
基于改进YOLOX算法的杨梅成熟度检测方法*
2023-11-11 04:02项新建周焜费正顺郑永平姚佳娜
中国农机化学报 2023年10期
项新建,周焜,费正顺,郑永平,姚佳娜
(浙江科技学院,杭州市,310023)
0 引言
中国是杨梅的主要生产国,杨梅果实采摘时限较短,成熟后必须尽快采摘[1]。杨梅种植地多在山地丘陵地区,果农如果无法适时采摘,会导致大批杨梅错过最佳食用期,因此杨梅采摘的智能化能够有效提高杨梅的生产效率和降低杨梅产业工人的劳动强度。机器视觉是水果采摘智能化设备中的重要组成部分,快速准确地识别到杨梅果实是实现智能采摘的核心问题[2-3]。
徐黎明等[4]设计出一种研究自然场景下成熟杨梅的识别技术,采用最大类间方差法根据R-G颜色特征对杨梅图像进行分割,再使用SUSAN算子自适应选取阈值对图像进行边缘检测,最后通过Hough实现对杨梅的识别。Ghazal等[5]对水果的视觉特征和各种分类器进行分析,观察到对于具有fruit 360数据集这种数据集中相似成像条件的较小数据集,将颜色特征和纹理特征进行组合再利用传统算法进行分类可以显著提高分级准确度。Khodabakhshian等[6]采用混合对比度拉伸法,利用顶帽运算滤波和高斯函数提高图像对比度,经Gabor小波变换和k-means聚类分割后采用SVM分类器进行番茄的果实分类。以上学者使用的主要是基于计算机视觉的传统算法进行水果检测,传统算法过于依赖人工提取的特征,存在泛化性差、易受环境影响等问题。
随着神经网络的发展,深度学习也越来越多的运用到了水果检测当中。Kang等[7]提出一种基于深度学习的苹果检测器的快速实现框架,采用多尺度金字塔和聚类分类器对训练数据进行快速标记,实验证明这种方法提高了模型的检测性能。Akram[8]等使用两种深度预训练模型(VGG16和Caffe AlexNet)用于植物病虫害特征提取,使用遗传算法来选择最具判别性的特征后采用多类支持向量机进行最后的分类,在PlantVillage和CASC-IFW数据集上进行实验,分类准确率达到98.6%。
目前较为流行的目标检测算法分为两种类型,一种是基于区域建议的双阶段目标检测算法,如R-CNN[9]、SPP-Net[10]、Fast R-CNN[11]、Faster R-CNN[12]、MaskR-CNN[13];另一种是基于回归分析的单阶段目标检测算法,如 YOLO[14]系列、SSD[15]系列、RetinaNet[16]等。双阶段目标检测算法通常先通过算法提取到候选框,再进行二次修正获得结果。而单阶段算法则直接在整幅图中预测目标的位置信息,相比较而言,单阶段算法在检测速度上拥有更优的性能。在实际使用场景中,单阶段算法更符合检测任务的需求。
