
基于深度学习的催化裂化过程建模方法
2023-07-19 06:29陈琳,周利,吉旭
西安石油大学学报(自然科学版) 2023年4期
陈 琳,周 利,吉 旭
(四川大学 化学工程学院,四川 成都 610065)
引 言
石油炼化具有重要的战略及现实意义,是许多国家的支柱产业之一。近年来,轻质和绿色燃料市场的不断增长、环保法规的日益严格以及原油质量的低劣化发展趋势,正迫使石油炼化产业进一步升级,特别是在建设和改进石油深加工技术方面[1-2]。催化裂化(Fluid Catalytic Cracking,FCC)将劣质重油转化为高价值的轻质油和化学品(例如汽油和丙烯),已成为炼油行业最关键的重油转化技术之一[3]。自1940年代以来,学术界和工业界对催化裂化的过程建模进行了大量的研究,以期达到快速准确的产品收率预测,为实现过程控制、故障诊断以及操作优化奠定基础。近年来,伴随着工业4.0和中国制造2025的浪潮,催化裂化逐渐趋于互联化和信息驱动,对催化裂化的过程建模研究也从传统的机理建模发展为数据驱动建模[4-5]。
机理模型是基于催化裂化过程反应及传递机理所建立的精确数学模型[6],可分为集总动力学模型[7-9]和分子尺度动力学模型[10]。由于催化裂化的原料和产物都是烃类和非烃类组成的复杂混合物,难以进行表征和描述,集总动力学模型将具有相似动力学规则的化合物集中成一个虚拟组分,称之为“集总”,以此来简化反应体系。如果能够获得准确的动力学参数,则集总动力学模型可以取得不错的预测结果,但其受原料波动的影响较大,且针对不同的原料或产品,必须重新调整参数构建模型。随着分子表征技术的发展以及计算水平的提高,以更高的分辨率来描述催化裂化反应过程的分子尺度动力学模型得以发展,这也导致了更加复杂的模型表现形式,例如结构导向集总模型[11-12]、蒙特卡罗模型[13-14]和单事件动力学模型[15-16]等。
尽管机理模型能够揭示反应过程本质,帮助我们理解过程现象,但由于催化裂化是一个高度复杂的工业系统,其过程伴随着非线性、强耦合、大时滞、强干扰等复杂的时空特性[17],这一方面要求研究人员具有很深的知识背景,另一方面,为了简化过程机理而作出的许多理想化假设会影响模型性能。相比之下,数据驱动模型对领域知识的要求不高,且具有更好的自适应性和可迁移性。此外,炼油厂生产过程中积累的海量过程数据,也为数据驱动模型的构建提供了基础条件。传统的数据驱动模型以支持向量机(Support Vector Machine,SVM)[18-19]、反向传播网络(Back Propagation Neural Network,BPNN)[20-21]、随机森林(Random Forest,RF)[22-23]等传统机器学习算法为主。由于传统机器学习算法的表达能力有限,通常还需要结合细致而繁琐的特征工程来提高模型性能[24]。随着人工智能技术的不断发展,深度学习被提出并应用到了化学工业之中[25-27]。深度学习具有强大的数据处理和特征映射能力,与传统机器学习算法中人工构造特征相比,深度学习利用大量数据来学习和挖掘特征,更能刻画数据中丰富的内在信息和物理意义。
