
基于改进YOLOv5的自然环境下番茄果实检测*
2023-11-11 04:03胡奕帆赵贤林李佩娟赵辰雨陈光明
中国农机化学报 2023年10期
胡奕帆,赵贤林,李佩娟,赵辰雨,陈光明
(1.南京工程学院,南京市,211167; 2.南京农业大学,南京市,210031)
0 引言
我国各地普遍种植番茄,是世界番茄产量最大的国家[1]。但是,番茄采摘主要依靠人工进行,采摘效率较低,无法保证采摘的质量。同时随着城镇化进程的不断推进农村人口减少与人口老龄化,劳动力不足逐渐导致劳动力成本升高[2]。因此,研究番茄果实目标检测算法,提升农业自动化、智能化水平,对于缓解人力资源不足,提高生产效率有着重大影响。
随着农业自动化、智能化的发展,计算机视觉已经被广泛应用于农业机器人当中,Liu等[3]基于YOLOv3网络提出了一个密集的体系结构,可以更加精准地匹配番茄,检测准确率为94.58%;刘芳等[4]为实现温室环境下农业采摘机器人对番茄果实的快速、精确识别,提出了一种改进型多尺度YOLO算法(IMS-YOLO)检测准确率为96.36%,检测时间为7.719 ms;周云成等[5]为提高番茄器官目标识别的准确率,提出一种基于RGB和灰度图像输入的双卷积链Fast R-CNN番茄器官识别网络,双卷积链Fast R-CNN识别网络对果的识别平均准确率最高为63.99%,特征检测时间为320 ms。目标检测是计算机视觉的前提和关键,检测的速度和精确度是考量算法的重要指标。以上方法虽然比传统的番茄果实目标检测方法提高了检测性能,但是难以实现高精度、快速度和低成本等条件下智慧农业的应用。
考虑到检测性能和速度的需求,本文提出一种改进YOLOv5s以检测自然环境下番茄果实的方法,通过添加注意力机制、替换backbone(主干网络)等手段,提高番茄果实检测的准确率和实时性。
1 算法与改进
1.1 目标检测算法
