
基于GA-LSTM的酿酒葡萄霜霉病预测方法研究*
2023-11-11 04:02施爱平钱震威李英豪冯亮
中国农机化学报 2023年10期
施爱平,钱震威,李英豪,冯亮
(江苏大学农业工程学院,江苏镇江,212013)
0 引言
我国贺兰山东麓地区是公认的世界上最适合种植酿酒葡萄的黄金生态区之一,该地区葡萄酒产业近年在政策的支持下高速发展。但一些问题也随之浮出水面,随着各种酒庄、葡萄园的兴建、扩张、大规模的引种,部分葡萄园中酿酒葡萄种植年限增加,病虫害问题也在近年来愈发严重,其中又以霜霉病发生最频繁、造成损失最为严重。不及时进行病虫害防治会导致大量减产,过量防治又会影响果实品质和产量,造成过量的化学残留,甚至影响葡萄园地块的可持续发展,对土地造成损伤,破坏环境。
农业专家系统最早诞生于20世纪70年代,世界公认最早的农业专家系统PLANT/ds[1]由美国伊利诺伊大学在1978年研究出来,用于大豆病虫害的诊断,接着,被用于监测谷物夜盗蛾、棉花管理、苹果园管理、杂草识别的专家系统分别被开发出来[2]。随着20世纪八九十年代计算机技术高速发展,农业专家系统也得到了发展,不再局限于诊断等,开始向监测、预测、预警等多种功能发展,在美国、日本等农业信息化技术更发达的国家,人工智能等技术被应用于农业专家系统中,进行病虫害预警等工作[3]。20世纪90年代后,我国的农业专家系统也开始快速发展。荀守华等[4]建立大袋蛾的灰色预测模型,对短期内灾情预测有较好的性能。崔振洋等[5]建立马尔科夫链预测模型对水稻稻瘟病进行预测,预测精度良好;孙朝云[6]将BP神经网络、RBF神经网络、Elman神经网络三种病虫害预测模型进行比较,发现Elman神经网络在预测精度和收敛速度相比其他两者都有不错的表现;范绍强等[7]采用回归分析法对小麦条锈病发生进行预测,经检验预测精度较高。张善文等[8]提出基于改进深度置信网络的大棚冬枣病虫害预测模型,平均预测准确率高达84.05%;Herms[9]提出基于日积温和植物物候学的害虫发育情况预测,对病虫害的短期预测有较好的结果;Grünig等[10]研究一种基于大数据和深度神经网络的病虫害预测方法,认为提高数据驱动方法中数据的可靠性至关重要,对病虫害模型有更好的支撑;李文学等[11]建立基于GIS的酿酒葡萄霜霉病季节流行时间动态模型,对发生范围、程度等进行预测,预测结果直观。