本研究基于深度学习算法,采用Jetson Nano A02开发一款便携式杨梅果实成熟度检测仪,提出一种适合在嵌入式系统中部署的基于轻量级目标检测网络YOLOX-NANO的改进杨梅果实检测算法,改进特征金字塔结构,在FPN层中引入通道与空间注意力机制,增强网络对小目标的识别精度。使用Focal loss以解决单阶段目标检测网络中的正负样本不均衡问题。引入了EIoU损失函数替代IoU,既考虑到边框与目标中心点距离还解决了边框横纵比定义模糊的问题。基于迁移学习的思想,使用预训练模型,加快网络收敛速度提升网络模型性能。
1 数据集准备
1.1 数据采集
本研究采用的数据集图像除从互联网上获取外,还由杨梅果园实地拍摄获得。拍摄的杨梅果实图像包含光线不足、强光照射、枝叶遮挡、果实堆叠等自然环境因素,图像包含成熟果实、将成熟果实以及未成熟果实三种,部分数据集如图1所示。

(a) 光线不足
杨梅图像的采集地位于杨梅种植基地,采用55 mm定焦镜头的Sony α6300微单相机进行不同距离的拍摄,共采集原始图像1 000幅以.jpg格式保存,图像分辨率为3 840像素×2 160像素,将图像根据杨梅果实的密集程度进行八等分和四等分后,删除部分无目标的无效图片,最终得到的样本数据为5 035幅图片。使用Labelme对数据集进行标注,根据杨梅表面的颜色对成熟度进行划分,其中全青色或整体呈现青色杨梅划为未成熟,表面转黄、红色明显但未全红划为将成熟,表面全红或转紫划为已成熟,成熟度划分示例如图2所示。

图2 成熟度划分示例
1.2 数据预处理
使用标注工具Labelme对图像进行标注后,转换成标准VOC格式。在已有数据集的基础上,本研究通过数据增强算法,对每幅图片进行一次扩增,每次扩增采取从翻转、增加噪声、平移、旋转中的随机最少一种扩增方法进行扩增,扩增样本图像至10 070幅,按照7∶1∶2的比例将数据集随机划为训练集(7 049)、验证集(1 007)、测试集(2 014)。
2 基于目标检测的杨梅果实识别算法
2.1 YOLOX目标检测算法