目标检测算法作为计算机视觉的基础,能够提供关键的场景信息。目前方法可以分为两大类:(1)基于候选区域的方法,先生成可能的目标区域,再对其进行分类,如Faster R-CNN和Mask R-CNN,这类方法识别准确,漏检率低,但实时性较差。(2)基于回归框的方法,直接预测目标的位置和类别,如SSD[6]和YOLO[7],这类方法实时性强,但识别准确率和漏检率较第一类稍差。在YOLO系列模型中,YOLOv4和YOLOv5的综合性能较优。尤其是YOLOv5的推理速度更快。
1.2 YOLOv5算法
YOLOv5通过模型设计和训练技巧的改进,达到了精度和速度的平衡,是目前广泛使用的实时目标检测模型之一。数据增强可以通过增加训练样本数量和丰富样本多样性来增强模型的泛化能力,避免过拟合。具体来说,一种方法是通过改变图像的拍摄角度、光照条件、添加遮挡等来获得更多不同的样本。另一种方法是对现有样本进行裁剪、翻转、平移、色域调整等图像变换,制造更多样化的训练数据。这两种数据增强方法可以有效提升模型对不同情景和变化的适应力。YOLOv5自带了多种数据增强技术,主要包括mosaic、cutout、mixup、图像扰动、随机缩放、随机裁剪、随机擦除等。这能产生更多样化的训练数据,增强模型的泛化能力。
为了模型压缩和加速,一种方法是替换网络的backbone架构,通过移除网络冗余信息来减小模型大小和计算量,另一种方法是引入注意力机制,它可以通过聚焦输入信息的关键部分提升模型效率。注意力机制往往是一个较小的子网络结构,可以很方便地集成到各种模型中,SEnet[8]通过对通道维度增加注意力机制,获取每个特征通道的最佳权重值。CBAM[9]结合了空间和通道的注意力机制,取得更好的效果。Triplet Attention[10]在CBAM基础上实现了跨维度交互,实现多维交互而不降低维度的重要性,因此消除了通道和权重之间的间接对应。特征融合用于加强目标检测中对小物体检测,因为卷积过程中,大物体的像素点多,小物体的像素点少,随着卷积的深入,大物体的特征容易被保留,小物体的特征越往后越容易被忽略。BiFPN[5]相当于给各个层赋予了不同权重去进行融合,让网络更加关注重要的层次,而且还减少了一些不必要的层的结点连接。
1.3 具体改进方法
