
国内外“睡美人”现象研究的兴起与进展*
2022-06-23 14:01高健航高继平师丽娟
情报杂志 2022年6期
高健航 高继平 师丽娟
(1.中国农业大学情报研究中心 北京 100083;2.中国科学技术信息研究所 北京 100038)
早在20世纪60年代,研究人员发现一些论文发表时无人问津但若干年后被大量引用。起初,学者将这类现象称为“阻滞发现”[1-2]、“过早发现”[3]、“迟滞承认”[4-5]等。直到2004年,荷兰莱顿大学计量学家Van Raan[6]将这类现象冠以一个童话般的名字“睡美人”,“睡美人”文献研究开始引发研究人员的广泛关注。归纳起来,睡美人文献研究演进过程如图1所示。
“睡美人”这类被延迟承认的文献中大多均提出超前沿的认知而被当时所忽略,但其中包含的变革性知识在后来的科技进步中起着重要作用。典型的睡美人文献莫过于孟德尔的豌豆杂交育种实验,其实验结果于1866年发布,直到1901年才逐渐被科学界认可并最终成为经典[7]。与睡美人相对应的概念为“昙花一现”[8],也有学者称之为“时髦女”[9]。这类文献在发布之初便得到学界广泛关注,但持续时间较短便被遗忘,在计算机、医学等快速发展的领域“昙花一现”现象较为明显。研究“睡美人”的同时,有学者开始寻找唤醒“睡美人”的关键文献并将其称之为“王子”[10]。此后,又有学者发现,一些高质量的论文发表之初表现活跃,但随后陷入沉寂,在若干年后再次被“王子”唤醒,这类论文被称之为“全要素睡美人”[11]。近年来,国内外对“睡美人”文献研究均取得一定进展,如Ke等[12]通过引入B指数对一篇文章是否有可能为“睡美人”文献进行识别;van Dalen等[13]对“睡美人”文献研究中发现顶级期刊中的“睡美人”更易被唤醒;Ye等[14]通过比对论文的引文轨迹提出定量识别“睡美人”与“昙花一现”方法;郭斐等[15]对“睡美人”文献的形成原因、识别标准及唤醒要素进行论述;杜建等[16]提出Bcp指数并对Science与Nature中的“睡美人”文献进行检验;Zong等[17]研究“睡美人”文献被唤起原因;侯建华等[18]引入Cc指标对“超弦理论”领域的“睡美人”文献进行识别并探索文献苏醒后引文曲线的特征。
通过研读中外 “睡美人”文献相关内容,结合可视化分析文献研究主题,发现现有研究主要集中在“睡美人”文献产生的原因、“睡美人”文献如何识别、如何唤醒等方面。对上述研究进行梳理与总结,有助于后续研究人员了解领域研究进展、发现新的研究视角,从而推动该研究领域的发展。

图1 “睡美人”现象研究的演进
1 睡美人文献产生原因
1.1 作者及发表期刊知名度
一般而言,作者知名度及期刊影响因子会在一定程度上影响该篇论文受关注情况。青年科学家学术成果不被业界认可现象屡见不鲜。同时,期刊水平高低也会对该篇文章受关注程度有所制约。排名靠前的期刊虽然关注度高,但由于期刊中论文质量高且审稿标准严格,往往会带来更多迟滞承认现象发生[19]。而排名一般的期刊由于关注度相对不高,一些发表在其中高水平文章也极易受到忽视。1968年,时年38岁的前苏联年轻学者Veselago在名为PhysicsUspekhi-Ussr的普刊中分析了同时具有负的介电常数和磁导率的均匀媒介具有什么样的电磁场性质,并提出了有关负折射、左手材料相关概念[20]。该理论在当时看来过于异想天开且由于作者知名度不高并未受到广泛关注便被忽略,直到1999年英国物理学家Pendry发明一种负折射材料才重新发现Veselago那篇具有超前理论的文章。
