
融合分区导向搜索与自适应扩散的新型Lichtenberg算法
2023-02-28 09:19李永钰
计算机工程与应用 2023年4期
李永钰,马 良,刘 勇
上海理工大学 管理学院,上海 200093
目前智能优化算法发展迅速,出现了许多具有代表性的优化算法。其中,受生物学原理的启发提出的群体智能优化算法是一类较为常见的优化算法,它们是从自然界群居生物的觅食、繁殖等行为或群体捕猎及生存策略中获得灵感,设计模型对问题进行求解的优化算法,例如蚁群优化算法、粒子群优化算法、鲸鱼优化算法和哈里斯鹰优化算法等。自上述算法提出以来,众多学者针对其不足提出改进,并将其应用于解决不同类型的优化问题[1]。例如文献[2]将粒子群优化算法进行改进,并应用于关联规则挖掘领域;文献[3]利用改进群智能优化算法,进行全局域中混沌局部的同步搜索,实现海上物流配送路径优化。
此外,还有受物理学原理的启发提出的优化算法。模拟退火算法就是一个经典的基于物理学原理的优化算法,其核心思想是模拟金属热浴之后的缓慢降温(退火)达到能量最低态(即常温固态)的过程,以随机“跳阱”策略克服局部搜索法的缺陷,搜索优化问题的全局最优解[4];引力搜索算法是受到牛顿万有引力定律的启发而提出的优化算法,其让种群粒子具有质量,且质量根据粒子的适应度值进行计算[5];随机分形搜索算法利用分形的扩散特性进行寻优,算法的扩散过程采用高斯随机游走方式来开发问题的搜索空间,而更新过程则分别对个体的分量及个体本身采用相应的更新策略来进行更新,以此进行全局搜索和局部搜索[6]。随着求解的问题逐渐呈现出大规模、高难度和不确定性等特点,近年来不断有新型智能优化算法提出,用于解决不同类型的优化问题。
Lichtenberg 算法(Lichtenberg algorithm,LA)是由Pereira等人于2021年提出的一种新型智能优化算法[7],它是受闪电传播这一物理现象启发而产生的,算法以Lichtenberg 图形(Lichtenberg figure,LF)来模拟闪电在空中生成的图形。LF是分形图的一种。与其他基于物理学原理的智能优化算法相比,LA算法具有概念简单、容易实现等优点。
目前,对LA算法的研究还处于起步阶段。文献[7]将LA算法应用于对复合材料机械结构的复杂逆损伤问题进行识别和评价,将其与遗传算法和向日葵优化算法进行对比。实验证明,LA算法可以有效地识别损伤,而且即使在噪声响应低和损伤严重性大的特定情况下,它也能够检测到损伤。文献[8]首次将LA 算法应用于识别薄板类结构裂纹的问题,用LA 算法生成表征裂纹的变量,若存在裂纹,则识别其扩展方向和强度。实验结果表明LA算法在表征边缘裂纹的扩展方向和强度方面展现出了优异的效果。文献[9]使用LA 算法对假肢结构模型参数进行优化,并与粒子群优化算法进行了对比,验证了LA算法的优良性能。不仅如此,假肢结构还可以根据用户需求进行制造和使用,并且可以利用LA算法分析各参数对假肢结构体的影响,并制作出最适合使用者的假肢结构。
上述研究成果表明了LA算法在求解工程应用问题上良好的效果。与此同时,LA算法和其他智能优化算法一样,也存在着过早收敛、易陷入局部最优等问题。针对上述问题,本文提出融合分区导向搜索与自适应扩散更新的新型Lichtenberg算法(novel Lichtenberg algorithm,NLA),分别将螺旋系数和Levy因子融入对中心区域和边缘区域粒子的更新中,增强算法的全局搜索能力;然后利用群体粒子的位置和适应度值信息进行自适应扩散更新,提高算法跳出局部最优的能力。
