
基于粒子群优化算法的模型超参调优方法应用研究
2023-11-02 13:02铁锦程赵战营
计算机应用与软件 2023年10期
铁锦程 赵战营
(上海浦东发展银行 上海 200120)
0 引 言
大数据、人工智能、云计算等技术的发展,推动着每一家金融机构探索科技创新赋能业务增长。ABCD(AI人工智能、Blockchain区块链、Cloud Computing云计算、Big Data大数据)是金融科技创新发展的核心技术,金融行业良好的信息化建设与规范的大数据资源管理,为人工智能在获客、风控、营销等领域应用落地打好了坚实的基础。数据是金融发展的重要战略资源,数据驱动信用卡业务的发展,迫切需要提升数据价值应用的效率和效果,机器学习技术通过AI算法对历史样本数据进行学习,生成对未来的数据进行预测的模型,广泛应用于获客、营销、风控、合规、消保等信用卡经营管理业务。
机器学习模型是数据价值应用的有效手段,然而数据和特征决定了机器学习效果的上限,而模型算法决定了逼近这个上限的程度。机器学习模型的性能与超参数直接相关,如何在现有数据特征的基础上,提高机器学习模型的效果很大程度上取决于模型超参数调优(Hyper-Parameters Optimization,HPO)。超参调优是机器学习工作流中最难的工作,多组可调整参数构成的高维连续数值空间中存在海量的参数组合,每次调整后,都需要利用训练得到的模型的准确率和泛化能力作为参数调优的评价标准[1]。人工调参是一种反复试验的方法,需要消耗大量的时间,所得到的结果也无法保证是最佳的参数组合,因此诞生了很多自动化超参数优化的方法。本文提出基于粒子群优化算法的模型超参数调优方法,通过设置偏移量、惯性系数、个体学习因子和群体学习因子等超参数初始值,随机选定若干组模型参数组合生成初始粒子群,通过动态更新惯性系数和偏移量来动态更新模型参数组合,不断循环迭代,直至模型参数近似最优。通过对比实验验证,与常用的网格搜索、随机搜索、贝叶斯优化等调优方法相比,本文提出的基于粒子群优化算法的模型超参数调优方法能够提高调参效率,在相同的样本集上使用该方法进行模型参数调优,通过多轮迭代逐步逼近最优解,更容易达到预期的模型效果目标,能够提升机器学习模型的预测精度和泛化能力。
1 模型超参数优化问题研究
1.1 模型超参数优化及其重要性