1.2 学术思想超前
多数“睡美人”文献集中存在于自然科学领域,尤以生命科学、物理、化学、数学等学科所占比重较大。究其原因,多因自然科学领域极易产生变革性思想,这些学术思想由于过于超前而不被同期学术界所认可。Glanzel[21]于2004年统计数据中得出,延迟承认论文中生命科学领域占比43%,物理领域占比22%,化学、工程、数学领域占比12%,这些学科易产生超前思想。如果论文的思想体系不能与当下权威学科范式相结合,极易被认为异想天开而被忽视。如上文所述Veselago案例,以及由 Einstein、 Podolski和Rosen于1935年发表的经典“睡美人”文献CanQuantum-MechanicalDescriptionofPhysicalRealityBeConsideredComplete?,该文提出了被后人称之为“EPR”悖论的量子力学概念,但由于概念超前,在论文发表近60年后才得到学术界认可并被大量引用。
1.3 学术共同体抵制 societies- commonly
Barber[1]于1961年提出,学术共同体对于未知事物、不确定方法、新的学科范式一般不会接受。2009年,Campanario[22]研究发现,有19位诺奖得主的研究成果曾遭遇学术抵制,24位诺奖得主的论文曾被期刊审稿人抵制。可见,即使诸如诺奖得主这样具有权威学术影响力的文章,也曾会因为早期观点与主流不合而遭遇学术共同体的抵制。以Smith于1970年发表在Nature的一篇关于超前蛋白质空间概念为例[23],由于观点超前,发表之初仅有3篇文章对此引用并且其中两篇是对文中的概念进行批判,直到1986年引文数量才得以上升并于2002年再次增长,得到业界承认。
学术论文发表与传播是一个复杂的过程,受多种因素影响。除上述原因之外,学术期刊的可获得性、文献撰写语言(主流或非主流)的可传播性,都有可能影响文献的发现与被认可时间,这些因素也有可能是“睡美人”文献产生的原因。
2 睡美人文献识别方法
目前,关于“睡美人”的主流识别方法可分为引文曲线拟合法、参数主观赋值法及无参数客观识别法。参数主观赋值法又可叫主观指标法,无参数客观识别法又可叫客观指标法。参数指标法主要包括三指标识别法、四分位数分布统计法、引文角度β识别法等,无参数识别法主要包括CS指数、B指数、SBc指数及Bcp指数等。
2.1 引文曲线拟合法
曲线拟合法通过将现有数据代入数学表达式或适当曲线来拟合单篇文献被引次数的年度分布情况[24]。
Avramescu[25]于1979年提出了5种引文曲线,如图2所示,横坐标t为论文年龄,纵坐标c(t)为论文被引频次。曲线①为“昙花一现”论文,发表即被承认,曲线先增后减,峰值较高;曲线②文章基本被认可,发表被承认,曲线先增后减,峰值较曲线①低;曲线③为几乎未被认可的文章;曲线④文章发表之初便被广泛认可但后期被认为为错误性作品;曲线⑤为“天才”型论文,从发表开始被引量一直递增。Avramescu用5种引文曲线对当时文章被引频次的变化现象进行解释,证实科学信息扩散模型的可靠性。在此基础上,2014年李江等[26]借助曲线拟合法基于341位诺奖得主构建引文曲线分析框架,并提出两种规则引文曲线和3种不规则引文曲线。如图3所示,a为经典引文曲线;b为指数增长曲线;c为双峰引文曲线;d为波形引文曲线;e为“睡美人”型曲线。