长短期记忆神经网络(LSTM)是针对RNN存在的梯度消失及爆炸问题由Hochreiter等[12]提出的模型,由Gers等[13]进行改进,增加遗忘门后,LSTM模型由于其处理时间序列数据问题的优越性,开始广泛应用于各种实际问题,如降水量、空气质量预测等[14-15],均得到不错的预测结果。Wei等[16]为了提高交通流预测的准确性,建立基于Bi-LSTM和注意力机制预测模型,证明注意力机制的加入加强了模型的预测性能;李莉等[17]建立基于LSTM的温室番茄蒸腾量预测模型,结合多种温室小气候数据进行研究,结果表明LSTM模型相比于NARX神经网络、RNN方法等,决定系数有所提高,误差有所降低,预测性能较好;曹守启等[18]提出基于K-means聚类和改进粒子群优化的LSTM预测模型,用于水产养殖的溶解氧预测,该模型一定程度改善了极端天气下预测鲁棒性差的问题;闵超等[19]运用匈牙利算法结合LSTM对储粮害虫轨迹跟踪及行为研究,为建立高效的储粮害虫防治方案提供一种策略参考;谢济铭等[20]提出基于贝叶斯超参数优化的BHO-Bi-LSTM(BHO-Bi-Directional Long Short Term Memory)车速预测集成模型,并与经典多元线性回归车速预测模型、Bi-LSTM车速预测模型进行对比,证明新模型有效改善合流区高峰时段车速特性复杂而导致不易预测的缺陷。由于病虫害预测问题本质上也是一种时间序列问题,本文对酿酒葡萄霜霉病预测LSTM模型进行研究,并针对模型超参数确定过程中手动调节存在的精度不足、收主观因素及经验影响、易陷入局部最优解的问题,采用遗传算法对超参数调节进行优化,最终建立GA-LSTM酿酒葡萄霜霉病预测模型用于霜霉病防治的决策支持。
1 数据来源及相关模型及算法基本理论
1.1 数据来源
本研究酿酒葡萄园气象及墒情数据采集自立兰酒庄葡萄园中气象传感器以及土壤温湿度传感器、冠层温湿度传感器,小型气象站每10 min进行以上数据的采集,由于酿酒葡萄霜霉病发病期多为七月上旬—九月下旬,随着每年当月的气象情况不同略有波动,本研究采用了2016—2021年每年6月1日—10月31日葡萄园间气象墒情数据,共918 d,共计132 192条气象数据。酿酒葡萄霜霉病发生情况数据采集自立兰酒庄葡萄园中病虫害试验田,该试验田不进行施药操作,以获取自然情况下葡萄园中霜霉病发生信息,由病虫害研究人员收集并上传霜霉病发生和严重性数据,在数据库中进行保存。
1.2 LSTM神经网络
长短期记忆(Long Short-Term Memory)神经网络是RNN的一个特殊变种,其被设计出来主要是为了解决RNN存在的梯度消失和梯度爆炸问题。LSTM通过给神经元加上门结构使其学习一些长依赖信息,拥有保存较长时间间隔数据的能力。LSTM中的重复神经网络模块相比RNN中简单模块而言要复杂许多,通过门控机制,在连续的时间步中,神经元一定程度上保留上一时刻的细胞状态,相当于对历史信息有了“记忆”。LSTM隐藏层单元传输状态如图1所示。
