
深度学习模型的矿业工程学科知识图谱构建
2023-09-02 07:06王海玲刘兴丽范俊杰
黑龙江科技大学学报 2023年4期
王海玲, 康 华, 刘兴丽, 范俊杰
(1.黑龙江科技大学 计算机与信息工程学院, 哈尔滨 150022; 2.黑龙江科技大学 矿业工程学院, 哈尔滨 150022)
0 引 言
随着人工智能技术的发展,数据挖掘、知识问答、聊天机器人、知识推荐等得到飞速发展。其中,知识图谱以其结构化的知识网络表示特点受到广泛关注。知识图谱是一种由于实体与关系关联的语义网络,可形成多源异构的知识互联,有效解决了数据离散、知识孤岛问题。
知识图谱可将矿业工程相关学科、专业知识形成统一、互联的知识形式有利于领域知识供给,在能有效支撑矿业知识检索、矿业智能决策与推荐,在商业与教育领域具有极高价值。
近年来,与矿业工程相关的知识图谱研究取了一些进展。如煤矿安全监测相关元素的本体构建[1]、煤矿安全事件知识图谱[2]、煤矿生产环节的科学知识图谱[3-4]、煤矿设备知识图谱[5]、煤矿安全建设知识图谱[6],矿业相关研究方向热点分析[7-11]。然而,在矿业工程领域并没有学科层面的知识图谱。目前,世界各国并未在学科的严格界定形成统一标准,但对学科度量达成了较为统一的共识,即学科包含人才培养、科学研究、梯队建设、社会服务等维度,其中,课程与科学研究是国内学科评价的基础与核心元素。文中以此为研究对象,通过知识图谱将学科、课程、科学研究等相关的分散的知识予以整合并且持续更新,帮助学生、教师及科研人员快速掌握专业知识体系,获取研究动态,以有效支持矿业工程学科的教育辅助、知识检索、知识推荐及知识问答,为矿业工程学科建设提供基础知识支撑。
鉴于此,笔者构建一种矿业工程学科知识图谱(Mining engineering disciplinary knowledge graph,MEDKG)。设计矿业工程学科的知识图谱本体模式,指导矿业工程学科的知识抽取,采用基于RoBerta-BiLSTM-CRF的深度学习模型,支持多源异构的知识抽取,有效提高知识抽取的精确度、准确率以及F1值,给出多特征的知识融合方法,实现大规模知识的自动更新。
1 知识图谱本体设计
1.1 知识图谱本体模式
本体模式是一种抽象化及语义化且概念化的规范,包含实体类型、属性及关系,是知识图谱的核心。为保证本体模式质量,文中在领域专家的指导下设计与构建MEDKG本体,其中,领域专家由来自矿业工程学科的专业教师组成,参考资料为矿业工程学科指南、专业大纲、课程大纲、教案、教材以及行业标准。MEDKG的构建目标是为矿业工程学科建设、高等教育与科学研究提供全面、动态的关联知识,因此,MEDKG本体划分为课程知识、专业知识与学科知识三个层次,如图1所示。具体包括课程知识、专业知识和学科知识。

图1 MEDKG本体模式Fig.1 Ontology scheme of MEDKG
(1)课程知识:关注矿业工程学科的专业技术知识,主要包括采矿工程与矿物加工工程专业的课程、章节、知识点等实体类型及其关系。
(2)专业知识:关注专业技术之间的关联性,涵盖采矿工程、矿物加工工程、安全技术及工程、交通运输工程、石油工程、油气储运工程、矿物资源工程、海洋油气工程、地质工程、地质勘探工程及冶金工程等二级学科实体及其关系。
(3)学科知识:关注专业技术研究动态,包括矿业工程领域的研究课题、领域相关文献、研究机构、研究人员与研究热点等内容,以助力科学研究。
1.2 实体及其属性
关系类型决定知识图谱质量的关键因素。MEDKG本体关系旨在将课程知识、专业知识与学科知识三种实体类型进行知识互联,形成立体、全面、完整的领域知识体系,既关注具体实体类型内部实体之间的关系,也注重不同实体类型之间的关系。MEDKG本体中部分实体与关系,如表1所示。