曲线拟合法通过引文曲线的变化发现文献的引文变化特征。优点为操作方便、计算简单,但针对于睡美人文献的识别,需人工观察每一条曲线,数据量大时,耗时耗力。
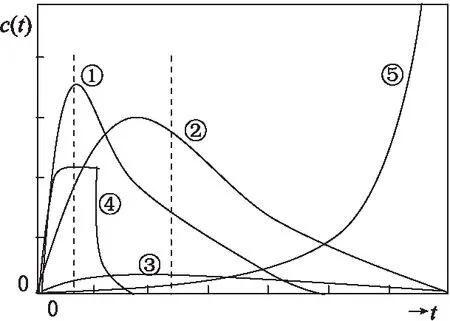
图2 A.Avramescu引文曲线示意图[25]

图3 李江引文曲线示意图[26]
2.2 参数主观赋值法
参数主观赋值法是通过人为主观设定参数的阈值来界定“睡美人”文献与其他文献的区别,主要包括三指标识别法、四分位数分布统计法及引文角β测量法等。
2.2.1三指标识别法
Van Raan[6]于2004年首次提出“睡美人”文献概念的同时提出三指标识别法,该方法是一种人为设定阈值的识别方法。三指标分别为睡眠深度、睡眠时长及唤醒强度,相关界定如下:①睡眠深度:即睡眠期年平均被引频数。年均被引最多1次(深度睡眠),年均被引1~2次(浅度睡眠)。②沉睡时长:从文章发表到唤醒时长,沉睡期至少为5年。③唤醒强度:论文被唤醒后4年间累计引文次数(自引除外),应超过20次。唤醒强度可划分为[21,30], [31,40], [41,50], [51,60] ,[>60]五个区间。
Van Raan通过对1980-2004年间近2 000万篇文章数据分析后提出睡美人文献识别方程:
N=f{s,cs,cw}:s-2.7.cs+2.5.cw-6.6
(1)
其中,s为沉睡时长,cs为睡眠深度,cw为唤醒强度。根据观察,总结出睡美人文献有如下特征:①睡眠时间越长,睡美人文献被唤醒的可能性越小。②对于浅度睡眠,睡眠时长对唤醒可能性影响较小。③唤醒强度较大的睡美人文献出现概率较低,且可能与睡眠深度与沉睡时长无关。
三指标识别方法在提出之初受到学界广泛认可,但随着研究的进展,这种基于平均值的计算方法弊端渐显。2012年,Calster[27]用实例验证了平均值算法的不足,指出该算法忽视了学科间差异性,未对唤醒期后的引用进一步研究,并且对于阈值的界定未经过科学的检验,不同阈值内的睡美人文献数量也会大有不同。此外,该方法忽略了“睡美人”苏醒之后的引用情况。
2.2.2四分位数统计法
四分位识别法由Costas等[28]于2010年在参照Aversa和Aksnes研究基础上提出[29-30]。该方法首先获取某篇文献达到总被引次数50%(Y50%)所用时间,其次统计该学科同年发表的全部文献达到各自被引50%所需要的时间并进行从小到大排序。前25%达到Y50%的最大值为P25,前75%达到Y50%值为P75,并将Y50%与P25、P75进行比较,结果如下:
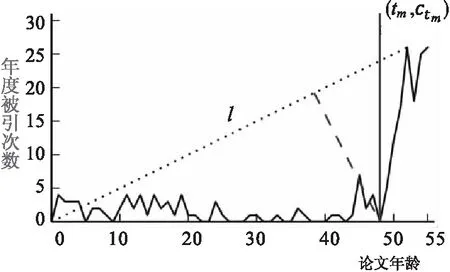
①Y50% 相较于三指标识别方法,四分位数统计法虽操作方法简单易懂但数据统计困难,且由于阈值设定门槛低,会有更多文献进入“睡美人”候选范围,存在范围不精准现象。但该方法仍然在对“睡美人”文献的识别中具有借鉴意义[31],可以将该方法作为识别“睡美人”文献的第一步,并对后续的识别工作有所改进。 2.2.3引文角β测量法 张家榕等[9]于2017年提出引文角β测量法用于统一测度“睡美人”文献和“昙花一现”文献,如图4所示。该方法将(0,0)点定义为论文发表的前一年时间点,横轴为时间,纵轴为引文数量,将零点与引文高峰点间的连线设为l,引文角即为l与横坐标的夹角。 