1 Lichtenberg算法
LA算法是一种基于群体和轨迹的优化算法。算法预先生成LF,算法的寻优过程即为对LF 进行放缩、旋转、产生二次分形图三种变换操作,从而实现对构成LF的粒子位置进行更新。上述变换操作完成后,随机选取构成LF 的部分粒子进行适应度值评估,仅保留适应度值最优的一个粒子,作为下一次迭代的初始点。当算法达到预设最大迭代次数时,算法停止,输出最优解。LA算法包括初始化LF和基于LF的变换操作两个阶段。
1.1 初始化LF
Turner提出,LF可以通过许多粒子的随机生长过程模拟产生[10]。扩散限制聚集(diffusion limited aggregation,DLA)模型是一种随机的团簇生长模型,由Witten 和Sander模拟固体颗粒的团簇生长数值模型而提出,这种模型会导致复杂的混沌行为[11]。通常可以用分形几何图形来刻画,因此本文选取DLA模型构造LF。
1.2 基于LF的变换操作
构成分形图的粒子的位置更新通过作用在分形图上的放缩、旋转、产生二次分形图的变换操作实现。
1.2.1 放缩
放缩操作即对初始化生成的分形图的大小乘以一个0~1之间的随机数,称为放缩系数。分形图的原始大小即为待优化问题搜索空间的大小。在每次迭代时,分形图都会以不同的大小绘制出来。这一操作缩短了每次迭代时各个点之间的距离,且仅改变分形图的形状大小,其余特征均不改变,提高了LA算法的搜索效率。
1.2.2 旋转
旋转操作即对分形图进行随机旋转。随机给定一个旋转角度,并根据笛卡尔坐标旋转方程对整个图形进行旋转。这仅适用于对二维和三维分形图进行旋转。
笛卡尔二维坐标旋转方程如式(1),α表示旋转角度。
其中,x、y分别表示构成分形图的一个粒子在平面直角坐标系的横坐标和纵坐标值,x′、y′分别是粒子经旋转操作后的横、纵坐标值。
笛卡尔三维坐标旋转方程如式(2),γ、β、α分别是作用在x、y、z轴上的旋转角度。
其中,x、y、z分别表示构成分形图的一个粒子在空间直角坐标系的横坐标值、纵坐标值和竖坐标值,x′、y′、z′分别是粒子经旋转操作后的横、纵、竖坐标值。
由于旋转角度的随机性,使得粒子在每次迭代时的位置都是不同的,增加了分形图粒子位置的多样性,避免了简单的重复操作,有利于算法跳出局部最优。
1.2.3 生成二次分形图
生成二次分形图这一变换操作利用局部搜索改进系数(ref)来实现,ref是介于0~1之间的随机数。该操作会在原分形图的基础上产生一个新的分形图,即为二次分形图,其大小通常是原图的0~100%。新生成的二次分形图与原图有相同的初始迭代点、放缩系数和旋转角度。如果改进系数为0,算法在本次迭代过程中将一直在同一个分形图上进行寻优,不会产生二次分形图,经改进系数作用后产生的二次图将会大大提高算法的局部搜索能力。图1 为初始化形成的LF 经过放缩、旋转和产生二次分形图操作后的LF,蓝色部分的图形为初始化的LF,红色部分为二次分形图。
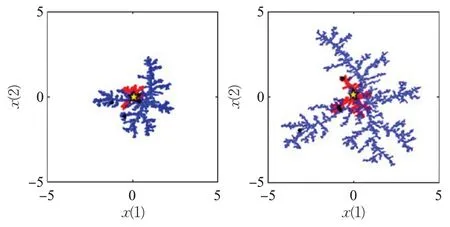
图1 进行放缩、旋转和产生二次分形图后的LFFig.1 LF after retracting,rotating and generating quadratic fractals
2 融合分区导向搜索与自适应扩散的新型Lichtenberg算法
2.1 分区导向搜索
