
基于改进GRU的白酒蒸汽运行预测模型研究
2022-12-03 10:18张子蓬
湖北工业大学学报 2022年4期
张 杰,张子蓬
(湖北工业大学计算机学院,湖北 武汉 430068)
中国白酒文化源远流长,采用纯粮谷类作物固态发酵酿造工艺[1]的中国白酒也是世界六大蒸馏酒之一,酿造好品质白酒的核心工艺是蒸馏,而上甑工艺[2]的好坏直接决定了蒸馏出白酒的质量。目前白酒蒸汽状态还处于依靠检测的方法,无法避免酒损。因此,准确地预测白酒蒸汽状态具有显著应用价值。然而白酒蒸汽状态的变化受多种因素的影响,给白酒蒸汽状态预测带来很大的困难,同时也使其成为具有重要意义的工业问题。
近年来,部分酿酒企业开始采用上甑机器人进行上甑操作,其中武汉奋进智能机器有限公司首创了定制化上甑机器人[3]。机器人在探汽上甑过程中,需要时刻通过红外热成像仪获取白酒蒸汽红外辐射来监测白酒蒸汽的运行状态,通过铺料上甑来阻止白酒蒸汽跑出。目前机器学习技术已经常被用于许多个领域,其中基于机器学习的模型在蒸汽类预测中也获得了一些不错的效果,比如有:支持向量机回归(SVM regression)[4]、决策树回归(Decision Tree regression)[5]、随机森林回归(Random Forest regression)[6]、人工神经网络回归(ANN regression)[7]。其中,人工神经网络可以模拟人脑神经元进行工作,常被使用在各种复杂工作场景下进行预测。在蒸汽预测中,陈小强等[8]提出了一种基于GMDH神经网络的超临界机组的过热蒸汽温度预测模型,与线性神经网络和BP神经网络相比,预测精度有显著提升。朱清智等[9]使用混沌搜索策略鲸鱼优化算法(CAWOA)和并行极限学习机(PELM)对主蒸汽流量进行预测,获得了较好的预测效果。谢七月等[10]介绍了基于改进自适应GPC的锅炉主蒸汽温度预测控制方法,相较于常规PID方法和GPC方法,对蒸汽温度的预测取得了很好的效果。Valsalam等[11]使用卡尔曼滤波方法优化了锅炉电厂的主蒸汽温度预测模型。刘祥杰等[12]提出了基于NFGPC模糊神经网络的非线性广泛预测模型对过热蒸汽温度进行预测。Golob等[13]使用神经网络模型预测了锅炉蒸汽的分布。Nguyen等[14]提出了基于LSTM神经网络模型和自动优化参数方法对蒸汽相关的时间序列数据进行预测。Alizamair等[15]使用多种机器学习模型和多种神经网络模型对不同深度土壤温度进行预测。Delcroix等[16]使用具有外源变量的自动回归神经网络模型对建筑物室内温度进行预测。Asmaa等[17]使用LSTM对温室作物的内部气候变化进行预测。。