表1 MEDKG本体的部分实体与关系
属性用于描述实体类的特征、特性等信息,具有丰富实体语义表达的作用。通过深入研究科研者、教师、学生以及应用者的使用需求,矿业工程学科知识本体中部分实体类的属性,如表2所示。为适应未来知识图谱应用需求,矿业知识图谱本体都设计了灵活的扩展性,以支持后续实体属性动态更新。

表2 MEDKG本体的部分实体属性
2 知识图谱构建
知识图谱构建是将多源异构数据组织成知识过程。为保证知识图谱的鲁棒性,MEDKG构建主要分为专家级的轻量级知识图谱与基于深度学习模型知识抽取的动态知识更新两个阶段,前者采用人工方式由专业教师根据本体构建部分学科知识图谱,其数据规模较少,知识不完备,之后利用后者进行知识扩展,如图2所示。

图2 MEDKG构建Fig.2 Construction of MEDKG
2.1 数据准备
数据准备阶段主要从两种角度收集数据,其一是专业资源,主要包含矿业工程学科及其11个二级学科的课程大纲、教材、教案等专业化的237套电子资源;其次是通过数据抓取技术从MOOC、51CTO、百度百科等合法平台获得矿业工程学科领域的结构化、半结构化以及结构化数据。通过人工筛选,基于规则的数据清洗等处理后形成矿业工程学科的知识抽取语料集。利用小样本数据增强技术[12]生成部分语料集。统计数据如表3所示。

表3 语料集统计
2.2 轻量级矿业工程学科知识图谱构建
轻量级MEDKG构建是在领域专家的指导下,采用众包方式由专业教师从矿业工程学科指南、教学大纲、教材、教学计划等专业材料中提取核心主题词,专业技术、课程、知识点等实体、属性及其关系,组建领域词典,经过专家审核后,采用批量映射方法导入Neo4j图知识库,从而构建兼具准确度与鲁棒性的轻量级的矿业工程知识图谱。本节共创建11个二级学科、126个专业技术、56门专业课程,12个重要研究机构等相关实体、属性及其关系的轻量级MEDKG,其数据统计,如表4所示。

表4 轻量级MEDKG
2.3 基于深度学习模型的知识抽取
在线资源具有丰富的专业数据,因其规模性与离散性使得知识抽取成本较大。随着CNN、RNN和GNN等神经网络结构,以及BERT、Grover和XLM等预训练语言模型的提出,基于深度学习模型在知识抽取方面取得显著成效,此类模型的知识抽取技术由嵌入层、编码层与解码层组成,难点在于合理的算法选择。
嵌入层是将文本数据转化为向量化表示,2018年,提出的BERT[13]在11项自然语言处理任务中达到了SOTA效果,然而BERT静态掩码机制与字粒度掩码使其产生OOV(Out of vocabulary)问题。为突破上述问题,文中采用RoBERTa-WWM语言模型,其中,RoBERTa[14]采用了动态掩码机制,可使训练的语言知识适应性更强。该模型采用的Transformer结构可将神经网络学习到知识加注于token表示,另外,WWM (Whole word masking)[15]为全词粒度掩码,可提取语句的获得字符级语义特征,提高中文语言模型的语义表达。
编码层采用双向长短期记忆网络(Bi-directional long short-term memory,BiLSTM),该模型的每个神经元都包含遗忘门、输入门、输出门,最终输出结果是由双向LSTM隐含层向量拼接而成。模型在遗忘门丢弃无效信息的公式为
ft=σ(Wf[ht-1,Xt]+bf)。
(1)
在输入门保留重要信息特征的公式为
it=σ(Wi[ht-1,Xt]+bi)。
(2)
输出结果的公式为
Ot=σ(Wo[ht-1,Xt]+bo),
(3)
Ct=ftCt-1+ittanh(Wc[ht-1,Xt]+bc),
(4)
ht=ottanh(Ct),
(5)
式中:ft——遗忘信息;
it——保留信息;
Ot——输入结果;
Xt——输入信息;
ht-1——前一时刻的隐藏状态向量;
Ct——控制状态。
BiLSTM增强了神经元的记忆力,关注输入上下文的语义特征。然而,BiLSTM无法学习到标签间的关联性。为了解决上述问题,在解码层采用条件随机场(Conditional random field,CRF),该模型可根据输入序列x=(x1,x1,…,xn),输出其标签序列y=(y1,y1,…,yn)的条件概率分布,其公式为