基本LA 算法中个体的位置会受到当前位置、目标位置和群体其他个体位置的共同影响,这表示构成分形图的所有个体都影响每个个体的下一个位置。因此LA算法的全局搜索能力相对有所不足,也就是说LA算法易出现在局部最优值附近停滞的情况。而算法前期需要大范围的全局搜索来找到所有可能的解。分形图作为混沌形态具有以下特征:远离中心吸引子的一切运动都趋向于中心,属于“稳定”的方向;一切到达中心吸引子内的运动都互相排斥,对应于“不稳定”方向,因此算法的迭代寻优过程就是粒子不断趋向中心吸引子的过程。考虑到粒子所处区域的不同表现出的差异性,对搜索空间的寻优过程也应当划分成不同区域各自进行更新。文献[12]将群体划分为两部分,分别采取worker phase和breeder phase两种更新规则进行更新。虽然该更新策略具有较强的开发能力,但是它存在“过度开发”问题,会极易导致粒子陷入局部最优。在此基础上,设计分区导向搜索策略。根据个体的适应度值将整个搜索空间划分为两个区域来指导个体寻优,群体中适应度值排名前20%的个体离中心吸引子更近,构成中心区域;剩下80%的个体离中心吸引子较远,构成边缘区域。由于中心区域和边缘区域在搜索空间处于不同的区域,需要分别设计针对性的更新方法。结合螺旋系数的周期趋向性和Levy 变异的随机性,实现中心区域的个体向最优位置靠拢,同时边缘区域的个体由子空间到整体解空间进行全局搜索。
2.1.1 中心螺旋搜索
由于中心区域的粒子适应度值较优,离全局最优的位置较近,说明它们正沿着正确的搜索方向搜索。为了使它们更快地趋向到全局最优位置,要求这些粒子能够在搜索空间内进行充分的探索,扩大搜索范围。因此,在更新过程中以全局最优粒子和中心区域的最优粒子为导向,将鲸鱼优化算法的螺旋搜索系数ebmcos(2πm)进行改进,步长因子b由固定值改为随迭代次数改变的动态步长因子,赋予其动态趋向性,可以动态改变个体的位置更新步长,使得中心区域的粒子在迭代前期可以大范围地探索最优位置,更新范围也随着迭代次数的增加而随之减小,迭代后期可以围绕目标位置进行周期性精细搜索。步长因子b定义如下:
加入了动态步长因子b的螺旋搜索系数可以加快粒子趋向中心吸引子这一过程,从而提升算法寻优精度,加快收敛速度。对中心区域粒子更新的数学表达式如式(3)所示:
其中,gbest是全局最优粒子,为中心区域中适应度值最优的粒子,ebmcos(2πm)为螺旋搜索系数。图2是模拟粒子进行周期性螺旋搜索的轨迹图,通过图2可以直观地看出当前粒子以步长x=ebmcos(2πm)向全局最优粒子螺旋式靠近。其中,t为当前迭代次数,n_iter为最大迭代次数。
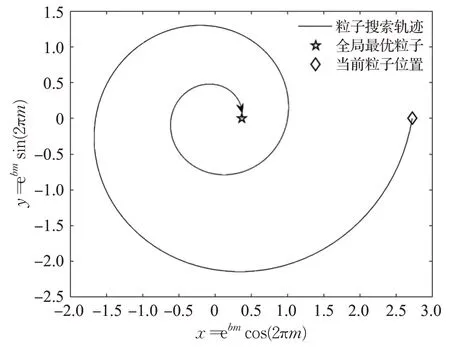
图2 螺旋搜索轨迹图Fig.2 Spiral search trajectory graph
2.1.2 边缘扰动搜索
边缘粒子由于适应度值较差,远离中心吸引子,这些粒子的搜索方向和步长均需要重新调整,它们需要探索更广阔的区域,才能向全局最优靠近。受文献[13]提出的对布谷鸟算法的最优鸟窝位置进行分阶段动态扰动的启发,提出一种改进的边缘扰动搜索策略,通过引入Levy 飞行机制,利用Levy 飞行方向和步长的不确定性对粒子位置增加扰动,提高群体的多样性。基本的Levy飞行机制在寻优过程中虽然加强了算法的全局搜索能力,但是还会存在陷入局部最优的问题。针对上述问题,引入sign函数,利用sign函数的分段特征,强化当前粒子的随机学习过程。sign函数表达式如下:
Levy分布的数学表达式如下:
其中,u、v均为0 到1 之间服从均匀分布的随机数,ω=1.5。
边缘扰动策略的公式如下:
其中,Xrand_1(t)是从边缘粒子中随机选择的,βmin=0.2,θ是(0,2]服从均匀分布的随机数。当sign函数取值为1时,个体由子空间到整体解空间进行Levy全局搜索,大范围搜寻最优位置;当sign 函数取值为0 时,个体保持当前位置不变;当sign函数取值为-1 时,产生边缘扰动搜索反向解,通过动态地调整搜索方向,可以避免算法陷入局部最优、搜索停滞的情况,帮助算法脱离局部极值。sign 函数的三种取值会使个体有三种不同的搜索方向进行选择,有效避免了迭代后期种群多样性下降,算法易早熟收敛的问题。在二维搜索空间中,假设群体规模为50,搜索空间为[-100,100],绘制了不同迭代时刻的个体分布图,如图3所示。
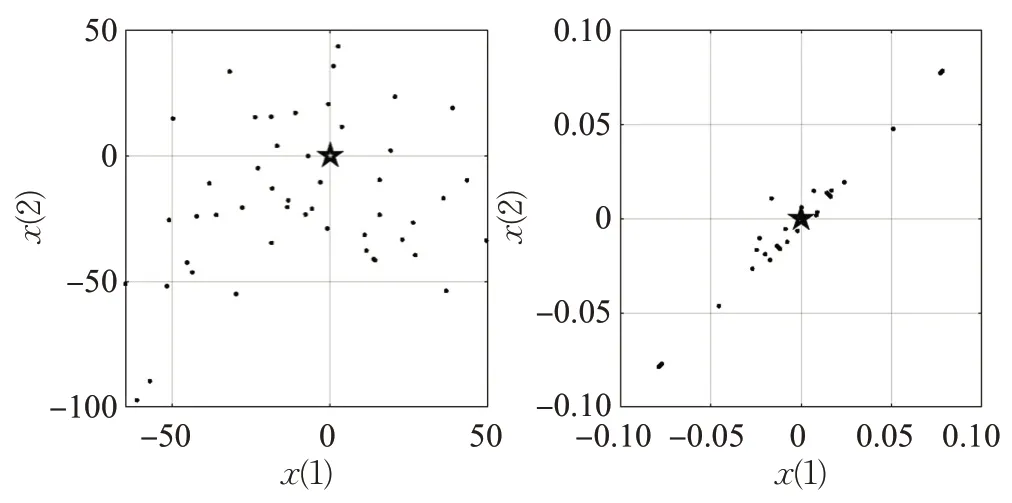
图3 不同迭代时刻的个体分布图Fig.3 Individual distribution map at different iterations
迭代初期粒子分布在[-100,50]区间,随着迭代次数增加,粒子逐渐向全局最优附近靠拢,主要分布在[-0.1,0.1]区间。由图3可以看出,迭代初期群体多样性较高,个体分布在搜索空间的广阔区域内,可以大范围地搜寻最优解,确定后期搜索的大方向;随着迭代次数的增加,个体不断向全局最优靠拢,种群多样性也随之降低。进一步证明将螺旋搜索系数和Levy变异相结合可以加强算法的全局搜索能力,上述两种更新策略相结合是切实可行的。
2.2 自适应扩散
在LA 算法原有的更新操作中,构成分形图的各粒子之间没有信息交互,单纯依靠对分形图进行放缩、旋转等操作实现粒子的位置更新,因此算法寻优能力较弱。适应度值是反映个体与全局最优之间关系的重要参数,适应度值较优的粒子所携带的位置信息更有利于算法进行寻优,因此如果能在个体更新时充分利用群体粒子的适应度值,可以有效提高算法跳出局部最优的能力[14]。但需要注意的是,如果构成分形图的粒子集中于某一方向进行搜索,很可能陷入局部最优,为了避免这种情况的发生,需要确定一个合适的选择概率,既要保证大部分粒子向全局最优方向进行搜索,也要保证小部分粒子的独立搜索能力。文献[15]提出的具备观测触发机制的透镜成像学习,嵌入一种基于迭代次数和最优适应度值的观测算子,来观测算法是否陷入局部最优。
本文在此基础上,提出了自适应扩散对算法进行改进,引入累积概率随机选择群体粒子与当前粒子进行交互,累积概率作为调节参数,使得个体根据种群所处的实际环境以及自身的适应度值动态调节,避免算法后期易陷入局部最优的问题。自适应扩散策略如式(10)所示:
其中,r是服从[0,1]均匀分布的随机数,X(k,j)是按累积概率从群体中随机选择的一个粒子在其维度j上的值,随机粒子k的具体选择方法见式(12),fitnessk是粒子k的适应度值。通过对随机粒子k与当前粒子的适应度值进行比较,选择更优的个体作为导向进行扩散更新。
其中,rand_num是[0,1]服从均匀分布的随机数,Ci是累积概率。每次更新时,先计算群体每个粒子的累积概率Ci,然后生成rand_num,并判断rand_num落在哪一个累积概率区间,则该粒子就被选中为X(k,j)。Ci的数学表达式如式(13)所示:
通过概率选择的随机性,当前个体与其他个体间的信息交流更加丰富,个体在探索阶段会根据收集到的信息自适应调节自己的搜索方向,避免随机选择粒子所造成的盲目跟随,使得粒子能有效跳出当前区域。