随着互联网、大数据、人工智能技术的发展,新生信息层出不穷,知识总量爆炸式增长,为数据价值的挖掘提出了新的挑战,机器学习能够发现和挖掘数据规律,并应用于对未来的预测,实现数据价值驱动业务增长。然而,机器学习模型的开发和应用,既需要对业务的深入理解,又需要统计、算法理论分析等知识技能,门槛相对较高、流程较为繁琐。业务分析人员完成模型定义之后,机器学习模型的开发应用主要涉及如下五个阶段,如图1所示。
机器学习算法模型的参数包含模型参数和超参数两类,模型参数是在训练过程中可进行自动优化或学习得到的参数,不需要手动设置;超参数是在模型训练之前设置的,用于控制模型拟合数据的灵活性,无法通过数据学习得到,需要用户手动配置[2]。在机器学习模型开发应用涉及的主要阶段中,超参数优化的目的是对模型超参配置进行调优,使得训练产出的模型具有较好的业务效果、稳定性和泛化能力。模型超参数优化是一项繁琐但至关重要的任务,直接决定着模型效果的优劣,很大程度上影响了算法的性能。一个机器学习模型中,一般有着多个超参数,每个超参数可调整的数值范围是非常广的,也就是说,参数调优是在多维连续数值空间内,找到最优的一组参数组合,使模型效果最优。这个难度是非常大的,且不同机器学习模型的超参数并不一致,更增加了模型参数调优的困难。传统参数调优时,需要高度依赖建模人员经验,对参数进行不断的调整优化,才能获得较优性能,整个过程非常费时费力,且需要较高的专业领域知识。因此,如何实现自动化的超参数优化是机器学习中研究的重点。
1.2 模型超参数优化问题分析
为机器学习算法选择较好的超参数是机器学习领域的一项重要研究课题,研究自动模型超参数优化方法,对于解放建模人员、快速寻找性能较好的模型超参数组合,提升模型参数调优的效率等具有重大的意义。自动超参数优化的方法主要有网格搜索、随机搜索、贝叶斯优化、种群智能类方法等。(1) 网格搜索方法[3]对参数区间进行网格化,并通过遍历网格参数的所有可能组合,来获得最优结果,以提高机器学习最优参数的搜索效率。网格搜索法通过改变步长来提高参数搜索效率,参数的范围和设置的步长会影响模型参数调优的速度,而且需要遍历所有可能的组合,所以网格搜索法只能在参数较少且取值范围较窄的模型中应用,在大规模的参数空间下性能往往表现很差。(2) 随机搜索方法[4]和网格搜索类似,也需要在参数空间对参数进行搜索,但是搜索样本点的选取服从概率分布,随机搜索可以通过固定数量的搜索寻找到近似最优参数组合,得到的结果比网格搜索更好。但是随机搜索没有利用先前表现良好的区域,缺乏先验经验的使用造成存在大量不必要的评估,且不能保证寻找到的是最佳参数组合。(3) 贝叶斯优化方法[5-6]以高斯回归模型作为代理模型,用先验经验与样本信息进行综合,不断更新代理模型并产生新的采样点,通过多次迭代从而产生最优超参数组合。