式中:y*——Viterbi算法预测得到的最优标签预列;
S(x,y)——输入序列对应输出序列得分;
Ei,j——标签识别标签的概率;
Tyi-1,yi——标签转移为标签的得分;
p(y|x)——对于输入预列的输出概率;
log2(p(y|x))——损失函数。
2.4 知识融合
知识融合将新获取的知识映射到矿业工程学科知识图谱中的过程,是知识图谱扩展与更新的关键。文中关注知识图谱的可持续更新。在知识融合中,待融合实体与目标实体往往文字表达不同,语义相同或相似,并且上下文语义一致。因此,提出基于实体特征与语义特征协同的知识融合方法(Multi- feature collaboration from entity and semantic, mFCES)。
对于每一个实体指称Ec,采用最长公共子序列(Longest common subsequence,LCS)算法与获得候选实体集L(Xm,Yn),计算公式为
式中:Xm——长度为m的序列;
Yn——长度为n的序列。
对于实体指称与其候选实体集合Em,通过归一化处理衡量两者的匹配度,计算公式为
(8)
式为:Lll——实体指称与候选实体LCS处理所后的长度的LCS长度;
Lcl——当前候选实体长度。
为增强语义特征,利用大规模领域语料训练fastText词向量[16],fastText模型引入子单词信息,增强了词义表征,与其他深度学习模型相比,在保证相同准确率的前提下具有高计算率。文中采用fastText的N-gram向量化度进行知识表示,然后计算其余弦相似度为
(9)
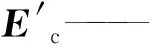

此外,借助轻量级矿业工程知识图谱的实体信息作为筛选条件,在实际应用中,实体的重要度通常可由该实体与其他实体的关联性体现,文中采用实体的出度与入度和计算其重要度,公式为
(10)
式中:Et——当前候选实体的热度值;
Ei——候选实体。
知识融合的目标实体将式(8)、(9)和(10)进行平均,计算公式为
(11)
3 研究结果分析
3.1 实验环境与评估指标
实验环境配置为Ubuntu的Linux操作系统,GPU为NVIDIA GeForce RTX 2080 Ti,程序IDE是Python3.6.0,预训练架构为Tensorflow2.2.0。
实验评估指标采用通用的精确率P、召回率R与F1值,计算公式为
式中:TP——知识抽取模型能正确抽取数量;
FP——将错误知识作为正确知识抽取的数量;
FN——将正确的知识判断为错误的知识的数量。
三个指标的值越高表示知识抽取模型的性能越好。
3.2 知识抽取
知识抽取实验是将处理好的数据集划分为训练集、测试集与验证集,其比例为7∶2∶1。实验在训练集上进行多轮训练,调整参数,性能稳定后在测试集进行测试,最后在验证集上进行文中方法的性能验证。文中方法的参数设置是Batch_ size与Seq_max_len参数为256,RoBerta 学习率为5×10-5,BiLSTM学习率为8×10-3,LSTM单元数为128,优化器为Radam,Dropout为0.4。
为了验证文中深度学习模型的有效性,对决定模型性能的嵌入层与编码层进行方法替换验证,嵌入层选择Word2vec替换RoBerta-wwm,编码层选择LSTM以及与BiLSTM类似的双向循环神经网络BiGRU替换BiLSTM。由于矿业工程学科知识抽取过程中涉及多类实体,且数据集中存在类别不均衡情况,文中多个实体类型的宏平均值进行比较说明。宏平均值是先对不同实体类型统计其评估指标,再计算所有实体类型评估指标的算术平均值。文中深度学习模型与其他模型在知识抽取中的实验结果对比,如表5 所示。