本文提出了四个模块来改进YOLOv5:(1)数据增强模块,使用mosaic、mixup[11]和cutout[12]等方式增强训练集;(2)backbone模块,使用Ghostconv[13]来减少参数量,加速计算;(3)注意力模块,在backbone中添加协同注意力机制(Coordinate Attention[14],CA),聚焦位置信息;(4)特征融合模块,使用改进的BiFPN[15]替换FPN,添加上下文信息,提高特征融合的效率。使用这四个模块的改进,使得模型的检测精度和速度都得到提升,改进后的网络结构如图1所示。
1.3.1 数据增强模块
数据增强部分主要采用了mosaic、cutout和mixup三种方式。其中mosaic数据增强可以在不损失信息的前提下获取二倍大小的特征图。为了进一步提高效果,本文在使用mosaic的同时,引入了cutout和mixup进行组合的数据增强。图2展示了mosaic增强的示例,图3和图4分别展示了cutout和mixup的增强效果,三种增强技术的组合,可以产生更丰富的训练样本,提升模型的泛化能力。

图3 使用cutout增强

图4 使用mixup增强
mixup是一种基于邻域风险最小化的增强技术,其原理是在训练过程中,以一定比例混合两个样本的图像数据和标签,从而构造出新的虚拟训练样本,这可以增强模型的泛化能力,并减少过拟合对错误标签的依赖。简单来说就是将两张图像及其标签平均化为一个新数据。
图像混合公式如式(1)所示。
x_mixup=α×x_i+(1-α)×x_j
(1)
式中:x_mixup——混合后的新图像;
x_i、x_j——两张原始图像;
α——混合比例参数。
标签混合公式如式(2)所示。
y_mixup=α×y_i+(1-α)×y_j
(2)
式中:y_mixup——混合后的新标签;
y_i、y_j——两张原始图像对应的标签。
mixup通过上述公式,以一定比例混合两张图像和标签,从而构造出新的虚拟训练样本。这种数据增广技术可以提高模型的泛化能力,增强对未知数据的适应性。