催化裂化是一个典型的动态连续过程,充分利用其过程数据的时序性对建模具有重要意义[28]。长短期记忆网络(Long Short-Term Memory,LSTM)作为专门处理时间序列问题的深度学习算法,在催化裂化过程建模中得到了应用[29-31]。Zhang等基于LSTM提出了一种加权自回归长短期记忆(WAR-LSTM)结构单元,将多个WAR-LSTM叠加为深度WAR-LSTM,从多变量中提取高层特征表示,从而充分利用催化裂化过程中的时空信息。虽然LSTM通过其门控单元在一定程度上改善了长序列训练过程中的梯度消失和梯度爆炸问题,但其本质还是串行结构,仍无法完全避免此问题[32]。2018年,Bai等提出了时间卷积网络(Temporal Convolutional Network,TCN),其本质是卷积神经网络(CNN)针对时间序列问题的优化和改造,其并行结构提高了模型计算效率,也避免了梯度消失和梯度爆炸问题,从而使TCN具有更长的记忆能力,在多个数据集的测试结果中表明,TCN的表现优于LSTM和GRU等一般循环神经网络(RNN)。然而,目前尚未在催化裂化过程建模领域中见到有关TCN的报道。
此外,在催化裂化的生产过程中,原料波动、设备故障、环境干扰等状况的出现会使得其过程的时滞性发生变化,即序列在时间维度上的相关性发生了改变,导致模型精度下降。注意力机制(Attention Mechanism)通过构建注意力矩阵,使模型自适应地对不同关注部分赋予不同的权重,并抽取出更加重要和关键的信息,从而增强模型的信息提取能力。在序列的时间维度上引入注意力机制,可使模型对每个特定时间步的重要性进行定量赋值,以此来捕捉并减小序列时滞性变化带来的影响,进而提升模型的自适应能力及鲁棒性。Han等[33]在LSTM的基础上引入了注意力机制,改善了传统LSTM的注意力分散问题,并将该模型应用于分析某复杂化工系统的生产能力和节能潜力,取得了较好效果。
综合以上分析,本文提出了一种基于深度学习的催化裂化过程建模方法,该方法结合了TCN、注意力机制和BPNN 3种网络结构,以充分利用催化裂化过程的时空信息。首先,利用TCN对过程时序数据进行深度信息提取;其次,利用注意力机制来自适应地捕捉时序过程中的时间权重;再者,利用BPNN作为网络最后的回归器,将经过TCN和注意力机制提取后的信息与产品收率进行关联;最后,将所提方法应用于实际的催化裂化生产过程来验证其有效性和实用性。
1 催化裂化工艺流程
自1940年代发展至今,催化裂化已形成相对完整的流程体系,图1给出了典型催化裂化工艺的简化流程图。催化裂化分为3个子系统,分别是反应-再生系统、分馏系统以及吸收-稳定系统。反应-再生系统作为催化裂化的核心系统,提供了原油裂解所需的高温催化环境。原料油从提升管底部进入反应器,在此处与高温再生催化剂接触而立即汽化,并随着预提升气一起加速上升。在上升过程中,原料油在高温和催化剂的作用下,发生裂化、异构化、氢转移等一系列复杂的化学反应,生成包含轻质油产品在内的油气混合物,与此同时,催化剂因积碳而逐渐失活。失活催化剂通过反应器顶部的分离器与油气进行分离,然后进入再生器通过空气燃烧去除积碳,从而恢复活性成为再生催化剂,并携带着燃烧所产生的高温重新进入提升管底部参与反应。从反应器顶部出来的油气混合物进入分馏系统被切割成富气、粗汽油、轻柴油、重柴油以及副产物油浆。富气和粗汽油作为中间产物进入吸收-稳定系统,通过吸收和精馏操作最终分离成干气、液化气和汽油。

