
基于改进YOLOv4-Tiny的自然环境下油茶果识别方法*
2023-11-11 04:02李庆松康丽春饶洪辉李泽锋刘木华
中国农机化学报 2023年10期
李庆松,康丽春,饶洪辉,李泽锋,刘木华
(江西农业大学工学院,南昌市,330045)
0 引言
中国是油茶种植面积最大的国家,由于油茶林地环境比较复杂,目前主要依靠手工收获[1]。在农业劳动力紧缺、采摘成本不断增加的情况下,以油茶果采摘机器人代替人工采摘具有重要的现实意义和广阔的应用前景[2]。由于油茶果颜色与枝叶颜色相近,果实密集分布、重叠、体积小或受枝叶遮挡的现象严重[3]。因此,对复杂环境下油茶果实的特征学习从而准确识别重叠与遮挡的油茶果是油茶果采摘机器人亟待解决的关键性问题[4]。
目前,国内外学者对重叠与遮挡果实的识别算法进行了大量研究[5-10]。刘丽娟等[11]使用YUV空间U、V分量对重叠与遮挡苹果图像进行分割,该方法有较高的识别精度和较快的识别速度,但由于苹果非标准圆形,对单一目标会出现过分割的问题。刘妤等[12]针对自然环境下重叠柑橘,提出了一种基于轮廓曲率和距离分析的分割方法,该算法相比Hough变换定位误差较小,但算法实用性有待提高。虽然上述方法在解决重叠与遮挡果实识别的问题上具有一定的鲁棒性,但识别目标主要是与背景颜色不同且体积较大的果实。
油茶果作为特有的木本油料作物,近年来,我国学者对自然环境下油茶果的识别也进行了大量研究。如陈斌等[13]利用Faster-RCNN网络对自然环境中的油茶果图像进行检测,该算法在相邻、单独和密集分布果实的识别上有较好的准确率和召回率,但对存在重叠和遮挡果实的检测效果不佳。张习之等[14]在原有自编码机的基础上进行改进,并利用金字塔池化模型融合高阶特征,试验表明,该算法油茶果识别准确率为90.4%,但单张图片的检测速度较慢。李立君等[15]通过凸壳理论对遮挡和重叠油茶果的轮廓进行重建从而识别被遮挡和重叠的油茶果,改算法的识别准确率比自编码机高,但也存在检测速度较慢的问题。