cutout则是通过在图像中随机遮挡一块区域,迫使模型学习整体特征而非依赖局部信息,以提高模型的鲁棒性。cutout可以增强卷积网络利用全局视觉上下文的能力。
x_{cutout}=M⊙x+(1-M)⊙v
(3)
式中:x——原始图像;
x_{cutout}——遮挡后的图像;
M——与原始图像x相同大小的遮挡Mask,被遮挡位置为0,其余位置为1;
v——用于填充被遮挡部分的真实值,通常设置为0;
⊙——元素对应位置的乘法操作。
1.3.2 backbone改进
传统的深度学习特征图是通过卷积得到的,卷积完成后输入下一个卷积层计算,这样存在大量冗余参数,提取到了大量无用的特征,消耗大量计算资源。如图5与图6所示,相比于YOLOv5的主干网络CSPDarknet53中的传统卷积,Ghostconv的计算成本更低,仅通过少量计算(cheap operations)就能生成大量特征图的结构,并且可以适用在任何大型的CNN模型中。Ghostconv卷积部分将传统卷积操作分为两部分:第一步,使用少量卷积核进行卷积操;第二步,使用3×3或5×5的卷积核进行逐通道卷积操作,最终将第一部分作为一份恒等映射与第二部分进行拼接。
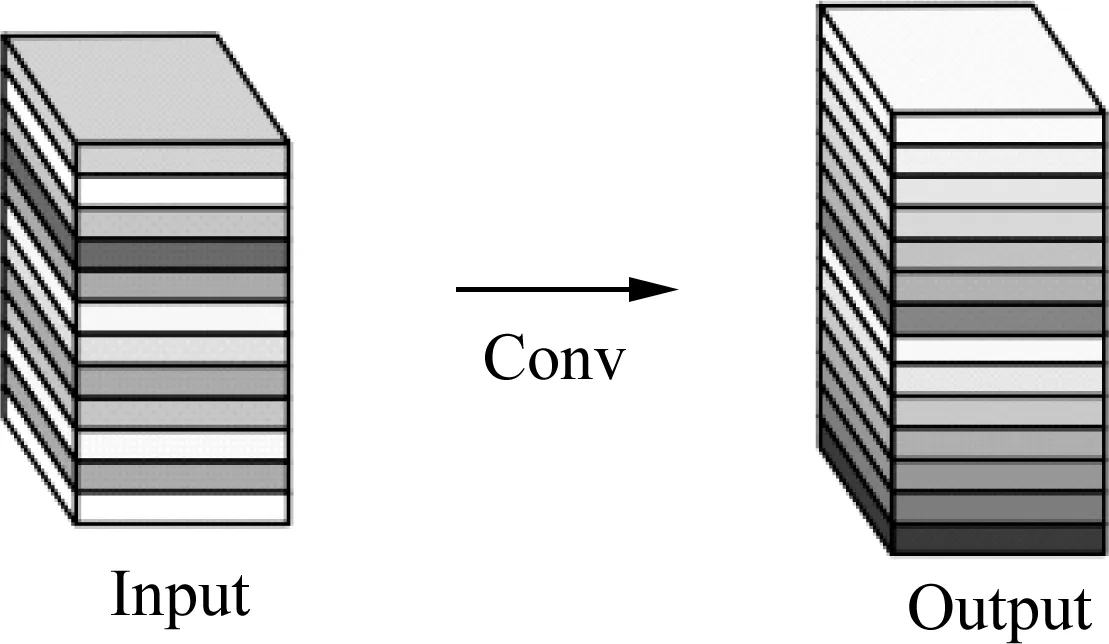
图5 Ghost卷积
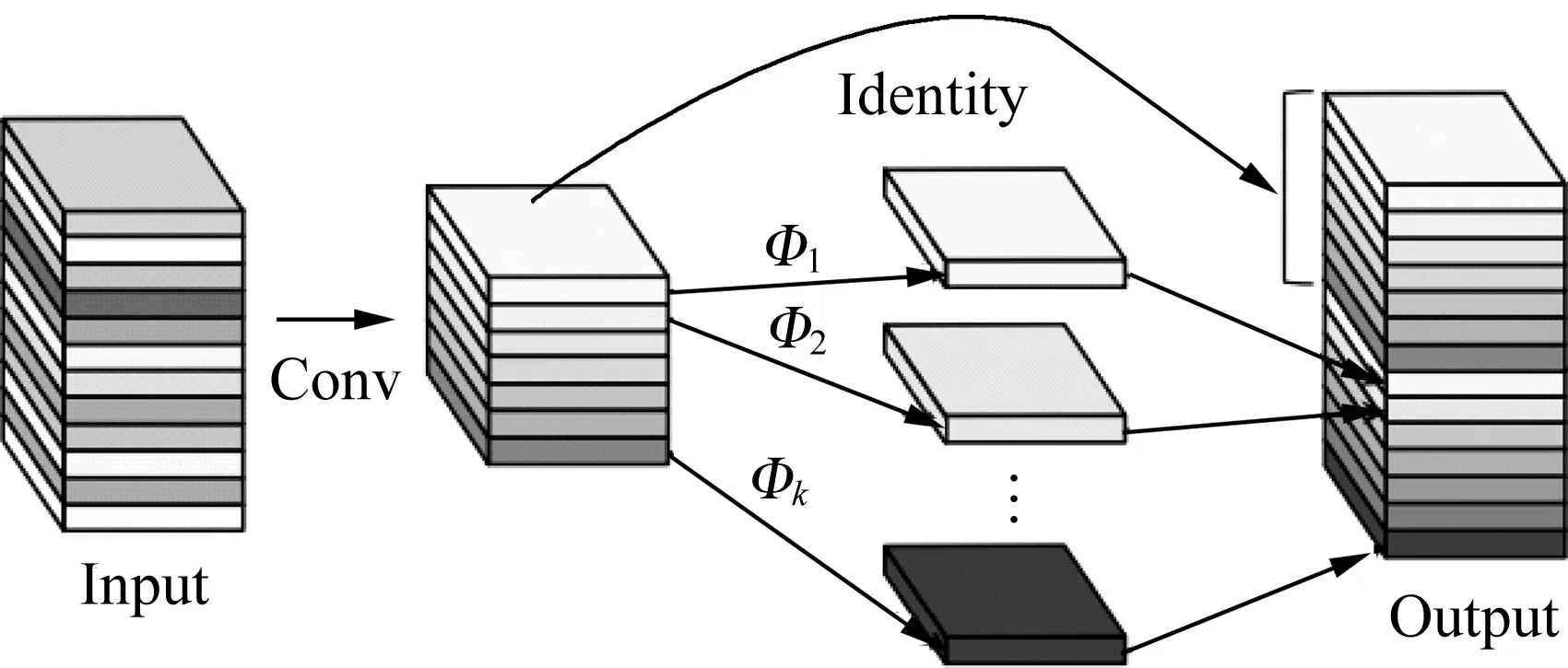
图6 Ghost模块
Ghost Bottleneck的作用和残差块的作用一样,结构也和残差块的结构类似。如图7所示,模块部分有两种结构,Stride=1,即当不进行下采样时,直接进行两个Ghostconv操作;Stride=2,当进行下采样时,增加一个Stride=2的深度卷积操作。将Ghostconv替换YOLOv5的主干网络后可以降低网络的计算成本,加速计算。
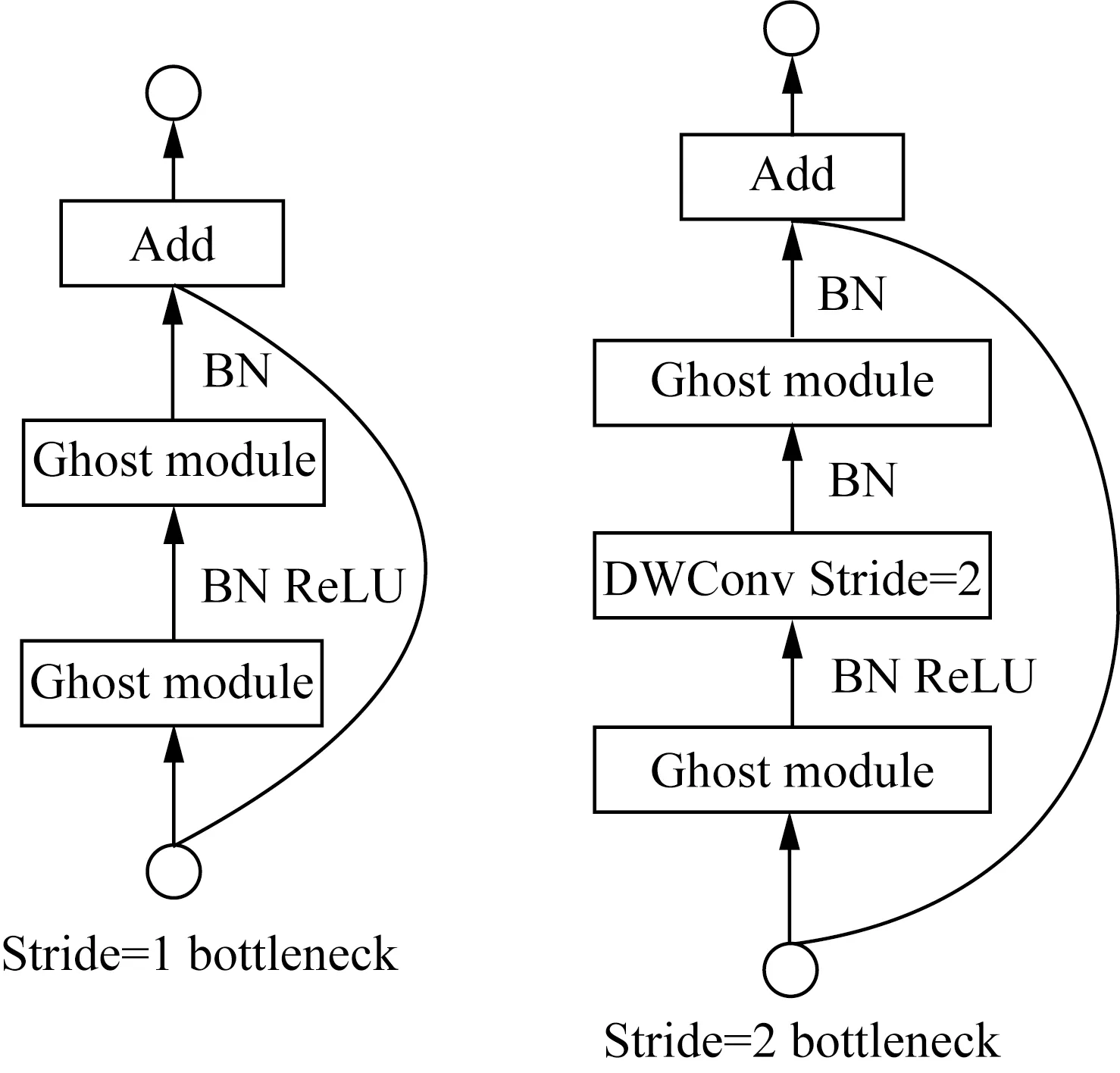
图7 Ghost瓶颈层
1.3.3 注意力机制模块