图4 引文角β测量法示意图[9] th为时间窗口中的点标记,t1为“昙花一现”文献引文峰值时间(t1 βm=arctan(cm/tm) (2) 当β1>>β2时,易于产生“昙花一现”型文献,β1≪β2时,易于产生“睡美人”文献。张家榕等将时间窗口最小值设定为10年,即t2-t1≥10,将t2-t1这时间段年均引文量设为AC,t 该方法结果受时间窗口大小、AC值、Ca值、Cb值影响较大,主观设定缺乏一定依据,且arctan(x)函数值随角度变化不均匀,具有敏感度不高的缺点[32]。 以上论述为目前对“睡美人”文献识别应用较多的几种参数识别方法。参数识别方法简单、易于理解,但由于阈值的设定具有强主观性且缺乏一定的科学依据。阈值设定的大小将决定睡美人文献数量的多少,阈值大则“睡美人”文献数量过多,不符合“睡美人”文献稀缺的特点,阈值设定过小,则会缺失对许多“睡美人”文献的识别。同时,参数识别法忽视不同学科间差异,用同阈值测算不同学科有失偏颇。 无参数客观识别法消除了人为主观对参数阈值的设定,通过综合考虑文献的相关引文数据来对睡美人文献进行判定。无参数识别法主要包括被引速率(Citation Speed,CS)[33]、B指数[34]、SBc指数[35]、Bcp指数[16],以及后续出现的Gs指数[36]、Da指数[37]、K指数[38]、DR指数[39]、Cc指数[18]等。 2.3.1被引速率CS指标 CS指标由Wang[33]于2013年提出,是指一篇文章自发表后以多快的速度达到其总被引次数。对于“昙花一现”型论文,自发表之后累计引文量快速上升,但随时间推移,曲线趋于平缓;“睡美人”型文献在发表之初曲线趋于平缓,后期引文累计量迅速增长,曲线斜率逐渐增大。如图5所示,曲线A为延迟承认的“睡美人”文献曲线,曲线B为即时承认的“昙花一现”型曲线[40]。被引速率计算公式如下: 图5 被引速率CS示意图[40] (3) Ci为该篇论文第i年累计引用次数,n为时间窗口大小,Cn为第n年累计被引次数。CS值位于(0,1)之间,值越小,说明该论文累计引文次数增长越慢,“睡美人”文献可能性越大,反之相反。Wang基于此种方法测度了短期内(31年)引文曲线的变化,预测论文长期引文的可行性及随着研究领域、文献类型、总引文数的不同、引文老化程度有何不同等问题。杜建等[40]通过引文轨迹特征和累计被引速率两方面验证2014年诺贝尔化学奖得主S. Hell论文是否为“睡美人”文献,并对该文献的唤醒原因进行分析。 2.3.2 B指数识别法 B指数即“美丽指数”,Ke等[12]于2015年提出。如图6所示,以横坐标表示论文发表时长,纵坐标表示年度被引次数。论文发表年被引次数点为(0,c0),引文峰值年被引次数点为(tm,ctm),l为(0,c0)与(tm,ctm)间连线,ct为文章发表后第t年的年引文数,参考线l及B值公式如下: (4) (5) 图6 B指数示意图[12] 当论文发表当年便达到引文峰值时,B=0。B值越大,“睡美人”文献可能性越强。基于B指数可以从更广泛角度考虑“睡美人”文献的识别,突破人为设定时间阈值的局限。但由于B指数仅考虑发文时到被引峰值这段期间引文量的变化,未考虑达到峰值之后的引文走势,且B值受被引总数影响较大,当“睡美人”文献被引总数偏少时,不能对“睡美人”文献进行准确的识别。 