贝叶斯搜索方法也可用来提升参数调优效率,但是贝叶斯搜索方法需要根据实际问题,结合相关领域知识选择合适的代理函数与采集函数,而不同机器学习模型的参数是多样的,很难找到一个全局的代理函数来近似。(4) 种群智能类方法,创建预定超参数的多个机器学习模型,通过模拟种群行为寻找最优变化趋势,并据此调整搜索行为,从而找到最优超参数组合。实践证明机器学习模型与种群智能方法相结合的超参数优化方法具有较好的应用效果。基于此,本文对粒子群优化算法进行改进,提出一种基于粒子群优化算法的模型超参数调优方法。
2 基于粒子群优化算法超参数调优方法
2.1 粒子群优化算法
粒子群优化算法[7](Particle Swarm Optimization,PSO)是Kennedy等提出的一种基于群体智能的优化方法。算法模拟了鸟类觅食的行为,由于鸟类在寻找食物时的有效策略是按照最近的飞行路径进行搜索,算法模拟了该行为。PSO中每个粒子都代表优化问题的一个可能解,通过搜索每个粒子的最优解,并和粒子群整体共享,从而达到优化的目的。Shi等[8]对原始PSO进行优化,在速度更新公式中引入了惯性权重(w),惯性权重表明了对前一步粒子速度的继承程度,含惯性权重的PSO称为标准粒子群优化算法(SPSO)。SPSO的速度迭代公式可由式(1)表示。
(1)
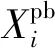
2.2 惯性系数自适应调整策略
研究表明,随着进化过程深入,惯性系数设置为递减有助于算法优化性能的提高,取值范围一般认为在0.4~0.9[9-10]。为使惯性系数能够随着搜索进程进行动态递减,本文提出一种新的惯性系数更新的方法,具体为:更新的惯性系数=前若干轮迭代的惯性系数的均值×剩余迭代轮次+(模型参数组合中参数总数-本轮次更新的参数个数)/模型参数组合中参数总数,数学表达方式如式(2)所示。
(2)
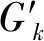
改进后的惯性系数能够跟随算法的迭代运行而动态调整,扩大了算法的搜索空间,在初期能够对全局进行充分探测,并在后期能够针对可能有最优解的区域进行重点搜索。因而本文的粒子群算法在进行迭代过程中,每个粒子都能够进行动态迭代更新,动态更新的惯性系数使得粒子寻优方法在性能上有所提高,针对不同的规模的数据都具有调整全局和局部的搜索能力。
3 基于粒子群优化算法超参数调优过程
3.1 机器学习模型超参数调优问题定义