注意力机制可以显著提升模型性能,主要分为通道注意力和空间注意力,通道注意力如SENet可以明显增强效果,但通常会忽略位置信息,而位置信息对生成空间注意图非常重要,先前的CBAM模块虽然引入空间信息编码,但未建立通道和空间注意力之间的关联。CA模块(图8)通过精确的位置信息对通道关系和长期依赖性进行编码,将通道注意力分解为两个一维特征编码过程,并分别沿两个空间方向聚合特征。这样,既可以沿一个方向捕获远程依赖,又可以沿另一方向保留精确的位置信息。
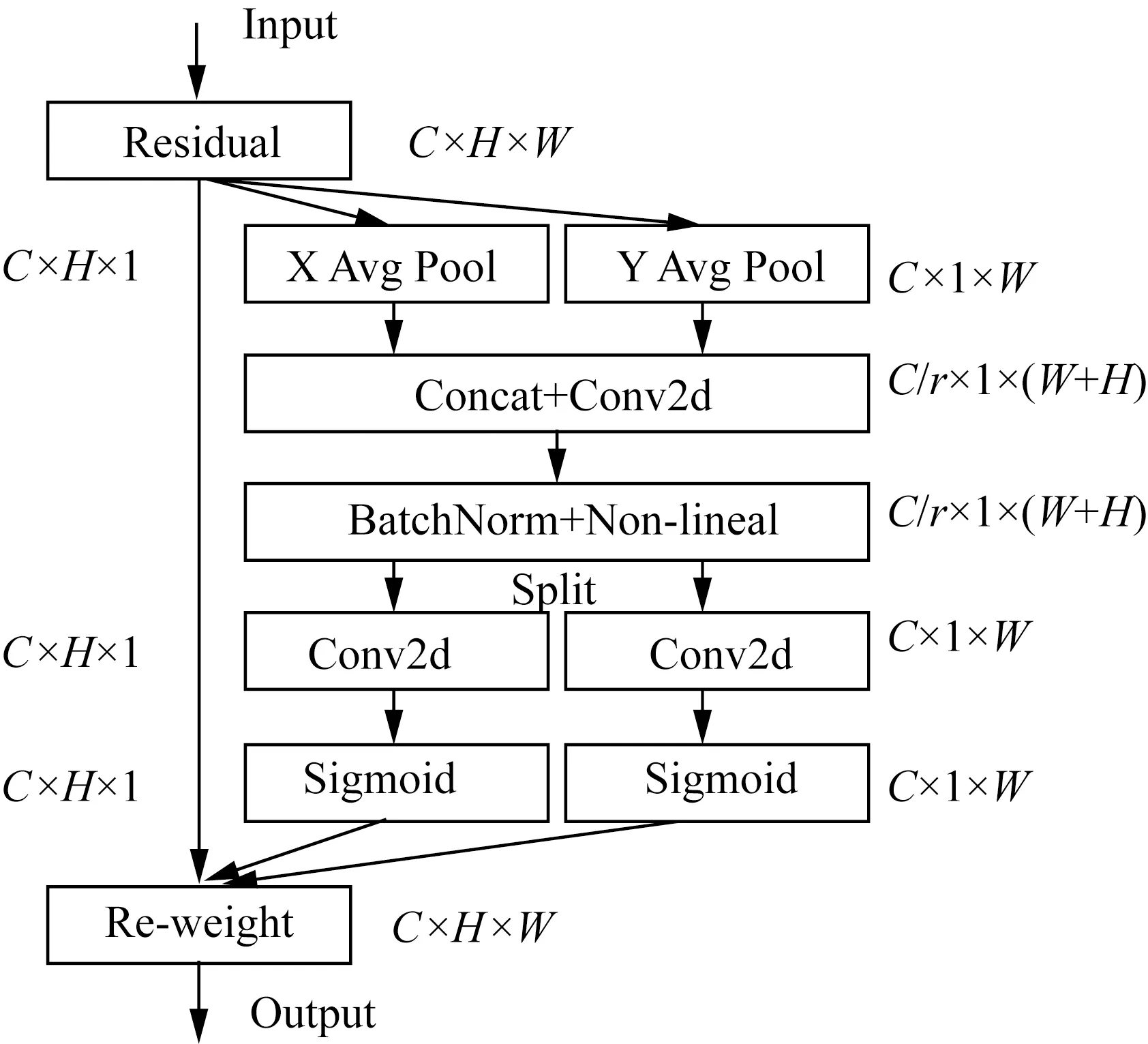
图8 CA注意力机制结构
CA分两个步骤:第一步是Coordinate Embedding,其目的是编码每个位置的精确空间信息。具体做法是使用一维池化核对特征图在高度和宽度上分别进行池化,得到一对编码后的一维向量。第二步是Coordinate Attention生成,它基于第一步的编码结果,通过全连接网络学习生成每个位置的注意力权重。这样通过编码精确的坐标信息,CA模块可以建模空间依赖关系,从而产生有效的注意力增强。具体公式如式(4)、式(5)所示。
h_c=δ[AvgPool1D(X;kernel_h)]
(4)
w_c=δ[AvgPool1D(X;kernel_w)]
(5)
式中:AvgPool1D——一维平均池化操作;
X——原始特征;
w_c——图像的宽;
h_c——图像的高;
kernel_h——特征图高;
kernel_w——特征图高。
将上述两组编码连接起来,输入一个多层全连接网络,学习注意力权重
f([h_c,w_c])=W2σ(W1[h_c,w_c])
(6)
式中:f——多层全连接网络;
σ——激活函数;
W1、W2——权重矩阵。
最终的CA注意力映射
CA(X)=f([h_c,w_c])⊗X
(7)
其中⊗表示逐元素相乘,即对原特征X进行加权。
从效果上看,CA模块相比SEnet、CBAM等注意力结构有更优秀的性能,因为CA通过精确的坐标编码增强了网络对目标的关注能力,这样可以更好地提升模型的检测性能,而计算量也比较低。总体来说,CA模块设计精巧,既考虑了位置信息对注意力的重要性,又控制了计算复杂度,相比其他结构,CA可以产生更有针对性和高效的注意力机制来增强模型。