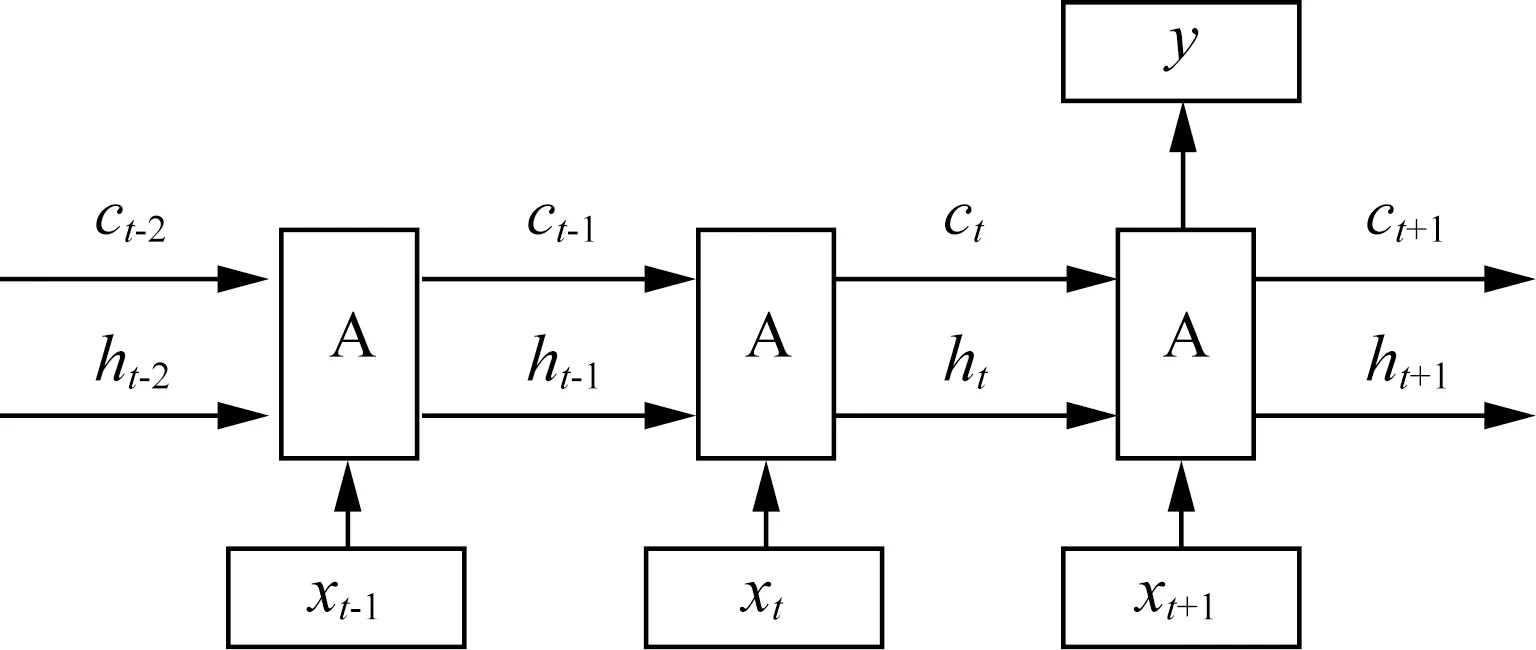
图1 LSTM隐藏层单元传输状态
图1中ct用于保存长依赖信息,ht用于保存短期信息。由图1可知,t时刻,LSTM中某个隐藏层单元输入项有三个,分别为当前时刻外部输入xt、上一时刻隐藏层单元的单元状态ct-1和上一时刻的隐藏状态ht-1,输出为当前时刻的ct和ht。
LSTM隐藏层单元的具体结构如图2所示,遗忘门负责遗忘阶段的信息处理,以一定的概率和比例对上一时刻单元状态ct-1进行选择性遗忘,以此控制历史单元状态信息流入当前计算时刻的量。遗忘门计算公式如式(1)所示。
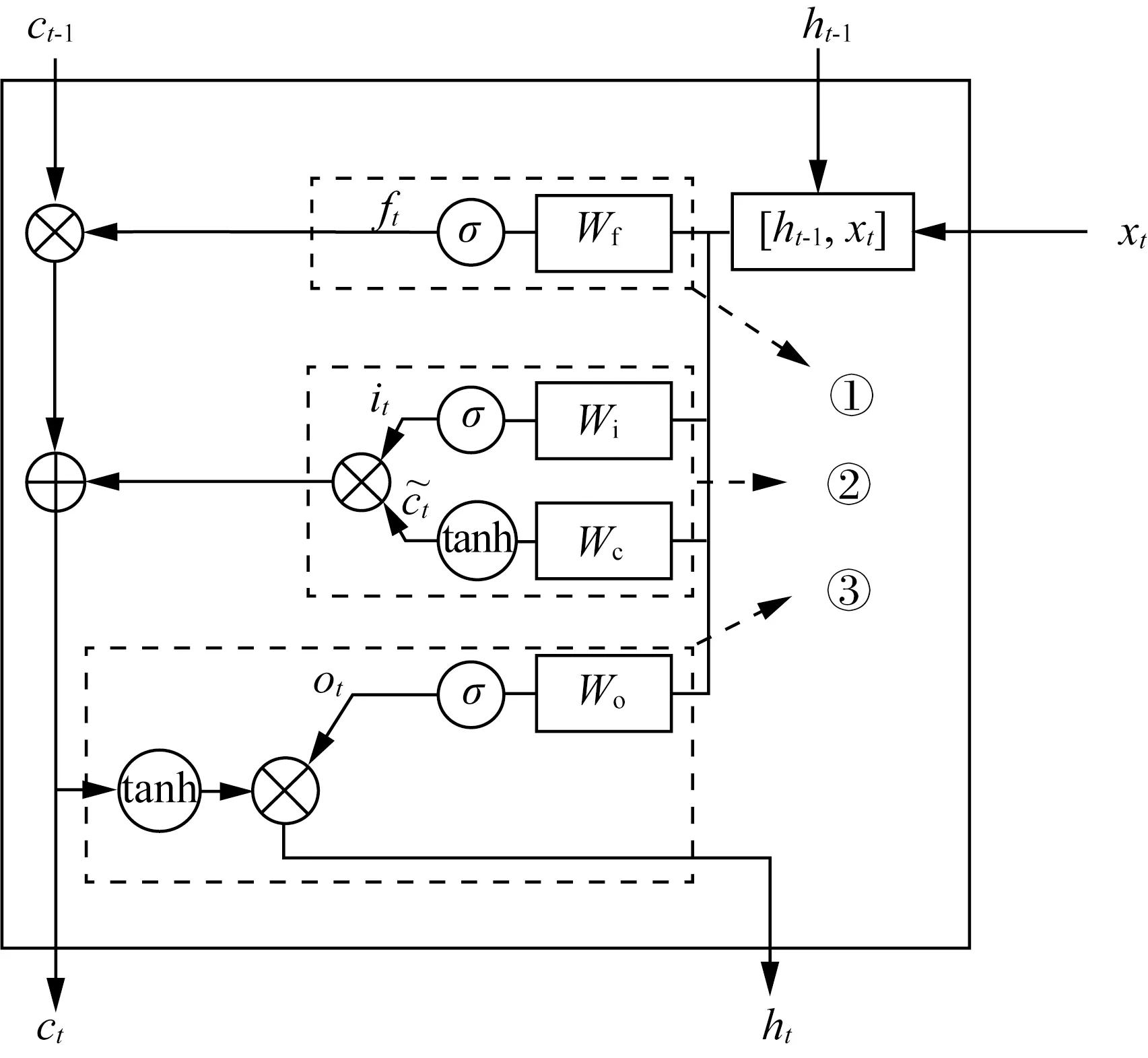
图2 LSTM隐藏层单元结构
ft=σ(Wf·[ht-1,xt]+bf)
(1)
式中:σ——sigmoid函数;
Wf——遗忘门权重矩阵;
ht-1——上一时输出值;
xt——当前时刻外部输入;
ct-1——上一时刻单元状态;
bf——遗忘门偏置。
输入门负责决定让多少新的外部输入信息加入单元状态中,输入门计算公式如式(2)~式(4)所示。
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
式中:Wi——输入门权重矩阵;
bi——输入门偏置;
it——外部信息更新单元状态程度系数;
Wc——外部输入保留权重;
bc——候选值偏置;

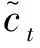
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot·tanh(ct)
(6)
y=σ(Wy·ht+by)
(7)
式中:Wo——输出门权重矩阵;
bo——输门偏置;
Wy——隐藏状态权重;
ht——当前时刻输出值;
ot——输出门;
by——输出值偏置。
1.3 遗传算法
遗传算法(Genetic Algorithm,GA)是由Holland于1975年提出,是优化算法的一种,遗传算法主要通过对达尔文生物进化论中“优胜劣汰”的自然选择机制以及遗传学进行模拟学习,来模仿生物进化机制,从而实现对对象的优化。