基于粒子群优化算法的参数寻优过程可归纳成对一个数学优化问题的求解过程,该问题定义如下:设α1,α2,…,αn为机器学习模型的n个超参数,ek为机器学习训练模型的损失函数,则基于粒子群优化算法的参数寻优问题定义如式(3)所示,约束条件如式(4)所示。
minek=F(α1,α2,…,αn)
(3)
s.t.αi∈[αimin,αimax]
(4)
式中:αimin、αimax为第i个超参数数值的最小值和最大值,即超参数αi的变化范围。通过更新惯性系数和偏移量来动态更新粒子的速度和位置得到新的参数组合。当满足基于训练数据下的损失函数最小或达到设定训练次数上限时,算法终止,并返回最优参数作为机器学习模型的超参数。
3.2 改进的模型超参数调优过程
基于粒子群优化算法的参数寻优过程如图2所示。
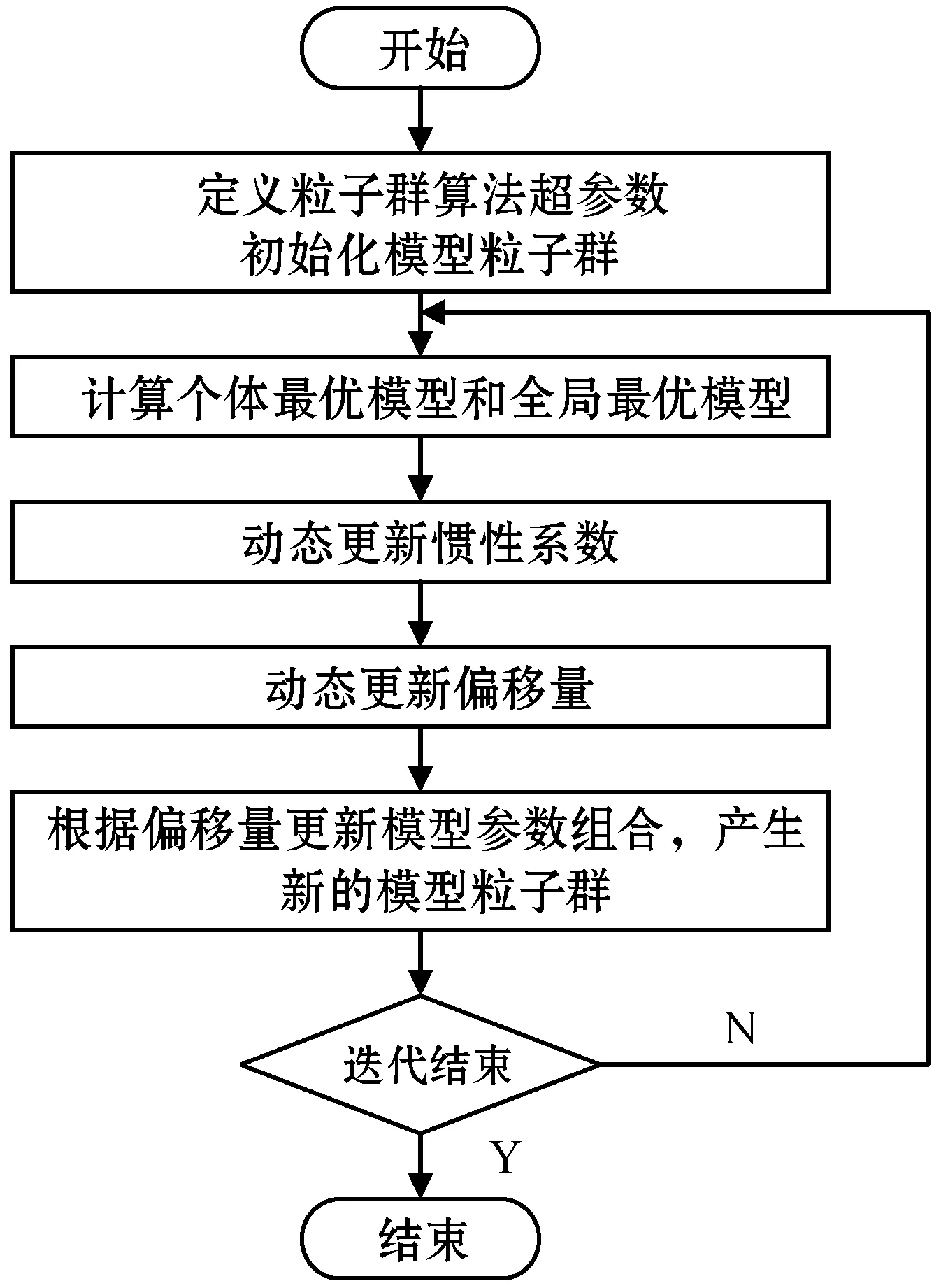
图2 基于粒子群优化算法的参数寻优过程
3.2.1设定超参数初始值和初始粒子群
确定粒子群算法超参数的初始值,包括偏移量、惯性系数、个体学习因子和群体学习因子。并确定机器学习模型的模型参数组合,随机选出若干组模型参数组合训练模型生成模型初始粒子群。
3.2.2迭代寻优,更新模型超参数组合
在整个迭代过程中,主要是通过更新粒子群算法中的惯性系数以及偏移量这两个超参数,来更新粒子群中的模型参数组合。具体地,在每一轮迭代开始时,利用偏移量更新粒子群中的模型参数组合,每一次迭代结束更新惯性系数,并基于更新的惯性系数计算下一次迭代过程的偏移量。
1) 参数组合更新。在迭代过程中,新模型参数组合的具体方式如式(5)所示。
[α1,k,α2,k,…,αn,k]=[α1,k-1,α2,k-1,…,αn,k-1]+
[p1,k,p2,k,…,pn,k]
(5)
式中:[α1,k,α2,k,…,αn,k]为第k轮迭代的模型参数组合;[α1,k-1,α2,k-1,…,αn,k-1]为第k-1轮迭代的模型参数组合;[p1,k,p2,k,…,pn,k]为第k轮迭代的偏移量;下标n表示模型参数组合中的参数总数,k=1,2,…,K,K为最大迭代轮次,当k=1时,[α1,k-1,α2,k-1,…,αn,k-1]为模型初始粒子群中的模型参数组合。
2) 惯性系数更新。在迭代过程中,惯性系数的更新方式详见2.2节,数学表达式参见式(2)。
3) 偏移量更新。在迭代过程中,下一次迭代过程的偏移量依据更新的惯性系数确定,如式(6)所示:
[p1,K+1,p2,K+1,…,pn,K+1]=GK+1·[p1,K,p2,K,…,pn,K]+