YOLOX[17]是由旷世科技于2021年提出的单阶段高精度目标检测算法。YOLOX引入了解耦头(Decoupled Head)、数据增强(Mosaic)、无锚框思想(anchor free)、动态匹配正样本(SimOTA)等目前目标检测领域的有效应用,网络结构图如图3所示,YOLOX主要分为三个部分,分别是backbone主干特征提取网络部分、Neck加强特征提取网络部分和Prediction检测头部分。YOLOX仍采用了CSPDarknet作为主干特征提取网络,图片输入到backbone中进行浅层特征提取,输出三层不同尺度的特征层传入Neck部分的加强特征提取网络层(FPN)之中进行多尺度特征信息融合提取深层特征,输出的三层特征图传入Prediction部分进行回归预测。
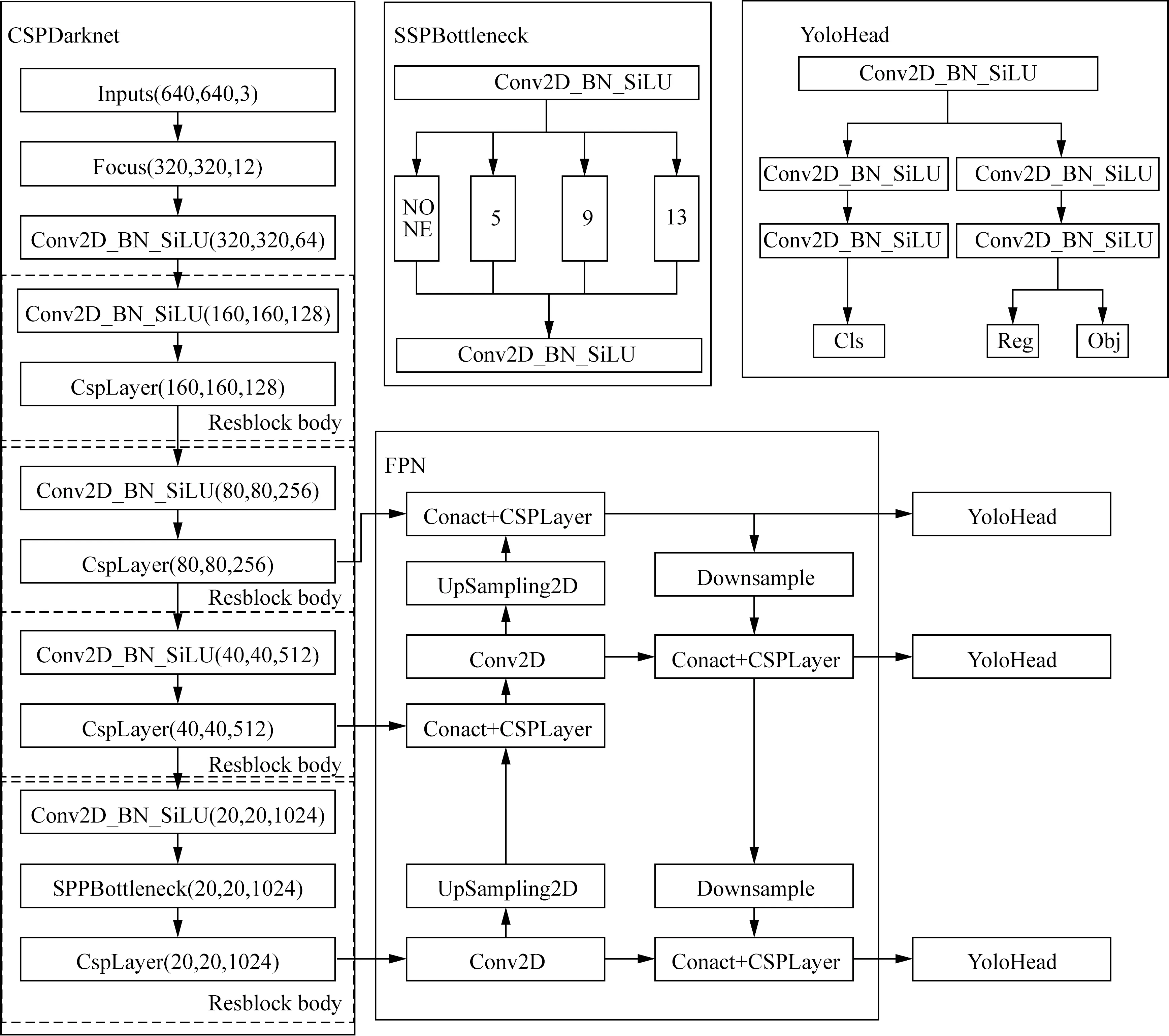
图3 YOLOX结构图
2.2 改进的ECA-FPN特征增强网络
根据现有的研究现状可知,通道注意力机制对深度卷积神经网络(CNN)性能的增强取得了显著的效果[18]。现有的注意力机制例如SENet[19]、CBAM[20]、BAM[21]、GCNet[22]、FcaNet[23]等在引入到各大主流网络中都得到了可观的性能增强效果。本文在特征加强提取网络(FPN)中引入了超强通道注意力模块(ECA)结构如图4所示。

图4 通道注意力机制(ECA)结构图
由图4可得,特征图k输入后在不降维的情况下进行逐通道全局平均池化再传入卷积核大小为k的快速一维卷积层来实现通道之间的信息交互。公式如式(1)所示。
w=σ[C1Dk(y)]
(1)
式中:C1D——快速一维卷积;
k——本地跨通道交互的覆盖范围,即有k个相近邻参与一个通道的注意力预测。
为了有效表示跨通道信息交互作用的覆盖范围(即卷积核大小k)与通道维度C(卷积核数量)之间的特征关系,ECA将C与k的值设为
C=φ(k)=2(γ×k-b)
(2)
给定通道维数C的值即可自适应确定卷积核大小k的值
(3)
式中:|*|odd——最接近的*奇数。
本文中γ的值设为2,b的值设为1。
FPN特征金字塔能够很好地解决多尺度融合的问题,然而传统的FPN在多尺度融合过程中会损失部分特征信息,卷积结构在处理不同感受野的特征图时在产生有效特征的同时也会产生无效特征。本文提出的ECA-FPN结构在FPN的输入层引入了ECA模块,以及在上采样的过程中引入ECA模块,从而实现了通道间充分的信息交流以达到增强网络性能的目的。结构图如图5所示。

图5 改进ECA-FPN结构图
