
基于图卷积编码器的蒙汉神经机器翻译
2023-11-02 12:34苏依拉仁庆道尔吉李雷孝
计算机应用与软件 2023年10期
薛 媛 苏依拉 仁庆道尔吉 石 宝 李雷孝
(内蒙古工业大学信息工程学院 内蒙古 呼和浩特 010080)
0 引 言
随着全球化的不断深入,国家与国家之间、民族与民族之间的交往日益频繁,而各国家、民族之间的语言差异造成了沟通障碍。因此机器翻译成为不同国家与民族之间的沟通桥梁。蒙古语属于小语种,蒙汉机器翻译系统在解决由于语言差异引起的交流障碍问题方面作出了很大的贡献,本文主要对句法依存树提高蒙汉机器翻译系统性能进行研究。
蒙汉机器翻译主要采用两种做法:(1) 传统的基于短语的机器翻译方法[1];(2) 利用神经网络模型进行机器翻译[2]。对于神经机器翻译方法,目前的缺陷是严格依赖于序列编码器-解码框架,并且不能有效利用句子的句法信息以及语言的层次结构信息[3]。究其原因是在编码序列信息时,并没有找到一种适合的方式将结构信息纳入其中[4]。有研究采用间接的方式引入结构信息[5],还有研究对机器翻译任务中建模结构信息加以严格的限制。对比本文方法,文献[6]实现了基于非词汇化概率上下文无关文法的蒙古文句法分析系统,然后设计并开发了基于树到串的蒙汉统计机器翻译系统,与该文不同,本文的目标是为编码器提供对丰富语法信息的访问,但是让它决定语法的哪些方面对机器翻译有益,而不必对语法和翻译任务之间的交互施加严格的限制。因此尝试在源端加入句法信息作为额外知识来辅助神经系统进行翻译。
自然语言处理(NLP)的核心技术之一依存句法分析[7],该方法主要通过分析一个句子中词与词之间的依赖关系来确定其句法结构。作为底层技术,依存分析可直接用于机器翻译以提升其效果,并且对于其他NLP任务效果的提升也是显而易见。虽然神经机器翻译技术已取得了很大的进步,但其翻译效果还不及人工翻译的原因之一在于神经网络只有根据输入的平行句子进行学习和对齐[8],并没有很好地利用句子的句法结构和语义结构信息。蒙古语和汉语在语法结构中存在较大差异。蒙古语属于阿尔泰语系,其语序为主-宾-谓结构,即主语在前,谓语在宾语之后,修饰语在被修饰语之前。而汉语属于汉藏语系,在语序结构中采用主-谓-宾结构,其在谓语和宾语部分与蒙古文出现差异,并且这种结构差异会使神经网络不能完全准确地进行对齐,造成翻译性能差,倘若能对句子的句法结构进行分析后再进行编码就会解决该问题,因此本文提出在编码器端加入句法结构信息用以辅助神经机器翻译。