遗传算法中由一个种群整体构成了待解决问题可能解的解集,解集中的解与群体中的个体一一对应,种群中的个体由基因编码方式得到。遗传算法的目的是得到群体中的最优个体,为此提出了个体的适应度函数,该函数是根据问题解决目标进行确定,用于评判个体的优劣、解决问题能力强弱,适应度越强,则GA有更高的概率选中该个体,在迭代的过程中生存并繁衍诞生子代,该个体染色体特征也以更大的比例在其子代中得到继承,这就是GA中的选择操作。除了选择操作,GA在迭代过程中还有两个不可或缺的操作:交叉和变异,分别进行染色体的基因重组和染色体中基因突变的操作。基于选择、交叉、变异三种操作,对适应度高的个体进行下一代种族群体的构建,并不断迭代循环,生成更优的子代,直到达到预设的迭代次数或个体达到期望的适应度,得出遗传算法的最优个体,也就是问题的最优解。
2 GA-LSTM酿酒葡萄霜霉病预测模型构建
2.1 数据预处理
2.1.1 异常数据及缺失值处理
在较大规模的数据集中由于传感器原因、人为因素和信息采集系统维护等情况,一些数据异常值或数据缺失等情况往往难以避免,这些数据异常对模型训练有不利的影响,因此需要对异常数据进行处理。
本文采用的原始数据集由于传感器维护原因有一个月的数据缺失,数据填充方式为:从中国气象网站获取一个月的每日温度、相对湿度、风速等,其他项数据如土壤温湿度、冠层温湿度等则是在隔年数据中选择当日气象数据较为接近的日期的数据作为填充。在绘制的气象数据折线图中,有一些异常值明显偏离了其余样本,虽然样本量较大,但数据中异常值数量并不多,只是极个别,因此在python中用matplotlib库进行数据可视化后,手动在折线图中标记出异常样本,然后进行异常值的处理,采用的处理方法是平滑化,公式如式(8)所示。
(8)
式中:xb——平滑化处理后数值;
xb-1——异常值左侧点数值;
xb+1——异常值右侧点数值。
即将异常值替换为异常值点附近两个值的平均数。
2.1.2 数据整合
在立兰酒庄内采集的原始气象数据间隔为10 min,若采用原始的间隔10 min的数据作为模型输入进行训练,则存在数据量计算量过大、气象数据时序性不强导致预测效果不佳等问题,因此将原始数据整合为每日气象数据,具体方法为将每天144条数据各项中土壤温湿度、空气温湿度、冠层温湿度、风速、光照度累加后平均,将每日降水量累加,得到新的数据集如式(9)~式(10)所示。
(9)
xm=∑xi
(10)
式中:xi——每10 min一条的原始数据。
xn——原始数据进行累加后平均的操作后新的每日数据;
xm——每日144条降水量数据累加后得到的新的日降水量。
新数据集部分数据示例如表1所示。

表1 新数据集部分数据示例
2.1.3 数据归一化