3 融合分区导向搜索与自适应扩散的新型Lichtenberg算法流程
NLA 算法采用分区导向搜索和自适应扩散对算法进行改进,下面给出NLA算法的实现步骤和伪代码,并对NLA算法进行时间复杂度分析。
3.1 NLA算法的主要步骤
NLA算法的主要计算步骤如下:
步骤1初始化NLA算法参数,随机生成初始解,计算适应度值并择优保存作为生成LF的初始点。
步骤2生成LF(本文只在步骤2生成一次分形图,后续迭代均在此分形图基础上进行),并对其进行放缩、旋转、产生二次分形图的变换操作。
步骤3分别从原LF 和生成的二次LF 中随机选择相同数量的粒子,其个数为群体规模的1/2。
步骤4将步骤3 选择出的粒子按照适应度值划分为两组,进行分区导向搜索。
步骤5计算更新后的适应度值,并按照式(7)进行自适应扩散更新。
步骤6计算每个粒子更新后的位置和适应度值,将适应度值最优的粒子保存,作为下一次迭代的初始点。
步骤7重复步骤2~步骤6的更新迭代过程,达到预设最大迭代次数时,终止NLA算法并输出最优解。
3.2 NLA算法伪代码


3.3 NLA算法时间复杂度分析
LA 算法的时间复杂度如下:假设群体规模为N,搜索空间维度为D,则LA初始化分形图的时间复杂度为O(N×D),对分形图进行放缩、旋转、产生二次分形图的变换操作的时间复杂度为O(N),计算个体适应度值的时间复杂度为O(N×D),LA 总的时间复杂度为O(N×D)。
同理,进行中心螺旋搜索的时间复杂度为O(N×D),进行边缘扰动搜索的时间复杂度为O(N×D),采取自适应扩散更新策略的时间复杂度为O(N×D),因此NLA 算法总的时间复杂度为O(N×D)。因为NLA 算法和LA 算法的时间复杂度处于同一水平,所以上述改进策略并未对基本LA算法产生负面影响。
4 仿真实验与结果分析
4.1 实验设计与测试函数
为了验证本文所提NLA 算法的有效性,采用CEC2021测试函数和20个不同特点的高维测试函数进行数值实验。仿真实验基于Intel®CoreTMi7-8565U CPU@1.80 GHz 2.00 GHz,16.0 GB内存,以及Win10操作系统,仿真软件为MATLAB R2020b。
将NLA 算法与基本LA 算法[7]、粒子群优化算法(particle swarm optimization,PSO)[16]、差分进化算法(differential evolution,DE)[17]、鲸鱼优化算法(whale optimizaiton algorithm,WOA)[18]、金鹰优化算法(golden eagle optimization,GEO)[19]、食肉植物算法(carnivorous plant algorithm,CPA)[20]进行比较,算法参数设置见表1。其中NLA 算法各参数的含义如下:Np为生成LF 的预设粒子数,Rc为生成LF 的预设半径,refinement(ref)为生成二次分形图的比例系数。

表1 各算法参数设置Table 1 Experimental parameter settings of each algorithm
4.2 CEC2021测试函数的实验结果分析