1.3.4 特征融合
深度学习中融合不同尺度特征是提高性能的关键,低层特征包括位置、细节,高层特征具有更强的语义信息,通过将两者结合可以改善模型效果。FPN属于neck部分,用于构建所有尺度的高级语义特征。如图9所示,FPN结构存在缺陷,如层与层之间存在语义鸿沟,直接融合会降低作用;下采样过程中会损失高层特征;各层ROI独立参与预测导致各层关联性小。在YOLOv5的neck部分中使用FPN+PAN结构,FPN引入了一条自顶向下的通道来融合特征,PANet在FPN基础上增加了一条自底向上的通道,NAS-FPN使用了不规则拓扑结构,这需要消耗大量的计算资源。BiFPN使用了类似Resnet的结构并且移除了边缘节点,然后将这两层当成一个模块,重复调用来获取更高层次的特征融合。使用softmax会带来较大的GPU延迟,因此BiFPN使用了Fast normalized fusion来模拟Softmax-based fusion,由于未使用指数因此计算速度更快,公式如式(8)所示。

(a) FPN
(8)
式中:wi——可学习的权重;
O——特征融合输出;
Ii——输入。
其中wi≥0并且在每个wi≥0后应用一个ReLu激活函数保证其大于0,ε=0.000 1来防止网络不稳定。
2 试验和结果分析
2.1 数据集和试验环境
本文的数据集来源于自己制作的数据集,分为成熟的番茄和未成熟的番茄两个类别。图像分辨率为720像素×720像素,共830张照片。数据集以7∶3比例划分训练集和验证集,其中训练样本为580张,验证样本为250张。本文试验环境:Intel© Xeon Silver 4216 (64)内存128 GB,显卡为NVIDIA GeForce RTX 2080 Ti 12G×2,操作系统为Ubuntu20.04,在Pytorch 1.10.0下实现模型的搭建及试验。
训练参数:将本文划分好的数据集作为输入,设置输入为640×640,学习率设置为0.001,动量和权重衰减被设置为0.937和0.000 5。采用Adam优化器对网络参数进行优化。Batch_size设置为32。