在以上研究中,大多使用人工神经网络等模型实现蒸汽预测。而且对于白酒蒸汽状态预测的方法缺少其他机器学习模型和深度学习模型的研究,比如门控循环单元模型(Gate Recurrent Unit)[18]。门控循环单元模型具有记忆神经元,能同时记忆短期行为和长期行为。这种模式使得门控循环单元很适合模拟自然过程的行为。同时,梯度提升树(Gradient Boosting Decision Tree)是基于梯度下降算法[19],使用多个弱学习器加权求和组合成一个强学习器,这种集成学习的模式使得梯度提升树在各个领域的预测研究得到普遍的使用。同时,白酒蒸汽状态的特征因子很多,如:空气湿度、酒醅湿度等,目前基于机器学习模型的特征因子重要性研究评估还没有展开,另外在预测模型中各种蒸汽状态特征因子的不同组合会高度影响预测模型的预测能力。
本文使用茅台酒厂上甑机器人工作数据进行实验,首先基于梯度提升树计算白酒蒸汽状态预测中每个特征因子的重要性大小,然后依此对特征因子进行多种组合,最后将各种特征因子输入预测模型,本文使用梯度提升树改进的门控循环单元作为蒸汽状态预测模型,通过不同因素组合的最终预测性能来确定最终的重要特征因子集合。
1 研究现状
本文在茅台酒厂进行了测试。在上甑机器人(图1)上下载了两秒一采样的半年数据(2020年1月1日至2020年6月30日),其特征因子分别为酒醅表面温度(Surface Temperature),酒醅相对湿度(Relative Humidity),酒厂环境温度(Ambient Temperature),甑桶内酒蒸汽气压(Steam Pressure),机器人辅料速度(Loading Speed),甑桶出酒量(Wine Yield),甑桶出酒速度(Production Speed),其中酒醅表面温度是通过红外热成像仪在距甑桶顶70 cm处得到。茅台镇是我国重要的酱酒圣地,镇内资源奇特,微生物体系奇异,具有得天独厚的酿造环境,以盛产美酒而闻名海内外,被誉为中国第一酒镇[20]。茅台镇属于亚热带季风气候,全年冬暖夏热,高温少雨,平均气温为18℃,夏季最高温度为40℃,这种特殊气候十分有利于酿造酱酒微生物的栖息和繁殖,核心产区内多达百余种微生物参与了酱酒的酿造过程。并且酒厂环境温度、酒醅相对湿度对这些微生物在参与上甑蒸馏的酿造过程的蒸汽生成有很大影响,而目前白酒蒸汽状态还依靠检测,无法避免酒损,故白酒蒸汽预测对于白酒的酿造具有重要意义。

图1 上甑机器人结构图
本文主要研究两个问题:
1)对于白酒蒸汽状态预测时,每个特征因子的功能是不一样的,白酒蒸汽状态与每个特征因子和其组合之间的关系是怎样的?
2)白酒蒸汽状态预测是一种多维时间序列预测,什么样的算法适合白酒蒸汽变化的规律?
面对以上疑问,本文提出了改进的门控循环单元融合模型(图2)。对于多个上甑过程中的特征因子,不同的特征因子与白酒蒸汽状态之间的相关性不一样。先使用GBDT对每个特征因子进行重要性排序,对于排序后的特征因子,根据重要性来完成不同的组合,然后输入门控循环单元模型,找到预测效果最优的特征因子输入组合,最后基于门控循环单元模型分析白酒蒸汽状态与其特征因子之间的关联,得到预测结果。