本文对CEC2021 函数的寻优实验参考文献[21]进行。CEC2021 测试函数是对表2 中10 个基本函数施加3种不同的变换操作而产生,3种变换操作包含Bias(偏差)、Shift(移位)和Rotation(旋转),对每种操作都有添加和不添加2种选择,共8种不同的组合方式,如表3(0代表不添加此变换,1代表添加此变换),总计10×8=80个不同的函数,进行变换操作后的函数最优值不变。本文选取表3 中勾选的4 种组合方式进行20 维函数的测试实验。迭代次数为200 次,种群规模为50,每个算法独立运行30 次,实验结果如表4 所示。由表4 可知,对于大部分函数来说,DE 和GEO 求得结果的平均值较大,说明DE 和GEO 寻优能力的不足,而且跳出局部最优的能力较弱。NLA算法在最优值、平均值、标准差这3 个指标上不仅是上述7 种算法中最好的,而且它取得了全部函数的理论最优值,收敛精度更高,寻优稳定性也更强。对单峰函数F1寻优时,PSO的最优值8.32E-05,WOA的最优值5.21E-33,而NLA算法的最优值是0;对添加Bias和Rotation操作的寻优难度大的函数,NLA算法相较于其他6种智能优化算法,在求解精度上具有明显的优势,对于函数F2~F4,NLA 算法和WOA 均找到了最优值,但NLA 算法较于WOA,在平均值和标准差上均有数百个量级的优势;另外,无论是对于单峰函数、基础函数、混合函数还是组合函数,NLA算法在测试函数上的寻优结果均优于LA算法,而且NLA算法的标准差均为0,说明NLA算法相较于基本LA算法,具有更稳定的寻优能力。根据上述实验结果分析,本文提出的改进算法具有更高的求解精度和更稳定的寻优能力。

表2 CEC2021测试函数Table 2 CEC2021 test functions
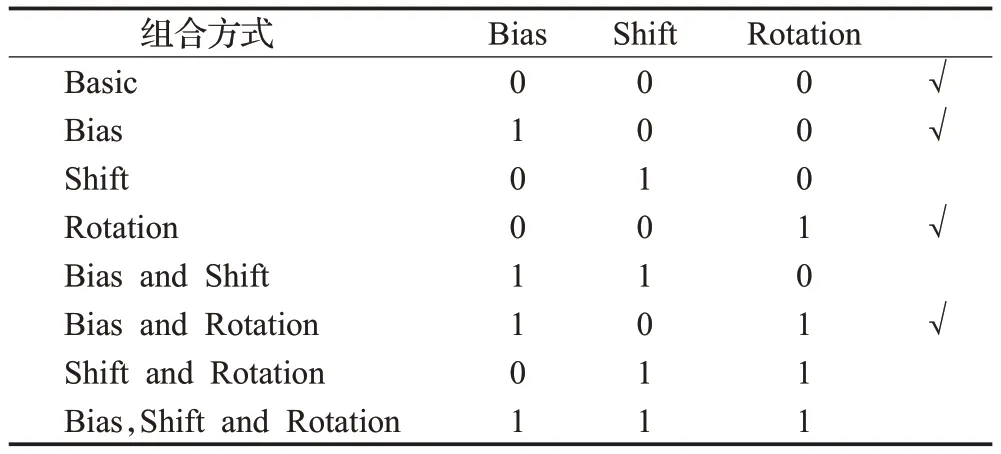
表3 作用于基础函数上的8种组合变换Table 3 Eight combined transformations acted on basic functions
本文选取了部分函数的迭代寻优结果绘制了收敛曲线,由于大部分函数的收敛曲线较为相似,只挑选两种具有代表性的呈现,其中纵坐标取以10为底的对数,如图4所示。由收敛曲线可知,NLA算法无论是在求解精度还是收敛速度上,都明显优于其他算法。针对F3,虽然WOA算法也收敛到了最优值,但NLA算法的收敛速度明显更快;针对F1 这个寻优难度大的函数,NLA算法也表现出了优越的性能,可以快速地收敛到最优值,而且NLA算法在迭代初期就达到了WOA算法的求解精度,这说明分区导向搜索加强了算法的全局搜索能力,此后基于自适应扩散的作用,使得算法跳出局部最优继续进行搜索,最终收敛到最优值。NLA 算法在初始阶段的适应度值就优于其他对比算法,说明分区导向搜索一定程度上提高了算法的全局搜索性能。综合对表4和图4的分析,NLA算法针对复杂的函数优化问题具有较好的求解精度和收敛速度,性能提升较大,是一种高效的算法。
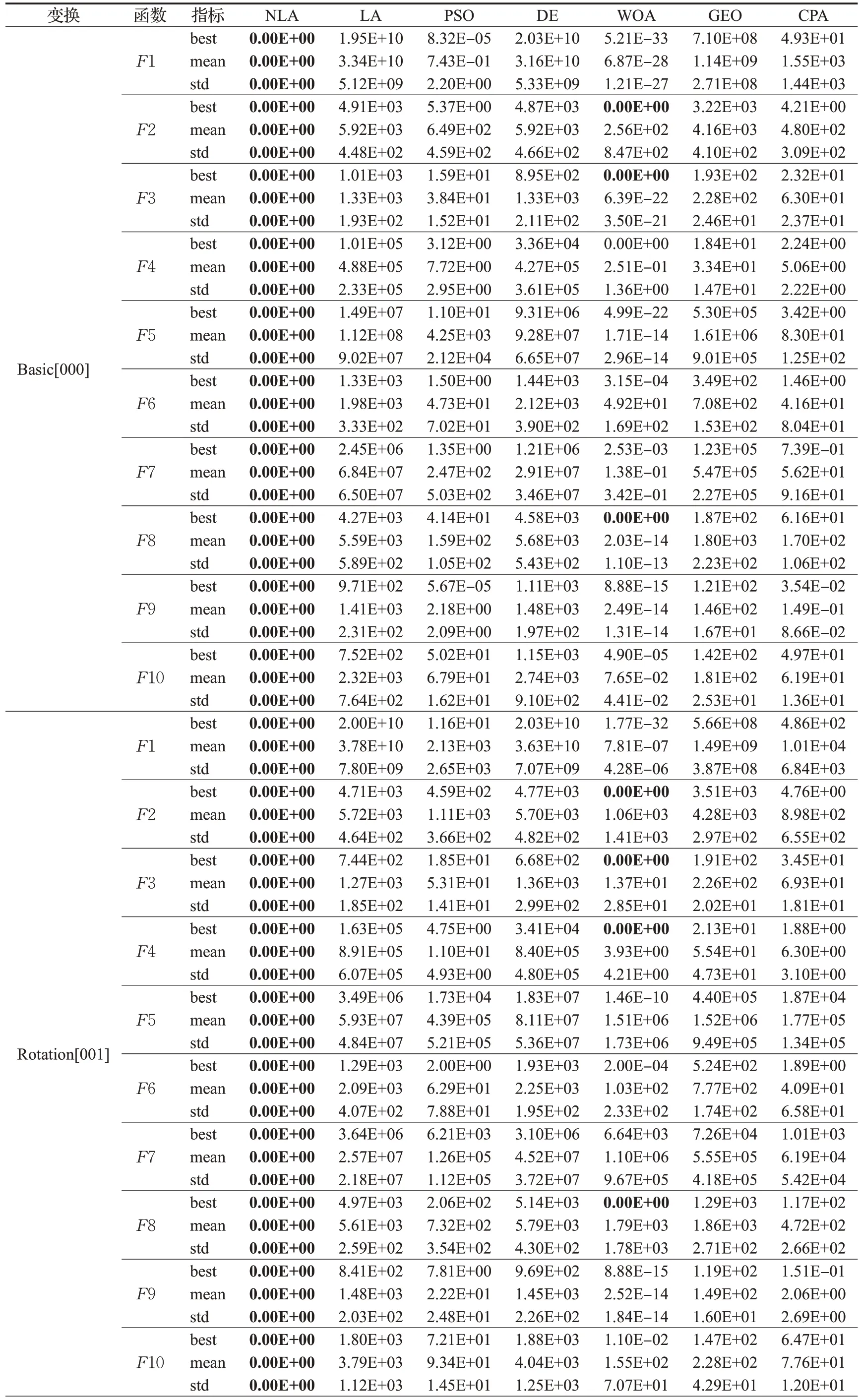
表4 20维测试函数结果Table 4 Results for 20 dimensional functions
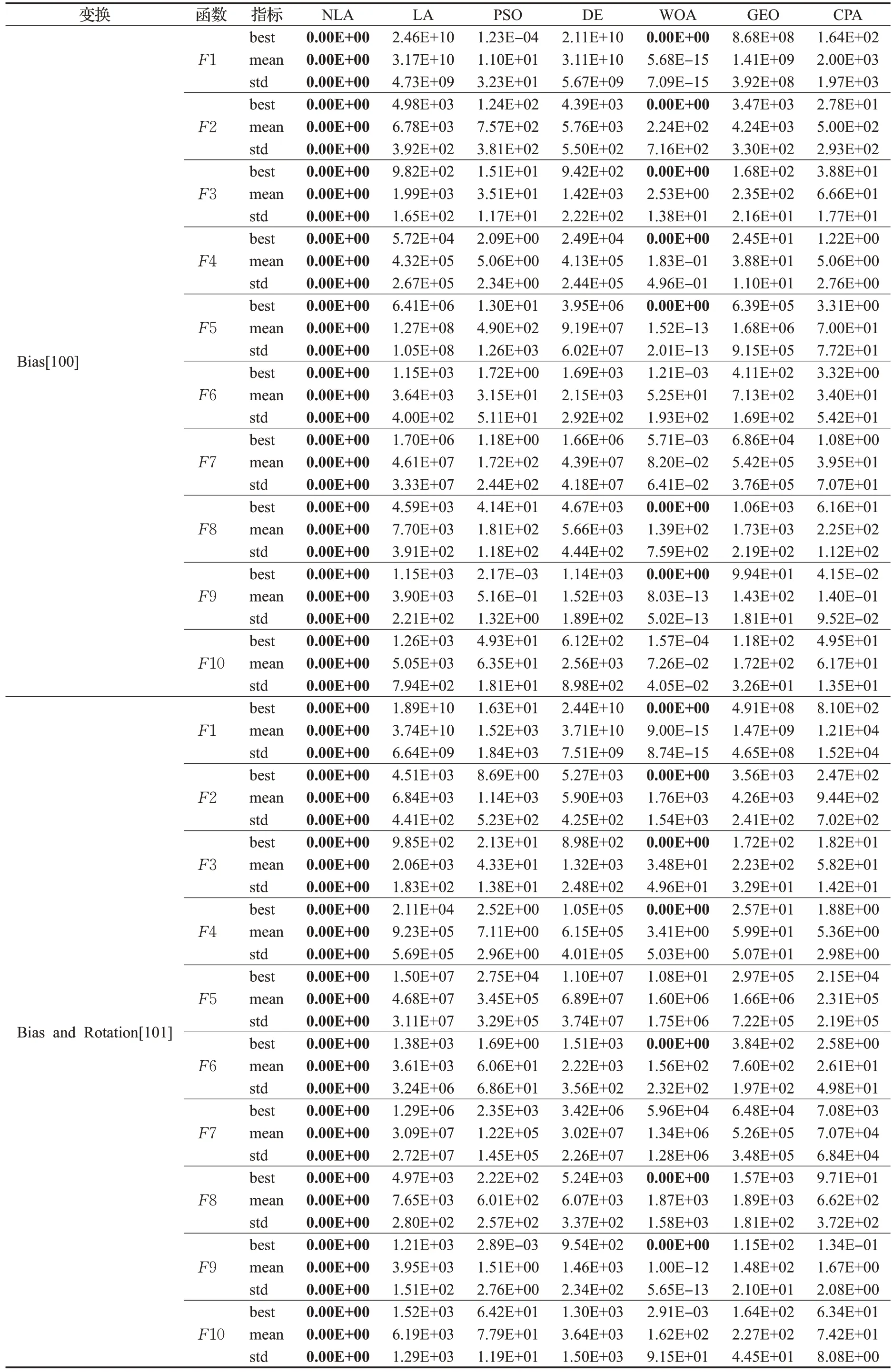
表4 (续)

图4 CEC函数收敛曲线对比Fig.4 Comparison of CEC functions convergence curves
4.3 其他类型测试函数的实验结果分析