DDparser,其全名为Baidu Dependency Parser,是百度开源的基于深度学习框架的依存句法分析系统,其功能为对于给定的源语言句子,可将其解析为依存句法树,该系统的开源对于NLP(Natural Language Processing)的下游任务提供了巨大的帮助,输入文本通过DDParser输出其对应的句法分析树。
对于句子“那家的饭菜太淡,还很贵”的依存句法关系如图1所示。连接两词的弧表示两个词语之间的依赖关系,由核心词指向依存词,弧上的标签表示依存词对核心词的关系。其中:ATT表示定中关系,即定语和修饰词之间的关系;DE通常连接“的”与其中心词;SBV表示主谓关系,通常也用来表示系词与表语之间的关系;ADV表示状中结构,图1中“淡”是一个形容词,而“太”作为副词来修饰“淡”,因此DDparser在解析其关系时,定义为状中结构;IC表示独立分句,“淡”和“贵”都用来形容饭菜,但处于两个分句中。对于百度依存句法分析系统中还存在很多句法关系,具体请查阅文献[7]。可以看出,将这种依存句法关系加入到翻译系统中,可以很好地辅助句子的理解,使得翻译更加准确。

图1 依存句法树举例
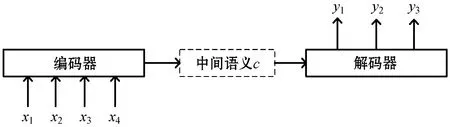
图2 编码器-解码器模型
1 相关技术
1.1 神经机器翻译
机器翻译是利用计算机将一种语言转换为另一种语言的过程[9]。给定一个含有N个词的源语言句子X=x1,x2,…,xi,…,xN和一个含有M个词的目标语言句子Y=y1,y2,…,yj,…,yM,NMT做的工作是将句子级概率分解为词级的概率的乘积:
(1)
式中:θ表示源语言与目标语言之间的转化公式。
神经机器翻译模型通常由编码器、解码器,以及构建编码器解码器之间的联系的一些方法组成,例如注意力机制,编码器接收一个源语言句子序列,将其转化为中间表示,解码器再将这个中间表示生成翻译,如图1所示。
1.2 序列编码方式
给定一个源语言句子序列,编码器的工作就是将其编码为一个计算机能够识别的连续稠密向量。编码方式有很多,包括词袋模型(Bag-of-words,BOW)、循环神经网络模型(Recurrent Neural Network,RNN)、卷积神经网络模型(Convolutional Neural Network,CNN)的编码器等,本文将重点介绍以上三种编码方式。
1.2.1BOW(词袋模型)
BOW[10]的原理十分简单,就是把一句话转换成计算机能看懂的向量形式,比如给定两句话:
(1) 我喜欢书法,晓丽也喜欢。
(2) 我也喜欢绘画。