ECA-FPN特征加强网络会输出三个特征加强后的特征层,在经过解耦头预测后,每个特征层将得到三个预测结果分别是预测框(Reg)、目标(Obj)、和目标种类(Cls)。
2.3 损失函数
2.3.1 高效交并比损失函数
本研究在边界框预测中引入了高效交并比损失函数(EIoU)[24],与原本的交并比(IoU)[25]损失函数相比,EIoU既考虑到边界框回归的重叠面积,也考虑到边框距离目标的中心点距离和边框长宽边的差。EIoU损失函数由三部分组成,计算公式如式(4)所示。
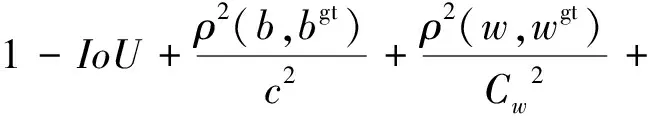
(4)
式中:b、bgt——预测框、真实框;
ρ2(b,bgt)——预测框中心点与真实框中心点的欧式距离;
c——同时包含预测框与真实框的最小外接框的对角线距离。
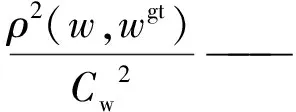
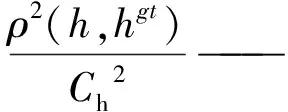
2.3.2 焦点损失函数
单阶段算法在目标检测时会生成大量预选框(Region Proposal),而其中大部分都是负样本,正样本只占很少一部分,这便导致样本类别不均衡问题[16]。大量无用的易分负样本会导致Loss函数的梯度下降方向指向非最优解。针对以上问题,为提高网络模型的精度,本研究采用的焦点损失函数(Focal Loss)通过减少易分类样本的权重,使模型在训练时更专注于难分类样本。
Focal Loss是基于标准交叉熵损失函数(Cross Entropy Loss)修改而来,公式如式(5)所示。
FL(pt)=-(1-pt)γlog(pt)
(5)
式中:pt——样本属于正确分类的概率;
γ——聚焦参数(focusing parameter),γ≥0。
当γ为0时,Focal Loss函数即为标准交叉熵损失函数。
3 试验验证
3.1 试验环境和参数
神经网络训练平台使用AMAX深度学习服务器XG-48202G,该服务器采用Intel E5-2620v4x2,内存为4通道8 GB共32 GB,采用NVIDIA GeForce RTX2080Ti显卡,显存大小为11 GB。服务器系统为Ubuntu18.04,内置软件开发环境Python3.7、pytorch1.7-GPU、CUDA10.2。测试环境的CPU为Intel i7-8565U,内存为双通道8 GB,显卡为mx220,显存大小为2 GB,系统为Windows 11专业版。