2.2 评价指标
目标检测常用的评价指标:准确率(Precision,P)、召回率(Recall,R)、平均精度均值(mAP,mean Average Precision)、F1,计算公式如式(9)~式(12)所示。
(9)
(10)
(11)
(12)
式中:TP——检测模型识别为番茄果实成熟或不成熟且正确的数量;
FP——检测模型识别番茄果实成熟或不成熟但错误的数量;
FN——检测模型遗漏识别番茄果实的数量;
AP——番茄果实检测平均精度;
N——模型检测所有种类的数量。
本文使用mAP@0.5、mAP和F1作为评价指标,来全面评估番茄检测模型的性能,mAP@0.5聚焦不同检测阈值下的精度,mAP给出不同类别的平均性能,F1综合考虑精度和召回率。
2.3 与主要目标检测算法性能对比
为进一步验证本文提出算法的性能,与YOLOv3-spp、YOLOv5s+Mobilenet v3和YOLOv5s模型进行对比试验,试验结果如表1所示。

表1 不同模型在同一数据集的性能对比
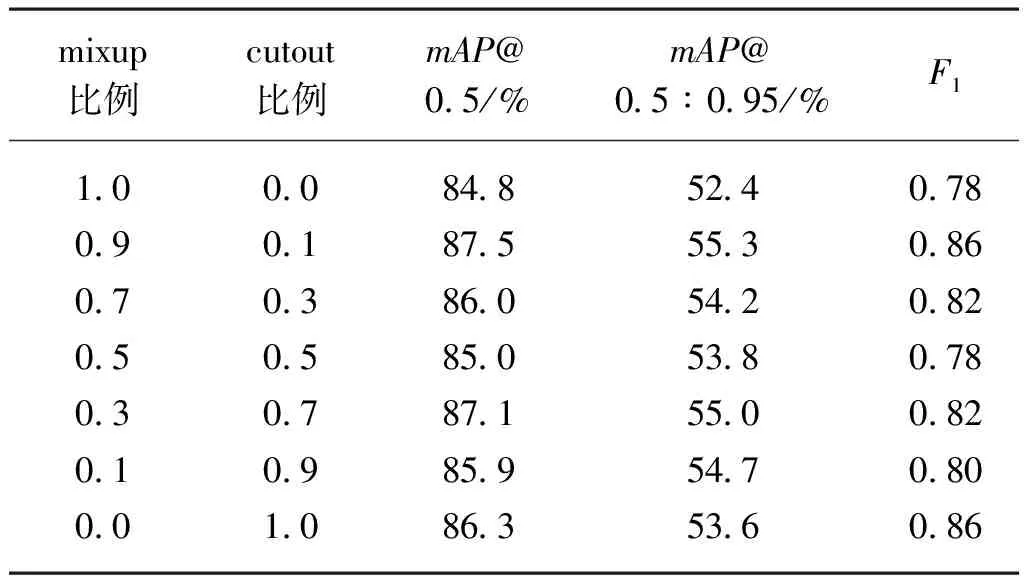
表2 不同数据增强比例对于YOLOv5s性能影响
YOLOv5s+Mobilenet v3是将YOLOv5s的主干网络由CSPDarknet替换完Mobilenet v3来缩减模型大小,速度达到了174 fps,但是mAP下降,本文相对于原始的YOLOv5模型mAP@0.5提高了4.2%,成熟番茄的识别率提高了1.9%,未成熟的番茄提高了0.5%,检测速度为101 fps,满足检测要求。图10为本文方法和YOLOv5s检测结果对比。总体而言,试验验证了所提方法在提高精度的同时,仍保持了较快的检测速度。

(a) YOLO v5s
2.4 不同数据增强方式对比试验