图1 典型催化裂化工艺的简化流程Fig.1 Simplified diagram of typical FCC process
催化裂化过程复杂,影响因素众多,其各产品的收率很大程度上取决于各装置的控制与优化水平,而这又进一步依赖于模型性能,因此,建立一个准确的产品收率预测模型至关重要。
2 研究方法
本节介绍所提出的深度学习建模方法,用于构建催化裂化过程信息与产品收率之间的映射关系,主要包括以下3个步骤:
(1)数据收集与预处理。从炼油厂的数据系统中收集有关催化裂化的过程信息,并进行数据预处理及数据集划分。
(2)模型构建。基于TCN、注意力机制和BPNN构建深度学习预测模型,如图2所示。

图2 所提建模方法示意图Fig.2 Schematic diagram of proposed modeling method
(3)模型训练与评价。基于梯度下降算法训练模型参数,训练完成后使用相关评价指标对模型的预测性能进行评价。
2.1 数据收集与预处理
首先,从炼油厂的数据系统(如DSC系统和LIMS系统)中收集有关催化裂化的过程信息,主要包括工艺变量(如温度、压力、流量、液位等)和物料性质(如初馏点、含碳量、密度等)。由于过程信息包含多个变量且均按照一定的时间间隔进行采样,即具有时间上的先后顺序,因此过程信息可视为多元时间序列。由于模型目标为预测产品收率,故将产品收率视为目标序列(Target Series),将除产品收率之外的过程信息视为驱动序列(Driving Series)。其中,驱动序列可表示为矩阵X:
(1)

目标序列可表示为向量y:
y=[y1,y2,…,yt]。
(2)
其次,为了确保数据的可用性,在数据收集完成后需进行数据的预处理,例如去除离群点、填补缺失值、数据降噪等。根据数据集情况的不同,可选择不同的预处理方法[34],例如采用三西格玛规则去除离群点、采用线性插值法填补缺失值等。此外,由于不同序列具有不同的物理意义和数量级,为了避免对模型性能造成影响,使用如下归一化方法将数据映射到同一尺度:
(3)
最后,采用滑动窗口法构造多元时间序列的监督数据集,如图2(a)所示,并按照合适的比例划分为训练集、验证集和测试集。其中,训练集用于训练模型参数,验证集用于初步评价模型并优化模型超参数,测试集用于模型的最终评价。
2.2 模型构建
所提建模方法旨在解决催化裂化产品收率预测的回归问题,具体而言,给定当前驱动序列[x1,x2,…,xt]和历史目标序列[y1,y2,…,yt-1],模型任务为学习以下非线性映射关系:
(4)


2.2.1 时间卷积网络
TCN的本质是一维CNN针对时间序列问题的优化和改造,能够将任意长度的输入序列映射到相同长度的输出,并且保证上下文信息的因果性。如图2(b)所示,TCN采用多层膨胀因果卷积(Dilated Causal Convolutions)进行信息提取。其中,因果卷积可表述为时间步t上的输出,只依赖于时间步t及其之前的卷积操作,而与时间步t之后的数据无关,这保证了层与层的因果性,即不存在未来信息的泄露。膨胀卷积则通过跳过特定步数的输入,使卷积核可以应用于大于其长度的区域,以此观测更长的输入序列。对于一个一维输入序列x∈Rn以及一个卷积核f:{0,…,k-1}→R,在序列成分s上的膨胀卷积操作F可由下式进行计算:
(5)
式中:*表示卷积运算,d表示膨胀因子,k表示卷积核的大小,s-d·i表示过去的方向。因此,膨胀卷积相当于在卷积核的每两个相邻引脚之间引入d-1个固定步数。d越大,输出所能观测的输入范围越大,当d=1时,膨胀卷积就等效为普通的卷积操作。在TCN中,d随着网络层数的增加呈指数增长,即d=O(2i),i表示网络层数。
此外,为避免随着网络深度的增加而出现网络退化问题,TCN采用残差模块作为基本单元来构建网络,即图2(b)中每层网络之间的卷积操作都用残差模块代替。一个残差模块可表述为输入x经过一系列非线性变换F,其结果直接与输入x线性叠加,再经过激活函数,得到整个模块的输出o,其计算公式如下[35]:
o=Activation(x+F(x))。
(6)
这种跳层连接的方式,使信息的前后向传播更加顺畅,进而使网络学习到恒等映射,避免网络退化。如图2(c)所示,在TCN的一个残差模块内,包含两层膨胀因果卷积层和非线性激活函数层(ReLU),以及与之配套的权值归一化层(Weight Norm)和随机失活层(Dropout)。
TCN综合膨胀因果卷积和残差连接,实现了对序列数据从局部到整体的感知。驱动序列经过TCN提取后得到抽象的高层特征表示H=[h1,h2,…,hi,…,ht],作为后续注意力层的输入。
2.2.2 注意力机制
在序列的时间维度上,并非每个时间步对产品收率都具有相同的贡献,因此采用注意力机制来对每个时间步的重要性进行定量赋值。这里将注意力机制作用于经TCN提取后的高层特征表示H。将hi输入一个单层MLP(多层感知机)得到ut,其中,引入了权重参数Ws和偏置参数bs,再通过softmax函数计算得到标准化的注意力权重αi,最后计算注意力权重αi和高层特征表示H的加权和,得到处理后的过程信息M。计算公式如下:
ut=tanh(Wshi+bs)。
(7)
(8)
(9)
式中:us,Ws,bs均为随机初始化,并将随着模型的训练不断学习优化。
2.2.3 BPNN回归器