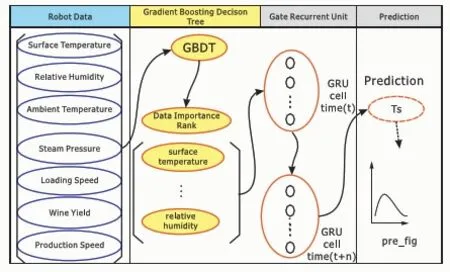
图2 改进的GRU模型的白酒蒸汽状态预测流程图
2 基于改进的门控循环单元的白酒蒸汽运行状态预测模型
2.1 改进的门控循环单元模型
门控循环单元模型(GRU)是一种结构简单,性能优良的循环神经网络。具有记忆神经元的GRU可以同时记忆白酒蒸汽状态与特征因子间的短期行为信息和长行为期信息。循环神经网络可以让输入信息在神经元里被保存下来,但这种保存是无目的性的,且会产生梯度消失和梯度爆炸问题,因此后来出现了LSTM[21],有针对性的将重要信息记忆下来,不相关信息遗忘,这个过程通过LSTM的3个门函数:输入门,遗忘门和输出门来确定输入值,遗忘值和输出值,这样就一定程度解决了循环神经网络的序列训练过程中的梯度爆炸和梯度消失问题,多用来进行时间序列的预测。
GRU的发展借鉴了LSTM神经网络的门结构,与LSTM相比,GRU神经网络的结构更简单,效果也不错,GRU模型通过两个门函数:更新门和重置门完成和LSTM相似的过程,其中更新门值和重置门值的大小与上一时刻状态信息权重正相关,门控制信号的范围是0~1,更新门值越接近1,则上一时刻记忆下来的信息越多,反之则遗忘的信息更多,重置门值越接近0,则上一时刻信息遗忘的越多,从模型复杂度上来看,长序列训练过程中需要适当遗忘一些信息,否则模型复杂度会增加,模型计算时间也会变长。GRU模型结构如图3所示,其中,Xt是t时刻的输入,ht是t时刻的输出,zt是t时刻的更新门,rt是t时刻的重置门,σ是sigmoid函数,tanh是双曲正切函数,⊗表示两个矩阵的张量积,⊙表示两矩阵对应位置元素相乘。

图3 门控循环单元模型结构图
更新门zt:用于确定上一时刻的状态信息在当前状态ht中的权重大小,通过sigmoid函数将数据变成0~1之间的数值,表示更新门控信号,越接近1说明上一时刻信息带入的越多,即:
zt=σ(WzXt+Uzht-1+bz)
重置门rt:用于确定前一时刻的状态信息在当前状态下遗忘的的权重大小,通过sigmoid函数将数据变成0~1之间的数值,表示重置门控信号,越接近0说明上一时刻信息遗忘的越多,即:
rt=σ(WrXt+Urht-1+br)
得到门控信号后,使用重置门确定上一时刻状态信息ht-1要遗忘的状态信息权重,然后将重置之后的数据与当前的状态信息输入xt拼接,再一起输入tanh激活函数将数据变成-1~1之间的数值,即:
最后在GRU中进行状态信息的更新操作,使用求得的更新门控信号zt,对历史状态信息和当前状态信息同时进行重置和更新两个步骤,其中(1-zt)*ht-1表示对历史状态信息选择性遗忘,zt*ht-1表示对当前状态信息选择性记忆,通过一个更新门控zt使遗忘和记忆始终处于一种稳态,即:
梯度提升树模型(GBDT)是一种基于Boosting思想的集成学习模型,迭代地使用多个弱学习器加权求和组合成一个强学习器,将每一步的残差训练成下一轮的弱学习器,串行训练以获得较高的精度,误差小于给定阈值时停止训练,以优化预测效果。本文使用梯度提升树算法计算特征因子在本模型的贡献率,从而评估该特征因子对于模型的重要性。流程为:首先求出特征因子a对于一个弱学习器的重要性,原因是当特征因子a作为每一轮弱学习器生成条件,若模型损失函数值变化越大,说明该特征因子越重要,N-1是非叶子节点,qi是与节点i关联的特征因子,计算得到特征因子a的损失值,将每个平方损失值累加起来,得到每一个弱学习器中特征因子a的重要性。然后计算特征因子a对于整个强学习器的影响程度,对每个含有特征因子a的弱学习器的重要程度求和,然后求均值。对每个特征因子进行上述操作,得到所有特征因子的重要性排序,对于排序后的特征因子,根据重要性来完成不同的组合:
2.2 模型预测实验
2.2.1数据采集本文选取酒厂上甑机器人上甑过程相关数据,采集茅台酒厂某车间1号上甑机器人半年的上甑数据,约八万个样本。本文数据集按照时间顺序将样本划分为训练集、验证集和测试集,划分比例为7∶2∶1,54 600条数据作为训练集,15 600条数据作为验证集,7800条数据作为测试集。
均方根误差:
平均绝对误差:
可决系数:
按照时间顺序将样本划分为训练集X_train、验证集X_val和测试集X_test,划分比例为7∶2∶1。
2.2.2搭建门控循环单元神经网络模型本文改进的门控循环单元网络中的超参数有每一批训练个数、训练轮数,每一层隐藏层神经元个数、舍弃率、学习率、特征因子的选取,这些超参数都和预测性能高度相关。在确定门控循环单元个数时,初始化每一批训练个数100,训练轮数150,学习率0.001,舍弃率0.5,选取特征因子有酒醅表面温度,酒醅相对湿度,甑桶内酒蒸汽气压。选取[16,32,64,128]来分别测试门控循环单元神经元个数,进一步确定最优的门控循环单元的神经元个数,然后用相同的思想来通过选取[50,150,200,250,300,350,400]进而来确定最优的每一批训练个数,然后再从[50,250,350,450,550,650,800]选取最优的训练轮数,从[0.0001,0.00001,0.000001]中选取最优的学习率,从[0.4,0.3,0.2,0.1]中选取最优的舍弃率。将以上超参数确定之后,也确定了门控循环单元预测模型的最优结构。