本文将上述7 种算法进行1 000 维函数的对比实验,分别在20个高维测试函数上独立运行30次,具体函数信息见表5。所有算法的群体规模设为50,迭代次数设为200,实验结果如表6所示。从表6可以看出,NLA算法是7 种算法中寻优结果最优的。对于这20 个测试函数,NLA算法能够找到除函数f5 和f7 外其他所有函数的理论最优值,并且得到的最优值、标准差都为理论最优值。对于寻优难度较大的f5,NLA 算法虽未取得其理论最优值,但寻优精度比LA 算法提高了十几个量级;对于f7,虽然上述算法都无法找到其理论最优值,但NLA算法的最优值更接近理论最优值,与LA算法相比,NLA算法找到的最优值提高了11个数量级的精度,且比其他对比算法有数个量级的提升;对于寻优难度较大的函数f19,大多数算法的寻优精度都很低,而NLA算法收敛到理论最优解,说明本文所提改进策略能够提高算法跳出局部最优的能力。同时从表5 的标准差可知,NLA 算法在17 个测试函数上得到的标准差都为0,说明NLA算法具有较强的稳定性。

表5 基础函数Table 5 Basic functions

表6 高维测试函数结果Table 6 Results for high-dimensional test functions
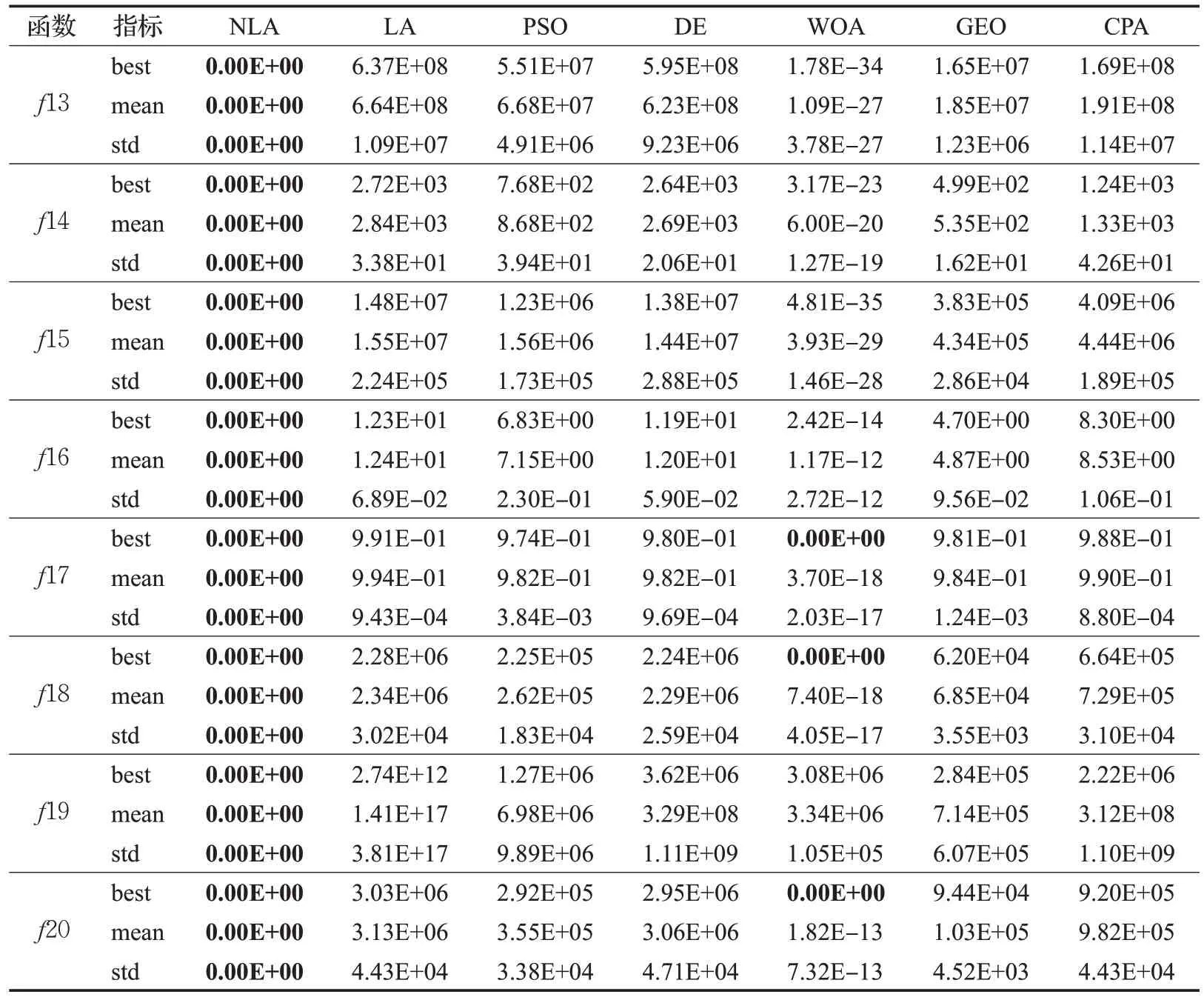
表6 (续)
为了更加直观地对比各算法的收敛精度和收敛速度,本文根据迭代次数和适应度值绘制了测试函数的收敛曲线图像,其中纵坐标取以10 为底的对数,如图5 所示。由收敛曲线可知,基本LA 算法在迭代前期的寻优性能较差,而在后期也陷入了局部最优,而NLA算法在整个迭代过程中,寻优性能良好,不断向最优解收敛。具体来说,对于f1,NLA算法的最优值在迭代过程中呈现指数级的下降速度,其收敛速度要远优于其他算法,其后期也表现出了较强的局部搜索能力;对于f5,NLA算法在前期更侧重于对搜索空间进行开发,因此放慢了收敛速度,但是在算法后期粒子找到最优区域以后,算法较强的寻优能力使得算法快速收敛;对于f7,算法在迭代前期对搜索空间进行充分的探索,但在搜索后期,收敛速度减慢,但最终的收敛精度仍高于其他对比算法;对于f17,NLA算法的表现相当优异,仅用了几次迭代就收敛到最优值,虽然WOA算法也找到理论最优值,但NLA算法的分区导向搜索和自适应扩散使得算法在迭代初期大范围地搜索,确定潜在最优解所在位置,迭代后期收敛速度加快,算法快速趋向于优秀粒子,逐渐收敛到最优值。针对大部分函数,NLA 算法的收敛精度要明显优于其他算法。综上,NLA 算法优化高维函数的可行性和有效性得以证明。
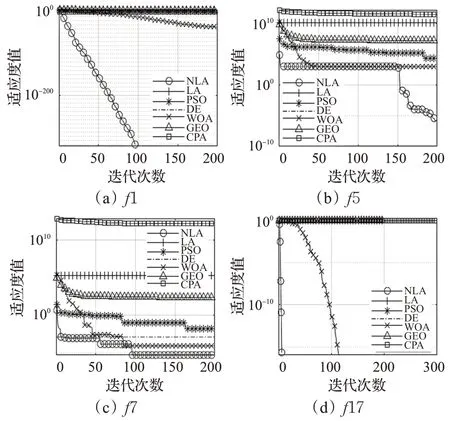
图5 高维函数收敛曲线对比Fig.5 Comparison of high-dimensional functions convergence curves
4.4 Wilcoxon秩和检验
Wilcoxon 秩和检验是一种非参数统计检验方法,可以针对复杂的数据分布进行检验,因此本文选取Wilcoxon 秩和检验方法进一步验证各算法之间差异性是否显著。选取NLA 算法在CEC2021 测试函数集上的运行结果与LA、PSO、DE、WOA、GEO、CPA的运行结果进行Wilcoxon 秩和检验并计算p-value,由于篇幅限制,仅列出部分10 维函数的实验结果,如表7 所示。当p-value 值小于5%时,说明两种算法的差异性显著,反之,则没有。由实验结果可知,大部分的p-value值都是小于5%的,因此可以认为NLA算法对CEC2021函数上的寻优性能优势是明显的,进一步证明了本文所提NLA算法的有效性。