2.3 模型训练与评价
基于构建好的深度网络模型,使用训练集训练模型参数,使用验证集对模型进行初步评价并优化模型超参数,最后使用测试集对模型进行最终评价。
在模型的训练和验证阶段,以均方根误差(MSE)作为模型损失函数L,计算公式如下:
(10)

使用基于梯度下降算法的Adam优化器不断更新和优化模型参数,以减小模型的损失函数值。此外,使用提前停止(Early Stopping)防止模型过拟合,即当验证集的损失函数不再减小时,则停止训练。
在模型测试阶段,使用平均绝对误差(MAE)、均方根误差(MSE)和决定系数(R2)作为模型的评价指标,其中MAE和MSE越小以及R2越大则表明模型性能越好,计算公式如下:
(11)
(12)
(13)

3 案例研究
3.1 案例描述
本案例以中国西北地区某炼化厂的催化裂化装置为建模对象,验证所提建模方法的有效性和实用性。该装置的年生产能力为3×106t,其工艺流程如图1所示。基于2016年10月到2017年4月期间的实际运行情况收集数据。从炼化厂的DCS系统中收集了51个工艺变量信息,包括温度、压力、流量、液位等信息,以及5个产品的流量信息,分别是干气、液化气、汽油、轻柴油和重柴油。由于建模目标为预测产品收率,故通过以下计算公式将产品流量转化为产品收率:
(14)
式中:yi表示第i个产品的收率,Fi表示第i个产品的流量,∑Ffeed表示总的原料流量。
此外,考虑到物料性质对产品收率的重要性,从炼化厂的LIMS系统中收集了11个性质变量,包括了原料性质和催化剂性质。因此,5个产品收率信息对应于本次建模任务的目标序列,其余62个变量信息则对应于驱动序列,数据收集情况见表1。
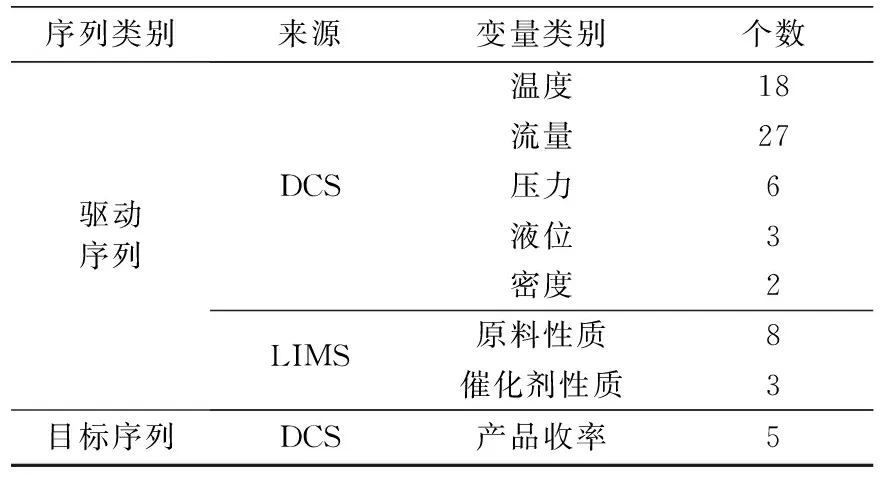
表1 数据收集情况统计Tab.1 Data collection statistics
由于DCS系统的分析频次是10 min,而LIMS系统的分析频次是24 h,存在数据不对齐问题,此外还存在着数据缺失、离群点和噪声等问题,因此有必要进行数据的预处理,其主要步骤为:(1)使用线性插值法对LIMS数据进行扩充,使之与DSC数据对齐;(2)使用三西格玛规则检测离群点,检测出的离群点标记为新的缺失值,所有缺失值均使用线性插值法进行填补;(3)使用移动平均法对数据进行降噪;(4)对数据进行归一化处理;(5)使用滑动窗口法构造多元时间序列的监督数据集,并按照时间先后顺序进行数据集划分。
经过以上步骤,共得到26 000条样本,其中,22 000条作为训练集,2 000条作为验证集,2 000条作为测试集。为了进一步观察数据集之间的关系和差异,使用主成分分析法(PCA)[25]将数据集维度降低至二维,即PC-1和PC-2,并绘制出如图3所示的数据分布图。图中训练集和验证集存在部分重叠,而测试集与前两者几乎没有重叠,说明数据集样本间的差异随时间推移越变越大,进一步反映出催化裂化过程的时变性,即其运行状态随着时间不断发生变化。因此,按照时间先后顺序划分的数据集,有利于测试模型的外推能力。