2.3.3 SBc指数识别法 考虑到B指数对于总被引频次较低的文献识别不敏感的缺陷,Peruzzo于2015年提出SBc指数[35]。如图7所示,与B指数相同的是,横坐标为论文发表时长,论文发表年被引次数点为(0,c0),引文峰值年被引次数点为(tm,ctm),l为(0,c0)与(tm,ctm)间连线,ct为文章发表后第t年的年引文数。与B指数不同的是,纵坐标为论文年度累计被引次数。SBc公式如下所示: (6) (7) SBC=max△tSB(△T) (8) 图中c点为引文累计峰值最大点,△t为论文发表时长变化,m(△t)为参考线l斜率,对于任意t 图7 SBc指数示意图[35] SBc指数在B指数基础上能对总被引频次较低的文献进行很好的识别,但是同B指数一样,对总被引频次依赖较大。也就是说,只要总被引频次越高,SBc值便越大,对于一些瞬间引文激增的现象不能做出很好的解释。 2.3.4 Bcp指数识别法 杜建等[16]在综合B指数和SBc指数的基础上,于2017年进一步提出Bcp指数。如图8所示[41],横坐标为论文发表时长,纵坐标为论文年度被引频次累计百分比。论文发表年被引次数点为(0,c0),论文被引频次累计百分比最大值点为(tm,1),两点间的连线为参考线l,参考线与引文曲线对应年度间差值(lt-ct)的累计值即为Bcp指数,具体计算公式如下: (9) 图8 BCP指数示意图[41] Bcp值取决于累计引文的曲线形状,值越大,“睡美人”文献特征越明显,并且Bcp值可以应用于不同学科进行测算。对年度被引次数累计百分比曲线上各点向l参考线做垂线,所得距离记作d(t), 该距离最大时的时间定义为觉醒年,记作taw,d(t)计算公式为: (10) 觉醒年通过某篇论文整个生命周期来计算,也就是说,觉醒年并不一定是年引用次数最少的,并且Bcp值并不依赖论文总引用数,即使一篇文章在时间观测窗口内被引次数较少,但依然能对“睡美人”文献进行有效识别[42]。 除上述所述几种方法外,也有不同学者根据引文时间窗口、睡眠时长、总被引频次、累计被引频次等维度相继提出Gs指数、Da指数、K指数等如表1所示。 综上所述,无参数识别法可以避免人为设定阈值的主观因素影响,同时可以考虑不同学科间差异,对“睡美人”文献识别准确度更高。但对于复杂的公式计算较困难,且对于“睡美人”文献、“昙花一现”型文献、“全要素睡美人”文献及常规文献并没有明确的界限对其进行划分。或许基于此,未来对于睡美人的识别工作更应注重多种方法结合使用。 表1 “睡美人”文献无参数识别指数 睡美人文献均有“王子”来唤醒,但就目前国内外研究而言,对于“王子”文献并没有一个明确的定义。“王子”文献的概念最早由Van Raan[6]提出,用于对“睡美人”文献的识别。Van Raan将“王子”文献定义为在睡美人沉睡期结束后,首次对该文献进行引用即为“王子”文献。但不同的学者提出不同的意见。如Huang[43]将“王子”分为两类,一类为“关键词王子”,一类为“h指数王子”,“王子”定义为使得“睡美人”受到更多关注的文献;Braun[44]认为“王子”文献应具有“睡美人”文献沉睡后首次引用、具有高被引次数、与“睡美人”文献共被引达一定次数这三个特点;Ohba[45]等对“睡美人”觉醒前后的文章进行搜索,认为“王子”文献应促使后续相关作品引用该“睡美人”文献,并且王子与睡美人间的共被引频次应超过30%;杜建等[46]强调“睡美人”文献与“王子”文献共被引要超过10%,并且还发现“王子”文献更多发表在有较高声望的期刊上。