表7 Wilcoxon秩和检验结果Table 7 Wilcoxon rank sum test result
4.5 改进策略的有效性分析
为了验证NLA 算法的有效性,将NLA 算法与其自身的两个变体进行测试,两个变体为仅加入分区导向搜索策略的LA 算法(LA1)和仅加入自适应扩散更新的LA算法(LA2)。本文选取f5、f7 这两个寻优难度较大的高维函数和CEC2021 的两个函数进行寻优对比,分别为不添加任何变换操作[000]的F5 和仅添加旋转操作[001]的F9,其参数设置与上述实验完全相同。三种算法的对比结果如表8所示。
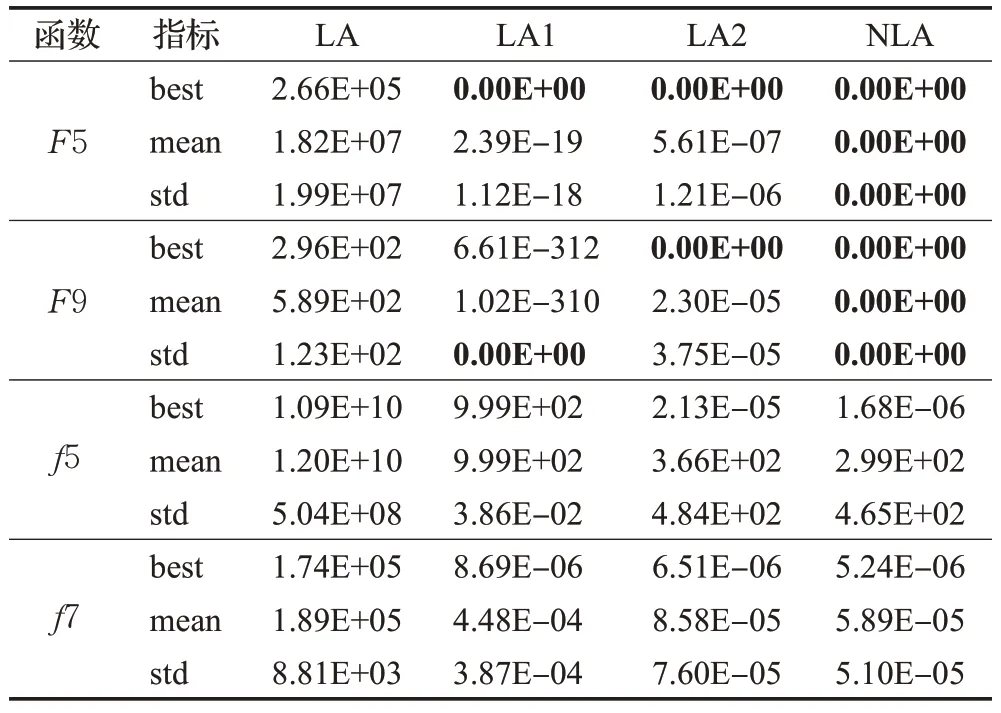
表8 不同改进策略对比结果Table 8 Comparison of different improvement strategies
由表8所示结果可以看出,针对函数F5,仅使用分区导向搜索的LA1和仅使用自适应扩散的LA2都找到了最优值,但其平均值和标准差较差,而NLA算法结合了两种策略的优势,既能找到最优值,且均值和方差均达到最优效果;而对函数F9,融入分区导向搜索的LA1算法的寻优结果与最优值很接近,稳定性也较好,融入自适应扩散的LA2算法找到了最优值,但寻优效果不稳定,NLA 算法展现了良好的寻优效果。针对f5、f7 这两个寻优难度大的函数,采用两种改进策略结合的NLA算法的寻优精度和稳定性要优于采用单一改进策略的LA算法。通过对比LA、LA1、LA2的寻优效果,两种改进策略对算法的性能均有一定程度的提升,其中融入分区导向搜索的LA 算法(LA1)的寻优稳定性更好,融入自适应扩散的LA 算法(LA2)的寻优精度更好,找到的最优值也与NLA算法更为接近。而结合两种改进策略的NLA算法对基本LA算法性能提升更大。
5 结束语
本文针对LA 算法在求解复杂函数优化问题时,寻优精度低、收敛速度慢、易陷入局部最优等问题,从混沌与分形的角度出发,结合复杂系统的内在特征,提出融合分区导向搜索与自适应扩散更新的新型Lichtenberg算法(NLA)。首先,将构成分形图的粒子根据适应度值进行分区,靠近吸引子的那部分中心粒子采用螺旋搜索,远离吸引子的那部分边缘粒子采用扰动搜索,加强算法的全局搜索能力。然后,结合复杂系统各部分之间的交互依存特征,充分利用各粒子的位置和适应度值信息,进行自适应扩散更新,避免算法陷入局部最优。为验证NLA 算法的性能,选取了CEC2021 测试函数以及20个不同特点的高维函数进行数值实验。结果证明,与LA、PSO、DE、WOA、GEO、CPA 相比,本文提出的NLA算法在优化复杂函数和高维函数时寻优精度高,稳定性更强,显示了良好的效果。将NLA 算法应用于智慧医疗系统资源调度是进一步的工作。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
太原科技大学学报(2022年1期)2022-02-24
计算机仿真(2021年1期)2021-11-18
动漫星空(兴趣百科)(2020年11期)2020-11-09
计算机工程与设计(2020年4期)2020-04-23
趣味(数学)(2019年12期)2019-04-13
现代装饰(2018年11期)2018-11-22
郑州大学学报(工学版)(2018年2期)2018-04-13
物联网技术(2017年5期)2017-06-03