下一步对特征因子进行选取测试,根据梯度提升树算法模型计算每个特征因子(酒醅表面温度,酒醅相对湿度,酒厂环境温度,甑桶内酒蒸汽气压,机器人辅料速度,甑桶出酒量,甑桶出酒速度)的重要性值大小,然后依此对特征因子进行各种组合,然后输入门控循环单元预测模型中,根据预测结果判断哪些特征因子组合对白酒蒸汽状态预测的影响更大。其中,门控循环单元预测模型输入特征的维度(input_dim)是特征因子的个数。本文选取茅台酒厂上甑机器人上甑过程相关数据进行实验,门控循环单元神经元个数(node_size),训练轮数(train_epoch),每一批训练个数(batch_size),学习率(learning_rate),舍弃率(dropout)的预测结果见表1-表5。

表1 神经元个数对于白酒蒸汽状态预测结果

表2 训练轮数对白酒蒸汽状态预测结果
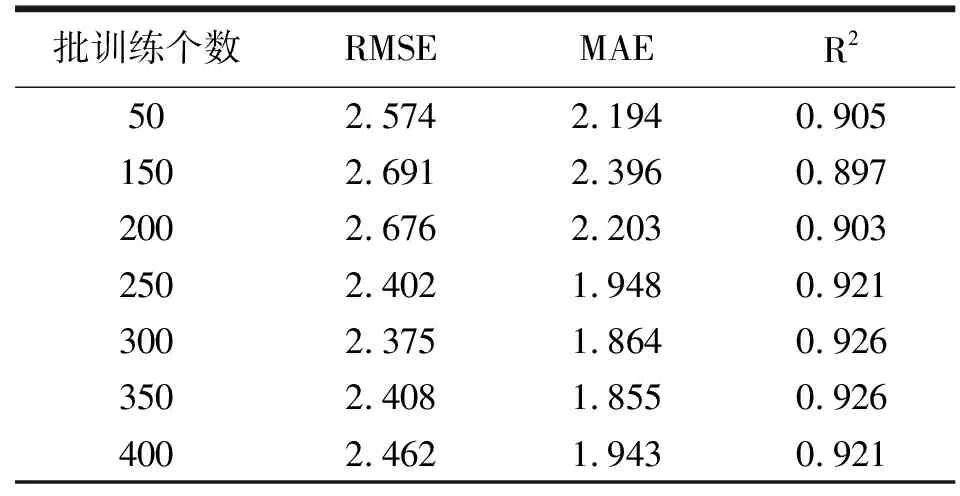
表3 每一批训练个数对白酒蒸汽状态预测结果
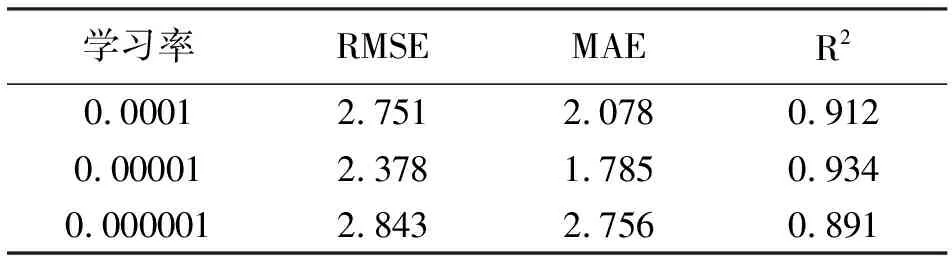
表4 学习率对白酒蒸汽状态预测结果

表5 舍弃率对白酒蒸汽状态预测结果
根据表1观察得到,不同的超参数构建的模型的预测能力也是不同的,当神经元节点个数过多时容易使模型产生过拟合,即偏差小、方差大,模型弱化了对新数据的预测能力,而当神经元节点过少时就容易使模型失去一定的拟合能力,进而不能准确表现出白酒蒸汽状态与其他特征因子之间的相关性,当神经元节点个数为32时,模型预测最优;根据表2观察得到,训练轮数过小会让模型不能收敛,训练轮数过大会使模型产生过拟合,同时预测能力不再变高,当训练轮数为650轮时,此时模型预测最优;类似的,根据表3观察得到,每一批训练个数决定了一次处理多少的训练样本信息,批次处理量过小会使模型无法收敛,当批次处理个数为350时,模型最优;根据表4观察得到,当学习率过小时收敛过程十分缓慢,且容易陷入局部最优,当学习率过大时容易在最优值附近来回震荡,当学习率为0.00001时,模型最优,由此得到最优模型主要超参数,进而也得到了门控循环单元预测模型结构。
2.2.3模型选取特征因子在确定门控循环单元预测模型结构后,进一步分析不同特征因子的组合对模型的预测效果,改进的门控循环单元模型的整体数据处理流程见图2,首先计算得到所有特征因子的重要性(图4)。在使用梯度提升树计算特征因子时,对梯度提升树模型的三个重要超参数(学习率(learning_rate),回归树的个数(sub_tree),每棵独立树最大深度(max_depth))进行相应的损失减少值测试,方便确定最优参数,经过计算如表6所示,确定超参数取值(加粗为最优超参数)。
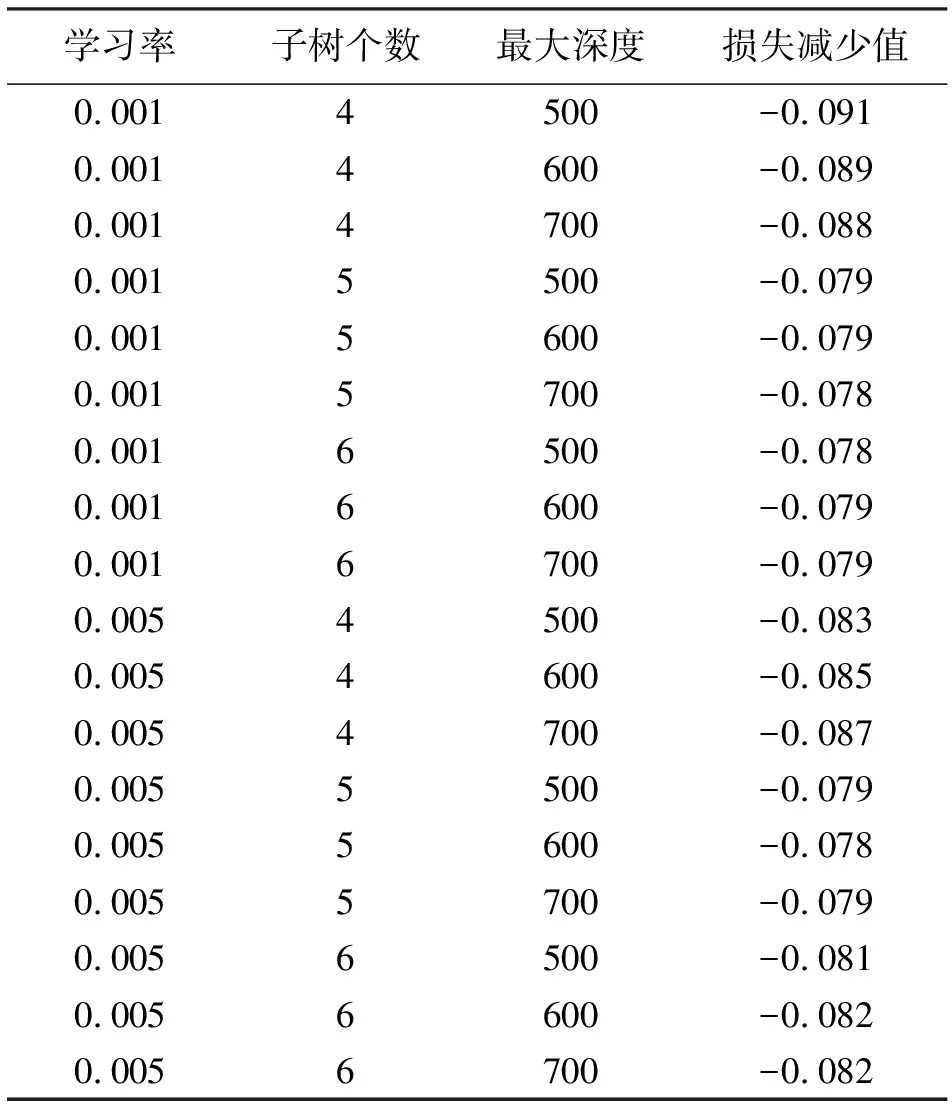
表6 各种超参数的梯度提升树对比

图4 特征因子重要性