同时杜建等[47]还指出“王子”文献应满足发表于“睡美人”文献被引频次激增附近的年份、被引频次较高、与“睡美人”文献共被引频次高、对“睡美人”文献的被引频次增多起到极大推动这四个特征。A.A.C. Teixeira等[38]使用共被引模式对“王子”文献进行识别,他们将王子分为“主要王子”和“辅助王子”,“主要王子”和“睡美人”文献具有大量的被引频次和共被引次数,“辅助王子”为虽有超过10次共被引频次但是自身被引频次及共被引频次均较低。王春宝等[48]为完善“王子”文献识别体系,提出采用王子系数Pr进行量化识别。 总体来看,“王子”文献应具有以下特点:①在“睡美人”文献发表后发表。②自身即为高被引文献。③对“睡美人”文献被引频次的增长起着明显带动作用。④与“睡美人”文献具有较高共被引次数。 早期研究人员对“王子”文献关注角度集中于科学论文,即“科学王子”。近年来,“睡美人”文献在被“科学王子”唤醒的同时, Van Raan等[49-50]研究发现,“睡美人”文献越来越早被专利,即“技术王子”所唤醒,而非“科学王子”,专利对于“睡美人”文献的唤醒作用在逐步增强。Van Raan[51]对1992-1994年在物理、化学、计算机等领域“睡美人”文献进行整理并分析专利对其引用情况,发现专利中的“睡美人”文献远多于“普通”文献。后续研究中,Van Raan与Winnink[50]对SB-SNPRs(即专利中引用的睡美人非专利参考文献)的出版年份和首次被专利引用年份进行统计,发现文章发表年份与专利首次引用年份时间差越来越短,表明近些年“睡美人”文献更多被“技术王子”唤醒而非“科学王子”。通过对医学领域杂志研究,Van Raan等[52]进一步发现,在“睡美人”文献被唤醒前,专利对“睡美人”文献的引用呈指数增长,表明技术时滞比文献睡眠时间更短。杜建等[23]对1970-2005年间发表在Science和Nature的78 403篇文章进行研究后发现,与即时识别论文相比,延迟识别论文显示出更强和更长的技术影响;最近几年,被延迟承认的论文经专利唤醒的次数越来越多,时间也越来越早,而不是被科学论文唤醒。随着近年来专利申请数量的稳步上升,专利中的包含的潜在价值愈发值得各领域学者深度挖掘。“技术王子”对于“睡美人”文献的唤起,必将成为一个热点议题。 如上文所述,“王子”唤醒“睡美人”需要具有较高共被引频次且“王子”本身也应具有高被引频次,但是这种主观阈值的界定没有明确的标准。同时,对于王子文献及王子专利的识别,不同学科具有较大的差异性,须有该学科的专业背景知识的学者才能对此进行更精确的判断。 “睡美人”文献中多包涵变革式的研究思想、突破性的理论创新、新的学科范式及跨学科的综合研究成果,对睡美人文献的识别有利于识别领域前沿预测未来技术发展方向、有利于追踪技术转化、有利于识别潜在技术与应用属性、有利于加强政策研究评价。因此,“睡美人”文献的精准识别是科技发展过程中重要一环。科学中的“睡美人”文献这一现象是通过信息科学研究引文随时间流动的一种很好模式,目前各方面研究均取得一定进展。但“睡美人”文献形成及唤醒机理的研究仍缺乏系统性与完整性,睡美人文献的预测方法或综合模型等核心问题尚未解决,不同学者的研究所用样本相对整个大科学体系学科领域单一且数据量较小,尚未形成系统的理论体系,未来的研究应重点关注以下几个方面: a.