由于自然环境中番茄遮挡情况较多,因此采用cutout数据增强。在使用mosaic时,试验了mixup和cutout不同比例的组合效果。将两者比例之和设为1,测试了0∶1、0.1∶0.9、0.3∶0.7、0.5∶0.5、0.7∶0.3、0.9∶0.1的值。结果表明,当mixup为0.9比例、cutout为0.1比例时,mAP@0.5达到87.5%,F1为0.84,相较无增强分别提升了0.5%和0.02。该组合比例下模型精度最优。
2.5 消融试验
为分析各改进对模型性能的影响,进行了消融试验。试验详情见表3,其中“√”表示该模块被使用,“×”表示未使用。YOLOv5s-A使用Ghostconv获得mAP@0.5提升但mAP下降。YOLOv5s-B在A基础上改用BiFPN,mAP@0.5和mAP较原网络均有提升。YOLOv5s-C在B基础上添加CA模块,mAP@0.5相比B提升0.4%,mAP提升2.4%。YOLOv5s-D在C基础上加入mixup和cutout,mAP@0.5达到87.5%,提升0.6%。

表3 消融试验
综上,各模块对检测精度均有提升,特别是CA模块和数据增强的联合使用取得了最佳效果。
3 结论
1) 本文针对自然环境下的番茄检测任务,在YOLOv5s模型基础上进行了以下几点改进:引入cutout数据增强,缓解遮挡问题;使用Ghostconv降低模型冗余;添加CA注意力机制增强特征表达;改用BiFPN进行多尺度特征融合。
2) 改进后的模型mAP@0.5达到87.5%,检测速度101 fps,精度和速度均满足实际需求。与其他主流检测算法比较,也显示出计算效率和资源占用上的优势,更适合本研究的应用场景。本研究为机器人番茄采摘与智能农业提供了有效的检测算法支持,具有推动作用。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
小猕猴学习画刊(2022年12期)2022-02-06
今日农业(2021年21期)2022-01-12
北京航空航天大学学报(2021年9期)2021-11-02
今日农业(2020年23期)2020-12-15
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
