mainstream two-stage vehicle target detection algorithm and single-stage vehicle target detection algorithm, analyzes the advantages and disadvan- tages of several representative convolution neural network algorithms, and finally summarizes the existing problems and future development direction of vehicle target detection.
Deep learning;Convolutional neural network;Vehicle detection;Target detection algorithm
U495
A
1671-7988(2022)02-24-03
U495
A
1671-7988(2022)02-24-03
10.16638/j.cnki.1671-7988.2022.002.006
杨伟,研究生,就读于长安大学汽车学院,研究方向:智能网联车及无人驾驶。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
初中生世界·九年级(2018年12期)2018-12-22
软件(2017年6期)2017-09-23
中国新通信(2017年9期)2017-05-27
读者(2015年9期)2015-05-04