嵌入式试验平台采用Jetson Nano A02版,该开发板具有4 GB内存,CPU采用4核ARM A57,最高频率为1.43 GHz。操作系统采用Ubuntu 16.04,内置软件开发环境Python3.69、pytorch1.6-GPU、CUDA10.2。
3.2 试验评价指标
本研究采用平均精度(Mean Average Precision,mAP)作为模型检测精度的评价指标,mAP与准确率(Precision,P)、召回率(Recall,R)有关,公式如式(6)~式(9)所示。
(6)
(7)
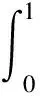
(8)
(9)
式中:TP——被正确划为正样本的数量;
FP——被错误划为正样本的数量;
FN——被错误划为负样本的数量;
M——分类的类别数;
AP(k)——第k类的AP值。
F1得分是一种用于衡量二分类模型精确度的指标。
(10)
3.3 模型训练
基于迁移学习思想[26],通过在大规模通用数据集上进行预训练,获得泛化性较强的网络模型来替代源模型进行目标任务数据集上的训练。相比源模型随机选取初始权重进行训练,预训练模型已具备一定的通用特征提取能力,使用预训练模型进行具体任务的训练可加快模型收敛速度,得到鲁棒性更优的模型。本研究使用COCO-Train2017数据集对YOLOX-NANO的主干网络CSPDarknet53进行预训练,得到了预训练模型权重。训练时,将预训练模型权重设置为初始权重,对前50个训练轮数(epoch)进行冻结训练,即前50个epoch不进行主干网络的权值更新,后150个epoch再进行主干网络权值更新,从而提高训练效率,加快模型收敛速度。置信度阈值设为0.5,即得分大于0.5的预测框会被保存。在前90%的epoch中采用Mosaic数据增强法训练。在冻结训练阶段,本研究的batchsize设为32,则每个epoch进行了315次迭代(step),在解冻阶段,batchsize设为32,每个epoch进行了315次迭代。
训练过程的Loss曲线如图6所示,横坐标为训练轮数(epoch),纵坐标为Loss值,解冻前训练集损失值收敛于2.36,测试集损失值收敛于1.95。解冻后的训练集损失值收敛于1.26,测试集损失值收敛于1.21。
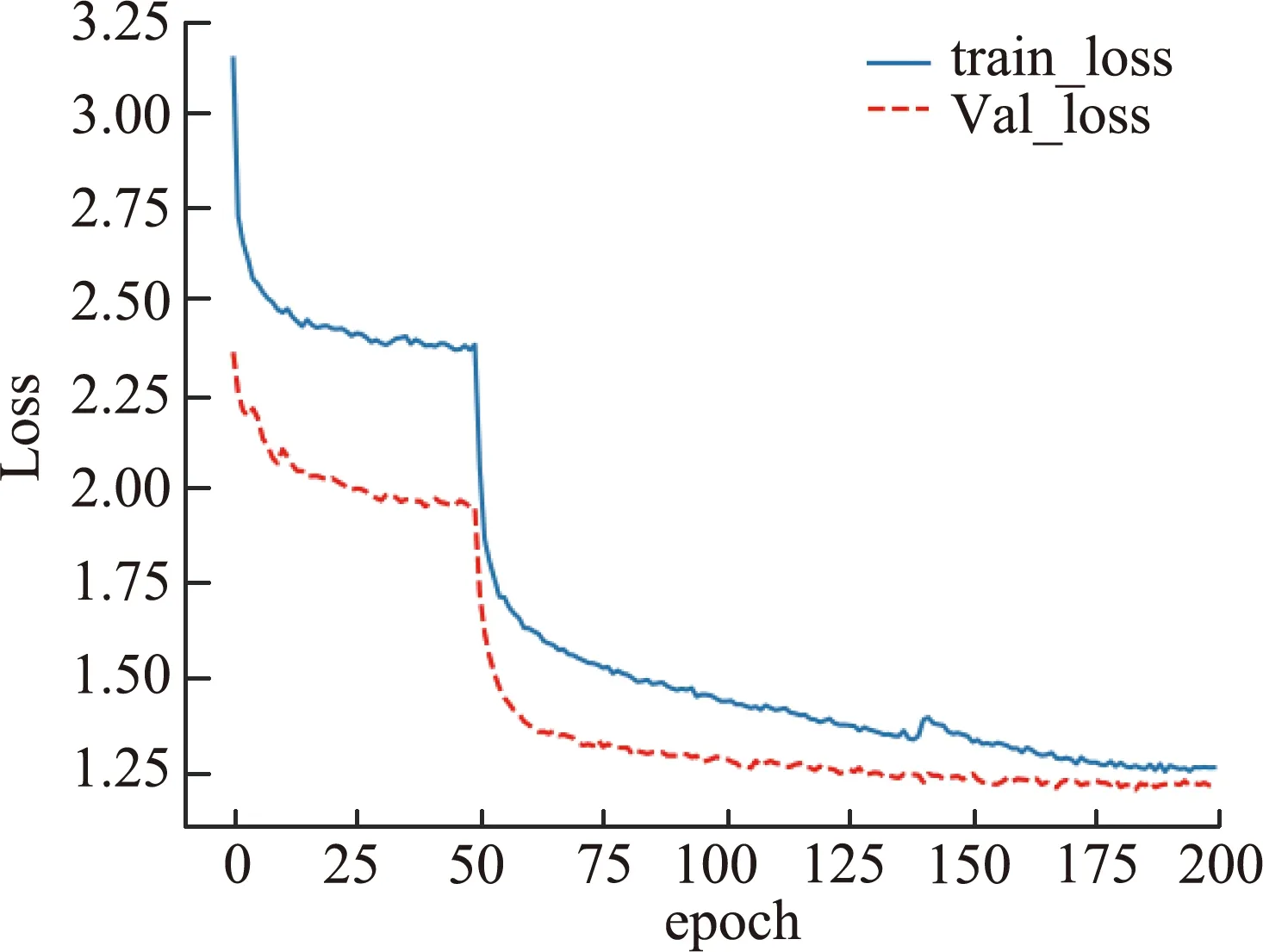