根据实验分析得到,特征因子按照其重要性降序排序为:酒醅表面温度、酒厂环境温度、甑桶内酒蒸汽气压、机器人辅料速度、甑桶内酒蒸汽气压、甑桶出酒速度、甑桶出酒量。按照特征因子的重要性依次组合出预测模型的输入:酒醅表面温度(input_1),酒醅表面温度+酒厂环境温度(input_2),酒醅表面温度+酒厂环境温度+甑桶内酒蒸汽气压(input_3),酒醅表面温度+酒厂环境温度+甑桶内酒蒸汽气压+机器人辅料速度(input_4),酒醅表面温度+酒厂环境温度+甑桶内酒蒸汽气压+机器人辅料速度+甑桶内酒蒸汽气压(input_5),酒醅表面温度+酒厂环境温度+甑桶内酒蒸汽气压+机器人辅料速度+甑桶内酒蒸汽气压+甑桶出酒速度(input_6),酒醅表面温度+酒厂环境温度+甑桶内酒蒸汽气压+机器人辅料速度+甑桶内酒蒸汽气压+甑桶出酒速度+甑桶出酒量(input_7)。使用改进的门控循环单元预测模型对以上的各种组合进行测试,来确定最优的特征因子组合,如表7所示。由测试得到,使用酒醅表面温度、酒厂环境温度和甑桶内酒蒸汽气压的组合输入,能够让模型的预测效果最优。
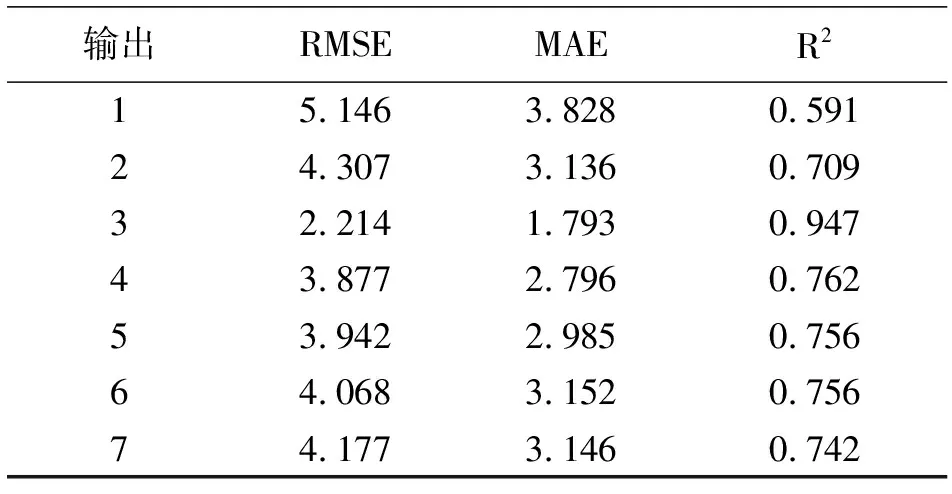
表7 特征因子组合的预测结果
2.2.4不同模型效果比较本文模型与几种常见模型进行了比较,如表8所示。本文模型与其他模型相比,RMSE,MAE均更小,可决系数更大。因此,本文的方法在白酒蒸汽状态的预测中是优于其他模型的。

表8 本模型与常见模型结果比较
4 结束语
本文提出了使用梯度提升树改进的门控循环单元预测模型,来实现白酒蒸汽状态的预测,目前白酒蒸汽状态还处于依靠检测的方法,无法避免酒损,因此,白酒蒸汽预测对于白酒的酿造意义重大。本文模型基于茅台酒厂上甑机器人上甑数据进行训练和测试,首先使用梯度提升树计算白酒蒸汽状态预测中每个特征因子的重要性大小,然后依此对特征因子进行多种组合,最后将各种特征因子输入预测模型,本文中使用门控循环单元作为预测模型,根据各种特征因子组合的预测效果来确定最重要的特征因子。实验结果表明:本文提出的改进的门控循环单元模型与常见预测模型相比,预测效果更优。由于数据采集限制,本文主要是对2020年1月1日至2020年6月30日的半年数据进行分析,全年不同月份气候对预测模型性能的影响还需要进一步探索。
猜你喜欢
西北林学院学报(2022年5期)2022-10-04
酿酒科技(2022年4期)2022-05-05
科学文化评论(2021年5期)2021-04-23
支点(2020年11期)2020-11-20
中等数学(2020年1期)2020-08-24
人民交通(2020年2期)2020-04-16
特别文摘(2019年1期)2019-02-28
华人时刊(2018年17期)2018-11-19
军事文摘·科学少年(2017年1期)2017-04-26
陕西画报(2016年1期)2016-12-01