表5 知识抽取实验结果
由表5可知,在知识抽取中,采用Word2vec和Bert语言模型的评估指标均低于RoBERTa-wwm模型,经分析其原因是word2vec为双层神经网络,其词向量忽略词与词间关系,Bert采用静态随机掩码策略,只能关注字级别语义特征,而RoBERTa-wwm的全词动态掩码很好地提取词 的级语义特征。因此,RoBERTa-wwm模型取的F1值比Word2vec提高了3.7%,比Bert提高了2% 。在编辑层测试中,模型BiLSTM、BiGRU均比LSTM性能好,说明句子上下文信息对知识抽取任务很重要,而双向网络结构能关注到句上下文特征。BiLSTM模型优于BiGRU模型,原因在于BiGRU的参数与门控机制简单,无法提取更多语义特征。实验结果表明,文中基于深度学习模型(表5中加粗行的模型)的知识抽取方法性能最优。
3.3 知识融合
首先对fastText的N-gram的取值进行实验,实验数据,如表6所示。
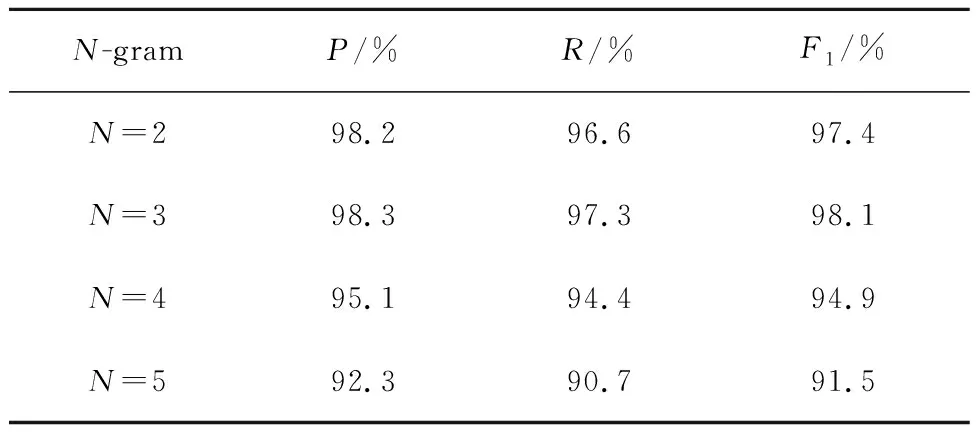
表6 N-gram值对知识融合影响
实验结果表明,组成词子序列的词元并非越多越好,词元越多会引入噪声,影响语义表达的准确性,实验证明文中fastText取3元语法效果较好。
知识融合实验中,文中的多特征知识融合方法(mFCES)与Levenshtein Distance算法以及Bert向量的余弦相似度方法(Bert-Cosine)进行实验对比,实验结果,如表7所示。