γg·[xg1,k,xg2,k,…,xgn,k]+
γq·[xq1,k,xq2,k,…,xqn,k]
k=1,2,…,K-1
(6)
式中:[p1,K,p2,K,…,pn,K]为第k轮迭代使用的偏移量;[p1,K+1,p2,K+1,…,pn,K+1]为更新的用于第k+1轮迭代使用的偏移量;Gk+1为更新的第k+1轮迭代使用的惯性系数;K为最大迭代轮次,下标n表示模型参数组合中的参数总数;γg为个体学习因子;γq为群体学习因子;[xg1,k,xg2,k,…,xgn,k]为第k轮迭代后当前个体与个体序列中最优解的差;[xq1,k,xq2,k,…,xqn,k]为第k轮迭代后当前个体与群体序列中最优解的差。
3.2.3算法参数限制和终止条件
模型参数组合中的每个参数设置一个最大偏移量,在迭代过程中更新偏移量时,每个参数的偏移量不超过其对应的最大偏移量。
在迭代过程中更新偏移量时,当参数的偏移量超过其对应的最大偏移量时,将该参数的偏移量赋值为最大偏移量。
当参数寻优迭代过程达到全局最优条件或者最大迭代轮次,结束迭代,并将得到的参数作为最优超参数组合返回给机器学习模型。
4 实证分析
4.1 应用场景说明
金融行业是数据高度密集型行业,数据不仅总量大,而且增长迅速。在金融行业企业数字化、智能化转型过程中,机器学习算法模型发挥着无可替代的作用。因此探索自动化的机器学习超参数调优方法,将有助于金融行业企业深挖数据价值、提升机器学习模型性能,并有助于建立自动化的智能决策全流程,提升智能决策水平,丰富客户体验。
本文立足于提升模型超参数优化效果,在风控、营销、推荐、催收、合规、消保等信用卡核心业务领域的模型中应用验证,效果提升明显。以下选取信用卡贷前审批和贷后催收两个场景详细介绍。其中信用卡贷前审批场景是信用卡企业综合运用客户各方面数据,决定客户是否准入以及如何授信的场景,往往直接决定着信用卡业务的客户质量,对信用卡企业的风险和收入有着直接的影响。信用卡贷后催收场景是指当客户逾期后,银行方面综合运用各方面数据决定客户的催收方式,以实现逾期款项收回的最大化。
本文选取金融业务中最常用的Xgboost、lightGBM和逻辑回归(Logistic Regression,LR)模型作为研究的对象,进行对比分析。
4.2 实验环境与编程示例