YOLOv4-Tiny是YOLOv4的轻量化版本,该算法兼顾识别准确率和识别速度,在果实图像识别中尤其是小目标检测中有一定的效果,但检测精度还有待提高。因此本文在YOLOv4-Tiny网络的基础上,针对现有算法在遮挡或重叠油茶果识别上识别准确率低、检测速度慢的问题,提出了一种基于改进YOLOv4-Tiny的自然环境下油茶果识别方法,以期提高被遮挡和重叠油茶果的识别准确率和速度。
1 试验材料
1.1 图像采集
2019年10月在江西省南昌市油茶良种种植基地使用索尼相机采集油茶果图像2 376幅,图像分辨率为640×480,采集油茶品种为赣无1。采集到图像包含单个油茶果的图像幅1 074幅,复杂光照(顺光、逆光、自然光照、阴天、灯光照射)下的油茶果图像286幅,存在枝叶遮挡的油茶果图像幅272,多个且存在重叠油茶果图像357幅,多个且不重叠油茶果图像387幅(相邻果实图像179幅,独立果实图像208幅)。为了减少后期神经网络提取特征时对硬件处理的压力和缩短运算时间,将图像的分辨率缩放为416×416。使用labelimg标注软件对缩放后的油茶果图像进行标注,并生成XML类型的标注文件,数据集标注的格式为PASCAL VOC。
1.2 样本增强
增强后图像分别如图1所示。

(a) 原图
训练卷积神经网络需要大量的样本数据,过小的样本数据易导致网络在学习过程中发生过拟合,因此需要对数据样本进行增强,以提高算法的鲁棒性和模型的泛化能力。本文使用水平翻转、旋转、添加噪声、高斯滤波(gaussian blur)和颜色抖动(对图像的亮度、对比度和饱和度进行调整)等方法对采集到的图像数据进行增强,使数据集更加丰富性、多样化,提升样本质量[16]。样本数据增强时需对每幅图像对应的XML文件进行同步变换。
每幅图像生成7幅增强图像,共得到19 005幅图像。训练集和验证集与测试集按照9∶1的比例随机从样本数据中独立同分布采样得到,其中训练集和验证集之和为17 104幅,测试集1 901幅。随之训练集与验证集也按照9∶1的比例随机从划分到的样本数据中独立同分布采样得到,其中训练集15 394幅,验证集1 710幅。
2 油茶果检测模型结构
2.1 传统YOLOv4-Tiny网络结构