可以构建包含所有单词的词典向量dictionary=[我,喜欢,书法,晓丽,也,绘画]。第一句话的向量表示为v1=[1,2,1,1,1,0];第二句话的向量表示为v2=[1,1,0,0,1,1]
向量的每一个维度表示词典向量中对应的单词在句子中出现的次数。不难发现这种方式虽然可以将一个句子映射为向量形式,但表示出的句子向量是无序的,它不能明确表示一个单词在句子中的相对位置,为了表明词的位置信息用了一个位置编码嵌入。通常选用整数型数字来表明词的位置信息,为该数字初始化一个列向量表示词的位置。因此词袋模型编码器可以表示为:
BOW(x1:N,i)=xi+pi
式中:pi表示位置向量。
1.2.2RNN编码器
RNN编码器[11]模型是在序列建模中应用的最多的一种变换方式,输入一个源语言句子X=x1,x2,…,xi,…,xN,传送给RNN后,RNN通过以下公式递归处理输入中的每一个词xi将其映射到实值向量中:
RNN(x1:i)=f(xi,RNN(xi))
(2)
式中:xi=x1,x2,…,xi-1;f是非线性函数,通常为LSTM(Long Short-Term Memory)或GRU(Gated Recurrent Unit),为了捕获当前词的前后文信息,一般采用双向LSTM或双向GRU,本文将采用双向LSTM。将词映射到实值向量中后,一个带有LSTM单元的前馈和后馈RNN开始分别计算其前向和后向隐藏状态。
(3)
(4)
整个源隐藏状态hi就包含着前向和后向的全部信息:
(5)
1.2.3CNN编码器
卷积神经网络对于处理网络结构的信息十分有效,最初的提出大多用于分析视觉图像。2017年Facebook AI实验室提出一款利用卷积神经网络进行机器翻译的翻译模型Fairseq,由于卷积神经网络的引入,模型不仅可以精确地控制上下文的长度,并且经过卷积的并行计算,在达到与RNN相同的翻译准确率上,速度足足快了9倍。CNN编码器[12]是用一个固定大小的窗口在输入句子序列上滑动以捕获句中每个词的局部文本信息,相比RNN,虽然CNN速度快并且可以并行计算,但缺点是牺牲了全局文本信息,而为了弥补文本信息的丢失,通常对CNN的层数进行堆叠。
CNN(x1:N,i)=f(xi-└w/2┘,xi-└w/4┘,…,xi,…xi+└w/2┘)
(6)
式中:f是非线性函数;w是窗口大小。
1.3 图卷积网络