图3 经PCA降维后的数据分布图Fig.3 Data distribution after PCA dimensionality reduction
模型的超参数设置由网格搜索法确定,其中,时间步t为24,卷积核大小k为2,TCN网络层数为4,TCN隐藏层单元数为48,BPNN隐藏层单元数为32,随机失活率dropout为0.02,学习率为0.000 2,最大训练代数为5 000。以上工作中,所有程序均使用Python语言编写完成,并在macOS和Linux平台上部署。其中,深度学习算法使用开源深度学习框架Pytorch[36]实现,并通过1个RTX-2080Ti GPU进行训练。
3.2 结果与讨论
3.2.1 模型预测结果
基于上述真实的催化裂化工业数据,将所提建模方法分别应用于干气、液化气、汽油、轻柴油和重柴油共5种产品的收率预测场景。图4分别给出了模型训练与验证的损失函数值随训练代数的变化趋势,可以观察到,随着训练代数的增加,每个场景下的模型训练与验证损失函数曲线均呈现出平稳下降趋势,并最终收敛于0附近,说明模型训练过程是稳定且充分的,同时也证明不存在模型过拟合问题。

图4 模型训练与验证的损失函数值随训练代数的变化Fig.4 Variation of loss function value of model training and validation with training times
模型预测值与实际工业值的对比如图5所示,每一个场景都包含3个子图,分别从不同的角度来进行对比。在中间的时序图中,预测值曲线和工业实测值曲线均保持紧密贴合,并且具有一致的发展趋势;在左上角的奇偶图中,预测值和工业值均沿着对角线均匀分布,并且几乎都落在±5%的误差范围内;在底部的残差图中,残差沿着水平轴上下随机分布,并且具有较小的震荡幅度。3种子图均说明所提建模方法具有不错的预测表现。表2给出了模型的评价结果,对于5个不同的产品收率预测场景,模型评价指标MAE均小于0.1,MSE均小于0.02,并且R2均超过了0.95,其中干气、液化气、轻柴油和重柴油的R2超过了0.98,说明所提建模方法具有较高的预测准确度。以上分析表明所提建模方法能充分挖掘催化裂化的过程信息,并将其准确地映射到产品收率,同时也能很好地适应于不同产品收率的预测场景。