数据归一化是将数据集中各项数据分别映射到0~1之间,将有量纲数据转化为无量纲数据,可以提高模型的精度、提高迭代速度、消除不同量纲数据带来的不良影响,如:每日光照度数值和空气温湿度数值相差巨大,但它们对于病虫害发生的影响水平可能是相近的,若不进行归一化处理,以原始数据输入进行训练,则模型训练过程中会大大放大光照度的影响水平而忽略温湿度等因素,因此,对新数据集中各项进行归一化处理,归一化公式如式(11)所示。
(11)
式中:xmin——数据集中该项最小值;
xmax——数据集中该项最大值。
2.1.4 数据集划分
数据集按照时间而非比例进行划分,将2016年6月1日—2018年10月31日数据共459组作为训练集,将2019年6月1日—2020年10月31日数据共306组划分为验证集,将2021年6月1日—10月31日数据共153组划分为测试集。
2.2 LSTM基础模型构建
本文选择选择基于Python编程语言的Keras开源神经网络框架作为主体进行LSTM酿酒葡萄霜霉病预测基础模型的搭建,选择sequential模型对LSTM模型进行构建。通过设置模型的初始参数,包括隐藏层层数、神经元(记忆单元)个数、激活函数、优化算法、学习率、批次大小(batch_size)等,完成模型的初步构建。
本文中LSTM酿酒葡萄霜霉病预测模型的输入有10个特征变量,分别为:空气温度、空气湿度、风速、土壤温度、土壤湿度、冠层温度、冠层湿度、光照度、降水量和霜霉病发生情况,因此本文输入序列的维度为10,则每次输入模型的数据集结构为[batch_size,20,10],其中batch_size指模型每一次训练数据集传入的批次大小,也可以说是模型更新一次权重所用的样本数,20指的是时间窗宽度,10指的是数据的维度,batch_size需在模型初始化时指定,也可以作为超参数在后续模型的训练中调整以得到更优的模型。本文LSTM模型的输出结构为[batch_size,5,1],表示模型输出维度为1,预测接下来5日内的病虫害发生情况,将batch_size初始化为32。
LSTM模型的结构初始化方面,由于随隐藏层数量增加会导致计算量急剧增长、计算效率变低、收敛速度变慢等问题,将隐藏层数量初始化为1,隐藏层神经元数量初始化为150,训练集使用次数(epoch)选择200次,选择激活函数选择为sigmoid函数,优化算法选择Adam,学习率初始化为0.001,为了防止过拟合情况发生,加入了dropout,dropout比率初始化为0.3,损失函数选择均方误差(MSE),其公式如式(12)所示。
(12)
式中:yi——预测值;