图6 训练Loss图
3.4 结果分析
为验证模型有效性,在训练参数相同情况下对改进后的 YOLOX-NANO网络进行横向纵向对比实验,比较不同模型的单类别平均精度AP、平均精度mAP、模型大小Size和每秒检测帧数FPS,其中AP值表示每种成熟度杨梅的识别平均精度,mAP值表示整体的识别平均精度,FPS体现出模型的检测速度。由于部分模型过大,无法在Jetson nano A02正常运行,因此在测试环境下,对测试集进行试验,结果如表1所示。
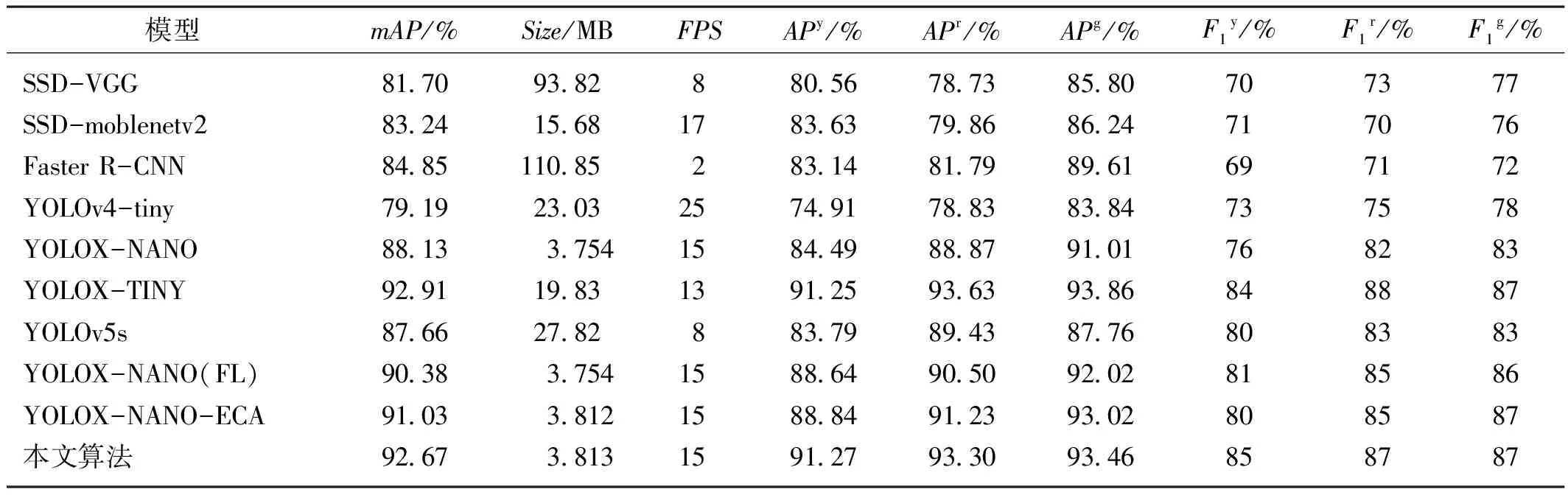
表1 对比试验结果
本研究改进算法在网络结构和推理速度基本不变的情况下,提高了mAP,对三种不同成熟度的杨梅果实的识别率均有提升,尤其对于数据集中数量比重较少的成熟杨梅和半成熟杨梅提升更明显。与同为轻量级网络的YOLOv4-tiny和SSD-moblenetv2相比,虽然推理速度有所下降,但是mAP比后者分别高出13.48%和9.43%,比Faster R-CNN高出7.82%。本研究改进的算法精度与YOLOX-TINY相差不大,但网络模型大小远远小于YOLOX-TINY,更易于在嵌入式设备中部署。
在Jetson Nano A02中部署了YOLOv4-tiny、YOLOv5s、YOLOX-NANO、YOLOX-TINY和本文算法对处于自然状态的杨梅图片进行检测,识别效果图如图7所示。其中,在YOLOv4tiny和YOLOv5s中,红色框代表成熟杨梅,蓝色框代表半成熟杨梅,绿色框代表未成熟杨梅。在YOLOX系列和本文改进算法中,红色框代表未成熟杨梅,绿色框代表成熟杨梅,蓝色框代表半成熟杨梅。可以看出YOLOv4tiny和YOLOv5s均存在漏检问题;YOLOX-NANO对严重遮挡杨梅存在漏检;YOLOX-TINY漏检率有所减少;本研究改进的YOLOX-NANO算法漏检率最低。

(a) YOLOv4tiny
在Jetson nano A02中对测试集进行检测。如图8所示,在单目标+强光的图片中,本文改进算法与YOLOX-NANO均能进行有效检测,在多目标+堆叠遮挡+强光条件下,YOLOX-NANO算法存在误检,本文改进算法能正确识别杨梅。

(a) YOLOX-NANO
如图9所示,在暗光条件下本文改进算法的漏检率比YOLOX-NANO更低,但是对模糊的目标依旧存在漏检现象。

(a) YOLOX-NANO