近两年深度学习领域诞生了一种新的网络,即图卷积网络[13]。该网络从出现时就受到科学界的广泛关注,那么GCN与CNN有什么不同呢?传统的CNN网络处理的数据是矩阵形式,就像以像素点排列的矩阵为基础。而GCN处理的数据是图结构,例如像社交网络、信息网络等这些拓扑结构,一般卷积神经网络就无能为力了。
一个无向图G={N,E},其中:N是图中所有节点的集合;E是所有边的集合,包括自还边。GCN是一个多层神经网络,可以直接在图上进行操作,对节点聚合信息。通常一个图上的节点信息用一个邻接矩阵来表示。对于一层GCN,节点的向量信息聚合公式如下:
(7)
式中:W∈Rd×d是权重矩阵;b∈Rd是偏置向量;ρ是激活函数比如线性修正单元(ReLU);N(n)是节点n的邻居节点集合,包括n本身。节点信息可以通过堆叠GCN层数来进行传递,层之间的传递关系可用如下公式来计算:
(8)
对于像神经机器翻译,图卷积网络的输入是一种语言的一句话,而一个句子词与词之间是有先后顺序的,也就是说如果用有向图来处理这种句子信息会更好,已有工作对GCN进行泛化,使其能够在有向图以及边有类型的图上进行操作[14]。这就使得GCN在依存树上操作有了可能。
为了处理依存树上边的方向,根据边的类型将其分为三类:入边(IN)、出边(OUT)和自环(LOOP)。递归计算如下:
(9)
式中:dir(u,n)表示边的方向,包含IN、OUT和LOOP。对于一个节点而言,可能包含入边、出边,以及还可能给出自环,因此式(9)可以被拆解为式(10)-式(12)。
(10)
(11)
(12)
式中:WIN、WOUT和WLOOP分别表示u→n、n→u和n→n的权重矩阵;bIN、bOUT和bLOOP为相应的偏置向量。
2 编码器-解码器模型构建
2.1 编码器
传统的RNN以及CNN处理的序列数据,而神经机器翻译的发展虽然已取得了很大的进步,但是现有的翻译系统还是会出现所翻译的句子还不够通顺,并且对于一些表达不同而句意相同的句子机器不能准确地进行识别。为了同时有效利用序列的前后文信息以及句法结构信息,本文提出在源语言端采用双编码器,该思想受Eriguchi等[15]提出的树到序列注意力机制神经机器翻译的启发。不同的是Eriguchi使用LSTM编码树结构信息,而本文将使用RNN等编码源语言的原始序列数据,用GCN编码句法树结构信息。为了证明该方法对于提高神经机器翻译系统性能的有效性,将分别采用两种方式编码源语言序列数据。
(1) BiRNN+GCN。首先用双向RNN学习序列信息,之后将RNN的输出传入给GCN学习句子的句法结构信息。具体结构如图3所示。RNN编码得到的隐藏状态向量h0作为GCN的输入。