损失函数就是模型在训练、验证过程中的评价指标,用于衡量模型训练过程中每一个epoch模型输出的预测值和数据集真实值之间的差距大小,判断模型预测性能是否优秀。
至此LSTM基础模型构建完毕。
2.3 基于GA优化LSTM酿酒葡萄霜霉病预测模型构建
2.3.1 遗传算法超参数搜索空间建立
LSTM酿酒葡萄霜霉病预测模型中需要手动调整的超参数种类很多,首先确定使用遗传算法进行自动搜索的超参数种类为:时间窗宽度、隐藏层节点数、epoch、Batch_size、Dropout比率、激活函数、优化函数,后确定各个超参数的取值范围,由此形成超参数搜索空间,本文经研究确定的超参数搜索空间如表2所示。

表2 超参数搜索空间
2.3.2 二进制编码、解码
染色体个体编码是遗传算法的关键步骤,二进制编码方法具有便于编码、解码、交叉、变异等优势,本文选择二进制方法进行编码,根据表2的超参数取值空间长度,确定各变量二进制编码时的二进制长度,各变量二进制编码长度如表3所示。
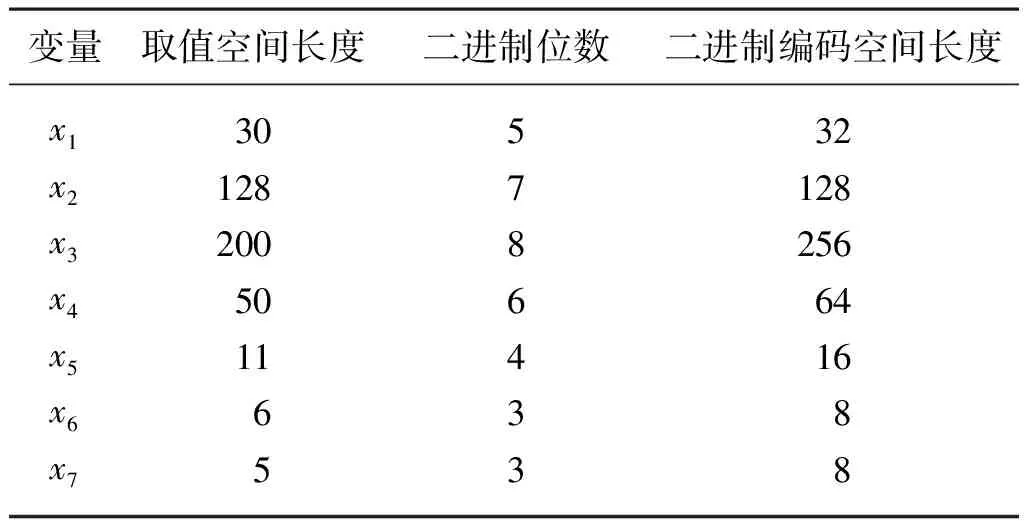
表3 变量二进制编码长度
在定义大于等于超参数取值空间的变量二进制长度后,按照编号顺序由x1~x7分别生成二进制编码长度的随机二进制字符串并连接起来得到染色体个体,重复进行以上操作得到多个个体构成初始种群。
解码是与编码对应的操作,是将GA中个体与模型进行联系的环节,将二进制编码重新解码为超参数组合才能够进行模型的训练计算并得到GA所需的适应度函数继续进行迭代,具体方法为将子代染色体按照变量的编码长度重新划分为各变量的二进制取值,进而得到二进制值对应的超参数取值,将解码得到的超参数组合代入模型进行训练。
2.3.3 遗传操作
进行遗传首先需确定对个体进行评价的适应度函数,该函数能够对模型的预测精度进行评估,本文构建的适应度函数如式(13)所示。
(13)
式中:A——群体中的某个个体;
R——超参数搜索空间。
1) 选择操作。选择操作是以高适应度为指标,从当前种群中选出合适的个体,给它们较大的机会作为父代繁殖子代,本文使用轮盘赌策略进行选择操作,即将当代群体个体适应度进行计算,并将适应度按比例放大或缩小,使得所有个体适应度值的和为1,将每个个体按照适应度的比例分布至轮盘上,通过生成一个[0,1)间的随机数,选择轮盘上该区域对应的个体,个体被选中的概率与适应度大小成正比,进行m次选择操作得到m个个体进行后续的遗传操作。