YOLOv4-Tiny是YOLOv4的轻量化版本,使用CSPDarknet53-Tiny作为特征提取的主干网络,整个主干网络共有38层。为了提高检测速度,使用Leaky激活函数代替YOLOv4网络中的Mish激活函数。整个网络共有600万参数,仅为YOLOv4参数的十分之一。虽然检测精度有所降低,但大大提高了检测速度,满足实时检测的需求,且对硬件要求低,极大地提高了将目标检测方法部署在移动设备或嵌入式系统上进行户外实时检测目标的可行性[17]。
2.2 YOLOv4-Tiny网络改进设计
原始YOLOv4-Tiny网络的两个有效输出特征图分别经过16倍和32倍下采样得到,感受野较大,适用于检测中、大目标。自然环境下遮挡或重叠油茶果的显著区域较小,属于小目标检测,且油茶果颜色与周围枝叶颜色相近,若使用原始YOLOv4-Tiny网络的两个有效输出特征层(P4和P5)对油茶果进行特征提取时,易丢失边缘特征信息,造成部分遮挡或重叠的油茶果出现错检和漏检的现象。而对原始图像做8倍下采样的第二个CSPNet结构包含较多遮挡和重叠的细节特征,因此本文在原有YOLOv4-Tiny网络中添加52×52(P3)的检测分支,并将P3输出通道经过卷积和下采样与P4相连,以减少训练过程中油茶果边缘特征信息的丢失,降低目标因被遮挡和重叠导致的错检和漏检的概率,不仅提升了网络的检测范围,而且使浅层特征信息更加丰富。为了降低YOLOv4-Tiny网络的参数量,将第一个CSPNet结构中第2层的3×3卷积换成1×1卷积。改进后的YOLOv4-Tiny骨干网络如图2所示。
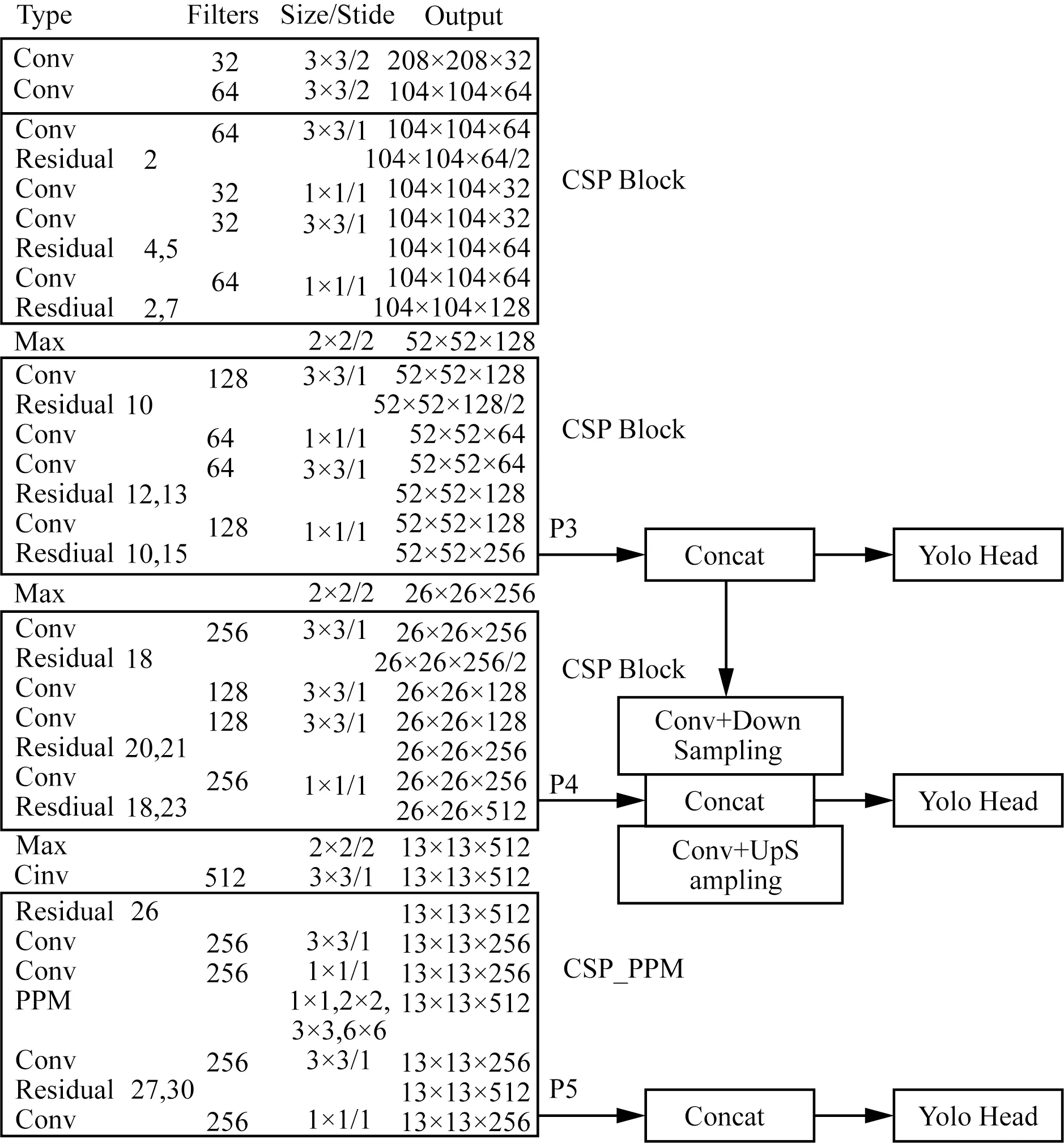
图2 改进的骨干网络
由于原有YOLOv4-Tiny骨干网络的深度较深,在训练过程中易导致感受野发生偏差,使网络无法有效融合全局特征,从而丢失特征信息[18]。针对此问题,本文将金字塔池化模型(Pyramid Pooling Module,PPM)引入到第四个CSPNet结构中,使用4种不同的平均池化窗口(1×1、2×2、3×3、6×6)将高层次特征信息向低层次特征映射,通过跳跃连接将未经过池化的特征层的高层语义信息与经过池化的特征层的浅层特征信息进行级联融合,保留全局信息,以克服被遮挡或重叠油茶果因网络加深时模型的表征能力不足所带来的网络性能损失。金字塔池化模型的结构如图3所示。