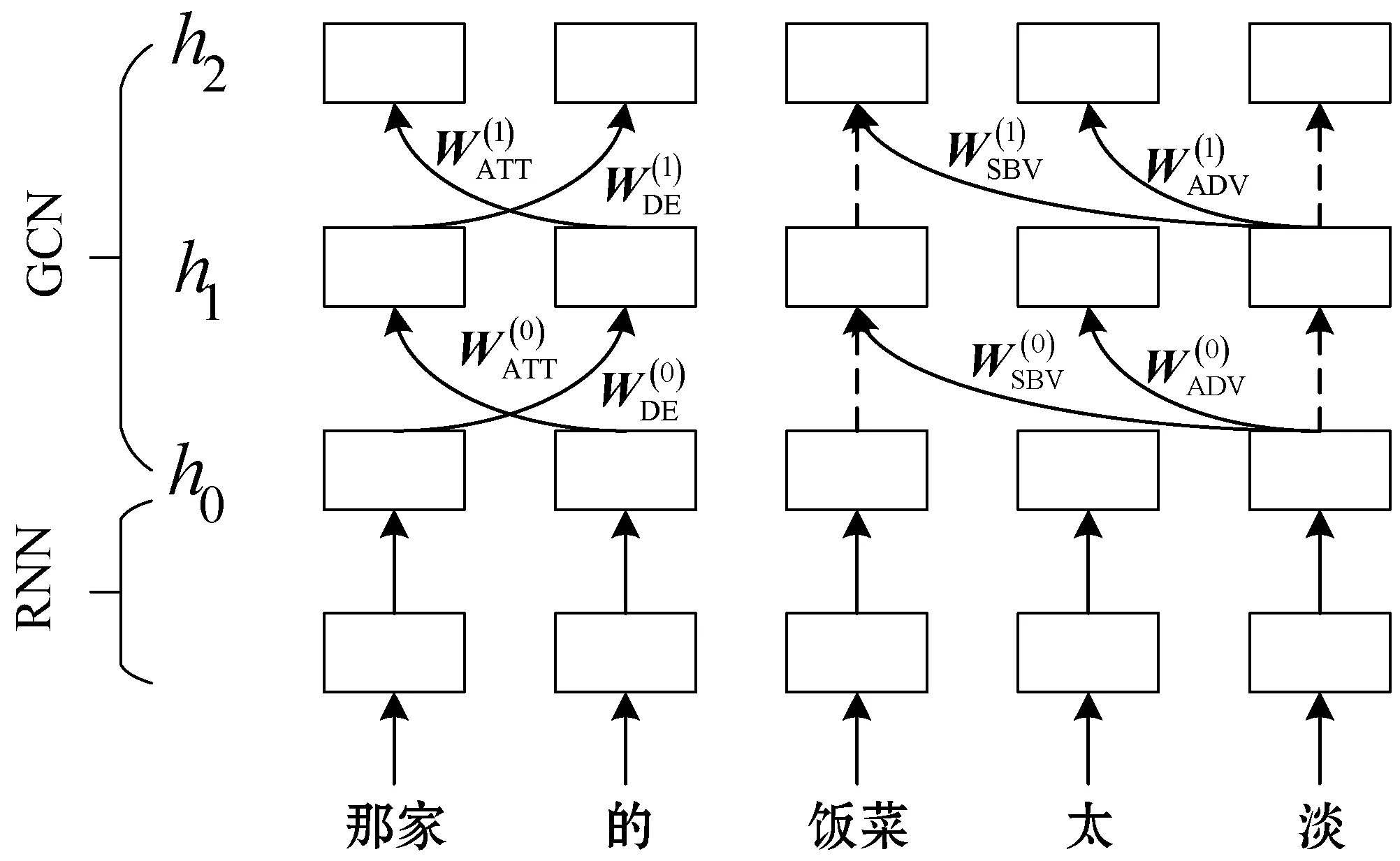
图3 RNN和GCN编码器结构关系
(2) CNN+GCN。用CNN学习词的表示,CNN虽然速度快但仅能学习局部的上下文信息,所以一般采用多层CNN来弥补这一缺点,但本文主要研究的是GCN对于神经机器翻译性能的影响,因此仅采用了一层CNN,并且CNN的窗口大小w取值为5,CNN与GCN组合编码结构图与RNN和GCN组合编码结构图相似,因此不再给出图。
2.2 解码器
解码器会根据源语言句子产生一个相应的目标序列,在本文中解码器是一个RNN,其网络单元采用LSTM,源语言句子根据编码器产生一个上下文向量ci,连同解码器产生的前一个值yi-1共同生成目标序列中的当前词。我们知道,神经机器翻译模型在训练时,它以正确标注的单词作为上下文进行预测,而在测试时,它只能从头开始重新生成整个序列。这样做的结果是训练和测试中的预测词分别来自不同的分布,训练来自于原本平行语料中的数据分布,而测试却来源于模型分布。这样做将会产生暴露偏差(Exposure Bias),并且随着目标序列的增长错误会不断累积。为了解决该问题,很容易想到在与测试相同的条件下进行模型训练,所以本文采用的方法是,首先从预测的单词中选择优质的单词集BestWords(BW),然后从BW和正确标注的单词中进行抽样,所得的结果作为上下文进行训练。使用LSTM进行解码,第j步,目标隐藏状态sj为:
sj=LSTM(ey′j-1,sj-1,cj)
(13)
目标词的概率分布Pj为:
Pj=softmax(g(ey′j-1,cj,sj))
(14)
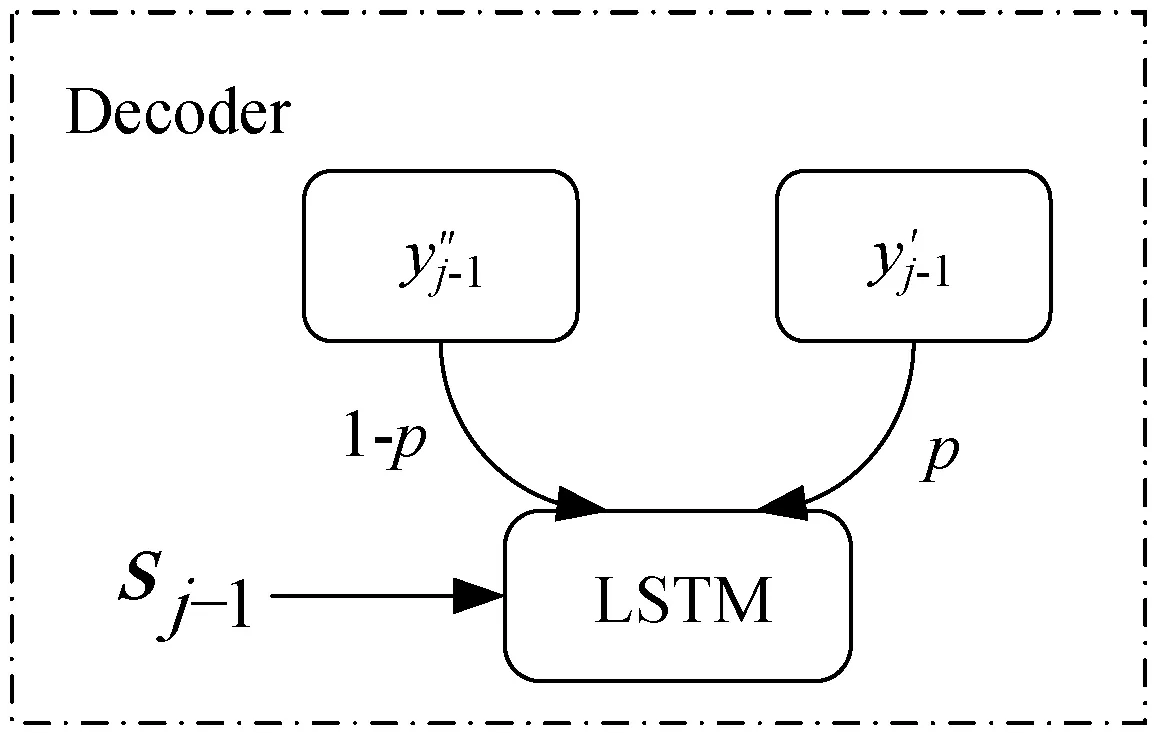
图4 解码器结构
3 实验与结果分析
本实验的技术路线如图5所示,对于蒙汉对齐语料库,在汉语端采用DDparser将其解析为依存树,同时采用BPE处理蒙古语目标端的稀有词和复合词,然后分别采用RNN+GCN和CNN+GCN作两组对比实验,通过增加训练步数,最终得到最好的翻译模型。
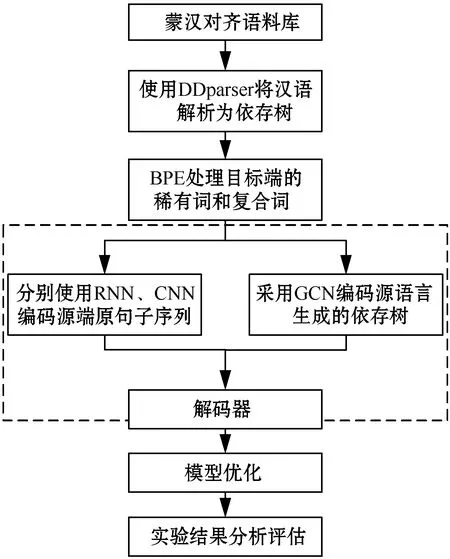
图5 技术路线
3.1 数据集来源及划分
本实验所采用的数据为由内蒙古工业大学构建的用于内蒙古自治区蒙古语言文字信息化专项扶持项目的121万蒙汉对齐语料库,包括政府新闻、法律公文、日常对话、词典条目、计算机相关术语、气象类相关术语、蒙古文谚语、日常用语和文学语句等语言信息。
对数据集划分结果如表1所示。
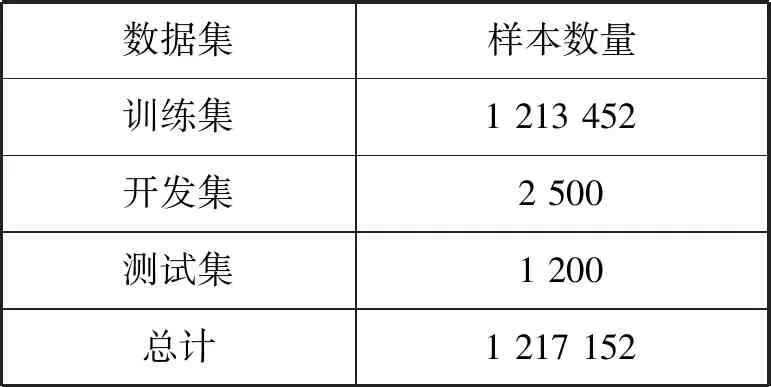