2) 交叉操作。预设一个交叉概率,本文设置交叉概率为0.7,对选择操作得到的m个个体进行两两不重复配对,配对的同时生成一个[0,1]区间内的随机数,若生成随机数小于交叉概率,进行后续步骤,若大于交叉概率则两个个体维持原状,在需进行交叉操作的染色体上随机确定交叉操作断点位置,配对染色体于断点处截断并交换断点后的部分。
3) 变异操作。预设一个变异概率,本文设置变异概率为0.05,对选择操作、和交叉操作得到的新的m个个体每个生成一个[0,1]区间内的随机数,若生成随机数小于变异概率,进行后续步骤,若大于则个体维持原状,被选中进行变异操作的染色体在二进制值上随机选择一个基本位进行取反,即0变为1,1变为0,新的染色体作为子代中一个个体。
重复进行以上遗传操作,进行迭代,直到达到终止条件:遗传代数达到预设最大值;最优个体数代未改变,满足其一停止迭代。GA优化LSTM酿酒葡萄霜霉病预测模型流程如图3所示。
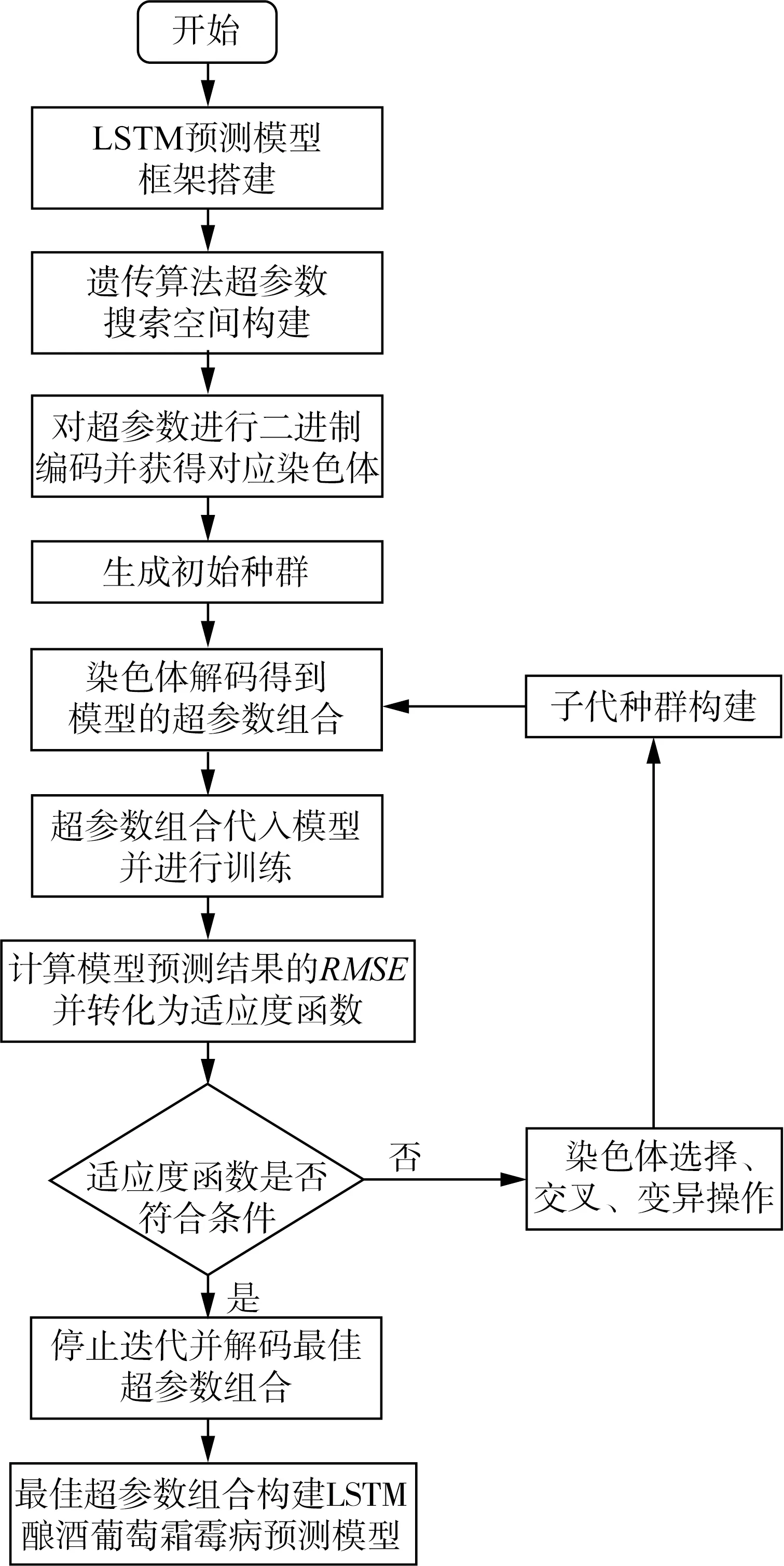
图3 GA优化LSTM酿酒葡萄霜霉病预测模型流程图
3 预测结果与分析
试验的硬件环境为内存16 GB、CPU Intel(R) Core(TM) i5-7300HQ CPU @ 2.50 GHz,GPU GeForce GTX 1050 Ti。
3.1 参数确定及预测结果
使用处理完的数据集对GA-LSTM酿酒葡萄霜霉病预测模型进行训练拟合并基于适应度函数完成超参数搜索过程,迭代结束后对GA得到的最优个体进行解码操作,得到GA-LSTM模型的最优超参数组合如表4所示。

表4 GA得到模型最优超参数组合
将得到的超参数组合代入模型,得到最终的GA-LSTM酿酒葡萄霜霉病预测模型,其在测试集上的预测结果如图4所示。
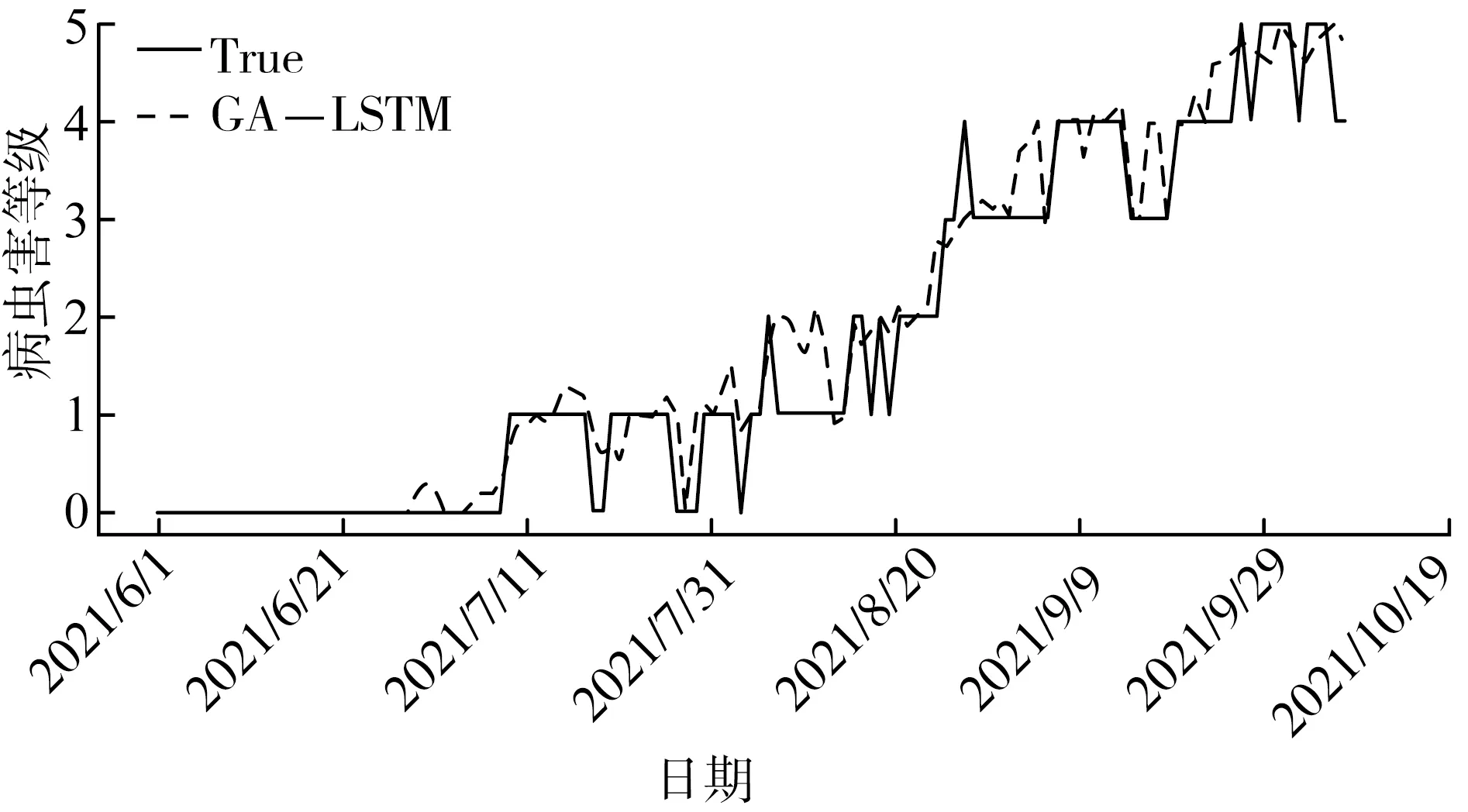
图4 GA-LSTM酿酒葡萄霜霉病预测模型测试集预测结果
GA-LSTM酿酒葡萄霜霉病预测模型预测所得均方根误差RMSE、均方误差MSE、平均绝对误差MAE指标结果如表5所示。

表5 预测模型评价指标
由图4可以看出,GA-LSTM酿酒葡萄霜霉病预测模型预测结果的曲线图与病虫害发生的真实曲线贴近。计算所得的评价指标RMSE、MAE和MSE也显示GA-LSTM模型在测试集上的预测性能优秀,误差较小。
3.2 模型对比验证研究
本文在GA-LSTM模型外还构建了BP神经网络酿酒葡萄霜霉病预测模型和手动调参LSTM模型,两种神经网络参数分别如表6、表7所示。

表6 BP神经网络酿酒葡萄霜霉病预测模型参数

表7 手动调参LSTM酿酒葡萄霜霉病预测模型超参数确定
三种模型在测试集上的预测结果如图5所示。