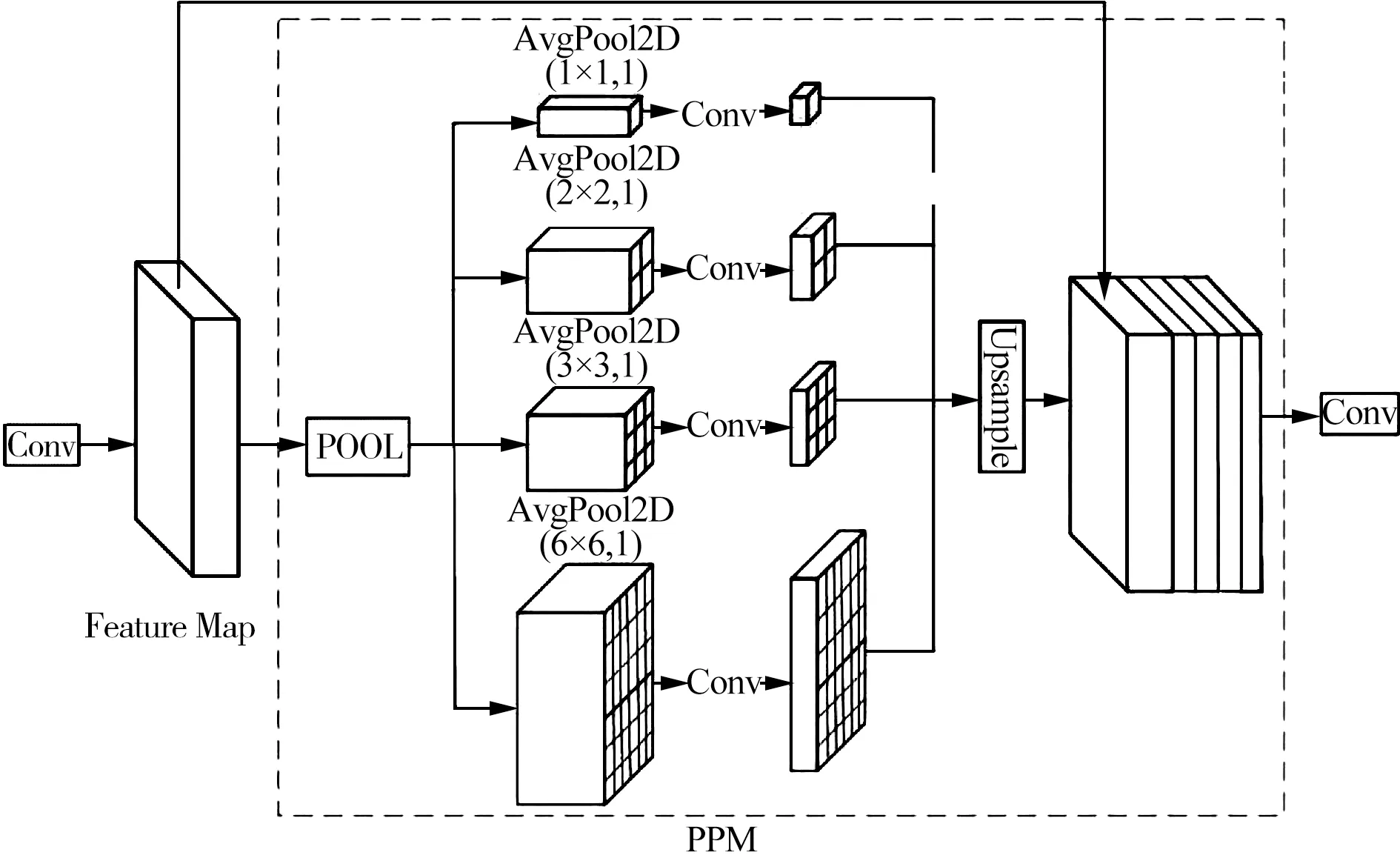
图3 CSP_PPM结构
2.3 K-means聚类先验框
原有YOLOv4-Tiny网络包含2个有效输出特征层,共6个先验框(anchors),改进后的YOLOv4-Tiny网络包含3个有效输出特征层,因此网络训练过程中需要9个先验框。为此本文使用K-means算法对19 005幅图像标注文件中的目标位置信息进行计算,并聚类出适合本文数据集的先验框,以提高bounding box的检出率。K-means聚类出的9个先验框的聚类中心如图4所示。

图4 K-means聚类
由图4可知,聚类出的9个先验框分别为(20,25)、(34,43)、(54,57)、(76,88)、(129,175)、(161,219)、(183,254)、(208,279)和(236,314)。K-means聚类算法采用bounding box与ground truth之间的交并比作为衡量每幅图像应该划进那一簇。K-means算法距离的计算如式(1)所示。
d(box,centroid)=1-IOU(box,centroid)
(1)
式中:d——每幅图像与聚类中心之间的距离;
IOU——bounding box与ground truth之间的交并比;
box——bounding box;
centroid——聚类中心。
3 模型训练及结果分析
3.1 模型训练
使用Pytorch框架搭建CNN网络,并在台式计算机上进行训练。其配置为Inter(R) Core(TM) i5-9400F CPU@2.90 GHz×6,32 GB内存和显存6 GB的GeForce GTX1660Ti,使用的系统为Windows10,安装了CUDA和cuDNN库,Python版本为3.6.13,Pytorch版本为1.2。