表1 数据集划分结果
3.2 语料预处理
本实验的源语言为汉语,目标语言为蒙古语,对于划分好的数据集,在汉语端采用由百度开源的中文依存句法分析工具——DDParser。将原始句子解析为依赖树。对于句子“创新是文化的生命力所在”,其经过DDParser解析后,输出结果如下:
[{′word′: [′创新′, ′是′, ′文化′, ′的′, ′生命力′, ′所在′],
′head′: [2, 0, 5, 3, 6, 2], ′deprel′: [′SBV′, ′HED′, ′ATT′, ′MT′, ′SBV′, ′VOB′]}]
为了解决蒙汉机器翻译中存在的大量稀有词和复合词问题,采用发布于github上的fastBPE对蒙古语进行BPE操作,对蒙古语采用子词级粒度[16]切分,操作数设为30 000,切分后词典大小由原来的13 827 560变为16 319 479,仅出现过一次的词由原来的314 616变为26 479,仅出现一次的词的比率由0.023下降为0.002,很好地缓解了数据稀疏问题。
对于中文采用自行编写的脚本程序字粒度切分,首先将原有的文本语料去掉标点符号生成新的文本,再将生成的文本进行逐字加空格生成新的语料文本。经过切分后词典大小由原来的11 900 543变为20 987 685,仅出现过一次的词由319 756下降到7 526,仅出现一次的比率由原来的2.69%下降为0.04%。
蒙汉平行语料分词、分字结果见表2。
3.3 模型训练及实验结果
本实验采用github上基于TensorFlow的开源工具包neuralmonkey,TensorFlow的版本为1.4.1,Python版本为3.6。采用Adam优化器,RNN模型学习率设为0.2,CNN模型学习率设为0.1,dropout设为0.2,训练步数设为150 000。LSTM和CNN编码器解码器的层数均设为4层,隐藏单元数均为512,GCN层的维度与其输入层的维度相等,并且实验发现采用两层GCN的效果更好。以上参数取值是多次实验结果最好的参数,所以模型优化主要体现在这里。因为本文主要的研究内容不在此,因此对于模型优化不作过多的介绍。本实验的基线系统有两个,其一是有哈佛大学开源的OpenNMT,其二是由Facebook AI实验室发布的基于CNN的神经机器翻译系统Fairseq,其中w=5。进行多组对比实验,得到实验结果如下:
如图6所示,为BiRNN和BiRNN+GCN随着训练步数的增加BLEU的变化图。可以看出,随着训练步数的增加BLEU值逐渐增加并收敛,并且加了GCN编码语义信息后要比直接采用BiRNN编码效果要好,当训练步数达到150 000步时,添加GCN后的BLEU值达到46.27,比基线系统(BLEU值为43.58)高了2.69个BLEU值,译文结果见图7。

图7 句子级实验结果
如图8所示,当采用CNN+GCN组合编码时,BLEU值会出现明显提高,当训练达到150 000步时,BLEU值达到43.72,比CNN基线系统(BLEU为41.63)提高了2.09。通过选择GCN层数来调节信息传播的距离:在k层中,一个节点最多可以从k跳处接收来自邻居的信息。本文通过对比实验发现:在BiRNN+GCN中,2层GCN取得更好的效果,如表3所示,其中1L、2L分别表示GCN的层数为1层和2层,+GCN表示BiRNN+GCN,可见,当采用1层GCN时,BLEU值为45.16,当采用两层GCN时,BLEU值提高了1.11,达到46.27,译文结果见图7。
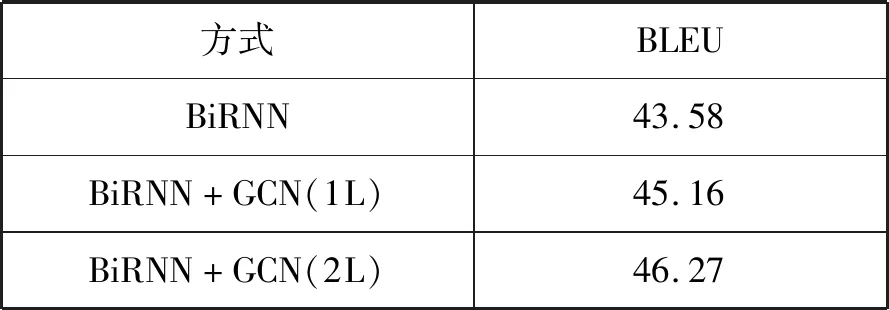
表3 GCN层数对翻译结果的影响
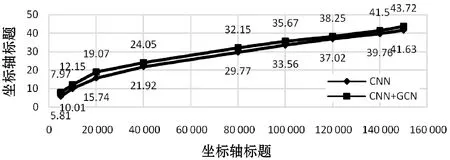
图8 CNN+GCN对比实验BLEU值变化趋势
4 结 语
蒙汉机器翻译已取得了空前的进步,但是仍达不到人类翻译的效果,一些句子翻译结果看似符合语法结构,但并不符合人类的表达习惯,原因在于现有的神经机器翻译系统并没有很好地利用句子的句法结构信息。因此本文提出将句子的依存句法树作为辅助信息来提高神经机器翻译效果,对于依存句法信息,传统的神经网络也可以进行编码,通常的做法是将句法树转化为序列信息进行编码,而本文提出直接使用图卷积神经网络编码这种句法结构信息,图和树的结构更加适应,并且采用有向图编码,能够进一步体现节点之间的关系。为了解决神经机器翻译系统在翻译时严格对照给定语料作为参考,对于一些意思相近而表达不同的结果,神经网络在学习时会严格进行校正,导致一些本来正确的翻译被淘汰掉,本文提出将预测出的优质翻译结果加入到下一步的训练过程中,可以有效解决上述问题。为了解决神经机器翻译中出现的复合词和未登录词对于翻译质量的影响,本文提出采用BPE,对蒙古语进行子词级切分,对汉语进行字粒度切分。以上方法结合,最终的翻译结果得到显著提升,并且为蒙汉机器翻译提供了一种新思路。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
考试周刊(2015年36期)2015-09-10