本文所涉及的实验环境信息如下:(1) CPU型号:Intel(R) Xeon(R) Gold 6152 CPU @ 2.10 GHz。(2) CPU核心数量:88。(3) 内存:1 TB。(4) 操作系统:Red Hat Enterprise Linux Server 7.9(Maipo)。(5) 编程语言及主要框架:Python 3.8.4,Scikit-Learn 0.24,XGBoost 0.90.0,LightGBM 2.3.1,Matplotlib 3.5.3。
本文动态更新惯性系数和动态更新偏移量,核心伪代码片段如下。
for i in range(max_iter):
#迭代更新粒子移动速度
pop_velocity[i][index] =
weight*pop_velocity[i][index]+
c1*random.uniform(0,1)*(local_best[i][index]-pop[i][index])+c2*random.uniform(0,1)*(global_best[index]-pop[i][index])
#惯性权重线性递减
if w_range:
weight-=w_range/max_iter
4.3 实验结果
4.3.1信用卡贷前审批场景实验效果
贷前风险模型基于客户在准件前的相关数据,如客户的征信信息、申请信息等,对客户在未来的逾期概率做出预测。
分别选用Xgboost、lightGBM和LR模型进行训练,训练样本共70万条,初始特征2 000多个,每个模型在训练时分别采用贝叶斯(BAYES)、粒子群优化(PSO)和网格(GRID)搜索算法进行超参数调优对比。三个模型进行参数调优的效果分别如图3-图5所示。
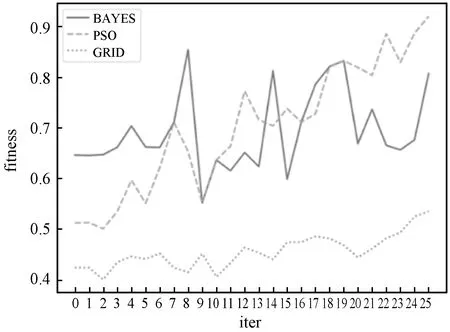
图3 基于Xgboost贷前风险模型调优结果对比

图4 基于lightGBM贷前风险模型调优结果对比
通过对比,可以看到在Xgboost、lightGBM和LR三种模型下,粒子群优化算法的调优效果都优于贝叶斯和网格搜索算法,且基于XGBOOST贷前风险模型得出效果较好,最终得到的最优参数如表1所示。
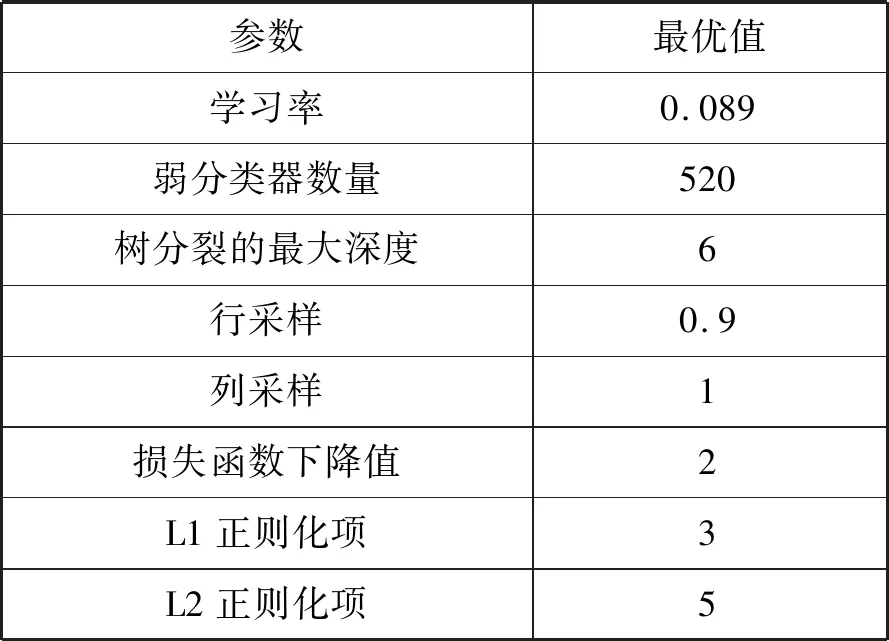
表1 贷前风险模型最终最优参数设置
4.3.2信用卡贷后催收场景实验效果
贷后催收模型用来预判客户最优的催收方式,应用于对逾期客户制定差异化的催收分案策略。同贷前审批场景一样,分别选用Xgboost、lightGBM和LR模型进行训练,训练样本共17万条,初始特征57个,每个模型在训练时分别采用贝叶斯、优化后的粒子群搜索算法和网格搜索算法进行超参数调优对比。三个模型进行参数调优的效果分别如图6-图8所示。