网络训练的batch_size前30轮设为16,后70轮设为4,共迭代100轮;学习率(learning_rate)前30轮为10-3,后70轮设为10-4;模型优化器选用随机梯度下降(SGD),根据训练模型梯度下降的程度对初始学习率进行动量减少,以达到更好的模型收敛结果,将动量参数(momentum)设为0.937;为了加快模型收敛,采用YOLOv4-Tiny网络模型的预训练权重;为了防止在模型训练过程中发生过拟合,设置权值衰减(weight_decay)为5×10-4。
训练过程中每迭代完一个epoch,使用验证集对模型训练效果进行评估,计算模型的平均准确率均值mAP、准确率P、F1值和召回率R这4个指标,并将数据保存在日志文件中。准确率P、召回率R以及F1值的计算公式如下。
(2)
(3)
(4)
式中:TP——被模型预测为正类的正样本;
FP——被模型预测为正类的负样本;
FN——被模型预测为负类的正样本;
TN——被模型预测为负类的负样本。
3.2 训练数据分析
训练结束后,从保存在日志文件中的数据读取每迭代一个epoch后模型的训练Loss值和验证Loss值并绘制如图5所示的Loss曲线。
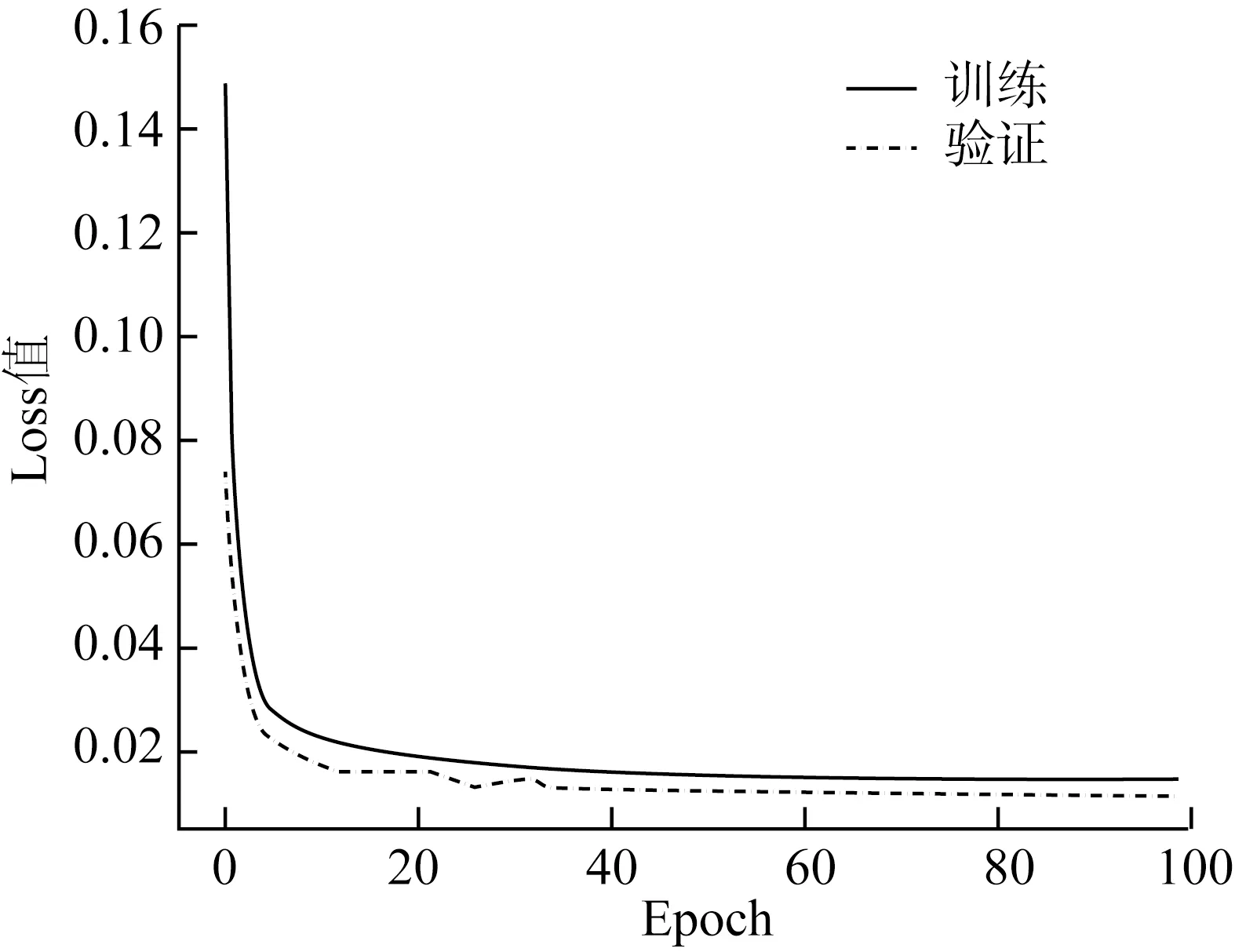
图5 损失值变化曲线
由图5可知,随着训练迭代次数的增加,模型的训练损失值和验证损失值不断减少,且训练集和验证集之间的分类误差逐渐降低。当训练迭代到第30轮左右时,训练损失曲线趋于稳定,没有发生过拟合和欠拟合现象,表明网络模型达到了预期的训练效果。改进后的YOLOv4-Tiny算法的训练损失值收敛于0.013,趋近于0,表明改进后YOLOv4-Tiny网络模型的识别精度较高,各项超参数设置合理。
3.3 油茶果目标识别结果与分析
为了验证改进后YOLOv4-Tiny算法模型的稳定性与可靠性,选取迭代次数为100时保存的权重文件作为模型最终的训练结果,对该算法在1 901幅测试集上油茶果的识别效果进行进一步分析。通过分析结果可知,本文算法在测试集上的召回率为86.15%,mAP为94.19%,F1值为0.9,准确率为94.76%。本文算法在不同环境下油茶果的识别效果如图6所示。

(a) 遮挡果实