由图5可以看出,GA-LSTM酿酒葡萄霜霉病预测模型预测结果相比LSTM模型和BP模型更加贴近真实值曲线,表示GA-LSTM模型有比LSTM和BP模型更好的预测性能。三种模型预测结果的评价指标如表8所示。

表8 三种模型预测结果指标
由表8可知,预测性能GA-LSTM模型优于LSTM模型优于BP模型,LSTM模型在时间序列问题上拥有比BP神经网络更好的性能,LSTM的三种门结构对时序数据的处理有正面作用,GA的加入对于LSTM模型的参数选择也有正面作用,优化了超参数调节环节。
4 结论
1) 本文以准确预测宁夏贺兰山东麓地区一葡萄园内酿酒葡萄霜霉病的发生情况为目的,进行了酿酒葡萄霜霉病预测模型的研究。采用宁夏立兰酒庄葡萄园内小型气象站采集的气象墒情等数据和人工采集的酿酒葡萄霜霉病发生情况作为数据来源,分别构建了基于手动调参LSTM、BP神经网络、GA-LSTM的酿酒葡萄霜霉病预测模型,并对三种模型在测试集上进行了预测并对比。
2) 在表现模型预测性能的指标中,GA-LSTM模型的RMSE值为0.410 3,LSTM模型的RMSE值为0.462 6,BP神经网络模型的RMSE值为0.484 6;GA-LSTM模型的MAE值为0.245 0,LSTM模型的MAE值为0.301 6,BP神经网络模型的MAE值为0.321 7,由评价指标结果可得酿酒葡萄霜霉病预测方面GA-LSTM模型优于LSTM模型优于BP模型,可以证明LSTM在时间序列数据的预测性能优于BP神经网络模型,使用遗传算法对于LSTM模型的超参数选择环节进行优化会在超参数组合方面优于手动调参的LSTM模型,自动搜索得到的超参数组合少了主观选择的局限性。
3) 后续研究可以在模型的输入数据环节加入关联分析,剔除对病虫害发生影响较小或没有影响的因素,可以较大程度上减轻计算机计算压力,减少计算量,优化模型。同时本研究得到的GA-LSTM模型不具备通用性,扩展性较差,难以应用于白粉病、灰霉病等病虫害的预测,后续可以通过一些方法增强模型的泛化性能。
猜你喜欢
今日农业(2022年4期)2022-11-16
计算机仿真(2022年8期)2022-09-28
酿酒科技(2021年8期)2021-12-06
军事文摘·科学少年(2021年1期)2021-02-04
农药科学与管理(2019年7期)2019-11-29
吉林蔬菜(2017年4期)2017-04-18
故事作文·低年级(2016年7期)2016-05-14
中国塑料(2016年11期)2016-04-16
新疆农垦科技(2014年2期)2014-02-28
河南科技(2014年8期)2014-02-27