“睡美人”识别理论有待进一步探索,从已有研究成果来看,参数识别具有较强主观因素,无参数识别又不能很好划分“睡美人”文献与其他文献间差异。而对于曲线拟合观测曲线引文变化进行“睡美人”文献的判定,存在一个问题,对于一篇文献发表之初被引频率在其所在领域已达一个高频次,后来由于某种原因被引频次激增,这种文献又是否可被划分为“睡美人”文献? b. “睡美人”文献除了王子出版物的唤醒机制,作者本身自引或随作者知名度的提高,学界开始从新重视该作者前期研究成果,这种睡美人自醒现象也值得关注。并且唤醒睡美人的王子或许并不止一个,一个王子也可以亲吻多个睡美人,这也将成为本方向今后关注的重点。 c.专利被视为技术上的创新,通过对专利中“睡美人”文献的挖掘,有助于研究人员从技术角度探索“睡美人”文献的唤醒机制。近年来研究也表明,专利对于“睡美人”文献的唤醒效果强于科学论文,以此为切入角度不仅有利于探讨知识的流向及科学与技术间互动模式,而且有助于探索领域前沿及变革性的技术创新,进而缩短对重大科学发现的认可时滞。 d.科学术语的规范问题也值得思考,作者在CNKI数据库以“睡美人文献”作检索词出现大量与科学计量学无关文献,在WoS(Web of Science)数据库检索“Sleeping Beauties”多为生命科学及医学领域文献。虽然“睡美人”文献冠以童话般寓意,但对于知识的查找和学术的传播所带来的影响依然值得深思。从学术规范用词的角度考虑,“迟滞承认”一词更能直观揭示引文流随时间变化的现象,也显得更加贴切。 e.现有研究多是基于文献被引现象来研究“睡美人”文献,且多以Web of Science平台为数据源。受数据库自身局限,如数据库收录期刊数量的限制、期刊所属国别地区、学科及语种选择等因素影响,单一数据源在分析复杂的引文关系中缺乏广泛的代表性。因此,仅依靠单一数据源的引文数据来研究“睡美人”文献现象会存在一定不足。近年来,Scopus、Lens与 GoogleScholar等网络引文分析数据库的出现为引文分析提供了新的选择,后续研究可考虑多源数据的应用。 Burrel[53]曾质疑说睡美人是否是一个基于引用过程的随机模型,在随机模型下,“睡美人”的现象是必然发生的,而对于那些离群的样本似乎很难用模型来解释。但作者认为,文献计量学的意义就在于通过对文献间内在联系的探索找到其潜存的规律,对代表知识和学术成果的文献进行分析与评价并做出独立的判断。任何评价方式都会存在其局限性,而如何将这种局限性限制到最低进行客观精准的识别评价,这也是做计量最重要的初衷所在。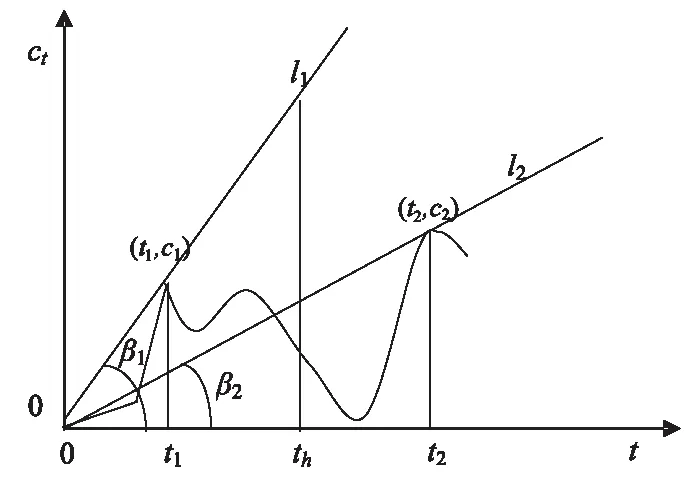
2.3 无参数客观识别法




3 “王子”文献及唤醒机制
4 总结与展望
猜你喜欢
儿童时代·快乐苗苗(2022年8期)2022-10-18商用汽车(2021年4期)2021-10-13临床骨科杂志(2020年1期)2020-12-12阅读与作文(小学高年级版)(2020年8期)2020-09-12制造技术与机床(2019年9期)2019-09-10制造技术与机床(2019年4期)2019-04-04军事运筹与系统工程(2016年3期)2016-09-26探测与控制学报(2015年4期)2015-12-15科技视界(2014年25期)2014-04-27小猕猴学习画刊(2013年1期)2013-03-19