表7 知识融合实验对比
由表7可知,文中提出的实体特征与语义特征协同的知识融合方法优于Edit Distance算法以及Bert词嵌入的余弦相似度方法,这是因为Levenshtein Distance并没考虑语义相似或关联特性,Bert词嵌入也只关注了字级别特征,特征信息不足,而文中方法即考虑了词级语义特征也关注了实体特征。
4 矿业工程学科知识图谱可视化分析
在矿业工程学科知识图谱本体模式的指导下,基于深度学习模型获取了海量矿业工程学科领域知识,通过多特征知识融合算法将新知识有效合并到轻量级矿业工程学科知识图谱,最终形成矿业工程学科知识图谱的实体规模约84 000个,关系规模约15 000条,文中创建的矿业工程学科知识图谱局部效果,如图3所示。
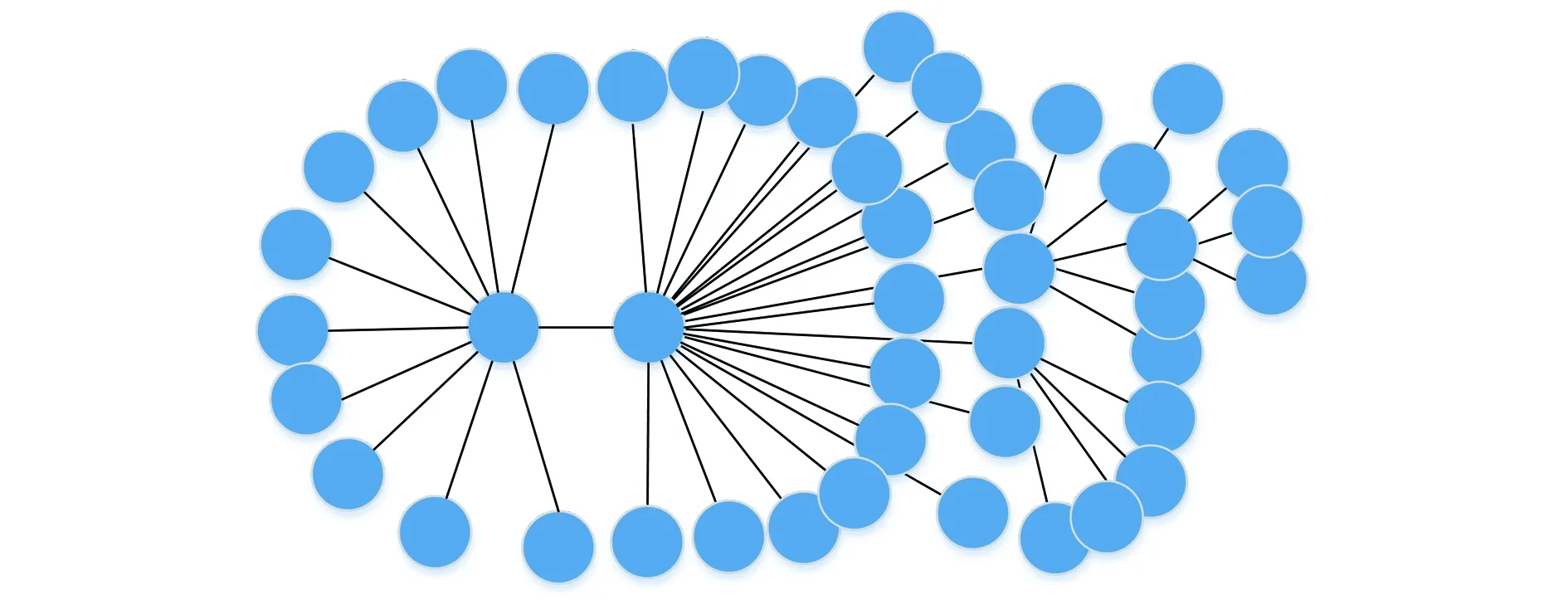
图3 矿业工程学科部分知识图谱Fig.3 Part of mining engineering disciplinary knowledge graph
文中研究成果还成功用于矿业工程学科的热点分析,矿业工程学科知识图谱与中国知网平台进行数据整合,实现的学科热点分析与评估功能,如图4所示。该应用可进行矿业工程学科知识图谱的研究机构、研究人员检索,同时还可实现矿业工程学科专业技术文献统计与研究热点可视化分析。

图4 矿业工程学科热点评价Fig.4 Subject hotspot assessment of mining engineering
5 结束语
设计了矿业工程学科的知识图谱的本体模式,在此指导下构建了矿业工程学科的知识图谱,涵盖课程知识、专业技术知识与学科知识三个知识层次,共包含矿业工程学科的所有二级学科、126种技术以及采矿工程与矿物加工工程的专业课程知识,实体规模约84 000个,关系规模约15 000条。为了保证知识图谱构建质量与效率,采用人工构建与深度模型自动化知识抽取与扩展策略相结合,其中,基于深度学习模型的知识抽取方法与多特征协同的知识融合方法,可有效支持大规模非结构化数据的知识抽取与扩展。
未来将研究多模态知识抽取以丰富在矿业工程学科知识图谱,并继续探索矿业工程学科知识图谱的知识问答、学生学习效果评估、协作学习与知识推荐等教育应用。
猜你喜欢
哲学分析(2023年4期)2023-12-21
参花(上)(2023年2期)2023-03-06
矿业安全与环保(2022年2期)2022-05-21
江苏教育·教师发展(2021年6期)2021-08-11
中国音乐学(2020年4期)2020-12-25
矿业安全与环保(2020年5期)2020-11-04
矿业安全与环保(2020年3期)2020-07-18
自然资源情报(2017年11期)2017-11-26
中国德育(2017年17期)2017-09-15
文学教育(2016年27期)2016-02-28