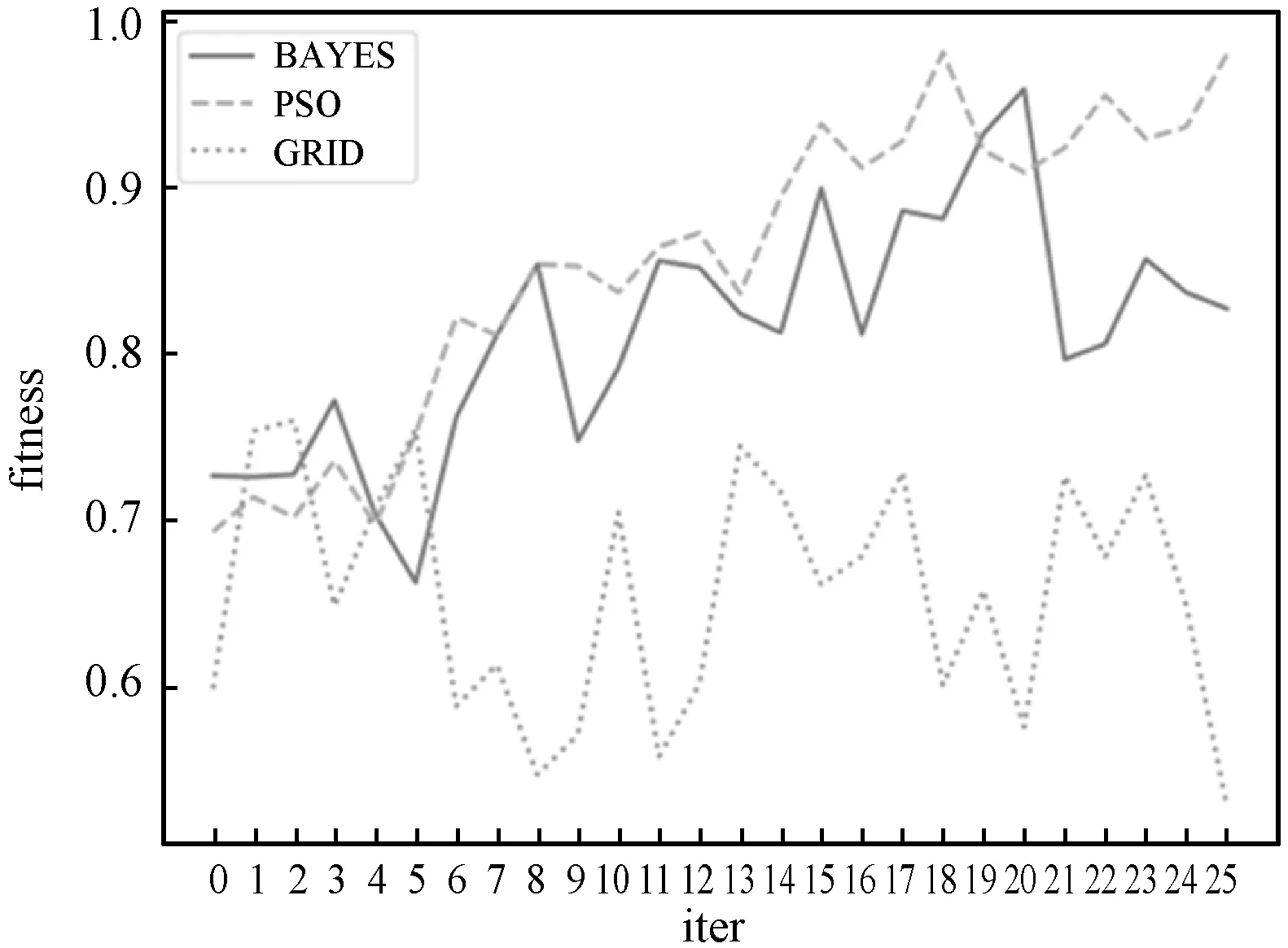
图6 基于Xgboost贷后催收模型调优结果对比

图7 基于lightGBM贷后催收模型调优结果对比
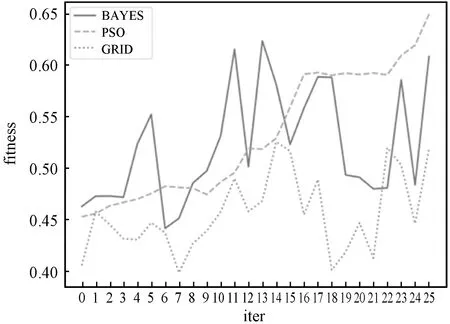
图8 基于逻辑回归算法贷后催收模型调优结果对比
通过对比,可以看到在贷后催收场景中,Xgboost、lightGBM和LR三种模型中,粒子群搜索算法的调优效果都优于贝叶斯和网格搜索算法,且基于XGBOOST贷后催收模型得出效果较好,最终得到的最优参数如表2所示。

表2 贷后催收模型最终最优参数设置
4.3.3实验结论
实验数据表明,在信用卡业务常用的XGboost、lightGBM和LR三种模型中,本文提出的基于粒子群优化算法的模型超参数优化方法均优于贝叶斯算法和网格搜索的调优效果。贝叶斯算法在迭代寻优的过程中,波动性较大且随着迭代轮次的加大,适应度与粒子群算法差距进一步拉大;而网格搜索算法,在预定的中止条件下无法得到相对于预期较理想的效果。相比之下,本文改进的粒子群算法能够较好地提升模型的准确度,使得模型具有更高的预测精度和泛化能力。
5 结 语
本文基于标准粒子群优化算法,提出对其中惯性系数的设置方式进行优化,使之能够随着迭代处理过程进行动态调整,从而提高粒子群寻优方法的性能。通过在不同场景、不同模型中进行实验对比,优化后的粒子群优化算法相对于贝叶斯算法、网格搜索算法都有着更优的调优能力,更适合在金融业务场景中应用。虽然粒子群超参数调优方法在金融数据中取得了较好的性能,但基于种群式的搜索成本是比较高的,无法直接适用于需要快速实现智能决策应用的场景。随着金融科技的持续推进,越来越多的优秀算法被引入金融行业,从而不断提升机器学习模型的应用成效。
猜你喜欢
中学生数理化·八年级物理人教版(2023年3期)2023-03-21
环球时报(2022-07-13)2022-07-13
地理空间信息(2022年3期)2022-04-01
中学生数理化·八年级物理人教版(2022年3期)2022-03-16
环球时报(2022-03-14)2022-03-14
电影(2018年8期)2018-09-21
制造技术与机床(2017年7期)2018-01-19
测绘工程(2017年3期)2017-12-22
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
小学科学(学生版)(2016年1期)2016-10-09