如图6(a)和图6(b)所示,当图像中的油茶果被枝叶遮挡或油茶果之间发生重叠时,该算法可以准确识别处图像中被遮挡或存在重叠的油茶果,但预测框与真实框之间的交并比小于无遮挡或无重叠现象油茶果的交并比。如图6(c)所示,该算法在密集分布的油茶果图像识别时的准确率较高,但仍有极少数油茶果未被识别到,这是因为处于远景位置的油茶果特征信息少,不易被网络识别到。
从图6可以看出,改进后的YOLOv4-Tiny算法不仅适用于相邻和独立分布的油茶果图像的识别,也适用于遮挡、重叠及密集分布的油茶果图像的识别,并且在较模糊的油茶果图像识别效果上也有较好的表现。虽然图6中预测框的位置因油茶果存在遮挡或折叠稍有偏离油茶果实际区域,但整体而言油茶果的主要区域已被识别到,且本文算法识别单幅油茶果图像仅需0.025 s,满足实时采摘的要求。
3.4 改进YOLOv4-Tiny识别效果对比试验
为了验证本文所提出的YOLOv4-Tiny改进措施的可行性,使用与本文改进算法相同的数据集和训练超参数对传统YOLOv4-Tiny网络进行训练,并在测试集上进行检测,测试集共有1 901幅油茶果图像。对改进前后YOLOv4-Tiny网络的检测时间与各项性能指标进行比较,网络检测时间如表1所示,召回率、mAP、F1值如表2所示。
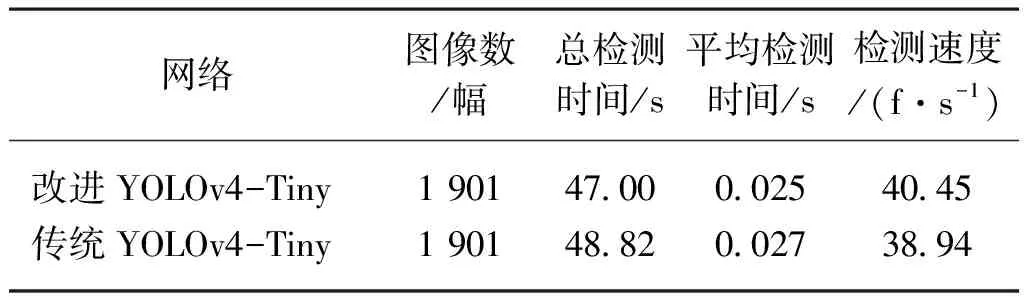
表1 改进前后网络检测时间对比
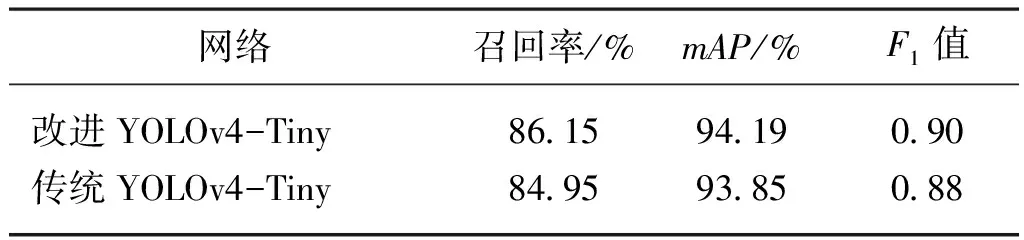
表2 改进前后网络性能对比
由表1和表2可知,改进后的YOLOv4-Tiny网络相比于传统YOLOv4-Tiny网络,在相同测试集上检测速度更快,网络性能更好。改进后YOLOv4-Tiny网络的召回率、mAP和F1值分别提高了1.2、0.34和2个百分点,单幅图像的平均检测时间减少了7.41%,检测速度提高了3.87%。
3.5 与常规方法对比分析
相关文献提出了基于自然环境下油茶果图像的识别方法,为了进一步分析本文所提出的算法性能,与Faster-RCNN[13]、自编码机[14]、凸壳理论[15]3种常规方法进行比较,结果如表3所示。

表3 不同油茶果识别方法的性能比较