表2 模型评价结果Tab.2 Model evaluation results

图5 模型预测值与实际值的对比Fig.5 Comparison between predicted value of model and actual value
3.2.2 注意力机制的作用
注意力权重的高低与对应位置信息的重要程度呈正相关,高权重的输入单元对于输出结果具有决定性作用,因此可以通过时间注意力权重来表征输入序列上每个时间步的重要性。考虑到汽油是催化裂化最重要的产品之一,本文以其收率预测场景为例,来说明注意力机制在模型中的作用。图6给出了基于训练集获得的汽油注意力权重热力图,图中每3天计算一次注意力权重的平均值,其数值的高低表现为热力图颜色的深浅。从该图中可以观察到,注意力权重从左至右呈现出递增的趋势,并且高注意力权重主要集中在时间步17到24之间,说明0到80 min内的过程信息(1个时间步为10 min)对汽油收率预测的贡献程度最大。这与现实中的经验保持一致,即与预测目标离得越近,特征的重要度会越高。然而,这种时间上的滞后性并不是保持固定不变的,从2016年10月到2017年3月中旬,注意力权重分布由向左集中逐渐变得分散,说明在这段期间内对汽油收率预测有重要影响的时间窗拉长了。这种现象仅凭经验是难以观察到的,并且造成这种现象的原因可能非常复杂。一方面,催化裂化是动态连续过程,其运行状态和操作模式本身就处于动态变化之中,另一方面,原料波动、设备故障、环境干扰等因素也可能会造成序列时滞性的变化。因此,注意力机制通过对不同时间步的重要性进行定量分配,使模型在进行信息提取过程中有效地捕捉到了序列时滞性的变化,进而使得所提建模方法更加适用于复杂动态系统的过程建模。

图6 汽油收率预测场景的注意力权重热力图Fig.6 Heat map of attention weight for gasoline yield prediction scenario
3.2.3 模型的竞争性
为了进一步验证所提建模方法(Attention-TCN)的合理性和可靠性,进行了不同模型的对比试验,对比模型包括Attention-TCN、TCN、Attention-LSTM和LSTM。所有模型均基于同一数据集,并且除模型搭建部分更换为对应模型外,其余步骤均与第二部分介绍的研究方法保持一致。表3给出了不同模型的评价结果对比,可以看出,就MAE、MSE和R2表征的模型准确性而言,Attention-TCN在5种产品收率预测场景下均优于其他模型。从模型主体结构来看,每个产品收率预测场景下的Attention-TCN均优于Attention-LSTM,TCN均优于LSTM,这种优势来源于TCN采用了先进的并行卷积结构,从而具有更为强大的局部感知能力和记忆能力,而LSTM受限于其串行结构,在信息传播过程更容易造成信息丢失。从是否应用注意力机制来看,每个产品收率预测场景下的Attention-TCN均优于TCN,Attention-LSTM均优于LSTM,说明注意力机制对于序列时滞性变化的捕捉,有效地增强了模型的预测性能。

表3 不同模型的评价结果对比Tab.3 Evaluation results of different models
4 结 论
本文提出了一种结合时间卷积网络(TCN)、注意力机制和反向传播网络(BPNN)的催化裂化过程建模方法。利用某实际催化裂化装置7个月的生产数据进行案例研究,分别预测干气、液化气、汽油、轻柴油和重柴油的收率,研究结果证明了所提建模方法的有效性和实用性。与其他建模方法的对比表明,采用并行结构的TCN比采用串行结构的LSTM更加适用于催化裂化的时序建模,此外,注意力机制通过对不同时间步的重要性进行定量分配,进一步提升了模型的预测性能。综上,本文所提出的建模方法具有较高的预测精度和竞争性,并且能适应于不同产品收率的预测场景。在未来的工作中,需要进一步提高模型的敏捷性和计算效率,并将其应用于催化裂化工艺的在线控制与优化,从而进一步提升催化裂化装置的经济效益。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
能源化工(2021年2期)2021-12-30
石油石化绿色低碳(2019年6期)2019-01-14
石油石化绿色低碳(2019年6期)2019-01-14
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广东石油化工学院学报(2016年6期)2016-05-17
当代化工研究(2016年6期)2016-03-20
化工进展(2015年6期)2015-11-13
合成化学(2015年5期)2015-03-26