使用包含自然环境干扰的数据集和图像扩增技术大大加强了网络模型的鲁棒性,同时结合注意力机制让网络的特征提取能力得到了增强从而精度得到了提升。
4 结论
本文提出一种改进YOLOX-NANO轻量级目标检测算法,针对不同成熟度杨梅进行识别。为增强模型对多尺度特征提取能力,又能够部署于嵌入式设备中,本文以YOLOX-NANO目标检测网络为基础,引入轻量级通道注意力模块。通过融合加强特征提取网络与通道注意力,在仅增加少量参数前提下,提高网络模型通道注意力。同时引入焦点损失函数解决样本不均衡问题,采用EIoU损失函数提高了模型检测精度。
1) 在FPN中引入ECA模块的改进算法相比原YOLOX-NANO算法,mAP提高了2.9%,未成熟杨梅、半成熟杨梅和成熟杨梅的AP分别提高了2.01%,4.35%,2.36%。而网络模型大小仅增加了0.059 MB,实现了增加少量参数提高准确率的目的。
2) 在解耦头中引入Focal Loss的改进算法,相较于原算法,mAP提高了2.25%,未成熟杨梅、半成熟杨梅和成熟杨梅的AP分别提高了1.01%,4.15%,1.63%,对于半成熟杨梅准确率提升相较于其他成熟度更为明显,且模型大小几乎不变。
3) 本文改进的YOLOX-NANO算法与原算法相比较,mAP提高了4.54%,未成熟杨梅、半成熟杨梅和成熟杨梅的AP分别提高了2.45%,6.78%,4.43%,对各成熟度杨梅的识别率均达到90%以上,检测效果与YOLOX-TINY持平,模型大小仅为3.813 MB远小于YOLOX-TINY的19.83 MB。
4) 本文改进的YOLOX-NANO算法能够在自然环境下对不同成熟度的杨梅果实进行检测,且检测效果良好,与其他轻量级网络相比,在准确度和模型大小上更具优势,更适合用于杨梅果实成熟度检测仪的研发。下一步将考虑如何通过剪枝蒸馏技术,对模型进行进一步的压缩以加快推理速度。
猜你喜欢
公民与法治(2022年6期)2022-07-26
中学生数理化·高一版(2021年2期)2021-03-19
航天工业管理(2020年9期)2020-12-28
航天工业管理(2020年1期)2020-04-20
文苑(2019年20期)2019-11-16
种子(2018年9期)2018-10-15
知识经济·中国直销(2018年8期)2018-08-23
西江月(2018年5期)2018-06-08
宝藏(2018年1期)2018-04-18
学苑创造·B版(2018年12期)2018-03-04