从表3可以看出,Faster-RCNN的F1值和识别准确率比本文算法的F1值和识别准确率分别高6.04和4.16个百分点,但其针对的主要是密集、相邻和独立果实检测的检测效果,关于遮挡和重叠果实的识别准确率和F1值未提及,就单幅图片的检测时间而言,该算法的检测时间是本文算法的8.4倍,检测时间较长。自编码机的识别准确率比本文算法降低了4.36个百分点,且单幅图片的检测时间远大于本文算法检测时间。凸壳理论算法的识别准确率与本文算法相近,但单幅图片的检测时间是本文算法的19.64倍,检测时间较长。与上述3种常规算法相比,改进后的YOLOv4-Tiny网络对遮挡、重叠、密集等复杂环境下油茶果的识别准确率位于第2,检测单幅图片的时间最少,综合效果较优,且检测速度满足实时采摘的要求。
4 结论
1) 在原有YOLOv4-Tiny网络的两个有效输出特征层的基础上增加了一个大尺度有效输出特征层,并引入金字塔池化网络对高、浅层特征信息进行融合,使网络学习更多遮挡和重叠目标信息。使用K-means算法聚类出适合本文数据集的先验框,提高模型检测效果。
2) 改进后的YOLOv4-Tiny算法在PASCAL VOC测试集数据上的召回率为86.15%,mAP为94.19%,F1值为0.9,比改进前分别提高了1.2、0.34和2个百分点;改进后该算法在单幅图片的平均检测时间为0.025 s,检测速度为40.45 f/s,比改进前检测时间减少了7.41%,检测速度提高了3.87%,满足实时采摘的要求。
3) 本文算法的识别准确率比自编码机和凸壳理论分别提高4.36和1.55个百分点,比Faster-RCNN降低了4.16个百分点,Faster-RCNN、自编码机和凸壳理论的单幅图片检测时间分别是改进后算法的8.4、66.4和19.64倍。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中外女性健康研究(2020年10期)2020-08-02
中国医学创新(2019年9期)2019-08-19
中国交通信息化(2018年5期)2018-08-21
现代园艺(2017年21期)2018-01-03
现代园艺(2017年21期)2018-01-03
医学信息(2017年16期)2017-09-05
中国西部(2017年4期)2017-04-26
